Обучаемый Telegram чат-бот с ИИ в 30 строчек кода на Python

Сегодня мне в голову пришла мысль: «А почему бы не написать Telegram чат-бота с ИИ, которого потом можно будет обучать?»
Сейчас сделать это совсем легко, поэтому, недолго думая, я принялся к написанию кода.
Языком я выбрал Python, т.к. на нём легче всего работать с подобного рода приложениями.
Итак, для создания Telegram чат-бота с ИИ нам потребуется:
1. API Telegram. В качестве обёртки я взял проверенную библиотеку python-telegram-bot
2. API ИИ. Выбрал я продукт от Google, а именно Dialogflow. Он предоставляет довольно-таки неплохое бесплатное API. Обёртка Dialogflow для Python
Шаг 1. Создаём бота в Telegram
Придумываем имя нашему боту и пишем @botfather. После создания бота нам придёт API токен, который желательно бы где-то сохранить, т.к. в дальнейшем он нам понадобится.

Шаг 2. Пишем основу бота
Создаём папку Bot, в которой потом создаём файл bot.py. Здесь будет код нашего бота.
Открываем консоль и переходим в директорию с файлом, устанавливаем python-telegram-bot.
После установки мы уже можем написать «основу», которая пока что будет просто отвечать однотипными сообщениями. Импортируем необходимые модули и прописываем наш токен API:
Далее напишем 2 обработчика команд. Это callback-функции, которые будут вызываться тогда, когда будет получено обновление. Напишем две таких функции для команды /start и для обычного любого текстового сообщения. В качестве аргументов туда передаются два параметра: bot и update. Bot содержит необходимые методы для взаимодействия с API, а update содержит данные о пришедшем сообщении.
Теперь осталось лишь присвоить уведомлениям эти обработчики и начать поиск обновлений.
Делается это очень просто:
Итого, полная основа скрипта выглядит вот так:
Теперь мы можем проверить работоспособность нашего нового бота. Вставляем на 2 строке наш API токен, сохраняем изменения, переносимся в консоль и запускаем бота:
После запуска пишем ему. Если всё настроено правильно, то Вы увидите вот это:
Основа бота написана, приступаем к следующему шагу!
P.s. не забывайте выключить бота, для этого вернитесь в консоль и нажмите Ctrl + C, подождите пару секунд и бот успешно завершит работу.
Шаг 3. Настройка ИИ
В первую очередь, идём и регистрируемся на Dialogflow (просто входим с помощью своего Google аккаунта). Сразу после авторизации мы попадаем в панель управления.
Жмём на кнопку Create agent и заполняем поля по усмотрению (это никакой роли не сыграет, это нужно лишь для следующего действия).
Жмём на Create и видим следующую картину:
Расскажу, почему созданный нами ранее «Агент» никакой роли не играет. Во вкладке Intents есть «команды», по которым работает бот. Сейчас он умеет лишь отвечать на фразы типа «Привет», и если не понимает, то отвечает «Я вас не понял». Не сильно впечатляет.
После создания нашего пустого агента, у нас появилась куча других вкладок. Нам нужно нажать на Prebuilt Agents (это уже специально обученные агенты, которые имеют множество команд) и из всего представленного списка выбрать Small Talk.
Наводим на него и жмём Import. Далее ничего не меняя, жмём Ok. Агент импортировался и теперь мы можем его настроить. Для этого в левом верхнем углу жмём на шестерёнку возле Small-Talk и попадаем на страницу настроек. Теперь мы можем изменить имя агента, как захотим (я оставляю как было). Меняем часовой пояс и во вкладке Languages проверяем, чтобы был установлен русский язык (если не установлен, то ставим).
Возвращаемся на вкладку General, спускаемся немного вниз и копируем Client access token
Теперь наш ИИ полностью настроен, можно возвращаться к боту.
Шаг 4. Собираем всё вместе
ИИ готов, основа бота готова, что дальше? Дальше нам нужно скачать обёртку API от Dialogflow для питона.
Установили? Возвращаемся к нашему боту. Добавляем в нашу секцию «Настройки» импорт модулей apiai и json (нужно, чтобы в будущем разбирать json ответы от dialogflow). Теперь это выглядит вот так:
Переходим к функции textMessage (которая отвечает за получение любого текстового сообщения) и посылаем полученные сообщения на сервера Dialogflow:
Этот код будет посылать запрос к Dialogflow, но нам нужно также извлечь ответ. Дописываем парочку строк, итого textMessage выглядит вот так:
Немного пояснений. С помощью
получается ответ от сервера, закодированный в байтах. Чтобы декодировать его, просто применяем метод
и после этого «заворачиваем» всё в
чтобы распарсить json ответ.
Если ответа нет (точнее, json приходит всегда, но не всегда есть сам массив с ответом ИИ), то это означает, что Small-Talk не понял пользователя (обучением можно будет заняться позже). Поэтому если «ответа» нет, то пишем пользователю «Я Вас не совсем понял!».
Итого, полный код бота с ИИ будет выглядеть вот так:
Сохраняем изменения, запускаем бота и идём проверять:
Вот и всё! Бот в 30 строк с ИИ написан!
Шаг 5. Заключительная часть
Думаю, Вы убедились, что написать бота с ИИ – дело 10 минут. Осталось лишь теперь его учить и учить. Делать это, кстати, можно во вкладке Training. Там можно посмотреть все сообщения, которые писались и что на них ответил бот (или не ответил). Там же его можно и обучать, говоря боту где он ответил правильно, а где нет.
Надеюсь, статья была Вам полезна, удачи в обучении!
PyBrain работаем с нейронными сетями на Python
В рамках одного проекта столкнулся необходимостью работать с нейронными сетями, рассмотрел несколько вариантов, больше всего понравилась PyBrain. Надеюсь её описание будет многим интересно почитать.
PyBrain — одна из лучших Python библиотек для изучения и реализации большого количества разнообразных алгоритмов связанных с нейронными сетями. Являет собой удачный пример совмещения компактного синтаксиса Python с хорошей реализацией большого набора различных алгоритмов из области машинного интеллекта.
О библиотеке
Библиотека построена по модульному принципу, что позволяет использовать её как студентам для обучения основам, так и исследователям, нуждающимся в реализации более сложных алгоритмов. Общая структура процедуры её использования приведена на следующей схеме:
Сама библиотека является продуктом с открытым исходным кодом и бесплатна для использования в любом проекте с единственно оговоркой, при её использовании для научных исследований, они просят добавлять в список цитируемых информационных источников (что народ и делает) следующую книгу:
Tom Schaul, Justin Bayer, Daan Wierstra, Sun Yi, Martin Felder, Frank Sehnke, Thomas Rückstieß, Jürgen Schmidhuber. PyBrain. To appear in: Journal of Machine Learning Research, 2010.
Основные возможности
Инструменты
Установка библиотеки
Перед установкой Pybrain, создатели рекомендуют установить следующие библиотеки:
Setuptools — пакетный менеджер для Python, который значительно упрощает установку новых библиотек. Для его установки рекомендуется скачать и выполнить (python ez_setup.py) этот скрипт.
После установки у Вас появиться возможность использовать команду для установки новых библиотек.
Сразу воспользуемся ими и установим два необходимых пакета:
Далее устанавливается сама PyBrain
Основы работы с библиотекой
Создание нейронной сети
Создание нейронной сети с двумя входами, тремя скрытыми слоями и одним выходом:
В результате, в объекте net находится созданная нейронная цепь, инициализированная случайными значениями весов.
Функция активации
Функция активации задаётся следующим образом:
Количество элементов передаваемых в сеть должно быть равно количеству входов. Метод возвращает ответ в виде единственного числа, если текущая цепь имеет один выход, и массив, в случае большего количества выходов.
Получение данных о сети
Для того, чтобы получить информацию о текущей структуре сети, каждый её элемент имеет имя. Данное имя может быть дано автоматически, либо по иным критериям при создании сети.
К примеру, для сети net имена даны автоматически:
Скрытые слои поименованы с номером слоя добавленным к имени.
Возможности при создании сети
Также возможно задать и тип выходного слоя:
Дополнительно возможно использование смещения (bias)
Оперирование данными (Building a DataSet)
Созданная сеть должна обрабатывать данные, работе с которыми и посвящён этот раздел. Типичным набором данных является набор входных и выходных значений. Для работы с ними PyBrain использует модуль pybrain.dataset, также далее используется класс SupervisedDataSet.
Настройка данных
Класс SupervisedDataSet используется для типичного обучения с учителем. Он поддерживает массивы выходных и выходных данных. Их размеры задаются при создании экземпляра класса:
Запись вида:
означает, что создаётся структура данных для хранения двухмерных входных данных и одномерных выходных.
Добавление образцов
Классической задачей при обучении нейронной сети является обучение функции XOR, далее показан набор данных используемый для создания такой сети.
Исследование структуры образца
Для получения массивов данных в текущем их наборе возможно использовать стандартные функции Python для работы с массивами.
выведет 4, так-как это количество элементов.
Итерация по множеству также может быть организована обычным для массивов способом:
Также к каждому набору полей можно получить прямой доступ с использованием его имени:
Также можно вручную освободить занимаемую образцом память полностью его удалив:
Тренировка сети на образцах
В PyBrain использована концепция тренеров (trainers) для обучения сетей с учителем. Тренер получает экземпляр сети и экземпляр набора образцов и затем обучает сеть по полученному набору.
Классический пример это обратное распространение ошибки (backpropagation). Для упрощения реализации этого подход в PyBrain существует класс BackpropTrainer.
Обучающий набор образцов (ds) и целевая сеть (net) уже созданы в примерах выше, теперь они будут объединены.
Тренер получил ссылку на структуру сети и может её тренировать.
Вызов метода train() производит одну итерацию (эпоху) обучения и возвращает значение квадратичной ошибки (double proportional to the error).
Если организовывать цикл по каждой эпохи нет надобности, то существует метод обучающий сеть до сходимости:
Данный метод возвратит массив ошибок для каждой эпохи.
Ещё примеры реализации разных сетей
Tom Schaul, Martin Felder, et.al. PyBrain, Journal of Machine Learning Research 11 (2010) 743-746.
Немного ссылок:
Заключение
В заключении хочу сказать, что эта библиотека производит очень хорошее впечатление, работать с ней удобно, описания алгоритмов получаются компактные, но не теряют понятности в дебрях кода.
Пишем голосового ассистента на Python
Введение
Технологии в области машинного обучения за последний год развиваются с потрясающей скоростью. Всё больше компаний делятся своими наработками, тем самым открывая новые возможности для создания умных цифровых помощников.
В рамках данной статьи я хочу поделиться своим опытом реализации голосового ассистента и предложить вам несколько идей для того, чтобы сделать его ещё умнее и полезнее.

Что умеет мой голосовой ассистент?
| Описание умения | Работа в offline-режиме | Требуемые зависимости |
| Распознавать и синтезировать речь | Поддерживается | pip install PyAudio (использование микрофона) |
pip install pyttsx3 (синтез речи)
Для распознавания речи можно выбрать одну или взять обе:
Шаг 1. Обработка голосового ввода
Начнём с того, что научимся обрабатывать голосовой ввод. Нам потребуется микрофон и пара установленных библиотек: PyAudio и SpeechRecognition.
Подготовим основные инструменты для распознавания речи:
Теперь создадим функцию для записи и распознавания речи. Для онлайн-распознавания нам потребуется Google, поскольку он имеет высокое качество распознавания на большом количестве языков.
А что делать, если нет доступа в Интернет? Можно воспользоваться решениями для offline-распознавания. Мне лично безумно понравился проект Vosk.
На самом деле, необязательно внедрять offline-вариант, если он вам не нужен. Мне просто хотелось показать оба способа в рамках статьи, а вы уже выбирайте, исходя из своих требований к системе (например, по количеству доступных языков распознавания бесспорно лидирует Google).
Теперь, внедрив offline-решение и добавив в проект нужные языковые модели, при отсутствии доступа к сети у нас автоматически будет выполняться переключение на offline-распознавание.
Замечу, что для того, чтобы не нужно было два раза повторять одну и ту же фразу, я решила записывать аудио с микрофона во временный wav-файл, который будет удаляться после каждого распознавания.
Таким образом, полученный код выглядит следующим образом:
Возможно, вы спросите «А зачем поддерживать offline-возможности?»
Я считаю, что всегда стоит учитывать, что пользователь может быть отрезан от сети. В таком случае, голосовой ассистент всё еще может быть полезным, если использовать его как разговорного бота или для решения ряда простых задач, например, посчитать что-то, порекомендовать фильм, помочь сделать выбор кухни, сыграть в игру и т.д.
Шаг 2. Конфигурация голосового ассистента
Поскольку наш голосовой ассистент может иметь пол, язык речи, ну и по классике, имя, то давайте выделим под эти данные отдельный класс, с которым будем работать в дальнейшем.
Для того, чтобы задать нашему ассистенту голос, мы воспользуемся библиотекой для offline-синтеза речи pyttsx3. Она автоматически найдет голоса, доступные для синтеза на нашем компьютере в зависимости от настроек операционной системы (поэтому, возможно, что у вас могут быть доступны другие голоса и вам нужны будут другие индексы).
Также добавим в в main-функцию инициализацию синтеза речи и отдельную функцию для её проигрывания. Чтобы убедиться, что всё работает, сделаем небольшую проверку на то, что пользователь с нами поздоровался, и выдадим ему обратное приветствие от ассистента:
На самом деле, здесь бы хотелось самостоятельно научиться писать синтезатор речи, однако моих знаний здесь не будет достаточно. Если вы можете подсказать хорошую литературу, курс или интересное документированное решение, которое поможет разобраться в этой теме глубоко — пожалуйста, напишите в комментариях.
Шаг 3. Обработка команд
Теперь, когда мы «научились» распознавать и синтезировать речь с помощью просто божественных разработок наших коллег, можно начать изобретать свой велосипед для обработки речевых команд пользователя 😀
В моём случае я использую мультиязычные варианты хранения команд, поскольку у меня в демонстрационном проекте не так много событий, и меня устраивает точность определения той или иной команды. Однако, для больших проектов я рекомендую разделить конфигурации по языкам.
Для хранения команд я могу предложить два способа.
1 способ
Можно использовать прекрасный JSON-подобный объект, в котором хранить намерения, сценарии развития, ответы при неудавшихся попытках (такие часто используются для чат-ботов). Выглядит это примерно вот так:
Такой вариант подойдёт тем, кто хочет натренировать ассистента на то, чтобы он отвечал на сложные фразы. Более того, здесь можно применить NLU-подход и создать возможность предугадывать намерение пользователя, сверяя их с теми, что уже есть в конфигурации.
Подробно этот способ мы его рассмотрим на 5 шаге данной статьи. А пока обращу ваше внимание на более простой вариант
2 способ
Можно взять упрощенный словарь, у которого в качестве ключей будет hashable-тип tuple (поскольку словари используют хэши для быстрого хранения и извлечения элементов), а в виде значений будут названия функций, которые будут выполняться. Для коротких команд подойдёт вот такой вариант:
Для его обработки нам потребуется дополнить код следующим образом:
В функции будут передаваться дополнительные аргументы, сказанные после командного слова. То есть, если сказать фразу «видео милые котики«, команда «видео» вызовет функцию search_for_video_on_youtube() с аргументом «милые котики» и выдаст вот такой результат:
Пример такой функции с обработкой входящих аргументов:
Ну вот и всё! Основной функционал бота готов. Далее вы можете до бесконечности улучшать его различными способами. Моя реализация с подробными комментариями доступна на моём GitHub.
Ниже мы рассмотрим ряд улучшений, чтобы сделать нашего ассистента ещё умнее.
Шаг 4. Добавление мультиязычности
Чтобы научить нашего ассистента работать с несколькими языковыми моделями, будет удобнее всего организовать небольшой JSON-файл с простой структурой:
В моём случае я использую переключение между русским и английским языком, поскольку мне для этого доступны модели для распознавания речи и голоса для синтеза речи. Язык будет выбран в зависимости от языка речи самого голосового ассистента.
Для того, чтобы получать перевод мы можем создать отдельный класс с методом, который будет возвращать нам строку с переводом:
В main-функции до цикла объявим наш переводчик таким образом: translator = Translation()
Теперь при проигрывании речи ассистента мы сможем получить перевод следующим образом:
Как видно из примера выше, это работает даже для тех строк, которые требуют вставки дополнительных аргументов. Таким образом можно переводить «стандартные» наборы фраз для ваших ассистентов.
Шаг 5. Немного машинного обучения
А теперь вернёмся к характерному для большинства чат-ботов варианту с JSON-объектом для хранения команд из нескольких слов, о котором я упоминала в пункте 3. Он подойдёт для тех, кто не хочет использовать строгие команды и планирует расширить понимание намерений пользователя, используя NLU-методы.
Грубо говоря, в таком случае фразы «добрый день«, «добрый вечер» и «доброе утро» будут считаться равнозначными. Ассистент будет понимать, что во всех трёх случаях намерением пользователя было поприветствовать своего голосового помощника.
С помощью данного способа вы также сможете создать разговорного бота для чатов либо разговорный режим для вашего голосового ассистента (на случаи, когда вам нужен будет собеседник).
Для реализации такой возможности нам нужно будет добавить пару функций:
А также немного модифицировать main-функцию, добавив инициализацию переменных для подготовки модели и изменив цикл на версию, соответствующую новой конфигурации:
Однако, такой способ сложнее контролировать: он требует постоянной проверки того, что та или иная фраза всё ещё верно определяется системой как часть того или иного намерения. Поэтому данным способом стоит пользоваться с аккуратностью (либо экспериментировать с самой моделью).
Заключение
На этом мой небольшой туториал подошёл к концу.
Мне будет приятно, если вы поделитесь со мной в комментариях известными вам open-source решениями, которые можно внедрить в данный проект, а также вашими идеями касательно того, какие ещё online и offline-функции можно реализовать.
Документированные исходники моего голосового ассистента в двух вариантах можно найти здесь.
P.S: решение работает на Windows, Linux и MacOS с незначительными различиями при установке библиотек PyAudio и Google.
Кстати, тех, кто планирует строить карьеру в IT, я буду рада видеть на своём YouTube-канале IT DIVA. Там вы сможете найти видео по тому, как оформлять GitHub, проходить собеседования, получать повышение, справляться с профессиональным выгоранием, управлять разработкой и т.д.
Нейронная сеть на практике с Python и Keras
Что такое машинное обучение и почему это важно?
Машинное обучение — это область искусственного интеллекта, использующая статистические методы, чтобы предоставить компьютерным системам способность «учиться». То есть постепенно улучшать производительность в конкретной задаче, с помощью данных без явного программирования. Хороший пример — то, насколько эффективно (или не очень) Gmail распознает спам или насколько совершеннее стали системы распознавания голоса с приходом Siri, Alex и Google Home.
С помощью машинного обучения решаются следующие задачи:
Машинное обучение — огромная область, и сегодня речь пойдет лишь об одной из ее составляющих.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
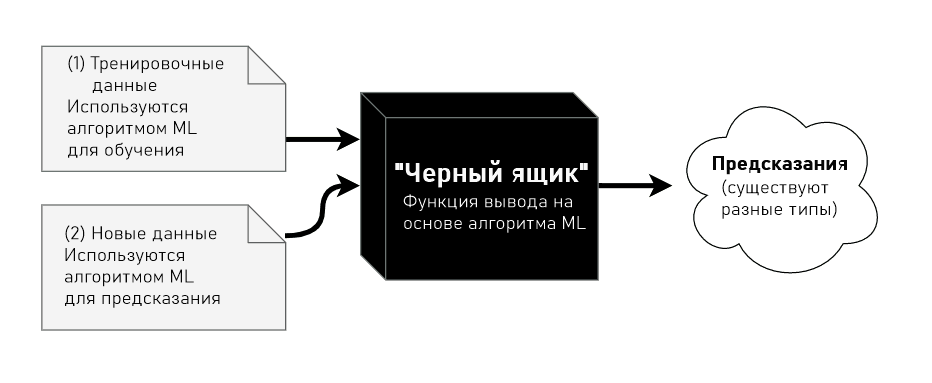
Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
В этом материале в качестве модели будет использоваться нейронная сеть.
Понимание работы нейронных сетей
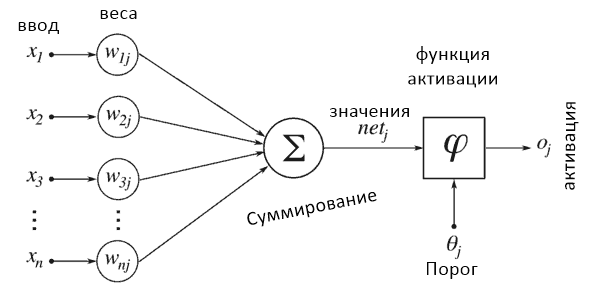
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.
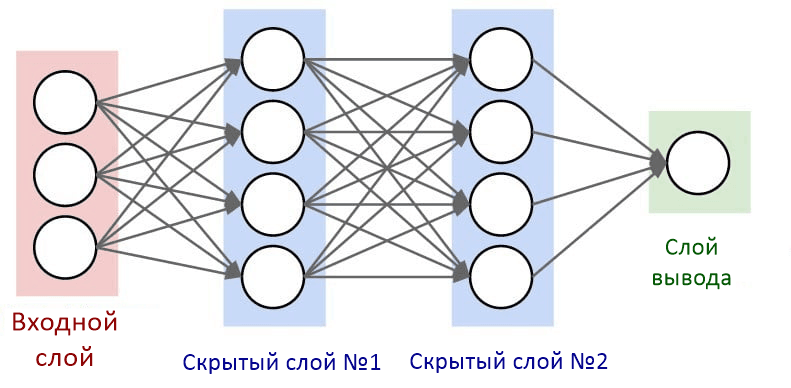
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.
Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Список необходимых библиотек:
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
Если эти модули установлены, то теперь можно запускать весь код в проекте.
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. MNIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:

Чтение меток
Файл ярлыка тренировочного набора (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | label |
Значения меток от 0 до 9.
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
Чтение изображений
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | pixel |
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
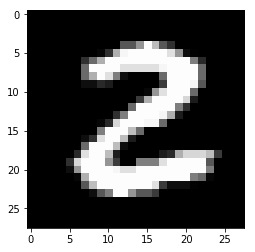
Кодирование меток изображения с помощью One-hot encoding
Будем использовать one-hot encoding для превращения целевых меток в вектор.
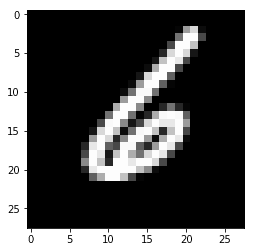
В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
Для обучения нейронной сети, выполним этот код.
Проверяем точность на тренировочных данных.
Посмотрим результаты
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Построим изображения соответствующей картинки
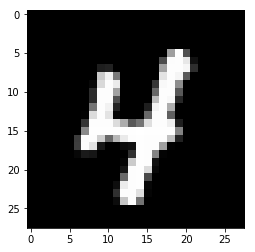
Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вывод слоя softmax — это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
Чтение вывода слоя softmax для конкретной цифры
Как можно видеть дальше, 5-ой индекс действительно близок к 1 (0,99), а это значит, что он с большой долей вероятности является
4… а это так и есть!
Просмотр матрицы ошибок

Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы. С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Попробуйте сами
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python:



