Выравнивание текста
Выравнивание текста определяет его внешний вид и ориентацию краев абзаца и может выполняться по левому краю, правому краю, по центру или по ширине. В табл. 1 показаны варианты выравнивания блока текста.
| Выравнивание по левому краю | Выравнивание по правому краю | Выравнивание по центру | Выравнивание по ширине | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diem nonummy nibh euismod tincidunt ut lacreet dolore magna aliguam erat volutpat. | Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diem nonummy nibh euismod tincidunt ut lacreet dolore magna aliguam erat volutpat. | Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diem nonummy nibh euismod tincidunt ut lacreet dolore magna aliguam erat volutpat. |
| Код HTML | Описание | ||
|---|---|---|---|
| Добавляет новый абзац текста, по умолчанию выровненный по левому краю. Перед абзацем и после него автоматически добавляются небольшие вертикальные отступы. | |||
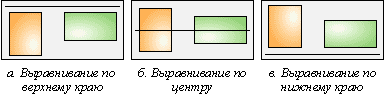
| , а по вертикали содержимое ячейки можно не центрировать, поскольку это положение задано по умолчанию. Использование ширины и высоты на всю доступную область веб-страницы гарантирует, что содержимое таблицы будет выравниваться строго по центру окна браузера, независимо от его размеров. Выравнивание по горизонталиЗа счет сочетания атрибутов align (горизонтальное выравнивание) и valign (вертикальное выравнивание) тега | , допустимо устанавливать несколько видов положений элементов относительно друг друга. На рис. 1 показаны способы выравнивания элементов по горизонтали.
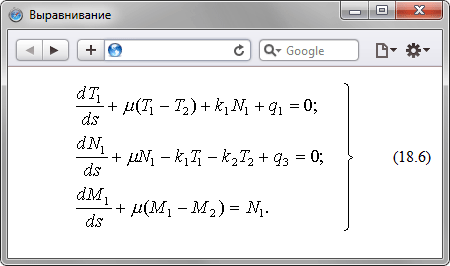
Рис. 1. Выравнивание элементов по горизонтали Рассмотрим некоторые примеры выравнивания текста согласно приведенному рисунку. Выравнивание по верхнему краюДля указания выравнивания содержимого ячеек по верхнему краю, для тега | требуется установить атрибут valign со значением top (пример 2). Пример 2. Использование valign В данном примере характеристики ячеек управляются с помощью параметров тега | , но тоже удобнее изменять через стили. В частности, выравнивание в ячейках указывается свойствами vertical-align и text-align (пример 3). Пример 3. Применение стилей для выравнивания Для сокращения кода в данном примере используется группирование селекторов, поскольку свойства vertical-align и padding применяются одновременно к двум ячейкам. Выравнивание по центруПо умолчанию содержимое ячейки выравнивается по центру их вертикали, поэтому в случае разной высоты колонок требуется задавать выравнивание по верхнему краю. Иногда все-таки нужно оставить исходный способ выравнивания, например, при размещении формул, как показано на рис. 2.
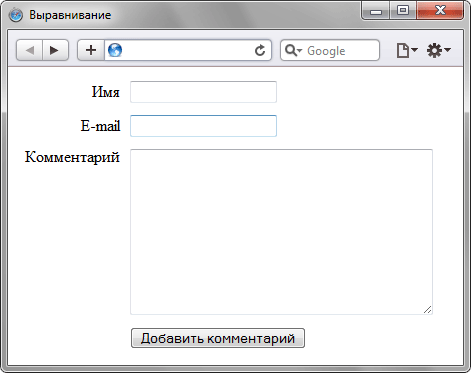
Рис. 2. Добавление формулы в документ В подобном случае формула располагается строго по центру окна браузера, а ее номер — по правому краю. Для такого размещения элементов понадобится таблица с тремя ячейками. Крайние ячейки должны иметь одинаковые размеры, в средней ячейке выравнивание делается по центру, а в правой — по правому краю (пример 4). Такое количество ячеек требуется для того, чтобы обеспечить позиционирование формулы по центру. Пример 4. Выравнивание формулы В данном примере первая ячейка таблицы оставлена пустой, она служит лишь для создания отступа, который, кстати, может быть установлен и с помощью стилей. Выравнивание элементов формыС помощью таблиц удобно определять положение полей формы, особенно, когда они перемежаются с текстом. Один из вариантов оформления формы, которая предназначена для ввода комментария, показан на рис. 3.
Рис 3. Расположение полей формы и текста Чтобы текст возле полей формы был выровнен по правому краю, а сами элементы формы — по левому, потребуется таблица с невидимой границей и двумя колонками. В левой колонке будет размещаться собственно текст, а в правой текстовые поля (пример 5). Пример 5. Выравнивание полей формы Выравнивание элементов в HTML
До сих пор мы с Вами выравнивали элементы только по левому краю. Точнее, мы с Вами вообще этим не занимались, а сам браузер по умолчанию выравнивает элементы по левому краю. Разумеется, было бы слишком скучно выравнивать всё по левому краю. Поэтому существуют различные способы выравнивания по центру и по правому краю. Ещё когда-то давно появился тег я сейчас Вам не советую его применять, ввиду наличия более современных способов, но не упомянуть я о нём не могу. Использовать его очень и очень просто. Всё, что Вам необходимо выравнять по центру, Вы помещаете внутри этого тега. Вот, например, тут мы выравниваем заголовок 1-го уровня по центру. Заголовок 1-го уровня, выравненный по центруМожно добавить картинку, выравненную также по центру, также давайте перейдём на следующую строку с помощью тега Заголовок 1-го уровня, выравненный по центруЧтобы решить эту проблему разработчики придумали универсальный способ выравнивания элементов HTML. Способ заключается в использовании так называемых контейнеров, которые создаются с помощью тега Давайте сейчас напишем тот же HTML-код, но с использованием контейнеров, вдобавок, давайте выравняем не по центру, а по правому краю. Заголовок 1-го уровня, выравненный по правому краюКак видите, всё работает. Советую Вам также поменять значения атрибута «align«, чтобы посмотреть на другие виды выравнивания содержимого контейнеров. А пока Ваша страница должна выглядеть так: Заголовок 1-го уровня, выравненный по центруЗаголовок 1-го уровня, выравненный по правому краю5 способов выровнять HTML-элемент горизонтально и вертикально
Каждый, кто работает с HTML/CSS, рано или поздно сталкивается с проблемой вертикального и горизонтального выравнивания элемента. Чтобы вы лишний раз не гуглили и не находили много разных вариантов, мы собрали здесь несколько самых популярных. Способ 1В поддерживаемых браузерах можно использовать top: 50% / left: 50% в сочетании с translateX(-50%) translateY(-50%) для динамического горизонтального/вертикального центрирования элемента: Пример можно посмотреть здесь, а тут можно увидеть полноэкранную версию. Способ 2В поддерживаемых браузерах также можно присвоить свойству display значение flex и использовать align-items: center с justify-content: center для вертикального и горизонтального центрирования соответственно. Главное, не забудьте добавить вендорные префиксы (как в примере), чтобы этот приём сработал в большем количестве браузеров: Способ 3В некоторых случаях вам будет нужно убедиться, что высота элемента html / body равна 100%. Примеры доступны здесь и здесь. Способ 4За примерами сюда и сюда. Этот вариант должен работать во всех поддерживаемых браузерах. Способ 5В некоторых случаях у родительского элемента фиксированная высота. Для вертикального выравнивания нужно всего лишь присвоить свойству line-height дочернего элемента высоту родительского. Хотя в некоторых случаях это будет работать, такой способ не стоит использовать, так как несколько строк текста всё испортят: Пример можно посмотреть здесь.
Автоматическое выравнивание кода
Доброго времени суток. Среди способов повышения читаемости кода, связанных с визуальным восприятием текста, можно выделить следующие: Было бы ошибкой утверждать, что эта задача никогда не решалась. Беглый поиск показал, что существует множество реализаций, в том числе для используемого мной редактора Sublime Text. Однако, если присмотреться более внимательно, становится понятно, что практические все эти плагины реализуют выравнивание лишь по одному, заранее выбранному символу. Среди самых продвинутых версий строит выделить следующий инструмент. Но и у него есть существенный недостаток: для своей работы он использует DLL с закрытым исходным кодом, что делает невозможным его кросс-платформенное использование, в том числе и под Linux. В связи с этим я решил искать собственный метод для решения задачи. Стоит заметить, что изначально я предполагал, что на решение потрачу не больше пары вечеров, но задача оказалась значительно сложнее, чем мне казалось на первый взгляд. Первым неудачным вариантом была попытка просто найти пары схожих токенов в двух соседних строках, а затем выровнять ее по ним. Причем необходимо было бы найти такие пары, которые, во-первых, не перекрывали бы друг друга, во-вторых, имели бы максимальную взвешенную сумму коэффициентов схожести. Однако следующий пример иллюстрирует нежизнеспособность данного подхода: В данном случае второй аргумент функции f и первый аргумент функции g столь похожи, что перевешивают похожесть запятых. Такое выравнивание неприемлемо, оно может сбить столку, так как для определения количества параметров функции придется пересчитывать количество запятых, расположенных в совершенно разным местах. Очевидно, что простым увеличением веса для пары (запятая, запятая) проблему не решить, так как сами параметры функции могут быть сколь угодно большими и, следовательно, иметь сколь угодно большой вес. Следовательно, необходимо учитывать не только степень похожести токенов, но и синтаксическую структуру выравниваемых строк. В этом случае возникает проблема, связанная с тем, что разные языки имеют свой собственный, порой уникальный, синтаксис, а инструмент хотелось бы видеть как можно более универсальным. Более того, в тексте программ могут встречаться места, выравнивать которые ни в коем случае нельзя. К ним можно отнести строковые константы и комментарии. Разные языки по разному распознают комментарии, так например С\С++ использует //, а Ruby и Python #. Поэтому единственным способом повышения универсальности является использование метода быстрого описания синтаксиса языка. ГрамматикаОсновная идея использования грамматик заключается в построении дерева выражения таким образом, что каждый узел этого дерева выравнивался бы отдельно с соответствующим узлом другого дерева и только с ним. Структура, полученная из предыдущего примера:
Пунктирными линиями показаны узлы, между которыми будет происходить выравнивание. В связи с тем, что в задачи инструмента не входит интерпретация кода, то отпадает необходимость хранить полное описание синтаксиса каждого языка в программе. Наоборот, достаточно описать лишь те правила, которые мы хотим использовать для выравнивания. К ним могут быть отнесены аргументы функции, упомянутые выше, операции присваивания, скобочные конструкции. Среди требований, предъявляемых к грамматике, нужно выделить также следующее: любая последовательность токенов, так или иначе, должна быть принята грамматикой. Это требование позволит использовать единую грамматику для схожих языков. Грамматика, применяемая для построения показанной выше структуры, может быть описана в форме Бэкуса-Наура следующим образом: Если же строка не может быть принята грамматикой (отсутствует закрывающая скобка, например), то на выходе распознавания будет линейная структура. Можно заметить, что выделение узлов в дереве соответствует не каждому правилу свертки грамматики, иначе, каждый токен находился бы в отдельном узле. Чтобы достичь желаемой структуры, необходимо выделить в грамматике те правила, применение которых должно образовывать новые узлы в дереве. В нашем случае такими правилами должны быть: В ходе разработки была реализован LR-0 парсер, использующий описание грамматики для построения дерева выражения. Описание алгоритма построения парсера выходит за рамки данной статьи, более подробно с ним можно ознакомиться в книге: Ахо, Лам, Сети, Ульман — Компиляторы. Принципы, технологии, инструменты. СравнениеПосле получения дерева выражения необходимо производить выравнивание токенов с учетом их похожести. Похожая задача возникает в генетике при изучении генома. Выравнивание последовательностей — метод, основанный на размещении двух или более последовательностей мономеров ДНК, РНК или белков друг под другом таким образом, чтобы легко увидеть сходные участки в этих последовательностях[wiki]. Один из способов для решения этой задачи в биоинформатике — применение динамического программирования, его я и взял за основу для задачи выравнивания токенов. Как и во всех задачах динамического программирования, исходная задача разбивается на более меткие, решение которых ищется рекурсивно. В данном случае, более мелкой задачей для выравнивания строк является выравнивание суффиксов этих строк. В результате рекурсивного прохода получается матрица, сопоставляющая индексам i, j токенов строк X и Y максимальный возможный суммарный вес схожести оставшихся суффиксов этих строк. Для того, чтобы обеспечить возможность выравнивания более чем двух строк, среди множество массивов пар выделяются цепочки, по которым и происходит выравнивание.
На рисунке показана цепочка из запятых, по которым будет происходить выравнивание. Выделение токеновВыделение токенов из строки производится с помощью последовательности попыток применить регулярное выражение для соответствующего типа токенов. Эта последовательность должна быть устроена таким образом, чтобы первыми применялись более конкретные регулярные выражения, а затем более общие, выделяющее, возможно даже, отдельные символы. После успешного распознавания токену присваивается тип, соответствующий регулярному выражению. В проекте также реализована иерархия типов, которая призвана упростить построение грамматик и улучшить точность выравнивания. До сих пор не был затронут вопрос о том, как считать схожесть двух отдельно взятых токенов. К сожалению, мне не удалось найти строгого формального решения для этой задачи, поэтому схожесть токенов в текущей реализации определяется в основном эвристическими методами. В частности, схожесть идентификаторов определяется как отношение расстояния Левенштейна между идентификаторами к длине максимального из них. Значения по-умолчанию в этом случае следующие: Определение минимального отступа между токенамиХорошим стилем программирования считается простановка отступов в некоторых конструкциях языка. Однако варианты постановки пробелов отличаются не только для разных языков, но и разные программисты пользуются разными стилями. Чтобы упростить настройку автоматического проставления отступов в этом случае, было решено добавить возможность обучения. Текущая реализацияНа момент написания статьи программа реализована как плагин к редактору Sublime Text 3. Среди особенностей следует отметить следующие: Среди планов на будущее хотелось бы отметить следующее: Примеры полученных результатовВ последнем примере используется отделение описания типа на уровне грамматики, поэтому похожие токены double и doubl небыли выровнены между собой.  Привет, юные искатели приключений! Сегодня мы отправимся  Дорогие друзья, добро пожаловать в захватывающий и  Волшебный мир, полный таинственных существ, удивительных |