Таинственный код нашего генома
Расшифровка генетического код стала важным научным событием двадцатого века. Сейчас перед учеными появляются новые загадки о функционировании нашего генома.
Автор
Редакторы
Последовательность ДНК определяет строение белка с помощью триплетного генетического кода, в котором каждой аминокислоте соответствует три нуклеотида. Случайные мутации приводят к изменению последовательности нуклеотидов, в результате чего появляются новые варианты белков. Именно так до недавнего времени представляли себе ученые эволюцию белков. Но благодаря исследованиям последних лет оказалось, что помимо генетического кода есть и другие «коды», которые диктуют эволюции белков свои правила.
Одним из важных свойств генетического кода является его избыточность — каждая аминокислота, как правило, кодируется не одним, а 2–6 кодонами. Интересно, что при этом частота использования разных кодонов, отвечающих за одну и ту же аминокислоту, различается как в прокариотических, так и в эукариотических геномах [1]. У организмов с коротким жизненным циклом предпочтения одних кодонов другим связывают с необходимостью в увеличении эффективности транскрипции и стабильности мРНК [2], [3]. Однако в случае геномов млекопитающих такое объяснение подходит лишь для небольшого количества случаев, поэтому в последние годы ученые активно занимаются изучением особенностей геномов млекопитающих и причин предпочтительного использования тех или иных кодонов.
Важное значение в частоте использования кодонов играют транскрипционные факторы — к такому выводу пришла группа ученых из Университета Вашингтона под руководством Джона Стаматояннопоулоса (John A. Stamatoyannopoulos). В опубликованной в журнале Science статье обсуждается, как транскрипционные факторы могут управлять эволюцией белков посредством влияния на частоту использования кодонов [4].
Транскрипционные факторы (ТФ) — это белки, регулирующие транскрипцию генов при связывании с ДНК. ТФ могут повышать транскрипцию или снижать ее, влияя, таким образом, на количество мРНК и белка, соответствующих определенному гену. Долгое время считалось, что ТФ связываются только в некодирующей (не содержащей генов) части ДНК. В своем новом исследовании группа Стаматояннопоулоса выяснила, что на самом деле во многих генах человека ТФ связываются с кодирующими последовательностями ДНК (т.е. с теми, которые являются частью генов). Так как эффективность связывания ТФ с ДНК зависит от того, какие именно нуклеотиды находятся в сайте связывания, ТФ могут снижать возможное разнообразие кодонов в местах своей посадки (рис. 1). При этом даже нейтральные с точки зрения белка мутации (те, при которых последовательность аминокислот не меняется благодаря избыточности генетического кода) могут изменять эффективность связывания ТФ с ДНК и становиться материалом для естественного отбора. Получается, что эволюция белков определяется не только хорошо изученным генетическим кодом, но и другим особенным кодом — «кодом связывания ТФ». Ранее были описаны и некоторые другие «регуляторные» коды, которые контролируют организацию хроматина [5], пространственную структуру и сплайсинг мРНК [5], [6], эффективность трансляции [7], ко-трансляционный фолдинг белков [8] (рис. 2). Все они могут влиять на предпочтительное использование тех или иных кодонов.
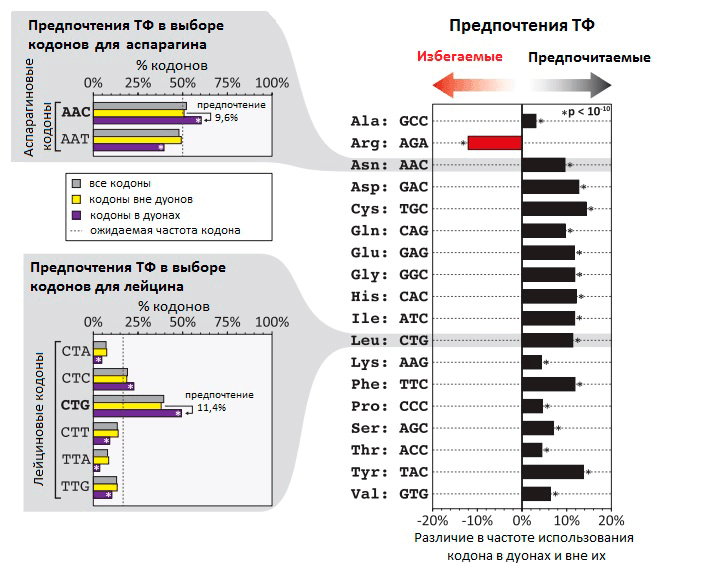
Рисунок 1. Неслучайная частота использования кодов в дуонах в местах связывания ТФ с ДНК. На гистограмме видно, что частота использования некоторых кодонов на 5–15% выше в дуонах, чем вне дуонов. В случае аргинина кодон AGA, напротив, гораздо реже встречается в дуонах, чем в других участках генома. В левой части рисунка — распределение частоты использования разных кодонов на примере кодонов для аспарагина и лейцина.
Насколько в геноме распространено применение дополнительных «регуляторных» кодов, которые перекрывают генетический код, и какое влияние они оказывают на эволюцию белков? Сотрудники лаборатории Стаматояннопоулоса попытались ответить на этот вопрос при исследовании «кода связывания ТФ». Чтобы выявить участки ДНК, связывающиеся с ТФ, они применили метод картирования с помощью дезоксирибонуклеазы I. Этот фермент разрушает одноцепочечные участки ДНК — если только они в этот момент не связаны с ТФ (в таком случае они сохранятся). Ученые исследовали 81 тип человеческих клеток, определив точные нуклеотидные последовательности связанных с ТФ участков генов. Оказалось, что приблизительно 14% кодонов в 86,9% генов человека связаны с различными транскрипционными факторами. В своей статье исследователи предлагают называть эти участки генов «дуонами», т.к. они кодируют два типа информации — информацию о белковой последовательности в виде генетического кода и информацию об экспрессии гена с помощью связывания ТФ. Для нормальной экспрессии гена необходимо связывание ДНК с ТФ, поэтому существуют определенные ограничения на использование различных кодонов, обусловленные строением ДНК-связывающего участка ТФ.
В геноме человека широко распространены однонуклеотидные полиморфизмы (single nucleotide polymorphisms, SNP) — различия последовательности гомологичных генов разных людей на один нуклеотид. Могут ли такие однонуклеотидные различия повлиять на эффективность связывания ТФ с ДНК? Чтобы узнать это, ученые из лаборатории Стаматояннопоулоса нашли на полученной ими карте дуонов почти 600 тыс. известных сайтов SNP, связанных с развитием какого-либо заболевания или проявлением определенного фенотипического признака. Оказалось, что 17,4% сайтов полиморфизма изменяют результаты картирования с помощью дезоксирибонуклеазы I, т.е. они, вероятно, снижают эффективность связывания ТФ с ДНК. Это изменение не зависит от того, является ли данный полиморфизм синонимичным или несинонимичным (т.е. влияет ли замена нуклеотида на замену аминокислоты в белке). Интересно, что значительная часть несинонимичных замен, хотя и приводит к изменению последовательности белка, не приводит к нарушению его функций. В этих случаях изменения нуклеотидной последовательности приводят только к нарушению связывания ТФ с ДНК. Эта находка поддерживает гипотезу о том, что SNP в кодирующей ДНК могут приводить к развитию заболеваний без влияния на функцию белка [9], [10]. Поэтому при изучении роли SNP в различных заболеваниях и при исследовании экзома необходимо учитывать весь спектр «регуляторных кодов», взаимодействующих с последовательностью гена.
«Регуляторные коды» далеко не всегда мирно и гармонично сосуществуют. В генах плодовой мушки Drosophila melanogaster ближе к концу экзонов наблюдается резкое снижение частоты использования оптимальных для трансляции кодонов и повышение частоты использования кодонов, которые облегчают сплайсинг мРНК [11]. Это показывает, что в ходе эволюции потребность в точном сплайсинге была выше, чем потребность в более эффективной трансляции. Также при исследовании дуонов и других ТФ-связывающих участков ДНК оказалось, что среди этих последовательностей нет стоп-кодонов.
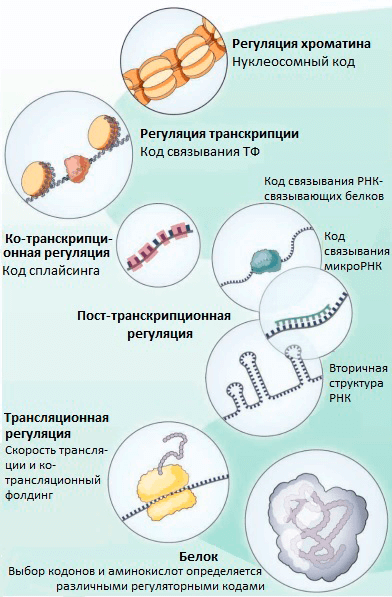
Рисунок 2. «Тайные коды» нашего генома, которые определяют частоту использования кодонов и выбор аминокислот в эволюции белков, независимо от выполнения белком его функций
Что же может обеспечить взаимовыгодное соседство «регуляторных» и генетического кодов? Одним из ключевых ограничений для белок-кодирующих генов является то, что последовательность гена должна обеспечивать нормальный фолдинг кодируемого белка. Мутации, нарушающие правильную укладку, с большой вероятностью будут отсеяны как вредные. Можно предположить, что когда необходимость правильного фолдинга отсутствует (например, в неструктурированных белках [12]), белок-кодирующая последовательность может содержать большее количество регуляторных элементов для различных «регуляторных кодов». Действительно ли это так, помогут узнать дальнейшие исследования.
Несмотря на то, что в работе Стаматояннопоулоса и его коллег было сделано много интересных наблюдений о функционировании «кода связывания ТФ», некоторые вопросы остаются открытыми. Например, авторы статьи отмечают, что ТФ гораздо реже связываются с генами с высокой экспрессией, но не ясно, как ТФ при связывании с белок-кодирующими участками ДНК могут воздействовать на транскрипцию этих генов. Возможно, что связывание ТФ в данном случае вызывает активацию альтернативного промотора или соседнего гена, снижая таким образом экспрессию гена с ТФ-связывающей последовательностью. С другой стороны, этот эффект может быть связан с перестройкой хроматина, которая приводит к снижению экспрессии ряда генов.
Новые исследования помогут ученым лучше понять, как различные «регуляторные коды» взаимодействуют друг с другом и с генетическим кодом. Интересно узнать, всегда ли природа могла найти оптимальное решение при сочетании разных кодов, или иногда возникали противоречия, приводящие к неоптимальным или вредным последствиям. Например, может оказаться, что белок-кодирующие последовательности ДНК, которым «трудно справиться» с обилием и разнообразием регуляторных элементов, активно используются патогенами при инфицировании хозяина. Обнаружение перекрывающихся «регуляторных кодов» в нашем геноме открывает новые перспективы для интерпретации различий и особенностей в последовательностях ДНК и указывает на то, что исследование генетического кода еще не подошло к концу.
Перевод редакционной колонки журнала Science [13].
Раньше жизнь была проще: как появился генетический код
Загадка происхождения жизни — один из самых жгучих вопросов, стоящих перед наукой. Пока ответ не найден, все успехи человечества в решении прикладных медицинских или биологических задач можно сравнить с попытками туземцев, никогда раньше не видевших самолетов, научиться пилотировать свалившийся на них с неба боинг. Тем не менее поиски ответа продолжаются. И хотя число ученых, сражающихся на этом фронте, в десятки раз меньше, чем занятых, к примеру, небольшими усовершенствованиями системы редактирования генов CRISPR, каждое их достижение удостаивается немедленного внимания научной общественности. А тем более если речь идет ни много ни мало о загадке происхождения генетического кода. В статье Чарльза Картера и Питера Уиллса, опубликованной в этом месяце в журнале Nucleic Acid Research, речь как раз об этом.
Два профессора — один из США, другой из Новой Зеландии — проанализировали взаимодействие частей механизма, обеспечивающего включение правильных аминокислот в растущую белковую цепь. Механизм этот настолько хитроумен, что отрицатели эволюционной теории нередко использовали его как пример «неустранимой сложности» — такого элемента живой природы, который якобы никак не мог возникнуть путем постепенных усовершенствований, потому что малейшее упрощение тут же лишает всю эту конструкцию смысла. Задача профессоров Уиллса и Картера в том и состояла, чтобы предложить разумную гипотезу, объясняющую, от каких простых предшественников могла эволюционировать эта изумительно сложная система.
Механизм трансляции — именно так называется эта система — призван переводить информацию, записанную в гене алфавитом из «букв»-нуклеотидов, в последовательность аминокислот — единиц строения белков. Ключевую роль в этом переводе играет тРНК. Эта довольно большая молекула на одном конце имеет три «буквы», узнающие соответствующий им кусочек гена (вернее, считанной с него мРНК). На другой конец молекулы — «акцепторный стебель» — в нужный момент навешивается соответствующая аминокислота. Аминокислот, как известно, существует двадцать, тРНК еще больше, и для каждой пары тРНК и аминокислоты есть своя «машинка», которая их соединяет, под названием «аминоацил-тРНК-синтетаза» (ААРС).
Все эти «машинки» различаются в деталях, но несколько десятилетий назад биологи заметили, что некоторые из них чуть больше похожи друг на друга. А именно, 20 ААРС распадаются на два класса, по десять «машинок» в каждом, причем эти классы устроены принципиально по-разному. Ранее Картер и Уиллс нашли убедительные доказательства, что каждый класс произошел от одного белка-предка. Классы ААРС различаются еще и тем, какие аминокислоты они предпочитают: первому классу обычно нравятся более крупные аминокислоты, второму — небольшие и электрически нейтральные.
Если два разных класса «машинок»-белков распознают два разных класса аминокислот, то довольно естественно предположить, что и тРНК должны разделяться на два класса, восходящие каждый к своему предку. Именно это и продемонстрировали Уиллс и Картер в своей статье.
Авторы сравнивают свою находку с палимпсестом, на котором реставраторам удалось восстановить под наслоениями содержание самой первой записи.
Оказалось, что всего три нуклеотида на «акцепторном стебле» хранят информацию о том, к какому классу относится та или иная тРНК. Этот недостающий фрагмент пазла и искали Картер и Уиллс, чтобы подтвердить свою гипотезу. Она состоит в том, что в самом начале развития жизни существовало всего два типа тРНК, обслуживаемые всего двумя типами машинок ААРС. Такая система была не слишком разборчивой и могла лишь определить, включать ли в белковую цепь аминокислоту покрупнее или обойтись маленькой. Возможно, что и выбор аминокислот в те времена был более скуден, чем сегодня, и даже не исключено, что их было в наличии всего две (а если их было больше, то точный выбор, вероятно, не имел большого значения для работы тех примитивных белков-катализаторов). Согласно гипотезе Картера и Уилса, именно из такой несложной системы развился сложнейший аппарат белкового синтеза, украшающий сегодня все формы жизни, от бактерий до человека.
Приятным сюрпризом для исследователей стало еще одно наблюдение, отвечающее на вопрос, мучающий молекулярных биологов уже три десятилетия. Как ужу было сказано, тРНК — довольно большая молекула, и если «машинка» ААРС возится в основном в районе «акцепторного стебля», то распознавание информации, записанной в гене, происходит довольно далеко оттуда (эта часть молекулы называется «антикодоном»). Чтобы объяснить, как такая конструкция могла возникнуть в эволюции, ученым приходилось предполагать, что миллиарды лет назад, когда элементы жизни только начинали оформляться, тРНК были гораздо меньше. При таких условиях ААРС могли бы узнавать тот же самый участок тРНК, что отвечал за ее специфичность, то есть содержал «кодовое слово», соответствующее информации в гене.
Ни малейших доказательств этой гипотезы найти не удавалось. Однако из анализа, проведенного Картером и Уиллсом, следует, что одна из трех обнаруженных ими «букв», определяющих разделение тРНК на два класса (а именно, нуклеотид номер два), как раз и есть остаток того самого древнего антикодона. В ходе дальнейшей эволюции эта функция переместилась на новое место, однако следы старого местоположения удается обнаружить. Авторы сравнивают свою находку с палимпсестом — древним пергаментом, на котором старый текст был заменен на новый, однако реставраторам удалось восстановить под наслоениями содержание той самой первой записи.
При всей серьезности результатов Уиллса и Картера они не ставят точку в истории происхождения генетического кода. Тем не менее круг возможных гипотез удалось сильно сузить. Чтобы доказать правильность гипотезы, исследователи могли бы попробовать воспроизвести архаичную систему трансляции в лаборатории. Потом, возможно, они позволили бы ей эволюционировать и с изумлением наблюдали бы, как на их глазах из этой примитивной химии вырастает «неустранимая сложность» современных живых систем. То, что возможности молекулярной биологии пока не позволяют проделать этот опыт, не означает, что он не будет поставлен никогда: человеческим возможностям свойственно расширяться.
Генетический код
Три пары оснований молекулы ДНК кодируют одну аминокислоту в белке.
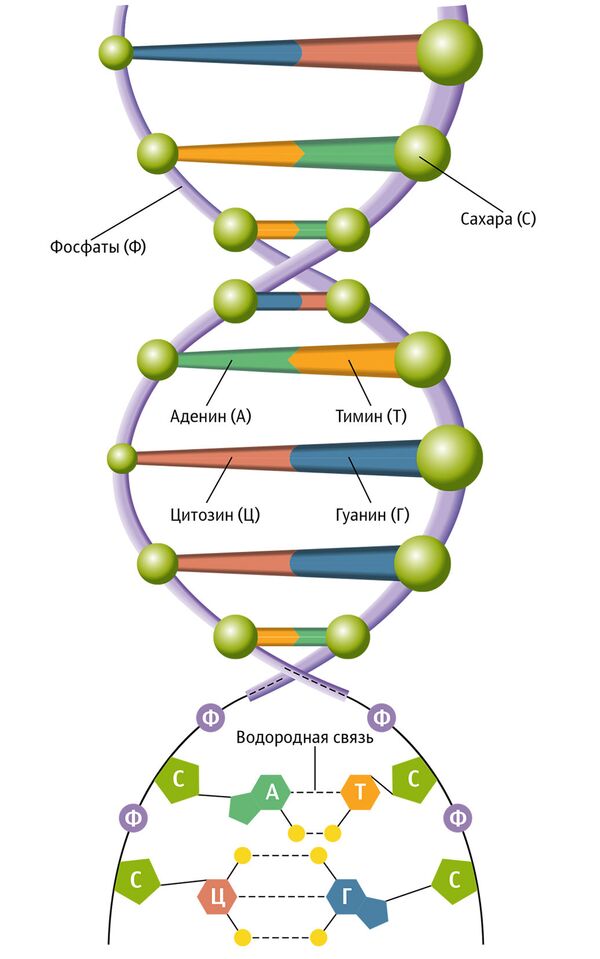
Сегодня ни для кого не секрет, что программа жизнедеятельности всех живых организмов записана на молекуле ДНК. Проще всего представить молекулу ДНК в виде длинной лестницы. Вертикальные стойки этой лестницы состоят из молекул сахара, кислорода и фосфора. Вся важная рабочая информация в молекуле записана на перекладинах лестницы — они состоят из двух молекул, каждая из которых крепится к одной из вертикальных стоек. Эти молекулы — азотистые основания — называются аденин, гуанин, тимин и цитозин, но обычно их обозначают просто буквами А, Г, Т и Ц. Форма этих молекул позволяет им образовывать связи — законченные ступеньки — лишь определенного типа. Это связи между основаниями А и Т и между основаниями Г и Ц (образованную таким образом пару называют «парой оснований»). Других типов связи в молекуле ДНК быть не может.
Спускаясь по ступенькам вдоль одной цепи молекулы ДНК, вы получите последовательность оснований. Именно это сообщение в виде последовательности оснований и определяет поток химических реакций в клетке и, следовательно, особенности организма, обладающего данной ДНК. Согласно центральной догме молекулярной биологии, на молекуле ДНК закодирована информация о белках, которые, в свою очередь, выступая в роли ферментов (см. Катализаторы и ферменты), регулируют все химические реакции в живых организмах.
Строгое соответствие между последовательностью пар оснований в молекуле ДНК и последовательностью аминокислот, составляющих белковые ферменты, называется генетическим кодом. Генетический код был расшифрован вскоре после открытия двуспиральной структуры ДНК. Было известно, что недавно открытая молекула информационной, или матричной РНК (иРНК, или мРНК), несет информацию, записанную на ДНК. Биохимики Маршалл Уоррен Ниренберг (Marshall W. Nirenberg) и Дж. Генрих Маттеи (J. Heinrich Matthaei) из Национального института здравоохранения в городке Бетезда под Вашингтоном, округ Колумбия, поставили первые эксперименты, которые привели к разгадке генетического кода.
Они начали с того, что синтезировали искусственные молекулы иРНК, состоявшие только из повторяющегося азотистого основания урацила (который является аналогом тимина, «Т», и образует связи только с аденином, «А», из молекулы ДНК). Они добавляли эти иРНК в тестовые пробирки со смесью аминокислот, причем в каждой пробирке лишь одна из аминокислот была помечена радиоактивной меткой. Исследователи обнаружили, что искусственно синтезированная ими иРНК инициировала образование белка лишь в одной пробирке, где находилась меченая аминокислота фенилаланин. Так они установили, что последовательность «—У—У—У—» на молекуле иРНК (и, следовательно, эквивалентную ей последовательность «—А—А—А—» на молекуле ДНК) кодирует белок, состоящий только из аминокислоты фенилаланина. Это было первым шагом к расшифровке генетического кода.
Сегодня известно, что три пары оснований молекулы ДНК (такой триплет получил название кодон) кодируют одну аминокислоту в белке. Выполняя эксперименты, аналогичные описанному выше, генетики в конце концов расшифровали весь генетический код, в котором каждому из 64 возможных кодонов соответствует определенная аминокислота.
Код ДНК. Какие тайны скрывает главная молекула

МОСКВА, 25 апр — РИА Новости, Татьяна Пичугина. Ровно 65 лет назад британские ученые Джеймс Уотсон и Фрэнсис Крик опубликовали статью о расшифровке структуры ДНК, заложив основы новой науки — молекулярной биологии. Это открытие изменило очень многое в жизни человечества. РИА Новости рассказывает о свойствах молекулы ДНК и о том, почему она так важна.

Во второй половине XIX века биология была совсем молодой наукой. Ученые только приступали к исследованию клетки, а представления о наследственности, хотя и были уже сформулированы Грегором Менделем, не получили широкого признания.
Весной 1868 года молодой швейцарский врач Фридрих Мишер приехал в Университет города Тюбингена (Германия), чтобы заняться научной работой. Он намеревался узнать, из каких веществ состоит клетка. Для экспериментов выбрал лейкоциты, которые легко получить из гноя.
Отделяя ядро от протоплазмы, белков и жиров, Мишер обнаружил соединение с большим содержанием фосфора. Он назвал эту молекулу нуклеином («нуклеус» на латыни — ядро).
Это соединение проявляло кислотные свойства, поэтому возник термин «нуклеиновая кислота». Его приставка «дезоксирибо» означает, что молекула содержит H-группы и сахара. Потом выяснилось, что на самом деле это соль, но название менять не стали.
В начале XX века ученые уже знали, что нуклеин представляет собой полимер (то есть очень длинную гибкую молекулу из повторяющихся звеньев), звенья сложены четырьмя азотистыми основаниями (аденином, тимином, гуанином и цитозином), а нуклеин содержится в хромосомах — компактных структурах, которые возникают в делящихся клетках. Их способность передавать наследственные признаки продемонстрировал американский генетик Томас Морган в опытах на дрозофилах.
Модель, объяснившая гены
А вот что делает в ядре клетки дезоксирибонуклеиновая кислота, сокращенно ДНК, долго не понимали. Считалось, что она играет какую-то структурную роль в хромосомах. Единицам наследственности — генам — приписывали белковую природу. Прорыв совершил американский исследователь Освальд Эвери, опытным путем доказавший, что генетический материал передается от бактерии к бактерии посредством ДНК.

Стало ясно, что ДНК нужно изучать. Но как? В то время ученым был доступен только рентген. Чтобы просвечивать им биологические молекулы, их приходилось кристаллизовать, а это сложно. Расшифровкой структуры белковых молекул по рентгенограммам занимались в Кавендишской лаборатории (Кембридж, Великобритания). Работавшие там молодые исследователи Джеймс Уотсон и Френсис Крик не располагали собственными экспериментальными данными по ДНК, поэтому они воспользовались рентгенограммами коллег из Королевского колледжа Мориса Уилкинса и Розалинды Франклин.
Уотсон и Крик предложили модель структуры ДНК, точно соответствующую рентгенограммам: две параллельные цепочки закручены в правую спираль. Каждая цепочка складывается произвольным набором азотистых оснований, нанизанных на остов их сахаров и фосфатов, и удерживается водородными связями, протянутыми между основаниями. Причем аденин соединяется только с тимином, а гуанин — с цитозином. Это правило называют принципом комплементарности.
Модель Уотсона и Крика объясняла четыре главных функции ДНК: репликацию генетического материала, его специфику, хранение информации в молекуле и ее способность мутировать.
Ученые опубликовали свое открытие в журнале Nature 25 апреля 1953 года. Через десять лет им вместе с Морисом Уилкинсом присудили Нобелевскую премию по биологии (Розалинда Франклин скончалась в 1958 году от рака в возрасте 37 лет).
«Теперь, более полувека спустя, можно констатировать, что открытие структуры ДНК сыграло в развитии биологии такую же роль, как в физике — открытие атомного ядра. Выяснение строения атома привело к рождению новой, квантовой физики, а открытие строения ДНК привело к рождению новой, молекулярной биологии», — пишет Максим Франк-Каменецкий, выдающийся генетик, исследователь ДНК, автор книги «Самая главная молекула».

Генетический код
Теперь оставалось узнать, как эта молекула действует. Было известно, что ДНК содержит инструкции для синтеза клеточных белков, которые выполняют всю работу в клетке. Белки — это полимеры, состоящие из повторяющихся наборов (последовательностей) аминокислот. Причем аминокислот — всего двадцать. Виды животных отличаются друг от друга набором белков в клетках, то есть разными последовательностями аминокислот. Генетика утверждала, что эти последовательности задаются генами, которые, как тогда считали, служат первокирпичиками жизни. Но что такое гены, никто в точности не представлял.
Ясность внес автор теории Большого взрыва физик Георгий Гамов, сотрудник Университета Джорджа Вашингтона (США). Основываясь на модели двухцепочечной спирали ДНК Уотсона и Крика, он предположил, что ген — это участок ДНК, то есть некая последовательность звеньев — нуклеотидов. Поскольку каждый нуклеотид — это одно из четырех азотистых оснований, то нужно просто выяснить, как четыре элемента кодируют двадцать. В этом состояла идея генетического кода.
К началу 1960-х установили, что белки синтезируются из аминокислот в рибосомах — своего рода «фабриках» внутри клетки. Чтобы приступить к синтезу белка, к ДНК приближается фермент, распознает определенный участок в начале гена, синтезирует копию гена в виде маленькой РНК (ее называют матричной), затем уже в рибосоме из аминокислот выращивается белок.
Выяснили также, что генетический код — трехбуквенный. Это значит, что одной аминокислоте соответствуют три нуклеотида. Единицу кода назвали кодоном. В рибосоме информация с мРНК считывается кодон за кодоном, последовательно. И каждому из них соответствует несколько аминокислот. Как же выглядит шифр?

На этот вопрос ответили Маршалл Ниренберг и Генрих Маттеи из США. В 1961 году они впервые доложили свои результаты на биохимическом конгрессе в Москве. К 1967-му генетический код полностью расшифровали. Он оказался универсальным для всех клеток всех организмов, что имело далеко идущие последствия для науки.
Открытие структуры ДНК и генетического кода полностью переориентировало биологические исследования. То, что у каждого индивида уникальная последовательность ДНК, кардинально изменило криминалистику. Расшифровка генома человека дала антропологам совершенно новый метод изучения эволюции нашего вида. Недавно изобретенный редактор ДНК CRISPR-Cas позволил сильно продвинуть вперед генную инженерию. По всей видимости, в этой молекуле хранится решение и самых злободневных проблем человечества: рака, генетических заболеваний, старения.



