Обзор дедупликации данных
область применения: Windows server 2022, Windows server 2019, Windows Server 2016, Azure Stack хЦи, версия 20H2
Что такое дедупликация данных
Дедупликация данных, часто называемая дедупликацией, — это функция, которая помогает снизить влияние избыточных данных на затраты на хранение. Если дедупликация данных включена, она оптимизирует свободное место в томе за счет проверки данных тома на наличие дублирующихся частей. Дублирующиеся части набора данных тома сохраняются один раз и (при необходимости) сжимаются для дополнительной экономии. Дедупликация оптимизирует избыточные данные, не нарушая достоверность или целостность данных. Дополнительные сведения о работе дедупликации данных см. в разделе Как работает дедупликация данных? на странице Understanding Data Deduplication (Понимание процесса дедупликации данных).
KB4025334 содержит сведение исправлений для дедупликации данных, включая важные исправления надежности, и настоятельно рекомендуется устанавливать его при использовании дедупликации данных с Windows Server 2016 и Windows Server 2019.
Преимущества дедупликации данных
Дедупликация данных помогает администраторам хранилища снизить затраты, связанные с дублирующимися данными. Большие наборы данных часто имеют массу дублирования, что увеличивает затраты на хранение данных. Например:
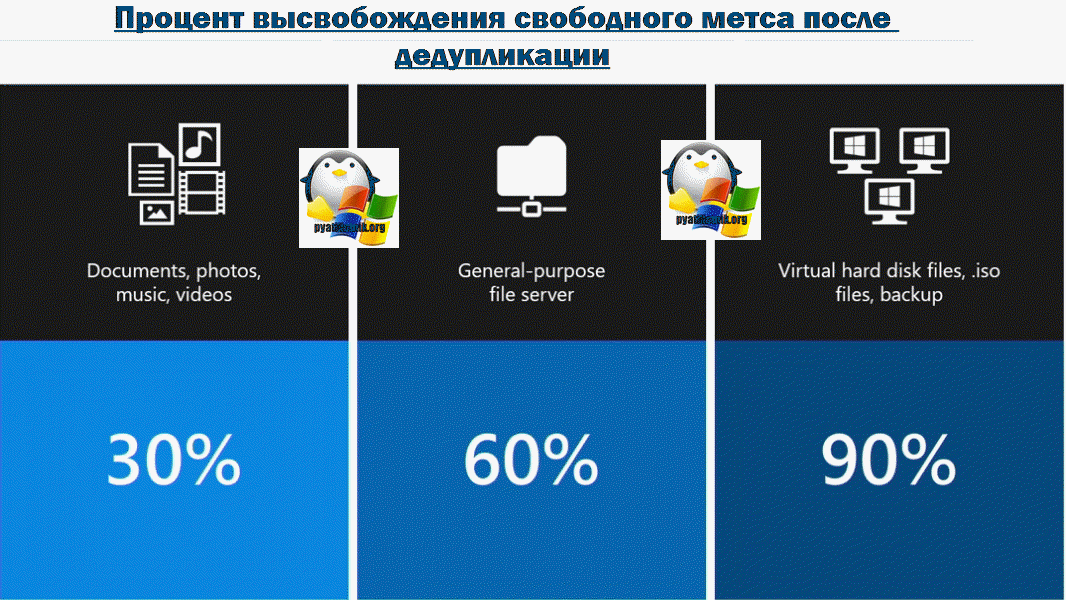
Экономия места, которую может обеспечить дедупликация данных, зависит от набора данных или рабочей нагрузки в томе. В наборах данных с высоким уровнем дупликации скорость оптимизации достигает 95 %, а объем использования службы хранилища может уменьшаться в 20 раз. В следующей таблице представлены типичные значения экономии за счет дедупликации для разных типов содержимого.
| Сценарий | Содержимое | Обычная экономия пространства |
|---|---|---|
| Документы пользователя | Документы Office, фотографии, музыка, видео и т. д. | 30-50 % |
| Общие ресурсы развертывания | Двоичные файлы программного обеспечения, CAB-файлы, символы и т. д. | 70–80 % |
| Библиотеки виртуализации | Образы ISO, файлы виртуальных жестких дисков и т. д. | 80–95 % |
| Файловый ресурс общего доступа | Все вышеперечисленное | 50–60 % |
Если вы просто хотите освободить место на томе, рассмотрите возможность использования Синхронизация файлов Azure с включенным распределением по уровням облака. Благодаря этому вы сможете кэшировать часто используемые файлы локально и распределять редко используемые файлы по уровням облака, сохраняя пространство в локальном хранилище и поддерживая производительность. Дополнительные сведения см. в статье Планирование развертывания Синхронизации файлов Azure.
Настройка дедупликации windows server 2019
 Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Добрый день! Дорогой читатель, я рад что ты вновь посетил один из крупнейших IT блогов рунета Pyatilistnik.org. Не так давно мы разобрали чистую установку Windows Server 2019, научились устанавливать в ней роли и компоненты. Время идет и ваш сервер может накопить большой объем данных, ресурсов на расширение может не быть, а выкручиваться как-то нужно, вот для таких ситуаций есть заумное слово дедупликация. В данном посте мы подробно разберем, что из себя представляет дедупликация данных в Windows Server 2019, что нового там появилось, ну и конечно, как все это настраивается и управляется. Уверен, что данный материал по самой новой серверной платформе будет многим полезен и актуален.
Что такое дедупликация данных?
На текущий момент основные производители жестких дисков, технологически не успевают за нуждами людей, сервисов в необходимом объеме дисков и уперлись в жалкие 10-12 ТБ на один HDD.Если рассматривать малый и средний бизнес, то у них в большинстве случаев просто нет возможности в покупке новых серверов или систем хранения данных, которые помогли бы им увеличить объем своих дисковых массивов. Именно борясь с данной проблемой люди придумали концепцию дедупликации.

По такому примеру построен дистрибутив всем известной операционной системы Windows 10, где на одном ISO Образе могут быть многие редакции: домашняя, профессиональная, максимальная, у каждой из них по сути одни и те же установочные файлы, а так как это так, то нет смысла хранить на дистрибутиве все эти версии одного и того же, в данном случае имеется только одна копия, и некоторое количество ссылок-указателей на него. Дедупликация делает все то же самое.
Еще очень распространенный пример, это сервис youtube, где есть одно оригинальное видео, которое лежит на дисковом пространстве, все остальные перезалитые ролики, просто ведут на оригинал по ссылке.
Плюсы и минусы дедупликации
Перед тем,как я опишу сам процесс дудупликации, я бы хотел отметить его положительные и отрицательные стороны.
Плюсы:
Минусы:
Что нового в дедупликации Windows Server 2019
Виды дедупликации
На текущий момент существует три вида дедупликации:
Механизм работы дедупликации
Технология дедупликации обычно разделяет данные на более мелкие порции, так называемые блоки и использует алгоритмы для назначения каждому блоку данных уникального хеш-идентификатора, называемого отпечатком. Чтобы создать отпечаток, он использует алгоритм, который вычисляет криптографическое значение хеша из блоков данных, независимо от типа данных. Эти слепки (хэши) хранятся в индексе.
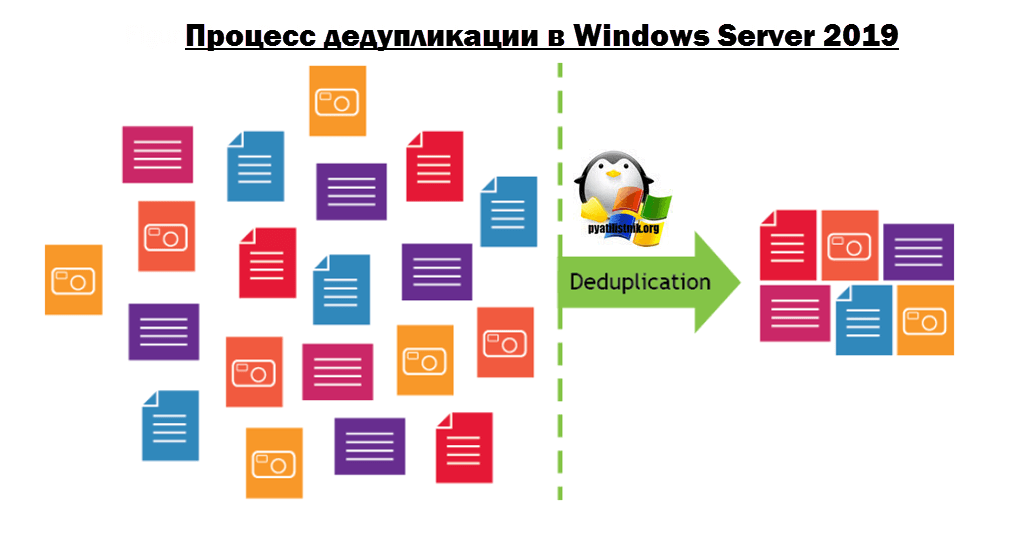
Алгоритм дедупликации сравнивает отпечатки фрагмента данных с теми, которые уже есть в индексе. Если в индексе присутствует отпечаток, блока данных, то блок заменяется указателем на блок данных (ссылкой). Если отпечаток не существует, данные записываются на диск как новый уникальный блок данных.
Более наглядно можно посмотреть на сайте Microsoft (https://docs.microsoft.com/ru-ru/windows-server/storage/data-deduplication/understand)
Эффективность дедупликации
Тут бы я хотел привести среднестатистические цифры, так сказать сколько можно выиграть в попугаях по разным типам данных:
Инструменты управления дедупликацией
Существует три инструмента, которые вам помогут отслеживать и управлять процессом дедупликации данных в Windows Server 2019:
Установка компонента дедупликации через «Диспетчер серверов»
Оставляем пункт «Установка ролей или компонентов» и нажимаем далее.
Далее вы выбираете сервер из пула или же виртуальный жесткий диск.
Пропускаем окно с компонентами Windows Server 2019.
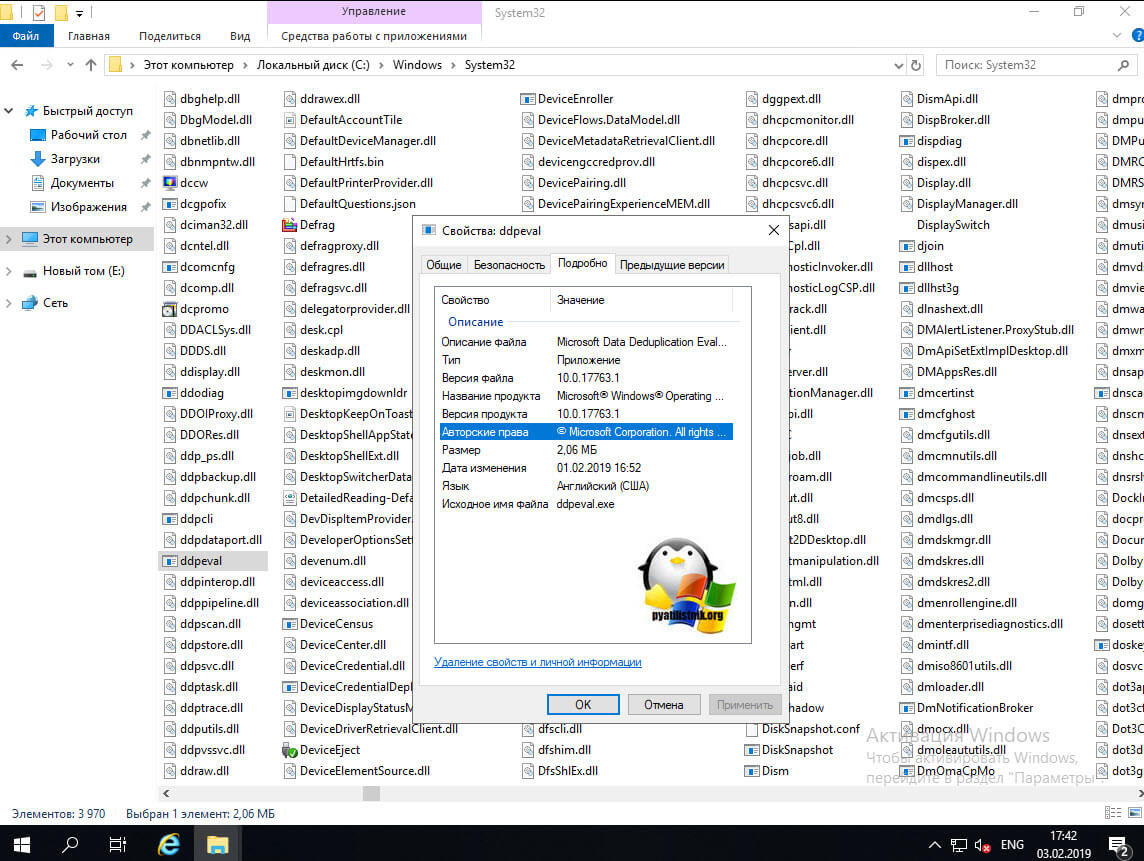
Для примера я запустил утилиту Deduplication Data Evaluation Tool в Windows 10 1809, через командную строку:
Учтите, что утилита ddpeval.exe не работает на системном диске. где установлена система. В моем примере, после того, как программка ddpeval.exe провела сбор данных, я вижу, что их можно оптимизировать за счет дедупликации на 27%, что для SSD-диска, с его не очень большим объемом, отличный результат.
Установка компонента дедупликации через PowerShell
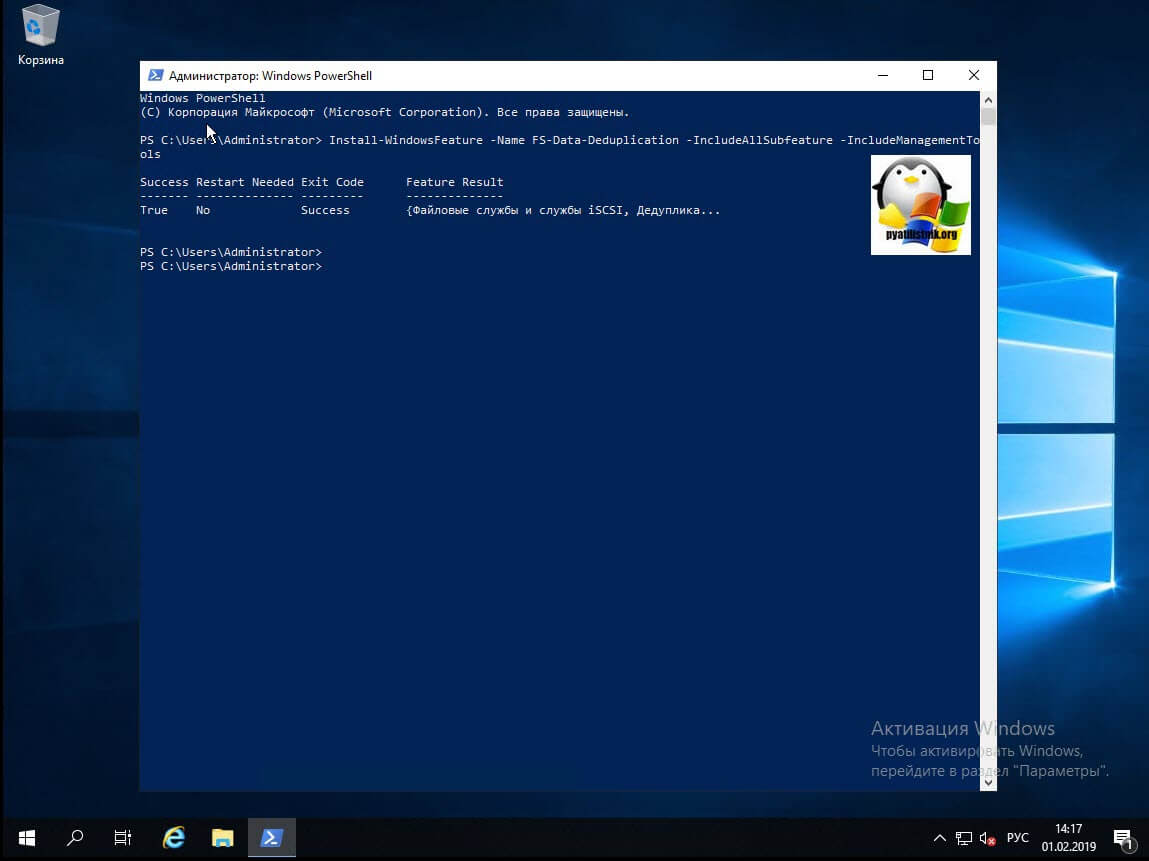
Данный метод куда быстрее, чем графический. Я вам уже подробно рассказывал, о процессе установки ролей и компонентов в Windows Server 2019, тут приведу лишь выдержку из нескольких команд. Открываем оснастку PowerShell и вводим вот такую команду:
У вас появится ползунок с процессом инсталляции.
Буквально в течении секунд 20-30 ваш компонент будет присутствовать в вашей Windows Server 2019.
Установка компонента дедупликации через Windows Admin Center
Открываете ваш браузер и подключаетесь к Windows Admin Center. Переходите в пункт «Роли и компоненты», где ставите галку на против дедупликации и нажимаете установить.
Будет произведен поиск зависимостей, по окончании которого вам нужно нажать»Да».
В области уведомления будет отображаться процесс установки.
Включение и настройка дедупликации из GUI интерфейса
И так компонент мы установили, теперь осталось его включить и настроить под свои нужды. Делать мы это будем разными методами, графическими и из командной строки PowerShell. Как я показывал выше через утилиту Deduplication Data Evaluation Tool вы можете оценить степень дедупликации. Если она вас устраивает, то можно ее применять.Еще один момент, перед процедурой я сделал контрольный замер свободного места на диске D.

Находим пункт «Тома (Volumes)». Напоминаю, что дедупликация может работать только с ними. У меня в примере есть том с буквой E: именно его я и хочу оптимизировать по распределению дискового пространства. Щелкаем по нему правым кликом и из меню выбираем пункт «Настройка дедупликации данных (Configure Data Deduplication)».
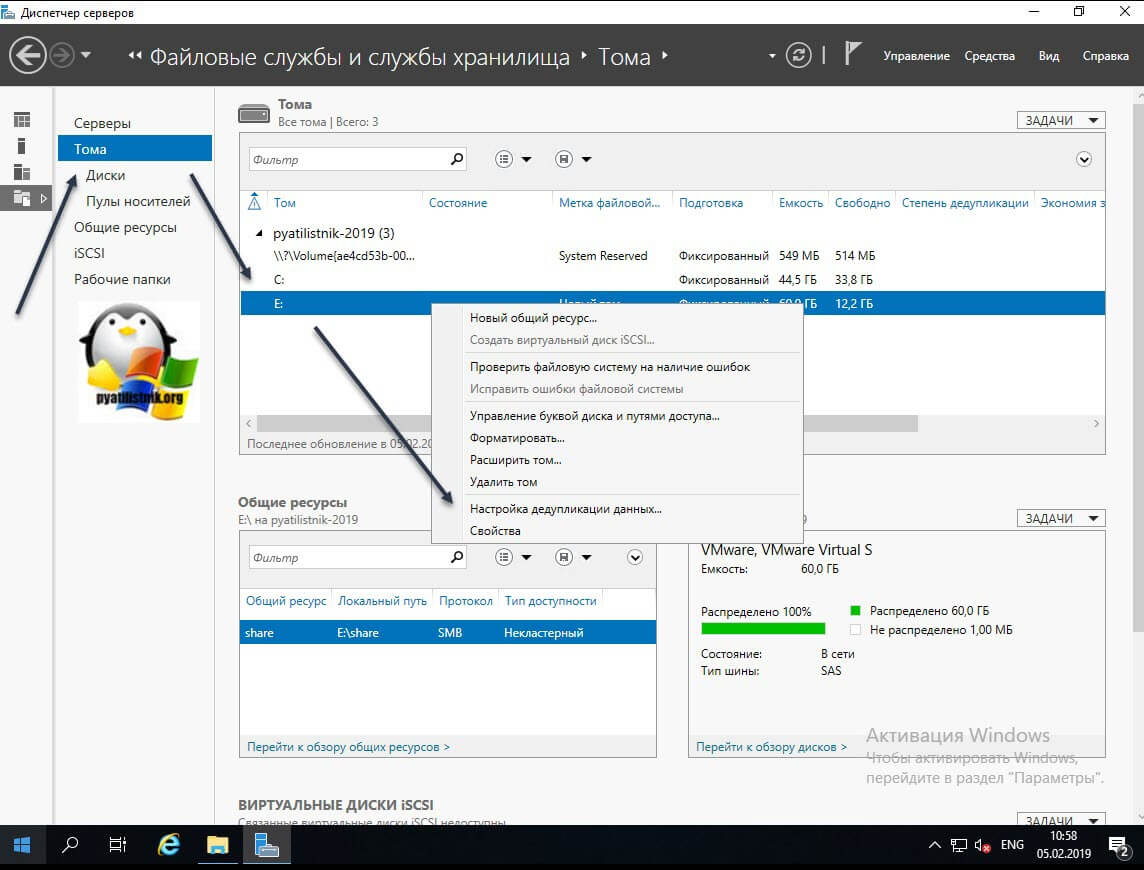
У вас откроется окно «Параметры дедупликации (Deduplication Settings)». По умолчанию дедупликия отключена, в выпадающем окне у вас будет три режима его работы:
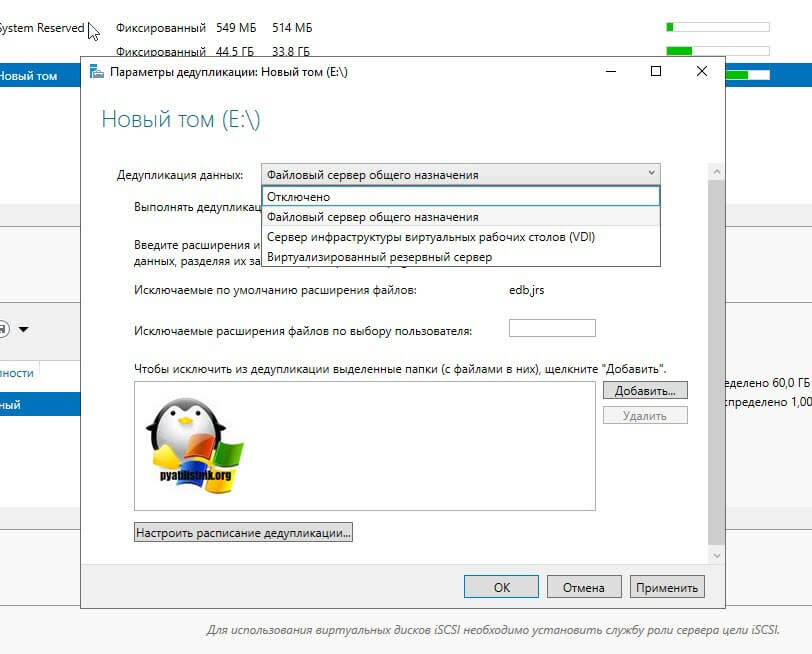
Оставляем выбраным пункт «Файловый сервер общего назначения». Далее вам необходимо определиться с возрастом файлов, которые будут подлежать процессу дедупликации. По умолчанию выставлено значение в 3 дня. Логика в этом есть, это сделано, чтобы отсеять временные файлы, мусорные. Старайтесь не ставить слишком маленькие значения, если у вас очень часто изменяются данные. На практике этого достаточно, но если вам необходимо сделать все сейчас, то установите это значение на единицу.
Далее вы можете определиться с форматами файлов, которые вы не хотели бы дедуплицировать. Тут уже каждый решает для себя сам. Вот вам список самых распространенных форматов файлов, которые вы могли бы исключить.
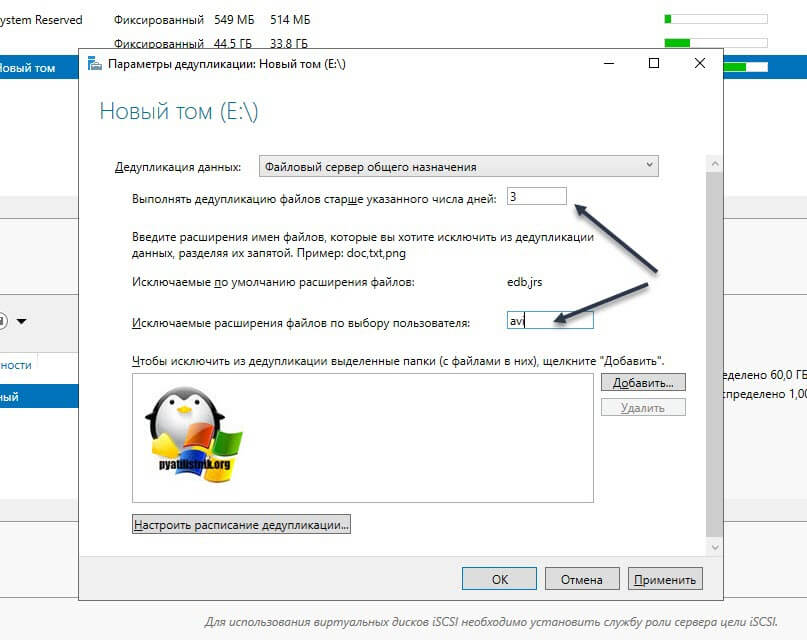
Так же есть возможность исключения нужных вам папок из задания. Для примера я исключу у себя папку с TotalCommander. Для этого нажмите кнопку «Добавить» и используя проводник укажите целевую папку.
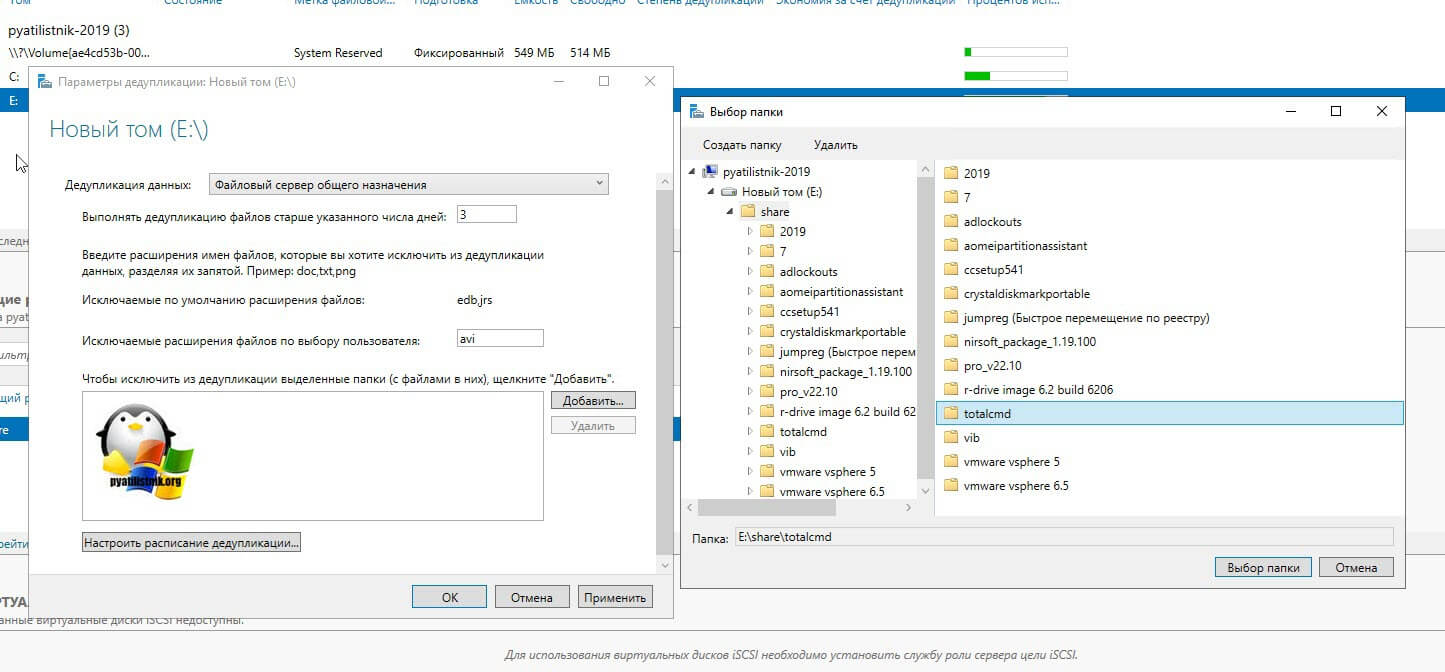
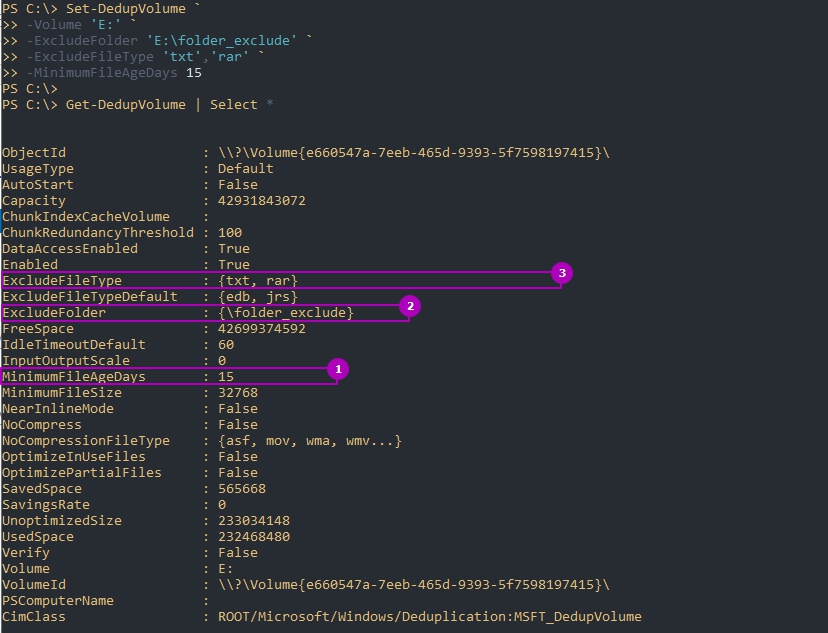
В списке исключения у вас будет выбранная папка. Чуть ниже будет очень полезная настройка, которая позволит вам управлять расписанием. Нажмите кнопку «Настроить расписание дедупликации (Set Deduplication Schedule)»
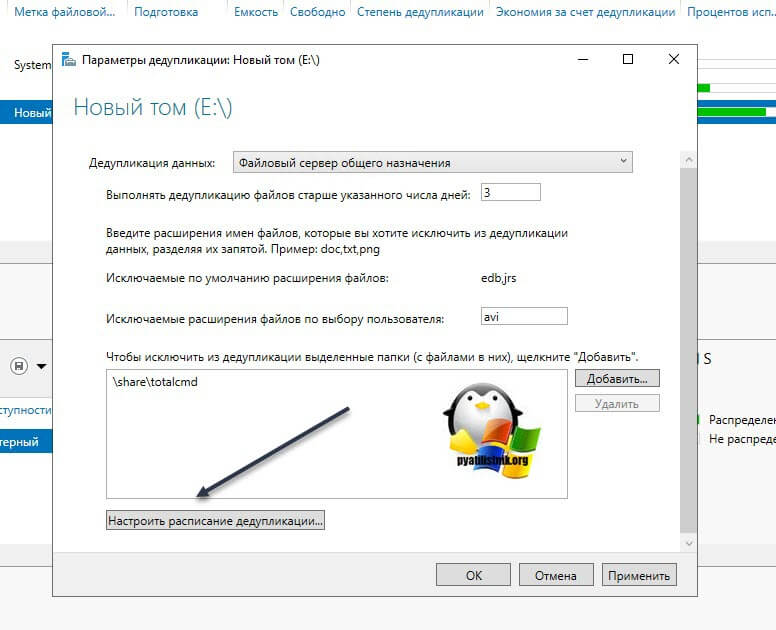
На выбор у вас есть возможность создавать два расписания, которые будут выполняться в фоновом режиме. Включаем галку «Включить фоновую оптимизацию (background optimization)». Далее, чтобы иметь возможность выбирать конкретные дни и время, вам необходимо выставить галку «Включить оптимизацию пропускной способности (Enable throughput optimization)». Первое задание у меня будет запускаться в 23-00 и выполняться до 9 утра. суммарно я на это выделил 10 часов, у вас эти цифры могут отличаться, тут нужно исходить от ваших условий.
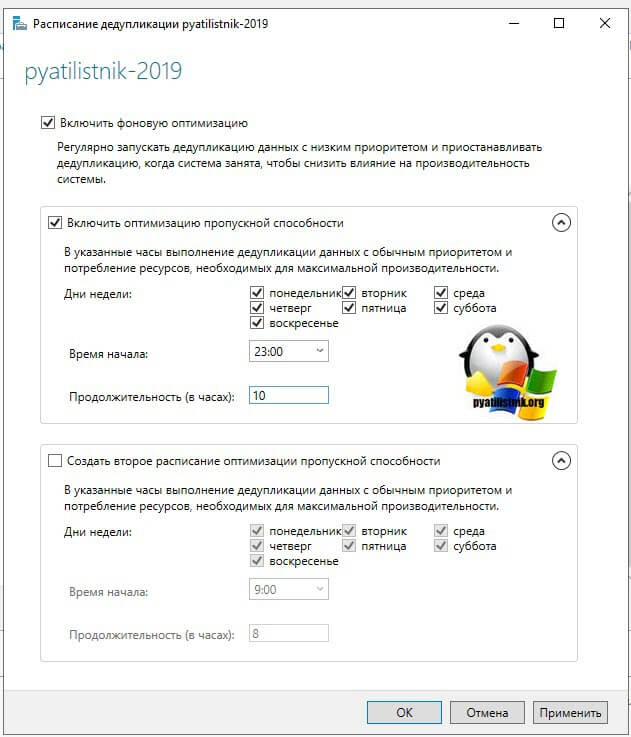
Если вам необходимо запустить процедуру сразу, то тут вам в помощь PowerShell. Откройте оболочку повершела.
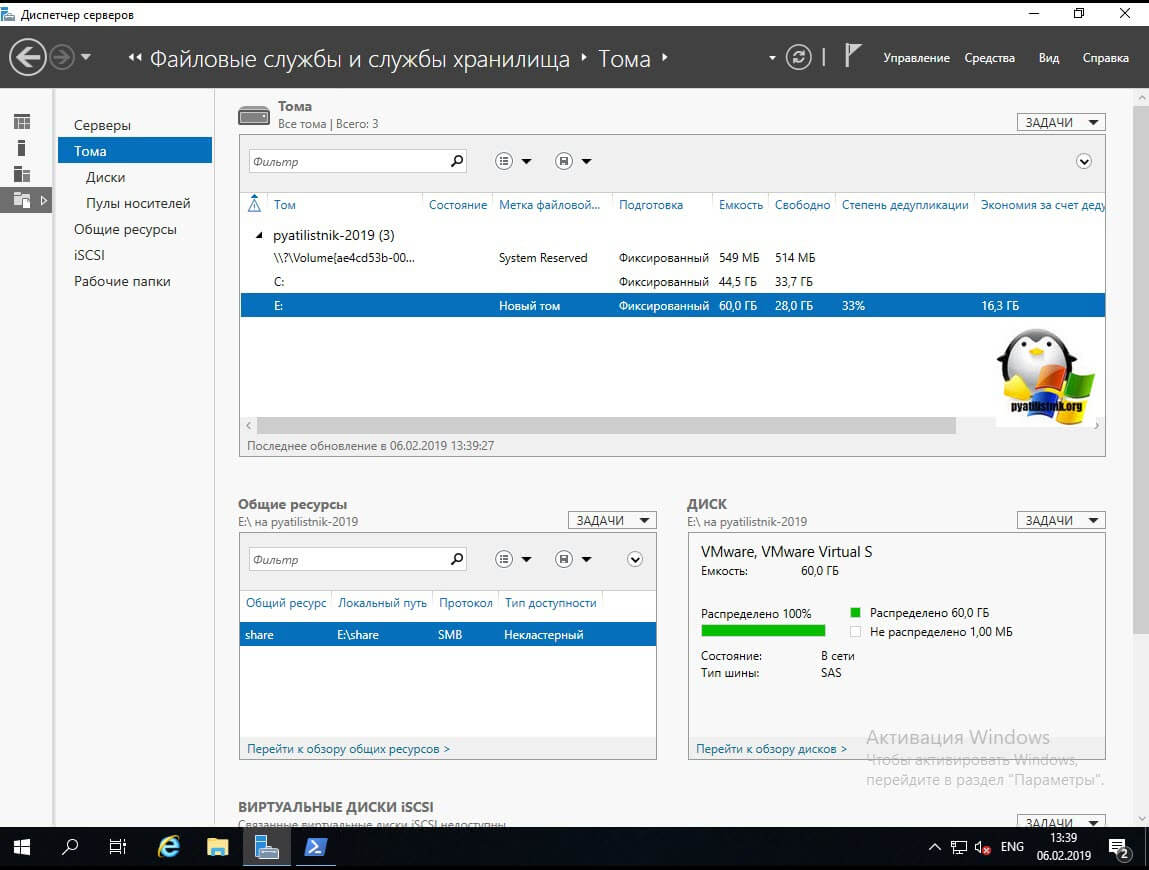
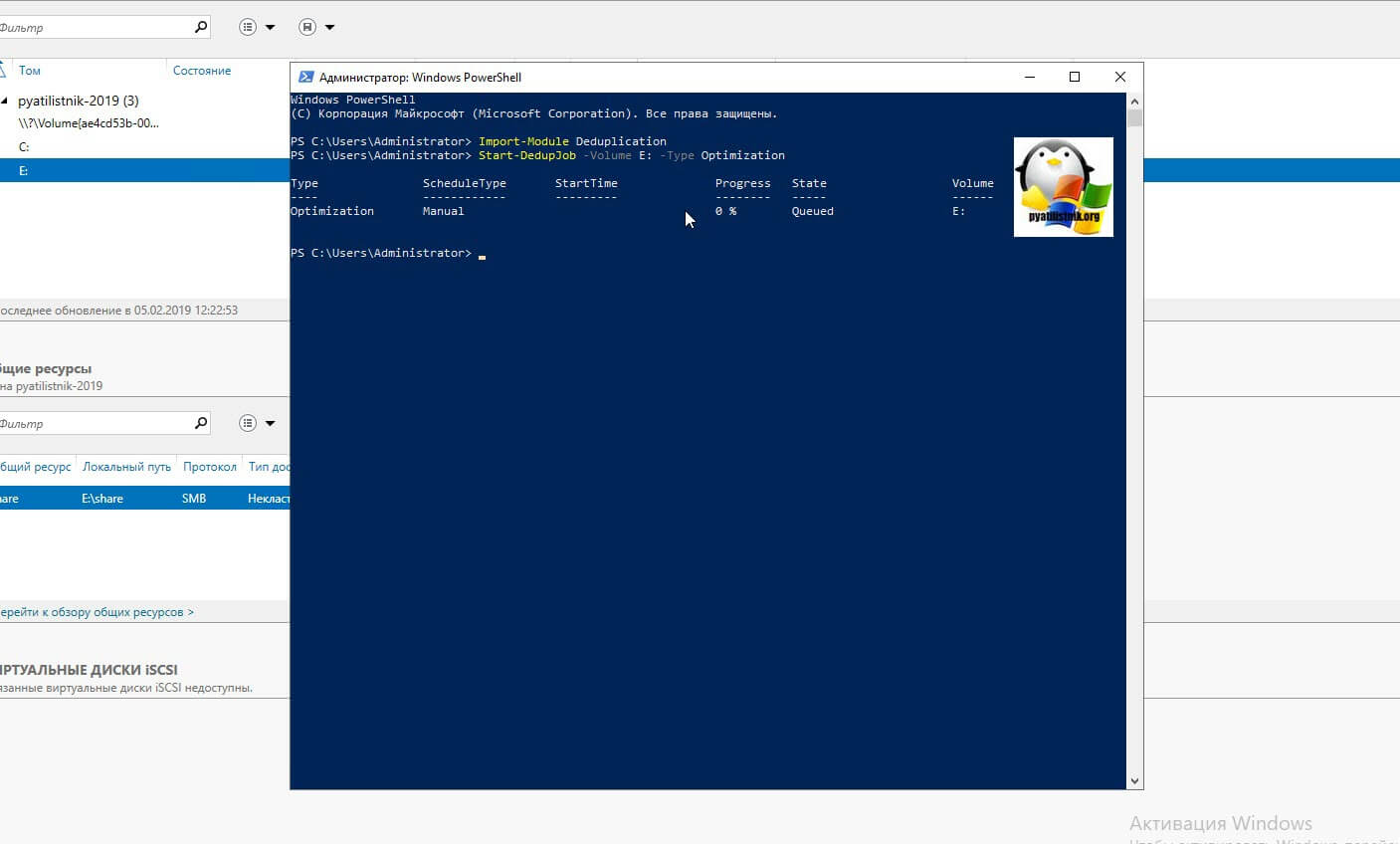 Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:\. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
Первая команда импортирует нужный модуль, который содержит необходимые командлеты, вторая запустит немедленно дедупликацию на томе E:\. Посмотреть статус выполнения хода дедупликации, вы сможете с помощью вот такой команды:
У вас будут столбы, где вы увидите, что тип задания «Manual (Запущенный вручную)», сам прогресс бар в процентах, статус и на каком томе выполняется задание.
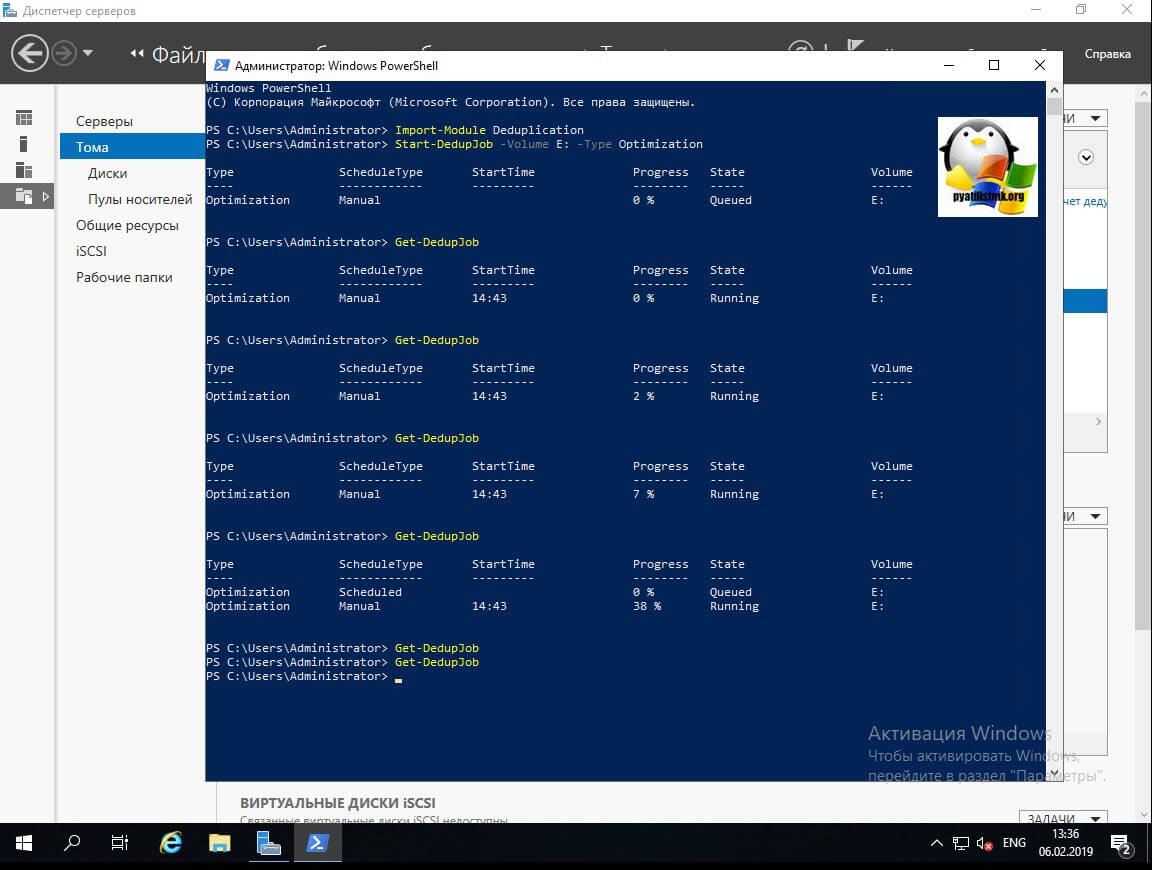
Теперь если посмотреть в оснастке диспетчера серверов степень дедупликации данных, то в моем случая я получил 33%, что весьма прилично.
Включение и настройка дедупликации через PowerShell
Графический метод, это хорошо, но все же большую свободу действий и возможностей нам компания Microsoft предоставляет, через использования сильного языка и его командлетов. Откройте оснастку Powershell. Первым делом импортируем модуль для нужных команд.
Первым делом нужно включить саму дедупликацию и выбрать один из ее типов. Сделать, это можно командой:
В результате на томе E: будет активированная дедупликация со стандартным типом «Файловый сервер общего назначения». Если нужно задать другие типы, то можно воспользоваться ключами:
Если в нужно явно задать режим работы, то сделайте командой:
Так же можно выполнить сразу для нескольких томов в Windows Server 2019:
Так же если у вас нет букв томов и вы знаете только GUID, то его так же можно использовать в командах:
Как отключить дедупликацию Windows
Простая задача, необходимо выключить и затем удалить роль дедупликации в Windows Server 2019. Если вы отключите дедупликацию данных с помощью графического интерфейса или Powershell, это на самом деле не отменит выполненную работу и дедуплицированные данные на текущий момент останутся. Хуже того, если вы отключили сервис, то вы не можете запустить команду очистки мусора (которая очищает данные, созданные с помощью технологии дедупликации).
Поэтому важно, чтобы вы оставили дедупликацию данных включенной, но сначала ИСКЛЮЧИЛИ весь диск. Затем выполните следующие две команды (которые будут выполняться в зависимости от количества имеющихся у вас данных). Первая команда исключает из процесса дедупликации раздел D:

Далее мониторим его статус, пока задание не будет выполнено:
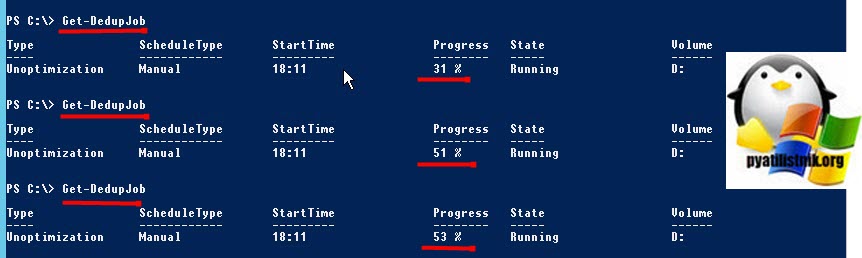
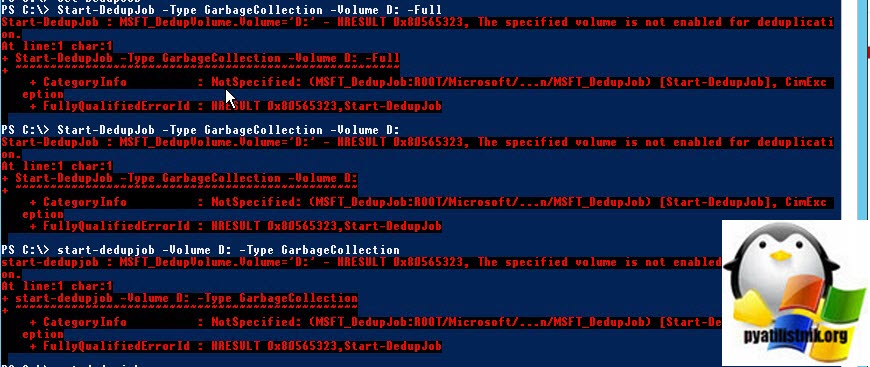
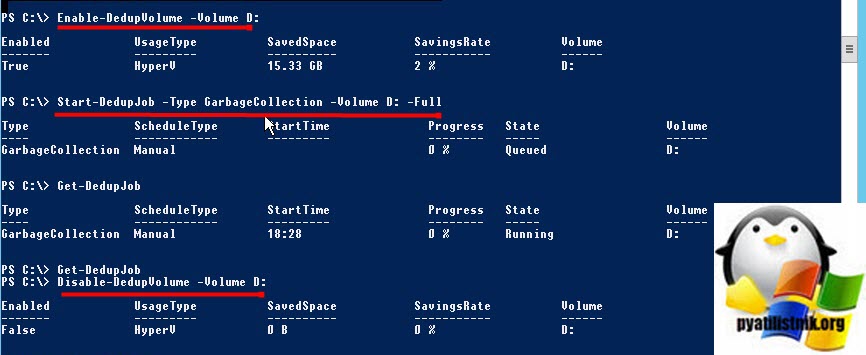
Поскольку задание по сбору мусора еще нужно запустить, нам нужно довольно нелогично включить дедупликацию для тома с помощью следующей команды
В противном случае вы будите получать ошибку:
+ CategoryInfo : NotSpecified: (MSFT_DedupJob:ROOT/Microsoft/. n/MSFT_DedupJob) [Start-DedupJob], CimExc
eption
+ FullyQualifiedErrorId : HRESULT 0x80565323,Start-DedupJob
Как только это будет сделано, следующим шагом будет запуск следующей команды, чтобы запустить сборку мусора на томе
Как настраивается и работает дедупликация данных в Windows Server 2016/2019
Навигация по посту
Для чего нужна и как работает дедупликация
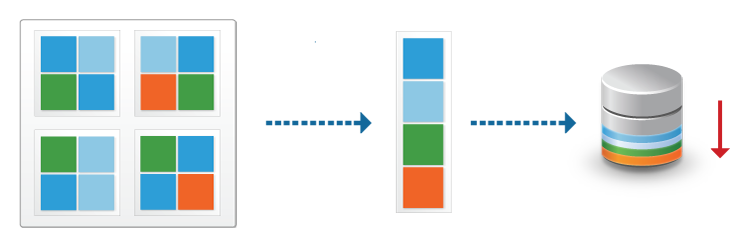
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:
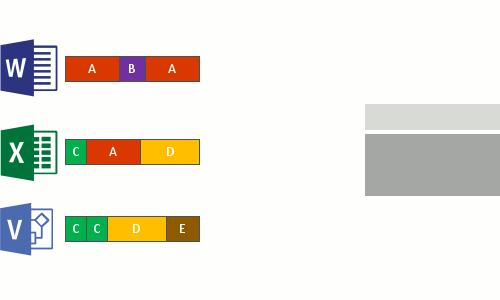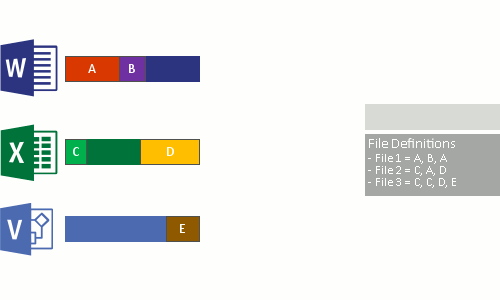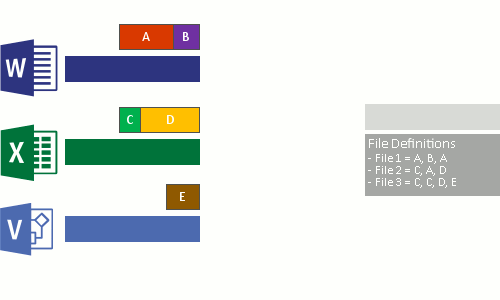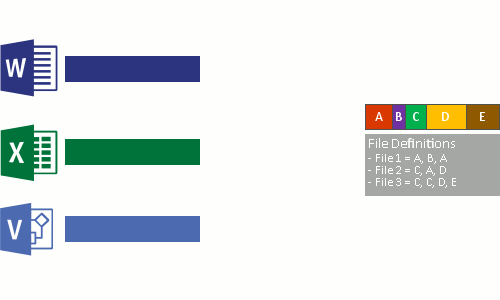
Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
Windows Server 2016
Windows Server 2019
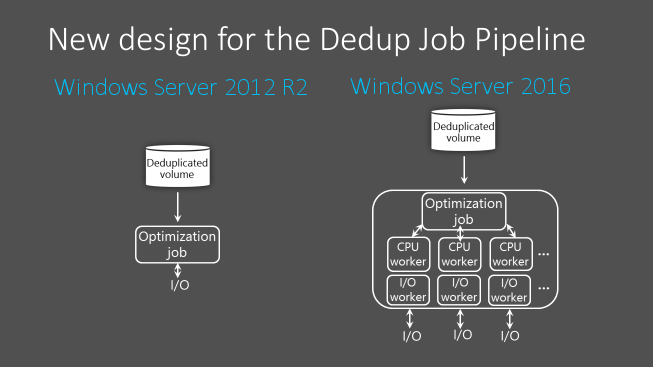
Процесс дедупликации происходит по расписанию, а не «на лету», и из-за этого есть общие рекомендации по размеру разделов. Если разделы будут больше описанных выше, то скорость работы сканирования может быть меньше чем обновление этих файлов. В версии 2016 в процесс дедупликации была добавлена парализация, что позволило увеличить скорость и общий объем работы для работы этой роли:
Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:
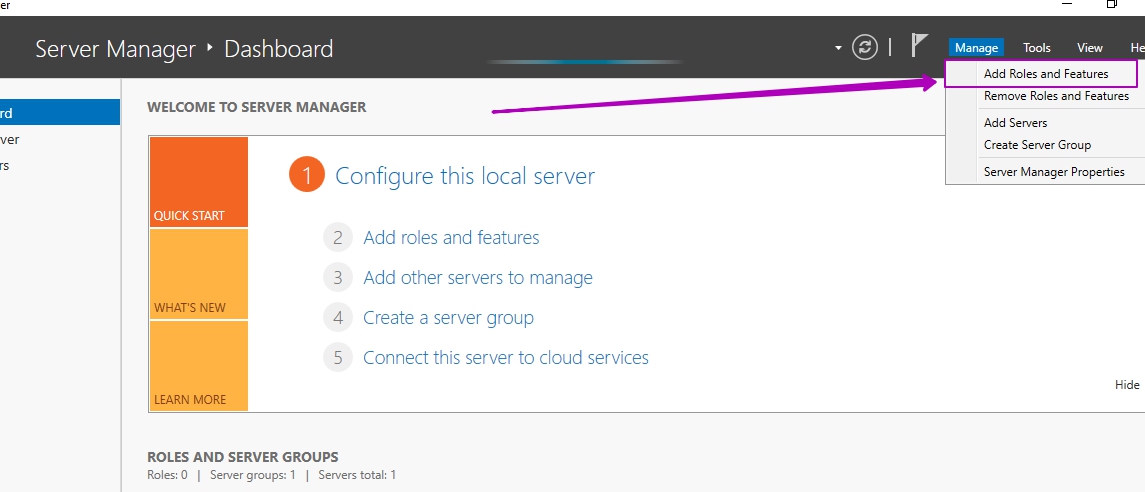
Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):
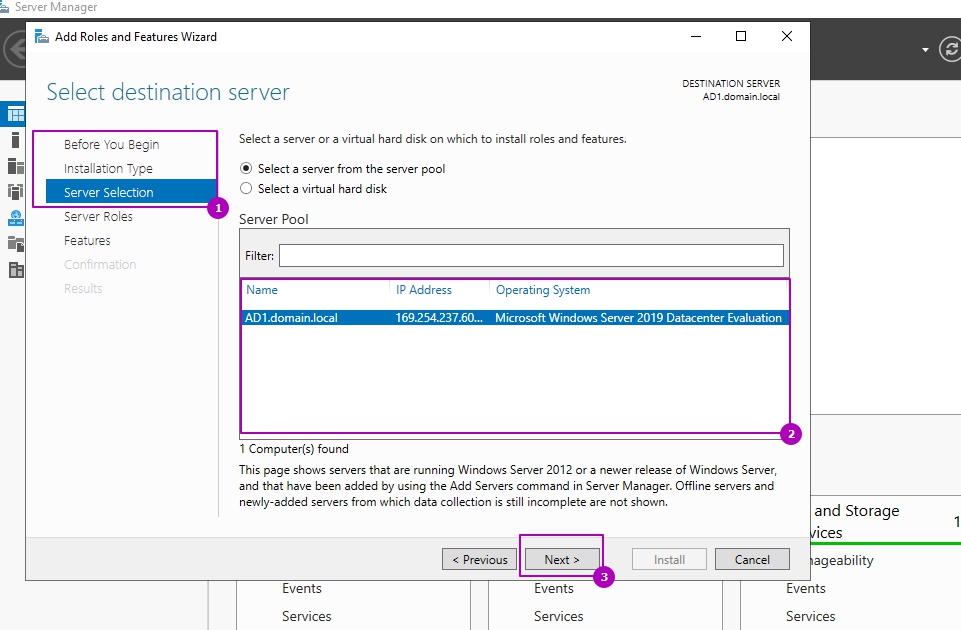
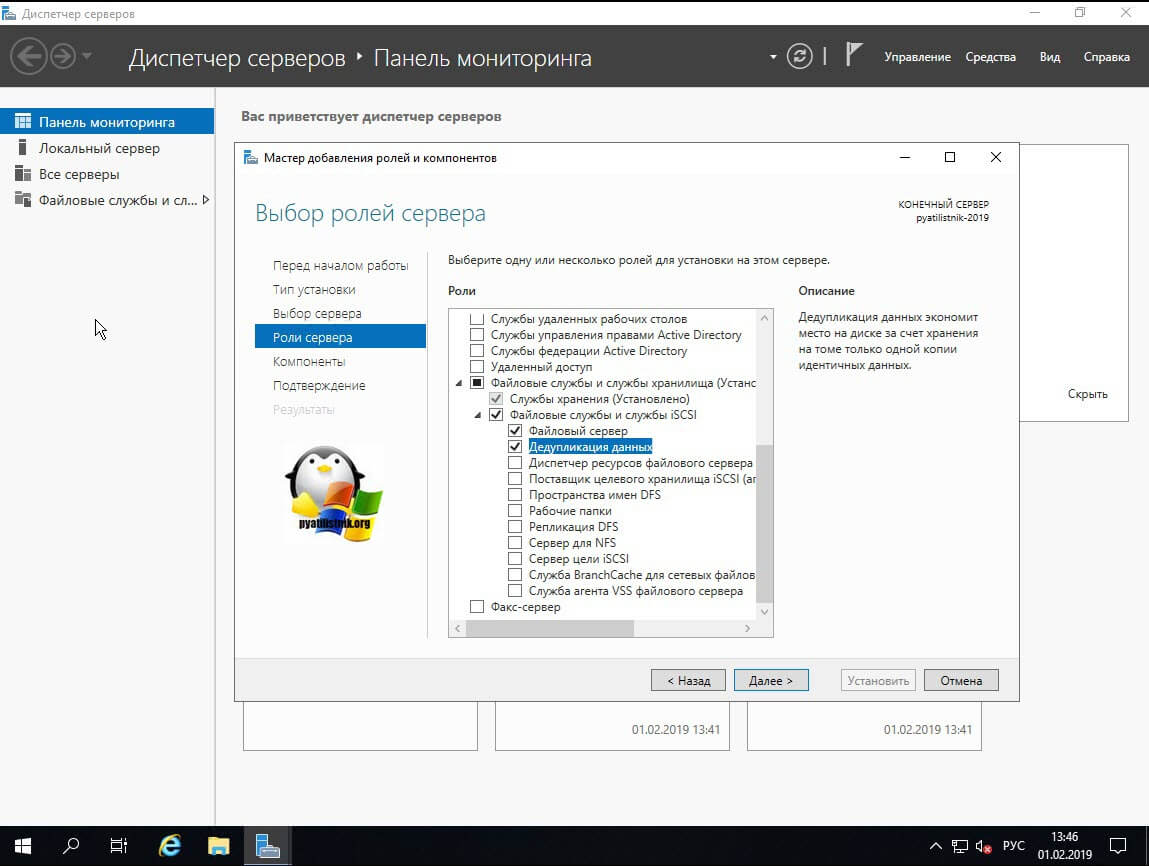
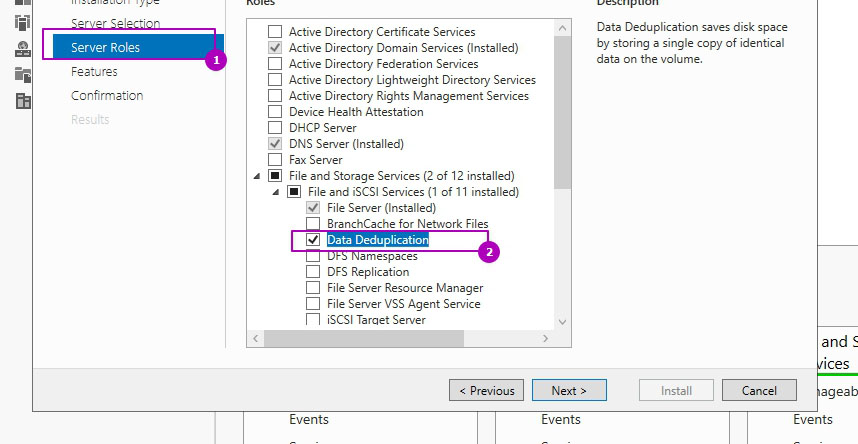
На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:
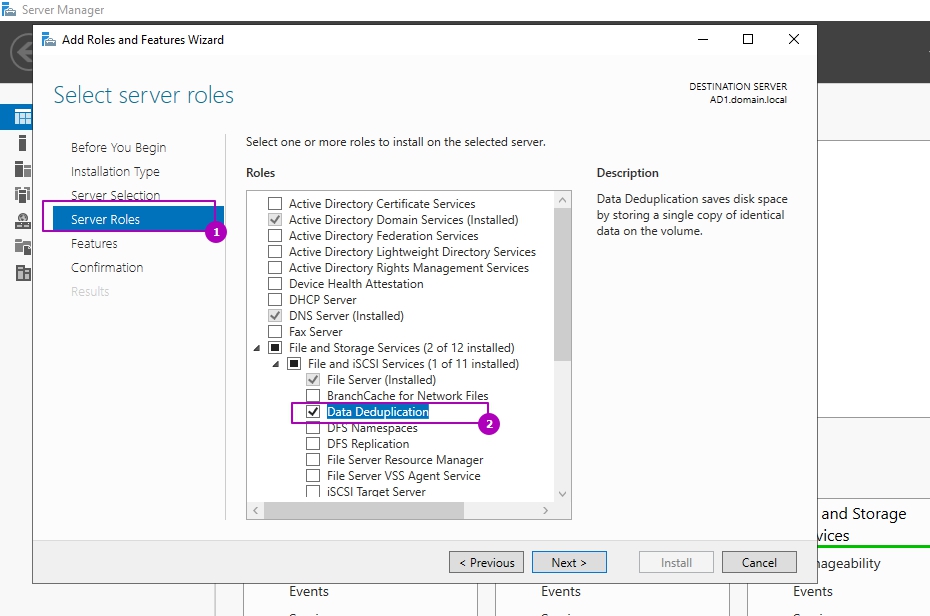
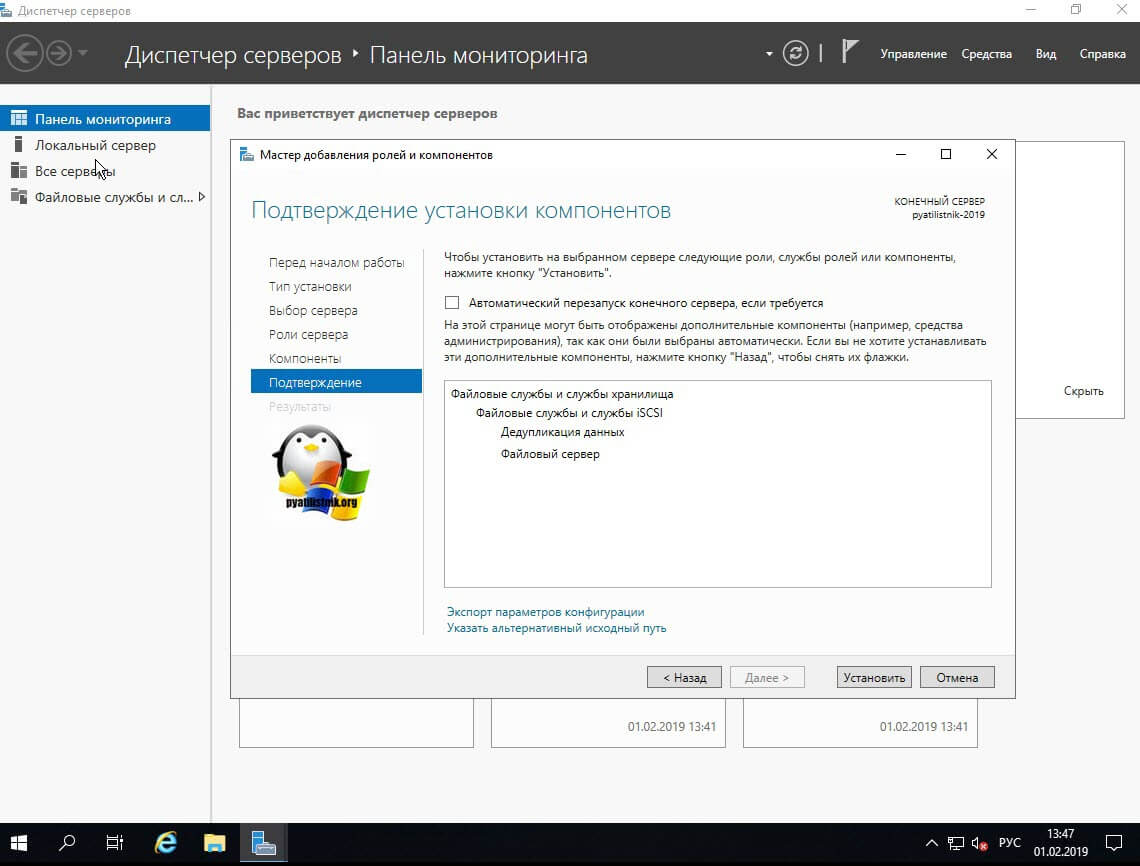
Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:
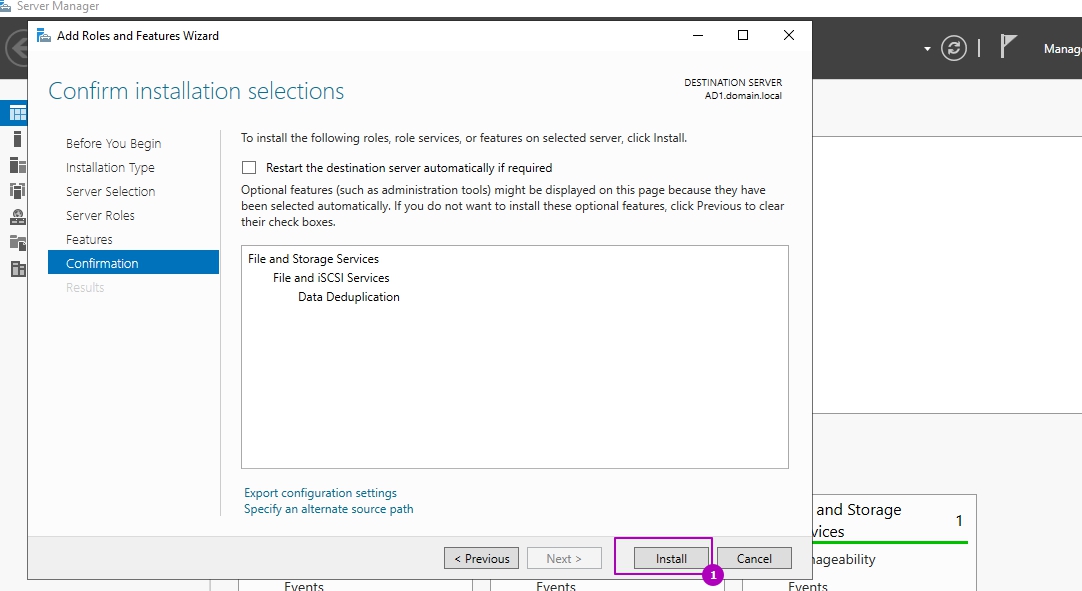
Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:
Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:

Для оценки места я поместил 3 одинаковых установочных архива с Exchange 2013 общим объемом 6 Гб на диск Е.
Открываем Powershell/CMD и пишем команду, которая имеет следующий синтаксис:
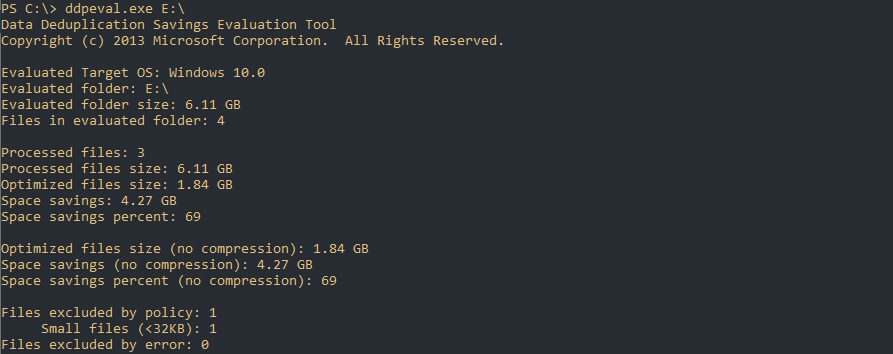
По каким-то причинам у меня определилась Windows 10, хотя я использую Windows Server 2019
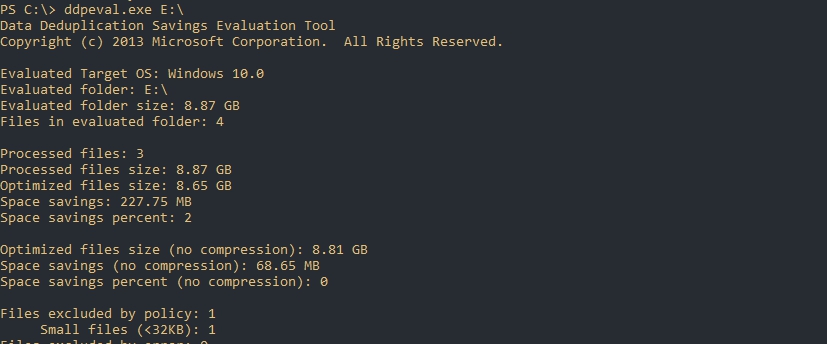
Я удалил файлы с Exchange и поместил 3 разных образа Linux (Ubuntu, Debian, Centos):

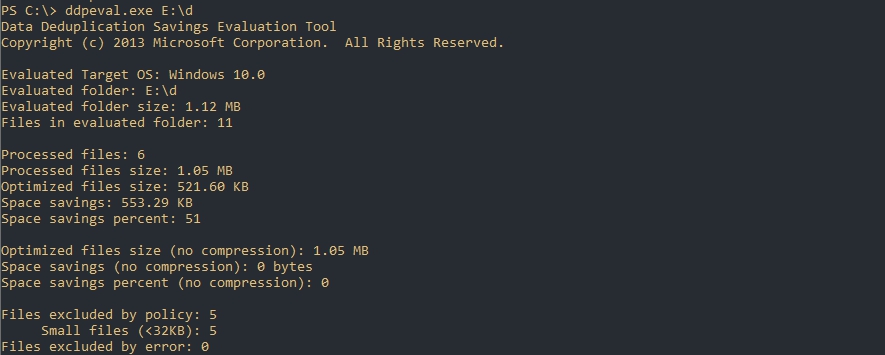
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:
Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:
Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:
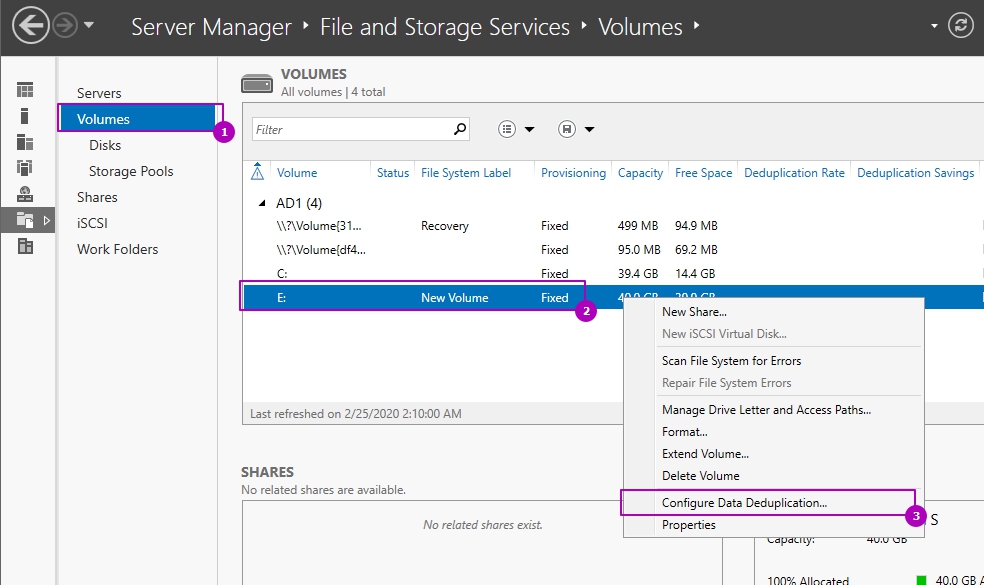
По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:
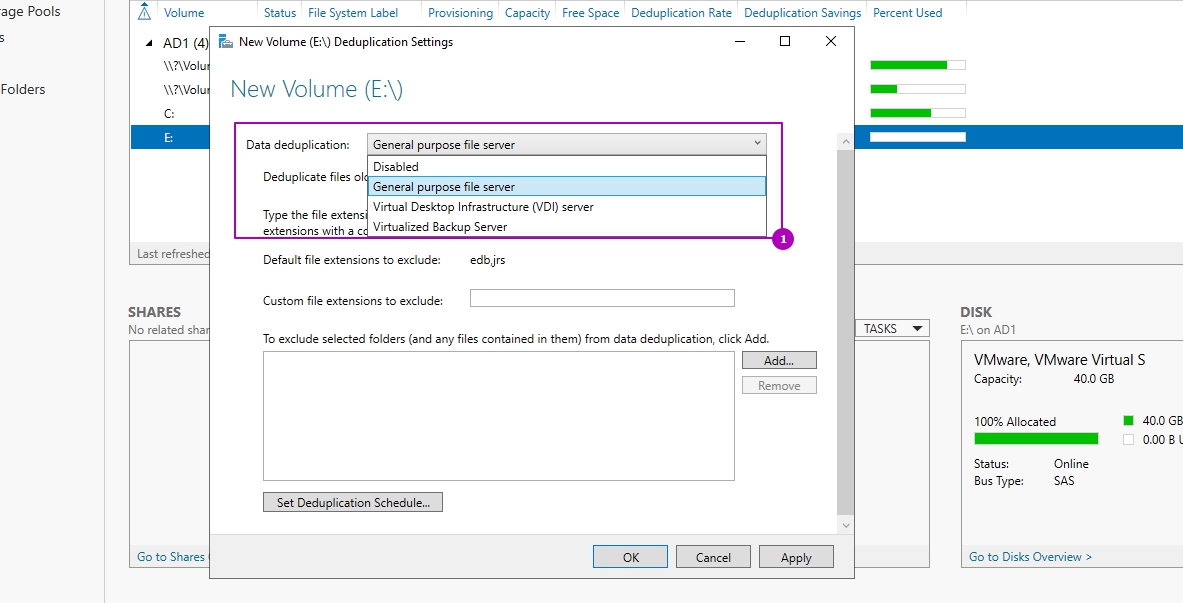
Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.
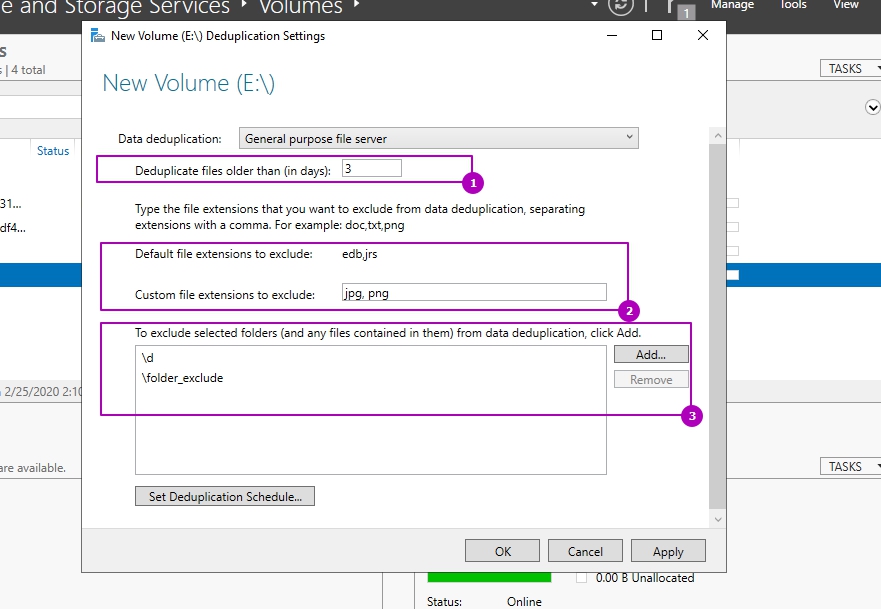
В окне расписания мы можем настроить следующее:
На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Следующим способом мы увидим все команды модуля дедупликации:
Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:

В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:\’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:\’
Так мы узнаем на каких томах настроена дедупликация:

Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
Следующий пример установит эти настройки и вернет их:
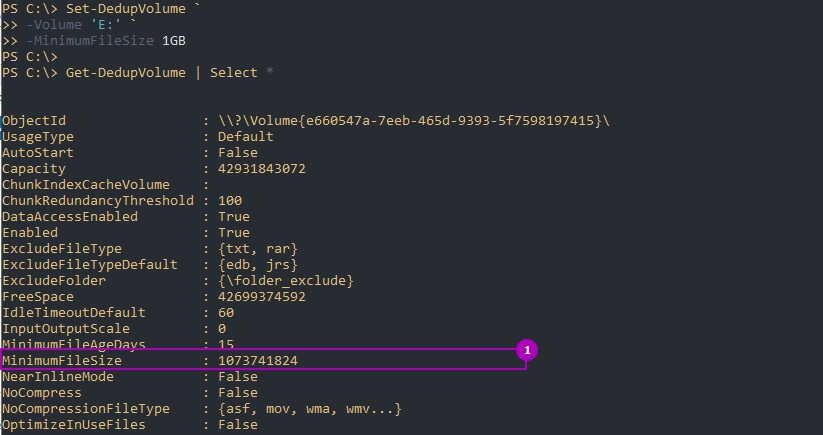
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Есть еще несколько параметров, которые устанавливаются:
Для отключения используется следующая команда:

Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:
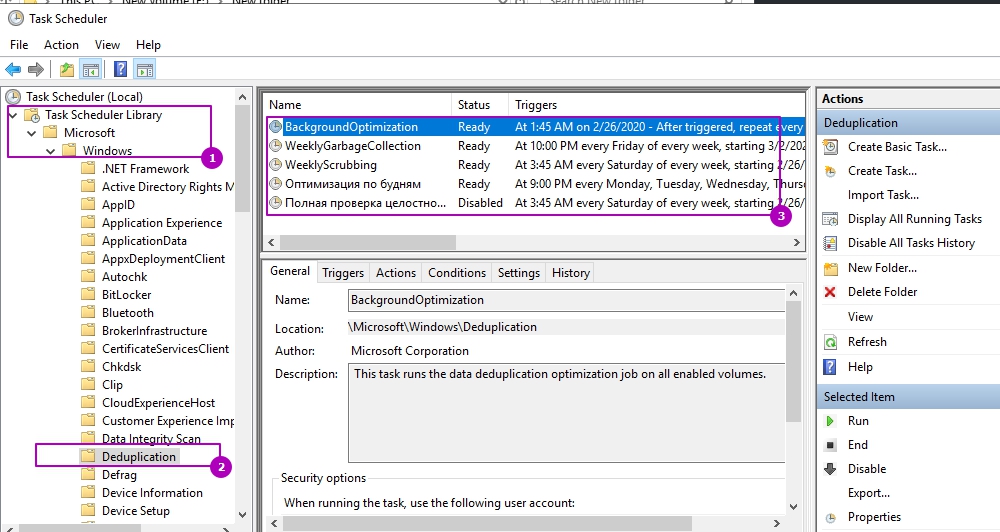
Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:

Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:

Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
На примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
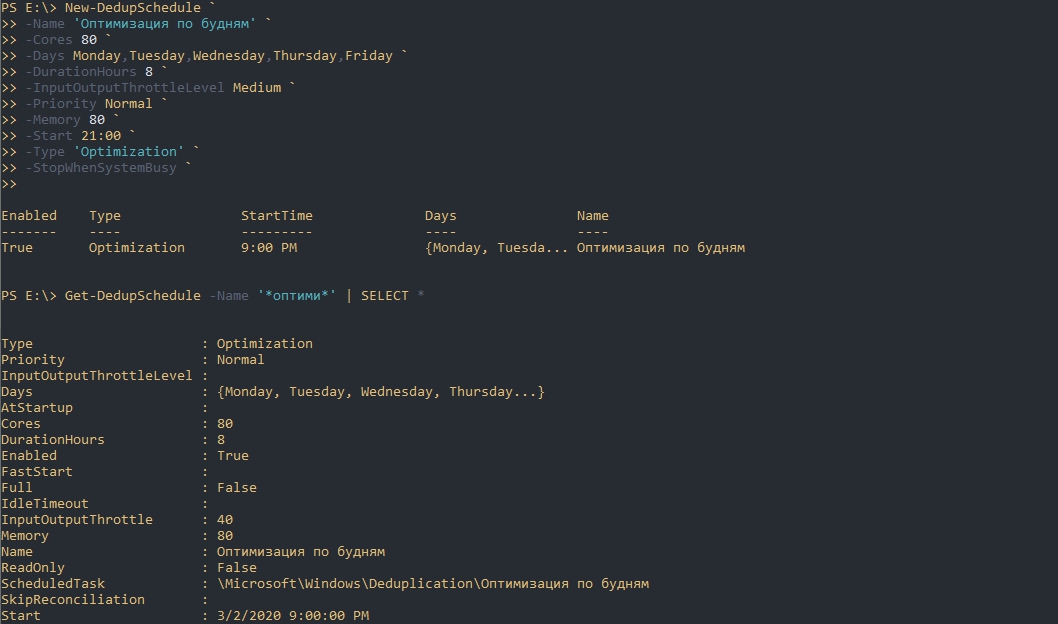
Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
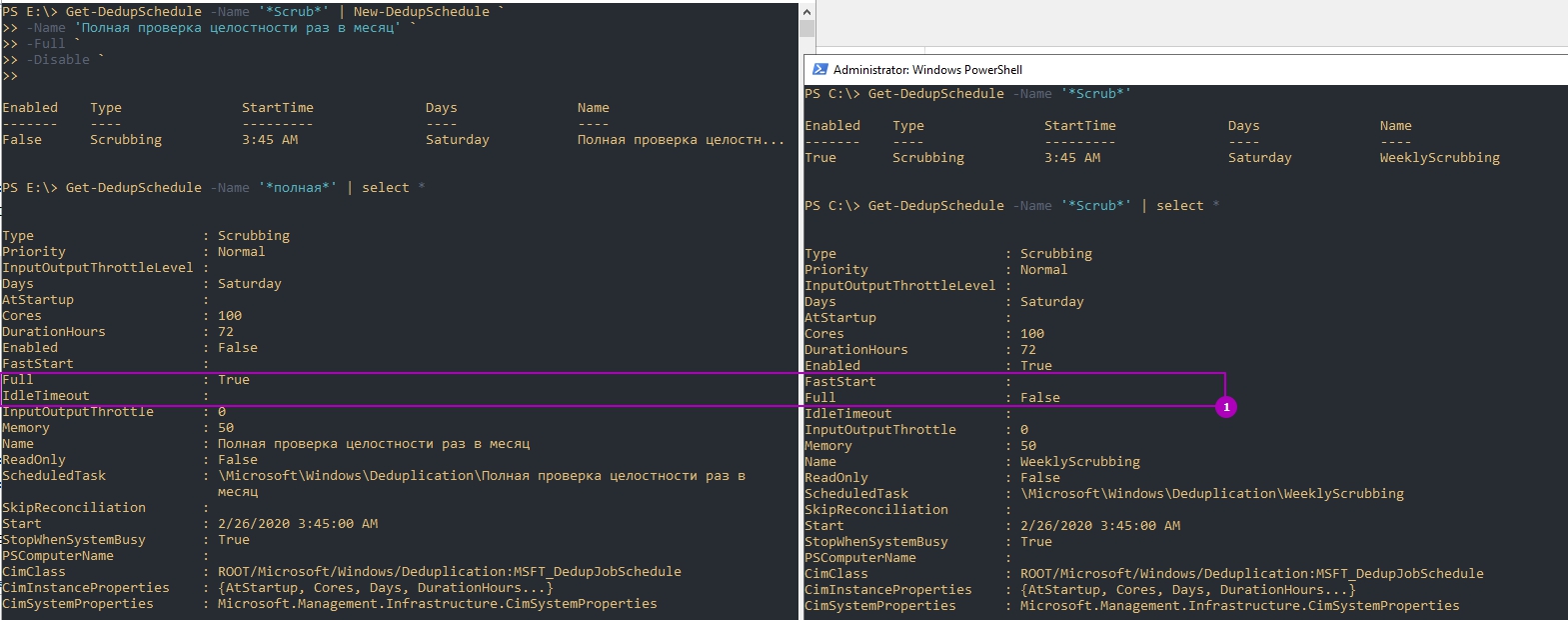
Так же можно и удалять задачи:
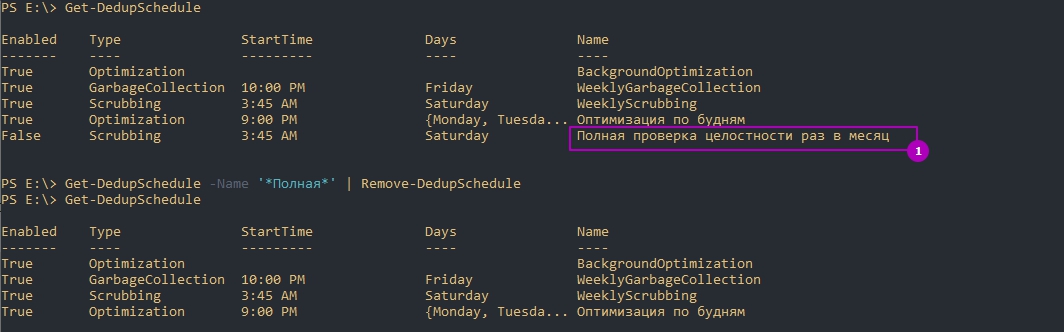
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
Учитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Запуск отдельных задач
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:

Вернуть состояние задачи можно так:

Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:

Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
А эти параметры есть только у Start-DedupSchedule:

Пример отмены задач:
Отмену дедупликации вы так же можете запустить задачей:
Статус дедупликации
Следующая команда вернет текущий статус дедупликации:
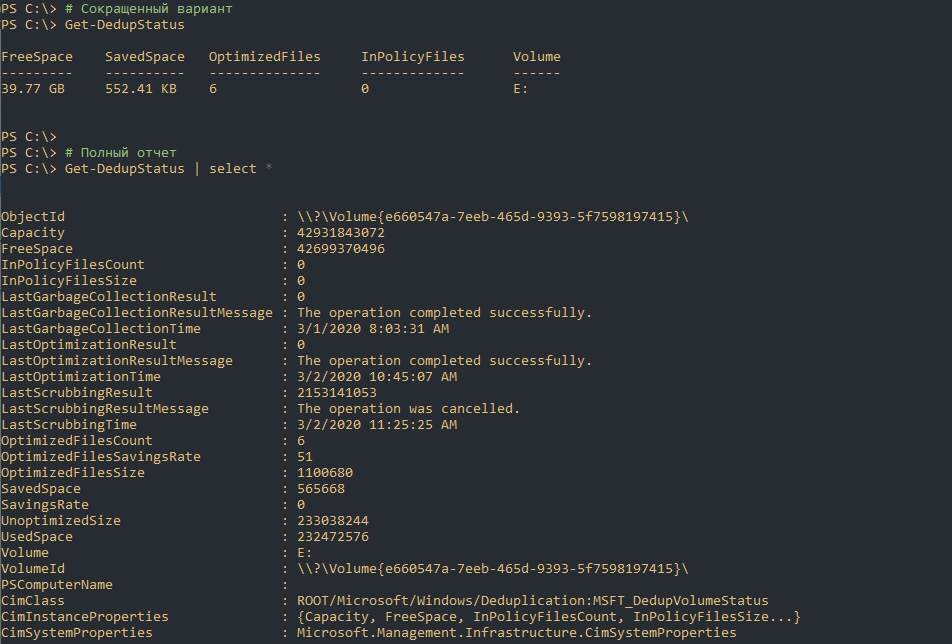
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
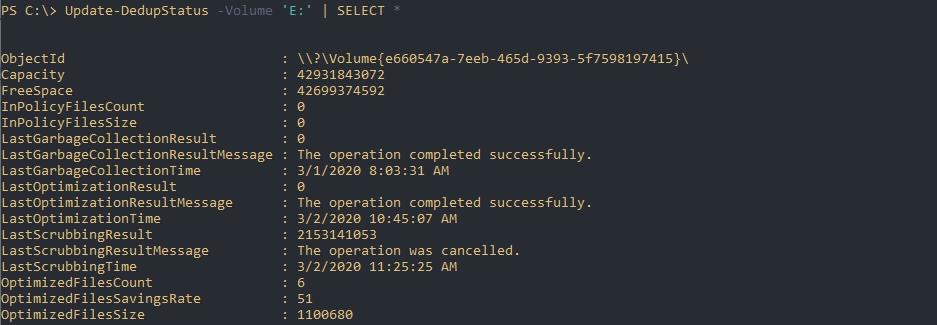
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:

Эта команда вернет информацию по работе с файлами:

Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
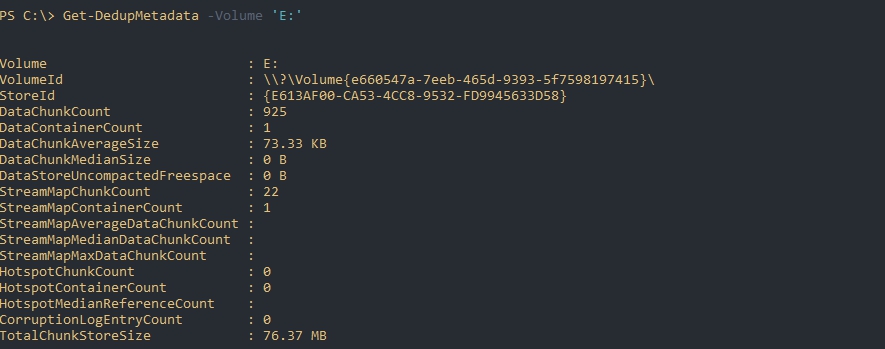
Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
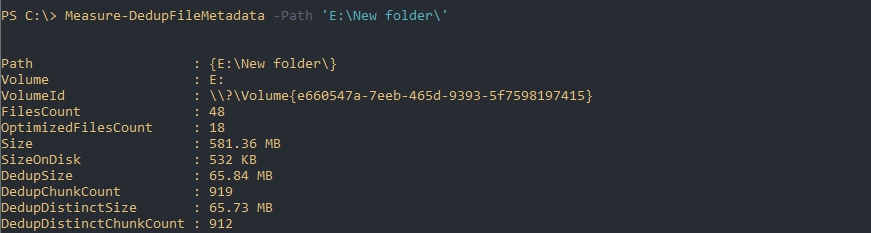
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку: