Регистр команд
Текущая команда находится в специально для нее отведенном регистре команд. В процессе работы с текущей командой увеличивается значение так называемого счётчика команд, который теперь указывает на следующую команду (если, конечно, не было команды перехода или останова).
Часто команду представляют как структуру, состоящую из записи операции (которую требуется выполнить) и адресов ячеек исходных данных и результата. По адресам указанным в команде берутся данные и помещаются в обычные регистры (в смысле не в регистр команды), получившийся результат тоже сначала оказывается в регистре, а уж потом перемещается по своему адресу, указанному в команде.
Связанные понятия
Сопрограммы (англ. coroutines) — методика связи программных модулей друг с другом по принципу кооперативной многозадачности: модуль приостанавливается в определённой точке, сохраняя полное состояние (включая стек вызовов и счётчик команд), и передаёт управление другому. Тот, в свою очередь, выполняет задачу и передаёт управление обратно, сохраняя свои стек и счётчик.
ПИН (англ. Personal Identification Number — персональный идентификационный номер) — аналог пароля. В ходе авторизации операции используется одновременно как пароль доступа держателя карты к терминалу (банкомату) и как секретный ключ для цифровой подписи запроса. ПИН предусматривается для кредитных и подобных карт (например, сим-карт); с его помощью производится авторизация держателя карты. ПИН должен знать только держатель карты. Обычно предусмотрено ограничение попыток правильного ввода (в основном.
Хранение кода в бд или собираем код по кирпичикам
Данная статья написана Napolsky. По известным причина он не смог ее опубликовать. Если статья вам понравилась — поощрите автора известным способом.
Как все начиналось
Для того чтобы понять, а «зачем оно собственно надо» быстренько пройдем тот путь, который и привел меня к хранению кода в бд. Так сложилось, что свой путь в веб программировании я начинал не с написания каких-либо скриптов или модулей для существующих систем, а сразу с написания собственного движка сайта с абсолютного нуля. К этому моменту я имел двухлетний опыт программирования на C++ и, конечно же, по накатанной пытался строить свой веб движок на ООП (правда в то время в PHP от ООП было одно название 🙂 ). В пределах разумного, я очень люблю свои «велосипеды». Особенно большие. И прежде чем воспользоваться готовым решением, всегда задаюсь вопросом «а нельзя ли написать получше?».
Вообще написание своих велосипедов очень полезно, особенно для начинающих разработчиков (когда на первом месте стоит поднятие профессионализма, а не написание кода в отведенный срок и бюджет). Только написание собственных решений дает понимание того, как что-то устроено изнутри на самом низком уровне. А это в свою очередь дает понимание сложности, ресурсоемкости, скорости тех или иных подходов, что, в конечном счете, выливается в выбор правильного инструментария для решения задачи. Например, в университете нас заставляли писать свои pushback’и для массивов, чтобы мы не забывали, что за казалось бы простыми и тривиальными вещами может скрываться что-то гораздо большее.
В итоге получился движок, построенной по довольно таки классической схеме: папки с классами, модулями, шаблонами и прочим. Ну и соответственно бесконечные инклуды всего этого при генерации страниц. А так как во мне, как и во многих программистах живет рационализатор, то меня стали беспокоить издержки такого подхода. В частности, больше всего мне не нравился тот факт, что приходилось подключать много «ненужного» кода («мертвого» кода, который заведомо не будет выполнен на странице) для страниц (например всю библиотеку, когда на данной странице нужна будет лишь одна функция из нее).
Не задумывались ли вы над количеством «мертвого» кода на странице? На самом деле его количество как правило в 7-15 раз превышает количество кода, который действительно будет выполнен при обращении к странице. Возьмите к примеру класс комментариев. В нем будут методы render(), delete(), edit(), add(), compress(), answer() и т д. При этом за 1 выполнение скрипта как правило будет вызван всего 1 из этих методов (delete — при удалении, edit — при редактировании и т д), а остальные заведомо не будут вызываться. Вот и считайте, сколько такого лишнего кода набежит на странице.
По началу я пытался проводить оптимизацию, «разрезая» и «склеивая» большие библиотеки или классы под нужды различных страниц, уменьшая таким образом количество инклудов и «мертвого» кода. Но это, конечно же, тупиковый путь. Шло время. Проекты, написанные на этом движке (царство им небесное 🙂 ) становились все больше. Вместе с этим росло количество и размеры подключаемого кода, а вместе с ними и время генерации страниц. Я начал все чаще думать о том, как избавиться от «мертвого» кода. И тут меня посетила смелая, показавшайся даже бредовой мысль. А что если…
Рождение идеи
А что если разделить код на максимально мелкие независимые части, чтобы иметь возможность собирать на странице только то, что действительно нужно? То есть разделить все функции, классы (в идеале и методы классов) и прочее. Таким образом, мы получим много много маленьких «кирпичиков», из которых потом будем складывать страницу. Тем самым появится возможность полностью избавиться от «мертвого» кода и инклудов. Меня по-настоящему взбудоражила эта идея, но вопросов было больше чем, ответов: как это сделать, будет ли это работать, какие подводные камни ожидают в реализации, насколько быстра такая система? Короче пока я не имел ни малейшего представления о том, как это реализовать и как оно будет работать. Но попробовать, конечно же, стоило.
Путь воина
Идеология заключается в том, что разбив всё на максимально малые кусочки кода, мы сможем собрать из них что угодно.Вопроса о том, как хранить «кирпичики» кода не возникало — так как они уже были не кодом, а являлись по сути данными с набором атрибутов, то единственным возможным вариантом было использование бд. Постараюсь показать принцип работы подобной системы максимально просто и абстрактно, только передав суть.
1 Хранение кирпичиков
Тут все просто и понятно: каждая отдельная функция, класс (а лучше даже метод класса), контроллер модуля, представление модуля и т д — это отдельная строка в бд. Например в простейшем случае таблица может иметь вид id|code|name|componentType (где componentType — тип кирпичика(функция, класс, модуль..))
2 Хранение зависимостей
Так как код одного кирпичика может вызывать другой кирпичик (например зависимости типа функция-функция, модуль-функция или даже страница-модуль), то нужно хранить репликации. Сделать это можно с помощью таблицы репликаций, которая, в простейшем случае, имеет вид id|parentId|childId. Таким образом мы решаем проблему правильного сбора «кирпичиков» для вложенных конструкций:
В этом случае в таблице репликаций будет запись, что А «нуждается» в B. Следовательно при подключении А автоматом будет подключена B.
3 генерация кода страниц
Хорошо, у нас есть все кирпичики, но как из них собрать код страницы? Для этого, конечно же, нужен отдельный скрипт, который будет собирать из наших бесполезных самих по себе «кирпичиков» работоспособный код страницы. Назовем этот скрипт Codegen. Каким он будет зависит от того, что и как вы хотите собрать из своих «кирпичиков». В этом заключается одна из сильных сторон подхода: из одних и тех же кирпичиков вы можете собирать принципиально разные коды страниц. Можете даже собрать «классическую» архитектуру. Во избежание недопониманий: генерация кода страницы годегеном происходит 1 раз, а не при каждом обращении к странице.
На выходе получаем монолитный сгенерированный код для каждой страницы. При этом, в зависимости от Codegen, возможно как сразу получать весь необходимый код для страницы, так и подгружать некоторые части во время выполнения страницы (посредством eval из базы).
Пожинаем плоды
Таким образом мы можем достичь следущих главных результатов:
— полное отсутствие инклудов на странице
— сведение «мертвого» кода к нулю
600%. Напоминаю, что это без кеша в классике. с кешом цифра будет поменьше)
За и против
Рассмотрим подробно плюсы и минусы идеологии хранения кода в бд.
Минусы
—Невозможность полноценно использовать IDE.Как следствие.Так как код хранится в бд, то для его редактирование/написание должен быть свой интерфейс(я например использую веб интерфейс). Как это примерно выглядит, можно посмотреть здесь. Вообще для меня особых неудобств это никогда не представляло. Все необходимые мне инструменты (подсветка кода, горячие клавиши..) могу быть легко реализованы на веб интерфейсе. Для тех, кому нужно большее, полноценной замены IDE все же нет.
—Сложность отладки. Вытекает из первого пункта. Осложняется тем, что если вы захотите какой-то код динамически загружать из бд и выполнять его функцией eval, то найти ошибку может быть действительно непросто.
—Поддержка. Как и у всего, что не распространено поддержки вашего проекта другими разработчиками не будет никакой. Действительно проблема, которая решается только популяризацией.
В этом топике так же были указаны еще минусы с которыми я попробую поспорить:
исходники это файлы, в итоге с ними можно делать любые файловые операции
Безопасность, прямой код инжекшн в случае проблем
Бекап, представляете, бывает так, что их не делают, и тогда любые ваши «кастомизации» on site коту под хвост если сломаеться база
Для работы движка (после того как сработает кодеген) бд уже не нужна. То есть сайт может работать и при выключенной бд.
Плюсы
— Скорость. Для меня это стало решающим фактором. Впервые, когда я сравнил скорость на старом «классическом» движке и на новом, я был потрясен результатом.
— Гибкость на макроуровне. Чем из наиболее мелких и простых частей состоит конструктор, тем более сложные вещи можно из него собрать.
— Атрибуты у частей кода. Так как наши кирпичики хранятся в таблице, то каждому из них мы можем задавать какие либо атрибуты, посредством добавления соответствующего поля. Это действительно очень важная особенность, открывающая новые просторы в разработке.
— Возможность проводить любую обработку исполняемого кода перед его выполнением. Как вы помните, весь код у нас проходит через codegen, а следовательно в нем мы можем его модифицировать произвольным образом. Например, применять языковые пакеты на стадии генерации кода страниц. Или еще таким образом: если в коде часто встречается какая-нибудь строка, например
А на стадии генерации просто заменять его на нужный вам код. Так что предварительная обработка кода тоже дает простор для фантазии программиста.
Заключение
В этой статье я хотел показать, что идеология хранения кода в бд не такая безнадежная, как может показаться на первый взгляд. На ряду с очевидными минусами, есть и уникальные плюсы, которые раздвигают рамки возможностей в веб программировании. И, что немаловажно, не только в теории, но и на практике: я использую этот подход уже на протяжении трех лет. А это по-моему, достаточный срок для проверки его «выживаемости» в реальных условиях. Я ни коим образом не утверждаю, что хранение кода в бд лучше, чем использование классического подхода. Но я верю, что это вполне конкурентоспособная концепция, и работа в этой области может дать толчок для появления принципиально новых фреймворков и CMS, с уникальными возможностями.
В каком устройстве хранится код команды
Самый основной элемент компьютера, это, конечно, процессор. Давайте подробней его рассмотрим. Упрощённая структура процессора (рис. 4):

Рис. 4. Упрощённая структура процессора
Основные элементы процессора:
· Регистры – это специальные ячейки памяти, физически расположенные внутри процессора. В отличие от ОЗУ, где для обращения к данным требуется использовать шину адреса, к регистрам процессор может обращаться напрямую. Это существенно ускорят работу с данными.
· Арифметико-логическое устройство выполняет арифметические операции, такие как сложение, вычитание, а также логические операции.
· Блок управления определяет последовательность микрокоманд, выполняемых при обработке машинных кодов (команд).
2.2. Режимы работы процессора.
Процессор архитектуры x86 может работать в одном из пяти режимов и переключаться между ними очень быстро:
1. Реальный (незащищенный) режим (real address mode) — режим, в котором работал процессор 8086. В современных процессорах этот режим поддерживается в основном для совместимости с древним программным обеспечением (DOS-программами).
2. Защищенный режим (protected mode) — режим, который впервые был реализован в 80286 процессоре. Все современные операционные системы (Windows, Linux и пр.) работают в защищенном режиме. Программы реального режима не могут функционировать в защищенном режиме.
3. Режим виртуального процессора 8086 (virtual-8086 mode, V86) — в этот режим можно перейти только из защищенного режима. Служит для обеспечения функционирования программ реального режима, причем дает возможность одновременной работы нескольких таких программ, что в реальном режиме невозможно. Режим V86 предоставляет аппаратные средства для формирования виртуальной машины, эмулирующей процессор8086. Виртуальная машина формируется программными средствами операционной системы. В Windows такая виртуальная машина называется VDM (Virtual DOS Machine — виртуальная машина DOS). VDM перехватывает и обрабатывает системные вызовы от работающих DOS-приложений.
4. Нереальный режим (unreal mode, он же big real mode) — аналогичен реальному режиму, только позволяет получать доступ ко всей физической памяти, что невозможно в реальном режиме.
5. Режим системного управления System Management Mode (SMM) используется в служебных и отладочных целях.
При загрузке компьютера процессор всегда находится в реальном режиме, в этом режиме работали первые операционные системы, например MS-DOS, однако современные операционные системы, такие как Windows и Linux переводят процессор в защищенный режим. Вам, наверное, интересно, что защищает процессор в защищенном режиме? В защищенном режиме процессор защищает выполняемые программы в памяти от взаимного влияния (умышленно или по ошибке) друг на друга, что легко может произойти в реальном режиме. Поэтому защищенный режим и назвали защищенным.
2.3. Регистры процессора (программная модель процессора).
Для понимания работы команд ассемблера необходимо четко представлять, как выполняется адресация данных, какие регистры процессора и как могут использоваться при выполнении инструкций. Рассмотрим базовую программную модель процессоров Intel 80386, в которую входят:
· 8 регистров общего назначения, служащих для хранения данных и указателей;
· регистры сегментов — они хранят 6 селекторов сегментов;
· регистр управления и контроля EFLAGS, который позволяет управлять состоянием выполнения программы и состоянием (на уровне приложения) процессора;
· регистр-указатель EIP выполняемой следующей инструкции процессора;
· система команд (инструкций) процессора;
· режимы адресации данных в командах процессора.
Начнем с описания базовых регистров процессора Intel 80386.
Базовые регистры процессора Intel 80386 являются основой для разработки программ и позволяют решать основные задачи по обработке данных. Все они показаны на рис. 5.

Рис. 5. Базовые регистры процессора Intel 80386
Среди базового набора регистров выделим отдельные группы и рассмотрим их назначение.
2.4. Регистры общего назначения.
2.5. Сегментные регистры.
В отличие от DS, ES, GS, FS, которые называются регистрами сегментов данных, CS и SS отвечают за сегменты двух особенных типов – сегмент кода и сегмент стека. Первый содержит программу, исполняющуюся в данный момент, следовательно, запись нового селектора в этот регистр приводит к тому, что далее будет исполнена не следующая по тексту программы команда, а команда из кода, находящегося в другом сегменте, с тем же смещением. Смещение очередной выполняемой команды всегда хранится в специальном регистре EIP (указатель инструкции, 16-битная форма IP), запись в который так же приведет к тому, что далее будет исполнена какая-нибудь другая команда. На самом деле все команды передачи управления – перехода, условного перехода, цикла, вызова подпрограммы и т.п. – и осуществляют эту самую запись в CS и EIP.

Рис. 6. Регистр флагов FLAGS.
CF – флаг переноса. Устанавливается в 1, если результат предыдущей операции не уместился в приемнике и произошел перенос из старшего бита или если требуется заем (при вычитании), в противном случае – в 0. Например, после сложения слова 0 FFFFh и 1, если регистр, в который надо поместить результат, – слово, в него будет записано 0000 h и флаг CF = 1.
PF – флаг четности. Устанавливается в 1, если младший байт результата предыдущей команды содержит четное число битов, равных 1, и в 0, если нечетное. Это не то же самое, что делимость на два. Число делится на два без остатка, если его самый младший бит равен нулю, и не делится, когда он равен 1.
AF – флаг полупереноса или вспомогательного переноса. Устанавливается в 1, если в результате предыдущей операции произошел перенос (или заем) из третьего бита в четвертый. Этот флаг используется автоматически командами двоично-десятичной коррекции.
ZF – флаг нуля. Устанавливается в 1, если результат предыдущей команды – ноль.
SF – флаг знака. Он всегда равен старшему биту результата.
TF – флаг ловушки. Он был предусмотрен для работы отладчиков, не использующих защищенный режим. Установка его в 1 приводит к тому, что после выполнения каждой программной команды управление временно передается отладчику.
IF – флаг прерываний. Сброс этого флага в 0 приводит к тому, что процессор перестает обрабатывать прерывания от внешних устройств. Обычно его сбрасывают на короткое время для выполнения критических участков кода.
DF – флаг направления. Он контролирует поведение команд обработки строк: когда он установлен в 1, строки обрабатываются в сторону уменьшения адресов, когда DF =0 – наоборот.
OF – флаг переполнения. Он устанавливается в 1, если результат предыдущей арифметической операции над числами со знаком выходит за допустимые для них пределы. Например, если при сложении двух положительных чисел получается число со старшим битом, равным единице, то есть отрицательное, и наоборот.
Флаги IOPL (уровень привилегий ввода-вывода) и NT (вложенная задача) применяются в защищенном режиме.
2.7. Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в оперативную память компьютера. Затем программа начинает выполняться, то есть процессор выполняет машинные команды в той последовательности, в какой они записаны в программе.
Для того чтобы процессор знал, какую команду нужно выполнять в определённый момент, существует счётчик команд – специальный регистр, в котором хранится адрес команды, которая должна быть выполнена после выполнения текущей команды. То есть при запуске программы в этом регистре хранится адрес первой команды. В процессорах Intel в качестве счётчика команд (его ещё называют указатель команды) используется регистр EIP (или IP в 16-разрядных программах).
Счётчик команд работает со сверхоперативной памятью, которая находится внутри процессора. Эта память носит название очередь команд, куда помещается одна или несколько команд непосредственно перед их выполнением. То есть в счётчике команд хранится адрес команды в очереди команд, а не адрес оперативной памяти.
Цикл выполнения команды – это последовательность действий, которая совершается процессором при выполнении одной машинной команды. При выполнении каждой машинной команды процессор должен выполнить как минимум три действия: выборку, декодирование и выполнение. Если в команде используется операнд, расположенный в оперативной памяти, то процессору придётся выполнить ещё две операции: выборку операнда из памяти и запись результата в память. Ниже описаны эти пять операций.
Суммируем полученные знания и составим цикл выполнения команды:
Это упрощённый цикл выполнения команды. К тому же действия могут отличаться в зависимости от процессора. Однако это даёт общее представление о том, как процессор выполняет одну машинную команду, а значит и программу в целом.
Система кодирования команд. Способы адресации
Способы адресации
Решить проблему сокращения разрядности команды только за счет сокращения количества указываемых в команде операндов и применения регистровой памяти невозможно. Этой же цели служит использование различных способов адресации операндов. Кроме того, применение нескольких способов адресации повышает гибкость программирования, так как в каждом конкретном случае позволяет обеспечить наиболее рациональный способ доступа к информации в памяти.
К основным способам адресации относятся следующие: прямая, непосредственная, косвенная, относительная.
где Аi – код, содержащийся в i-м адресном поле команды.
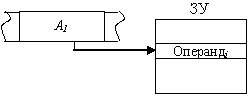
Допускается использование прямой адресации при обращении как к основной, так и к регистровой памяти.
Непосредственная адресация. В команде содержится не адрес операнда, а непосредственно сам операнд ( рис. 11.5):

Косвенная адресация ( рис. 11.6). Адресная часть команды указывает адрес ячейки памяти (рис. 11.6,а) или номер регистра (рис. 11.6,б), в которых содержится адрес операнда:
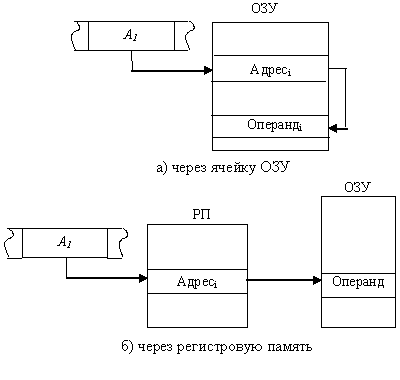
Применение косвенной адресации операнда из оперативной памяти при хранении его адреса в регистровой памяти существенно сокращает длину поля адреса, одновременно сохраняя возможность использовать для указания физического адреса полную разрядность регистра.
Косвенная адресация не применяется по отношению к операндам, находящимся в регистровой памяти.
Рассмотрим два примера.
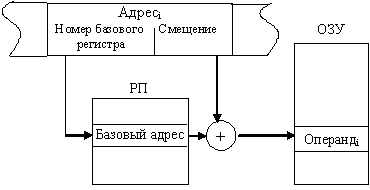
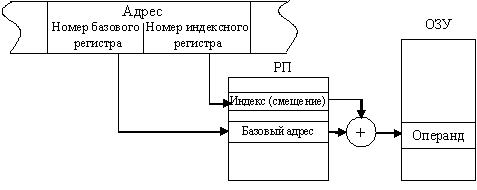
Главный недостаток относительной адресациии – большое время вычисления физического адреса операнда. Но существенное преимущество этого способа адресации заключается в возможности создания «перемещаемых» программ – программ, которые можно размещать в различных частях памяти без изменения команд программы. То же относится к программам, обрабатывающим по единому алгоритму информацию, расположенную в различных областях ЗУ. В этих случаях достаточно изменить содержимое базового адреса начала команд программы или массива данных, а не модифицировать сами команды. По этой причине относительная адресация облегчает распределение памяти при составлении сложных программ и широко используется при автоматическом распределении памяти в мультипрограммных вычислительных системах.
Система кодирования команд. Способы адресации
Система кодирования команд
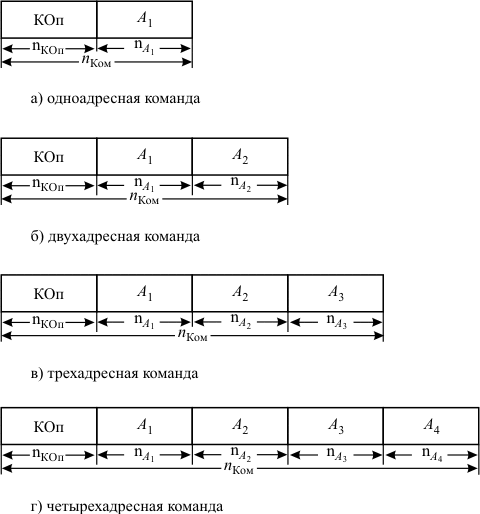
Запись любой команды определяется ее форматом. Формат команды – это структура команды, позволяющая распознать назначение отдельных ее полей.
Схема выполнения трехадресной команды имеет вид:
Здесь ADD – код операции сложения.
Формат двухадресной команды представлен на рис.11.1,б. Выполнение операции с помощью такой команды проходит по следующей схеме:
Выполнение того же самого действия c = a + b в двухадресной системе кодирования команд потребует уже двух команд, например:
Одноадресная команда имеет формат, приведенный на рис.11.1,а. Обычно ЭВМ с одноадресной системой команд имеют особую структуру, в состав которой входит специальный регистр ( регистр результата – РР ). Он служит для хранения результата операции и используется в качестве одного из операндов при выполнении операции ( рис. 11.2).

Схема выполнения операции на ЭВМ с одноадресной системой команд имеет вид:
Операцию c = a + b в одноадресной системе команд можно выполнить следующим образом:
Взаимозависимость формата команды и основных параметров ЭВМ
Важной характеристикой команды служит ее длина, которая складывается из длины поля кода операции и суммы длин адресных полей:
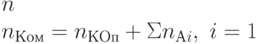
где n – количество адресных полей в команде.
Максимальное количество операций, которое может быть закодировано в поле кода операций длиной nкоп, составляет
Тогда по известному количеству команд ( K ), составляющих систему команд данной ЭВМ, можно определить необходимую длину поля операции:
Естественно, что эта величина должна быть минимально возможным целым числом. Так, для ЭВМ, имеющей систему команд из 100 команд, длина поля кода операции составит 7 бит.
Если поле адреса команды содержит просто номер ячейки ЗУ, к которой производится обращение, то длина этого поля определяется следующим образом:
где VЗУ – объем запоминающего устройства.
Правомерна и другая постановка задачи – определение максимального объема запоминающего устройства ( VЗУmax ), к которому можно обратиться при заданной длине поля адреса. В этом случае
Современные ЭВМ имеют, как правило, запоминающие устройства с минимальной адресуемой единицей 1 байт ( 1 байт = 8 бит ). Поэтому, например, адресация ЗУ объемом 1 мегабайт ( 1М байт = 2 20 байт ) требует 20 разрядов адресного поля, а поле адреса длиной 16 разрядов позволяет обращаться к памяти максимального объема 64 килобайта ( 1К байт = 2 10 байт ).
Одним из способов уменьшения длины поля адреса является введение в состав ЭВМ дополнительно специального блока памяти небольшого объема – регистровой памяти ( РП ). Это запоминающее устройство имеет высокое быстродействие и служит для хранения часто используемой информации: промежуточных результатов вычислений, счетчиков циклов, составляющих адреса при некоторых режимах адресации и т.д.. Так как объем РП невелик, адресация ее элементов требует относительно короткого адресного поля. Например, для регистровой памяти объемом 8 регистров требуется всего лишь трехразрядное адресное поле.



