Как ускорить код на Python в тысячу раз

Обычно говорят, что Python очень медленный
В любых соревнованиях по скорости выполнения программ Python обычно занимает последние места. Кто-то говорит, что это из-за того, что Python является интерпретируемым языком. Все интерпретируемые языки медленные. Но мы знаем, что Java тоже язык такого типа, её байткод интерпретируется JVM. Как показано, в этом бенчмарке, Java намного быстрее, чем Python.
Вот пример, способный показать медленность Python. Используем традиционный цикл for для получения обратных величин:
3,37 с ± 582 мс на цикл (среднее значение ± стандартное отклонение после 7 прогонов по 1 циклу)
Ничего себе, на вычисление всего 1 000 000 обратных величин требуется 3,37 с. Та же логика на C выполняется за считанные мгновения: 9 мс; C# требуется 19 мс; Nodejs требуется 26 мс; Java требуется 5 мс(!), а Python требуется аж целых 3,37 СЕКУНДЫ. (Весь код тестов приведён в конце).
Первопричина такой медленности
Обычно мы называем Python языком программирования с динамической типизацией. В программе на Python всё представляет собой объекты; иными словами, каждый раз, когда код на Python обрабатывает данные, ему нужно распаковывать обёртку объекта. Внутри цикла for каждой итерации требуется распаковывать объекты, проверять тип и вычислять обратную величину. Все эти 3 секунды тратятся на проверку типов.
В отличие от традиционных языков наподобие C, где доступ к данным осуществляется напрямую, в Python множество тактов ЦП используется для проверки типа.

Даже простое присвоение числового значения — это долгий процесс.
Шаг 1. Задаём a->PyObject_HEAD->typecode тип integer
Шаг 2. Присваиваем a->val =1
Подробнее о том, почему Python медленный, стоит прочитать в чудесной статье Джейка: Why Python is Slow: Looking Under the Hood
Итак, существует ли способ, позволяющий обойти проверку типов, а значит, и повысить производительность?
Решение: универсальные функции NumPy
В отличие list языка Python, массив NumPy — это объект, созданный на основе массива C. Доступ к элементу в NumPy не требует шагов для проверки типов. Это даёт нам намёк на решение, а именно на Universal Functions (универсальные функции) NumPy, или UFunc.
Если вкратце, благодаря UFunc мы можем проделывать арифметические операции непосредственно с целым массивом. Перепишем первый медленный пример на Python в версию на UFunc, она будет выглядеть так:
Это преобразование не только повышает скорость, но и укорачивает код. Отгадаете, сколько теперь времени занимает его выполнение? 2,7 мс — быстрее, чем все упомянутые выше языки:
2,71 мс ± 50,8 мкс на цикл (среднее значение ± стандартное отклонение после =7 прогонов по 100 циклов каждый)
Здесь можно найти все операторы Ufunc.
Подводим итог
Если вы пользуетесь Python, то высока вероятность того, что вы работаете с данными и числами. Эти данные можно хранить в NumPy или DataFrame библиотеки Pandas, поскольку DataFrame реализован на основе NumPy. То есть с ним тоже работает Ufunc.
UFunc позволяет нам выполнять в Python повторяющиеся операции быстрее на порядки величин. Самый медленный Python может быть даже быстрее языка C. И это здорово.
Приложение — код тестов на C, C#, Java и NodeJS
На правах рекламы
Воплощайте любые идеи и проекты с помощью наших VDS с мгновенной активацией на Linux или Windows. Создавайте собственный конфиг в течение минуты!
Ускорение кода на Python средствами самого языка
Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и на Хабре.
Так что же делать?
Тогда, если для вашего проекта выше перечисленные методы не подошли, что делать? Менять Python на другой язык? Нет, сдаваться нельзя. Будем оптимизировать сам код. Примеры будут взяты из программы, строящей множество Мандельброта заданного размера с заданным числом итераций.
Время работы исходной версии при параметрах 600*600 пикселей, 100 итераций составляло 3.07 сек, эту величину мы возьмем за 100%
Скажу заранее, часть оптимизаций приведет к тому, что код станет менее pythonic, да простят меня адепты python-way.
Шаг 0. Вынос основного кода программы в отдельную
Данный шаг помогает интерпретатору python лучше проводить внутренние оптимизации про запуске, да и при использовании psyco данный шаг может сильно помочь, т.к. psyco оптимизирует лишь функции, не затрагивая основное тело программы.
Если раньше рассчетная часть исходной программы выглядела так:
мы получили время 2.4 сек, т.е. 78% от исходного.
Шаг 1. Профилирование
Стандартная библиотека Python’a, это просто клондайк полезнейших модулей. Сейчас нас интересует модуль cProfile, благодаря которому, профилирование кода становится простым и, даже, интересным занятием.
Полную документацию по этому модулю можно найти здесь, нам же хватит пары простых команд.
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
.
С её помощью, легко определить места, требующие оптимизации (строки с наибольшими значениями ncalls (кол-во вызовов функции), tottime и percall (время работы всех вызовов данной функции и каждого отдельного соответственно)).
В моем случае интересной частью вывода было (время выполнение отличается от указанного выше, т.к. профилировщик добавляет свой «оверхед»):
4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
3533224 0.296 0.000 0.296 0.000
360000 0.081 0.000 0.081 0.000
360000 0.044 0.000 0.044 0.000
360000 0.036 0.000 0.036 0.000
.
Итак, профиль получен, теперь займемся оптимизацией вплотную.
Шаг 2. Анализ профиля
Видим, что на первом месте по времени стоит наша основная функция mandelbrot, за ней идет системная функция abs, за ней несколько функций из модуля math, далее — одиночные вызовы функций, с минимальными временными затратами, они нам не интересны.
Итак, системные функции, «вылизаные» сообществом, нам врядли удастся улучшить, так что перейдем к нашему собственному коду:
Шаг 3. Математика
Сейчас, код выглядит так:
Заметим, что оператор возведения в степень ** — довольно «общий», нам же необходимо лишь возведение во вторую степень, т.е. все конструкции вида x**2 можно заменить на х*х, выиграв таким образом еще немного времени. Посмотрим на время:
1.9 сек, или 62% изначального времени, достигнуто простой заменой двух строк:
Шажки 5, 6 и 7. Маленькие, но важные
Прописная истина, о которой знают все программисты на Python — работа с глобальными переменными медленней работы с локальными. Но часто забывается факт, что это верно не только для переменных но и вообще для всех объектов. В коде функции идут вызовы нескольких функций из модуля math. Так почему бы не импортировать их в самой функции? Сделано:
Еще 0.1сек отвоевано.
Вспомним, что abs(x) вернет число типа float. Так что и сравнивать его стоит с float а не int:
Еще 0.15сек. 53% от начального времени.
И, наконец, грязный хак.
В конкретно этой задаче, можно понять, что нижняя половина изображения, равна верхней, т.о. число вычислений можно сократить вдвое, получив в итоге 0.84сек или 27% от исходного времени.
Заключение
Профилируйте. Используйте timeit. Оптимизируйте. Python — мощный язык, и программы на нем будут работать со скоростью, пропорциональной вашему желанию разобраться и все отполировать:)
Цель данной статьи, показать, что за счет мелких и незначительных изменения, таких как замен ** на *, можно заставить зеленого змея ползать до двух раз быстрее, без применения тяжелой артиллерии в виде Си, или шаманств psyco.
Также, можно совместить разные средства, такие как вышеуказанные оптимизации и модуль psyco, хуже не станет:)
Спасибо всем кто дочитал до конца, буду рад выслушать ваши мнения и замечания в комментариях!
UPD Полезную ссылку в коментариях привел funca.
Три простых способа улучшить производительность кода Python
1. Бенчмарк, бенчмарк и еще раз бенчмарк
Тестирование производительности программы кажется утомительным процессом. Но если у вас уже есть рабочий код Python, разделенный на функции, то задачу можно свести к простому добавлению декоратора к функции, требующей профилирования.
Прежде всего установим line_profiler, позволяющий измерить затраты времени на каждую строчку кода в функции:
Во время исполнения программы функция sum_of_lists при вызове будет профилирована. Обратите внимание на декоратор @profile над определением функции.
Чтобы запустить бенчмарк, введите:

В пятой колонке видим, какой процент времени исполнения ушел на каждую строчку. Это поможет вам определить, какие участки кода нуждаются в оптимизации больше всего.
Имейте в виду, что эта библиотека для измерения сама потребляет значительные ресурсы во время использования. Но она замечательно подходит для выявления слабых мест в программе с последующей заменой их на что-нибудь более эффективное.
Чтобы запустить line_profiler из Jupyter Notebook, попробуйте магическую команду %%lprun .
2. По возможности избегайте циклов
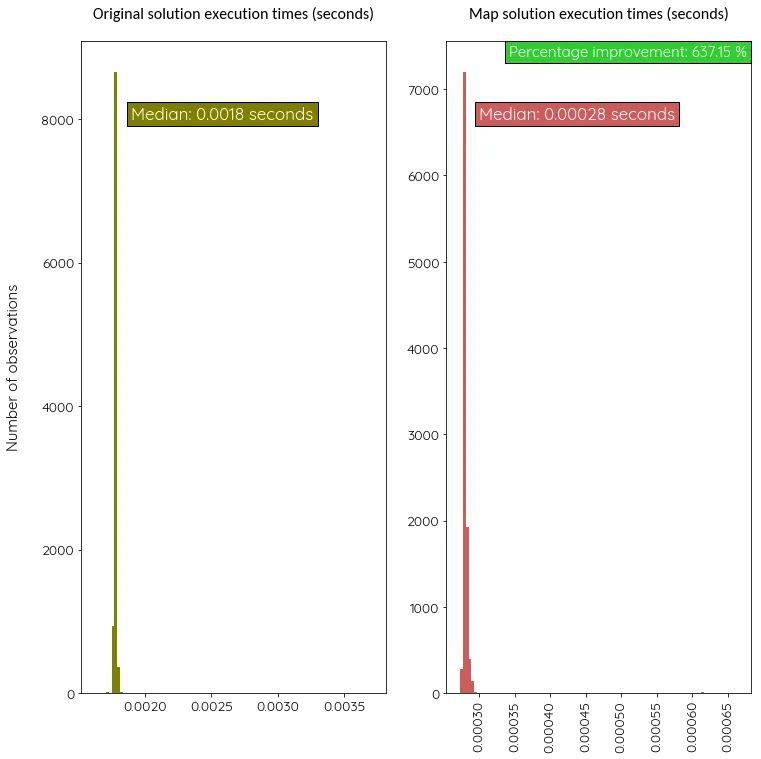
Посмотрим, насколько резво работает новая версия с картой по сравнению с изначальной. Измерим их скорость 1000 раз.
Версия с map более чем в 6 раз быстрее!
3. Компилируйте ваши модули Python с помощью Cython
Если совсем нет желания редактировать проект, но хочется хоть какого-нибудь улучшения производительности без лишних усилий, ваш лучший друг – Cython.
Для этого потребуется установить на машине как собственно Cython, так и компилятор С:
Если вы работаете на Debian системе, загрузите GCC следующим образом:
Давайте разделим изначальный код примера на два файла с названиями test_cython.py и test_module.pyx :
Наш главный файл должен импортировать эту функцию с файла test_module.pyx :
Теперь напишем скрипт setup.py для компиляции нашего модуля при помощи Cython:
Наконец пришло время скомпилировать наш модуль:
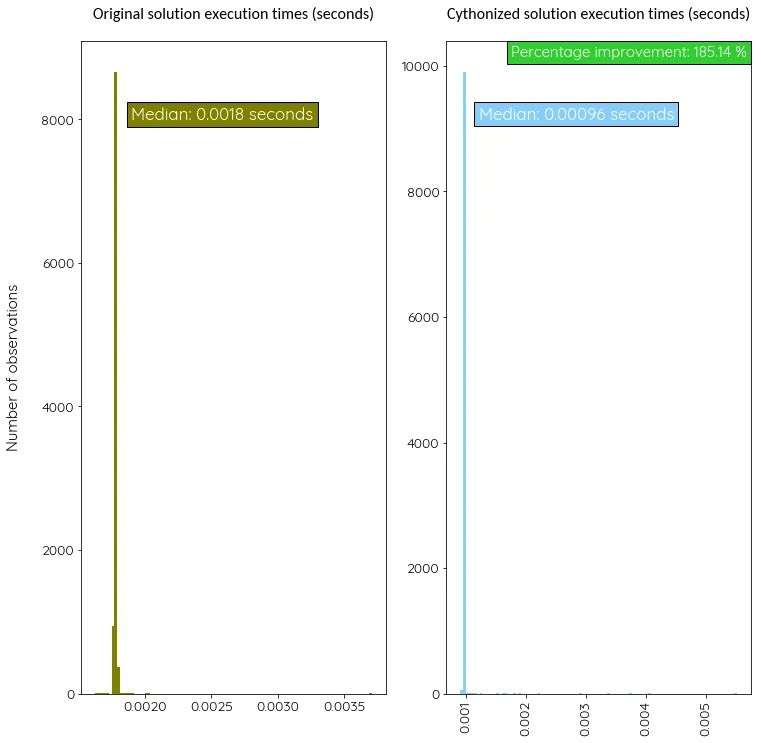
Теперь сравним эффективность этой версии с оригинальной, произведя, снова-таки, тысячу измерений.
В этом случае Cython улучшил производительность нашей программы почти вдвое по сравнению с первым вариантом. Но этот показатель будет меняться в зависимости от того, какого рода код вы пытаетесь оптимизировать.
Итоги
Python & оптимизация времени и памяти
Введение
Зачастую скорость выполнения python оставляет желать лучшего. Некоторые отказываются от использования python именно по этой причине, но существует несколько способов оптимизировать код python как по времени, так и по используемой памяти.
Хотелось бы поделиться несколькими методами, которые помогают в реальных задачах. Я пользуюсь win10 x64.
Экономим память силами Python
В качестве примера рассмотрим вполне реальный пример. Пусть у нас имеется некоторый магазин в котором есть список товаров. Вот нам понадобилось поработать с этими товарами. Самый хороший вариант, когда все товары хранятся в БД, но вдруг что-то пошло не так, и мы решили загрузить все товары в память, дабы обработать их. И тут встает резонный вопрос, а хватит ли нам памяти для работы с таким количеством товаров?
Давайте первым делом создадим некий класс, отвечающий за наш магазин. У него будет лишь 2 поля: name и listGoods, которые отвечают за название магазина и список товаров соответственно.
Теперь мы хотим наполнить магазин товарами (а именно заполнить поле listGoods). Для этого создадим класс, отвечающий за информацию об одном товаре (я использую dataclass’ы для таких примеров).
Далее необходимо заполнить наш магазин товарами. Для чистоты эксперимента я создам по 200 одинаковых товаров в 3х категориях:
Теперь пришло время измерить память, которую занимает наш магазин в оперативке (для измерения памяти я использую модуль pympler):
Получается, что наш магазин в оперативке занял почти 106Кб. Да, это не так много, но если учесть, что я сохранил лишь 600 товаров, заполнив в них только информацию о наименовании, цене и валюте, в реальной задаче придется хранить в несколько раз больше полей. Например, можно хранить артикул, производителя, количество товара на складе, страну производителя, цвет модели, вес и много других параметров. Все эти данные могут раздуть ваш магазин с нескольких килобайт до нескольких сотен мегабайт (и это при условии, что данные еще даже не начинали обрабатываться).
Теперь перейдем к решению данной проблемы. Python создает новый объект таким образом, что под него выделяется очень много информации, о которой мы даже не догадываемся. Надо понимать, что python создает объект __dict__ внутри класса для того, чтобы можно было добавлять новые атрибуты и удалять уже имеющиеся без особых усилий и последствий. Посмотрим, как можно динамически добавлять новые атрибуты в класс.
Однако в нашем примере это абсолютно не играет никакой роли. Мы уже заранее знаем, какие атрибуты должны быть у нас. В python’e есть магический атрибут __slots__, который позволяет отказаться от __dict__. Отказ от __dict__ приведет к тому, что для новых классов не будет создаваться словарь со всеми атрибутами и хранимым в них данными, по итогу объем занимаемой памяти должен будет уменьшиться. Изменим немного наши классы:
И протестируем по памяти наш магазин.
Как видно, объем, занимаемый магазином, уменьшился почти в 2.4 раза (значение может варьироваться в зависимости от операционной системы, версии Python, значений и других факторов). У нас получилось оптимизировать занимаемый объем памяти, добавив всего пару строчек кода. Но у такого подхода есть и минусы, например, если вы захотите добавить новый атрибут, вы получите ошибку:
На этом преимущества использования слотов не заканчиваются, из-за того, что мы избавились от атрибута __dict__ теперь ptyhon’у нет необходимости заполнять словарь каждого класса, что влияет и на скорость работы алгоритма. Протестируем наш код при помощи модуля timeit, первый раз протестируем наш код на отключенных __slots__ (включенном__dict__):
Результат оказался более чем удовлетворительным, получилось ускорить код примерно на 15% (тестирование проводилось несколько раз, результат был всегда примерно одинаковый).
Таким образом, у нас получилось не только уменьшить объем памяти, занимаемой программой, но и ускорить наш код.
Пытаемся ускорить код
Способов ускорить python существует несколько, начиная от использования встроенных фишек язык (например, описанных в прошлой главе), заканчивая написанием расширений на C/C++ и других языках.
Я расскажу лишь о тех способах, которые не займут у вас много времени на изучение и позволят в короткий срок начать пользоваться этим функционалом.
Cython
На мой взгляд Cython является отличным решением, если вы хотите писать код на Python, но при этом вам важна скорость выполнения кода. Реализуем код для подсчета сумм стоимости всех телевизоров, телефонов и тостеров на чистом Python и рассчитаем время, которое было затрачено (будем создавать 20.000.000 товаров):
Перепишем класс магазина под cython:
Теперь в main.py нашего проекта сделаем вызов cython кода. Для этого делаем сначала импорт всех установленных библиотек:
И делаем сразу же компиляцию нашего cython и его импорт в основной python код
Теперь необходимо вызвать код cython
Запускаем. Обратим внимание, что было выведено в консоли. В cython, где мы делали вывод времени на создание товаров, мы получили:
А там где был вывод после подсчета сумм получили:
Как мы видим, скорость создания товаров сократилась с 44 до 4 секунд, то есть мы ускорили данную часть кода почти в 11 раз. При подсчете сумм время сократилось с 13 секунд до 1 секунды, примерно в 13 раз.
Магия Python
Бывает так, что нет возможности переписать код на cython или другой язык, потому что уже имеется достаточно большая кодовая база (или по другой причине), а скорость выполнения программы хочется увеличить. Рассмотрим код из прошлого примера, где мы использовали лямбда функции и генератор списков. Тут на помощь может прийти PyPy, это интерпретатор языка python, использующий JIT компилятор. Однако PyPy поддерживает не все сторонние библиотеки, если вы используете в коде таковые, то изучите подробнее документацию. Выполнить python код при помощи PyPy очень легко.
Для начала качаем PyPy с официального сайта. Распаковываем в любую папку, открываем cmd и заходим в папку, где теперь лежит файл pypy3.exe, в эту же папку положим наш код с программой. Теперь в cmd пропишем следующую команду:
Таким образом, 19 секунд python’овского кода из прошлого примера у нас получилось сократить до 4.5 секунд вообще без переписывания кода, то есть почти в 4 раза.
Вывод
Мы рассмотрели несколько вариантов оптимизации кода по времени и памяти. На зло всем хейтерам, которые говорят, что python медленный, мы смогли достичь ускорения кода в десятки раз.
Были рассмотрены не все возможные варианты ускорения кода. В некоторых случаях можно использовать Numba, NumPy, Nim или multiprocessing. Все зависит от того, какую задачу вы решаете. Некоторые задачи будет проще решать на других языках, так как python не способен решить всё на этом свете.
7 простых способов оптимизировать код Python
1. Используйте операции с множествами (set)
Python использует хеш-таблицы для управления множествами. Всякий раз, когда мы добавляем элемент в множество, интерпретатор Python определяет его позицию в памяти, выделенной для множества, используя хэш целевого элемента.
Поскольку Python автоматически изменяет размер хеш-таблицы, скорость будет постоянной (O (1)) вне зависимости от размера набора. Именно это ускоряет выполнение операций.
В Python операции с множествами включают объединение, пересечение и разность. Поэтому вы можете попробовать использовать их в своем коде – там, где это возможно. Обычно эти операции работают быстрее, чем итерации по спискам. 
2. Избегайте использования глобальных переменных.
Это не касается не только Python, почти все языки не одобряют чрезмерное или незапланированное использование глобальных переменных. Причина в том, что у них могут быть скрытые / неочевидные побочные эффекты, ведущие к коду Спагетти. Плюс ео всему, Python очень медленный при доступе к внешним переменным.
Это вынуждает ограничить использование глобальных переменных. Можно объявить внешнюю переменную, используя ключевое слово global (что тоже не всегда правильно 😊).
Кроме того, лучше сделать локальную копию, прежде чем использовать глобальные переменные внутри циклов.
3. Использование внешних библиотек / пакетов.
Некоторые библиотеки python имеют эквивалент «C» с теми же функциями, что и исходная библиотека. Будучи написаны на “C”, они работают быстрее. Например, попробуйте использовать cPickle вместо использования pickle.
Также можно использовать пакет PyPy. Он включает компилятор JIT (Just-in-time), который делает код Python невероятно быстрым. PyPy можно дополнительно настроить для еще большего повышения производительности.
4. Используйте встроенные модули и функции.
Python является интерпретируемым языком и основан на абстракциях высокого уровня. Поэтому лучше использовать встроенные модули везде, где это возможно. Это сделает код более эффективным, поскольку встроенные модули предварительно компилируются и выполняются быстро. В то время как длительные итерации, которые включают интерпретируемые шаги, выполняются очень медленно.
Аналогичным образом, предпочтительно использовать встроенные функции, такие как, например, map, которые значительно ускоряют код
5. Ограничьте поиск в методе с использованием цикла
При работе в цикле нужно кэшировать вызов метода, а не вызывать метод для объекта. В противном случае поиск получится дороговатым.
Просто взгляните на этот пример, и сразу станет понятно, о чем речь. 
6. Оптимизация использования строк.
Конкатенация строк идет медленно, никогда не делайте это внутри цикла. Вместо этого используйте метод join. Или используйте функцию форматирования для формирования унифицированной строки.
7. Оптимизация при помощи оператора if.
Как и в большинстве языков программирования, в Python есть “ленивая” оценка. Это означает, что если есть цепочка условий «and», то проверка остановится на первом ложном условии.
Также можно сначала проверить быстрое условие (если оно есть), например «строка должна начинаться с @», или «строка должна заканчиваться точкой».



