Виды кодов
Преобразователи кодов
При выполнении различных операций в ПК применяют несколько видов кодирования для удобства хранения, передачи и обработки информации. Задачу перекодировки решают преобразователи кодов. Как и любое логическое устройство, они характеризуются таблицей истинности, являющейся основанием для синтеза логической схемы.
2. Двоично-десятичные коды, каждой цифре порядка соответствует его двоичный эквивалент, занимающий 4 позиции:
| 0001 0000 |
| 0001 0001 |
| 0001 0010 |
| 0001 0011 |
| 0001 0100 |
| 0001 0101 |
| 0001 0110 |
| 0001 0111 |
| 0001 1000 |
| 0001 1001 |
| И так далее |
3. Десятично-сбалансированые коды – десятичная цифра кодируется с помощью n-бит, где n>=4, например:
0101=0*2 3 +1*2 2 +0*2 1 +1*2 0 =5, код DCB
4. Код DCB с избытком 3, в предыдущем коде добавляется 3
5. Десятично-сбалансированные, самоопределяющиеся коды. Дополнение до какого-либо числа для проверки правильности кодировки или действия. Каждое число >4 – дополнение, сумма цифр всегда 15
| число | код | число | код |
6. Коды Грея – осуществляют переход от одного уровня к следующему изменением всего одной цифры. Числа представляются в простом двоичном коде. Например:
Для преобразования используется функция – «исключающее ИЛИ», то есть
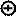 G0= A0 A1=А0А1’+А0’А1
G0= A0 A1=А0А1’+А0’А1
 G1= A1 A2
G1= A1 A2
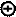 G2= A2 A3
G2= A2 A3
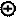 G3= A3 A0
G3= A3 A0
7. ASCII – кодирование символов клавиатуры
8. Коды с обнаружением ошибок
Частным случаем преобразователей кодов являются шифраторы и дешифраторы, преобразующие десятичное число в двоичное и обратно, соответственно.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Понятие кода. Типология кодов.
Коды – правила организации знаков, система определенных норм, с помощью которых информация представляется в знаковом виде. В более узком плане коды – способы организации синтагм из парадигм.
Коды одновременно являются способами организации знаков и регуляторами поведения. Все виды кодов выполняют функцию организации системных значений и имеют следующие характеристики:
1)они функционируют на основании некоторой единой парадигмы;
2)коды определяются конвенционально, т. е. опираются на соглашения пользователей;
3)коды транслируются по каналам ком-ции;
4)коды являются производными от культуры социальной общности, при этом коды и культура находятся в непрерывной прямой и обратной связи, т. е. влияют друг на друга.
1.Критерий характера парадигм
Аналоговые коды работают с непрерывными парадигмами. Разделительные коды опираются на дискретные парадигмы.
Аналоговые коды не разделяются четко на отдельные, дискретные элементы. Разделительные коды отделяют одно значение в парадигме от другого.(напевать мелодию – аналоговый код, записать мелодию нотами – разделительный код)
2.Репрезентационные и презентационные коды.
Эта типология связана не только с функцией кода в процессе знаковой деятельности, но и с функцией организации ком-ции субъекта.
1)репрезентационные коды – коды независимого существования, они заменяют субъекта, способны существовать автономно от него и от социальной ситуации, в которой осуществляется ком-ция. Это коды языка, с помощью которого формируются тексты. Тексты выполняют функции репрезентационных кодов.
2)презентационные коды – это коды-индексы, они не отделяются от ком-тора и ситуации взаимодействия и как правило надежнее всего функционируют в межличностной ком-ции, хотя представлены и в массовой ком-ции.
Невербальная ком-ция опирается на систему презентационных кодов. С помощью этих кодов ком-тор реализует две функции:
— передает индексичную информацию о себе и о своей реакции на ситуацию взаимодействия;
— интерактивное управление аудиторией.
Виды презентационных кодов:
· Дистанция, степень близости;
· Предметные характеристики самопрезентации, аксессуары;
· Контакт глазами, движения глаз;
· Позиция в геометрическом пространстве;
· Невербальные аспекты речи.
3.Сложные и простые коды
1)Сложные коды – коды, выделяющие, обосабливающие ком-тора. Для овладения ими требуется специальная подготовка. Сложные коды – атрибут профессиональных групп и субкультур. Чем выше профессиональный уровень субъекта, тем сложнее его кодовая система.
— сложные и простые коды выражают архитектонику текста, построение предложений, характеристики и объем словарного запаса;
— простой код ближе к устному взаимодействию и презентационным кодам невербальной ком-ции. Сложный код приемлем для письменной ком-ции, хотя он может быть и устным; подходит для абстрактных репрезентационных ком-тивных форматов;
— простые коды выступают в контактной ком-ции, сложные – в рефереционной функции, когда требуется точная передача информации;
— сложные коды для своего освоения требуют специального обучения, простые коды осваиваются в ходе выработки повседневного опыта.
4.Массовые и специальные коды.
1)Массовые коды относятся к простым кодам, они обращаются к сознанию обществ массового типа, ориентированы на сообщество, а не на индивида, выполняют объединяющую функцию.
2)Специальные коды – коды, употребляемые в рамках профессиональных сообществ, опираются на общий профессиональный или интеллектуальный опыт.
При исполнении специальных кодов акцент делается на различие между группой пользователей кода и остальных субъектов. При исполнении массового кода акцент противоположен, подчеркивание единства общности.
5.Логические и эстетические (условные) коды.
1)Логические коды – коды точных наук, в которых невозможно отклонение, искажение. Они символичны, статичны, безличны, не подвержены культурному влиянию.
2)Условный код мобилен, культурно детерминирован.
Главное отличие между логическим и условным кодом в природе их парадигм. Парадигмы логических кодов однозначны, определены, четкие, организованные. Условные коды имеют открытые парадигмы. Они подвержены конвенции, опираются на переменчивые культуры, на опыт пользователей. Они менее точно определены и способны к изменению. Динамика условного кода – от меньшинства к большинству, от специального сознания к массовому.
Билет 21. Развитие средств коммуникации в процессе антропогенеза.
Человеческая психика имеет длительную историю развития. Способы отражения действительности, средства коммуникации, механизмы регуляции поведения, деятельность современного человека, по предположению ряда палеоантропологов, формировались в течение миллиона лет, начиная с четвертичного периода, ознаменовавшегося появлением первых людей. Существует и другая позиция, призывающая ограничить историю вида, в качестве критерия формирования человека рассматривающая возникновение второй сигнальной системы и знаковой функции речи. Далее проводится краткий анализ путей развития средств коммуникации древних людей, позволивших им достигнуть современного уровня.
Существуют доказательства того, что синантроп использовал в пищу не сырую, а обработанную на огне пищу. Для регуляции совместной деятельности в таких условиях средства коммуникации должны были выйти за пределы жестов и мимики, необходимость общения ночью требовала звуковых сигналов.
Первые находки останков древних людей, принадлежащих к типу неандертальцев, сделаны в Европе в конце XIX и начале XX в. Древние останки неандертальцев были найдены и на территории бывшего СССР — в Узбекистане. Неандертальцы обладали черепами вытянутой формы с выраженным надглазничным валиком. Объем черепной коробки превышал 1200 см3, однако лобные доли были относительно невелики и мозг имел ряд черт сходства с мозгом человекообразных обезьян. Строение костей нижних конечностей показывает, что ноги еще не были вполне выпрямлены в коленных суставах. По-видимому, у них была довольно неуклюжая походка.
Как и синантропы, неандертальцы обитали в пещерах. Остатки других зверей показывают, что неандертальцы вели интенсивную охоту, в то время как более древние люди добывали пищу в большей степени собиранием плодов и корней. В процессе охоты они нападали на животное сообща, убив его, разрезали кожу каменными орудиями, срезали мясо, раздалбливали кости. Предполагают, что шкуры животных неандертальцы использовали для укрытия тела и для подстилок. Значительно усложнилась техника ведения хозяйства. Происходило дальнейшее разделение труда и выделение наиболее опытных охотников для управления первобытным стадом.
Каменные орудия неандертальцев были более разнообразны и лучше обрабатывались. В раскопках найдены ручные рубила, у которых обработанный конец мог служить как ударный, колющий и режущий инструмент.
Элементарные типы и операции над ними. Часть I: типы данных, размер, ограничение.
Строительными кирпичиками любого языка является элементарные типы данных с которыми мы можем работать. Зная их, мы всегда понимаем, что у нас хранится в той или иной переменной, что возвращает та или иная функция. Какие действия мы можем совершить над нашими данными. Это база. Поэтому именно этому я и хотел уделить внимание в данной статье в общем, а так же примерам работы с бинарными данными в частности.
Материал в первую очередь адресую тем кто только начал или хочет начать писать на Erlang-e. Но я постарался максимально полно охватить данный аспект языка и поэтому надеюсь, что написанное будет полезно и более продвинутой аудитории.
Первоначальный материал пришлось разделить на три части, в данной будут рассмотрены базовые типы языка, способы создания базовых типов и потребляемые ресурсы на каждый из типов.
Вступление
Для начала хочу выразить огромную признательность участникам русскоязычной рассылке по Erlang-у в Google-е за поднятие кармы и возможности выложить на хабр данную статью.
В процессе изложения будут приводиться примеры из командной оболочки (шелла) Эрланга. Поэтому нужно усвоить простые принципы работы. Каждая команда в шелле разделяется запятыми. При это совершенно не важно, производится набор в одну строку или в несколько.
1> X=1, Y = 2,
1> Z = 3,
1> S=4.
4
Указателем завершения ввода и запуск на выполнение является точка. При этом шелл выведет на экран значение возвращаемое последней из команд. В примере выше возвращается значение переменной S. Значения всех инициированных переменных запоминается, а так как в Эрланге нельзя переопределить значение инициированной переменной, то попытка переопределения приведет к ошибке:
2> Z=2.
** exception error: no match of right hand side value 2
Поэтому если требуется в текущей сессии работы заставить шелл «забыть» значения переменных, то можно воспользоваться функцией f(). Вызванная без аргументов она удаляет все инициализированные переменные. Если в качестве аргумента указать имя переменной, то удалена будут только она (передать список переменных нельзя):
3> f(Z).
ok
4> X = 4.
** exception error: no match of right hand side value 4
5> f().
ok
6> X = 4. %все, что идет после знака процента является комментарием
4
Для выхода достаточно ввести halt(), или вызвать интерфейс пользовательских команд Crtl+G и ввести q (команда h выведет справку). При выводе цифровых данных в шелле они приводятся к десятичному виду.
Изложенный материал относится к последней, актуальной на данный момент, версии 5.6.5. Для кодирования строк используется ISO-8859-1 (Latin-1) кодировка. Соответственно и все численные коды символов берутся из этой кодировки. Первая половина (коды 0-127) кодировки соответствует кодам US-ASCII, поэтому проблем с латинским алфавитом не возникает.
Несмотря на заявление разработчиков о том, что во внутреннем представлении используется Latin-1 «снаружи» виртуальной машины это зачастую совершенно неочевидно. Это возникает оттого, что Эрланг передает и принимает символы в виде кодов. Если для терминала установлена локаль, то коды интерпретируются исходя из установленной кодовой страницы и если это возможно выводятся в виде печатных символов. Вот пример SSH сессии:
# setenv | grep LANG
LANG=
# erl
Erlang (BEAM) emulator version 5.6.5 [source] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.6.5 (abort with ^G)
1> [255].
«\377»
2> halt().
# setenv LANG ru_RU.CP1251
# erl
Erlang (BEAM) emulator version 5.6.5 [source] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.6.5 (abort with ^G)
1> [255].
«я»
Причем совершенно не важно, что указано в переменной окружения LANG, главное что бы она была установлена.
1. Элементарные типы
В языке не очень много базовых типов. Это число (целое или с плавающей запятой), атом, двоичные данные, битовые строки, функции-объекты (аналогично JavaScript-у), идентификатор порта, идентификатор процесса (Erlang процесса, а не системного), кортеж, список. Существует ряд псевдотипов: запись, булев, строки. Любой тип данных (не обязательно элементарный) называется терм.
1.1 Число
Потребление памяти и ограничения. Целое занимает одно машинное слово, что для 32-ух и 64-х разрядных процессорах составляет 4 байта и 8 байт соответственно. Для больших целых 1…N машинных слов. Числа с плавающей точкой в зависимости от архитектуры занимают 4 и 3 машинных слова соответственно.
1.2 Список
Список (List) позволяют группировать данные в одну структуру. Список создается при помощи квадратных скобок, элементы списка разделяются запятыми. Элемент списка может быть любого типа. Первый элемент списка называется голова (head), а оставшаяся часть — хвост (tail).
Потребление памяти и ограничения. Каждый элемент списка занимает одно машинное слово (4 или 8 байт в зависимости от архитектуры) + размер хранимых в элементе данных. Таким образом на 32-ух разрядной архитектуре значение переменной List будет занимать (1 + 1) + (1 + 4) + (1 + 1) = 9 слов или 36 байт.
1.3 Строка
На самом деле в Эрланге нет строк (String). Это просто синтаксический сахар который позволяет в более удобной форме записывать список целых чисел. Каждый элемент этого списка представляет собой ASCII код соответствующего символа.
Потребление памяти и ограничения. Т.к. строка это список целых чисел, а каждый символ это один элемент списка, то на символ уходит 8 или 16 байт (2 машинных слова).
1.4 Атом
Атом (Atom) это просто литерал. Он не может быть связан с каким либо цифровым значением подобно константе в других языках. Значение возвращаемое атомом является самим атомом. Атом должен начинаться со строчной буквы и состоят из цифр, латинских букв, знака подчеркивания _ или собачки @. В этом случае его можно не заключать в одиночные кавычки. Если имеется другие символы, то нужно использовать одиночные кавычки для обрамления. Двойные кавычки для этого не подходят, т.к. в них заключают строки.
Например:
hello
phone_number
‘Monday’
‘phone number’
В строках и в закавыченных атомах можно использовать такие управляющие последовательности:
| Sequence | Description |
| \b | возврат (backspace) |
| \d | удалить (delete) |
| \e | эскейп (escape) |
| \f | прогон страницы (form feed) |
| \ | новая строка (newline) |
| \r | возврат каретки (carriage return) |
| \s | пробел (space) |
| \t | горизонтальная табуляция (tab) |
| \v | вертикальная табуляция (vertical tab) |
| \XYZ, \YZ, \Z | восьмеричный код символа |
| \^a. \^z \^A. \^Z | Ctrl + A … Ctrl + Z |
| \’ | одиночная кавычка |
| \» | двойная кавычка |
| \\ | обратная косая черта |
Имя незаковыченного атома не может быть зарезервированным словом. К таким словам относятся:
after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor.
Потребление памяти и ограничения. Каждый объявленный атом является уникальным и его символьное представление хранится во внутренней структуре виртуальной машины которая называется таблица атомов. Атом занимает 4 или 8 байт (одно машинное слово) и является просто ссылкой на элемент таблицы атомов в котором содержится его символьное представление. Сборщик мусора (garbage-collection) не выполняет очистку таблицы атомов. Сама таблица так же занимает место в памяти. Допускается использовать атомы в 255 символов, в общей сложности допустимо использовать 1 048 576 атомов. Таким образом атом в 255 символов будет занимать 255 * 2 + 1 * N машинных слов, где N – количество упоминаний атома в программе.
1.5 Кортеж
Кортеж (Tuple) подобен списку и состоит из набора элементов. Он так же имеет размер равный количеству элементов, но в отличие от списка его размер фиксирован. Кортеж создается при помощи фигурных скобок и его элементами могут быть любые типы данных, кортежи могут быть вложенными.
Кортежи удобны тем, что позволяют не только включать в структуру конкретные данные, но и описывать их. Это, а так же фиксированность кортежа позволяют очень эффективно применять их в шаблонах. Будет хорошей практикой при создании кортежа в первый элемент записывать атом описывающий сущность кортежа. Если проводить аналогии с РСУБД, то список является таблицей, каждая строка таблицы это элемент списка, а кортеж находящийся в этом элемент – конкретная запись в соответствующем столбце.
Потребление памяти и ограничения. Кортеж занимает 2 машинных слова + размер необходимый для хранения непосредственно самих данных. К примеру, кортеж в строке 5 будет занимать (2 + 1) + (2 + 1) = 6 машинных слов или 24 байта на 32-ой архитектуре. Максимальное количество элементов в кортеже 67 108 863.
1.6 Запись
Запись (Record) на самом деле является еще одним примером синтаксического сахара и во внутреннем представлении хранится как кортеж. Запись на этапе компиляции преобразуется в кортеж, поэтому использовать записи напрямую в шелле невозможно. Но можно воспользоваться rd() функцией для объявления структуры записи (строка 1). Объявление записи всегда состоит из двух элементов. Первый элемент обязательно должен быть атом называемый имя записи. Второй всегда кортежем, возможно даже пустым, элементы которого являются парой имя_поля – значение_поля, при этом имя поля должно быть атомом, а значение любым допустимым типом (в том числе и записью, строка 11).
Оператором создания кортежа на основании записи (строка 2) является решетка # после которой следует имя записи и кортеж со значениями полей, возможно даже и пустым, но ни когда с именами полей которые не объявлены в описание записи.
1> rd(person,
person
2> #person<>.
#person
3> #person
#person
Преимущество записи перед кортежем в том, что работа с элементами осуществляется по имени поля (имя должно быть атомом и быть объявленным в описании записи, строка 1), а не по номеру позиции. Соответственно порядок присвоения не имеет значения, не нужно помнить, что у нас содержится в первом элементе имя, телефон или адрес. Можно изменить порядок следования полей, добавить новые поля. Кроме того возможно присвоение значения по умолчанию когда соответствующее поле не задано.
4> rd(person,
person
5> P = #person<>.
#person
6> J = #person
#person
7> P#person.name.
«Smit»
8> J#person.name.
«Joi
9> W = J#person
#person
Если же при создании записи (строка 4) значение по умолчанию не определено (поле phone), то его значение равно атому undefined. Получить доступ к значению переменной созданной с помощью записи можно используя синтаксис описанный в строках 7 и 8. Можно скопировать значение переменной в новую переменную (строка 9). При этом если значение ни каких полей не определено, то получается полная копия, если же определены, то в новой переменной соответствующие поля переопределяются. Все эти манипуляции ни как не затрагивают ни определение записи, ни значения полей в старой переменной.
Лично мне это очень напоминает описание и создание экземпляров класса, хотя еще раз подчеркну, что это всего лишь способ хранения в переменной кортежа.
10> rd(name,
name
11> rd(person,
person
12> P = #person
#person
phone = 123>
13> First = (P#person.name)#name.first.
«Robert»
Пример выше иллюстрирует вложенные записи и синтаксис доступа к внутренним элементам.
1.7 Бинарные данные и битовые строки
И бинарный тип (Binaries) и битовые строки (Bit strings) позволяют работать с двоичным кодом напрямую. Отличие бинарного типа от битовой строки в том, что бинарные данные должны состоять только из целого количества байт, т.е. количество бит в них кратно восьми. Битовые же строки позволяют работать с данными на уровне бит, т.е. по сути бинарный тип это частный случай битовой строки количество разрядов в которой кратно восьми. Можно как создавать данные описав их структуру, так и использовать данный тип в шаблонах. Двоичные данные описываются такой структурой:
>
Отдельной элемент такой структуры называется сегмент. Сегменты описывают логическую структуру двоичных данных и могут состоят из произвольного числа битов/байтов. Это дает очень мощный и удобный инструмент при использовании в шаблонах (пример такого применения будет рассмотрен в третьей части).
1> >.
>
2> >.
>
3> >.
>
4> Var = 30.
30
5> >.
>
Что бы понять, почему в результате создания двоичных данных в строке 2 мы получили 144 (т.е. 10010000, ведь мы, надеюсь, еще не забыли, что шелл при выводе приводит все цифровые данные к десятичному виду), а не ожидаемые 400 нужно рассмотреть битовый синтаксис описания сегмента.
Полная форма описания сегмента состоит из значения (Value), размера (Size) и спецификатора ( TypeSpecifierList ). Причем размер и спецификатор являются необязательными и если не заданы принимают значения по умолчанию.
Значение (Value) в конструкторе может быть числом (целым или с плавающей точкой), битовой строкой или строкой, которая, как мы помним, является на самом деле списком целых чисел. Однако вместе с тем значение сегмента не может быть списком даже целых чисел, т.к. внутри конструктора строка является синтаксическим сахаром для посимвольного преобразования в целые числа, а не в список. Т.е. запись > является синтаксическим сахаром для >, а не >.
Внутри шаблонов значение может быть литералом или неопределенной переменной. Вложенные шаблоны недопускаются. В Value так же можно использовать выражения, но в этом случае сегмент должен быть заключен в круглые скобки (строка 5).
Размер (Size) определяет размер сегмента в юнитах (Unit, о них чуть ниже) и должен быть числом. Значение по умолчанию Size зависит от типа (Type, см. ниже) Value, но может быть и явно задано. Для целых это 8, чисел с плавающей точкой 64, бинарный соответствует количеству байт, битовые строки количеству разрядов. Полный размер сегмента в битах можно вычислить как Size * Unit.
При использовании в шаблонах величина Size должна быть явно заданной (строка 7) и может не задаваться только для последнего сегмента поскольку в него попадает остаток данных (сродни чтению строки со start символа и до конца строки без указания нужного length количества символов).
6> Bin = >.
>
7> > = Bin,
8> Z. %переменная размером в 3 разряда, её значение 110
>
9> >.
>
10> >.
>
11> >.
>
Использую битовый синтаксис одни и те же данные могут быть описаны по разному (строки 9 и 11 описывают одну и туже двухбайтовую структуру).
1.8 Ссылка
Ссылка (Reference) представляет собой терм создаваемый функцией make_ref/0 и может считать уникальным. Она может быть использовать для такой структуры данных как первичный ключ.
Потребление памяти и ограничения. На 32-ух разрядной архитектуре требуется 5 машинных слов на одну ссылку для текущей локальной ноды и 7 слов для удаленной. На 64-ой 4 и 6 слов соответственно. Кроме того ссылка связана с таблицей нод которая также потребляет оперативную память.
1.9 Булев
Булев тип (Boolean) является псевдо типом т.к. на самом деле это всего лишь два атома true и false.
1.10 Объект-функция
Поэтому входные аргументы должны быть того же типа, что объявленные в функции. После ключевого слова when и до -> можно включать выражение результатом которого является true либо false. Тело функции выполняется в случае если выражение возвращает true. Если в ходе всех проверок тело функции так и не было выполнено (т.е. функция ни чего не вернула), то генерируется ошибка (строка 12). Переменные внутри функции являются локальными.
Функции могут быть вложенными, при этом результатом возвращаемым внешней функцией будет внутренняя:
1.11 Идентификатор процесса
Идентификатор процесса (Pid) возвращают функции spawn/1,2,3,4, spawn_link/1,2,3,4 and spawn_opt/4 при создании Эрланг процесса. Удобным механизмом взаимодействия с процессом может быть обращение к нему по имени, а не через цифровой идентификатор. Поэтому в Эрланге есть возможность связывать с Pid-ом символическое имя и в дальнейшем посылать сообщения процессу используя его имя.
Потребление памяти и ограничения. На данный тип уходит 1 машинное слово для локальных и 5 для удаленных нод. Кроме того функция связана с таблицей нод которая так же занимает память.
1.12 Идентификатор порта
Идентификатор порта ( Port Identifier) возвращает функция open_port/2 при создании порта. Порт представляет собой базовый механизм взаимодействия между Эрланг процессами и внешним миром. Он предоставляет байт ориентированный интерфейс связи с внешним программами. Процесс создавший порт называется владелец порта или процессом присоединенным к порту. Все данные проходящие через порт так же проходят и через владельца порта. После завершения процесса сам порт и внешняя программа должны так же завершиться. Внешняя программа должна представлять собой другой процесс операционной системы который принимает и отправляет данные со стандартного входа и выхода. Любой Эрланг процесс может послать данные через порт, но только владелец порта может получить данные через него. Для идентификатора порта, как и для идентификатора процесса, может быть зарегистрировано символьное имя.
Потребление памяти и ограничения. На данный тип уходит 1 машинное слово для локальных и 5 для удаленных нод. Кроме того функция связана с таблицей нод и таблицей портов которые так же занимает память.



