Код с малой плотностью проверок на чётность
Также называют кодом Галлагера, по имени автора первой работы на тему LDPC-кодов.
Содержание
Предпосылки


При передаче информации её поток разбивается на блоки определённой (чаще всего) длины, которые преобразуются кодером (кодируются) в блоки, называемыми ключевыми словами. Ключевые слова передаются по каналу, возможно с искажениями. На принимающей стороне декодер преобразует ключевые слова в поток информации, исправляя (по возможности) ошибки передачи.
Таким образом, для сравнительно коротких кодовых слов кодеры и декодеры могут просто содержать в памяти все возможные варианты, или даже реализовывать их в виде полупроводниковой схемы. Для большего размера кодового слова эффективнее хранить порождающую и проверочную матрицу. Однако, при длинах блоков в несколько тысяч бит хранение матриц размером, соответственно, в мегабиты, уже становится неэффективным. Одним из способов решения данной проблемы становится использования кодов с малой плотностью проверок на чётность, когда в проверяющей матрице количество единиц сравнительно мало, что позволяет эффективнее организовать процесс хранения матрицы или же напрямую реализовать процесс декодирования с помощью полупроводниковой схемы.
Первой работой на эту тему стала работа Роберта Галлагера «Low-Density Parity-Check Codes» 1963 года [2] (основы которой были заложены в его докторской диссертации 1960 года). В работе учёный описал требования к таким кодам, описал возможные способы построения и способы их оценки. Поэтому часто LDPC-коды называют кодами Галлагера. В русской научной литературе коды также называют низкоплотностными кодами или кодами с малой плотностью проверок на чётность.
LDPC-коды
LDPC-коды описываются низкоплотностой проверочной матрицей, содержащей в основном нули и относительно малое количество единиц. По определению, если каждая строка матрицы содержит ровно  и каждый столбец ровно
и каждый столбец ровно  единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок
единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок  , то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
, то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
Обычно рассматриваются матрицы больших размеров. Например, в работе Галлагера в разделе экспериментальных результатов используются «малые» количества строк n=124, 252, 504 и 1008 строк (число столбцов проверочной матрицы немного больше). На практике применяются матрицы с большим количеством элементов — от 10 до 100 тысяч строк. Однако количество единиц в строке или в столбце остаётся достаточно малым, обычно меньшим 10. Замечено, что коды с тем же количеством элементов на строку или столбец, но с большим размером, обладают лучшими характеристиками.
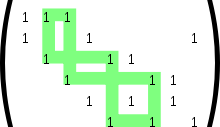
Важной характеристикой матрицы LDPC-кода является отсутствие циклов определённого размера. Под циклом длины 4 понимают образование в проверочной матрице прямоугольника, в углах которого стоят единицы. Отсутствие цикла длины 4 можно также определить через скалярное произведение столбцов (или строк) матрицы. Если каждое попарное скалярное произведение всех столбцов (или строк) матрицы не более 1, это говорит об отсутствии цикла длины 4. Циклы большей длины (6, 8, 10 и т. д.) можно определить, если в проверочной матрице построить граф, вершинами которого являются единицы, а рёбра — все возможные соединения вершин, параллельные сторонам матрицы (то есть вертикальные или горизонтальные линии). Минимальный цикл в этом графе и будет минимальным циклом в проверочной матрице LDPC-кода. Очевидно, что цикл будет иметь длину как минимум 4, а не 3, так как рёбра графа должны быть параллельны сторонам матрицы. Вообще, любой цикл в этом графе будет иметь чётную длину, минимальный размер 4, а максимальный размер обычно не играет роли (хотя, очевидно, он не более, чем количество узлов в графе, то есть n×k).
Описание LPDC-кода возможно несколькими способами:
Последний способ является условным обозначением группы представлений кодов, которые построены по заданным правилам-алгоритмам, таким, что для повторного воспроизведения кода достаточно знать лишь инициализирующие параметры алгоритма, и, разумеется, сам алгоритм построения. Однако данный способ не является универсальным и не может описать все возможные LDPC-коды.
Способ задания кода проверочной матрицей является общепринятым для линейных кодов, когда каждая строка матрицы является элементом некоторого множества кодовых слов. Если все строки линейно-независимы, строки матрицы могут рассматриваться как базис множества всех кодовых векторов кода. Однако использование данного способа создаёт сложности для представления матрицы в памяти кодера — необходимо хранить все строки или столбцы матрицы в виде набора двоичных векторов, из-за чего размер матрицы становится равен  бит.
бит.
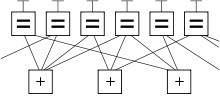
Распространённым графическим способом является представление кода в виде двудольного графа. Сопоставим все  строк матрицы нижним вершинам графа, а
строк матрицы нижним вершинам графа, а  столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
К другим графическим способам относят преобразования двудольного графа, происходящие без фактического изменения самого кода. Например, можно все верхние вершины графа представить в виде треугольников, а все нижние — в виде квадратов, после чего расположить рёбра и вершины графа на двухмерной поверхности в порядке, удобном для визуального понимания структуры кода. Например, такое представление используется в качестве иллюстраций в книгах Девида Маккея.
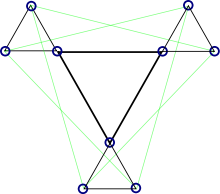
Вводя дополнительные правила графического отображения и построения LDPC-кода, можно добиться, что в процессе построения код получит определённые свойства. Например, если использовать граф, вершинами которого являются только столбцы проверочной матрицы, а строки изображаются многогранниками, построенными на вершинах графа, то следование правилу «два многогранника не разделяют одно ребро» позволяет избавиться от циклов длины 4.
При использовании специальных процедур построения кода могут использоваться и свои способы представления, хранения и обработки (кодирования и декодирования).
Построение кода
В настоящее время используются два принципа построения проверочной матрицы кода. Первый основан на генерации начальной проверочной матрицы с помощью псевдослучайного генератора. Коды, полученные таким способом называют случайными (англ. random-like codes ). Второй — использование специальных методов, основанных, например, на группах и конечных полях. Коды, полученные этими способами называют структурированными. Лучшие результаты по исправлению ошибок показывают именно случайные коды, однако структурированные коды позволяют использовать методы оптимизации процедур хранения, кодирования и декодирования, а также получать коды с более предсказуемыми характеристиками.
В своей работе Галлагер предпочёл с помощью генератора псевдослучайных чисел создать начальную проверочную матрицу небольшого размера с заданными характеристиками, а далее увеличить её размер, дублируя матрицу и используя метод перемешивания строк и столбцов для избавления от циклов определённой длины.
В 2007 году в журнале «IEEE Transactions on Information Threory» была опубликована статья об использовании конечных полей для построения квази-цикличных LDPC-кодов для каналов с аддитивным белым Гауссовым шумом и двоичных каналов со стиранием.
Декодирование
Как и для любого другого линейного кода, для декодирования используется свойство ортогональности порождающей и транспонированной проверочной матриц:

где  — порождающая матрица, и
— порождающая матрица, и  — проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
— проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
 ,
,
а для принятого кодового слова с ошибкой:
 ,
,
Рассмотрим [7] симметричный канал без памяти со входом  и аддитивным гауссовым шумом
и аддитивным гауссовым шумом  . Для принятого кодового слова
. Для принятого кодового слова  нужно найти соответствующий наиболее вероятный вектор
нужно найти соответствующий наиболее вероятный вектор  , такой что
, такой что
Данные значения используются воссоздания вектора x. Если полученный вектор удовлетворяет  , то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
, то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
Код с малой плотностью проверок на четность
Также называют кодом Галлагера, по имени автора первой работы на тему LDPC-кодов.
Содержание
Предпосылки

При передаче информации её поток разбивается на блоки определённой (чаще всего) длины, которые преобразуются кодером (кодируются) в блоки, называемыми ключевыми словами. Ключевые слова передаются по каналу, возможно с искажениями. На принимающей стороне декодер преобразует ключевые слова в поток информации, исправляя (по возможности) ошибки передачи.
Таким образом, для сравнительно коротких кодовых слов кодеры и декодеры могут просто содержать в памяти все возможные варианты, или даже реализовывать их в виде полупроводниковой схемы. Для большего размера кодового слова эффективнее хранить порождающую и проверочную матрицу. Однако, при длинах блоков в несколько тысяч бит хранение матриц размером, соответственно, в мегабиты, уже становится неэффективным. Одним из способов решения данной проблемы становится использования кодов с малой плотностью проверок на чётность, когда в проверяющей матрице количество единиц сравнительно мало, что позволяет эффективнее организовать процесс хранения матрицы или же напрямую реализовать процесс декодирования с помощью полупроводниковой схемы.
Первой работой на эту тему стала работа Роберта Галлагера «Low-Density Parity-Check Codes» 1963 года [2] (основы которой были заложены в его докторской диссертации 1960 года). В работе учёный описал требования к таким кодам, описал возможные способы построения и способы их оценки. Поэтому часто LDPC-коды назвают кодами Галлагера. В русской научной литературе коды также называют низкоплотностными кодами или кодами с малой плотностью проверок на чётность.
LDPC-коды
LDPC-коды описываются низкоплотностой проверочной матрицей, содержащей в основном нули и относительно малое количество единиц. По определению, если каждая строка матрицы содержит ровно k и каждый столбец ровно j единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок 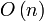 , то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
, то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
Обычно рассматриваются матрицы больших размеров. Например, в работе Галлагера в разделе экспериментальных результатов используются «малые» количества строк n=124, 252, 504 и 1008 строк (число столбцов проверочной матрицы немного больше). На практике применяются матрицы с большим количеством элементов — от 10 до 100 тысяч строк. Однако количество единиц в строке или в столбце остаётся достаточно малым, обычно меньшим 10. Замечено, что коды с тем же количество элементов на строку или столбец, но с большим размером, обладают лучшими характеристиками.
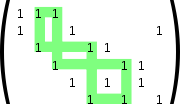
Важной характеристикой матрицы LDPC-кода является отсутсвие циклов определённого размера. Под циклом длины 4 понимают образование в проверочной матрице прямоугольника, в углах которого стоят единицы. Отсутствие цикла длины 4 можно также определить через скалярное произведение столбцов (или строк) матрицы. Если каждое попарное скалярное произведение всех столбцов (или строк) матрицы не более 1, это говорит об отсутствии цикла длины 4. Циклы большей длины (6, 8, 10 и т. д.) можно определить, если в проверочной матрице построить граф, вершинами которого являются единицы, а рёбра — все возможные соединения вершин, параллельные сторонам матрицы (то есть вертикальные или горизонтальные линии). Минимальный цикл в этом графе и будет минимальным циклом в проверочной матрице LDPC-кода. Очевидно, что цикл будет иметь длину как минимум 4, а не 3, так как рёбра графа должны быть параллельны стронами матрицы. Вообще, любой цикл в этом графе будет иметь чётную длину, минимальный размер 4, а максимальный размер обычно не играет роли (хотя, очевидно, он не более, чем количество узлов в графе, то есть n×k).
Описание LPDC-кода возможно несколькими способами:
Последний способ является условным обозначением группы представлений кодов, которые построены по заданным правилам-алгоритмам, таким, что для повторного воспроизведения кода достаточно знать лишь инициализирующие параметры алгоритма, и, разумеется, сам алгоритм построения. Однако данный способ не является универсальным и не может описать все возможные LDPC-коды.
Способ задания кода проверочной матрицей является общепринятым для линейных кодов, когда каждая строка матрицы является элементом некоторого множества кодовых слов. Если все строки линейно-независимы, строки матрицы могут рассматриваться как базис множества всех кодовых векторов кода. Однако использование данного способа создаёт сложности для преставления матрицы в памяти кодера — необходимо хранить все строки или столбцы матрицы в виде набора двоичных векторов, из-за чего размер матрицы становится равен 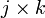 бит.
бит.
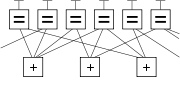
Распространённым графическим способом является представление кода в виде двудольного графа. Сопоставим все k строк матрицы k нижним вершинам графа, а n столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
К другим графическим способам относят преобразования двудольного графа, происходящие без фактического изменения самого кода. Например, можно все верхние вершины графа представить в виде треугольников, а все нижние — в виде квадратов, после чего расположить рёбра и вершины графа на двухмерной поверхности в порядке, удобном для визуального понимания структуры кода. Например, такое представление испольуется в качестве иллюстраций в книгах Девида Маккея.
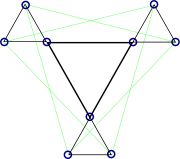
Вводя дополнительные правила графического отображения и построения LDPC-кода, можно добиться, что в процессе построения код получит определённые свойства. Например, если использовать граф, вершинами которого являются только столбцы проверочной матрицы, а строки изображаются многогранниками, построенными на вершинах графа, то следование правилу «два многогранника не разделяют одно ребро» позволяет избавиться от циклов длины 4.
При использовании специальных процедур построения кода могут использоваться и свои способы представления, хранения и обработки (кодирования и декодирования).
Построение кода
В настоящее время используются два принципа построения проверочной матрицы кода. Первый основан на генерации начальной проверочной матрицы с помощью псевдослучайного генератора. Коды, полученные таким способом называют случайными (англ. random-like codes ). Второй — использование специальных методов, основанных, например, на группах и конечных полях. Коды, полученные этими способами называют структурированными. Лучшие результаты по исправлению ошибок показывают именно случайные коды, однако структурированные коды позволяют использовать методы оптимизации процедур хранения, кодирования и декодирования, а также получать коды с более предсказуемыми характеристиками.
В своей работе Галлагер предпочёл с помощью генератора псевдослучайных чисел создать начальную проверочную матрицу небольшого размера с заданными характеристиками, а далее увеличить её размер, дублируя матрицу и используя метод перемешивания строк и столбцов для избавления от циклов определённой длины.
В 2007 году в журнале «IEEE Transactions on Information Threory» была опубликована статья об использовании конечных полей для построения квази-цикличных LDPC-кодов для каналов с аддитивным белым Гауссовым шумом и двоичных каналов со стиранием.
Декодирование
Как и для любого другого линейного кода, для декодирования используется свойство ортогональности порождающей и транспонированной проверочной матриц:
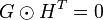
где G — порождающая матрица, и H — проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
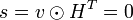 ,
,
а для принятого кодового слова с ошибкой:
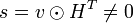 ,
,
Данные значения используются воссоздания вектора x. Если полученный вектор удовлетворяет 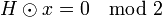 , то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжаеся до некоторого шага (например, 100), то он прерывается и блок объявлявляется принятым с ошибкой.
, то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжаеся до некоторого шага (например, 100), то он прерывается и блок объявлявляется принятым с ошибкой.
Все, что вы хотели узнать об LDPC кодах, но стеснялись спросить (наверное)

Предисловие
С кодами малой плотности проверок на чётность, которые дальше мы будем именовать коротко LDPC (Low-density parity-check codes), мне удалось познакомиться более или менее близко, работая над семестровым научным проектом в ТУ Ильменау (магистерская программа CSP). Моему научному руководителю направление было интересно в рамках педагогической деятельности (нужно было пополнить базу примеров, а также посмотреть в сторону недвоичных LDPC), а мне из-за того, что эти коды были плюс-минус на слуху на нашей кафедре. Не все удалось рассмотреть в том году, и поэтому исследование плавно перетекло в мое хобби… Так я набрал некоторое количество материала, которым сегодня и хочу поделиться!
Кому может быть интересна данная статья:
В общем, присоединяйтесь!
Внимание:
Предполагается, что читатель знаком с основами помехоустойчивого кодирования. Если тема совсем нова, то от себя в качестве ликбеза могу предложить данный материал: Channel codes basics (CommPy).
Содержание
Краткая историческая справка
LDPC коды — идея довольно старая, впервые они были описаны Робертом Галлагером ещё в 1963 г. в его работе на степень PhD [1]. Однако, из-за своей неоправданной сложности (по тем временам) они не находили применения в технике относительно долгое время.
И только в 1990-х годах эти коды были, так сказать, заново открыты М. Дэви и Д. Маккеем, которые предложили инновационные на тот момент способы построения LDPC кодов с уменьшенной сложностью [2].
Сейчас LDPC коды это:
Кроме того, все больше LDPC коды проникают и в спутниковую связь. В свое время, я делал небольшой обзор по малым спутникам CubeSat (посмотреть можно по ссылке) — там тенденция однозначная и обусловлена внедрением стандартов DVB-S2/S2X.
И я думаю, это прекрасная мотивация узнать о данных кодах немного больше.
Азы блочного кодирования
LDPC коды — это линейные блочные коды, а значит проверочные биты в данной схеме кодирования добавляются в конец информационного сообщения — блоком.
Соответсвенно, процедура кодирования (encoding) — есть ничто иное, как перемножение вектора информационного сообщения длинной  на некоторую порождающую матрицу
на некоторую порождающую матрицу  :
:

где символ  — это умножение по модулю (см. modulo). Для двоичных кодов это modulo 2, для недвоичных modulo q, исходя из полей Галуа
— это умножение по модулю (см. modulo). Для двоичных кодов это modulo 2, для недвоичных modulo q, исходя из полей Галуа  .
.
Соответственно, и кодовая скорость тоже задается через порождающую матрицу:
Порождающая матрица состоит из двух конкатенированных (соединенных) частей:

где  — это, так называемая, четная (parity) часть, а
— это, так называемая, четная (parity) часть, а  — единичная (identity) матрица.
— единичная (identity) матрица.
Дело в том, что при умножении и сложении по модулю нужно соблюдать правила сопоставления отрицательных и положительных чисел:
На двоичном случае все это незаметно, и поэтому минус иногда пропускают.
Так как мы говорим о линейных блочных кодах, порождающая матрица и должна обеспечивать эту линейность (см. Linear code). То есть, строки порождающей матрицы должны быть линейно независимыми (да, на слух звучит немного парадоксально).
Обратите внимание, identity-часть нужна для того, чтобы оставлять код систематическим: информационное сообщение остается неизменным, а проверочные биты добавляются в конец блоком. При такой схеме, правильно восстановив кодовое слово, можно восстановить и изначальное сообщение, просто убрав проверочные биты. Удобно, не правда ли?
Порождающая матрица напрямую связана с другой важнейшей матрицей, использующейся во время процедуры декодирования: с матрицей проверки на четность (parity-check matrix).
Матрица проверки на четность имеет  строк и
строк и  столбцов, где соответствует требуемой длине кодового слова, а , повторим, соответствует длине сообщения:
столбцов, где соответствует требуемой длине кодового слова, а , повторим, соответствует длине сообщения:

Ее основную идею очень удобно объяснять с помощью графа Таннера:
То есть существует два вида узлов: так называемые, узлы переменных (variable nodes), количество которых соответствуют числу столбцов , и узлы проверки (check nodes), соответствующие числу строк ( ). Узлы связаны между собой, и связь определяется положением единиц в матрице
). Узлы связаны между собой, и связь определяется положением единиц в матрице  . Картинка справа — это моя собственная мнемоничка моего же производства. Как мне кажется, это самый простой способ уловить суть структуры: если элемент матрицы равен 1, значит связь между узлами есть, если равен 0 — связи нет.
. Картинка справа — это моя собственная мнемоничка моего же производства. Как мне кажется, это самый простой способ уловить суть структуры: если элемент матрицы равен 1, значит связь между узлами есть, если равен 0 — связи нет.
Для того, чтобы считать процедуру декодирования успешной, нужно, чтобы на всех проверочных узлах сформировались определенные значения — как правило, нули (см. декодирование на основе синдромов):

Собственно говоря, эта матрица и определяет последние две буквы в аббревиатуре LDPC (Parity-Check).
Азы LDPC кодов
Но всё выше описанное — это общие моменты для большинства блочных кодов. Чем же тогда LDPC отличаются от тех же кодов Хэмминга?
В общем-то, тем, что и определяет их как low-density: их матрицы проверки на четность должны быть разряженными (sparce), то есть нулей в них должно быть значительно больше, чем чего-либо другого:
«Low density parity check codes are codes specified by a parity check matrix containing mostly zeros and only small number of ones.» [1]
Например, у того же Галлагера данная матрица была такой:
(3,4)-регулярная матрица проверки на четность длинною 12. Пояснение: кодовое слово, которое будет закодировано с помощью такого кода, будет иметь длину 12 бит; в каждом столбце 3 единицы, а в каждой строке 4, отсюда обозначение (3,4); количество единиц в строках и столбцах — это константы (в нашем случае 3 и 4), а значит код — регулярный.
У Маккея и Нила матрица проверки на четность была такой:
(3,4)-регулярная матрица проверки на четность длинною 12.
В стандарте DVB-S2 приняты уже нерегулярные (irregular) матрицы проверки на четность. См.:
Eroz M., Sun F. W., Lee L. N. DVB‐S2 low density parity check codes with near Shannon limit performance //International Journal of Satellite Communications and Networking. – 2004. – Т. 22. – №. 3. – С. 269-279.
Связано это с лучшей помехоустойчивостью нерегулярных схем.
Однако, ничего не замечаете? Правильно: эти матрицы не попадают под стандартную форму из формулы (3), ведь для LDPC кодов мы стремимся сделать проверочные матрицы разреженными. А если матрицы проверки не попадают под стандартную форму, значит не совсем понятно, как для них формировать порождающие матрицы.
Ответ, конечно, есть (и не один). Допустим, такой: изначальную матрицу приводят к стандартной форме через метод Гаусса (Gaussian elimination), из стандартной формы получают порождающую матрицу, а ее используют для кодирования.
Приведем пример из данного учебного материала:
Была такая матрица :
От нее, путем перемещений и преобразований строк по модулю 2, а также перемещений столбцов, перешли к матрице  :
:
Преобразования со строками с точки зрения линейной алгебры не влияют на кодовое слово, а вот перемещения столбцов нужно запомнить:
Формируем порождающую матрицу:
Создаем кодовое слово:
И проверяем синдром (то есть закодировали мы слово матрицей, произведенной от , а в процессе декодирования будем использовать разреженную матрицу ):
Магия линейной алгебры сработала!
Завершая раздел, нужно сказать, что такой метод кодирования самый простой для понимания, однако весьма сложный для вычисления в случае больших матриц — порождающая матрица, как правило, перестает быть разряженной. Конечно, на все это есть свои решения, однако, это уже совсем другая история.
Декодирование LDPC кодов
По LDPC кодам есть неплохой подбор материалов на Medium:
Однако, лично мне объяснение одного из центральных и самых, наверное, популярных алгоритмов декодирования — алгоритма Belief propagation (aka SPA — Sum-product algorithm) показалось, мягко говоря, слишком формальным (там просто прикреплена научная статья). Душа просит картинок и примеров!
За основу возьмем уже знакомый нам учебный материал:
Итак, во-первых, предположим, что у нас есть некая система связи:
Система связи состоит из:
Передатчик состоит из :
Приемник состоит из:
Договоримся, что под цифровыми модемами будем понимать в первую очередь самые популярные их разновидности: PSK и QAM.
Чем интересны для нас данные типы модуляции? Во-первых, тем, что именно они входят в стандарты современных беспроводных систем (LTE, Wi-Fi, DVB и т.д. ).
А, во-вторых, тем, что они умеют представлять зашумленные значения, полученные из канала связи, в форме, так называемых, мягких значений демодуляции (soft decisions). Или, если выражаться более наукообразно, в форме логарифмированных коэффициентов правдоподобия (LLR — log likelihood ratios):

где  обозначает вероятность, а
обозначает вероятность, а  обозначает некоторое событие.
обозначает некоторое событие.
Несложно догадаться, что схема, состоящая только из источника сообщений и модема, весьма чувствительна к сильным шумам, а значит и к ошибкам демодуляции. Благо, что мы включили в нашу схему помехоустойчивый (канальный) кодек. Декодер нам эту ошибку как раз и исправит. А точнее тот алгоритм, который в этот самый декодер зашит.
Итак, Belief propagation.
Потому что алгоритм работает с вероятностями. А точнее, с теми натуральными логарифмами от отношений вероятностей, которые мы указали в формуле (5).
Потому что эти вероятности будут итеративно «пересылаться» от узлов переменных к узлам проверки (сообщение V2C — Variable-to-Check) и наоборот (сообщение C2V — Check-to-Variable).
Под пересылкой сообщений между узлами проверки и переменных понимается то, что LLR будут складываться и перемножаться по определенным формулам.
На этапе инициализации алгоритма LLR соответствуют априорным вероятностям. SPA является одним из алгоритмов максимальной апостериорной вероятности (MAP — maximum a posteriori probability), а значит он стремится максимизировать апостериорную вероятность, полученную после итеративной пересылки между узлами проверок и переменных.
Предлагаю рассмотреть пошагово.
Предупреждение:
Ниже будет представлено некоторое количество математических формул, и иногда они будут довольно непростыми для визуального восприятия. Поэтому если вы не настроены в данный момент на штудирование, предлагаю перейти сразу к пункту «Пример декодирования через SPA на Python (numpy)». Вернетесь к теории, когда будет время и настроение или когда захочется посмотреть, что лежит в основе скриптов (наверное).
1. Инициализация
Итак, для начала рассмотрим априорные вероятности.
Начальной точкой для нашего алгоритма является матрица значений LLR, повторяющая структуру матрицы . Подберем аналитическое описание:

где  является массивом единиц, а
является массивом единиц, а  обозначает произведение Адамара (поэлементное умножение). На практике без единичной матрицы можно будет обойтись: заменим скобку на итерационное умножением Адамара вектора LLR со столбцами матрицы контроля четности (нужен будет дополнительный цикл). Если матрицы будут достаточно большими, такой подход может быть более эффективным с точки зрения памяти.
обозначает произведение Адамара (поэлементное умножение). На практике без единичной матрицы можно будет обойтись: заменим скобку на итерационное умножением Адамара вектора LLR со столбцами матрицы контроля четности (нужен будет дополнительный цикл). Если матрицы будут достаточно большими, такой подход может быть более эффективным с точки зрения памяти.
2. Сообщение V2C
Затем следует, так называемый, горизонтальный шаг: алгоритм требует обработки сообщения (V2C) в области вероятности. Для перехода от LLR к вероятностям воспользуемся отношением между гиперболическим тангенсом и натуральным логарифмом [4, с.32 ]:

Собственно говоря, процедура передачи V2C сообщения — это перемножение ненулевых вероятностей в каждой строке:
где j — это номер определенной строки, i — это номер определенного столбца,  — это множество ненулевых значений в j-ой строке, а выражение
— это множество ненулевых значений в j-ой строке, а выражение  означает, что мы исключаем i-ый узел переменных (variable node) из рассмотрения.
означает, что мы исключаем i-ый узел переменных (variable node) из рассмотрения.
То есть на данном этапе нам нужно:
Пункт с исключением узла из рассмотрения можно провести двумя способами: 1) выяснять нужное подмножество до перемножения вероятностей или удалять значение из результата после подсчетов. Я, простоты ради, буду пользоваться вторым методом.
Я думаю, кто-то из вас, возможно, слышал названия и других алгоритмов декодирования LDPC кодов. Например, Min-sum [5], Log-SPA [6] или еще какие-нибудь [7]. Такие алгоритмы еще иногда называются субоптимальными. В чем их отличие? Собственно, в данном пункте: данные алгоритмы стремятся снизить сложность декодирования и для этого используют иные формулы для вычисления горизонтального шага. Как правило, здесь начинается подсчет рисков: каким количеством помехоустойчивости мы готовы пожертвовать ради повышения скорости декодирования.
3. Проверка критерия остановки декодирования
Итак, мы подходим к концу первой итерации, а значит пора обновить наши априорные вероятности — сделать их апостериорными:

где  — это множество элементов, отвечающих ненулевым элементам матрицы проверки на четность в
— это множество элементов, отвечающих ненулевым элементам матрицы проверки на четность в  -ом столбце.
-ом столбце.
Наложим их на биты через обратный NRZ:

И вычислим синдром по формуле (4). Если вектор нулевой — останавливаем декодирование. Если нет, то переходим к следующему шагу.
4. Сообщение C2V
На этом этапе нужно пересчитать матрицу  :
:
И далее перейти к вычислению матрицы  . И так до тех пор, пока не выполнится пункт 3 (или не кончится количество доступных итераций).
. И так до тех пор, пока не выполнится пункт 3 (или не кончится количество доступных итераций).
Пример декодирования через SPA на Python (numpy)
А теперь давайте перейдем к вещам более интересным — к примерам и скриптам!
Возьмем все тот же пример из [4, с.33 ]:

Начинаем декодировать (должна понадобиться одна итерация).
Попробуем другой пример [4, с.36 ]:
Исправить нужно первый и последний биты.
Готовые решения для моделирования
Ну, что же, теперь мы знаем азы блочного кодирования, в целом, и LDPC кодов, в частности, и даже попробовали сделать что-то, так сказать, своими руками. Можно считать, что стадия перехода от обезьяны к человеку пройдена — теорию усвоили (или хотя бы запасли на будущее).
Давайте использовать готовые решения.
Наверное, первое, что придет вам на ум, — это Communication Toolbox от MathWorks (MatLab). Решение, пожалуй, действительно хорошее, но мне оно не нравится по нескольким причинам:
Поэтому я отправился в путешествие по проектам на GitHub и нашел весьма интересный инструментарий: проект aff3ct, написанный на C++.
Прочтем, как проект позиционируют его разработчики:
Работает ПО не только для LDPC кодов, но и для других кодеков (например, можно рассмотреть Turbo-коды и полярные коды).
У проекта есть хорошая документация в формате PDF, в формате WEB-страниц, а также онлайн-версия с визуализацией уже полученных результатов (BER/FER Comparator).
Выберем что-нибудь для примера:
Лучше открыть в новой вкладке для полноты эффекта.
Можно запустить любой эксперимент и под свой вкус. Для этого нужно будет по инструкции (см. Instalation) установить ПО и запустить его из командной строки с нужными параметрами.
Устанавливать нужно путем сборки из исходников. Поэтому не забывайте про суперпользователей и места нахождения make-файлов.
Например, я запустил на досуге такую модель к командной строке Ubuntu 18.04:
В итоге сформировалась такая таблица:
Даже такое аскетичное представление данных — как мне кажется, это уже классная возможность.
Можно, конечно, пойти дальше написать какие-нибудь обертки для отрисовки графиков.
У создателей проекта есть и собственные решения по визуализации. Например, PyBER. Суть «тулзы» заключается в том, что с помощью GUI вы можете выбирать сформированные aff3ct txt-файлы, PyBER вам их распарсит и отрисует (полученное можно даже экспортировать, вроде). Лично мне не понравилось представление: графики представлены через plot, а не через более логичный semilogy. Поэтому оставляю опыт использования PyBER на ваше усмотрение.
Допустим, результаты моделирования можно сохранить в txt-файл, а значения отношений битовых ошибок (BER — bit error ratio) можно вытащить уже из него c помощью простой манипуляции с awk:
Все это передать, допустим, в Python и нарисовать графики под свой вкус.
Для кодовых скоростей 1/2 и 3/4 (AWGN канал) у меня получились такая картинка:
Без изысков, но в качестве первого шага неплохо, как мне кажется.
Послесловие
Не спорю, сколько я ни пытался объять необъятное, прошлись мы все же только по вершкам. Однако, я все же надеюсь, что данная статья хоть сколько-то снизит порог вхождения человеку, желающему погрузиться в тему LDPC-кодов (наверное).
Конструктивная критика только приветствуется. И спасибо за ваше внимание!
Литература
R.G. Gallager Low-Density Parity-Check Codes, IRE Transactions on Information Theory, 1962
D.J.C. MacKay Good Error-Correcting Codes Based on Very Sparse Matrices, IEEE Transactions on Information Theory, VOL.45, NO 2., March 1999
«3GPP RAN1 meeting #87 final report». 3GPP. Retrieved 31 August 2017.
Johnson, S. J. (2006). Introducing low-density parity-check codes. University of Newcastle, Australia, V1
Declercq D., Fossorier M. Decoding algorithms for nonbinary LDPC codes over GF(q) //IEEE transactions on communications. – 2007. – Т. 55. – №. 4. – С. 633-643.
Wymeersch H., Steendam H., Moeneclaey M. Log-domain decoding of LDPC codes over GF (q) //2004 IEEE International Conference on Communications (IEEE Cat. No. 04CH37577). – IEEE, 2004. – Т. 2. – С. 772-776.
Chen J. et al. Reduced-complexity decoding of LDPC codes //IEEE transactions on communications. – 2005. – Т. 53. – №. 8. – С. 1288-1299.
Приложения
Хотите немного линейной алгебры?
Давайте порассуждаем о том, как можно найти подмножества ненулевых вероятностей?
Для второго способа нужна будет, правда, заранее подготовленная матрица, которая будет повторять структуру матрицы H с точностью до наоборот: вместо единиц в ней будут нули, а вместо нулей единицы. Назовем ее «зеркалом» матрицы H:
где  — это сложение по модулю (в нашем случае modulo 2).
— это сложение по модулю (в нашем случае modulo 2).
Соответственно, процедура замены нулей на единицы в матрице — это сложение двух матриц:
После перемножения нужно будет вернуть структуру к исходному виду:
Выглядит забавно, не правда ли? Такой подход очень удобен при небольших матрицах проверки на четность: можно использовать встроенные функции для перемножения элементов в векторах. Однако, я думаю, для больших матриц такой подход может быть неподходящим из-за дополнительного расхода памяти и побочных вычислений.
Вопрос о сложности и простоте декодирования, может быть, не так хорошо просматривается на двоичных кодах, однако на кодах недвоичных встает, так сказать, во весь рост. Пример для GF(4).
Во-первых, вместо вектора LLR, нам придется работать с матрицей LLR (нужно ведь проверять вероятность уже не только двух событий):
Соответственно, пересылаемые сообщения — это уже тензоры, которые придется разбивать на слои и обрабатывать в цикле:
И уже потом выбирать наиболее вероятное значение:
Сложность будет расти пропорционально увеличению q в выражении GF(q). Волей-неволей задумаешься о более быстрых алгоритмах…



