Кодировки в чем разница между ascii и utf 8
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Что нужно знать для создания PHP-сайтов?
Ответ здесь. Только самое важное и полезное для начинающего веб-разработчика.
Узнайте, как создавать качественные сайты на PHP всего за 2 часа и 27 минут!
Создайте свой сайт за 3 часа и 30 минут.
После просмотра данного видеокурса у Вас на компьютере будет готовый к использованию сайт, который Вы сделали сами.
Вам останется лишь наполнить его нужной информацией и изменить дизайн (по желанию).
Изучите основы HTML и CSS менее чем за 4 часа.
После просмотра данного видеокурса Вы перестанете с ужасом смотреть на HTML-код и будете понимать, как он работает.
Вы сможете создать свои первые HTML-страницы и придать им нужный вид с помощью CSS.
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Хотите изучить JavaScript, но не знаете, как подступиться?
После прохождения видеокурса Вы освоите базовые моменты работы с JavaScript.
Развеются мифы о сложности работы с этим языком, и Вы будете готовы изучать JavaScript на более серьезном уровне.
*Наведите курсор мыши для приостановки прокрутки.
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т.е. нечитаемых символов.
Что такое кодировка?
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.

Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
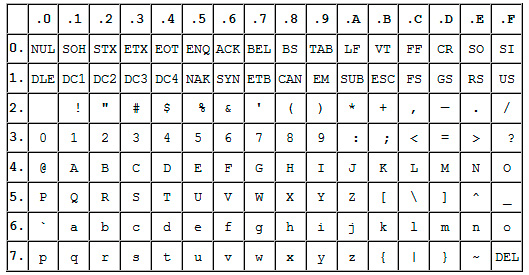
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
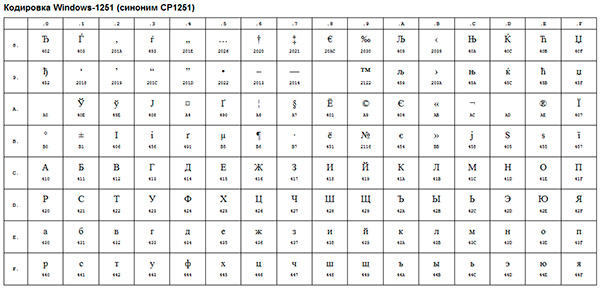
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.

Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
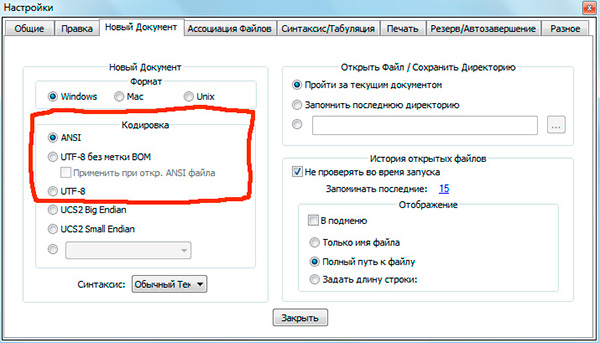
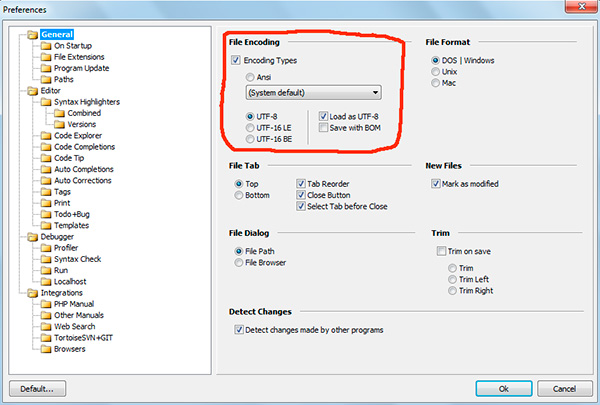
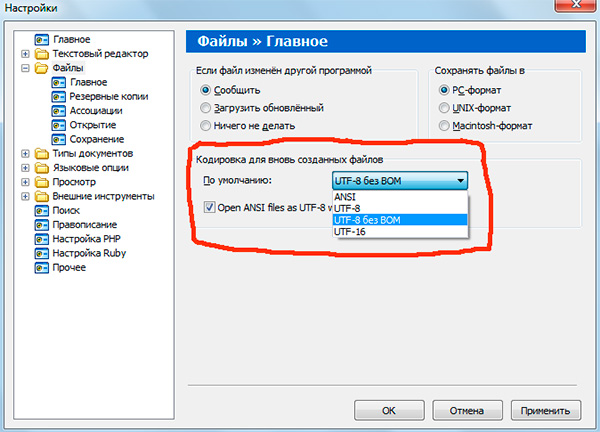
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.

Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.

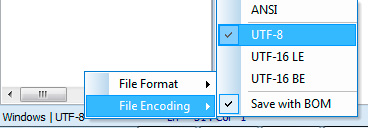
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).

В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Русские Блоги
Тщательно разобраться в кодировке символов: разница между ASCII, Unicode, UTF-8, GBK
Я немедленно приступил к работе.При просмотре структуры файла класса сегодня в тексте упоминалась сокращенная кодировка UTF-8. Раньше кодирование ASCII, UTF-8, Unicode и т. Д. Находилось в нечетком состоянии. Сегодня я поделюсь своим опытом обучения. Напишите блог с простой и понятной идеей.
Проще говоря, кодирование символов означает преобразование информации, которую компьютер не распознает, в двоичные символы, распознаваемые компьютером.
1. Код ASCII
Мы знаем, что вся информация внутри компьютера в конечном итоге имеет двоичное значение. Каждый двоичный бит (бит) имеет 0 с участием 1 Два состояния, поэтому восемь двоичных битов могут объединять 256 состояний, что называется байтом. Другими словами, байт может использоваться для представления всего 256 различных состояний, и каждое состояние соответствует символу, который составляет 256 символов. 00000000 Чтобы 11111111 。
В 1960-х годах Соединенные Штаты сформулировали набор кодов символов для единообразного регулирования отношений между английскими символами и двоичными цифрами. Это называется кодом ASCII и используется до сих пор.
Код ASCII определяет всего 128 символов, например пробелы. SPACE 32 (двоичный 00100000 ), заглавные буквы A 65 (двоичный 01000001 ). Эти 128 символов (включая 32 управляющих символа, которые не могут быть распечатаны) занимают только последние 7 бит байта, а первый бит всегда определяется как 0 。
Два, не-ASCII кодирование
Кодировки на английском языке 128 символов достаточно, но для других языков 128 символов недостаточно. Например, во французском языке, если над буквой есть фонетический символ, он не может быть представлен кодом ASCII. В результате некоторые европейские страны решили использовать старший бит неиспользуемого байта для программирования нового символа. Например, на французском é Код 130 (двоичный 10000010 ). Таким образом, система кодирования, используемая в этих европейских странах, может представлять до 256 символов.
Что касается шрифтов азиатских стран, то здесь используется больше символов, насчитывающих до 100 000 китайских иероглифов. Один байт может представлять только 256 видов символов, что явно недостаточно, и для представления одного символа необходимо использовать несколько байтов. Например, распространенным методом кодирования для упрощенного китайского языка является GB2312, который использует два байта для представления китайского символа, поэтому теоретически он может представлять до 256 x 256 = 65536 символов.
Вопрос о китайской кодировке необходимо обсудить в специальной статье, которая не освещена в этой заметке. Здесь только указано, что, хотя для представления символа используется несколько байтов, китайская кодировка символов типа GB не имеет ничего общего с Unicode и UTF-8 ниже.
3. Юникод
Как упоминалось в предыдущем разделе, в мире существует несколько методов кодирования, и одно и то же двоичное число можно интерпретировать как разные символы. Следовательно, если вы хотите открыть текстовый файл, вы должны знать его метод кодирования, в противном случае будут отображаться искаженные символы, если вы декодируете его с помощью неправильного метода кодирования. Почему электронные письма часто выглядят искаженными? Это потому, что метод кодирования, используемый отправителем и получателем, отличается.
Вполне возможно, что если есть какой-то код, в него будут включены все символы мира. Каждому символу присваивается уникальный код, тогда искаженная проблема исчезнет. Это Unicode, как следует из названия, это кодировка всех символов.
В-четвертых, проблема Unicode
Результатом этого является: 1) Существует несколько методов хранения Unicode, что означает, что существует множество различных двоичных форматов, которые могут использоваться для представления Unicode. 2) Юникод нельзя продвигать долго, до появления Интернета.
Пять, UTF-8
Одной из самых больших особенностей UTF-8 является то, что это метод кодирования переменной длины. Он может использовать от 1 до 4 байтов для представления символа, а длина байта зависит от разных символов.
Правила кодировки UTF-8 очень простые, их всего два:
В следующей таблице приведены правила кодирования, буквы x Представляет доступные закодированные биты.
Ниже по-прежнему используются китайские иероглифы. строгий Рассмотрим пример, чтобы продемонстрировать, как реализовать кодировку UTF-8.
Что такое кодировки?
Компьютеры постоянно работают с текстами: это ленты новостных сайтов, фондовые биржи, сообщения в социальных сетях и мессенджерах, банковские приложения и многое другое. Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок. Кодировки прошли большой путь от таблиц символов, созданных отдельно для каждого компьютера, до единой кодировки, принятой во всём мире.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
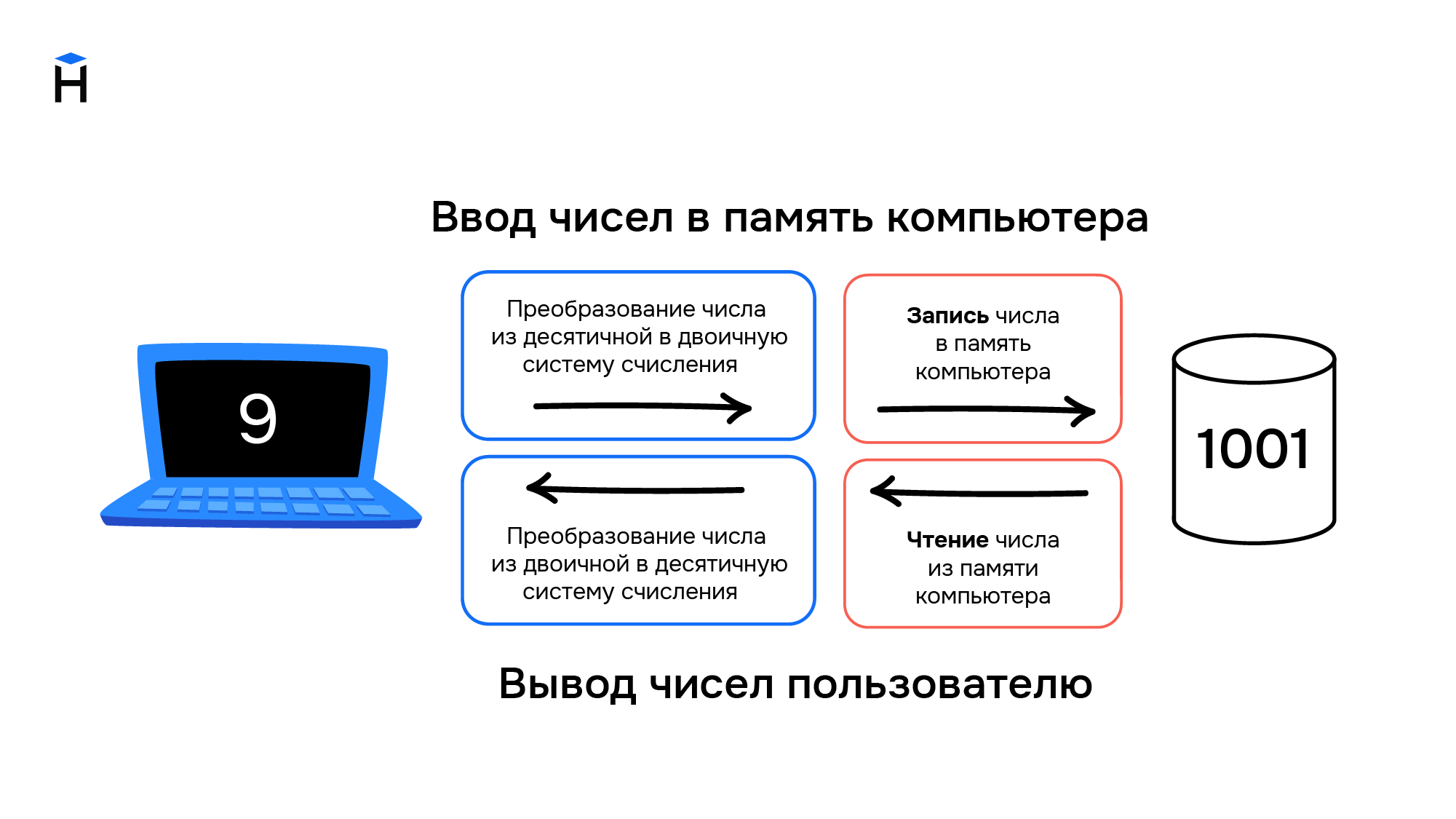
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
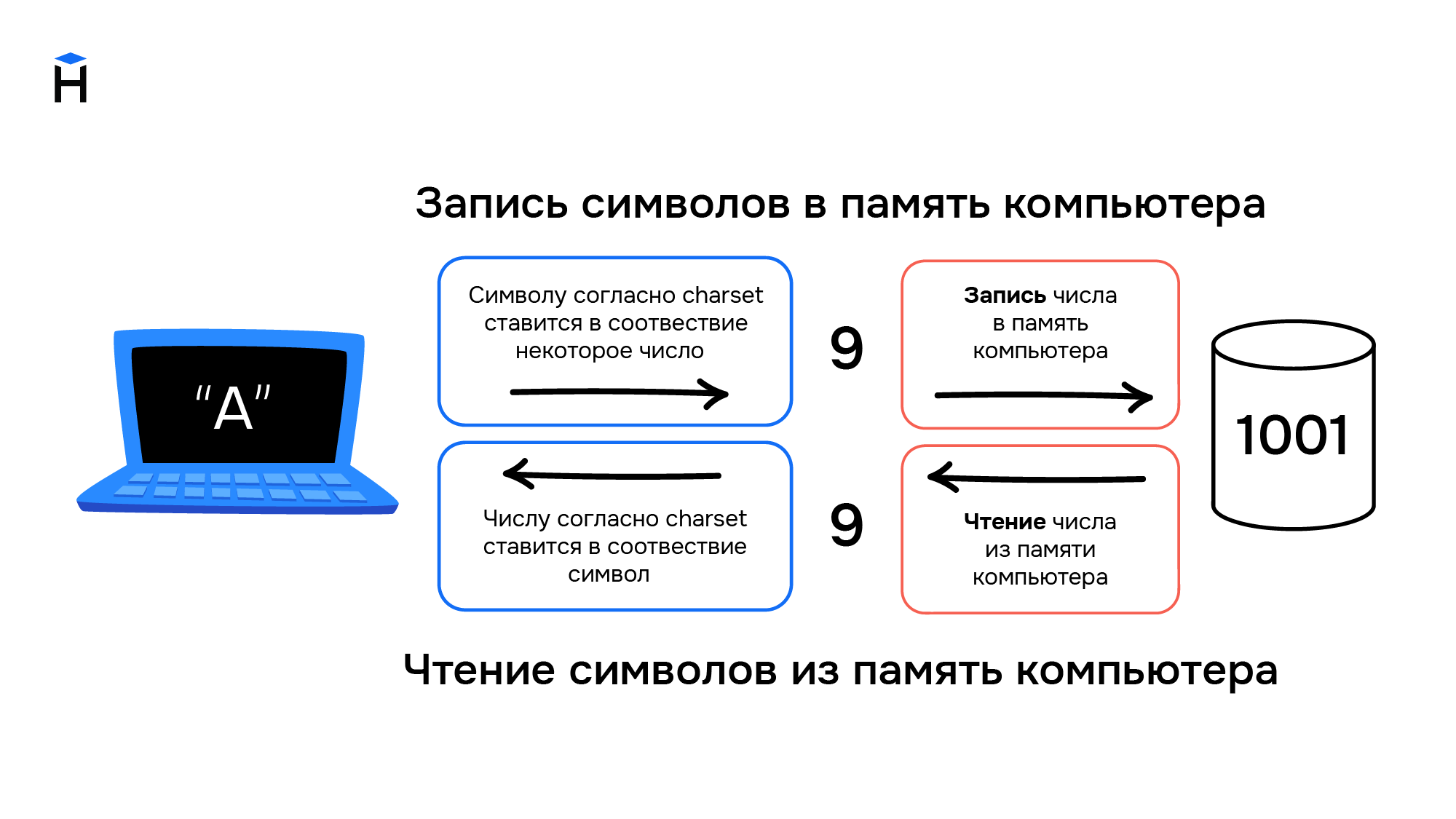
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
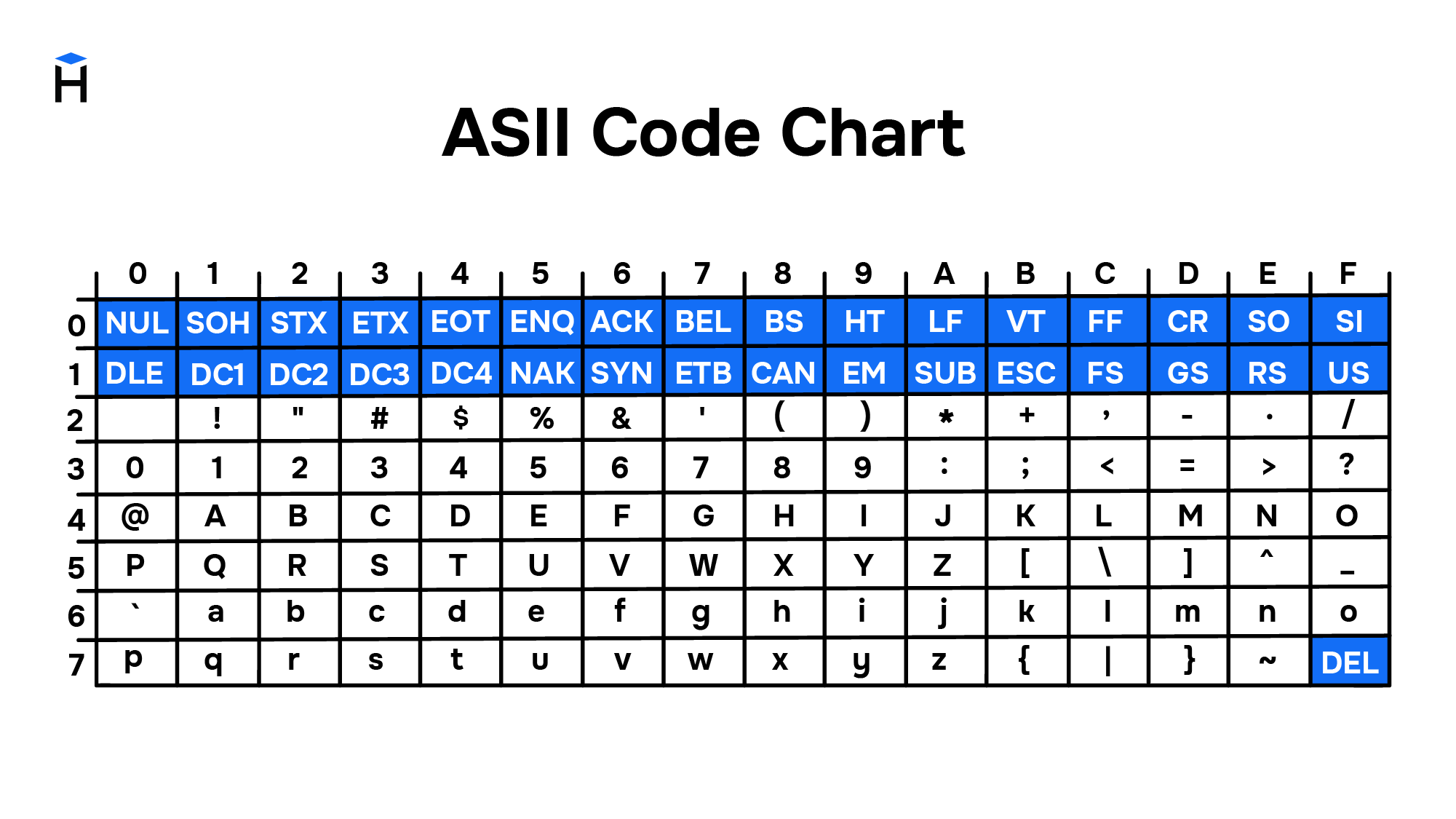
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
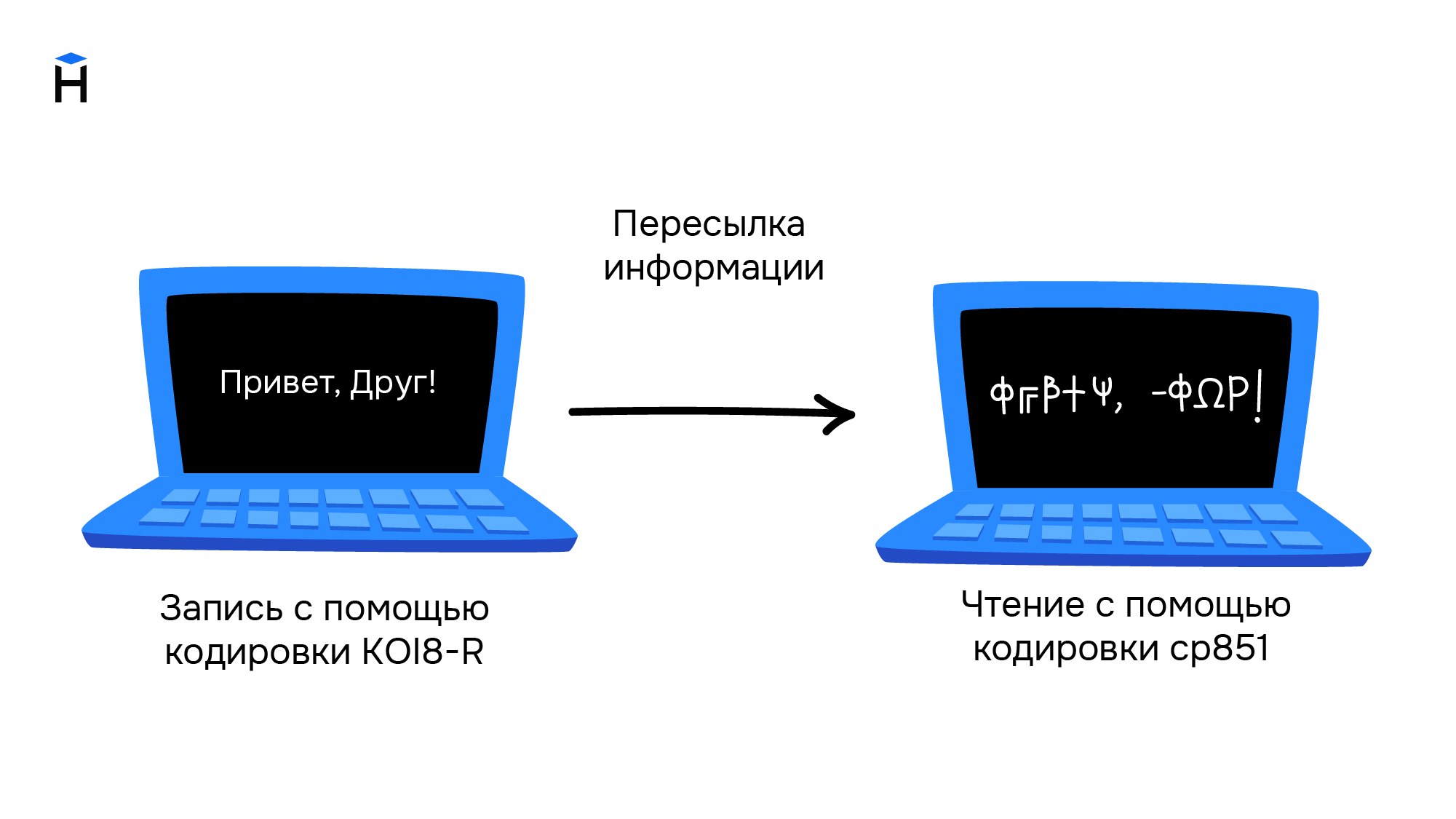
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.



