Getting Started with PySpark on Windows
I decided to teach myself how to work with big data and came across Apache Spark. While I had heard of Apache Hadoop, to use Hadoop for working with big data, I had to write code in Java which I was not really looking forward to as I love to write code in Python. Spark supports a Python programming API called PySpark that is actively maintained and was enough to convince me to start learning PySpark for working with big data.
In this post, I describe how I got started with PySpark on Windows. My laptop is running Windows 10. So the screenshots are specific to Windows 10. I am also assuming that you are comfortable working with the Command Prompt on Windows. You do not have to be an expert, but you need to know how to start a Command Prompt and run commands such as those that help you move around your computer’s file system. In case you need a refresher, a quick introduction might be handy.
Often times, many open source projects do not have good Windows support. So I had to first figure out if Spark and PySpark would work well on Windows. The official Spark documentation does mention about supporting Windows.
Installing Prerequisites
PySpark requires Java version 7 or later and Python version 2.6 or later. Let’s first check if they are already installed or install them and make sure that PySpark can work with these two components.
Java is used by many other software. So it is quite possible that a required version (in our case version 7 or later) is already available on your computer. To check if Java is available and find it’s version, open a Command Prompt and type the following command.
If Java is installed and configured to work from a Command Prompt, running the above command should print the information about the Java version to the console. For example, I got the following output on my laptop.
Instead if you get a message like
It means you need to install Java. To do so,
Go to the Java download page. In case the download link has changed, search for Java SE Runtime Environment on the internet and you should be able to find the download page.
Click the Download button beneath JRE
Accept the license agreement and download the latest version of Java SE Runtime Environment installer. I suggest getting the exe for Windows x64 (such as jre-8u92-windows-x64.exe ) unless you are using a 32 bit version of Windows in which case you need to get the Windows x86 Offline version.
Python
Python is used by many other software. So it is quite possible that a required version (in our case version 2.6 or later) is already available on your computer. To check if Python is available and find it’s version, open a Command Prompt and type the following command.
If Python is installed and configured to work from a Command Prompt, running the above command should print the information about the Python version to the console. For example, I got the following output on my laptop.
Instead if you get a message like
It means you need to install Python. To do so,
Go to the Python download page.
Click the Latest Python 2 Release link.
Download the Windows x86-64 MSI installer file. If you are using a 32 bit version of Windows download the Windows x86 MSI installer file.
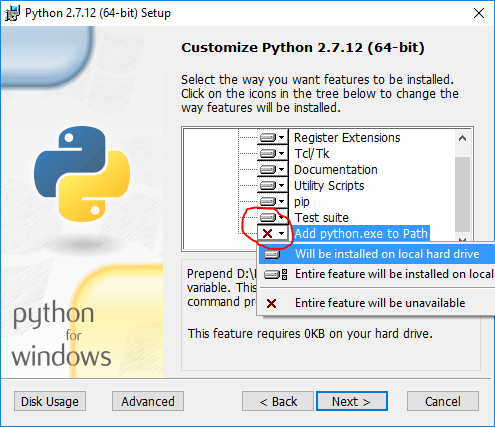
When you run the installer, on the Customize Python section, make sure that the option Add python.exe to Path is selected. If this option is not selected, some of the PySpark utilities such as pyspark and spark-submit might not work.
Installing Apache Spark
Go to the Spark download page.
For Choose a Spark release, select the latest stable release of Spark.
For Choose a package type, select a version that is pre-built for the latest version of Hadoop such as Pre-built for Hadoop 2.6.
For Choose a download type, select Direct Download.
In order to install Apache Spark, there is no need to run any installer. You can extract the files from the downloaded tarball in any folder of your choice using the 7Zip tool.
Make sure that the folder path and the folder name containing Spark files do not contain any spaces.
The PySpark shell outputs a few messages on exit. So you need to hit enter to get back to the Command Prompt.
Configuring the Spark Installation
This error message does not prevent the PySpark shell from starting. However if you try to run a standalone Python script using the bin\spark-submit utility, you will get an error. For example, try running the wordcount.py script from the examples folder in the Command Prompt when you are in the SPARK_HOME directory.
which produces the following error that also points to missing winutils.exe
Installing winutils
Create a hadoop\bin folder inside the SPARK_HOME folder.
Download the winutils.exe for the version of hadoop against which your Spark installation was built for. In my case the hadoop version was 2.6.0. So I downloaded the winutils.exe for hadoop 2.6.0 and copied it to the hadoop\bin folder in the SPARK_HOME folder.
Create a system environment variable in Windows called SPARK_HOME that points to the SPARK_HOME folder path. Search the internet in case you need a refresher on how to create environment variables in your version of Windows such as articles like these.
Create another system environment variable in Windows called HADOOP_HOME that points to the hadoop folder inside the SPARK_HOME folder.
If you now run the bin\pyspark script from a Windows Command Prompt, the error messages related to winutils.exe should be gone. For example, I got the following messages after running the bin\pyspark utility after configuring winutils
The bin\spark-submit utility can also be successfully used to run wordcount.py script.
Configuring the log level for Spark
There are still a lot of extra INFO messages in the console everytime you start or exit from a PySpark shell or run the spark-submit utility. So let’s make one more change to our Spark installation so that only warning and error messages are written to the console. In order to do this
Copy the log4j.properties.template file in the SPARK_HOME\conf folder as log4j.properties file in the SPARK_HOME\conf folder.
Set the log4j.rootCategory property value to WARN, console
Save the log4j.properties file.
Summary
In order to work with PySpark, start a Windows Command Prompt and change into your SPARK_HOME directory.
To start a PySpark shell, run the bin\pyspark utility. Once your are in the PySpark shell use the sc and sqlContext names and type exit() to return back to the Command Prompt.
To run a standalone Python script, run the bin\spark-submit utility and specify the path of your Python script as well as any arguments your Python script needs in the Command Prompt. For example, to run the wordcount.py script from examples directory in your SPARK_HOME folder, you can run the following command
bin\spark-submit examples\src\main\python\wordcount.py README.md
References
I used the following references to gather information about this post.
Downloading Spark and Getting Started (chapter 2) from O’Reilly’s Learning Spark book.
Any suggestions or feedback? Leave your comments below.
Установка Apache PySpark в Windows 10
Дата публикации Aug 30, 2019

Последние несколько месяцев я работал над проектом Data Science, который обрабатывает огромный набор данных, и стало необходимым использовать распределенную среду, предоставляемую Apache PySpark.
Я много боролся при установке PySpark на Windows 10. Поэтому я решил написать этот блог, чтобы помочь любому легко установить и использовать Apache PySpark на компьютере с Windows 10.
1. Шаг 1
PySpark требует Java версии 7 или новее и Python версии 2.6 или новее. Давайте сначала проверим, установлены ли они, или установим их и убедимся, что PySpark может работать с этими двумя компонентами.
Установка Java
Проверьте, установлена ли на вашем компьютере Java версии 7 или новее. Для этого выполните следующую команду в командной строке.

Если Java установлена и настроена для работы из командной строки, выполнение вышеуказанной команды должно вывести информацию о версии Java на консоль. Иначе, если вы получите сообщение, подобное:
«Java» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл.
тогда вы должны установить Java.
б) Получить Windows x64 (например, jre-8u92-windows-x64.exe), если вы не используете 32-разрядную версию Windows, в этом случае вам нужно получитьWindows x86 Offlineверсия.
в) Запустите установщик.
2. Шаг 2
питон
Если Python установлен и настроен для работы из командной строки, при выполнении вышеуказанной команды информация о версии Python должна выводиться на консоль. Например, я получил следующий вывод на моем ноутбуке:
Вместо этого, если вы получите сообщение, как
«Python» не распознается как внутренняя или внешняя команда, работающая программа или пакетный файл ».
Это означает, что вам нужно установить Python. Для этого
а) Перейти к питонускачатьстр.
б) НажмитеПоследний выпуск Python 2ссылка.
c) Загрузите установочный файл MSI для Windows x86–64. Если вы используете 32-разрядную версию Windows, загрузите установочный файл MSI для Windows x86.
г) Когда вы запускаете установщик, наНастроить Pythonраздел, убедитесь, что опцияДобавить python.exe в путьвыбран. Если этот параметр не выбран, некоторые утилиты PySpark, такие как pyspark и spark-submit, могут не работать.
3. Шаг 3
Установка Apache Spark
а) Перейти к искрескачатьстр.
б) Выберите последнюю стабильную версию Spark.
с)Выберите тип упаковки: sвыберите версию, предварительно созданную для последней версии Hadoop, такую какПредварительно построен для Hadoop 2.6,
г)Выберите тип загрузки:ВыбратьПрямое скачивание,
f) Для установки Apache Spark вам не нужно запускать какой-либо установщик. Извлеките файлы из загруженного tar-файла в любую папку по вашему выбору, используя7Zipинструмент / другие инструменты для разархивирования.
Убедитесь, что путь к папке и имя папки, содержащей файлы Spark, не содержат пробелов.
Я создал папку с именем spark на моем диске D и распаковал заархивированный tar-файл в папку с именем spark-2.4.3-bin-hadoop2.7. Таким образом, все файлы Spark находятся в папке с именем D: \ spark \ spark-2.4.3-bin-hadoop2.7. Давайте назовем эту папку SPARK_HOME в этом посте.
Чтобы проверить успешность установки, откройте командную строку, перейдите в каталог SPARK_HOME и введите bin \ pyspark. Это должно запустить оболочку PySpark, которую можно использовать для интерактивной работы со Spark.
Оболочка PySpark выводит несколько сообщений при выходе. Поэтому вам нужно нажать Enter, чтобы вернуться в командную строку.
4. Шаг 4
Настройка установки Spark
Первоначально, когда вы запускаете оболочку PySpark, она выдает много сообщений типа INFO, ERROR и WARN. Давайте посмотрим, как удалить эти сообщения.
Установка Spark в Windows по умолчанию не включает утилиту winutils.exe, которая используется Spark. Если вы не укажете своей установке Spark, где искать winutils.exe, вы увидите сообщения об ошибках при запуске оболочки PySpark, такие как
«ОШИБКА Shell: не удалось найти двоичный файл winutils в двоичном пути hadoop java.io.IOException: не удалось найти исполняемый файл null \ bin \ winutils.exe в двоичных файлах Hadoop».
Это сообщение об ошибке не препятствует запуску оболочки PySpark. Однако если вы попытаетесь запустить автономный скрипт Python с помощью утилиты bin \ spark-submit, вы получите ошибку. Например, попробуйте запустить скрипт wordcount.py из папки примеров в командной строке, когда вы находитесь в каталоге SPARK_HOME.
«Bin \ spark-submit examples \ src \ main \ python \ wordcount.py README.md»
Установка winutils
Давайте загрузим winutils.exe и сконфигурируем нашу установку Spark, чтобы найти winutils.exe.
a) Создайте папку hadoop \ bin внутри папки SPARK_HOME.
б) Скачатьwinutils.exeдля версии hadoop, для которой была создана ваша установка Spark. В моем случае версия hadoop была 2.6.0. Так что язагруженноеwinutils.exe для hadoop 2.6.0 и скопировал его в папку hadoop \ bin в папке SPARK_HOME.
c) Создайте системную переменную среды в Windows с именем SPARK_HOME, которая указывает путь к папке SPARK_HOME.
d) Создайте в Windows другую переменную системной среды с именем HADOOP_HOME, которая указывает на папку hadoop внутри папки SPARK_HOME.
Поскольку папка hadoop находится внутри папки SPARK_HOME, лучше создать переменную среды HADOOP_HOME, используя значение% SPARK_HOME% \ hadoop. Таким образом, вам не нужно менять HADOOP_HOME, если SPARK_HOME обновлен.
Если вы теперь запустите сценарий bin \ pyspark из командной строки Windows, сообщения об ошибках, связанные с winutils.exe, должны исчезнуть.
5. Шаг 5
Настройка уровня журнала для Spark
Каждый раз при запуске или выходе из оболочки PySpark или при запуске утилиты spark-submit остается много дополнительных сообщений INFO. Итак, давайте внесем еще одно изменение в нашу установку Spark, чтобы в консоль записывались только предупреждения и сообщения об ошибках. Для этого:
a) Скопируйте файл log4j.properties.template в папку SPARK_HOME \ conf как файл log4j.properties в папке SPARK_HOME \ conf.
b) Установите для свойства log4j.rootCategory значение WARN, console.
c) Сохраните файл log4j.properties.
Теперь любые информационные сообщения не будут записываться на консоль.
Резюме
Чтобы работать с PySpark, запустите командную строку и перейдите в каталог SPARK_HOME.
а) Чтобы запустить оболочку PySpark, запустите утилиту bin \ pyspark. Когда вы окажетесь в оболочке PySpark, используйте имена sc и sqlContext и введите exit (), чтобы вернуться в командную строку.
б) Чтобы запустить автономный скрипт Python, запустите утилиту bin \ spark-submit и укажите путь к вашему скрипту Python, а также любые аргументы, которые нужны вашему скрипту Python, в командной строке. Например, чтобы запустить скрипт wordcount.py из каталога examples в папке SPARK_HOME, вы можете выполнить следующую команду:
«bin \ spark-submit examples \ src \ main \ python \ wordcount.py README.md«
6. Шаг 6
Важно: я столкнулся с проблемой при установке
После завершения процедуры установки на моем компьютере с Windows 10 я получал следующее сообщение об ошибке.
Решение:
Я просто разобрался, как это исправить!
В моем случае я не знал, что мне нужно добавить ТРИ пути, связанные с миникондами, в переменную окружения PATH.
C: \ Users \ uug20 \ Anaconda3
C: \ Users \ uug20 \ Anaconda3 \ Scripts
C: \ Users \ uug20 \ Anaconda3 \ Library \ bin
После этого я не получил никаких сообщений об ошибках, и pyspark начал работать правильно и открыл записную книжку Jupyter после ввода pyspark в командной строке.
Руководство по PySpark для начинающих
PySpark — это API Apache Spark, который представляет собой систему с открытым исходным кодом, применяемую для распределенной обработки больших данных. Изначально она была разработана на языке программирования Scala в Калифорнийском университете Беркли.
Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
Преимущества использования Apache Spark:
Настройка среды в Google Colab
Чтобы запустить pyspark на локальной машине, нам понадобится Java и еще некоторое программное обеспечение. Поэтому вместо сложной процедуры установки мы используем Google Colaboratory, который идеально удовлетворяет наши требования к оборудованию, и также поставляется с широким набором библиотек для анализа данных и машинного обучения. Таким образом, нам остается только установить пакеты pyspark и Py4J. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически обращаться к объектам Java из виртуальной машины Java.
Итоговый ноутбук можно скачать в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/pyspark_beginner.ipynb
Команда для установки вышеуказанных пакетов:
Spark Session
SparkSession стал точкой входа в PySpark, начиная с версии 2.0: ранее для этого использовался SparkContext. SparkSession — это способ инициализации базовой функциональности PySpark для программного создания PySpark RDD, DataFrame и Dataset. Его можно использовать вместо SQLContext, HiveContext и других контекстов, определенных до 2.0.
Создание SparkSession
How to Install Apache Spark on Windows 10
Home » DevOps and Development » How to Install Apache Spark on Windows 10
Apache Spark is an open-source framework that processes large volumes of stream data from multiple sources. Spark is used in distributed computing with machine learning applications, data analytics, and graph-parallel processing.
This guide will show you how to install Apache Spark on Windows 10 and test the installation.

Install Apache Spark on Windows
Installing Apache Spark on Windows 10 may seem complicated to novice users, but this simple tutorial will have you up and running. If you already have Java 8 and Python 3 installed, you can skip the first two steps.
Step 1: Install Java 8
Apache Spark requires Java 8. You can check to see if Java is installed using the command prompt.
Open the command line by clicking Start > type cmd > click Command Prompt.
Type the following command in the command prompt:
If Java is installed, it will respond with the following output:
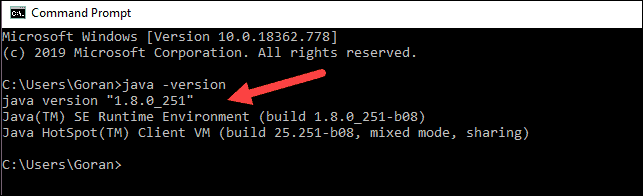
Your version may be different. The second digit is the Java version – in this case, Java 8.
If you don’t have Java installed:
1. Open a browser window, and navigate to https://java.com/en/download/.
2. Click the Java Download button and save the file to a location of your choice.
3. Once the download finishes double-click the file to install Java.
Note: At the time this article was written, the latest Java version is 1.8.0_251. Installing a later version will still work. This process only needs the Java Runtime Environment (JRE) – the full Development Kit (JDK) is not required. The download link to JDK is https://www.oracle.com/java/technologies/javase-downloads.html.
Step 2: Install Python
1. To install the Python package manager, navigate to https://www.python.org/ in your web browser.
2. Mouse over the Download menu option and click Python 3.8.3. 3.8.3 is the latest version at the time of writing the article.
3. Once the download finishes, run the file.
4. Near the bottom of the first setup dialog box, check off Add Python 3.8 to PATH. Leave the other box checked.
5. Next, click Customize installation.
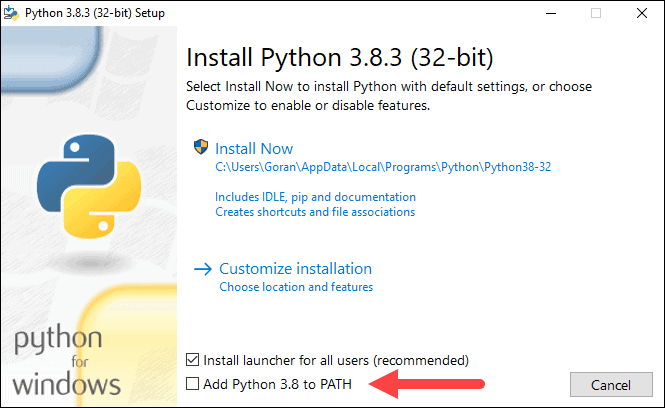
6. You can leave all boxes checked at this step, or you can uncheck the options you do not want.
7. Click Next.
8. Select the box Install for all users and leave other boxes as they are.
9. Under Customize install location, click Browse and navigate to the C drive. Add a new folder and name it Python.
10. Select that folder and click OK.
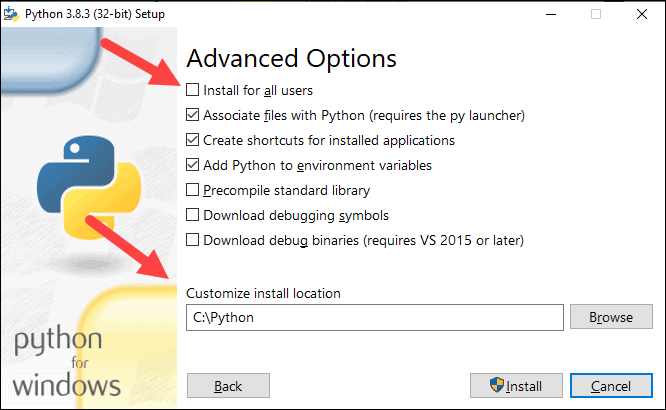
11. Click Install, and let the installation complete.
12. When the installation completes, click the Disable path length limit option at the bottom and then click Close.
13. If you have a command prompt open, restart it. Verify the installation by checking the version of Python:
Note: For detailed instructions on how to install Python 3 on Windows or how to troubleshoot potential issues, refer to our Install Python 3 on Windows guide.
Step 3: Download Apache Spark
2. Under the Download Apache Spark heading, there are two drop-down menus. Use the current non-preview version.
3. Click the spark-2.4.5-bin-hadoop2.7.tgz link.
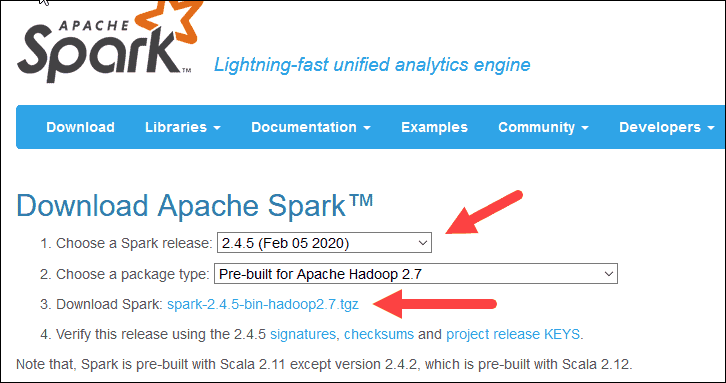
4. A page with a list of mirrors loads where you can see different servers to download from. Pick any from the list and save the file to your Downloads folder.
Step 4: Verify Spark Software File
1. Verify the integrity of your download by checking the checksum of the file. This ensures you are working with unaltered, uncorrupted software.
2. Navigate back to the Spark Download page and open the Checksum link, preferably in a new tab.
3. Next, open a command line and enter the following command:
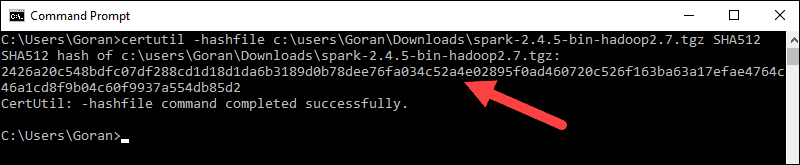
5. Compare the code to the one you opened in a new browser tab. If they match, your download file is uncorrupted.
Step 5: Install Apache Spark
Installing Apache Spark involves extracting the downloaded file to the desired location.
1. Create a new folder named Spark in the root of your C: drive. From a command line, enter the following:
2. In Explorer, locate the Spark file you downloaded.
3. Right-click the file and extract it to C:\Spark using the tool you have on your system (e.g., 7-Zip).
4. Now, your C:\Spark folder has a new folder spark-2.4.5-bin-hadoop2.7 with the necessary files inside.
Step 6: Add winutils.exe File
Download the winutils.exe file for the underlying Hadoop version for the Spark installation you downloaded.
1. Navigate to this URL https://github.com/cdarlint/winutils and inside the bin folder, locate winutils.exe, and click it.
2. Find the Download button on the right side to download the file.
3. Now, create new folders Hadoop and bin on C: using Windows Explorer or the Command Prompt.
4. Copy the winutils.exe file from the Downloads folder to C:\hadoop\bin.
Step 7: Configure Environment Variables
Configuring environment variables in Windows adds the Spark and Hadoop locations to your system PATH. It allows you to run the Spark shell directly from a command prompt window.
1. Click Start and type environment.
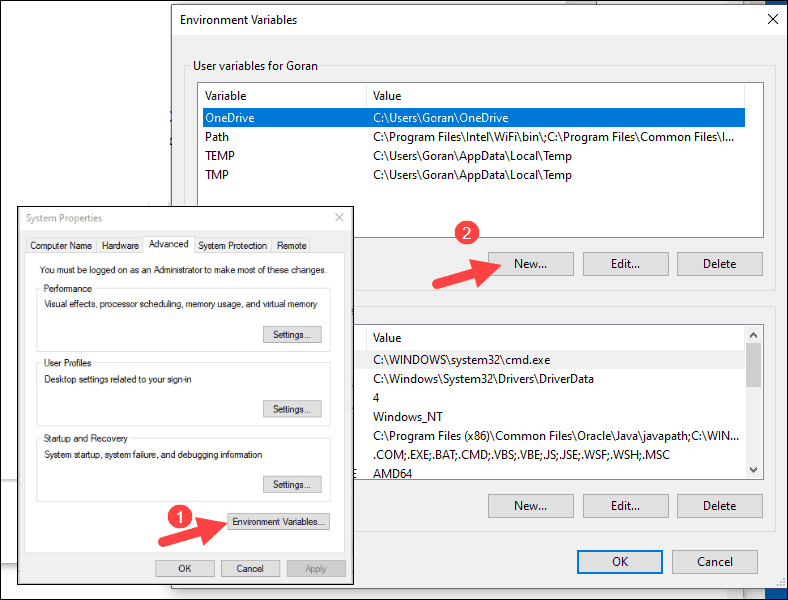
2. Select the result labeled Edit the system environment variables.
3. A System Properties dialog box appears. In the lower-right corner, click Environment Variables and then click New in the next window.
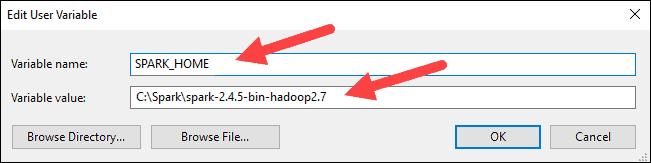
4. For Variable Name type SPARK_HOME.
5. For Variable Value type C:\Spark\spark-2.4.5-bin-hadoop2.7 and click OK. If you changed the folder path, use that one instead.
6. In the top box, click the Path entry, then click Edit. Be careful with editing the system path. Avoid deleting any entries already on the list.
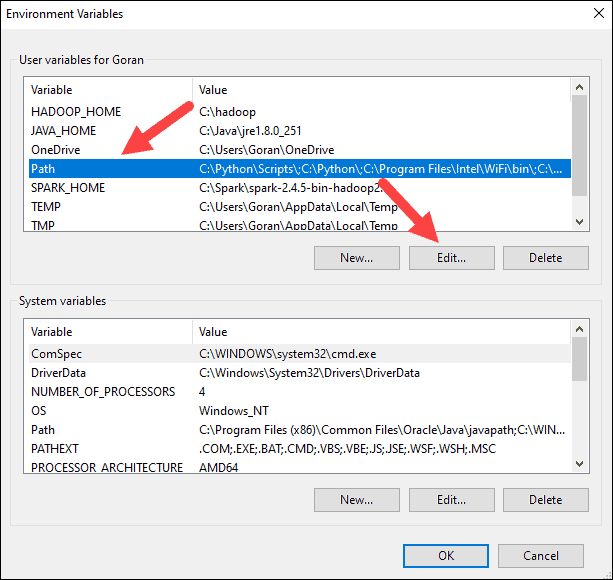
7. You should see a box with entries on the left. On the right, click New.
8. The system highlights a new line. Enter the path to the Spark folder C:\Spark\spark-2.4.5-bin-hadoop2.7\bin. We recommend using %SPARK_HOME%\bin to avoid possible issues with the path.
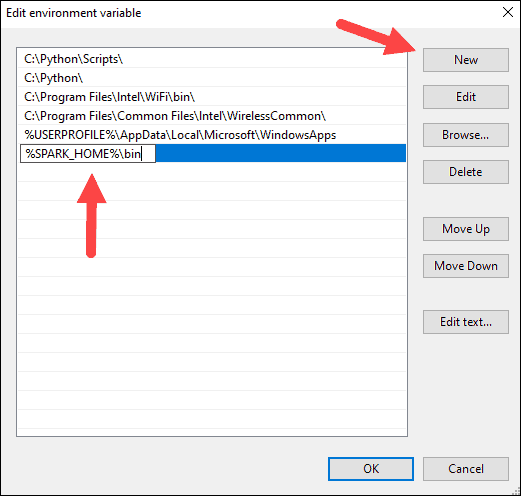
9. Repeat this process for Hadoop and Java.
10. Click OK to close all open windows.
Note: Star by restarting the Command Prompt to apply changes. If that doesn’t work, you will need to reboot the system.
Step 8: Launch Spark
1. Open a new command-prompt window using the right-click and Run as administrator:
2. To start Spark, enter:
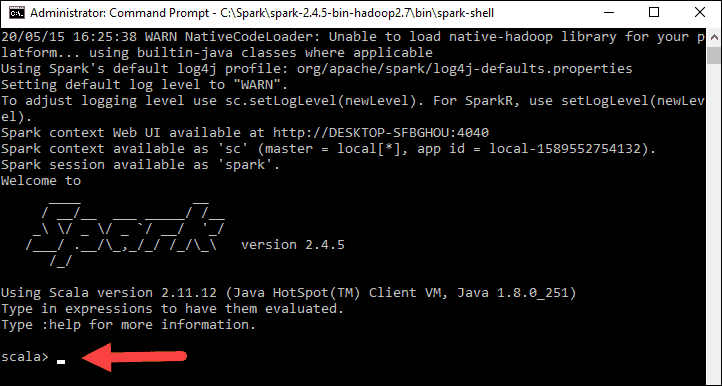
If you set the environment path correctly, you can type spark-shell to launch Spark.
3. The system should display several lines indicating the status of the application. You may get a Java pop-up. Select Allow access to continue.
Finally, the Spark logo appears, and the prompt displays the Scala shell.
4., Open a web browser and navigate to http://localhost:4040/.
5. You can replace localhost with the name of your system.
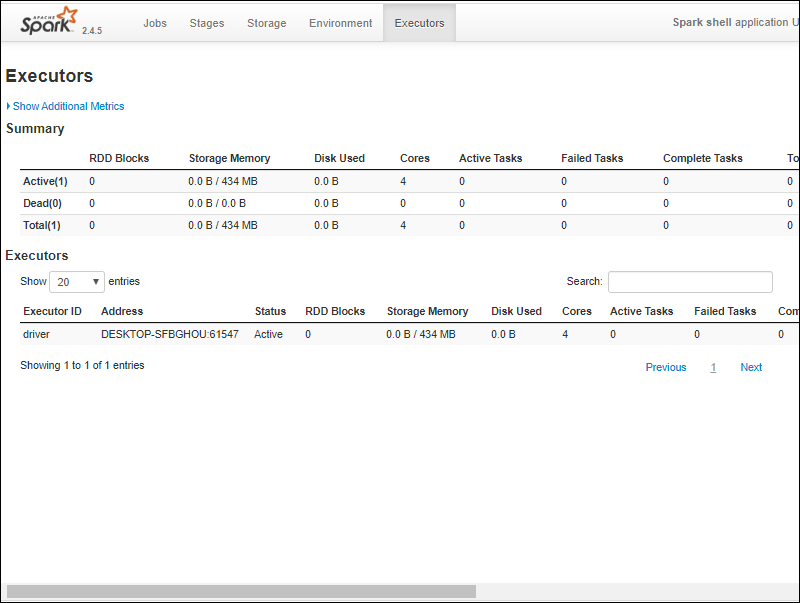
6. You should see an Apache Spark shell Web UI. The example below shows the Executors page.
7. To exit Spark and close the Scala shell, press ctrl-d in the command-prompt window.
Note: If you installed Python, you can run Spark using Python with this command:
Test Spark
In this example, we will launch the Spark shell and use Scala to read the contents of a file. You can use an existing file, such as the README file in the Spark directory, or you can create your own. We created pnaptest with some text.
1. Open a command-prompt window and navigate to the folder with the file you want to use and launch the Spark shell.
2. First, state a variable to use in the Spark context with the name of the file. Remember to add the file extension if there is any.
3. The output shows an RDD is created. Then, we can view the file contents by using this command to call an action:
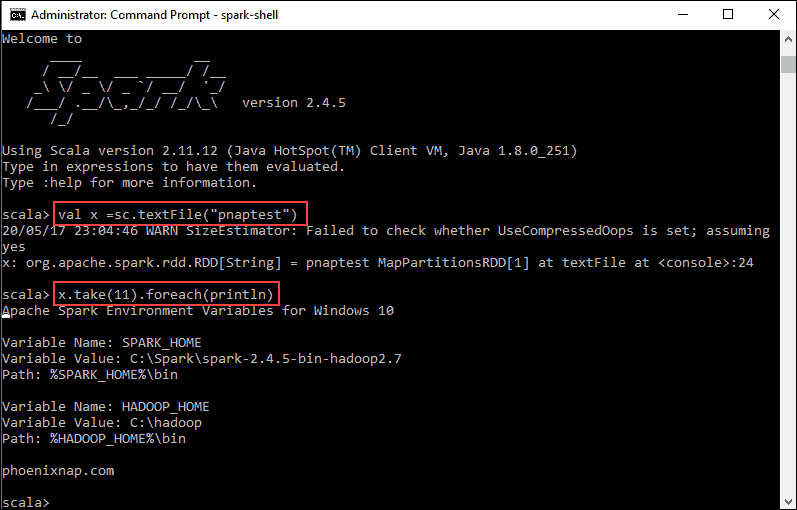
This command instructs Spark to print 11 lines from the file you specified. To perform an action on this file (value x), add another value y, and do a map transformation.
4. For example, you can print the characters in reverse with this command:
5. The system creates a child RDD in relation to the first one. Then, specify how many lines you want to print from the value y:
The output prints 11 lines of the pnaptest file in the reverse order.
You should now have a working installation of Apache Spark on Windows 10 with all dependencies installed. Get started running an instance of Spark in your Windows environment.
Our suggestion is to also learn more about what Spark DataFrame is, the features, and how to use Spark DataFrame when collecting data.