Помехоустойчивое кодирование. Теорема Шеннона
Теория помехоустойчивого кодирования базируется на результатах исследований, проведенных Шенноном и сформулированных им в виде теоремы:
Хотя доказательство этой теоремы, предложенной Шенноном, в дальнейшем подвергалось более глубокому и строгому математическому представлению, идея его осталась неизменной. Доказывается только существование искомого способа кодирования, для чего находят среднюю вероятность ошибки по всем возможным способам кодирования и показывают, что она может быть сделана сколь угодно малой. При этом существует хотя бы один способ кодирования, для которого вероятность ошибки меньше средней.
Источник создает информацию со скоростью Vх букв в секунду и энтропией каждой буквы в среднем Н(х), т.е. его производительность:
В соответствии с теоремой о эффективном кодировании среднее количество символов на одну букву lср ≥ Н(х), т.е. в первом приближении можно получить, что
При наличии помех пропускная способность канала связи падает, т.е. при двоичном симметричном канале имеем:
Теорема о помехоустойчивом кодировании требует чтобы
где lср – средняя длина кодовой комбинации для записи одной буквы.
По сравнению с эффективным кодом lср увеличивается до:

Однако, такой величины lср1 помехоустойчивые коды не достигают. Это можно рассматривать как теоретический предел.
MT1402: Теоретические основы информатики. Имитационное моделирование
Как отмечалось при рассмотрении исходных понятий информатики, для представления дискретных сообщений используется некоторый алфавит. Однако однозначное соответствие между содержащейся в сообщении информацией и его алфавитом отсутствует.
В целом ряде практических приложений возникает необходимость перевода сообщения хода из одного алфавита к другому, причем, такое преобразование не должно приводить к потере информации.
Введем ряд с определений.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Не обсуждая технических сторон передачи и хранения сообщения (т.е. того, каким образом фактически реализованы передача-прием последовательности сигналов или фиксация состояний), попробуем дать математическую постановку задачи кодирования.
смысл которого в том, что операция обратимого кодирования может увеличить количество информации в сообщении, но не может его уменьшить. Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднее информационное содержание знака, т.е.:
Как следует из (3.1), минимально возможным значением средней длины кода будет:
Первая теорема Шеннона, которая называется основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак первичного алфавита, будет сколь угодно близко к отношению средних информации на знак первичного и вторичного алфавитов.
Из (3.2) видно, что имеются два пути сокращения %%K_
В качестве меры превышения К(А,В) над %%K_
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения. Очевидно, %%Q(A,B) → 0%% при %%К(А,В) → K_
Используя понятие избыточности кода, можно построить иную формулировку теоремы Шеннона:
При отсутствии помех всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
При декодировании двоичных сообщений возникает проблема выделения из потока сигналов (последовательности импульсов и пауз) кодовых слов (групп элементарных сигналов), соответствующих отдельным знакам первичного алфавита. При этом приемное устройство фиксирует интенсивность и длительность сигналов, а также может соотносить некоторую последовательность сигналов с эталонной (таблицей кодов). Возможны следующие особенности вторичного алфавита, используемого при кодировании:
Комбинации перечисленных особенностей определяют основу конкретного способа кодирования, однако, даже при одинаковой основе возможны различные варианты построения кодов, отличающихся своей эффективностью. Нашей ближайшей задачей будет рассмотрение различных схем кодирования для некоторых основ.
Информационная теория
Обработка информации — важная техническая задача, чем, например, преобразование энергии из одной формы в другую. Важнейшим шагом в развитии теории информации стала работа Клода Шеннона (1948). Логарифмическое измерение количества данных было первоначальной теорией, и прикладными задачами по коммуникации в 1928 году. Наиболее известным является вероятностный подход к измерению информации, на основе которого представлен широкий раздел количественной теории.
Отличительная черта вероятностного подхода от комбинаторного состоит в том, что новые предположения об относительной занятости любой системы в разных состояниях и общего количества элементов не учитываются. Ряд информации взят из отсутствия неопределённости в выборе различных возможностей. В основе такого подхода лежат энтропийные и вероятностные множества.
Основная теорема Шеннона о кодировании
Важный практический вопрос при обработке информации — какова мощность системы передачи данных. Можно получить определённый ответ, используя уравнение Шеннона. Оно позволяет точно понять информационную пропускную способность любого сигнального канала. Формула Шеннона в информатике: I = — (p1log2 p1 + p2 log2 p2 +. + pN log2 pN)
Основная теория Шеннона о кодировании для дискретного канала с помехой, приведённая здесь без доказательства, аналогична теореме канала не имеющего помех: если источник данных с энтропией H (Z), а канал связи имеет ширину полосы C, то сообщения, сгенерированные источником, всегда могут быть закодированы так, чтобы их скорость передачи vz была произвольно близка к значению: vzm = C | H (Z).
Не существует метода кодирования, который бы позволял передавать со скоростью, превышающей vzm, и с произвольно низкой вероятностью ошибки. Другими словами, если поток информации: H ‘(Z) = vz * H (Z) C он не существует.
Стоит рассмотреть сигнал, который эффективно передаётся (т. е. без избыточности) в виде зависящего от времени аналогового напряжения. Картина изменения в течение определённого интервала T позволяет приёмнику выявить, какое из возможных сообщений было фактически отправлено.
Используя идею межсимвольного влияния, можно сказать, что, поскольку нет избыточности значения будут независимыми при условии, и они достаточно далеки друг от друга, чтобы их стоило отбирать отдельно. По сути, невозможно сказать, что одно из значений просто от знания другого. Конечно, для любого сообщения оба типа данных заранее определяются содержанием.
Но получатель не может знать, какое из всех возможных сообщений прибыло, пока оно не пришло. Если приёмник заранее знает, какое напряжение, должно быть, передано, то само сообщение не дало бы никакой новой информации! То есть получатель не будет знать больше после его прибытия, чем раньше.
Это приводит к замечательному выводу:
Именно поэтому случайный шум может привести к ошибкам в полученном сообщении. Статистические свойства эффективного сигнала аналогичны. Если шум был явно разным, приёмник мог легко отделить информацию и избежать каких-либо неполадок. Поэтому для обнаружения и исправления ошибок нужно сделать реальный сигнал менее «шумоподобным».
Условие применения формулы Шеннона — избыточность, создаёт предсказуемые отношения между различными участками сигнального устройства. Хотя это снижает эффективность передачи информации в системе, но помогает отличать детали сигнала от случайного шума. Здесь обнаружена максимально возможная информационная пропускная способность системы. Поэтому нужно избегать избыточности и позволять сигналу иметь «непредсказуемые» качества, которые делают его статистически похожим на случайный шум.
Передача сигналов
Реальный сигнал должен иметь конечную мощность. Следовательно, для этого набора сообщений должен быть некоторый максимально возможный уровень мощности. Это значит что напряжение тока сигнала ограничено к некоторому ряду. Это также означает, что мгновенное напряжение сигнала, должно быть, ограничено и не выступает за пределы диапазона. Аналогичный аргумент должен быть верен и для шума. Поскольку предполагается, что система эффективна, можно ожидать, сигнал и шум будут иметь аналогичные статистические свойства.
Это означает:
При передаче сигналов в присутствии шума нужно стараться, чтобы сигнал был больше и свести к минимуму эффекты шума. Поэтому можно ожидать, что система передачи информации применится и обеспечит, чтобы для каждого типичного сообщения сила почти равнялось некоторому максимальному значению.
Это означает, что в такой системе, большинство сообщений будет одинаковый уровень мощности. В идеале каждое ИС должно иметь одинаковый, максимально возможный уровень мощности. На самом деле можно повернуть этот аргумент с ног на голову и сказать, что «типичны» только сообщения со средними силами, подобными этому максимуму. Те, что обладают гораздо более низкими способностями, необычны — то есть редки.
Определённое уравнение
Сигнал и шум не коррелированны, то есть они не связаны каким-либо образом, который позволит предсказать один из них. Суммарная мощность, получаемая при объединении этих некоррелированных ИС, по-видимому, случайно изменяющихся величин, задаётся.
Поскольку сигнал и шум статистически аналогичны, их комбинация будет иметь то же значение форм-фактора, что и сам сигнал или шум. Потому можно ожидать, что комбинированный сигнал и шум, как правило, будут ограничены диапазоном напряжения.
Стоит рассмотреть теперь разделение этого диапазона на полосы одинакового размера. (т. е. каждая из этих полос будет охватывать ИС.) Чтобы предоставить другую метку для каждой полосы, нужны символы или цифры. Поэтому всегда можно указать, какую полосу занимает уровень напряжения в любой момент с точки зрения B-разрядного двоичного числа. По сути, этот процесс является ещё одним способом описания того, что происходит, когда берут цифровые образцы с B-разрядным аналоговым преобразователем, работающим в общем диапазоне.
Нет никакого реального смысла в выборе значения, которое настолько велико. Это потому что шум кубика будет просто иметь тенденцию рандомизировать фактическое напряжение на эту сумму, делая любые дополнительные биты бессмысленными. В результате максимальное количество битов информации, которую можно получить относительно уровня в любой момент, будет определено.
Уравнение Шеннона может использовать:
При передаче информации некоторые параметры используемых сигналов могут приобретать случайный символ в канале связи, например, из-за многолучевого распространения радиоволн, гетеродинирующих сигналов. В результате амплитуда и начальная фаза данных являются случайными. Согласно статистической теории связи, эти особенности сигналов необходимы для их оптимальной обработки, они определяют как структуру приёмника, так и качество связи.
Хартли понимал информационное получение как подбор одного вида данных из набора равновероятного сообщения и определил объём, содержащейся ВС, как логарифм N. Выполняются примеры решения по формуле Хартли в информатике: N = mn.
Помехи разложения всегда присутствуют в границе любого реального сигнала. Однако, если их уровень настолько мал, что вероятность искажения практически равна нулю, можно условно предположить, что все сигналы передаются неискажёнными.
В этом случае средний объём информации, переносимой одним символом, можно считать расчётным: J (Z; Y) = Хапр (Z) — Хапест (Z) = Хапр (Y). Поскольку функция H (Y) = H (Z) и H (Y / Z) = 0, а индекс max
Следовательно, главная дискретная ширина полосы таблицы без информации о помехах в единицу времени равна: Cy = Vy • max
Согласно теореме, метод кодирования онлайн, который может использоваться и позволяет:
Вероятностный подход к определению вычисления объёма информации — математический вывод формулы Шеннона не является удовлетворительным для метода оценки роли энтропии, отражения элементов системы и может не применяться. Как общий информатический объект невозможно допустить единый способ измерения и его правила.
5rik.ru
Материалы для учебы и работы
Основная теорема Шеннона о кодировании для канала с помехами.
Информационная способность кода и избыточность.
Получатель сообщения в каком-либо коде не знает, какой из символов к нему поступит, поэтому сообщения (сигналы) в любом коде можно рассматривать как системы со многими случайными состояниями. Число возможных состояний равно числу всех различимых сигналов (символов) кода. Это дает возможность говорить об энтропии кода. Если считать, что все N символов (сигналов) кода при передаче сообщений могут появляться с равной вероятностью, то вероятность каждого их них будет  .
.
Теорема помехоустойчивого кодирования базируется на результатах исследований проведенных Шенном и сформулированных им в виде теоремы:
1. При любой производительности источника сообщений, меньшей, чем пропускная способность канала, существует такой способ кодирования, который позволяет обеспечить передачу всей информации, создаваемой источником сообщений, со сколь угодно малой вероятности ошибки.
2. Не существует способа кодирования, позволяющего вести передачу информации со сколь угодно малой вероятностью ошибки, если производительность источника сообщений больше пропускной способности канала.
Анализ теоремы. Теорема устанавливает теоретический предел возможной эффективности системы при достоверной передачи информации. Ею опровергнуто представление о том, что достижение сколь угодно малой вероятности ошибки в случае передачи информации по каналу с помехами, возможно лишь при введении бесконечно большой избыточности, т.е. при уменьшении скорости передачи до нуля. Из теоремы следует, что помехи в канале не накладывают ограничений на точность передачи. Ограничение накладывается только на скорость передачи, при которой может быть достигнута сколь угодно высокая достоверность передачи.
Теорема неконструктивна: в ней не затрагивается вопрос о путях построения кодов.
Следует отметить, что при любой конечной скорости передачи информации вплоть до пропускной способности сколь угодно малая вероятность ошибки достигается лишь при безграничном увеличении длительности кодируемых последовательностей знаков. Не исключено, конечно, вероятность, что искаженный в нескольких элементах сигнал 1 или сигнал 3, но вероятность искажения сигнала в нескольких элементах значительно меньше, чем в одном.
Для выполнения коррекции единичного искажения необходимо построить цепи расшифровки таким образом, чтобы исполнительный срабатывал как при приеме неискаженного сигнала, так и при приеме сигналов, отличающихся от основного одним элементом.
Рассматриваемый код обладает значительной избыточностью
 ,
,
т.е. 3 элемента из 5 несут контрольные и корректирующие функции, не обеспечивая передачу информации.
Общее число элементов n корректирующего кода определяется как сумма рабочих (информационных) элементов n0 и контрольных элементов k:

Из неравенства при заданном N определяются n0, n и затем k.
Число элементов, в которых одна кодовая комбинация должна отличаться от другой, или, как говорят, число переходов определяется по формуле
где r – число обнаруживаемых ошибок; s – число исправляемых ошибок.
Пример кода с автоматическим исправлением ошибок рассмотрим на практическом занятии.
В заключении приведем основную теорему Шеннона о кодировании для канала с помехами.
В качестве примера рассмотрим определение избыточности приведенного ранее n-элементарного (n=4) кода на одно сочетание (k=2), обеспечивающего 6 комбинаций.
 , округляем до n0=3.
, округляем до n0=3.

Это означает, что ¼ от элементов в коде на одно сочетание является избыточной, не выполняет функций передачи информации. Введение их вызвано не требованиями кодирования, а стремлением повысить помехоустойчивость сигнала.
Инструменты сайта
Основное
Навигация
Информация
Действия
Содержание
Статус документа: черновик.
Теория информации по Шеннону
Энтропия
Если наше событие (опыт) состоит в определении цвета первой встретившейся нам вороны, то мы можем почти с полной уверенностью рассчитывать, что этот цвет будет черным. Несколько менее определено событие (опыт), состоящее в выяснении того, окажется ли первый встреченный нами человек левшой или нет — здесь тоже предсказать результаты опыта можно, почти не колеблясь, но опасения в относительно правильности этого предсказания будут более обоснованны, чем в предыдущем случае. Значительно труднее предсказать заранее пол первого встретившегося нам на улице человека. Но и этот опыт имеет относительно небольшую степень неопределенности по сравнению, например с попыткой определить победителя в чемпионате страны по футболу с участием двадцати совершенно незнакомых нам команд.
Пример. Предположим, что найденная Иваном-царевичем лягушка в течение минуты либо
После приведения этой формулировки, Шеннон пишет:
Происхождение слова «энтропия» ☞ ЗДЕСЬ.
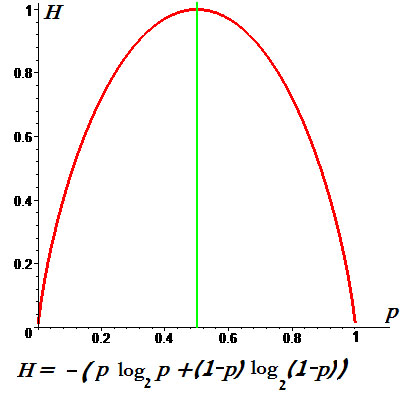
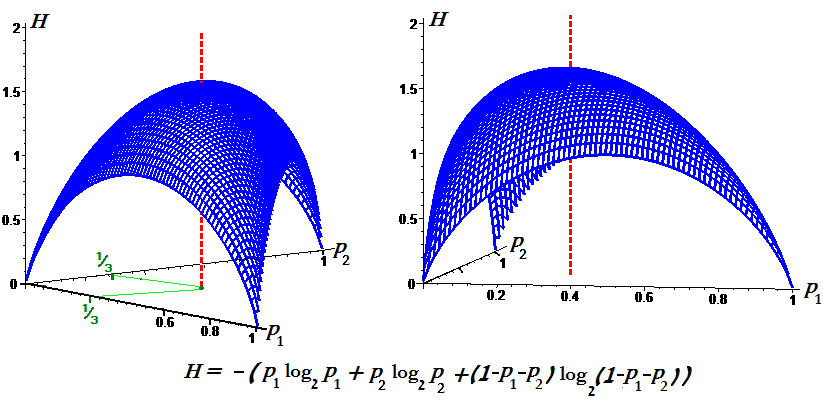
Свойства энтропии
Проанализируем теперь формулу для энтропии.
Условная энтропия
Проиллюстрируем результат теоремы на примере, который подробно будем разбирать во всех последующих пунктах. Источник приведенных в нем данных ☞ ЗДЕСЬ.
Пример. Пусть случайный процесс заключается в ежесекундном появлении на экране монитора одной буквы русского алфавита в соответствии с приведенными ниже вероятностями
Пока мы только лишь формально осваиваем введенный математический аппарат, оставляя обсуждение лежащего под ним здравого смысла до следующих пунктов.
Понятие об информации
Информационная избыточность
Если считать, что коммуникация каждого из символов нового алфавита «стоит» одинакового количества ресурсов (энергии, времени), то наиболее выгодный код позволит сэкономить эти ресурсы.
Частота встречаемости букв в обычном (неспециальном) тексте (без учета пробелов) [2]:
| a | б | в | г | д | е,ё | ж | з | и | й | к | л | м | н | о | п | р |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.075 | 0.017 | 0.046 | 0.016 | 0.030 | 0.087 | 0.009 | 0.018 | 0.075 | 0.012 | 0.034 | 0.042 | 0.031 | 0.065 | 0.110 | 0.028 | 0.048 |
| с | т | у | ф | х | ц | ч | ш | щ | ъ,ь | ы | э | ю | я | |||
| 0.055 | 0.065 | 0.025 | 0.002 | 0.011 | 0.005 | 0.015 | 0.007 | 0.004 | 0.017 | 0.019 | 0.003 | 0.007 | 0.022 |
Пример [обезьяна за клавиатурой]. Известна теорема о бесконечных обезьянах: абстрактная обезьяна, ударяя случайным образом по клавишам печатной машинки 7) в течение неограниченно долгого времени, рано или поздно напечатает любой наперёд заданный текст (например «Войны и мира»). В указанной ссылке приводятся оценки времени наступления этого события. Следующие примеры 8) показывают, что может произойти, если обезьяна будет бить по клавиатуре специально сконструированной машинки, в которой клавиши соответствуют биграммам, триграммам и т.п. русского языка и при этом размеры клавиш пропорциональны частотам встречаемости в русском языке (а обезьяна будет чаще ударять по большим клавишам).
Приближения нулевого порядка (символы независимы и равновероятны):
ФЮНАЩРЪФЬНШЦЖЫКАПМЪНИФПЩМНЖЮЧГПМ ЮЮВСТШЖЕЩЭЮКЯПЛЧНЦШФОМЕЦЕЭДФБКТТР МЮЕТ
Приближение первого порядка (символы независимы, но с частотами, свойственными русскому языку):
ИВЯЫДТАОАДПИ САНЫАЦУЯСДУДЯЪЛЛЯ Л ПРЕЬЕ БАЕОВД ХНЕ АОЛЕТЛС И
Приближение второго порядка (частотность диграмм такая же как в русском языке):
ОТЕ ДОСТОРО ННЕДИЯРИТРКИЯ ПРНОПРОСЕБЫ НРЕТ ОСКАЛАСИВИ ОМ Р ВШЕРГУ П
Приближение третьего порядка (частотности триграмм такие же как в русском языке):
С ВОЗДРУНИТЕЛЫБКОТОРОЧЕНЯЛ МЕСЛОСТОЧЕМ МИ ДО
Вместо того, чтобы продолжить процесс приближения с помощью тетраграмм, пентаграмм и т.д., легче и лучше сразу перейти к словарным единицам. Приближение первого порядка на уровне слов 9) : cлова выбираются независимо, но с соответствующими им частотами.
СВОБОДНОЙ ДУШЕ ПРОТЯНУЛ КАК ГОВОРИТ ВСПОМНИТЬ МИЛОСТЬ КОМНАТАМ РАССКАЗА ЖЕНЩИНЫ МНЕ ТУДА ПОНЮХАВШЕГО КОНЦУ ИСКУСНО КАЖДОМУ РЯСАХ К ДРУГ ПЕРЕРЕЗАЛО ВИДНО ВСЕМ НАЧИНАЕТЕ НАД ДВУХ ЭТО СВЕТА ХОДУНОМ ЗЕЛЕНАЯ МУХА ЗВУК ОН БЫ ШЕЮ УТЕР БЕЗДАРНЫХ
Приближение второго порядка на уровне слов. Переходные вероятности от слова к слову соответствуют русскому языку, но «более дальние» зависимости не учитываются:
ОБЩЕСТВО ИМЕЛО ВЫРАЖЕНИЕ МГНОВЕННОГО ОРУДИЯ К ДОСТИЖЕНИЮ ДОЛЖНОСТЕЙ ОДИН В РАСЧЕТЫ НА БЕЗНРАВСТВЕННОСТИ В ПОЭЗИИ РЕЗВИТЬСЯ ВСЕ ГРЫЗЕТ СВОИ БРАЗДЫ ПРАВЛЕНИЯ НАЧАЛА ЕГО ПОШЛОЙ
| е | и | а | в | д | к | з | б | г | ж | всего | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| количество | 236 | 231 | 195 | 111 | 94 | 94 | 46 | 42 | 40 | 30 | 1119 |
| вероятность | 0.211 | 0.206 | 0.174 | 0.099 | 0.084 | 0.084 | 0.041 | 0.038 | 0.036 | 0.027 |
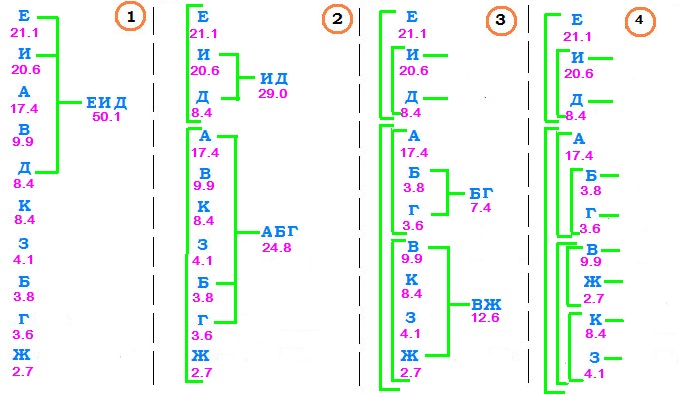
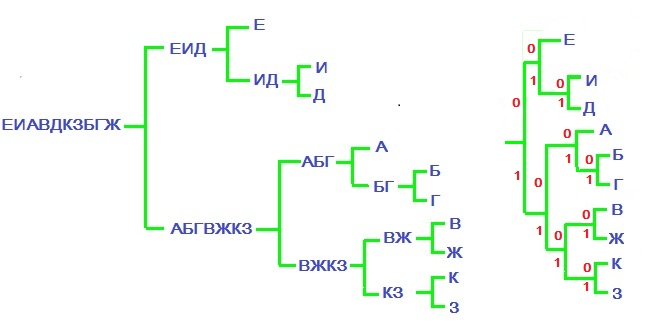
Результатом оказывается кодовая таблица
А теперь перейдем к фундаментальному результату теории кодирования, связав код Шеннона-Фано с понятием энтропии.
Пример. Обратимся к рассмотренному ☞ ЗДЕСЬ примеру сокращенного русского языка
Если же перейти к алфавиту, составленному из биграмм
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11000 | 10001 | 10100 | 010001 | 000 | 01101 | 0010100 | 00100 | 010000 | 11001 | 0101 | 10101 | 1110 | 0111 | 1001 | 01001 | 001011 | 1101 | 0010101 | 10000 |
| _и | _м | _o | _т | ||||||||||||||||
| 1011 | 01100 | 1111 | 0011 |
Ои | то | ми | и_ | о_ | им | и_ | оо | ои | тм | и_ | о_ | о_ | о_ | оо | ии | им | то | ми | им | от | ои | м_ | …
Пропускная способность канала связи
Рассуждения предыдущего пункта относились к случаю, когда процесс коммуникации происходит без искажений. Обратимся теперь от теории к реальности: помехи всегда будут.
Дополнительно вводятся ограничения на допустимые к передаче последовательности — например, запрет двух пробелов подряд между словами. ♦
Пример. Для рассмотренного выше «телеграфного» примера имеем разностное уравнение в виде
При наличии помех в линии связи дело будет обстоять иначе. В этом случае только наличие избыточности в передаваемой последовательности сигналов может помочь нам точно восстановить переданное сообщение по принятым данным. Ясно, что использование кода, приводящего к наименьшей избыточности закодированного сообщения здесь уже нецелесообразно и скорость передачи сообщения должна быть уменьшена. Насколько уменьшена?

Статья не закончена!
Источники
[1]. Шеннон К. Математическая теория связи. (Shannon C.E. A Mathematical Theory of Communication. Bell System Technical Journal. — 1948. — Т. 27. — С. 379-423, 623–656.)
[2]. Яглом А.М., Яглом И.М. Вероятность и информация. М. Наука. 1973.



