
Установка Auto PY to EXE
Установка через pip
При помощи следующей команды можно установить текущую версию Auto PY to EXE.
Установка с GitHub
Также можно выполнить установку напрямую с GitHub. Для установки Auto PY to EXE с GitHub необходимо сначала клонировать репозиторий GitHub.
Можно также проверить версию при помощи следующей команды:

Текущая версия Auto PY to EXE 2.9.0 и теперь она установлена на ваш компьютер.
Открываем приложение
Чтобы открыть Auto PY to EXE, нужно выполнить в терминале следующую команду:
Откроется удобное приложение с GUI:
Интерфейс пользователя Auto PY to EXE
Процесс преобразования
Шаг 1. Добавляем местоположение файла
Добавляем местоположение файла
Я добавил местоположение основного файла Python моего проекта. Здесь я использую для примера один из своих проектов на Python. Это приложение с GUI, визуализирующее различные алгоритмы сортировки. О создании этого проекта можно прочитать здесь: Build a Sorting Algorithm Visualizer in Python
Шаг 2. Выбор «One Directory» или «One File»
One directory или One file
Шаг 3. Выбор «Console Based» или «Window Based»
После этого нужно будет выбрать тип приложения: консольное (Console Based) или оконное (Window Based). Если выбрать «Window Based», то это скроет весь консольный вывод приложения. Если ваш проект генерирует консольный вывод, то нужно выбрать «Console Based». Если у вас приложение с GUI или вам не нужно отображать пользователю консольный вывод, то выберите «Window Based». Я выбрал второй вариант, потому что моё приложение имеет GUI.
Console Based или Window Based
Шаг 4. Преобразование
Нажмите кнопку для преобразования
Для завершения процесса придётся немного подождать.
Папка с результатами
После завершения процесса можно будет выбрать опцию открытия папки с результатами.
Готово! Наш проект на Python теперь преобразован в исполняемый файл. Его можно запускать на других компьютерах без необходимости установки Python.
Ресурсы
На правах рекламы
Серверы для всех, в том числе, и для разработчиков! VDS с посуточной оплатой на базе новейших процессоров AMD EPYC и хранилища на основе NVMe дисков от Intel для размещения проектов любой сложности, создавайте собственную конфигурацию сервера в пару кликов!
pyqtdeploy, или упаковываем Python-программу в exe’шник… the hard way
Наверняка, каждый, кто хоть раз писал что-то на Python, задумывался о том, как распространять свою программу (или, пусть даже, простой скрипт) без лишней головной боли: без необходимости устанавливать сам интерпретатор, различные зависимости, кроссплатформенно, чтобы одним файлом-exe’шником (на крайний случай, архивом) и минимально возможного размера.
Для этой цели существует немало инструментов: PyInstaller, cx_Freeze, py2exe, py2app, Nuitka и многие другие… Но что, если вы используете в своей программе PyQt? Несмотря на то, что многие (если не все) из выше перечисленных инструментов умеют упаковывать программы, использующие PyQt, существует другой инструмент от разработчиков самого PyQt под названием pyqtdeploy. К моему несчастью, я не смог найти ни одного вменяемого гайда по симу чуду, ни на русском, ни на английском. На хабре и вовсе, если верить поиску, есть всего одно упоминание, и то — в комментариях (из него я и узнал про эту утилиту). К сожалению, официальная документация написана довольно поверхностно: не указан ряд опций, которые можно использовать во время сборки, для выяснения которых мне пришлось лезть в исходники, не описан ряд тонкостей, с которыми мне пришлось столкнуться.
Данная статья не претендует на всеобъемлющее описание pyqtdeploy и работы с ним, но, в конце концов, всегда приятно иметь все в одном месте, не так ли?
Замечание. В статье исполняемый файл собирается под linux. Несмотря на это, в качестве синонима используется слово «exe’шник» для экономии букв и уменьшения числа повторений.
Тут мне подвернулся pyqtdeploy. «Утилита от самих разработчиков PyQt… Ну уж они-то должны знать, как по-максимуму отвязаться от лишних зависимостей внутри PyQt и Qt?» — подумал я и взялся плотненько за сей агрегат.
Так что же такое pyqtdeploy? В первом приближении, то же самое, что и выше перечисленные программы. Все ваши модули (стандартная библиотека, PyQt, все прочие модули) упаковываются средствами Qt (используется утилита rcc) в так называемый файл ресурсов, генерируется обертка вокруг питоновского интерпретатора на C++, позволяющая получать доступ ко все вашим модулям, и потом все это пакуется/компилируется/… в исполняемый файл. Для работы самого pyqtdeploy нужны Python 3.5+ и PyQt5. Перечислим несколько особенностей (за подробностями сюда и сюда):
Установка pyqtdeploy
Как уже было сказано выше, у нас должен быть установлен Python 3.5+ и PyQt5:
Сборка нашего exe’шника состоит из нескольких этапов:
Структура программы
Возьмем в качестве примера проект со следующей структурой: main.py — «точка входа» для нашей программы, она вызывает mainwindow.py — допустим, отрисовывает окошечко с виджетами и берет из resources иконку icon.png и mainwindow.ui, сгенерированный нами с помощью Qt Designer. Имеющиеся зависимости, версии библиотек и прочие необходимые вещи будут всплывать по ходу повествования:
Обзор плагинов sysroot (документация)
Как уже было сказано ранее, на этом этапе мы собираем все необходимые части, которые затем будут использоваться при генерации исполняемого файла. Данный процесс осуществляется с использованием конфигурационного файла sysroot.json (в принципе, вы можете назвать его как хотите и указать затем путь к нему). Он состоит из блоков, каждый из которых описывает сборку отдельного компонента (Python, Qt и т.д.). В pyqtdeploy реализован API, позволяющий вам написать свой плагин, управляющий сборкой необходимой вам библиотеки/модуля/whatever, если он еще не реализован разработчиками pyqtdeploy. Давайте пробежимся по стандартным плагинам и их параметрам (примеры из документации):
openssl (не обязательный) — позволяет собирать из исходников или использовать установленную в системе библиотеку (подробности). Компонент, описывающий данный плагин в sysroot.json, выглядит следующим образом:
zlib (не обязательный) — используется при сборке других компонентов (если не указан, по идее, будет использоваться тот, что установлен в системе) (подробности):
qt5 (обязательный) — тут понятно (подробности):
python (обязательный) — тут тоже понятно (подробности):
sip (обязательный) — компонент, отвечающий за автоматическое генерирование Python-bindings для C/C++ библиотек (подробности тут и тут):
pyqt5 (обязательный) — тут тоже понятно (подробности):
pyqt3D, pyqtchart, pyqtdatavisualization, pyqtpurchasing, qscintilla (не обязательные) — дополнительные модули, не входящие в состав PyQt. Имеют единственный параметр source — имя архива с исходниками.
Стоит заметить, что некоторые значения параметров могут не работать друг с другом. В таких случаях вы получите ошибку при сборке sysroot с информацией, что не так. Я постарался здесь описать такие случаи, по крайней мере, для обязательных компонентов.
Собираем sysroot
Давайте взглянем на итоговый sysroot.json для нашей программы:
Что интересного мы тут видим? Во-первых, не используется ряд компонентов(например, ssl, pyqt3D и прочие). Во-вторых, собирать наш exe’шник мы будет под linux (а точнее, linux-64; в нашем случае, можно не указывать перед каждым компонентом платформу).
В pyqt5 собираем только модули QtCore, QtGui, QtWidgets.
Прежде чем приступить к сборке sysroot, не забываем скачать все необходимые исходники: zlib, Qt5, Python, sip, PyQt5 и кладем их в папочку с sysroot.json (можно и любую другую, указав потом путь к ней). Запускаем сборку:
Данная команда имеет еще несколько опций, которые можно посмотреть здесь.
Ну и запаситесь попкорном, ибо, в зависимости от мощности вашего калькулятора компьютера, это может занять немалое время.
Создаем «проектный» файл (документация)
Как только у нас все удачно собралось, приступаем к выбору модулей, которые мы хотим запаковать в exe’шник. Для этого в pyqtdeploy есть удобная утилита с GUI. Запускаем (имя .pdy файла может быть любым):
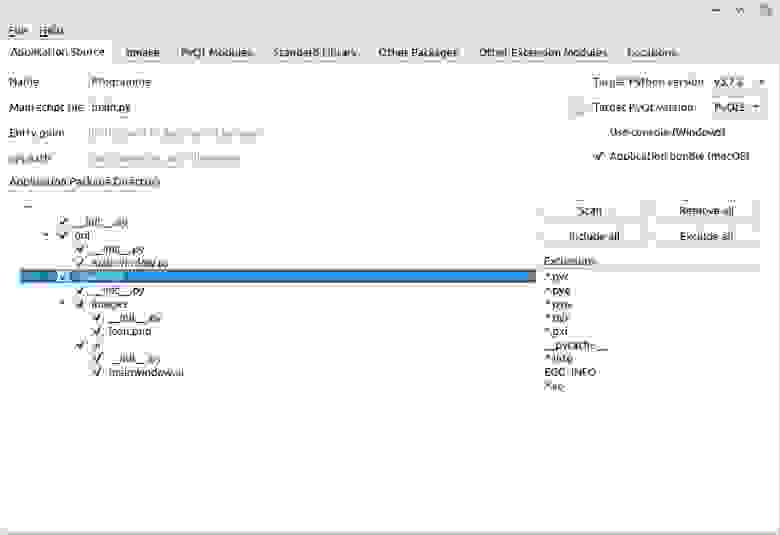
Application Source. В первой вкладке мы видим следующие настройки:
Еще один момент: любой файл с расширением .py будет «заморожен» (будет сгенерирован байт-код) — в ряде случаев это может быть нежелательным.
qmake. Так как в сборке участвует qmake, здесь можно добавить дополнительные параметры для него (я не использовал);

PyQt Modules. На этой вкладке выделяем все PyQt-модули, которые мы явно импортируем в нашей программе. Если они зависят от других модулей, те выделятся автоматически. В нашем случае использовались QtCore, QtGui, QtWidgets, uic; sip подхватился автоматом.
Если планируется использовать уже установленный PyQt, а не привязывать статически его к нашему исполняемому файлу, ничего не выделяем (такой сценарий не тестировался).
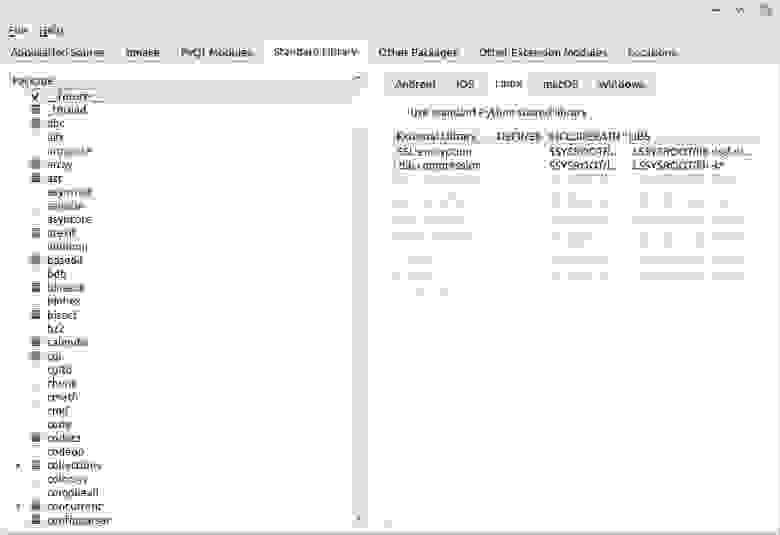
Standard Library. Здесь тот же подход, что и в предыдущем пункте, только для стандартной библиотеки. Если у вас в программе явно импортируется какой-то модуль, ставим галку. Если выделенным нами модулям (или самому интерпретатору) нужны другие модули, они выделятся автоматом (квадратики).
Python использует ряд модулей/пакетов (например, ssl), которым для работы нужны внешние библиотеки. Если мы хотим их статически привязать, то мы настраиваем это дело справа. В INCLUDEPATH указываем путь к заголовочным файлам (headers), в LIBS — путь к этой либе (мной не использовались, так что подробности смотрим в доках).
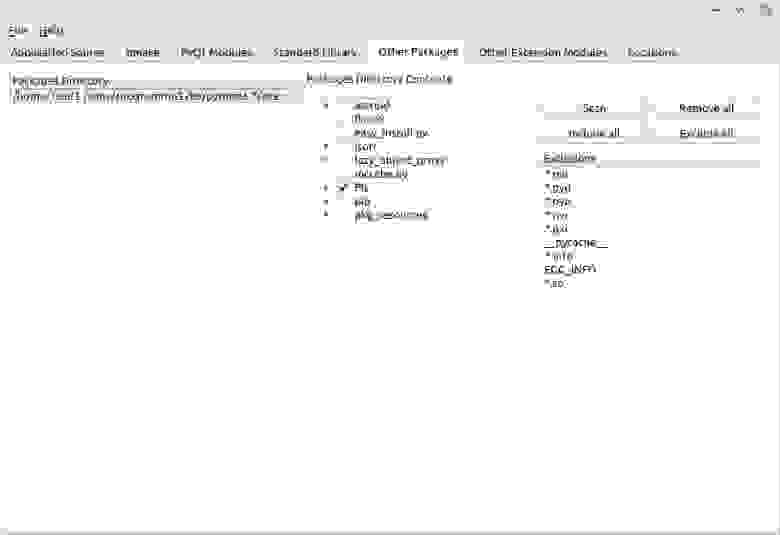
Other Packages. На этой вкладке выбираем необходимые нам сторонние пакеты (например, установленные из pypi). Подход тот же, что и в Application source: кликаем дважды на пустой строке, выбираем папку (в нашем случае, site-packages используемого при разработке virtual environment), жмем Scan и выбираем нужные пакеты/модули (у нас это PIL).
Other Extension Modules. Тут мы настраиваем модули расширения на C, которые хотим СТАТИЧЕСКИ привязать к exe’шнику (сторонние; те, что в стандартной библиотеке, привязываются сами).
С компиляцией я не разбирался, но советую почитать, во-первых, про эту вкладку в доках, во-вторых, про qmake (там гораздо подробнее описаны опции, чем в pyqt’шных доках).
Locations. Тут тоже подробно не останавливаемся, за описанием отдельных путей сюда. Если вы действовали в соответствии с этой статьей (собранный sysroot лежит тут же, рядом с main.pdy), тут менять ничего не надо.
Собираем exe’шник (документация)
Наконец-таки собираем наш исполняемый файл:
Гипотетически, все должно собраться, на деле — доки и гугл вам в помощь.
Лирическое отступление #1 — меняем поведение программы в зависимости от того, «заморожено» оно или нет
Если вам нужно определить, запущена ваша программа как есть или из собранного exe’шника, используется тот же подход, что и в PyInstaller:
Лирическое отступление #2 — использование ресурсов (изображения, иконки и пр.)
У Qt имеется специальная «система ресурсов», которая позволяет с помощью утилиты rcc упаковать любые бинарные файлы в exe’шник. Далее с помощью пути специального формата вы можете получить доступ к необходимому ресурсу. В нашем проекте файл с иконкой icon.png расположен в src/resources/images, тогда путь в «системе ресурсов» будет выглядеть так — :/src/resources/images/icon.png. Как видите, ничего хитрого. Однако с таким путем есть одна засада — его понимают только Qt’шные функции. Т.е. если вы напишите у себя в программе что-нибудь в духе:
Все будет в порядке. Но если, например, так:
Ничего не выйдет, ибо open будет пытаться найти такой путь в вашей файловой системе и, естественно, ничего не найдет.
Если вам нужно читать запакованные ресурсы не только средствами Qt (например, вы, как и я, создавали GUI с помощью Qt Designer и получили файл .ui, который потом надо прочитать с помощью loadUi ), нужно будет сделать как-то так:
Итоги
Стоит ли так сильно заморачиваться, если вам нужен exe’шник, и старые добрые дедовские способы распространения программы вам по каким-то причинам не подходят? Если вы не используете PyQt, то, на мой взгляд, точно не стоит. Используйте что-нибудь более дружелюбное (тот же PyInstaller). Если хотите выжать максимум соков из вашего файла — дерзайте. В конечном счете мне таки удалось уменьшить размер файла до
35 МБ), что все-равно больше, чем хотелось бы.
Когда у нас собрана минимально необходимая Qt и PyQt, было бы неплохо попробовать сделать на их основе exe’шник с помощью PyInstaller или cx_Freeze и посмотреть на размер, но это, как говорится, уже другая история.
Как скомпилировать Python
Я хочу рассказать об удивительном событии, о котором я узнал пару месяцев назад. Оказывается, одна популярная python-утилита уже более года распространяется в виде бинарных файлов, которые компилируются прямо из python. И речь не про банальную упаковку каким-нибудь PyInstaller-ом, а про честную Ahead-of-time компиляцию целого python-пакета. Если вы удивлены так же как и я, добро пожаловать под кат.
Объясню, почему я считаю это событие по-настоящему удивительным. Существует два вида компиляции: Ahead-of-time (AOT), когда весь код компилируется до запуска программы и Just in time compiler (JIT), когда непосредственно компиляция программы под требуемую архитектуру процессора осуществляется во время ее выполнения. Во втором случае первоначальный запуск программы осуществляется виртуальной машиной или интерпретатором.
Если сгруппировать популярные языки программирования по типу компиляции, то получим следующий список:
Ahead-of-time compiler: C, C++, Rust, Kotlin, Nim, D, Go, Dart;
Just in time compiler: Lua, С#, Groovy, Dart.
В python из коробки нет JIT компилятора, но отдельные библиотеки, предоставляющие такую возможность, существуют давно
Смотря на эту таблицу, можно заметить определенную закономерность: статически типизированные языки находятся в обеих строках. Некоторые даже могут распространяться с двумя версиями компиляторов: Kotlin может исполняться как с JIT JavaVM, так и с AOT Kotlin/Native. То же самое можно сказать про Dart (версии 2). A вот динамически типизированные языки компилируются только JIT-ом, что впрочем вполне логично.
При запуске виртуальная машина сначала накапливает информацию о типах переменных, затем после накопления статистики, запускается компиляция наиболее нагруженных частей программы. Виртуальная машина отслеживает типы аргументов и переключает выполнение программы между уже скомпилированными и не скомпилированными участками кода в зависимости от текущих значений переменных.
При использовании JIT компиляции типы не очень то и нужны, ведь информация о типах собирается во время работы программы. Поэтому все популярные динамически типизированные языки программирования распространяются именно с JIT компилятором. Но как быть с AOT компиляцией кода, в котором нет типов? Меня очень заинтересовал этот вопрос, и я полез разбираться.
С апреля 2019 года эта утилита распространяется в скомпилированном виде, о чем рассказывается в блоге проекта. А для компиляции используется еще одна утилита от тех же авторов — mypyc. Погуглив немного, я нашел достаточно большую статью “Путь к проверке типов 4 миллионов строк Python-кода” про становление и развитие mypy (на Хабре доступен перевод: часть 1, часть 2, часть 3). Там немного рассказывается о целях создания mypyc: столкнувшись с недостаточной производительностью mypy при разборе крупных python-проектов в Dropbox, разработчики добавили кеширование результатов проверки кода, а затем возможность запуска утилиты как сервиса. Но исчерпав очевидные возможности оптимизации, столкнулись с выбором: переписать все на go или на cython. В результате проект пошел по третьему пути — написание своего AOT python-компилятора.
Дело в том, что для правильной работы mypy и так необходимо построить то же синтаксическое дерево, что и интерпретатору во время исполнения кода. То есть mypy уже “понимает” python, но использует эту информацию только для статистического анализа, а вот mypyc может преобразовывать эту информацию в полноценный бинарный код.
Думаю тут многие решили, что разобрались в вопросе того, как скомпилировать динамически типизированный python-код. Python c версии 3.4 поддерживает аннотацию типов, а mypy как раз и используется для проверки корректности аннотаций. Получается, python как бы уже и не динамически типизированный язык, что позволяет применить AOT компиляцию. Но загвоздка в том, что mypyc может компилировать и неаннотированный код!
Функция bubble_sort
Для примера рассмотрим функцию сортировки “пузырьком”. Файл lib.py:
У типов нет аннотаций, но это не мешает mypyc ее скомпилировать. Чтобы запустить компиляцию, нужно установить mypyc. Он не распространяется отдельным пакетом, но если у вас установлен mypy, то и mypyc уже присутствует в системе! Запускаем mypyc, следующей командой:
После запуска в проекте будут созданы следующие директории:
.mypy_cache — mypy кэш, mypyc неявно запускает mypy для разбора программы и получения AST;
build — артефакты сборки;
lib.cpython-38-x86_64-linux-gnu.so — собственно сборка под целевую платформу. Данный файл представляет из себя готовый CPython Extension.
CPython Extension — встроенный в CPython механизм взаимодействия с кодом, написанным на С/C++. По сути это динамическая библиотека, которую CPython умеет загружать при импорте нашего модуля lib. Через данный механизм осуществляется взаимодействие с модулями, написанными на python.
Компиляция состоит из двух фаз:
Компиляция python кода в код С;
Компиляция С в бинарный .so файл, для этого mypyc сам запускает gcc (gcc и python-dev также должен быть установлены).
Файл lib.cpython-38-x86_64-linux-gnu.so имеет преимущество перед lib.py при импорте на соответствующей платформе, и исполняться теперь будет именно он.
Ну и давайте сравним производительность модуля до и после компиляции. Для этого создадим файл main.py с кодом запуска сортировки:
Получим примерно следующие результаты:
Ожидаемо скомпилированный код оказался быстрее (
в 2 раза), что неплохо, так как для такого результата нам потребовалось запустить лишь одну команду. Хотя от скомпилированного кода привычно ожидаешь большего.
Чтобы ответить на вопрос “как компилируется динамически типизированный код”, придется заглянуть в представление этой функции на С. Но разобрать ее будет достаточно сложно, поэтому давайте попробуем разобраться с примером попроще.
Функция sum(a, b)
Скомпилируем функцию суммы от двух переменных:
Перед запуском компиляции я ожидал увидеть примерно следующий код на С:
Однако результат оказался cущественно иным (код немного упрощен):
Рассмотрим, что тут происходит. Во-первых, так как мы не знаем типы входных переменных, функция в качестве аргументов принимает указатели на объекты класса PyObject, по сути это внутренние CPython структуры. Далее компилятор должен сложить эти объекты, но как, если настоящие типы аргументов неизвестны во время компиляции: это могут быть целые числа, числа с плавающей точкой, списки и вообще не факт, что аргументы можно складывать, тогда нужно вернуть ошибку. И что же делает в этом случае mypyc?
Как оказалось, все очень просто: он просит CPython самостоятельно сложить эти аргументы. Функция PyNumber_Add — это внутренняя функция СPython, которая доступна из расширения, ведь СPython отлично умеет складывать свои объекты.
Взаимодействие CPython c Extension можно изобразить следующим диалогом:
— А посчитай-ка мне функцию sum для A, B;
— Хорошо, но скажи сначала, сколько будет A + B;
Вот такой нехитрый прием используется при компиляции динамического кода: компилируем все, что можем, а все остальное отдаем интерпретатору.
Конечно, данный пример выглядит гротескно, но даже несмотря на такую неэффективность, mypyc позволяет добиться существенного прироста производительности, как в примере с сортировкой.
Функция sum(a: int, b: int)
Для повышения эффективности, нужно, чтобы расширение, получив управление, могло как можно дольше оставлять его у себя без обращения к CPython. Если бы у mypyc была информация о типах переменных, то он бы мог самостоятельно произвести сложение без возврата управления. Но вывести типы самостоятельно mypyc не может, он даже не контролирует код, из которого осуществляется вызов функции sum. Соответственно, ему нужно помочь, проставив аннотации вручную. Давайте посмотрим, как поменяется результирующая С-функция, если добавить аннотацию типов:
Скомпилированный результат на C (немного очищенный):
Главное, что можно заметить: функция существенно поменялась, а значит, компилятор реагирует на появление аннотации. Давайте разбираться, что изменилось.
Теперь CPyDef_sum получает на вход не указатели на PyObject, а структуры CPyTagged. Это все еще не int, но уже и не часть CPython, а часть библиотек mypyc, которую он добавляет в скомпилированный код расширения. Для ее инициализации в рантайме сначала проверяется тип, так что теперь функция sum работает только с int и обойти аннотацию не получится.
Далее происходит вызов CPyTaggetAdd вместо PyNumber_Add. Это уже внутренняя функция mypyc. Если заглянуть в код CPyTaggetAdd, то можно понять, что там происходит проверка диапазонов значений a и b, и если они укладываются в int, то происходит простое суммирование, а также проверка на переполнение:
— А посчитай-ка мне функцию sum для A, B;
— Хорошо, тогда держи ответ С.
Функция bubble_sort(data: List[int])
Настало время вернуться к функции сортировки, чтобы провести замеры скорости. Изменим начальную функцию, добавив аннотацию для data:
Скомпилируем результат и замерим время сортировки:
Внутри виртуальной машины Python. Часть 2
Оглавление
Компиляция исходного кода Python
Python обычно не рассматривается как компилируемый язык, но на самом деле он является таковым. Во время компиляции исходный код, написанный на Python, преобразуется в байт-код, который потом выполняется виртуальной машиной. Однако, процесс компиляции в Python является довольно простым и не включает в себя множество сложных этапов. Он состоит из следующих шагов в указанном порядке:
От исходников к дереву парсинга
Парсер Python — это синтаксический анализатор LL (1), он основывается на принципах, которые изложены в «драконьей» книге. Модуль Grammar/Grammar содержит расширенную форму Бэкуса — Наура (Extended Backus-Naur Form (EBNF)) со спецификацией грамматики языка Python. Отрывок этой спецификации показан в листинге 3.0.
Листинг 3.0. Отрывок синтаксиса BNF в Python
При выполнении модуля, переданного интерпретатору в командной строке, совершается вызов PyParser_ParseFileObject. Эта функция инициирует синтаксический анализ файла. Она же вызывает функцию токенизации PyTokenizer_FromFile, передавая ей имя файла-модуля в качестве аргумента. Функция токенизации в Python разбивает содержимое модуля на правильные токены или же выдает исключение при обнаружении недопустимых.
Python токены
Исходный код Python состоит из токенов. Например, слово return является ключевым токеном, а литерал — 2 числовым и так далее. Первая задача при синтаксическом анализе состоит в том, чтобы токенизировать исходный код, разбив его на токены-компоненты. В Python есть несколько видов токенов:
Листинг 3.1: Python алгоритм для генерации токенов INDENT и DEDENT.
Функция PyTokenizer_FromFile из модуля Parser/parsetok.c сканирует исходный Python файл слева-направо и сверху-вниз производя токенизацию содержимого. Символы пробелов (отличные от терминаторов) служат для разграничения токенов, но не являются обязательными. Там, где есть некоторая двусмысленность, такая как: 2+2, токенайзер пытается выделить максимально длинную строку, которая формирует легальный токен при чтении справа налево. В данном примере токенами являются литерал 2, оператор + и ещё один литерал 2.
Сгенерированные токены передаются парсеру, который пытается построить из них дерево «парсинга» (в соответствии с грамматикой python, подмножество которой указано в листинге 3.0). Когда анализатор обнаруживает токен, нарушающий грамматику, генерируется исключение SyntaxError. Модуль parser предоставляет ограниченный доступ к дереву конкретного кода Python и используется в листинге 3.2 для получения примера синтаксического дерева.
Листинг 3.2. Использование модуля parser для получения дерева в Python
Вызов parser.suite(source) в листинге 3.2 возвращает объект дерева (ST), который является промежуточным представлением дерева парсинга из исходного кода (предполагается, что исходный код синтаксически корректен). Вызов parser.st2list возвращает фактическое синтаксическое дерево, представленное в виде списка python. Первые элементы в списках — целые числа, которое идентифицируют продукционные правила в грамматике Python.
Рисунок 3.0: Дерево парсинга для листинга 3.2 (функция, возвращающая строку ‘hello world’)
Рисунок 3.0 — это древовидная диаграмма, показывающая то же дерево из листинга 3.2, но уже с некоторыми удаленными токенами, а также часть команд была заменена строковыми описаниями в соответствии числовым номерам. Все эти продукционные правила указаны в заголовочных файлах Include/token.h и Include/graminit.h.
В виртуальной машине CPython для представления дерева парсинга используется древовидная структура данных. Каждое продукционное правило — это узел в ней. Структура данных нода (узла) из Include/node.h показана в листинге 3.3.
Листинг 3.3: Структура данных нода в виртуальной машине
По мере обхода дерева парсинга узлы могут запрашиваться по их типу, дочерним элементам (если таковые имеются), номеру строки исходного файла (которая привела к созданию данного узла) и так далее. Макросы для взаимодействия с узлами дерева парсинга также определены в файле Include/node.h.
От дерева парсинга к абстрактному синтаксическому дереву
Следующим этапом процесса компиляции в python является преобразование деревьев парсинга в абстрактное синтаксическое дерево (AST). Абстрактное синтаксическое дерево является представлением кода, которое не зависит от тонкостей синтаксиса python. Например, дерево парсинга на рисунке 3.0 содержит узел «двоеточие» [прим. двоеточие объявления функции], потому что это синтаксическая конструкция, но, как показано в листинге 3.4, AST не будет содержать таких «подробностей».
Листинг 3.4. Использование astмодуля для управления AST исходного кода Python
Различные определения узлов AST находятся в файле Parser/Python.asdl. Большинство определений в AST соответствуют конкретной исходной конструкции, такой как оператор if или поиск атрибута. Модуль ast вместе с Python-интерпретатором дает нам возможность манипулировать AST. Такие инструменты как codegen могут по конкретному AST вывести исходный код python. В реализации CPython AST-узлы представлены C-структурами, которые определены в Include/Python-ast.h. Эти структуры фактически генерируются кодом Python. Модуль Parser/asdl_c.py генерирует этот файл из AST определения ASDL. Например, вот кусок из определения нода statement, который показан в листинге 3.5.
Union в листинге 3.5 — это ключевое слово языка C, которое используется для создания атрибута, который может принимать один из любых типов, перечисленных в самом union. Функция PyAST_FromNode в модуле Python/ast.c отвечает за генерацию AST из данного дерева парсинга. Теперь пришло время создавать байт-код из сгенерированного AST.
Построение таблицы символов
Имена и Связывания
В python на объекты ссылаются по именам. «Names» похожи на переменные в C++ или Java, но это не совсем так.
В приведенном выше примере x — это имя, которое ссылается на объект: 5. Процесс присвоения ссылки на значение 5 к x называется биндингом. Связывание приводит к тому, что имя начинает ссылаться на объект, расположенный внутри самой вложенной области видимости текущей исполняемой программы. Связывание происходит во многих случаях, например, при присваивании переменной, функции, а также метода, когда переданный параметр привязан к аргументу и т.д. Важно отметить, что имена — это просто символы и они не имеют типа, который ассоциируется с ними. Тип существует у самих объектов, на которые эти имена ссылаются.
Блоки кода
Блоки кода являются центральной частью для Python программы и их понимание имеет первостепенное значение для изучения внутреннего устройства виртуальной машины Python. Блок кода — это фрагмент программного кода, который выполняется в Python как единое целое. Примерами блоков кода являются модули, функции и классы. Команды, введенные в интерактивном режиме в REPL, команды сценария запускаемые с флагом -c, также являются блоками кода. Блок кода имеет несколько пространств имен, связанных с ним. Например, блок кода модуля имеет доступ к пространству имен global, а блок кода функции имеет также доступ к пространству имен local, по-мимо пространства global.
Пространства имен
Пространство имен (namespace) является контекстом, в котором какой-то набор имен связан с объектами. Пространства имен Python реализованы в виде словаря. Встроенное пространство имен является примером namespace, которое содержит все встроенные функции и доступ к нему можно получить через ввод __builtins__.__dict__ в терминале (выходной текст будет довольно большим). Интерпретатор имеет доступ к нескольким пространствам имен, в том числе к глобальному, встроенному и локальному. Данные в namespace создаются в разное время и также имеют разное время жизни. Например, новое локальное пространство имен создается при вызове функции и удаляется при её окончании или выходе из функции. Глобальное пространство имен создаётся в начале выполнения модуля и все имена, определенные в этом namespace, доступны во всём модуле. Встроенная область видимости создаётся, когда вызывается интерпретатор и он уже содержит все встроенные имена. Эти три пространства имен являются основными namespace доступными интерпретатору.
Области видимости
Область видимости — это часть программы, в которой набор биндингов (пространство имен) виден и доступен напрямую без использования точечной нотации. [прим. кажется, здесь опечатка и имеется ввиду доступ через функцию globals()]. Во время выполнения программы могут быть доступны следующие области видимости:
Примечание
В Python есть своеобразное правило для области видимости, которое предотвращает изменение ссылки на объект глобальной области видимости в локальной. Такое действие приведет к исключению UnboundLocalError. Следующий пример иллюстрирует это:
Листинг A3.0. Попытка изменить глобальную переменную из функции
Чтобы изменить «глобальный» объект в локальной области, необходимо использовать ключевое слово global с именем объекта:
Листинг A3.1. Использование ключевого слова global для изменения глобальной переменной из функции
Python также имеет ключевое слово nonlocal. Оно используется, когда необходимо изменить переменную, находящуюся во внешней, но «не глобальной» области видимости. Это очень удобно при работе с вложенными функциями (также называемыми замыканиями). Очень простая иллюстрация ключевого слова nonlocal показана в следующем фрагменте, который определяет простой счетчик для объекта:
Листинг A3.2. Вложенные функции со счётчиком
Листинг 3.6. Создание таблицы символов из AST
После первого прохода алгоритма таблица символов содержит все имена, которые использовались в модуле, но не содержит контекстной информации о них. Например, интерпретатор не может определить, является ли данная переменная глобальной, локальной или свободной. Вызов функции symtable_analyze из Parser/symtable.c инициирует вторую фазу генерации таблицы символов. Эта фаза алгоритма определяет область видимости (локальную, глобальную или свободную) для символов, полученных на первом этапе. Комментарии в файле Parser/symtable.c достаточно информативны и перефразированы ниже, чтобы дать представление о втором этапе процесса построения таблицы символов:
Структуры данных таблицы символов
Существует две структуры данных, которые являются центральными для генерации таблицы символов:
Листинг 3.7. Структура данных таблицы символов.
Модуль Python может содержать несколько блоков кода — например, несколько определений функций. Поле st_blocks является отображением всех существующих блоков кода в один элемент таблицы символов. Запись таблицы st_top — это таблица символов для компилируемого модуля (напомним, что модуль также является блоком кода), поэтому она будет содержать имена, определенные в глобальном пространстве имен модуля. Поле st_cur относится к записи таблицы символов для кодового блока, который обрабатывается в данный момент. Каждый блок кода внутри «блока кода модуля» имеет свою собственную запись таблицы символов, которая содержит символы, определенные в этом блоке кода.
Рисунок 3.1: таблица символов и записи в ней.
В очередной раз, просмотр структуры данных _symtable_entry из файла Include/symtable.h очень полезен, чтобы понять, как она работает. Данная структура данных показана в листинге 3.8.
Листинг 3.8. Структура данных _symtable_entry
Комментарии в исходном коде объясняют, что делает каждое поле. Поле ste_symbols содержит отображение символов/имен, которые встречаются при анализе блока кода. Флаги, на которые отображаются символы, представляют собой числовые значения, которые дают нам информацию о контексте, в котором используется символ/имя. Например, символ может быть аргументом функции или определением глобального оператора. Некоторые примеры этих флагов, определенных в модуле Include/symtable.h, приведены в листинге 3.9.
Листинг 3.9. Флаги, которые определяют контекст определения имени
Возвратимся же к обсуждению таблиц символов. Предположим, что компилируется модуль, содержащий код из листинга 3.10. После того, как таблица символов построена, есть три записи таблицы символов.
Листинг 3.10. Простая функция Python
Первая запись make_counter является замыканием модуля и будет определена областью видимости local. Следующая запись таблицы символов будет о том, что функция make_counter содержит имена count и counter, помеченные как локальные. Последняя запись таблицы символов будет о вложенной функции counter. Она будет иметь переменную count, помеченную как free. Следует отметить, что хоть make_counter и определена как локальная в записи таблицы символов, но она рассматривается как глобальная в самом блоке кода модуля, поскольку *st_global указывает на символы *st_top, которые в данном случае являются символами замыкающего модуля.
От AST к объектам кода
Следующим шагом для компилятора является генерация объектов кода из информации полученной благодаря AST и таблицам символов. Отвечающие за это функции, реализованы в модуле Python/compile.c. Процесс создания объектов кода является многоэтапным. На первом шаге AST преобразуется в базовые блоки инструкций байт-кода Python. Алгоритм преобразования похож на тот, который используется при генерации таблиц символов — функции с именами compiler_visit_xx (где xx этот тип узла) рекурсивно посещают каждый узел и генерируют базовые блоки инструкций байт-кода. Базовые блоки и связи между ними представляются в виде графа — графа потока управления [прим. именуемый также CFG — control flow graph]. Он показывает «пути» кода, которые могут быть использованы во время выполнения программы. На втором этапе сгенерированный граф потока управления «сглаживается» с использованием поиска по графу в глубину (DFS). После того как граф сглажен, рассчитывается смещения перехода и оно используется в качестве аргумента для инструкции jump байт-кода. Объекта кода генерируется из этого набора инструкций. Чтобы лучше разобраться в этом процессе, рассмотрим функцию fizzbuzz в листинге 3.11.
Листинг 3.11. Простая python функция
AST для этой функции показан на рисунке 3.2.
Рисунок 3.2: Очень простой AST для листинга 3.2
Этот AST из рисунка 3.2 при компиляции в CFG возвращает граф, аналогичный показанному на рисунке 3.3. Пустые блоки на рисунке были опущены. Рассмотрение этого графа обеспечит некоторую информацию о том, что скрывается за базовыми блоками. Базовые блоки имеют одну точку входа, но могут иметь несколько выходов. Эти блоки описаны более подробно далее.

Рисунок 3.3: Граф потока управления для функции fizzbuzz из листинга 3.11. Прямая линия представляет нормальное, прямолинейное выполнение кода, в то время как изогнутые линии представляют «прыжки».
В следующие описания включены только фактические инструкции. Для некоторых инструкций нужны аргументы, но он были удалены, поскольку сейчас нас не интересуют.
Функция LOAD_GLOBAL принимает классическую функцию str в качестве аргумента и загружает ее в стек значений. LOAD_FAST загружает аргумент n в стек, а return_value возвращает значение, полученное через CALL_FUNCTION т.е. через инструкцию str(n).
Как и в предыдущем разделе, мы рассмотрим структуры данных, которые используются при построении базовых блоков, чтобы лучше понять данный процесс.
Структура данных: compiler
На рисунке 3.4 показана взаимосвязь между основными структурами данных, используемыми в процессе генерации базовых блоков, которые составляют граф потока управления.
Рисунок 3.4: Четыре основные структуры данных, используемые при создании объекта кода.
На самом верхнем уровне находится структура данных compiler, которая отвечает за глобальный процесс компиляции модуля. Эта структура данных определена в листинге 3.12.
Листинг 3.12. Структура данных compiler
Поля, которые представляют для нас здесь интерес, следующие:
Структура данных: compiler_unit
Структура данных compiler_unit, показанная ниже в листинге 3.13, собирает информацию необходимую для генерации требуемых инструкций байт-кода в блоках кода. Большинство полей, определенных в compiler_unit, встретится нам при изучении объектов кода.
Листинг 3.13. Структура данных compiler_unit
Поля u_blocks и u_curblock ссылаются на базовые блоки, которые вместе составляют компилируемый блок кода. Поле *u_ste является ссылкой на запись таблицы символов для компилируемого блока кода. Остальные поля имеют довольно понятные имена, которые говорят сами за себя. Во время компиляции происходит обход различных узлов, составляющих блок кода. В зависимости от того, начинает ли данный тип узла новый базовый блок или нет, создается базовый блок (содержащий инструкции этих узлов), или же инструкции для узла добавляются в существующий базовый блок. Вот самые частые типы узлов, которые могут начинать новый базовый блок:
Структуры данных basic_block и instruction
Структура данных базового блока довольно интересна в рамках процесса генерации графа потока управления. Базовый блок — это последовательность инструкций, которая имеет одну точку входа, но несколько точек выхода. Определение структуры данных basic_block, используемой в виртуальной машине python, приведено в листинге 3.14.
Листинг 3.14. Структура данных basicblock_
Как упоминалось ранее, CFG в основном состоит из базовых блоков и соединительных «путей» между ними. Поле *b_instr ссылается на массив структур данных instruction и каждая из этих структур данных содержит байт-код инструкцию. Эти байт-коды можно найти в заголовочном файле Include/opcode.h. Структура данных instruction показана в листинге 3.15.
Листинг 3.15. Структура данных instruction
Ещё раз взгляните на CFG для функции fizzbuzz. Мы видим, что на самом деле есть два пути способа перейти от выполнения блока 1 к блоку 2. Первый — через нормальное выполнение, когда все инструкции в блоке 1 выполняются и поэтому поток выполнения автоматически продолжается в блоке 2. Второй способ — инструкция перехода, мы видели такую сразу после первой операции сравнения. «Целью» такой инструкции перехода является другой базовый блок, но на самом деле виртуальная машина выполняет объекты кода, которые ничего не знают о базовых блоках. Блок кода содержит только поток байт-кодов, который индексируется с помощью смещения. Получается, мы должны взять блоки с «целями» прыжка и заменить их на смещения в массиве инструкций. Это то, что делает процесс сборки базовых блоков.
Сборка базовых блоков
После того как CFG сгенерирован, базовые блоки содержат инструкции байт-кода, являющиеся репрезентацией AST. Но блоки не упорядочены линейно, а инструкции перехода все ещё содержат базовые блоки в качестве целей перехода, вместо относительного или абсолютного смещения в потоке команд. Функция assemble обрабатывает линеаризацию CFG и создание объекта кода из CFG.
Во-первых, функция сборки базовых блоков добавляет инструкции return None в любой блок, который заканчивается без оператора RETURN. Теперь вы знаете, почему вы можете определять методы без добавления RETURN. Затем следует предварительный post-order обход графа CFG (дочерние элементы посещаются перед их корневым узлом), чтобы «сгладить» блоки.
Обход графа
Расчёт смещения прыжка происходит в два этапа. На первом этапе смещение каждой инструкции в массиве инструкций рассчитывается, как показано во фрагменте из листинга 3.16. Это простой цикл, который работает с конца сглаженного массива, создавая смещение от 0.
Листинг 3.16. Расчет смещения байт-кода
На втором этапе, цели прыжка для команд перехода рассчитываются, как показано в листинге 3.17. Происходит вычисление относительных смещений при переходах и замена ими абсолютных значений.
Листинг 3.17. Сборка смещений перехода
Вычисленные смещения «прыжка» добавляются в сглаженный граф в порядке, обратном порядке обхода при линеаризации. Обратный post-order является топологической сортировкой CFG. Это означает, что для каждого ребра от вершины u до вершины v, u идет перед v в отсортированном порядке. Причина этого очевидна: мы хотим, чтобы узел, который перепрыгивает на другой, всегда был раньше «цели перехода». После завершения передачи байт-кода, объекты кода могут быть собраны для каждого блока кода, используя полученный байт-код и информацию из таблицы символов. Сгенерированный объект кода возвращается в вызывающую функцию, тем самым отмечая конец процесса компиляции.



