Уникальный идентификатор
Прежде чем переходить к следующему этапу нормализации, требуется применить к нашей таблице одно правило (оно же будет действовать для всех таблиц, которые мы создадим позднее).
У каждой сущности должен быть уникальный идентификатор, т.е. некоторый атрибут, имеющий следующие свойства:
Он уникален для каждого экземпляра сущности (т.е. во всех строках таблицы он не должен повторяться).
Для каждого экземпляра сущности он имеет значение в течение всего срока существования экземпляра в БД, причём это значение не меняется, пока экземпляр существует. Это означает, что данный столбец не может быть пустым; причём он заполняется в момент создания строки, и его значение не изменяется вплоть до удаления строки.
Например, название книги не может быть идентификатором. Вполне возможно появление двух книг с одинаковыми названиями. К тому же в названии книги может найтись опечатка, и его придётся подправить – а идентификатор не должен меняться.
Теоретически в качестве идентификатора можно выбрать даже несколько полей таблицы, при этом все вместе эти поля должны удовлетворять перечисленным выше требованиям. Так, вряд ли появятся две разные книги одного автора, одного названия и изданные в один год; поэтому из этих трёх полей можно бы сделать идентификатор. Но работать с ним было бы достаточно неудобно.
На ER-диаграммах названия идентифицирующих атрибутов обычно подчеркивают или помечают звездочкой. Иногда идентификаторы называют ключевыми полями или ключами.
(Интересно, что библиотекари тоже столкнулись с необходимостью такого идентифицирующего атрибута,. Поэтому каждая библиотечная книга имеет специальный “шифр” или “инфентарный номер”; он обычно подписывается на внутренней стороне обложки.)
Предметная область базы данных и ее модели
Информационная модель предметной области базы данных
Одним из ключевых моментов создания ИС с целью автоматизации информационных процессов организации является всестороннее изучение объектов автоматизации, их свойств, взаимоотношений между этими объектами и представление полученной информации в виде информационной модели данных.
Информационная модель предметной области базы данных содержит следующие основные конструкции:
Сущности, атрибуты и идентификаторы (ключи) сущности, домены атрибутов
Предметом информационной модели является абстрагирование объектов или явлений реального мира в рамках предметной области, в результате которого выявляются сущности (entity) предметной области. Как правило, они обозначаются именем существительным естественного языка.
Внимание! При представлении сущности в базе данных хранятся только ее атрибуты.
Одним из основных компьютерных способов распознавания сущностей в базе данных является присвоение сущностям идентификаторов (Entity identifier). Часто идентификатор сущности называют ключом. Задача выбора идентификатора сущности является семантически субъективной задачей. Поскольку сущность определяется набором своих атрибутов, то для каждой сущности целесообразно выделить такое подмножество атрибутов, которое однозначно идентифицирует данную сущность.
Различают однозначные и многозначные атрибуты. Однозначными являются атрибуты, которые в пределах конкретного экземпляра сущности имеют только одно значение. В противном случае они считаются многозначными.
На уровне информационного моделирования данных назначение домена атрибуту носит общий характер. Например, атрибут текстовый, числовой, бинарный, дата или «не определен». В последнем случае аналитик должен дать описание домена. На последующих стадиях тип домена конкретизируется, смысл понятия домена в логической и физической моделях базы данных уже, чем его может понимать аналитик. Это связано с тем, что в рамках физической модели базы данных домен реализуется посредством механизма ограничения домена, СУБД не понимает неопределенных доменов.
Отношения, связи
Выявление слабых сущностей и связанных с ними обязательных отношений необходимо для обеспечения целостности и согласованности данных. Так, например, неизвестному клиенту невозможно приписать заказ.
Подтипы и супертипы
Супертип с порожденными им подтипами является примером так называемой составной сущности. Составная сущность является логической конструкцией модели для представления набора сущностей и связей между ними как единого целого.
Пример. Сущность Автомобиль можно разбить на следующие подтипы: автомобили с приводом на два колеса, автомобили с приводом на четыре колеса, автомобили с переключаемым приводом.
Поэтому важно на ранней стадии проектирования установить, является ли наличие супертипов в модели необходимым. Для этого можно предпринять следующие действия:
Код атрибута в пределах одной сущности должен быть уникален
Мы опишем работу с ER-диаграммами близко к нотации Баркера, как довольно легкой в понимании основных идей. Данная глава является скорее иллюстрацией методов семантического моделирования, чем полноценным введением в эту область.
Основные понятия ER-диаграмм
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как «Поставщик», «Сотрудник», «Накладная».
Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Например, представителем сущности «Сотрудник» может быть «Сотрудник Иванов».
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности «Сотрудник» могут быть такие атрибуты как «Табельный номер», «Фамилия», «Имя», «Отчество», «Должность», «Зарплата» и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Графически связь изображается линией, соединяющей две сущности:

Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: «иметь», «принадлежать» и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:
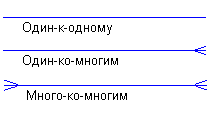
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:
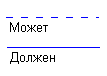
Модальность «может» означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность «должен» означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Связь может иметь разную модальность с разных концов (как на Рис. 4).
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так:
Слева направо: «каждый сотрудник может иметь несколько детей».
Справа налево: «Каждый ребенок обязан принадлежать ровно одному сотруднику».
Пример разработки простой ER-модели
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
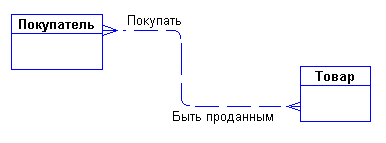
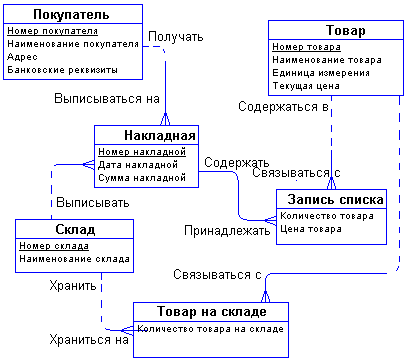
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Куда поместить сущности «Накладная» и «Склад» и с чем их связать? Спросим себя, как связаны эти сущности между собой и с сущностями «Покупатель» и «Товар»? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом:
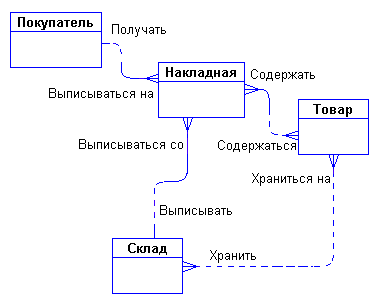
Точно также поступим со связью, соединяющей сущности «Склад» и «Товар». Введем дополнительную сущность «Товар на складе». Атрибутом этой сущности будет «Количество товара на складе». Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму:
Концептуальные и физические ER-модели
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы. Это означает, что диаграмма не учитывает особенности конкретной СУБД. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведенной на Рис. 9 может выглядеть, например, следующим образом:
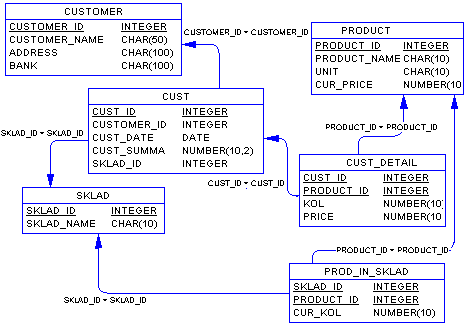
Легко заметить, что полученные таблицы сразу находятся в 3НФ.
Выводы
Реальным средством моделирования данных является не формальный метод нормализации отношений, а так называемое семантическое моделирование.
Диаграммы сущность-связь позволяют использовать наглядные графические обозначения для моделирования сущностей и их взаимосвязей.
Различают концептуальные и физические ER-диаграммы. Концептуальные диаграммы не учитывают особенностей конкретных СУБД. Физические диаграммы строятся по концептуальным и представляют собой прообраз конкретной базы данных. Сущности, определенные в концептуальной диаграмме становятся таблицами, атрибуты становятся колонками таблиц (при этом учитываются допустимые для данной СУБД типы данных и наименования столбцов), связи реализуются путем миграции ключевых атрибутов родительских сущностей и создания внешних ключей.
При правильном определении сущностей, полученные таблицы будут сразу находиться в 3НФ. Основное достоинство метода состоит в том, модель строится методом последовательных уточнений первоначальных диаграмм.
В данной главе, являющейся иллюстрацией к методам ER-моделирования, не рассмотрены более сложные аспекты построения диаграмм, такие как подтипы, роли, исключающие связи, непереносимые связи, идентифицирующие связи и т.п.
ИНФОЛОГИЧЕСКОЕ МОДЕЛИРОВАНИЕ
Инфологическая модель создается по результатам проведения исследований предметной области.
Инфологическая модель представляет собой описание будущей базы данных, представленное с помощью естественного языка, формул, графиков, диаграмм, таблиц и других средств, понятных как разработчикам БД, так и обычным пользователям.
Назначение такой модели состоит в адекватном описании процессов, информационных потоков, функций системы с помощью общедоступного и понятного языка, что делает возможным привлечение экспертов предметной области, консультантов, пользователей для обсуждения модели и внесения исправлений. В данном случае под созданием инфологической модели будем понимать именно ее создание для БД. В общем случае, инфологическая модель может создаваться для любой проектируемой системы и представляет ее описание (в общем случае в произвольной форме).
Создание инфологической модели является естественным продолжением исследований предметной области, но в отличие от него является представлением БД с точки зрения проектировщика (разработчика). Наглядность представления такой модели позволяет экспертам предметной области оценить ее точность и внести исправления. От правильности модели зависит успех дальнейшей разработки.
Инфологическую модель можно представить в виде словесного описания, однако наиболее наглядным является использование специальных графических нотаций, разработанных для проведения подобного рода моделирования.
Важно отметить, что создаваемая на этом этапе модель полностью не зависит от физической реализации будущей системы. В случае с БД это означает, что совершенно не важно где физически будут храниться данные: на бумаге, в памяти компьютера и кто или что эти данные будет обрабатывать. В этом случае, когда структуры данных не зависят от их физической реализации, а моделируются исходя из их смыслового назначения, моделирование называется семантическим.
Существует несколько способов описания инфологической модели, однако, в настоящее время одним из наиболее широко распространенных подходов, применяемых при инфологическом моделировании, является подход, основанный на применении диаграмм «сущность-связь» (ER – Entity Relationship). При рассмотрении последующих примеров будем использовать одну из самых распространенных в рамках ER моделей нотацию IDEF1X. Данный стандарт был разработан в 1993 г. Национальным институтом стандартизации и технологий и является федеральным стандартом обработки информации (США), описывающим семантику и синтаксис языка, правила и технологии для разработки логической модели данных.
Для построения инфологической модели важно знать элементы этой модели. Базовыми элементами модели сущность-связь являются сущности.
Сущность по форме представляет собой только некоторое реального описание объекта, точнее набор описаний его значимых признаков-атрибутов. Конкретный набор значений атрибутов объекта будет называться экземпляром сущности. 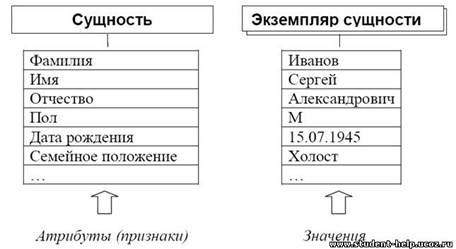
Рис. 1. Сущность и экземпляр сущности
Как видно из рис. 1, понятие «сущность» – означает форму информации, ее смысл. Понятие «элемент сущности» – отражает содержание.
Так, без наличия описания информации (т.е. сущности) будет трудно понять содержание следующей информации
| ИВАНОВ |
| СЕРГЕЙ |
| АЛЕКСАНДРОВИЧ |
| М |
| 15.07.1945 |
| ХОЛОСТ |
| . |
Это может быть как описанием объекта «сотрудник предприятия», так и описанием объекта «покупатель», или чем-то иным.
Поэтому, процесс выделения сущностей из автоматизируемой предметной области и их описание является ключевым для создания любых структур данных.
В качестве сущности может быть выбран не только объект, но и явление, процесс, трансформация, действие.
Если автоматизируется какой-либо процесс, то необходимо указать свойства этого процесса, объекты участвующие в этом процессе.
Пример. При автоматизации процесса покупки товаров (сущность «Покупка товаров») необходимо указать:
· какой товар необходимо купить (сущность «Товар»);
· у кого его необходимо купить (сущность «Продавец»);
· другие признаки операции покупка товара, такие как «количество», «цена», «сумма» и пр.
Отсюда следует, что сущности, выделенные из предметной области могут быть связанными между собой. Одна сущность может ссылаться на другую и даже быть признаком другой сущности более высокого уровня (так, сущность «сотрудник» может быть элементом или необходимым атрибутом сущности «организация»).
Понятие «связь» между сущностями представляет собой наличие какой-либо зависимости, ассоциации между сущностями – т.е. наличие информационной или логической связи между объектами автоматизируемой предметной области.
Существует множество видов сущностей и связей между ними.
Рассмотрим понятие их более подробно:
Итак, сущность – это реальный или воображаемый объект реального мира, имеющий существенное значение для рассматриваемой предметной области, информацию о котором необходимо хранить в БД. В некоторых случаях сущностью может являться событие, процесс или явление, имеющие место в реальном мире.
Фактически каждая сущность представляет собой множество подобных индивидуальных объектов, именуемых экземплярами. Имя сущности дается по имени ее экземпляра. Каждый экземпляр сущности индивидуален и должен отличаться от других экземпляров. Это отличие выражается в наличии у каждого экземпляра сущности уникальных свойств, называемых атрибутами.
Примерами сущностей могут быть Товар, Клиент, Покупатель. Наименование товара «Кирпич» является экземпляром сущности товар. Один и тот же объект реального мира может являться экземпляром нескольких сущностей. Так Иванов И.И. может быть как клиентом, так и покупателем, а также являться сотрудником фирмы.
Согласно нотации IDEF1X сущности изображаются в виде прямоугольников, как это показано на рис. 2.

Рис. 2. Пример изображения сущностей на ER диаграмме
Процесс выделения сущностей из автоматизируемой предметной области и их описание является ключевым для создания любых структур данных.
В качестве сущности может быть выбран не только объект, но и явление, процесс, действие.
Если автоматизируется какой-либо процесс, то необходимо указать свойства этого процесса, объекты участвующие в нем.
Например, при автоматизации процесса покупки товаров необходимо указать:
· какой товар необходимо купить (сущность «Товар»);
· у кого его необходимо купить (сущность «Продавец»);
· другие признаки: «Количество», «Цена», «Сумма» и пр. (сущность «Покупка товаров»).
Отсюда следует, что сущности, выделенные из предметной области могут быть связанными между собой. Одна сущность может ссылаться на другую и даже быть признаком другой сущности более высокого уровня (так, сущности «Товар» и «Продавец» могут быть элементами или необходимыми атрибутами сущности «Покупка товаров», сущность «Сотрудник» – элементом или необходимым атрибутом сущности «Организация»).
Понятие связь между сущностями представляет собой наличие какой-либо зависимости, ассоциации между сущностями – т.е. наличие информационной или логической связи между объектами автоматизируемой предметной области.
Ключевым моментом в методологии IDEF1X является взаимосвязь или отношения в которых находятся сущности. Форма взаимодействия одной сущности с другими является важной ее характеристикой. Различают два основных вида взаимодействия. Сущность является независимой если каждый ее экземпляр может быть однозначно идентифицирован без установления связей с другой сущностью. Сущность является зависимой (дочерней), если уникальная идентификация ее экземпляров возможна только путем установления связи с другой сущностью.
Например, сущности «Отдел» и «Сотрудник» являются независимыми, если предположить, что сотрудник может работать в организации, не числясь ни в одном отделе. Примером зависимой сущности может являться сущность «Заказ» в паре сущностей «Клиент»-«Заказ». Информация о заказе не имеет смысла без информации о клиенте его разместившем.
Согласно нотации IDEF1X независимые сущности изображаются в виде обычных прямоугольников, зависимые – в виде прямоугольников со скругленными углами, как это показано на рис.38. При нанесении на ER диаграмму сущности, необходимо руководствоваться следующими требованиями:
· сущность должна иметь наименование с четким смысловым значением и именоваться существительным в единственном числе.
· сущность должна обладать уникальным в пределах модели именем, имеющим четкое смысловое значение, выраженное в виде существительного в единственном числе, которое записывается над прямоугольником;
· именование сущности обычно производится по имени ее экземпляра, а единственное число облегчает в дальнейшем чтение модели.
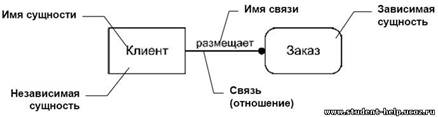
Рис. …. Пример изображения связей между сущностями в нотации IDEF1X
Сущность «Заказ» на рис.3 изображена в виде прямоугольника со скругленными углами, т.к. является зависимой от клиента. Зависимость эта обусловлена тем, что экземпляр сущности «Заказ» не может существовать, если не указан клиент, его разместивший. «Заказ» в свою очередь, может являться независимой по отношению к сущности «Состав заказа», содержащей информацию о наименованиях, количестве и стоимости заказанных товаров или услуг. В этом случае сущности «Заказ» и «Состав заказа» являются зависимыми и изображаются в виде прямоугольников со скругленными углами, сущность «Клиент», является независимой и изображается в виде обычного прямоугольника.
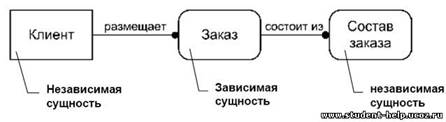
Рис. …. Изображение зависимых сущностей «Заказ» и «Состав заказа»
Таким образом, если сущность имеет несколько отношений с другими сущностями и при этом хотя бы в одном случае является зависимой, она изображается как зависимая.
Атрибут сущности – это именованная характеристика, являющаяся некоторым свойством сущности, значимым для рассматриваемой предметной области. Наименование атрибута должно быть выражено существительным в единственном числе и быть уникальным в пределах БД.
Примерами атрибутов могут являться «Номер клиента», «Имя клиента», «Номер заказа», «Дата заказа» и др. На ER диаграмме атрибуты помещаются внутри прямоугольника. В этом случае название сущности размещается за пределами прямоугольника. Ключевые атрибуты помещаются в списке атрибутов первыми и отделяются от неключевых горизонтальной линией (рис….).
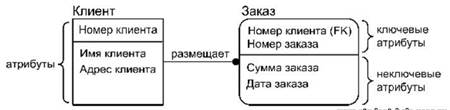
Рис. …. Отображение атрибутов сущности на ER диаграмме
На этапе инфологического моделирования мы скорее имеем дело с признаками сущности.
Признак – это обобщенная характеристика сущности, позволяющая описать ее свойства не вдаваясь в подробности.
На этапе инфологического моделирования признаки выступают в роли атрибутов. На этом этапе от разработчика не требуется проводить глубокий анализ сущности с целью выяснения всех ее атрибутов и их характеристик. Достаточно просто установить, что сущность обладает определенным набором признаков, которые необходимо выделить. В дальнейшем, при создании даталогической модели, признаки трансформируются в атрибуты, или наборы атрибутов, в зависимости от их сложности.
Ключ сущности – это атрибут или набор атрибутов, значения которых однозначно идентифицируют экземпляр сущности.
При инфологическом моделировании необходимо говорить о ключевых признаках. Таким образом, для идентификации сущности необходимо выделить ключевой признак.
Ключ сущности может быть сложным (составным), состоящим из нескольких атрибутов или признаков. При этом комбинация значений атрибутов, входящих в ключ, должна быть уникальной в пределах сущности. Выбор первичного ключа является очень важной и зачастую непростой задачей, от решения которой может зависеть эффективность будущей БД. Сложность выбора обусловлена тем, что, во-первых, значение ключевого атрибута должно быть уникальным в пределах сущности, а во-вторых, в одной сущности может существовать несколько атрибутов или их наборов, подходящих на роль ключа сущности. Такие атрибуты (наборы атрибутов) называются потенциальными ключами (кандидатами). Один атрибут или набор атрибутов из числа кандидатов должен быть выбран в качестве первичного ключа. При этом он должен удовлетворять следующим требованиям:
· уникальности – два экземпляра сущности не должны иметь одинаковых значений возможного ключа;
· компактности – составной ключ не должен содержать ни одного атрибута, удаление которого не приводило бы к утрате уникальности;
· значимости – атрибут ключа не должен быть пустым;
· постоянства – значение атрибутов ключа не должно меняться в течение всего времени существования экземпляра сущности.
Если существует несколько кандидатов на роль первичного ключа, предпочтение следует отдавать более простому (содержащему меньшее количество атрибутов) ключу. Ключи, входящие в список кандидатов, но не ставшие первичными называются альтернативными ключами. На ER диаграмме такие атрибуты помечаются символами (AK) после имени атрибута.
На рис. изображена сущность «Контрагент», в качестве потенциальных ключей которой можно выделить:
1. «Код контрагента» (АК1.1);
2. «Наименование контрагента» (АК2.1) + «Телефон» (АК2.2);
3. «Город контрагента» (АК3.1)+ «Адрес контрагента» (АК3.2).

Рис. …. Альтернативные ключи сущности «Контрагент»
Если учесть очень маленькую вероятность существования двух контрагентов с одинаковыми наименованиями и телефонами или расположенных в городах с одинаковыми названиями и по одинаковым адресам, то второй и третий варианты подойдут на роль первичного ключа, однако, существует еще первый вариант, который проще по составу чем второй и третий – «Код контрагента». Это «синтетический» атрибут, т.к. не имеет прямого отношения к сущности «Контрагент», ведь не существует единого классификатора всех контрагентов, в котором каждому из них соответствует свой уникальный номер. «Код контрагента» в данном случае – это номер, присвоенный ему в пределах данной организации.
С точки зрения теории баз данных использование атрибута «Код контрагента» в качестве ключевого неправильно, так как он не в состоянии обеспечить уникальности экземпляров сущности, ведь можно ввести дважды данные об одном и том же контрагенте, присвоив им при этом разные коды. При этом сущность окажется не только избыточной, но также может произойти нарушение целостности информации в БД вследствие использования в связанных с контрагентом сущностях информации об одном и том же контрагенте, ссылаясь на него при этом по разным номерам.
Иллюстрация такого случая приведена на рис.3.7. Видно, что всего было оформлено 3 заказа Контрагентом 1. Но, так как в списке контрагентов ему соответствуют коды 1 и 3, то в одном случае заказ был оформлен Контрагентом с кодом 1, а во втором – с кодом 3. С точки зрения СУБД Контрагент 1 с кодом 1 и Контрагент 1 с кодом 3 являются разными экземплярами. Если не исправить данное положение, то со временем это приведет к серьезным трудностям в обработке информации БД, связанной с получением итоговых сведений.
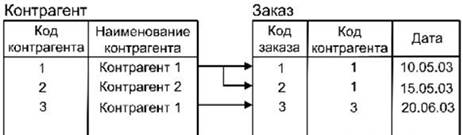
Рис. 3.7 Пример нарушения целостности информации базы данных
Тем не менее, на практике, в силу особенностей реализации технологий реляционных СУБД, используется именно такой подход, при котором очень часто в качестве первичного ключа сущности используется именно суррогатный ключ (код или номер), а контроль целостности информации и избыточность остаются либо «на совести» пользователя, от которого требуется повышенное внимание при добавлении информации в БД, либо «на совести» программиста, реализующего различные блокировки.
Следующим важным понятием в методе «сущность-связь» является понятие отношения между сущностями.
Отношение (связь) – это некоторая ассоциация (логическое соотношение) между двумя сущностями, предполагающая зависимость между атрибутами этих сущностей.
Связи позволяют по одной сущности находить другие сущности, связанные с ней. Название связи обычно представляется глаголом или глагольной фразой (отглагольным существительным), которая выражает некоторое ограничение или бизнес-правило и облегчает чтение диаграммы. Изображенная на рис. связь позволяет определить какие именно заказы разместил клиент и какой именно сотрудник оформил заказ. Глагольные фразы облегчают понимание смысла связи и могут быть созданы как для прямого, так и для обратного чтения связи. Так, в примере, представленном на рис. связь между сущностями «Клиент» и «Заказ» может быть прочитана следующим образом: Клиент размещает Заказ, Заказ размещается Клиентом. Обычно достаточно создания одной глагольной фразы для чтения связи в направлении от независимой сущности к зависимой, исключением являются связи типа многие-ко-многим, при которых для лучшего понимания типа связи желательно создание двух глагольных фраз.
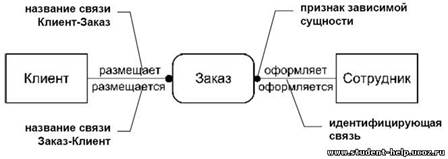
Пример изображения связи на ER диаграмме
На этапе инфологического моделирования используют идентифицирующие и неидентифицирующие связи. Выше было сказано о том, что существуют зависимые и независимые сущности. Тип связи между двумя сущностями определяет какая из них является зависимой (дочерней), а какая – независимой (родительской).
Идентифицирующая связь устанавливается между родительской и дочерней сущностями и означает, что каждому экземпляру дочерней сущности должен соответствовать хотя бы один экземпляр родительской. При этом дочерняя сущность не может существовать «вне рамок» родительской. На ER диаграммах идентифицирующая связь показывается в виде сплошной линии. Точка на линии ставится со стороны дочерней сущности (рис.43). Неидентифицирующая связь устанавливается между двумя независимыми сущностями и означает, что каждый экземпляр дочерней сущности может быть идентифицирован без использования экземпляра родительской сущности. На ER диаграммах неидентифицирующая связь показывается в виде пунктирной линии (рис.44).
Пусть даны две сущности «Материал» и «Единица измерения». Если предположить, что при учете материалов в БД можно не указывать единицу измерения данного материала, то сущности «Материал» и «Единица измерения» являются независимыми, а связь между ними – неидентифицирующей (рис.44).
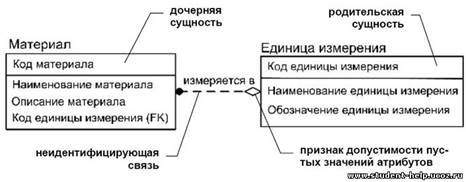
Пример неидентифицирующей связи между сущностями
Связь между сущностями обеспечивается за счет миграции атрибутов родительской сущности в дочернюю.
Миграция – перенос атрибутов одной сущности в другую для установления связи между ними.
Мигрировавший атрибут называется внешним ключом и помечается на ER диаграмме символами (FK) (Foreign Key). Мигрировавший атрибут или группа атрибутов могут быть помещены в состав первичного ключа сущности или в состав неключевых атрибутов в зависимости от типа связи между сущностями. При этом действуют следующие правила:
· если сущности связаны идентифицирующей связью, то все ключевые атрибуты родительской сущности мигрируют в состав первичного ключа дочерней сущности (рис.40);
· если сущности связаны неидентифицирующей связью, то все ключевые атрибуты родительской сущности мигрируют в состав неключевых атрибутов дочерней сущности (рис.44).
При этом возможны два варианта отношений:
Допускаются пустые значения внешних ключей в дочерней сущности (знак ромба на неидентифицирующей связи со стороны независимой сущности).
Пустые значения внешних ключей в дочерней сущности не допускаются (отсутствие знака ромба со стороны независимой сущности).
Каждая связь, независимо от того, является ли она идентифицирующей или нет обладает мощностью.
Мощность связи (cardinality) – характеристика связи между сущностями, предназначенная для обозначения отношения числа экземпляров родительской сущности к числу экземпляров дочерней.
Существует четыре различных типа мощности (рис.45):
1. Одному экземпляру родительской сущности соответствуют 0, 1 или много экземпляров дочерней сущности. Не помечается дополнительным значком на диаграмме.
2. Одному экземпляру родительской сущности соответствуют 1 или много экземпляров дочерней сущности (исключено нулевое значение). На диаграмме помечается значком P.
3. Одному экземпляру родительской сущности соответствуют 0 или 1 экземпляр дочерней сущности (исключены множественные значения). На диаграмме помечается значком Z.
4. Одному экземпляру родительской сущности соответствует заранее заданное число экземпляров дочерней сущности. На диаграмме помечается цифрой.
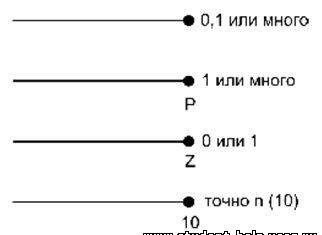
Обозначение мощности в нотации IDEF1X
Существует еще одна, не вошедшая в приведенный выше перечень, мощность связи – многие-ко-многим. Такая связь возможна только на логическом уровне представления модели и означает, что каждому экземпляру родительской сущности может соответствовать несколько экземпляров дочерней, а каждому экземпляру дочерней – несколько экземпляров родительской.
В этом случае понятия «родительская» и «дочерняя» применимы к обоим связываемым сущностям. На диаграмме такая связь обозначается сплошной линией с двумя точками на концах. Обе сущности, участвующие в связи обозначаются как независимые. Пример такой связи приведен на рис.46. В данном случае, в отгрузку могут быть включены несколько товаров, в то же время один товар может участвовать в нескольких отгрузках.
Особой разновидностью связей является категориальная связь, используемая для описания структур, в которых сущность является типом (категорией) другой сущности. При этом родительская сущность (родовой предок) содержит общие свойства, присущие дочерним (категориальным) сущностям. Категориальную связь, называемую иногда иерархией наследования создают тогда, когда несколько сущностей имеют общие по смыслу атрибуты, либо когда сущности имеют общие по смыслу связи, либо когда это диктуется бизнес-правилами. Для каждой категории можно указать дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой.
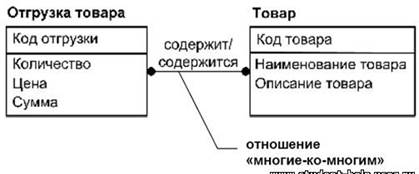
Пример связи «многие-ко-многим»
В качестве примера рассмотрим следующий случай: допустим, известно, что при оформлении операций, связанных с перемещением товарно-материальных ценностей в организации используется два вида накладных: приходная и расходная. В данном случае сущность «Накладная» является родительской, так как объединяет общие для обеих сущностей атрибуты, а сущности «Приходная» и «Расходная» содержат информацию об особенностях накладных каждого вида. Дискриминатором в данном случае будет вид накладной (рис.47).
Категориальные связи делятся на два типа – полные и неполные. Если экземпляру родового предка соответствует экземпляр в каком-либо потомке, то связь является полной, на ER диаграмме изображается с помощью дискриминатора (рис.47). Если категория еще не выстроена полностью и в родовом предке есть экземпляры, для которых нет соответствующих экземпляров в потомках, категория является неполной, на ER диаграмме изображается с помощью дискриминатора (рис.47). Возможны иерархии наследования, в которых присутствуют и полные и неполные категории. При этом сущности, в одном случае являющиеся потомками, могут одновременно являться предками по отношению к другим связям.
В примере, изображенном на рис.47 первая категориальная связь (вид накладной) является полной, т.к. существует только два вида накладных: приходная и расходная. Тип расходной накладной является неполной категориальной связью, т.к. предполагается, что сюда включены еще не все сущности данной категории (например отгрузка материалов на сторону или списание материалов). Отсутствие сущности на диаграмме может быть обусловлено тем, что еще не выявлено ее существование в рамках данной модели, не установлен ее тип или ее существование внутри модели нежелательно.
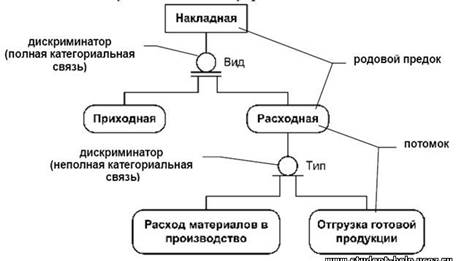
Пример полной и неполной категориальной связи



