Код Хаффмана
В этой статье мы рассмотрим один из самых распространенных методов сжатия данных. Речь пойдет о коде Хаффмана (Huffman code) или минимально-избыточном префиксном коде (minimum-redundancy prefix code). Мы начнем с основных идей кода Хаффмана, исследуем ряд важных свойств и затем приведем полную реализацию кодера и декодера, построенных на идеях, изложенных в этой статье.
Идея, лежащая в основе кода Хаффмана, достаточно проста. Вместо того чтобы кодировать все символы одинаковым числом бит (как это сделано, например, в ASCII кодировке, где на каждый символ отводится ровно по 8 бит), будем кодировать символы, которые встречаются чаще, меньшим числом бит, чем те, которые встречаются реже. Более того, потребуем, чтобы код был оптимален или, другими словами, минимально-избыточен.
Первым такой алгоритм опубликовал Дэвид Хаффман (David Huffman) [1] в 1952 году. Алгоритм Хаффмана двухпроходный. На первом проходе строится частотный словарь и генерируются коды. На втором проходе происходит непосредственно кодирование.
Стоит отметить, что за 50 лет со дня опубликования, код Хаффмана ничуть не потерял своей актуальности и значимости. Так с уверенностью можно сказать, что мы сталкиваемся с ним, в той или иной форме (дело в том, что код Хаффмана редко используется отдельно, чаще работая в связке с другими алгоритмами), практически каждый раз, когда архивируем файлы, смотрим фотографии, фильмы, посылаем факс или слушаем музыку.
Код Хаффмана
| (1) | ci не является префиксом для cj, при i!=j |
| (2) | 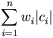 | минимальна (|ci| длина кода ci) |
называется минимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Замечания:
Известно, что любому бинарному префиксному коду соответствует определенное бинарное дерево.
Определение 2: Бинарное дерево, соответствующее коду Хаффмана, будем называть деревом Хаффмана.
Задача построения кода Хаффмана равносильна задаче построения соответствующего ему дерева. Приведем общую схему построения дерева Хаффмана:
Приведем пример: построим дерево Хаффмана для сообщения S=»A H F B H C E H E H C E A H D C E E H H H C H H H D E G H G G E H C H H».
Для начала введем несколько обозначений:
В списке, как и требовалось, остался всего один узел. Дерево Хаффмана построено. Теперь запишем его в более привычном для нас виде.
Листовые узлы дерева Хаффмана соответствуют символам кодируемого алфавита. Глубина листовых узлов равна длине кода соответствующих символов.
| A=0010bin | C=000bin | E=011bin | G=0101bin |
| B=01001bin | D=0011bin | F=01000bin | H=1bin |
Теперь у нас есть все необходимое для того чтобы закодировать сообщение S. Достаточно просто заменить каждый символ соответствующим ему кодом:
S / =»0010 1 01000 01001 1 000 011 1 011 1 000 011 0010 1 0011 000 011 011 1 1 1 000 1 1 1 0011 011 0101 1 0101 0101 011 1 000 1 1″.
Оценим теперь степень сжатия. В исходном сообщении S было 36 символов, на каждый из которых отводилось по [log2|A|]=3 бита (здесь и далее будем понимать квадратные скобки [] как целую часть, округленную в положительную сторону, т.е. [3,018]=4). Таким образом, размер S равен 36*3=108 бит
Итак, нам удалось сжать 108 в 89 бит.
Ясно, что следуя этому алгоритму мы в точности получим исходное сообщение S.
Канонический код Хаффмана
Как можно было заметить из предыдущего раздела, код Хаффмана не единственен. Мы можем подвергать его любым трансформациям без ущерба для эффективности при соблюдении всего двух условий: коды должны остаться префиксными и их длины не должны измениться.
Далее, для краткости, будем называть канонический код Хаффмана просто каноническим кодом.
Определение 4: Бинарное дерево, соответствующее каноническому коду Хаффмана, будем называть каноническим деревом Хаффмана.
В качестве примера приведем каноническое дерево Хаффмана для сообщения S, и сравним его с обычным деревом Хаффмана.
Выпишем теперь канонические коды для всех символов нашего алфавита в двоичной и десятичной форме. При этом сгруппируем символы по длине кода.
| B=00000bin=0dec | A=0001bin=1dec | C=010bin=2dec | H=1bin=1dec |
| F=00001bin=1dec | D=0010bin=2dec | E=011bin=3dec | |
| G=0011bin=3dec |
Убедимся в том, что свойства (1) и (2) из определения 3 выполняются:
Рассмотрим теперь три символа: A, D, G. Все они имеют код одной длины. Лексикографически A м уровне (имеет длину кода 3). Его порядковый номер на этом уровне равен 2 (учитывая два нелистовых узла слева), т.е. численно равен коду символа C. Теперь запишем этот номер в двоичной форме и дополним его нулевым битом слева (т.к. 2 представляется двумя битами, а код символа C тремя): 2dec=10bin=>0 10bin. Мы получили в точности код символа C.
Таким образом, мы пришли к очень важному выводу: канонические коды вполне определяются своими длинами. Это свойство канонических кодов очень широко используется на практике. Мы к нему еще вернемся.
Теперь вновь закодируем сообщение S, но уже при помощи канонических кодов:
Z / =»0001 1 00001 00000 1 010 011 1 011 1 010 011 0001 1 0010 010 011 011 1 1 1 010 1 1 1 0010 011 0011 1 0011 0011 011 1 010 1 1″
Т.к. мы не изменили длин кодов, размер закодированного сообщения не изменился: |S / |=|Z / |=89 бит.
Теперь приведем алгоритм декодирования (CANONICAL_DECODE) [5]:
Z / =»0001 1 00001 00000 1 010 011 1 011 1 010 011 0001 1 0010 010 011 011 1 1 1 010 1 1 1 0010 011 0011 1 0011 0011 011 1 010 1 1″
Итак, мы декодировали 3 первых символа: A, H, F. Ясно, что следуя этому алгоритму мы получим в точности сообщение S.
Это, пожалуй, самый простой алгоритм для декодирования канонических кодов. К нему можно придумать массу усовершенствований. Подробнее о них можно прочитать в [5] и [9].
Вычисление длин кодов
Для того чтобы закодировать сообщение нам необходимо знать коды символов и их длины. Как уже было отмечено в предыдущем разделе, канонические коды вполне определяются своими длинами. Таким образом, наша главная задача заключается в вычислении длин кодов.
Оказывается, что эта задача, в подавляющем большинстве случаев, не требует построения дерева Хаффмана в явном виде. Более того, алгоритмы использующие внутреннее (не явное) представление дерева Хаффмана оказываются гораздо эффективнее в отношении скорости работы и затрат памяти.
На сегодняшний день существует множество эффективных алгоритмов вычисления длин кодов ([3], [4]). Мы ограничимся рассмотрением лишь одного из них. Этот алгоритм достаточно прост, но несмотря на это очень популярен. Он используется в таких программах как zip, gzip, pkzip, bzip2 и многих других.
Вернемся к алгоритму построения дерева Хаффмана. На каждой итерации мы производили линейный поиск двух узлов с наименьшим весом. Ясно, что для этой цели больше подходит очередь приоритетов, такая как пирамида (минимальная). Узел с наименьшим весом при этом будет иметь наивысший приоритет и находиться на вершине пирамиды. Приведем этот алгоритм.
Будем считать, что для каждого узла сохранен указатель на его родителя. У корня дерева этот указатель положим равным NULL. Выберем теперь листовой узел (символ) и следуя сохраненным указателям будем подниматься вверх по дереву до тех пор, пока очередной указатель не станет равен NULL. Последнее условие означает, что мы добрались до корня дерева. Ясно, что число переходов с уровня на уровень равно глубине листового узла (символа), а следовательно и длине его кода. Обойдя таким образом все узлы (символы), мы получим длины их кодов.
Максимальная длина кода
Как правило, при кодировании используется так называемая кодовая книга (CodeBook), простая структура данных, по сути два массива: один с длинами, другой с кодами. Другими словами, код (как битовая строка) хранится в ячейке памяти или регистре фиксированного размера (чаще 16, 32 или 64). Для того чтобы не произошло переполнение, мы должны быть уверены в том, что код поместится в регистр.
Оказывается, что на N-символьном алфавите максимальный размер кода может достигать (N-1) бит в длину. Иначе говоря, при N=256 (распространенный вариант) мы можем получить код в 255 бит длиной (правда для этого файл должен быть очень велик: 2.292654130570773*10^53
=2^177.259)! Ясно, что такой код в регистр не поместится и с ним нужно что-то делать.
Для начала выясним при каких условиях возникает переполнение. Пусть частота i-го символа равна i-му числу Фибоначчи. Например: A-1, B-1, C-2, D-3, E-5, F-8, G-13, H-21. Построим соответствующее дерево Хаффмана.
Такое дерево называется вырожденным. Для того чтобы его получить частоты символов должны расти как минимум как числа Фибоначчи или еще быстрее. Хотя на практике, на реальных данных, такое дерево получить практически невозможно, его очень легко сгенерировать искусственно. В любом случае эту опасность нужно учитывать.
Эту проблему можно решить двумя приемлемыми способами. Первый из них опирается на одно из свойств канонических кодов. Дело в том, что в каноническом коде (битовой строке) не более [log2N] младших бит могут быть ненулями. Другими словами, все остальные биты можно вообще не сохранять, т.к. они всегда равны нулю. В случае N=256 нам достаточно от каждого кода сохранять лишь младшие 8 битов, подразумевая все остальные биты равными нулю. Это решает проблему, но лишь отчасти. Это значительно усложнит и замедлит как кодирование, так и декодирование. Поэтому этот способ редко применяется на практике.
Второй способ заключается в искусственном ограничении длин кодов (либо во время построения, либо после). Этот способ является общепринятым, поэтому мы остановимся на нем более подробно.
Существует два типа алгоритмов ограничивающих длины кодов. Эвристические (приблизительные) и оптимальные. Алгоритмы второго типа достаточно сложны в реализации и как правило требуют больших затрат времени и памяти, чем первые. Эффективность эвристически-ограниченного кода определяется его отклонением от оптимально-ограниченного. Чем меньше эта разница, тем лучше. Стоит отметить, что для некоторых эвристических алгоритмов эта разница очень мала ([6], [7], [8]), к тому же они очень часто генерируют оптимальный код (хотя и не гарантируют, что так будет всегда). Более того, т.к. на практике переполнение случается крайне редко (если только не поставлено очень жесткое ограничение на максимальную длину кода), при небольшом размере алфавита целесообразнее применять простые и быстрые эвристические методы.
Мы рассмотрим один достаточно простой и очень популярный эвристический алгоритм. Он нашел свое применение в таких программах как zip, gzip, pkzip, bzip2 и многих других.
Начнем работу с уровня L. Переместим узел RNL на место своего родителя. Т.к. узлы идут парами нам необходимо найти место и для соседного с RNL узла. Для этого найдем ближайший к L уровень j, содержащий листовые узлы, такой, что j < (L-1). На месте LNj сформируем нелистовой узел и присоединим к нему в качестве дочерних узел LNj и оставшийся без пары узел с уровня L. Ко всем оставшимся парам узлов на уровне L применим такую же операцию. Ясно, что перераспределив таким образом узлы, мы уменьшили высоту нашего дерева на 1. Теперь она равна (L-1). Если теперь L / < (L-1), то проделаем то же самое с уровнем (L-1) и т.д. до тех пор, пока требуемое ограничение не будет достигнуто.
Вернемся к нашему примеру, где L=5. Ограничим максимальную длину кода до L / =4.
Видно, что в нашем случае RNL=F, j=3, LNj=C. Сначала переместим узел RNL=F на место своего родителя.
Теперь на месте LNj=C сформируем нелистовой узел.
Присоединим к сформированному узлу два непарных: B и C.
Таким образом, мы ограничили максимальную длину кода до 4. Ясно, что изменив длины кодов, мы немного потеряли в эффективности. Так сообщение S, закодированное при помощи такого кода, будет иметь размер 92 бита, т.е. на 3 бита больше по сравнению с минимально-избыточным кодом.
Ясно, что чем сильнее мы ограничим максимальную длину кода, тем менее эффективен будет код. Выясним насколько можно ограничивать максимальную длину кода. Очевидно что не короче [log2N] бит.
Вычисление канонических кодов
Теперь присвоим коды остальным символам. Код первого символа на уровне i равен Si, второго Si + 1, третьего Si + 2 и т.д.
Выпишем оставшиеся коды для нашего примера:
| B = S5 = 00000bin | A = S4 = 0001bin | C = S3 = 010bin | H = S1 = 1bin |
| F = S5 + 1 = 00001bin | D = S4 + 1 = 0010bin | E = S3 + 1 = 011bin | |
| G = S4 + 2 = 0011bin |
Видно, что мы получили точно такие же коды, как если бы мы явно построили каноническое дерево Хаффмана.
Передача кодового дерева
Для того чтобы закодированное сообщение удалось декодировать, декодеру необходимо иметь такое же кодовое дерево (в той или иной форме), какое использовалось при кодировании. Поэтому вместе с закодированными данными мы вынуждены сохранять соответствующее кодовое дерево. Ясно, что чем компактнее оно будет, тем лучше.
Можно сохранить список частот символов (т.е. частотный словарь). С его помощью декодер без труда сможет реконструировать кодовое дерево. Хотя этот способ и менее расточителен чем предыдущий, он не является наилучшим.
Более того, этот метод можно несколько расширить. Мы можем применить алгоритм RLE не только к группам нулевых длин, но и ко всем остальным. Такой способ передачи кодового дерева является общепринятым и применяется в большинстве современных реализаций.
Реализация: SHCODEC
Приложение: биография Д. Хаффмана
 |
| Символ | Частота |
|---|---|
| ‘b’ | 3 |
| ‘e’ | 4 |
| ‘p’ | 2 |
| ‘ ‘ | 2 |
| ‘o’ | 2 |
| ‘r’ | 1 |
| ‘!’ | 1 |
После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета: 
Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
Повторим те же шаги и получим последовательно:
Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:
Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
Если мы так сделаем, то получим следующие коды для символов:
| Символ | Код |
|---|---|
| ‘b’ | 00 |
| ‘e’ | 11 |
| ‘p’ | 101 |
| ‘ ‘ | 011 |
| ‘o’ | 010 |
| ‘r’ | 1000 |
| ‘!’ | 1001 |
Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа. Например, если есть строка «101 11 101 11» и наше дерево, то мы получим строку «pepe».
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для ‘b’, то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на ‘b’.
На практике, при реализации данного алгоритма сразу после построения дерева строится таблица Хаффмана. Данная таблица — это по сути связный список или массив, который содержит каждый символ и его код, потому что это делает кодирование более эффективным. Довольно затратно каждый раз искать символ и одновременно вычислять его код, так как мы не знаем, где он находится, и придётся обходить всё дерево целиком. Как правило, для кодирования используется таблица Хаффмана, а для декодирования — дерево Хаффмана.
Входная строка: «beep boop beer!»
Входная строка в бинарном виде: «0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 000»
Закодированная строка: «0011 1110 1011 0001 0010 1010 1100 1111 1000 1001»
Как вы можете заметить, между ASCII-версией строки и закодированной версией существует большая разница.
Приложенный исходный код работает по тому же принципу, что и описан выше. В коде можно найти больше деталей и комментариев.
Все исходники были откомпилированы и проверены с использованием стандарта C99. Удачного программирования!
Чтобы прояснить ситуацию: данная статья только иллюстрирует работу алгоритма. Чтобы использовать это в реальной жизни, вам надо будет поместить созданное вами дерево Хаффмана в закодированную строку, а получатель должен будет знать, как его интерпретировать, чтобы раскодировать сообщение. Хорошим способом сделать это, является проход по дереву в любом порядке, который вам нравится (я предпочитаю обход в глубину) и конкатенировать 0 для каждого узла и 1 для листа с битами, представляющими оригинальный символ (в нашем случае, 8 бит, представляющие ASCII-код знака). Идеальным было бы добавить это представление в самое начало закодированной строки. Как только получатель построит дерево, он будет знать, как декодировать сообщение, чтобы прочесть оригинал.



