7.7 Обнаружение и исправление ошибок в коде Хэмминга
Решение: Для обнаружения ошибки производят уже знакомые нам проверки на четность.
Первая проверка: сумма П1+П3+П5+П7 = 0+0+1+1 четна. В младший разряд номера ошибочной позиции запишем 0.
Вторая проверка: сумма П2+П3+П6+П7 = 1+0+1+1 нечетна. Во второй разряд номера ошибочной позиции запишем 1
Третья проверка: сумма П4+П5+П6+П7 = 0+1+1+1 нечетна. В третий разряд номера ошибочной позиции запишем 1. Номер ошибочной позиции 110= 6. Следовательно, символ шестой позиции следует изменить на обратный, и получим правильную кодовую комбинацию.
Код, исправляющий одиночную и обнаруживающий двойную ошибки
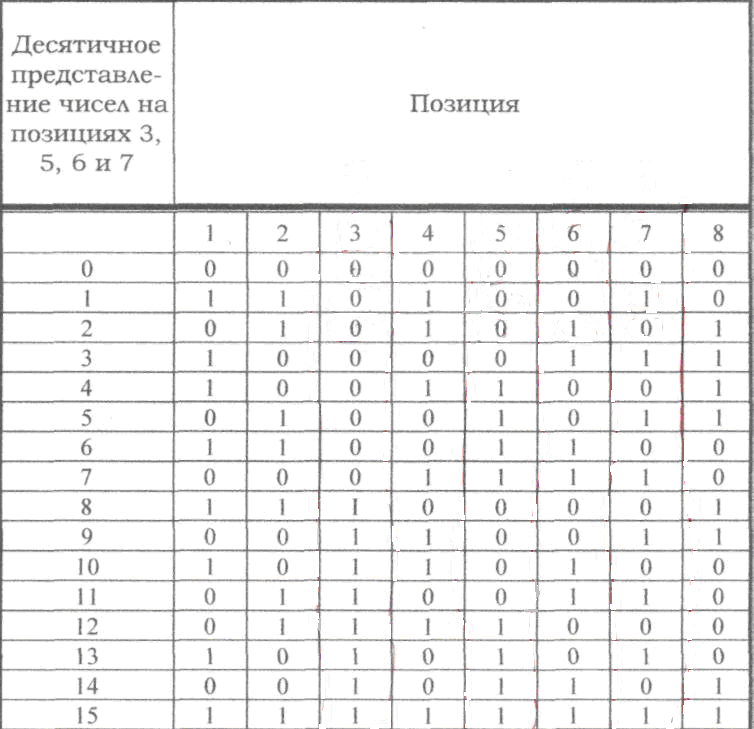
Если по изложенным выше правилам строить корректирующий код с обнаружением и исправлением одиночной ошибки для равномерного двоичного кода, то первые 16 кодовых комбинаций будут иметь вид, показанный в таблице. Такой код может быть использован для построения кода с исправлением одиночной ошибки и обнаружением двойной.
8.1 Двоичные циклические коды
Вышеприведенная процедура построения линейного кода матричным методом имеет ряд недостатков. Она неоднозначна (МДР можно задать различным образом) и неудобна в реализации в виде технических устройств. Этих недостатков лишены линейные корректирующие коды, принадлежащие к классу циклических.
Циклическими называют линейные (n,k)-коды, обладающие следующим свойством: для любого кодового слова:
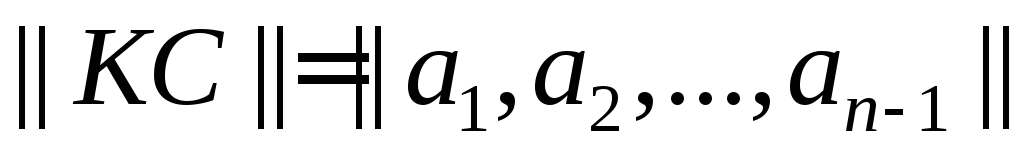
существует другое кодовое слово:
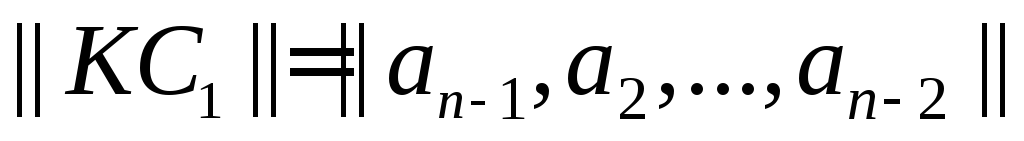
полученное циклическим сдвигом элементов исходного кодового слова ||КС|| вправо или влево, которое также принадлежит этому коду.
Для описания циклических кодов используют полиномы с фиктивной переменной X.
Например, пусть кодовое слово ||КС|| = ||011010||.
Его можно описать полиномом
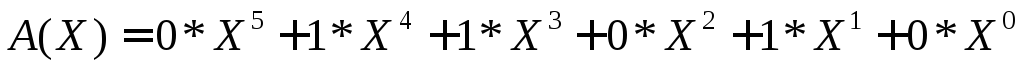
Таким образом, разряды кодового слова в описывающем его полиноме используются в качестве коэффициентов при степенях фиктивной переменной X.
Наибольшая степень фиктивной переменной X в слагаемом с ненулевым коэффициентом называется степенью полинома. В вышеприведенном примере получился полином 4-й степени.
Теперь действия над кодовыми словами сводятся к действиям над полиномами. Вместо алгебры матриц здесь используется алгебра полиномов.
Рассмотрим алгебраические действия над полиномами, используемые в теории циклических кодов. Суммирование полиномов разберем на примере С(Х)=А(Х)+В(Х).
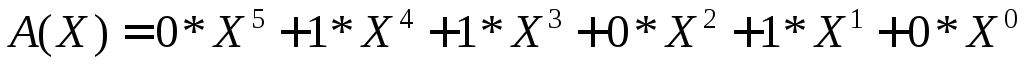

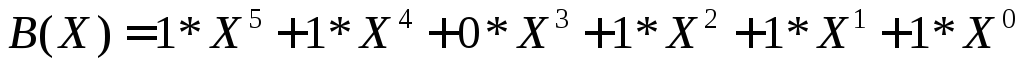
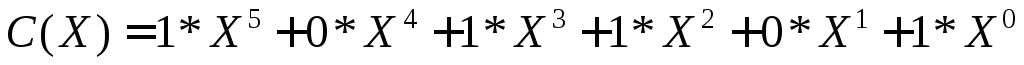
Таким образом, при суммировании коэффициентов при X в одинаковой степени результат берется по модулю 2. При таком правиле вычитание эквивалентно суммированию.
Умножение выполняется как обычно, но с использованием суммирования по модулю 2.
X 6 +X 5 +0*X 4 +X 3 результат== |X 3 +X 2
Циклический сдвиг влево на одну позицию коэффициентов полинома степени n-1 получается путем его умножения на X с последующим вычитанием из результата полинома X n +1, если его порядок > п.
Проверим это на примере.
Пусть требуется выполнить циклический сдвиг влево на одну позицию
В результате должен получиться полином
Это легко доказывается:
В основе циклического кода лежит образующий полином r-го порядка (напомним, что r— число дополнительных разрядов). Будем обозначать его gr(X).
Образование кодовых слов (кодирование) КС выполняется путем умножения информационного полинома с коэффициентами, являющимися информационной последовательностью И(Х) порядка i 18 / 34 18 19 20 21 22 23 24 25 26 > Следующая > >>
Тут вы можете оставить комментарий к выбранному абзацу или сообщить об ошибке.
Обнаружение и исправление ошибок в коде Хэмминга
Построение кода Хэмминга
Пример: Построить макет кода Хемминга и определить значения корректирующих разрядов для кодовой комбинации k=4, X=0101.
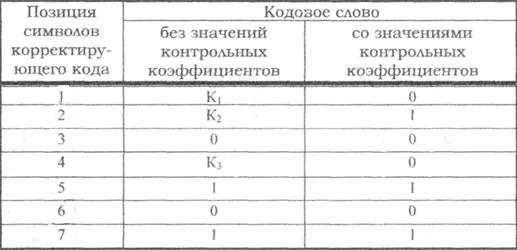
Решение:
Согласно таблице минимальное число контрольных символов r=3, при этом n = 7. Контрольный коэффициенты будут расположены на позициях 1, 2, 4. Составим макет корректирующего кода и запишем его во вторую колонку таблицы. Пользуясь таблицей для номеров проверочных коэффициентов, определим значения коэффициентов К1 К2 и К3.
Первая проверка: сумма П1+П3+П5+П7 должна быть четной, а сумма К1+0+1+1 будет четной при К =0.
Вторая проверка: сумма П2+П3+П6+П7 должна быть четной, а сумма К2+0+0+1 будет четной при К2=1.
Третья проверка: сумма П4+П5+П6+П7 должна быть четной, а сумма К3+1+0+1 будет четной при К3=0.
Окончательное значение искомой комбинации корректирующего кода записываем в третью колонку таблицы макета кода.
Решение: Для обнаружения ошибки производят уже знакомые нам проверки на четность.
Первая проверка: сумма П1+П3+П5+П7 = 0+0+1+1 четна. В младший разряд номера ошибочной позиции запишем 0.
Вторая проверка: сумма П2+П3+П6+П7 = 1+0+1+1 нечетна. Во второй разряд номера ошибочной позиции запишем 1
Третья проверка: сумма П4+П5+П6+П7 = 0+1+1+1 нечетна. В третий разряд номера ошибочной позиции запишем 1. Номер ошибочной позиции 110= 6. Следовательно, символ шестой позиции следует изменить на обратный, и получим правильную кодовую комбинацию.
Код, исправляющий одиночную и обнаруживающий двойную ошибки
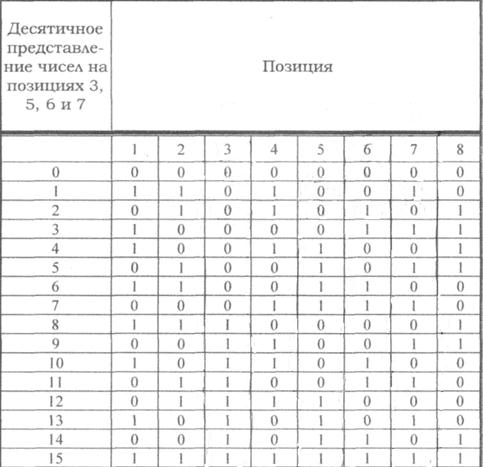
Если по изложенным выше правилам строить корректирующий код с обнаружением и исправлением одиночной ошибки для равномерного двоичного кода, то первые 16 кодовых комбинаций будут иметь вид, показанный в таблице. Такой код может быть использован для построения кода с исправлением одиночной ошибки и обнаружением двойной.
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Помехоустойчивое кодирование с иcпользованием различных кодов
Это продолженеие статьи о помехоустойчивом кодировании, которая очень долго лежала в черновиках. В прошлой части нет ничего интересного с практической точки зрения — лишь общие сведения о том, зачем это нужно, где применяется и т.п. В данной части будут рассматриваться некоторые (самые простые) коды для обнаружения и/или исправления ошибок. Итак, поехали.
Попытался все описать как можно легче для человека, который никогда не занимался кодированием информации, и без каких-либо особых математических формул.
Когда мы передаем сообщение от источника к приемнику, при передаче данных может произойти ошибка (помехи, неисправность оборудования и пр.). Чтобы обнаружить и исправить ошибку, применяют помехоустойчивое кодирование, т.е. кодируют сообщение таким образом, чтобы принимающая сторона знала, произошла ошибка или нет, и при могла исправить ошибки в случае их возникновения.
По сути, кодирование — это добавление к исходной информации дополнительной, проверочной, информации. Для кодирования на передающей стороне используются кодер, а на принимающей стороне — используют декодер для получения исходного сообщения.
Избыточность кода — это количество проверочной информации в сообщении. Рассчитывается она по формуле:
k/(i+k), где
k — количество проверочных бит,
i — количество информационных бит.
Например, мы передаем 3 бита и к ним добавляем 1 проверочный бит — избыточность составит 1/(3+1) = 1/4 (25%).
Код с проверкой на четность
Проверка четности – очень простой метод для обнаружения ошибок в передаваемом пакете данных. С помощью данного кода мы не можем восстановить данные, но можем обнаружить только лишь одиночную ошибку.

Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10110 (изменился второй бит)
Как мы видим, количество единиц в принятом пакете нечетно, следовательно, при передаче произошла ошибка.
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10010 (изменились 2 и 3 биты)
В принятых данных число единиц четно, и, следовательно, декодер не обнаружит ошибку.
Так как около 90% всех нерегулярных ошибок происходит именно с одиночным разрядом, проверки четности бывает достаточно для большинства ситуаций.
Код Хэмминга
первый проверочный бит на 2 0 = 1;
второй проверочный бит на 2 1 = 2;
третий проверочный бит на 2 2 = 4;
r1 = i1 + i2 + i4
r2 = i1 + i3 + i4
r3 = i2 + i3 + i4
В принципе, работа этого алгоритма разобрана очень детально в статье Код Хэмминга. Пример работы алгоритма, так что особо подробно описывать в этой статье не вижу смысла. Вместо этого приведу структурную схему кодера:
и декодера
(может быть, довольно запутано, но лучше начертить не получилось)
e0,e1,e2 опрделяются как функции, зависящие от принятых декодером бит k1 — k7:
e0 = k1 + k3 + k5 + k7 mod 2
e1 = k2 + k3 + k6 + k7 mod 2
e2 = k4 + k5 + k6 + k7 mod 2
Набор этих значений e2e1e0 есть двоичная запись позиции, где произошла ошибка при передаче данных. Декодер эти значения вычисляет, и если они все не равны 0 (то есть не получится 000), то исправляет ошибку.
Коды-произведения
В канале связи кроме одиночных ошибок, вызванных шумами, часто встречаются пакетные ошибки, вызванные импульсными помехами, замираниями или выпадениями (при цифровой видеозаписи). При этом пораженными оказываются сотни, а то и тысячи бит информации подряд. Ясно, что ни один помехоустойчивый код не сможет справиться с такой ошибкой. Для возможности борьбы с такими ошибками используются коды-произведения. Принцип действия такого кода изображён на рисунке:
Передаваемая информация кодируется дважды: во внешнем и внутреннем кодерах. Между ними устанавливается буфер, работа которого показана на рисунке:
Информационные слова проходят через первый помехоустойчивый кодер, называемый внешним, т.к. он и соответствующий ему декодер находятся по краям системы помехоустойчивого кодирования. Здесь к ним добавляются проверочные символы, а они, в свою очередь, заносятся в буфер по столбцам, а выводятся построчно. Этот процесс называется перемешиванием или перемежением.
При выводе строк из буфера к ним добавляются проверочные символы внутреннего кода. В таком порядке информация передается по каналу связи или записывается куда-нибудь. Условимся, что и внутренний, и внешний коды – коды Хэмминга, с тремя проверочными символами, то есть и тот, и другой могут исправить по одной ошибке в кодовом слове (количество «кубиков» на рисунке не критично — это просто схема). На приемном конце расположен точно такой же массив памяти (буфер), в который информация заносится построчно, а выводится по столбцам. При возникновении пакетной ошибки (крестики на рисунке в третьей и четвертой строках), она малыми порциями распределяется в кодовых словах внешнего кода и может быть исправлена.
Назначение внешнего кода понятно – исправление пакетных ошибок. Зачем же нужен внутренний код? На рисунке, кроме пакетной, показана одиночная ошибка (четвертый столбец, верхняя строка). В кодовом слове, расположенном в четвертом столбце — две ошибки, и они не могут быть исправлены, т.к. внешний код рассчитан на исправление одной ошибки. Для выхода из этой ситуации как раз и нужен внутренний код, который исправит эту одиночную ошибку. Принимаемые данные сначала проходят внутренний декодер, где исправляются одиночные ошибки, затем записываются в буфер построчно, выводятся по столбцам и подаются на внешний декодер, где происходит исправление пакетной ошибки.
Использование кодов-произведений многократно увеличивает мощность помехоустойчивого кода при добавлении незначительной избыточности.
Код Хэмминга. Пример работы алгоритма
Прежде всего стоит сказать, что такое Код Хэмминга и для чего он, собственно, нужен. На Википедии даётся следующее определение:
Коды Хэмминга — наиболее известные и, вероятно, первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Другими словами, это алгоритм, который позволяет закодировать какое-либо информационное сообщение определённым образом и после передачи (например по сети) определить появилась ли какая-то ошибка в этом сообщении (к примеру из-за помех) и, при возможности, восстановить это сообщение. Сегодня, я опишу самый простой алгоритм Хемминга, который может исправлять лишь одну ошибку.
Также стоит отметить, что существуют более совершенные модификации данного алгоритма, которые позволяют обнаруживать (и если возможно исправлять) большее количество ошибок.
Сразу стоит сказать, что Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
Как это работает.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Подготовка
Допустим, у нас есть сообщение «habr», которое необходимо передать без ошибок. Для этого сначала нужно наше сообщение закодировать при помощи Кода Хэмминга. Нам необходимо представить его в бинарном виде.
На этом этапе стоит определиться с, так называемой, длиной информационного слова, то есть длиной строки из нулей и единиц, которые мы будем кодировать. Допустим, у нас длина слова будет равна 16. Таким образом, нам необходимо разделить наше исходное сообщение («habr») на блоки по 16 бит, которые мы будем потом кодировать отдельно друг от друга. Так как один символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII символа. Итак, мы получили две бинарные строки по 16 бит:
и
После этого процесс кодирования распараллеливается, и две части сообщения («ha» и «br») кодируются независимо друг от друга. Рассмотрим, как это делается на примере первой части.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас получилось 5 контрольных бит (выделены красным цветом):
Было:
Стало:
Таким образом, длина всего сообщения увеличилась на 5 бит. До вычисления самих контрольных бит, мы присвоили им значение «0».
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого контрольного бита зависит от значений информационных бит (как неожиданно), но не от всех, а только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты отвечает каждых контрольный бит необходимо понять очень простую закономерность: контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная с позиции N. Не очень понятно, но по картинке, думаю, станет яснее:
Здесь знаком «X» обозначены те биты, которые контролирует контрольный бит, номер которого справа. То есть, к примеру, бит номер 12 контролируется битами с номерами 4 и 8. Ясно, что чтобы узнать какими битами контролируется бит с номером N надо просто разложить N по степеням двойки.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём каждый контрольный бит и смотрим сколько среди контролируемых им битов единиц, получаем некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу. Вот и всё! Можно конечно и наоборот, если число чётное, то ставим единицу, в противном случае, ставим 0. Главное, чтобы в «кодирующей» и «декодирующей» частях алгоритм был одинаков. (Мы будем применять первый вариант).
Высчитав контрольные биты для нашего информационного слова получаем следующее:
и для второй части:
Вот и всё! Первая часть алгоритма завершена.
Декодирование и исправление ошибок.
Теперь, допустим, мы получили закодированное первой частью алгоритма сообщение, но оно пришло к нас с ошибкой. К примеру мы получили такое (11-ый бит передался неправильно):
Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую картину:
Как мы видим, контрольные биты под номерами: 1, 2, 8 не совпадают с такими же контрольными битами, которые мы получили. Теперь просто сложив номера позиций неправильных контрольных бит (1 + 2 + 8 = 11) мы получаем позицию ошибочного бита. Теперь просто инвертировав его и отбросив контрольные биты, мы получим исходное сообщение в первозданном виде! Абсолютно аналогично поступаем со второй частью сообщения.
Заключение.
В данном примере, я взял длину информационного сообщения именно 16 бит, так как мне кажется, что она наиболее оптимальная для рассмотрения примера (не слишком длинная и не слишком короткая), но конечно же длину можно взять любую. Только стоит учитывать, что в данной простой версии алгоритма на одно информационное слово можно исправить только одну ошибку.
Примечание.
На написание этого топика меня подвигло то, что в поиске я не нашёл на Хабре статей на эту тему (чему я был крайне удивлён). Поэтому я решил отчасти исправить эту ситуацию и максимально подробно показать как этот алгоритм работает. Я намеренно не приводил ни одной формулы, дабы попытаться своими словами донести процесс работы алгоритма на примере.
Обнаружение ошибок в кодах Хемминга
Ошибка на выходе из канала связи может быть обнаружена и исправлена так (для построенного кода – не больше одной в каждом элементарном коде). Номер позиции S (записанный в двоичной системе), в которой произошла ошибка, определяется так:
где Si определяется по формулам (4) для элементарного кода, полученного на выходе канала связи. Если ошибки нет, то Si = 0 и общий результат S = 0.
Пример 1: Пусть на вход канала связи поступил элементарный код 0110011 (т.е закодировано **1*011 (поз. 3,5,6,7– информационные, а контрольные члены заменены * )). На выходе получено 0110001 (искажен 6–й член элементарного кода). Вычислим S.
S= 1 1 0 = 6 (в десятичной системе).
Пример 2:Пусть на выходе получено 0111011 (искажен 4–й (контрольный) член элементарного кода).
Тогда восстановленное сообщение имеет вид: 0110011, а исходное сообщение – 1011(удалены контрольные члены, выделенные цветом)
Декодирование
После получения закодированного сообщения происходит его разбивка на элементарные коды, вычисление для каждого кода Sи в случае его неравенства 0 – корректировка соответствующего информационного члена (если S указывает на контрольный член, то корректировка не нужна). После удаления всех контрольных членов получаем исходное сообщение.
Примечание: Рассмотрено построение кодов Хемминга для бинарного кодирования и допустимом числе ошибок в элементарных кодах не более одной. Существует теория для построения таких кодов для равномерного кодирования любой арности и числе ошибок не более 2, 3,… и. д.
Алфавитное кодирование с минимальной избыточностью
Пусть задано алфавитное кодирование со схемой å
Теорема 1 Если алфавитное кодирование со схемой å обладает свойством взаимной однозначности, то выполняется следующее неравенство (неравенство Макмиллана):

Пояснения.
2. Нельзя построить схему алфавитного кодирования, обладающую свойством взаимной однозначности, если неравенство (3.5) нарушено.
3 Теоремы 1 и 3 не дают полного алгоритма построения схемы алфавитного кодирования, обладающей свойством взаимной однозначности (если выполняется неравенство 5 – такая схема существует и можно продолжать ее построение, используя другие свойства и теоремы).
l = ]logq r [ (наименьшее целое число не меньшее логарифма r по основанию q). Если схема кодирования такова, что элементарные коды имеют различную длину, то можно говорить о величине среднего превышения длины кода над длиной самого сообщения:
 где li = l (Bi) (6)
где li = l (Bi) (6)
Если имеется статистика о вероятности появления символов входного алфавита
 (7)
(7)
l * =  (8)
(8)
В формуле (8) минимум берется по всем схемам кодирования å, обеспечивающим свойство взаимной однозначности.
Оценим интервал значений lср для схем кодирования å, обеспечивающих свойство взаимной однозначности.
 (10)
(10)
Такие коды дают в среднем минимальное увеличение длин слов при кодировании сообщений заданного источника. Представляет практический интерес задача построения таких кодов (схем кодирования) для источника сообщений с фиксированными характеристиками (в силу вышеизложенного можно ограничиться рассмотрением только схем кодирования, обладающих свойством префикса).
Построение кодов Хаффмана
Обобщим представление об алфавитном кодировании. Каждой схеме алфавитного кодирования å со свойством префикса можно поставить в соответствие кодовое дерево (связный ациклический неориентированный граф), которое является частью обобщенного кодового дерева. Обобщенное кодовое дерево строится так:
Ø выбирается начальная вершина (нулевой ярус дерева m = 0 );
Ø из этой вершины выходит пучок ребер, количество которых равно q (мощность алфавита O ), и каждому из них приписано значение элементов алфавита O=<b1,b2…> (первый ярус дерева m = 1 );
Ø из каждой вершины первого яруса снова выходит пучок ребер, количество которых равно q, и которые обозначены элементами алфавита O (второй ярус дерева m = 2 );
Ø аналогично строятся третий, четвертый и т.д. ярусы;
Кодовое дерево для конкретной схемы кодирования со свойством префикса будет являться частью обобщенного дерева, причем каждому элементарному коду должна соответствовать концевая вершина этого дерева, а начальные вершины должны совпадать.
 |
На рисунке 1 показано обобщенное кодовое дерево для q = 3. Количество вершин на каждом ярусе равно q m (на первом – 3, на втором – 9, на третьем – 27 и т.д.). При равномерном алфавитном кодировании все элементарные коды имеют одинаковую длину.
Более сложный случай, когда
(для конкретного значения r всегда можно подобрать целое m, удовлетворяющее этому неравенству).
Общие принципы поиска кода (схемы кодирования) с минимальной избыточностью:
§ для построения элементарных кодов использовать только m и m+1 ярусы кодового дерева;
§ переходить на m+1 ярус можно только после исчерпания всех возможностей m– го яруса.
Для реализации этого алгоритма необходимо представить r в виде:
t число вершин m+1 яруса, не задействованных при построении схемы кодирования ( t * будет иметь следующий вид:
Если имеется информация о вероятности появления символов входного алфавита
Лемма 1 Для кода с минимальной избыточностью из условия pj * =  = 0,26 + (0,28+0,46)х2 = 1,74.
= 0,26 + (0,28+0,46)х2 = 1,74.
Пример2: Построить код с минимальной избыточностью (код Хаффмана) для следующих исходных данных:
Решение
q =3; r = 7 в соответствии с формулой (12) m = 1. Для кодирования будет достаточно 1–го и 2–го ярусов обобщенного кодового дерева (см. рис. 3).
Равенство выполняется для n = 2 и t= 0.

Определим l * для полученной схемы по формуле (13)
l * = (( 3-2) х1 + (3х2 – 0) (1+1)) / 7 = 13/7 = 1,86.



