Cluster Shared Volumes в Windows Server 2012 R2 (часть 2)
Продолжаем тему Cluster Shared Volumes в Windows Server 2012 R2. В предыдущей статье мы затронули общий принцип работы, сегодня же посмотрим на CSV с более практической точки зрения. Для опытов у меня как раз завалялся 🙂 3-х узловой кластер с общим диском, который и будет использоваться под CSV.
Создание CSV
Запускаем оснастку Failover Cluster Manager, открываем нужный кластер, переходим в раздел Storages — Disks и выбираем Cluster Disk 1. Обратите внимание, что он отображается как доступное хранилище (Available Storage), в качестве файловой системы у него NTFS
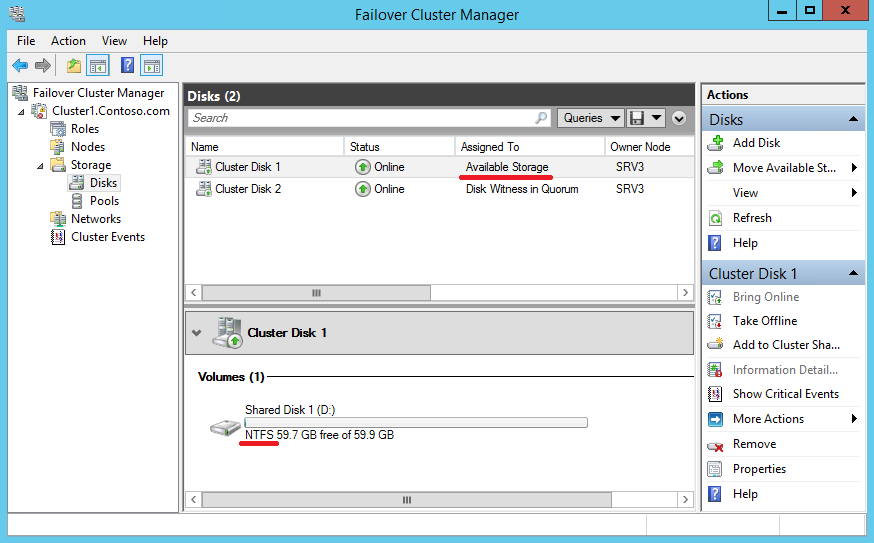
а в проводнике он виден как обычный логический диск.
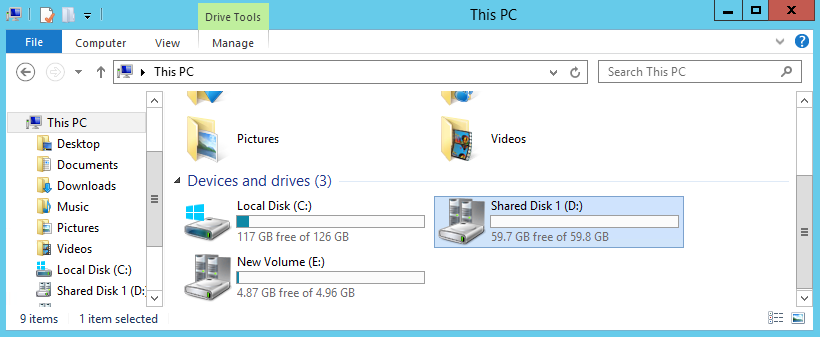
Теперь кликаем на диске правой клавишей мыши и в контекстном меню выбираем пункт «Add to Cluster Shared Volumes».
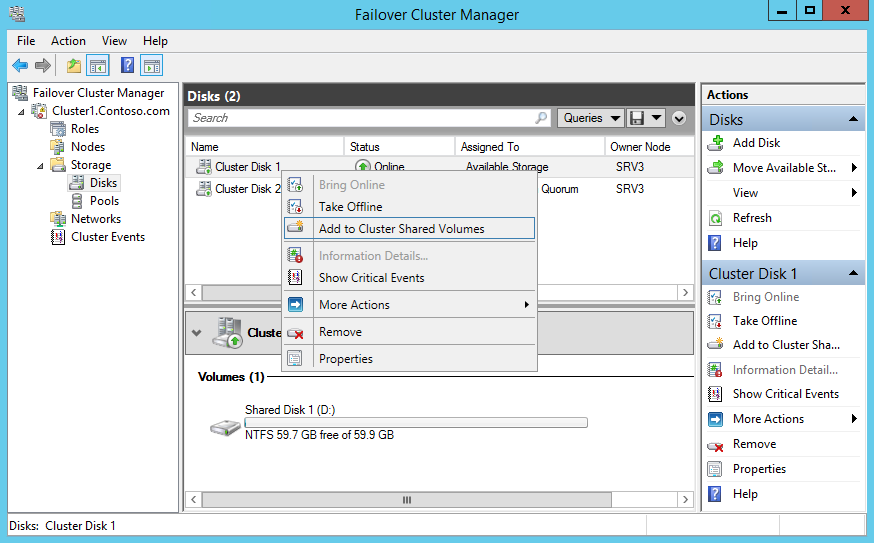
После преобразования диск отображается как общий кластерный том (Cluster Shared Volume), а в качестве файловой системы у него CSVFS. Впрочем на самом деле файловая система осталась прежней, а CSVFS показана лишь для того, чтобы администратору и приложениям проще различать обычные и CSV тома.
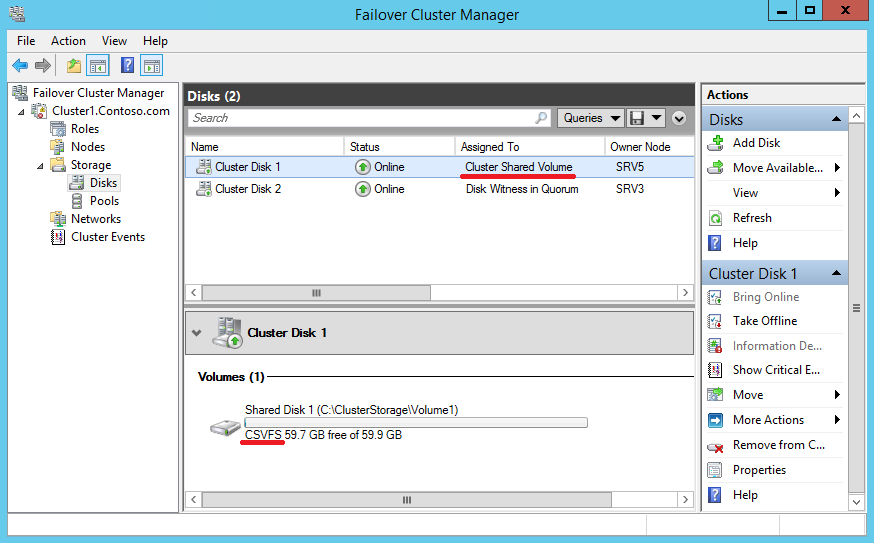
В проводнике же диск теперь виден не как обычный том, а как подключенная папка. Все диски после добавления в CSV отображаются на всех узлах кластера как подкаталоги в папке %systemdrive%\ClusterStorage и по умолчанию именуются как Volume1, Volume2 и т.д. Так в нашем случае общий том имеет путь C:\ClusterStorage\Volume1. Каталог Volume1 при желании можно переименовать, дав ему более осмысленное название, а вот папку ClusterStorage нельзя ни в коем случае трогать.
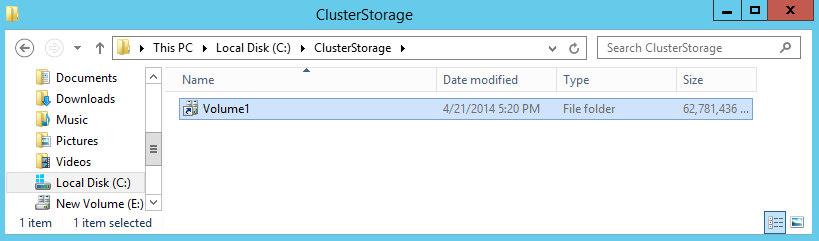
Удалить диск из CSV так же просто, как и добавить — надо просто открыть контекстное меню для диска и выбрать «Remove from Cluster Shared Volumes».
Не забываем о PowerShell. Добавить диск в CSV можно командой:
Ну а удалить, соответственно:
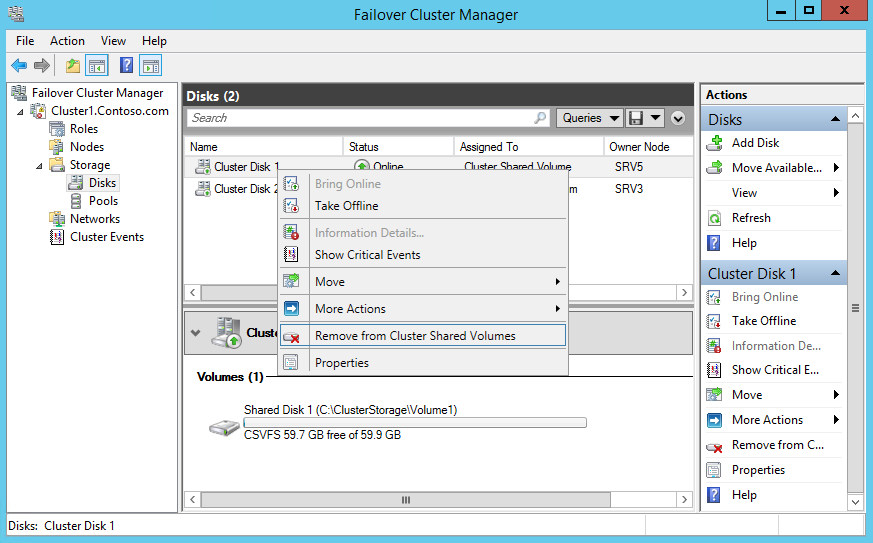
И еще один интересный момент. На каждом узле кластера с CSV создается скрытая административная шара с именем ClusterStorage$. Она доступна только для членов группы администраторов, на нее можно зайти удаленно по пути \\«имя кластера»\ClusterStorage$, в нашем случае это \\Cluster1\ClusterStorage$.
Режимы работы CSV
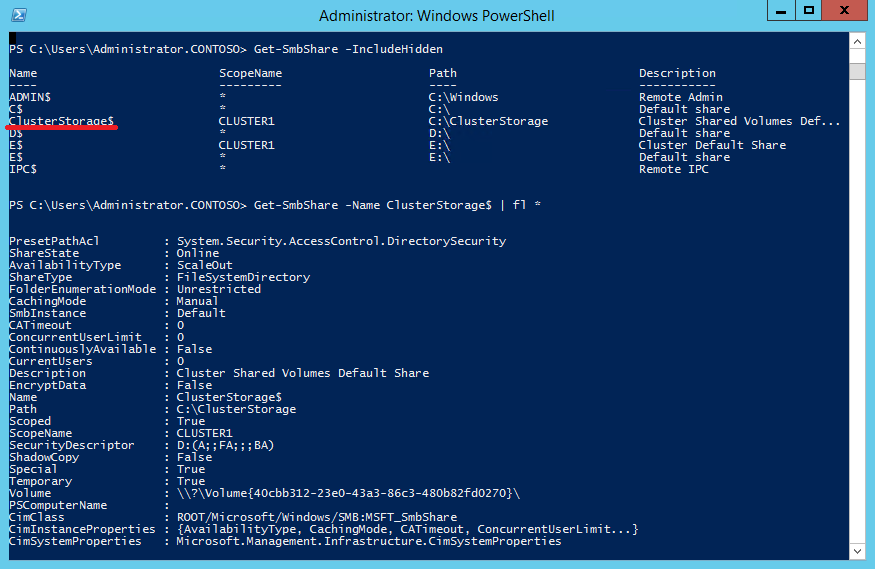
Теперь рассмотрим более подробно режимы работы CSV. Для начала выведем имеющиеся в наличии тома CSV командой:
А затем выведем состояние тома:
Как видите, сейчас все узлы работают в штатном режиме (Direct), без перенаправления.
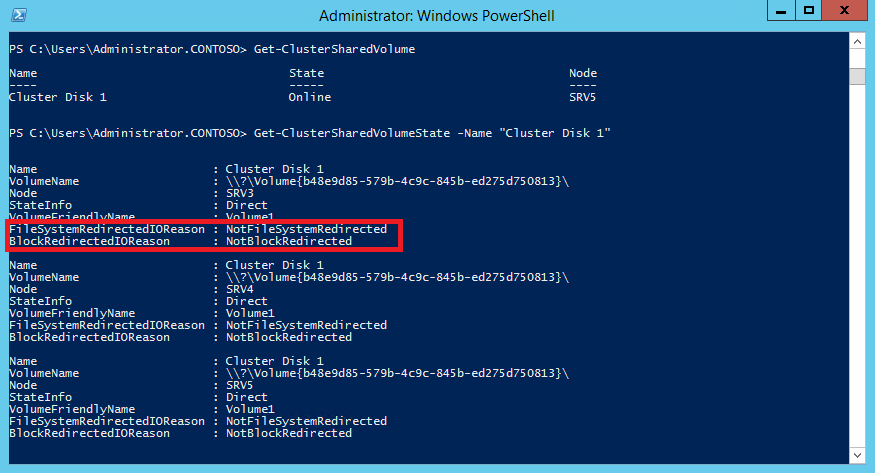
Теперь переведем наш CSV в режим перенаправления (File System Redirected mode). В этом режиме все операции, как с данными так и с метаданными будут производиться только через узел-координатор.
Для включения перенаправления надо выбрать нужный том CSV, кликнуть на нем правой клавишей и нажать «Turn On Redirected Access».
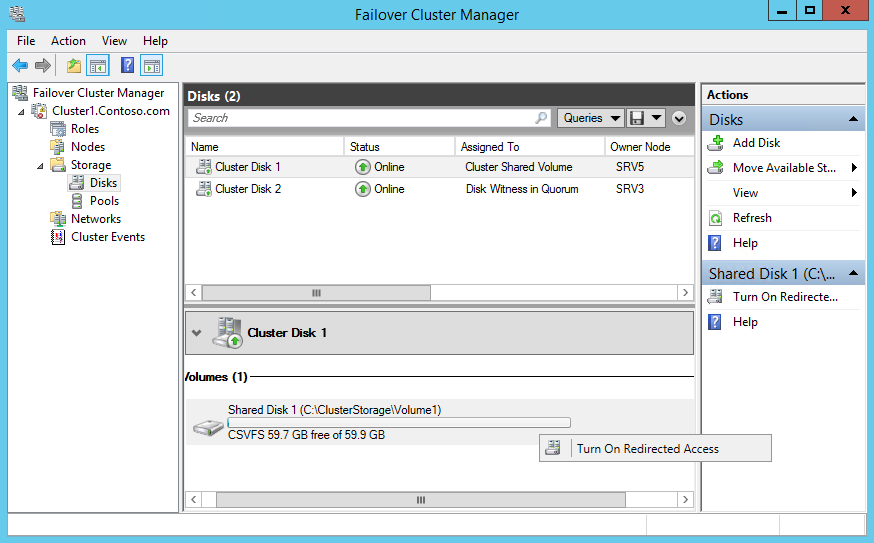
Также можно включить перенаправление из PowerShell, командой:
Теперь CSV на всех узлах кластера находится в состоянии FileSystemRedirected, а в качестве причины указан запрос пользователя (UserRequest).
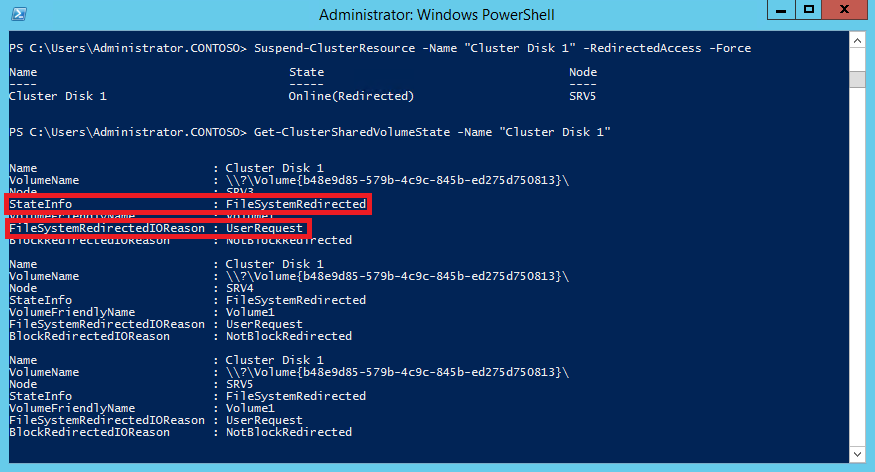
Для выключения режима перенаправления надо также кликнуть мышкой на томе и нажать на Turn off Redirected Access, либо выполнить команду:
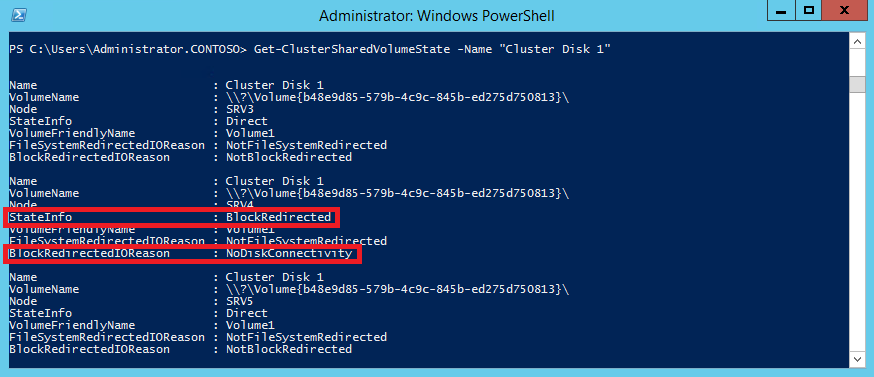
И остается еще один режим перенаправления блочного доступа (Block Redirected), при котором узел не имеет прямого доступа к хранилищу, а блочные данные передаются по сети через узел-координатор. Для активации этого режима отключим на узле кластера SRV4 сетевой интерфейс, отвечающий за подключение к дисковому хранилищу.
Как видите, теперь узел SRV4 находится в режиме BlockRedirected, а причиной переключения является отсутствие прямого подключения к диску (NoDiskConnectivity). Как только подключение к диску будет восстановлено, узел перейдет в нормальный режим работы.
Заключение
В заключение скажу, что сфера применения общих кластерных томов не особенно широка. Изначально CSV предназначены исключительно для хранения виртуальных дисков Hyper-V. Начиная с Windows Server 2012 на базе CSV можно создавать отказоустойчивые файловые сервера (SOFS). Также SQL Server 2014 вроде как позволяет размещать базы данных на томах CSV.
Хотя в принципе можно хранить на CSV и другие типы файлов, не стоит размещать на CSV обычную файловую шару. CSV не очень подходит для нагрузок, связанных с созданием большого объема изменений метаданных — созданием, удалением, копированием и переименованием файлов.
Распределенные файловые системы. Технологический обзор. Продуктовый обзор
Файловая система (file system) — это способ организации, хранения и именования данных на носителях информации в компьютерах. Файловые системы используются также в другом электронном оборудовании: в цифровых фотоаппаратах и диктофонах, в мобильных телефонах, и т. п.
Распределенные файловые системы (distributed file system) работают сразу на многих компьютерах (серверах) с репликацией для защиты от сбоев. Иногда «распределенными» также называют сетевые файловые системы, тем самым показывая, что распределенные файловые системы имеют больше возможностей, чем обычная передача данных по сети. Носители СХД, связанные с распределенными файловыми системами, могут (и даже должны) быть распределены между многими компьютерными системами.
Определения
Существует также понятие «кластерная файловая система». Различия между всеми этими терминами (сетевая, распределенная, кластерная) немного расплывчаты. Поэтому сначала нужно определить, что такое сетевая, кластерная и распределенная система.
С таким определением, например, NFSv3 можно отнести к сетевой файловой системе (network file system). GFS2 – это кластерная файловая система. GlusterFS – это распределенная файловая система. NFSv4, в свою очередь, это некий гибрид между сетевой файловой системой, но с поддержкой нескольких серверов, внедренных в нее.
Сумятицу иногда вносит то, что иногда вкладывается разный смысл в понятие «распределенный» (distributed). Здесь надо понимать, что «распределенность» должна присутствовать не только между серверами (тогда это кластер) в локальной сети, но также и между местоположениями этих серверов в глобальной сети (WAN), со всеми присущими ей особенностями. А именно: большими задержками и низкой надежностью соединений.
Распределенные (в таком определении) файловые системы состоят из нескольких географически разнесенных серверов, соединенных по модели sharing nothing, где каждый активный сервер имеет собственную СХД. Кроме того, распределенные файловые системы делятся на два типа: параллельные системы (Parallel file systems) и полностью параллельные файловые системы (Fully parallel file systems).
Так называются системы, которые предоставляют параллельный доступ к их серверам хранения для каждого клиента. Это позволяет устранить «узкие места» одного сервера по всем параметрам: IOPS, полоса, ограничения вычислительной способности процессора и кэш-памяти. Такие системы используются в высокопроизводительных компьютерных системах и бизнес-приложениях, например, в информационных системах фондовых бирж, Примеры: pNFS, Lustre.

Сравнение между сетевой и распределенной файловой системой на примере Lustre (источник: https://www.atipa.com/lustre-parallel-storage)
Полностью параллельными такие системы называются в том случае, когда не только данные, но и метаданные (различные индексы и пр.), также распределяются параллельно между всеми клиентами. Примеры таких систем – OrangeFS и Ceph.
Соотношения между сетевыми системами (Network), кластерными системами (Cluster), распределенными (Distributed), а также параллельными (Parallel) и полностью параллельными системами (Fully parallel) могут быть представлены следующим образом.

Соотношения между видами и типами распределенных (distributed file system) файловых систем (источник: lvee.org/en/abstracts/33)
С какой целью создавались распределенные файловые системы и какие задачи они решают
Во-первых, как уже указывалось, они нужны для защиты от сбоев и облегчения масштабирования СХД. Большое значение имеет API (Application Programming Interface), который они обеспечивают. Это значит, что каждое приложение, скрипт или библиотека стандартных подпрограмм, написанные в течение последних нескольких десятков лет, могут использовать распределенную файловую систему без коррекций их кода, без процедур импорта и экспорта данных. Даже такие решения, как SQL, не могут сравниться с универсальностью и простотой API распределенных файловых систем.
Во-вторых, распределенные файловые системы стали настолько популярными, что, используя их, мы иногда этого и не замечаем. Например, стриминг фильмов с сайта популярных видеохостингов (того же YouTube) почти всегда делается через распределенные файловые системы.
При производстве анимационных фильмов модели сцен и рендерные части в процессе производства почти всегда централизованно хранятся в распределенной файловой системе.
Виртуальные «блочные устройства» в облаке на самом деле часто являются файлами в распределенной файловой системе.
Системы распределенных вычислений в крупных научных лабораториях, таких как ЦЕРН, часто состоящие из более чем 100 тысяч процессоров, используют распределенные файловые системы для хранения данных экспериментов и результатов их обработки.
Можно сказать, что распределенные файловые системы – это то, как сегодня хранятся большинство данных, особенно «неструктурированных», которые используются при анализе «больших данных» (Big Data). Без этих систем провайдерам было бы очень сложно предоставлять различные онлайновые и медиауслуги.
Как пример можно было бы привести неудачу широко рекламировавшейся в свое время услуги «интернет-телевидения» (IPTV). Для того, чтобы ей воспользоваться, нужно было провести ряд сетевых настроек, которые любому IT-шнику могут показаться элементарными (например, «маска подсети» и пр.), но для простого обывателя они являлись отпугивающим фактором, несмотря на возможность смотреть «100 фильмов за 100 рублей в месяц». В результате эта услуга, что называется, «не пошла». Распределенные файловые системы с удобным интерфейсом как раз и помогают решить эти проблемы. Пример – любой популярный видеохостинг, либо пакет онлайн-телевидения от интернет-провайдера (например, «ОнЛайм» от Ростелекома).
Для различных предприятий и организаций распределенные файловые системы помогут решить проблемы управления данными и снизить стоимость хранения данных.
Распределенные файловые системы – кто они?
Учитывая сказанное выше об определениях, к распределенным файловым системам различные источники относят много систем, причем разные источники могут давать разные непересекающиеся списки. Ниже приведен неполный список из разных источников.
Продуктовый обзор
ZFS, IBM GPFS (Spectrum Scale), Ceph, Lustre
Файловая система ZFS была разработана в 2001 году в компании Sun Microsystems, приобретенной компанией Oracle в 2010 году. Аббревиатура ZFS означала «Zettabyte File System» (файловая система для объемов зеттабайт). Однако в настоящее время ZFS может хранить данные много большего объема.
Эта система проектировалась с очень большим запасом по параметрам, на основе совершенно справедливого прогноза огромного роста данных, подлежащих хранению в распределенных системах в будущем.
ZFS от Oracle и открытая система OpenZFS пошли разными путями, с тех пор, как Oracle закрыл проект OpenSolaris. OpenZFS — это общий проект, объединяющий разработчиков и компаний, которые используют файловую систему ZFS и работают над ее совершенствованием, чтобы сделать ZFS более широко используемым продуктом с открытым исходным кодом.
Некоторые теоретические пределы параметров, заложенные при проектировании ZFS:
Функции ZFS
ZFS обладает рядом полезных функций:
Хранение в пулах (Pooled storage)
В отличие от большинства файловых систем, ZFS объединяет функции файловой системы и менеджера томов (volume manager). Это означает, что ZFS может создавать файловую систему, которая будет простираться по многим группам накопителей ZVOL или пулам. Более того, можно добавлять емкость в пул простым добавлением нового накопителя. ZFS сама выполнит партицию и форматирование нового накопителя.

Пулы хранения в ZFS
В пулах можно легко создавать файловые системы (области хранения данных) для каждого приложения и предмета использования.
Копирование при записи (Copy-on-write)
В большинстве файловых систем при перезаписи данных на то же физическое место носителя ранее записанные там данные теряются навсегда. В ZFS новая информация пишется в новый блок. После окончания записи метаданные в файловой системе обновляются, указывая на местоположение нового блока. При этом, если в процессе записи информации с системой что-то происходит, старые данные будут сохранены. Это означает, что не нужно запускать проверку системы после аварии.
Снапшоты (Snapshots)
Copy-on-write закладывает основу для другой функции ZFS: моментальных снимков системы (снапшотов). ZFS использует для отслеживания изменений в системе.
Снапшот содержит оригинальную версию файловой системы, и в «живой» файловой системе присутствуют только изменения, которые были сделаны с момента последнего снапшота. Никакого дополнительного пространства не используется. Когда новые данные записываются в «живую» систему, выделяются новые блоки для сохранения этих данных.
Если файл удаляется, то ссылка на него в снапшоте тоже удаляется. Поэтому снапшоты в основном предназначены для отслеживания изменений в файлах, а не для добавления или создания файлов.
Снапшоты могут устанавливаться в режим read-only (только чтение), чтобы восстановить прежнюю версию файла. Также можно сделать откат «живой» системы на предыдущий снапшот. При этом будут потеряны только те изменения, которые были сделаны после момента этого снапшота.
Верификация целостности данных и автоматическое восстановление данных
При любой записи данных в ZFS создается контрольная сумма (checksum). При считывании данных, происходит сверка с этой контрольной суммой. Если проверка показывает расхождение с контрольной суммой, то ZFS устраняет ошибку считывания.
В традиционных файловых системах данные не могут быть восстановлены, если повреждение данных затрагивает область контрольной суммы. В ZFS данные и контрольная сумма физически разделены и данные могут быть восстановлены из блока высокого уровня.

Верификация целостности и автоматическое восстановление данных в ZFS
RAID-Z
ZFS может создавать RAID-массивы без необходимости использования дополнительного программного или аппаратного обеспечения. Поэтому неудивительно, что ZFS имеет собственный вариант RAID: RAID-Z.
RAID-Z представляет собой вариант RAID-5, котором предусмотрены средства преодоления ошибки write hole error, присущей RAID-5, когда данные и информация о паритете становятся не соответствующими друг другу после случайного перезапуска системы.
RAID-Z имеет три уровня: RAID-Z1, в котором нужно по крайней мере два диска для хранения и один для паритета; RAID-Z2, который требует по крайней мере двух дисков для хранения и двух для паритета; RAID-Z3 требует по крайней мере двух дисков для хранения и трех для паритета.
Добавление дисков в пул RAID-Z делается попарно.
Автоматическая замена на запасной диск (Hot spare)
В пуле хранения, сконфигурированном с запасным диском, отказавший диск автоматически заменяется запасным.

Автоматическая замена дисков при отказе
Один и тот же диск может быть запасным для нескольких пулов сразу.
При создании ZFS преследовалась цель сделать их «последним словом» в файловых системах. Во времена, когда большинство файловых систем были 64-битными, создатели ZFS решили, что лучше сразу заложить адресное пространство на 128 бит для будущего развития. Это означает, что ZFS имеет емкость в 16 миллиардов раз большую емкость, чем 32- или 64-битные системы. Создатель ZFS Джефф Бонвик (Jeff Bonwick), характеризуя величину этой емкости, сказал, что система в полной конфигурации с такой емкостью потребует для электропитания энергию, достаточную, чтобы вскипятить все океаны в мире.
IBM Spectrum Scale
Объем создаваемых, хранимых и анализируемых данных в мире возрастает экспоненциально. Часто требуется анализировать информацию быстрее конкурентов, причем в условиях роста собственной IT-инфраструктуры.
Файловая система в СХД организации должна поддерживать как большие данные (Big Data), так и традиционные приложения. IBM Spectrum Scale™ решает широкий спектр задач, и представляет собой высокопроизводительное решение для управления данными со встроенными функциями архивирования и аналитики.
IBM Spectrum Scale – это универсальная программно-конфигурируемая система хранения корпоративного класса, которая работает со многими типами носителей и автоматически переводит данные с уровня на уровень в зависимости от частоты их использования, обеспечивая отказоустойчивость, масштабируемость и управляемость.
Это решение, созданное на основе файловой системы IBM General Parallel File System (GPFS), способно масштабировать емкость и производительность для аналитических систем, репозиториев контента и других задач.
Когнитивные механизмы IBM умеют распределять данные среди различных устройств хранения, тем самым оптимизируя использование доступной емкости, упрощая администрирование и обеспечивая высокую производительность. IBM Spectrum Scale поддерживает глобального пространства имен с универсальным доступом, которое объединяет современные средства для работы с файлами, размещенных в сетевых файловых системах (NFS), блочные хранилища и серверы со встроенными хранилищами данных большого объема. Файловая система IBM Spectrum Scale может использоваться для работы с файлами (POSIX, NFS, CIFS), объектами (S3, SWIFT) и распределенной файловой системой Hadoop (HDFS) при решении задач анализа больших данных на месте хранения.

Задачи и возможности IBM Spectrum Scale.
Свойства IBM Spectrum Scale
Хорошая масштабируемость, которая позволяет обеспечивать максимальную пропускную способность и минимальные задержки при доступе.
Аналитика с учетом данных, позволяющая автоматически переносить данные на оптимальный уровень хранения (флеш, диск, кластер, лента), что позволяет до 90 % снизить расходы на архивирование данных.

Автоматическое размещение данных по уровням в файловой системе IBM Spectrum Scale
Распределенность, то есть возможность доступа к данным из любого места, ускоряет работу приложений по всему миру, за счет технологии распределенного кэширования и активного управления файлами.
Безопасность данных, технологии идентификация, шифрования, защиты Erasure Coding и репликации позволяют достичь соответствия регулятивным требованиям.
Универсальность, единое решение для управления масштабируемым хранилищем данных, обеспечивающее унификацию виртуализации, поддержки аналитических сред, обработки файлов и объектов.
Прозрачные политики хранения делают возможным сжатие и многоуровневое хранение данных на ленточных накопителях или в облаке, с целью сокращения расходов. Размещение данных с учетом места их использования уменьшает задержки и увеличивает производительность работы с данными.
Интеллектуальное кэширование данных, технология Active File Management (AFM) распространяет глобальное пространство имен Spectrum Scale за пределы географических границ, обеспечивая высокую производительность при чтении и записи данных и автоматическое управление пространством имен. Данные записываются или изменяются локально и в других местах эти данные получают с минимальной задержкой.
Графический интерфейс IBM Spectrum Scale GUI обеспечивает простое администрирование объемов данных уровня петабайт различных типов: файловых, объектных или блочных.
IBM Spectrum Scale – это хорошо зарекомендовавшее себя масштабируемое решение по администрированию данных, которое ранее называлось GPFS (General Parallel File System). Начиная с версии 4.1, это решение называется Spectrum Scale. Однако версии до 4.1 будут поддерживаться под старым названием GPFS.
Основные характеристики
Применения
Spectrum Scale используется уже более 15 лет во многих отраслях экономики во всем мире, и в таких областях, требовательных к объему и производительности обработки данных, как:
Функциональные возможности
Основные компоненты системы

Три NSD, определенные как диски tiebreaker disk для кворумных узлов (источник: IBM)
Три редакции Spectrum Scale
Есть три разных редакции (Edition) Spectrum Scale:
Cluster Shared Volumes в Windows Server 2012 R2 (часть 1)
Общие кластерные тома (Cluster Shared Volumes, CSV) позволяют нескольким узлам в кластере одновременно обращаться к файловой системе NTFS (или ReFS в Windows Server 2012 R2), без ограничений на используемое оборудование. Впервые общие кластерные тома впервые появились в Windows Server 2008 R2 как общее хранилище для виртуальных машин Hyper-V.
Если помните, технология Hyper-V в Windows Server 2008 имела множество ограничений, одним из которых являлась невозможность переноса виртуальных машин между узлами кластера без простоя (Live Migration). Одной из причин этого было отсутствие на тот момент у Microsoft нормальной кластерной файловой системы. Файловая система NTFS, несмотря на все свои достоинства, таковой не является: к одному тому NTFS одновременно может подключиться и использовать его только один экземпляр операционной системы.
Теперь вспомним принцип работы отказоустойчивого кластера в Windows. Кластер состоит из нескольких (2 и более) узлов, на каждом из которых запущен экземпляр операционной системы. Каждый из узлов кластера имеет доступ к общему диску (как правило это выделенный LUN), который является общим кластерным ресурсом. Как у любого кластерного ресурса, у диска одновременно может быть только один узел-владелец, который может подключить диск к операционной системе и получить доступ к хранящимся на нем разделам (томам) NTFS. При переключении нагрузки (Failover) на другой узел кластера происходит смена владельца ресурса, т.е. LUN отключается от одного узла и подключается к другому.
Получается, что если к тому NTFS одновременно может получить доступ только один узел кластера, то все виртуальные машины, размещенные на одном LUN-е, должны работать на этом самом узле. При этом независимое перемещение на другой узел отдельной ВМ невозможно, все машины, находящиеся на LUN-e, перемещаются одновременно. Для независимой миграции виртуальных машин с узла на узел каждой ВМ необходимо размещаться на отдельном LUN-e, что не очень удобно. К тому же переключение LUN-а требует некоторого времени, в течение которого виртуальные машины будут недоступны.
Для устранения этих недостатков и была придумана технология CSV, позволяющая всем узлам кластера обращаться к общему хранилищу одновременно. CSV представляет из себя прослойку для файловой системы, обеспечивая следующее условие: один узел кластера, являющийся текущим владельцем, имеет доступ к LUN на уровне файловой системы (NTFS или ReFS), все же остальные узлы имеют доступ на блочном уровне.
Надо сказать, что вначале тома CSV имели довольно скромный функционал и были ограничены в использовании. Однако теперь, в Windows Server 2012 R2, большинство ограничений CSV снято, а также появилось много новых возможностей. Сегодня мы рассмотрим общий принцип работы томов CSV в Windows Server 2012 R2.
Основные компоненты
В качестве примера (на рисунке ниже) возьмем 3-х узловой кластер с общим диском, который подключен как том CSV. Первый и второй узлы подключены к хранилищу напрямую, третий узел не имеет подключения к общему хранилищу. Владельцем общего диска является второй узел. CSV тома на каждом узле кластера подключены как папки к системному диску в виде C:\ClusterStorage\Volume1.
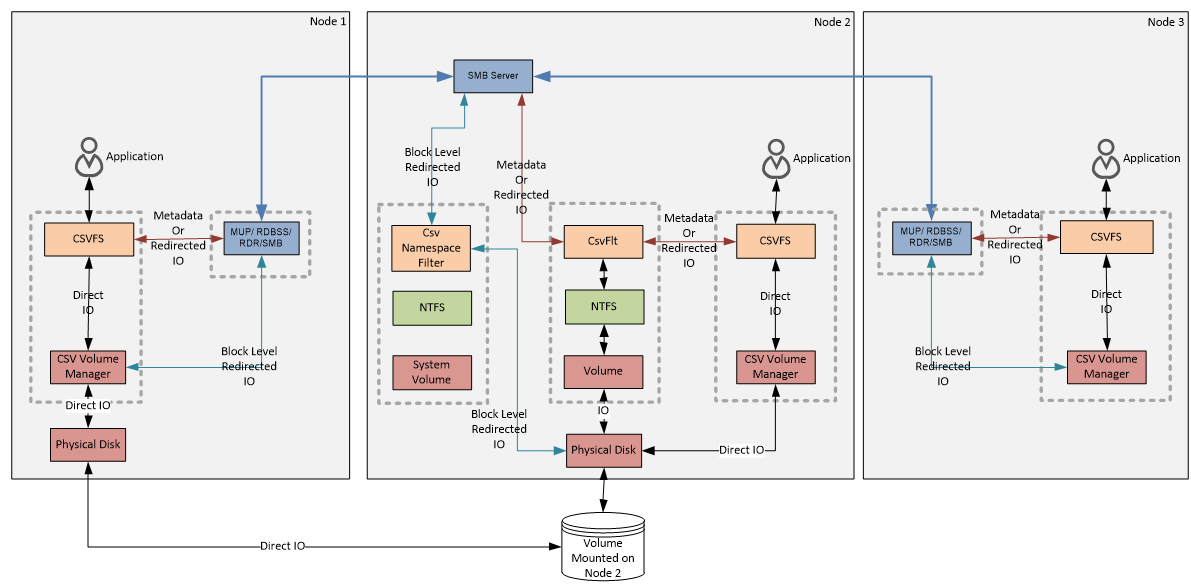
Примечание. Узел, являющийся текущим владельцем диска, на котором расположен том CSV, называется узлом-координатором. В этом контексте все остальные узлы кластера называются серверами данных. Для каждого тома CSV в каждый момент времени может быть только один узел-координатор. Возможен вариант, когда в кластере используется несколько томов CSV, расположенных на разных дисках. В этом случае каждый узел-владелец диска является координатором для всех томов CSV, на этом диске расположенных.
Работу CSV обеспечивают несколько ключевых компонентов, о которых стоит упомянуть подробнее.
CsvFlt
Драйвер фильтра CSV (csvflt.sys). Предоставляет приложениям доступ к файловой системе NTFS, находящейся на томах CSV. Поскольку том создается скрытым, операционная система не может назначить ему идентификатор (volume GUID) и присвоить букву диска. Из за этого приложения, работающие в пользовательском режиме, не могут обращаться к нему напрямую. CsvFlt отлавливает и перенаправляет запросы приложений к NTFS, обеспечивая для CSV функциональность обычного локального диска.
Csv Namespace Filter
Драйвер управления именами CSV (csvnsflt.sys). Защищает точку монтирования CSV (C:\ClusterStorage) от неавторизованных запросов (запросов, исходящих не от службы кластера) на изменение, удаление или смену атрибутов для папок и файлов, находящихся в этой директории. Если, к примеру, зайти на один из узлов кластера и в проводнике сменить дефолтное название папки C:\ClusterStorage\Volume1 на что-то типа C:\ClusterStorage\IT, то изменения будут произведены сразу на всех узлах. Кроме того, он отвечает за управление режимом Block level redirected IO, о котором пойдет речь чуть позже.
CsvFS и CSV Volume Manager
Драйвер файловой системы CSV (csvfs.sys) и диспетчер томов CSV (csvvbus.sys). Эти компоненты обеспечивает приложениям возможность прямого доступа к файлам на чтение\запись (Direct IO), а также перенаправление для операций с метаданными и в режиме Redirected IO.
Потоки данных
После знакомства с отдельными компонентами перейдем к их взаимодействию, для чего рассмотрим основные операции и потоки данных, проходящие через CSV.
Операции с метаданными (Metadata). Под ними подразумеваются любые операции с файлами (кроме операций чтения и записи) — создание, удаление, переименование, перемещение, изменение размера или атрибутов файла и другие подобные операции. Также и некоторые операции чтения\записи могут быть причиной изменения метаданных. Например, запись может вызвать увеличение размера файла, что повлечет за собой изменение в метаданных.
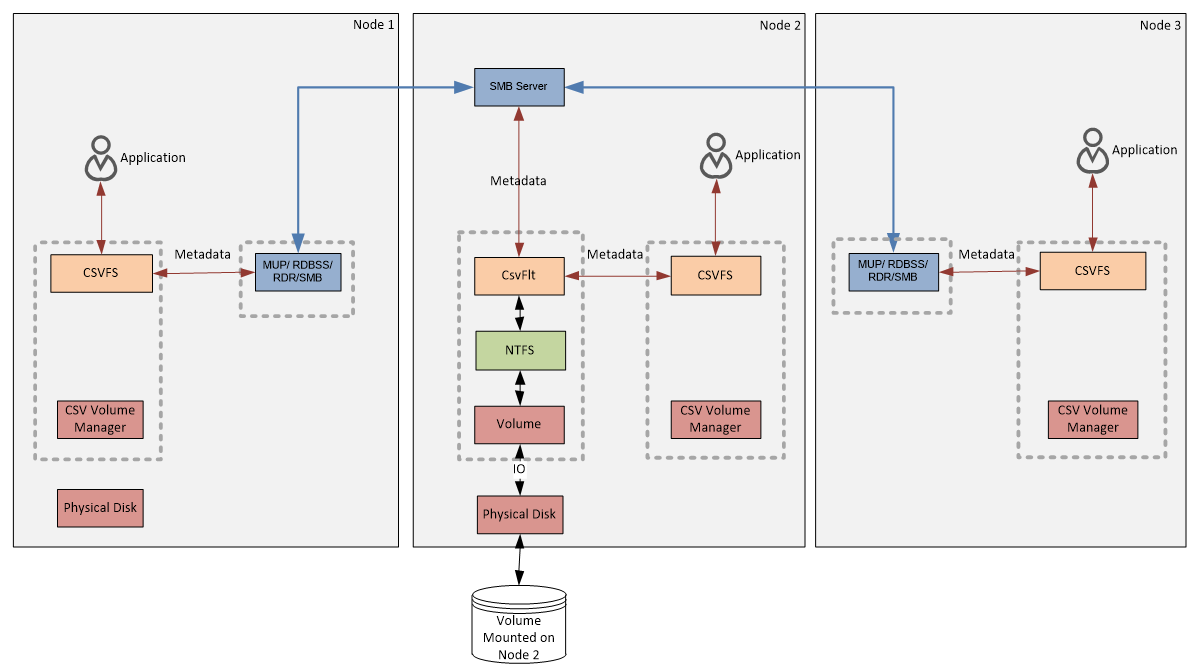
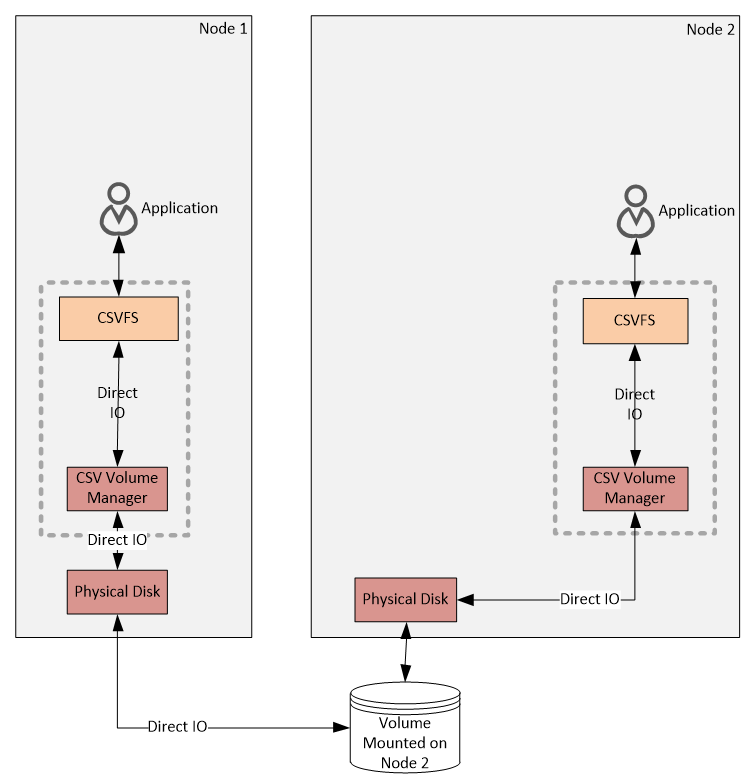
Операции прямого чтения\записи (Direct IO). Так как эти операции производятся на блочном уровне, для них не требуется доступ к файловой системе NTFS, необходим только физический доступ к диску. Хотя в Direct IO участвуют CSVFS и CSV Volume Manager, по сути приложения напрямую обращаются к физическому диску, минуя файловую систему. В нашем примере операции Direct IO возможны только для двух узлов кластера, так как у третьего нет физического подключения к диску.
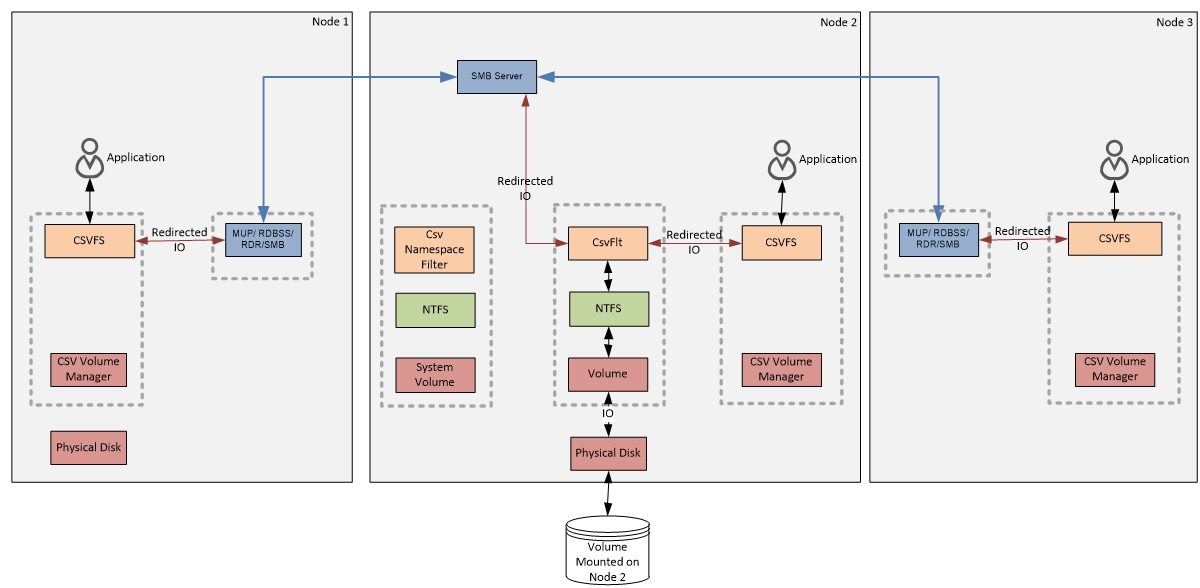
Перенаправление файловой системы (File System Redirected IO). Это специальный режим работы CSV, в котором весь поток данных (как метаданные, так и блочные данные) для всех узлов кластера идет исключительно через NTFS, т.е. через узел-координатор. Этот режим может быть активирован только по запросу пользователя.
Поскольку при использовании File System Redirected IO все данные передаются на диск по локальной сети общего назначения, производительность кластера сильно ограничена. Однако его можно использовать в определенных ситуациях, например, при проведении регламентных работ в сети SAN.
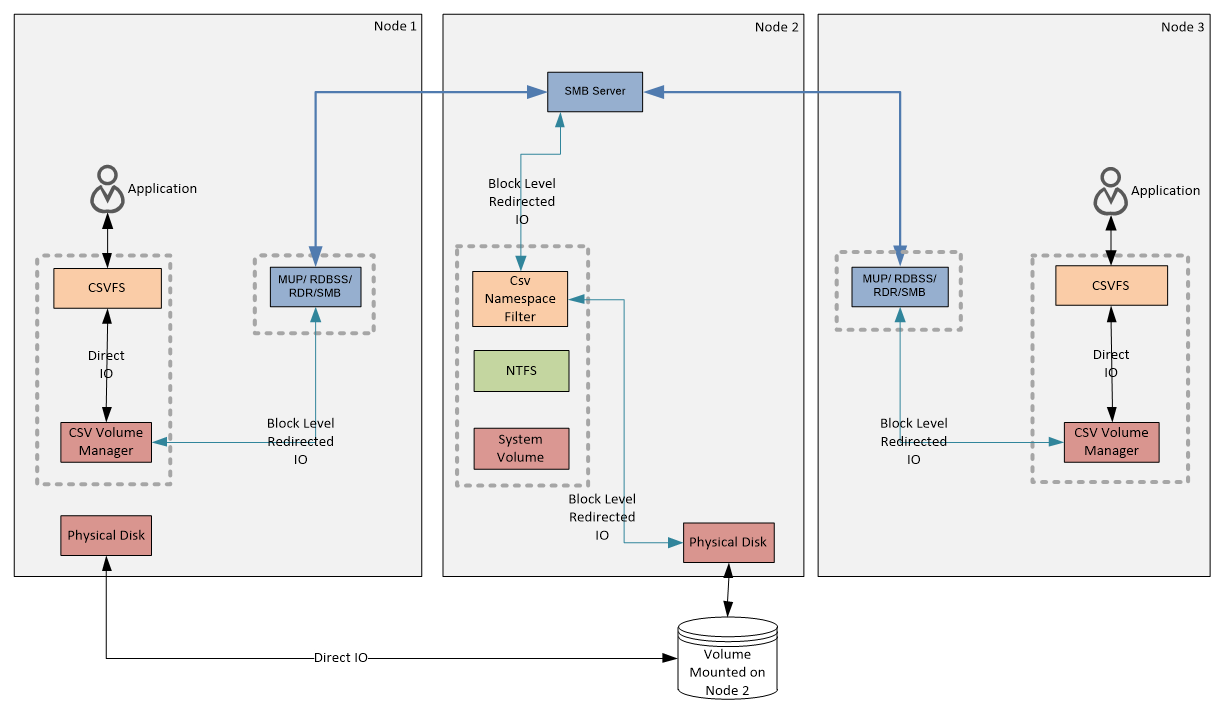
Перенаправление блочного доступа (Block Level Redirected IO) — еще один режим работы CSV. В этом режиме все обращения конкретного узла кластера к диску производятся через узел-координатор. При использовании Block Level Redirected IO обращение к диску производится напрямую. За передачу данных отвечает фильтр СsvNsFlt, который перенаправляет запросы к диску, минуя NTFS.
Block Level Redirected IO включается автоматически, при отсутствии у узла прямого доступа к диску. К примеру, Node 3 не имеет физического подключения к общему диску, поэтому для него все операции производятся по сети, через узел-координатор. Также этот режим может использоваться и в случае временной недоступности диска. Например, если попытка прямого обращения к диску оказалось неудачной из за сбоя на коммутаторе системы хранения, то будет задействован Block Level Redirected IO и данные будут перенаправлены на узел-координатор.
Пожалуй на сегодня все, остальное в следующий раз. Если же что то осталось непонятным, то вы можете обратиться к первоисточнику.