Создание простой нейронной сети на Python

Feb 26 · 8 min read
![]()
В течение последних десятилетий машинное обучение оказало огромное влияние на весь мир, и его популярность только набирает обороты. Все больше людей увлекается подотраслями этой науки, например нейронными сетями, которые разрабатываются по принципам функционирования человеческого мозга. В этой статье мы разберем код Python для простой нейронной сети, классифицирующей векторы 1х3, где первым элементом является 10.
Шаг 1: импорт NumPy, Scikit-learn и Matplotlib
Для этого проекта мы используем три пакета. NumPy будет служить для создания векторов и матриц, а также математических операций. Scikit-learn возьмет на себя обязанность по масштабированию данных, а Matpotlib предоставит график изменения показателей ошибки в процессе обучения сети.
Шаг 2: создание обучающей и контрольной выборок
Нейронны е сети отлично справляются с изучением тенденций как в больших, так и в малых датасетах. Тем не менее специалисты по данным должны иметь в виду опасность возможного переобучения, которое чаще встречается в проектах с небольшими наборами данных. Переобучение происходит, когда алгоритм слишком долго обучается на датасете, в результате чего модель просто запоминает представленные данные, давая хорошие результаты конкретно на используемой обучающей выборке. При этом она существенно хуже обобщается на новые данные, а ведь именно это нам от нее и нужно.
Чтобы гарантировать оценку модели с позиции ее возможности прогнозировать именно новые точки данных, принято разделять датасеты на обучающую и контрольную выборки (а иногда еще и на тестовую).
Шаг 3: масштабирование данных
Многие модели МО не способны понимать различия между, например единицами измерения, и будут, естественно, придавать большие веса признакам с большими величинами. Это может нарушить способность алгоритма правильно прогнозировать новые точки данных. Более того, обучение моделей МО на признаках с высокими величинами будет медленнее, чем нужно, по крайней мере при использовании градиентного спуска. Причина в том, что градиентный спуск сходится к искомой точке быстрее, когда значения находятся приблизительно в одном диапазоне.
Шаг 4: Создание класса нейронной сети
Один из простейших способов познакомиться со всеми элементами нейронной сети — создать соответствующий класс. Он должен включать все переменные и функции, которые потребуются для должной работы нейронной сети.
Шаг 4.1: создание функции инициализации
Функция _init_ вызывается при создании класса, что позволяет правильно инициализировать его переменные.
Нейронные сети на Python: как написать и обучить



Нейронные сети — это огромное множество алгоритмов в области машинного обучения. Из чего они состоят и как работают? Давайте попробуем в этом разобраться.
Нейронная сеть — это функциональная единица машинного или глубокого обучения. Она имитирует поведение человеческого мозга, поскольку основана на концепции биологических нейронных сетей.
Нейронные сети способны решать множество задач. В основном они состоят из таких компонентов:
Чтобы реализовать нейросеть, необходимо понимать, как ведут себя нейроны. Нейрон одновременно принимает несколько входов, обрабатывает эти данные и выдает один выход.

Схематическое изображение нейронной сети
Проще говоря, нейронная сеть представляет собой блоки ввода и вывода, где каждое соединение имеет соответствующие веса (это сила связи нейронов; чем вес больше, тем один нейрон сильнее влияет на другой). Данные всех входов умножаются на веса:
Входы после взвешивания суммируются с прибавлением значения порога «c»:
Полученное значение пропускается через функцию активации (сигмоиду), которая преобразует входы в один выход:
Так выглядит сигмоида:
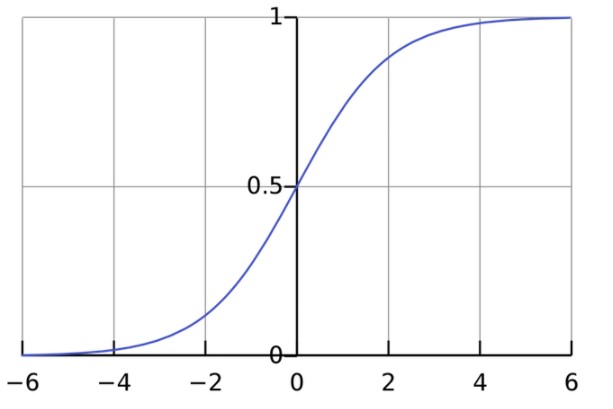
Интервал результатов сигмоиды — от 0 до 1. Отрицательные числа стремятся к нулю, а положительные — к единице.
Пусть нейрон имеет следующие значения: w = [0,1] c = 4
Входной слой: x = 2, y = 3.
((x*w 1 ) + (y*w 2 )) + c = 2*0 + 3*1 + 4 = 7
Как написать свой нейрон
Мы использовали значения из примера выше и видим, что результаты вычислений совпадают и равны 0.99.
Как собрать нейросеть из нейронов
Нейросеть состоит из множества соединенных между собой нейронов.
Пример несложной нейронной сети:
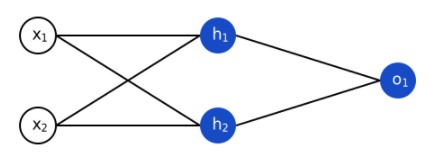
Простая нейронная сеть
Внимание! Слоев в нейросети, так же как и нейронов, может быть любое количество.
Представим, что нейроны из графика выше имеют веса [0, 1]. Пороговое значение (b) у обоих нейронов равно 0 и они имеют идентичную сигмоиду.
При входных данных x=[2, 3] получим:
h 1 = h 2 = ƒ(w*x+b) = ƒ((0*2) + (1*3) +0) = ƒ(3) = 0.95
Входные данные по нейронам передаются до тех пор, пока не получатся выходные значения.
Код нейросети
Видим, что нейронная сеть создана, выходное значение равно 0.72.
Обучение нейронной сети
Обучение нейросети — это подбор весов, которые соответствуют всем входам для решения поставленных задач.
Класс нейронной сети:
Каждый этап процесса обучения состоит из:
Дана двуслойная нейросеть:
ŷ = σ(w 2 σ(w 1 x + b 1 ) + b 2 )
В данном случае на выход ŷ влияют только две переменные — w (веса) и b (смещение).
Настройку весов и смещений из данных входа или процесс обучения нейросети можно изобразить так:

Процесс обучения нейросети
Прямое распространение
Как видно, формула прямого распространения представляет собой несложное вычисление:
ŷ = σ(w 2 σ(w 1 x + b 1 ) + b 2 )
Далее необходимо добавить в код функцию прямого распространения. Предположим, что смещения в этом случае будут равны 0.
Чтобы вычислить ошибку прогноза, необходимо использовать функцию потери. В примере уместно воспользоваться формулой суммы квадратов ошибок — средним значением между прогнозируемым и фактическим результатами:
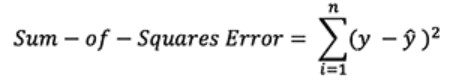
Формула суммы квадратов ошибок
Обратное распространение
Обратное распространение позволяет измерить производные в обратном порядке — от конца к началу, и скорректировать веса и смещения. Для этого необходимо узнать производную функции потери — тангенс угла наклона.
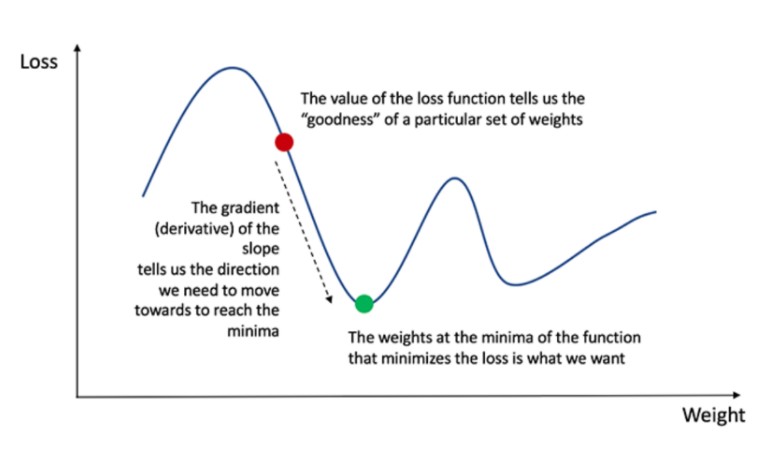
Тангенс угла наклона — производная функции потери
Производная функции по отношению к весам и смещениям позволяет узнать градиентный спуск.
Производная функции потери не содержит весов и смещений, для ее вычисления необходимо добавить правило цепи:
Благодаря этому правилу можно регулировать веса.
Добавляем в код Python функцию обратного распространения:
Нейронные сети базируются на определенных алгоритмах и математических функциях. Сначала может казаться, что разобраться в них довольно сложно. Но существуют готовые библиотеки машинного обучения для построения и тренировки нейросетей, позволяющие не углубляться в их устройство.
Простая нейронная сеть в 9 строк кода на Python
Из статьи вы узнаете, как написать свою простую нейросеть на python с нуля, не используя никаких библиотек для нейросетей. Если у вас еще нет своей нейронной сети, вот всего лишь 9 строчек кода:
Перед вами перевод поста How to build a simple neural network in 9 lines of Python code, автор — Мило Спенсер-Харпер. Ссылка на оригинал — в подвале статьи.
В статье мы разберем, как это получилось, и вы сможете создать свою собственную нейронную сеть на python. Также будут показаны более длинные и красивые версии кода.
 Диаграмма 1
Диаграмма 1
Но для начала, что же такое нейронная сеть? Человеческий мозг состоит из 100 миллиарда клеток, называемых нейронами, соединенных синапсами. Если достаточное количество синаптичеких входов возбуждены, то и нейрон тоже становится возбужденным. Этот процесс также называется “мышление”.
Мы можем смоделировать этот процесс, создав нейронную сеть на компьютере. Не обязательно моделировать всю сложную модель человеческого мозга на молекулярном уровне, достаточно только высших правил мышления. Мы используем математические техники называемые матрицами, то есть просто сетки с числами. Чтобы сделать все максимально просто, построим модель из трех входных сигналов и одного выходного.
Мы будем тренировать нейрон на решение задачи, представленной ниже.
Первые четыре примера назовем тренировочной выборкой. Вы сможете выделить закономерность? Что должно стоять на месте “?”
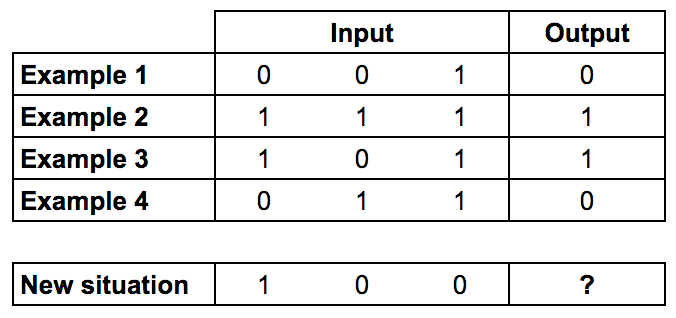 Диаграмма 2. Input — входный сигнал, Output — выходной сигнал.
Диаграмма 2. Input — входный сигнал, Output — выходной сигнал.
Вероятно вы заметили, что выходной сигнал всегда равен самой левой входной колонке. Таким образом ответ будет 1.
Процесс обучения нейронной сети
Как же должно происходить обучение нашего нейрона, чтобы он смог ответить правильно? Мы добавим каждому входу вес, который может быть положительным или отрицательным числом. Вход с большим положительным или большим отрицательным весом сильно повлияет на выход нейрона. Прежде чем мы начнем, установим каждый вес случайным числом. Затем начнем обучение:
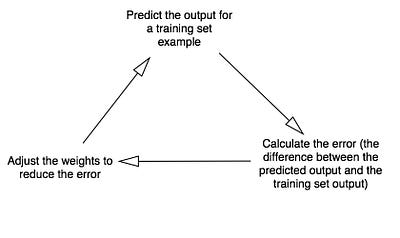 Диаграмма 3
Диаграмма 3
В конце концов вес нейрона достигнет оптимального значения для тренировочного набора. Если мы позволим нейрону «подумать» в новой ситуации, которая сходна с той, что была в обучении, он должен сделать хороший прогноз.
Формула для расчета выхода нейрона
Вам может быть интересно, какова специальная формула для расчета выхода нейрона? Сначала мы берем взвешенную сумму входов нейрона, которая:
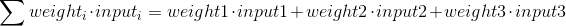
Затем мы нормализуем это, поэтому результат будет между 0 и 1. Для этого мы используем математически удобную функцию, называемую функцией Sigmoid:
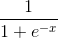
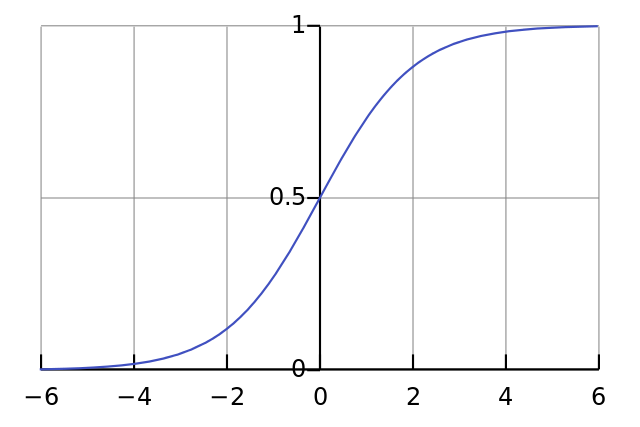
Если график нанесен на график, функция Sigmoid рисует S-образную кривую.
Подставляя первое уравнение во второе, получим окончательную формулу для выхода нейрона:
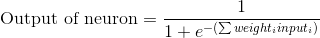
Возможно, вы заметили, что мы не используем пороговый потенциал для простоты.
Формула для корректировки веса
Во время тренировочного цикла (Диаграмма 3) мы корректируем веса. Но насколько мы корректируем вес? Мы можем использовать формулу «Взвешенная по ошибке» формула
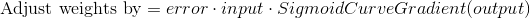
Почему эта формула? Во-первых, мы хотим сделать корректировку пропорционально величине ошибки. Во-вторых, мы умножаем на входное значение, которое равно 0 или 1. Если входное значение равно 0, вес не корректируется. Наконец, мы умножаем на градиент сигмовидной кривой (диаграмма 4). Чтобы понять последнее, примите во внимание, что:
Градиент Сигмоды получается, если посчитать взятием производной:
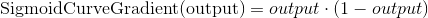
Вычитая второе уравнение из первого получаем итоговую формулу:
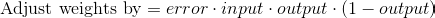
Существуют также другие формулы, которые позволяют нейрону учиться быстрее, но приведенная имеет значительное преимущество: она простая.
Написание Python кода
Хоть мы и не будем использовать библиотеки с нейронными сетями, мы импортируем 4 метода из математической библиотеки numpy. А именно:
Например, мы можем использовать array() для представления обучающего множества, показанного ранее.
“.T” — функция транспонирования матриц. Итак, теперь мы готовы для более красивой версии исходного кода. Заметьте, что на каждой итерации мы обрабатываем всю тренировочную выборку одновременно.
Код также доступен на гитхабе. Если вы используете Python3 нужно заменить xrange на range.
Заключительные мысли
Попробуйте запустить нейросеть, используя команду терминала:
Итоговый должен быть похож на это:
У нас получилось! Мы написали простую нейронную сеть на Python!
Сначала нейронная сеть присваивала себе случайные веса, а затем обучалась с использованием тренировочного набора. Затем нейросеть рассмотрела новую ситуацию [1, 0, 0] и предсказала 0.99993704. Правильный ответ был 1. Так очень близко!
Традиционные компьютерные программы обычно не могут учиться. Что удивительного в нейронных сетях, так это то, что они могут учиться, адаптироваться и реагировать на новые ситуации. Так же, как человеческий разум.
Конечно, это был только 1 нейрон, выполняющий очень простую задачу. А если бы мы соединили миллионы этих нейронов вместе?
Как построить свою первую нейросеть

С помощью статьи PhD Оксфордского университета и автора книг о глубоком обучении Эндрю Траска показываем, как написать простую нейронную сеть на Python. Она умещается всего в девять строчек кода и выглядит вот так:
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) — 1
for iteration in xrange(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(training_set_inputs.T, (training_set_outputs — output) * output * (1 — output))
print 1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights))))
Чуть ниже объясним как получается этот код и какой дополнительный код нужен к нему, чтобы нейросеть работала. Но сначала небольшое отступление о нейросетях и их устройстве.
Человеческий мозг состоит из ста миллиардов клеток, которые называются нейронами. Они соединены между собой синапсами. Если через синапсы к нейрону придет достаточное количество нервных импульсов, этот нейрон сработает и передаст нервный импульс дальше. Этот процесс лежит в основе нашего мышления.

Мы можем смоделировать это явление, создав нейронную сеть с помощью компьютера. Нам не нужно воссоздавать все сложные биологические процессы, которые происходят в человеческом мозге на молекулярном уровне, нам достаточно знать, что происходит на более высоких уровнях.
Для этого мы используем математический инструмент — матрицы, которые представляют собой таблицы чисел. Чтобы сделать все как можно проще, мы смоделируем только один нейрон, к которому поступает входная информация из трех источников и есть только один выход (рис. 1). Наша задача — научить нейронную сеть решать задачу, которая изображена на рисунке ниже. Первые четыре примера будут нашим тренировочным набором. Получилось ли у вас увидеть закономерность? Что должно быть на месте вопросительного знака — 0 или 1?

Вы могли заметить, что вывод всегда равен значению левого столбца. Так что ответом будет 1.
Процесс тренировки
Но как научить наш нейрон правильно отвечать на заданный вопрос? Для этого мы зададим каждому входящему сигналу вес, который может быть положительным или отрицательным числом. Если на входе будет сигнал с большим положительным весом или отрицательным весом, то это сильно повлияет на решение нейрона, которое он подаст на выход. Прежде чем мы начнем обучение модели, зададим для каждого примера случайное число в качестве веса. После этого мы можем приняться за тренировочный процесс, который будет выглядеть следующим образом:

В какой-то момент веса достигнут оптимальных значений для тренировочного набора. Если после этого нейрону будет дана новая задача, которая следует такой же закономерности, он должен дать верный ответ.
Формула для вычисления выхода нейронной сети
Итак, что же из себя представляет формула, которая рассчитывает значение выхода нейрона? Для начала мы возьмем взвешенную сумму входных сигналов:

После этого мы нормализуем это выражение, чтобы результат был между 0 и 1. Для этого, в этом примере, я использую математическую функцию, которая называется сигмоидой:

Если мы нарисуем график этой функции, то он будет выглядеть как кривая в форме буквы S (рис. 4).

Подставив первое уравнения во второе, мы получим итоговую формулу выхода нейрона.

Вы можете заметить, что для простоты мы не задаем никаких ограничений на входящие данные, предполагая, что входящий сигнал всегда достаточен для того, чтобы наш нейрон подал сигнал на выход.
Машинное обучение и нейросети
Комплект продвинутых курсов для освоения машинного и глубокого обучения от классических моделей до нейронных сетей. Дополнительная скидка 5% по промокоду BLOG.
Формула корректировки весов
Во время тренировочного цикла (он изображен на рисунке 3) мы постоянно корректируем веса. Но на сколько? Для того, чтобы вычислить это, мы воспользуемся следующей формулой:

Давайте поймем почему формула имеет такой вид. Сначала нам нужно учесть то, что мы хотим скорректировать вес пропорционально размеру ошибки. Далее ошибка умножается на значение, поданное на вход нейрона, что, в нашем случае, 0 или 1. Если на вход был подан 0, то вес не корректируется. И в конце выражение умножается на градиент сигмоиды. Разберемся в последнем шаге по порядку:
Градиент сигмоиды может быть найден по следующей формуле:

Таким образом, подставляя второе уравнение в первое, конечная формула для корректировки весов будет выглядеть следующим образом:

Существуют и другие формулы, которые позволяют нейрону обучаться быстрее, но преимущество этой формулы в том, что она достаточно проста для понимания.
Как написать это на Python
Хотя мы не будем использовать специальные библиотеки для нейронных сетей, мы импортируем следующие 4 метода из математической библиотеки numpy:
Теперь мы можем, например, представить наш тренировочный набор с использованием array():
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])=
training_set_outputs = array([[0, 1, 1, 0]]).T

Теперь мы готовы к более изящной версии кода. После нее добавим несколько финальных замечаний.
Обратите внимание, что на каждой итерации мы обрабатываем весь тренировочный набор одновременно. Таким образом наши переменные все являются матрицами.
Итак, вот полноценно работающий пример нейронной сети, написанный на Python:
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
Задаем порождающий элемент для генератора случайных чисел, чтобы он генерировал одинаковые числа при каждом запуске программы
random.seed(1)
Функция сигмоиды, график которой имеет форму буквы S.
Мы используем эту функцию, чтобы нормализовать взвешенную сумму входных сигналов.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
Производная от функции сигмоиды. Это градиент ее кривой. Его значение указывает насколько нейронная сеть уверена в правильности существующего веса.
def __sigmoid_derivative(self, x):
return x * (1 — x)
Мы тренируем нейронную сеть методом проб и ошибок, каждый раз корректируя вес синапсов.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in xrange(number_of_training_iterations):
Тренировочный набор передается нейронной сети (одному нейрону в нашем случае).
output = self.think(training_set_inputs)
Вычисляем ошибку (разницу между желаемым выходом и выходом, предсказанным нейроном).
error = training_set_outputs — output
Умножаем ошибку на входной сигнал и на градиент сигмоиды. В результате этого, те веса, в которых нейрон не уверен, будут откорректированы сильнее. Входные сигналы, которые равны нулю, не приводят к изменению веса.
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
Корректируем веса.
self.synaptic_weights += adjustment
Заставляем наш нейрон подумать.
def think(self, inputs):
Пропускаем входящие данные через нейрон.
return self.__sigmoid(dot(inputs, self.synaptic_weights))
if __name__ == «__main__»:
Инициализируем нейронную сеть, состоящую из одного нейрона.
neural_network = NeuralNetwork()
print «Random starting synaptic weights:
» print neural_network.synaptic_weights
Тренировочный набор для обучения. У нас это 4 примера, состоящих из 3 входящих значений и 1 выходящего значения.
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
Обучаем нейронную сеть на тренировочном наборе, повторяя процесс 10000 раз, каждый раз корректируя веса.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print «New synaptic weights after training:
» print neural_network.synaptic_weights
Этот код также можно найти на GitHub. Обратите внимание, что если вы используете Python 3, то вам будет нужно заменить команду “xrange” на “range”.
Несколько финальных замечаний
Попробуйте теперь запустить нейронную сеть, используя в терминале эту команду:
Результат должен быть таким:
Random starting synaptic weights:
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
New synaptic weights after training:
[[ 9.67299303]
[-0.2078435 ]
[-4.62963669]]
Ура, мы построили простую нейронную сеть с помощью Python!
Сначала нейронная сеть задала себе случайные веса, затем обучилась на тренировочном наборе. После этого она предсказала в качестве ответа 0.99993704 для нового примера [1, 0, 0]. Верный ответ был 1, так что это очень близко к правде!
Традиционные компьютерные программы обычно не способны обучаться. И это то, что делает нейронные сети таким поразительным инструментом: они способны учиться, адаптироваться и реагировать на новые обстоятельства. Точно так же, как и человеческий мозг.
Конечно, мы создали модель всего лишь одного нейрона для решения очень простой задачи. Но что если мы соединим миллионы нейронов? Сможем ли мы таким образом однажды воссоздать реальное сознание?
Машинное обучение и нейросети
Научим вас создавать чат-ботов, нейросети и агента для игры в Pong.



