Увеличиваем скорость работы Python до уровня C++ с Numba
Увеличиваем скорость работы Python до уровня C++ с Numba
В этой статье автор разобрался, как увеличить скорость работы Python, и продемонстрировал реализацию на реальном примере.
Прим. ред. Это перевод. Мнение редакции может не совпадать с мнением автора оригинала.
Тест базовой скорости
Для сравнения базовой скорости Python и C++ я буду использовать алгоритм генерации случайных простых чисел.
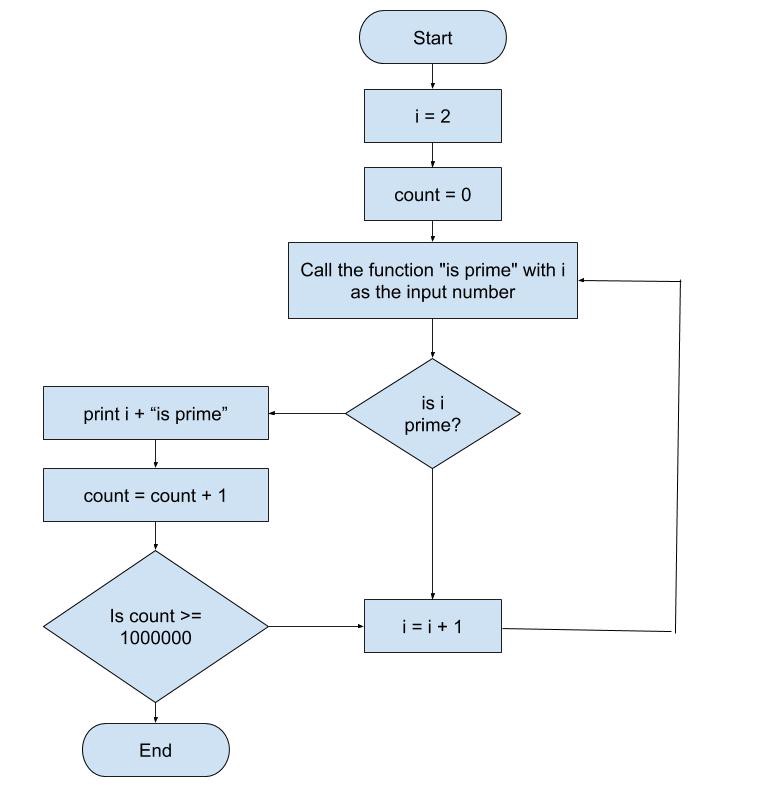
Блок-схема алгоритма генерации простых чисел
Реализация на Python
Реализация на C++
Результат
Комментарий
Как и ожидалось, программа на C++ выполняется в 25 раз быстрее, чем на Python. Ожидания подтвердились, потому что:
Благодаря тому, что Python это гибкий универсальный язык, наш результат можно улучшить. Один из лучших способов увеличить скорость Python — Numba.
Numba
Numba — это Open Source JIT-компилятор, который переводит код на Python и NumPy в быстрый машинный код.
Чтобы начать использовать Numba, просто установите её через консоль:
Реализация на Python с использованием Numba
Как вы могли заметить, в коде добавились декораторы njit:
Итоговая скорость Python
Теперь вы знаете что Python способен обогнать C++. О других способах увеличения скорости работы Python читайте в статье про пять проектов, которые помогают ускорить код на Python.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Три простых способа улучшить производительность кода Python
1. Бенчмарк, бенчмарк и еще раз бенчмарк
Тестирование производительности программы кажется утомительным процессом. Но если у вас уже есть рабочий код Python, разделенный на функции, то задачу можно свести к простому добавлению декоратора к функции, требующей профилирования.
Прежде всего установим line_profiler, позволяющий измерить затраты времени на каждую строчку кода в функции:
Во время исполнения программы функция sum_of_lists при вызове будет профилирована. Обратите внимание на декоратор @profile над определением функции.
Чтобы запустить бенчмарк, введите:

В пятой колонке видим, какой процент времени исполнения ушел на каждую строчку. Это поможет вам определить, какие участки кода нуждаются в оптимизации больше всего.
Имейте в виду, что эта библиотека для измерения сама потребляет значительные ресурсы во время использования. Но она замечательно подходит для выявления слабых мест в программе с последующей заменой их на что-нибудь более эффективное.
Чтобы запустить line_profiler из Jupyter Notebook, попробуйте магическую команду %%lprun .
2. По возможности избегайте циклов
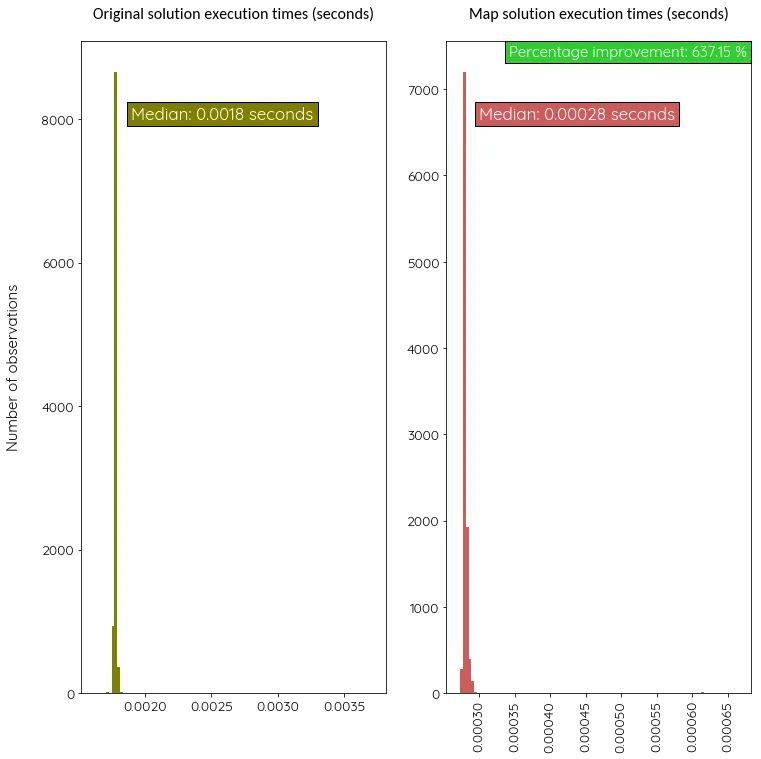
Посмотрим, насколько резво работает новая версия с картой по сравнению с изначальной. Измерим их скорость 1000 раз.
Версия с map более чем в 6 раз быстрее!
3. Компилируйте ваши модули Python с помощью Cython
Если совсем нет желания редактировать проект, но хочется хоть какого-нибудь улучшения производительности без лишних усилий, ваш лучший друг – Cython.
Для этого потребуется установить на машине как собственно Cython, так и компилятор С:
Если вы работаете на Debian системе, загрузите GCC следующим образом:
Давайте разделим изначальный код примера на два файла с названиями test_cython.py и test_module.pyx :
Наш главный файл должен импортировать эту функцию с файла test_module.pyx :
Теперь напишем скрипт setup.py для компиляции нашего модуля при помощи Cython:
Наконец пришло время скомпилировать наш модуль:
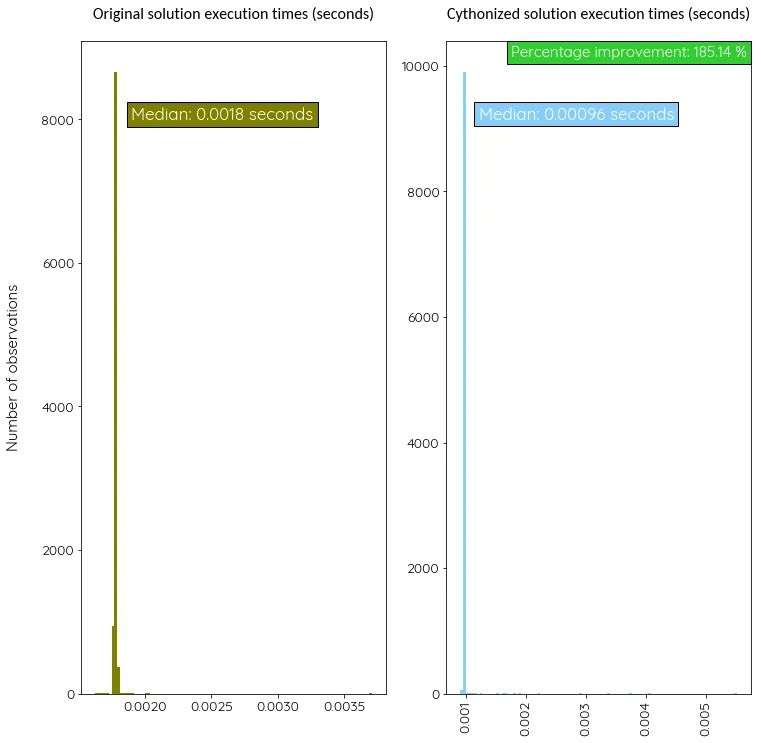
Теперь сравним эффективность этой версии с оригинальной, произведя, снова-таки, тысячу измерений.
В этом случае Cython улучшил производительность нашей программы почти вдвое по сравнению с первым вариантом. Но этот показатель будет меняться в зависимости от того, какого рода код вы пытаетесь оптимизировать.
Итоги
Ускорение Python-скриптов без приложения умственных усилий
Одно из распространенных применений Python — небольшие скрипты для обработки данных (например, каких-нибудь логов). Мне часто приходилось заниматься такими задачами, скрипты обычно были написаны наспех. Вкупе с моим слабым знанием алгоритмов это приводило к тому, что код получался далеко не оптимальным. Это меня ничуть ни расстраивало: лишняя минута выполнения не сделает погоды.
Ситуация немного изменилась, когда объем данных для обработки вырос. И после того, как время выполнения очередного скрипта перевалило за сутки, я решил уделить немного времени оптимизации — все-таки хотелось бы получить результат до того, как он потеряет актуальность. В рамках этой статьи я не планирую говорить о профилировании, а затрону тему компиляции Python-кода. При этом обозначу условие: варианты оптимизации не должны быть требовательными к времени разработчика, а, напротив, быть дружественными к «пыщ-пыщ и в продакшен».
Поскольку я с самого начала выставил себе требование, что способ ускорения должен быть простым, остаются только варианты, для реализации которых достаточно по диагонали пролистать мануалы. Поэтому я бегло погуглил что-то вроде ‘jit python’, ‘compiler python’ и выбрал для бенчмарка:
К сожалению, запустить numba мне не удалось — скрипты падали с исключениями типа NotImplementedError: cell vars are not supported. Кажется, как универсальное средство ускорения всего подряд numba пока не подойдет.
Бенчмарк проводился на Macbook Pro Late 2013 (2.4 GHz Intel Core i5). Для запуска был написан небольшой fabric-скрипт, так что желающие могут легко повторить в интересующих их условиях. Итак, результат: 
Как видно, прирост производительности меняется от скрипта к скрипту (что неудивительно). Тем не менее можно отметить безоговорочную победу pypy в обеих номинациях, некоторое ускорение от Cython и бессмысленности использование nuitka для этих целей (что не отменяет возможности использования, если, например, просто нужно собрать воедино все зависимости). Также интересно, что для агрегации python 3 оказался быстрее cythonized-версии такого же скрипта. Я для себя решил, что в разных случаях резонно использовать и pypy, и Cython: например, если в скрипте вовсю используются numpy/scipy/pandas etc., то с pypy могут возникнуть сложности (не весь этот стек работает из коробки с pypy), а вот транслировать одну тяжелую функцию в Cython будет довольно легко.
Исходники теста лежат на Github, улучшения и дополнения приветствуются.
Как оптимизировать код на Python

Как я сократил время выполнения приложения на 1/10
Данные советы просты в реализации и могут пригодиться вам в обозримом будущем.
Считается, что первоочередной задачей программиста является написание чистого и эффективного кода. Как только вы создали чистый код, можете переходить к следующим 10 подсказкам. Я подробно объясню их ниже.
Как я измеряю время и сложность кода?
Используйте структуры данных из хеш-таблиц
Если есть такая возможность, то вместо перебора данных коллекций пользуйтесь поиском.
Векторизация вместо циклов
Присмотритесь к Python-библиотекам, созданным на С (Numpy, Scipy и Pandas), и оцените преимущества векторизации. Вместо прописывания цикла, который раз за разом обрабатывает по одному элементу массива М, можно выполнять обработку элементов одновременно. Векторизация часто включает в себя оптимизированную стратегию группировки.
Сократите количество строк в коде
Пользуйтесь встроенными функциями Python. Например, map()
Каждое обновление строковой переменной создает новый экземпляр
Пример выше уменьшает объем памяти.
Для сокращения строк пользуйтесь циклами и генераторами for
Пользуйтесь многопроцессорной обработкой
Если ваш компьютер выполняет более одного процесса, тогда присмотритесь к многопроцессорной обработке в Python.
Она разрешает распараллеливание в коде. Многопроцессорная обработка весьма затратна, поскольку вам придется инициировать новые процессы, обращаться к общей памяти и т.д., поэтому пользуйтесь ей только для большого количества разделяемых данных. Для небольших объемов данных многопроцессорная обработка не всегда оправдана.
Многопроцессорная обработка очень важна для меня, поскольку я обрабатываю по несколько путей выполнения одновременно.
Пользуйтесь Cython
Cython — это статический компилятор, который будет оптимизировать код за вас.
Загрузите расширения Cythonmagic и пользуйтесь тегом Cython для компиляции кода через Cython.
Воспользуйтесь Pip для установки Cython:
Для работы с Cython:
Пользуйтесь Excel только при необходимости
Не так давно мне нужно было реализовать одно приложение. И мне бы пришлось потратить много времени на загрузку и сохранение файлов из/в Excel. Вместо этого я пошел другим путем: создал несколько CSV-файлов и сгруппировал их в отдельной папке.
Примечание: все зависит от задачи. Если создание файлов в Excel сильно тормозит работу, то можно ограничиться несколькими CSV-файлами и утилитой на нативном языке, которая объединит эти CSV в один Excel-файл.
Пользуйтесь Numba
Это — JIT-компилятор (компилятор «на лету»). С помощью декоратора Numba компилирует аннотированный Python- и NumPy-код в LLVM.
Разделите функцию на две части:
1. Функция, которая выполняет вычисления. Ее декорируйте с @autojit.
2. Функция, которая выполняет операции ввода-вывода.
Пользуйтесь Dask для распараллеливания операций Pandas DataFrame
Dask очень классный! Он помог мне с параллельной обработкой множества функций в DataFrame и NumPy. Я даже попытался масштабировать их в кластере, и все оказалось предельно просто!
Пользуйтесь пакетом swifter
Swifter использует Dask в фоновом режиме. Он автоматически рассчитывает наиболее эффективный способ для распараллеливания функции в пакете данных.
Это плагин для Pandas.
Пользуйтесь пакетом Pandarallel
Pandarallel может распараллеливать операции на несколько процессов.
Опять же, подходит только для больших наборов данных.
Общие советы
Как только вы добились чистого кода, можно приступать к рекомендациям, описанным выше.

Заключение
В данной статье были даны краткие подсказки по написанию кода. Они будут весьма полезны для тех, кто хочет улучшить производительность Python-кода.
Как оптимизировать код на Python
Как я сократил время выполнения приложения на 1/10

Jul 20, 2019 · 4 min read

Данные советы просты в реализации и могут пригодиться вам в обозримом будущем.
Считается, что первоочередной задачей программиста является написание чистого и эффективного кода. Как только вы создали чистый код, можете переходить к следующим 10 подсказкам. Я подробно объясню их ниже.
Как я измеряю время и сложность кода?
Используйте структуры данных из хеш-таблиц
Если есть такая возможность, то вместо перебора данных коллекций пользуйтесь поиском.
Векторизация вместо циклов
Присмотритесь к Python-библиотекам, созданным на С (Numpy, Scipy и Pandas), и оцените преимущества векторизации. Вместо прописывания цикла, который раз за разом обрабатывает по одному элементу массива М, можно выполнять обработку элементов одновременно. Векторизация часто включает в себя оптимизированную стратегию группировки.
Сократите количество строк в коде
Пользуйтесь встроенными функциями Python. Например, map()
Каждое обновление строковой переменной создает новый экземпляр
Пример выше уменьшает объем памяти.
Для сокращения строк пользуйтесь циклами и генераторами for
Пользуйтесь многопроцессорной обработкой
Если ваш компьютер выполняет более одного процесса, тогда присмотритесь к многопроцессорной обработке в Python.
Она разрешает распараллеливание в коде. Многопроцессорная обработка весьма затратна, поскольку вам придется инициировать новые процессы, обращаться к общей памяти и т.д., поэтому пользуйтесь ей только для большого количества разделяемых данных. Для небольших объемов данных многопроцессорная обработка не всегда оправдана.
Многопроцессорная обработка очень важна для меня, поскольку я обрабатываю по несколько путей выполнения одновременно.
Пользуйтесь Cython
Cython — это статический компилятор, который будет оптимизировать код за вас.
Загрузите расширения Cythonmagic и пользуйтесь тегом Cython для компиляции кода через Cython.
Воспользуйтесь Pip для установки Cython:
Для работы с Cython:
Пользуйтесь Excel только при необходимости
Не так давно мне нужно было реализовать одно приложение. И мне бы пришлось потратить много времени на загрузку и сохранение файлов из/в Excel. Вместо этого я пошел другим путем: создал несколько CSV-файлов и сгруппировал их в отдельной папке.
Примечание: все зависит от задачи. Если создание файлов в Excel сильно тормозит работу, то можно ограничиться несколькими CSV-файлами и утилитой на нативном языке, которая объединит эти CSV в один Excel-файл.
Пользуйтесь Numba
Это — JIT-компилятор (компилятор «на лету»). С помощью декоратора Numba компилирует аннотированный Python- и NumPy-код в LLVM.
Разделите функцию на две части:
1. Функция, которая выполняет вычисления. Ее декорируйте с @autojit.
2. Функция, которая выполняет операции ввода-вывода.
Пользуйтесь Dask для распараллеливания операций Pandas DataFrame
Dask очень классный! Он помог мне с параллельной обработкой множества функций в DataFrame и NumPy. Я даже попытался масштабировать их в кластере, и все оказалось предельно просто!
Пользуйтесь пакетом swifter
Swifter использует Dask в фоновом режиме. Он автоматически рассчитывает наиболее эффективный способ для распараллеливания функции в пакете данных.
Это плагин для Pandas.
Пользуйтесь пакетом Pandarallel
Pandarallel может распараллеливать операции на несколько процессов.
Опять же, подходит только для больших наборов данных.
Общие советы
Как только вы добились чистого кода, можно приступать к рекомендациям, описанным выше.

Заключение
В данной статье были даны краткие подсказки по написанию кода. Они будут весьма полезны для тех, кто хочет улучшить производительность Python-кода.