Как открыть исходный код страницы сайта в любом браузере
Веб-страница, которую вы читаете, состоит, среди прочего, из исходного кода. Это информация, которую ваш веб-браузер загружает и преобразует в то, что вы сейчас читаете.
Большинство веб-браузеров предоставляют возможность просматривать исходный код веб-страницы без дополнительного программного обеспечения, независимо от того, на каком устройстве вы находитесь. Некоторые даже предлагают расширенные функциональные возможности и структуру, облегчая просмотр HTML и другого программного кода на странице.
Зачем нужен исходный код
Есть несколько причин, по которым вы можете захотеть увидеть исходный код страницы. Если вы веб-разработчик, возможно, вы захотите увидеть конкретный стиль или реализацию другого программиста. Может быть, вы занимаетесь обслуживанием сайта и пытаетесь выяснить, почему определенная часть веб-страницы отображается или ведет себя не так, как должна.
Вы также можете быть новичком, пытаетесь научиться кодировать свои собственные страницы и ищите примеры из реальной жизни. Конечно, возможно, что вы не попадаете ни в одну из этих категорий и просто хотите просмотреть исходный код из чистого любопытства.
Ниже приведены инструкции по просмотру исходного кода в выбранном вами браузере.
Исходный код страницы в Google Chrome
Настольная версия Chrome предлагает три различных способа просмотра исходного кода страницы, первый и самый простой с использованием следующей комбинации клавиш быстрого доступа: CTRL + U ( COMMAND + OPTION + U в macOS).
При нажатии этой комбинации вы откроете новую вкладку браузера с HTML и другим кодом активной страницы. Этот источник имеет цветовую кодировку и структурирован таким образом, чтобы упростить выделение и поиск того, что вы ищете. Вы также можете получить это, введя следующий текст в адресную строку Chrome, добавив выделенную часть слева от URL-адреса веб-страницы, и нажав клавишу Enter : view-source: (например, view-source:https://webznam.ru).
Третий метод заключается в использовании инструментов разработчика Chrome, которые позволяют вам глубже погрузиться в код страницы, а также настроить её на лету для целей тестирования и разработки. Интерфейс инструментов разработчика можно открывать и закрывать с помощью сочетания клавиш: CTRL + SHIFT + I ( COMMAND + OPTION + I в macOS).
Вы также можете запустить их по следующему пути:
Google Chrome на Android
Просмотр источника веб-страницы в Chrome для Android также просто: добавьте следующий текст перед адресом (или URL) – view-source:. HTML и другой код рассматриваемой страницы будет немедленно отображаться в активном окне.
Google Chrome на iOS
Хотя нет собственных методов просмотра исходного кода с помощью Chrome на iPad, iPhone или iPod touch, наиболее простым и эффективным является использование стороннего решения, такого как приложение View Source.
Исходный код страницы в Microsoft Edge
Браузер Edge позволяет просматривать, анализировать и даже манипулировать исходным кодом текущей страницы через интерфейс инструментов разработчика.
После первого запуска инструментов разработчика Edge добавляет в контекстное меню браузера две дополнительные опции (доступные по щелчку правой кнопкой мыши в любом месте веб-страницы): Проверить элемент и Просмотреть источник, последний из которых открывает интерфейс инструментов разработчика с исходным кодом страницы сайта.
Исходный код страницы в Mozilla Firefox
Чтобы просмотреть исходный код страницы в настольной версии Firefox, вы можете нажать CTRL + U ( COMMAND + U на macOS) на клавиатуре, чтобы открыть новую вкладку, содержащую HTML и другой код для активной веб-страницы.
При вводе следующего текста в адресную строку Firefox, непосредственно слева от URL-адреса страницы, на текущей вкладке будет отображён исходный код: view-source: (например, view-source:https://webznam.ru).
Ещё один способ получить доступ к исходному коду страницы – воспользоваться инструментами разработчика Firefox, доступными с помощью следующих шагов.
Firefox также позволяет вам просматривать исходный код для определенной части страницы, что позволяет легко выявлять проблемы. Для этого сначала выделите интересующую область мышью. Затем щелкните правой кнопкой мыши и выберите Исходный код выделенного фрагмента из контекстного меню браузера.
Mozilla Firefox на Android
Просмотр исходного кода в Android версии Firefox достижим через использование view-source: в URL-адресе.
Mozilla Firefox на iOS
Исходный код страницы в Apple Safari
Хотя Safari для iOS по умолчанию не включает возможность просмотра источника страницы, браузер довольно легко интегрируется с приложением View Source, доступным в App Store за 0,99 долл. США.
После установки этого стороннего приложения вернитесь в браузер Safari и нажмите кнопку «Поделиться», расположенную в нижней части экрана и представленную квадратом и стрелкой вверх. Теперь должен быть виден общий лист iOS, перекрывающий нижнюю половину окна Safari. Прокрутите вправо и нажмите кнопку «Просмотр источника».
Теперь должно отображаться структурированное представление с цветовой кодировкой исходного кода активной страницы вместе с другими вкладками, которые позволяют просматривать ресурсы страницы, сценарии и многое другое.
На MacOS
Чтобы просмотреть исходный код страницы в настольной версии Safari, сначала необходимо включить меню «Разработка». Следующие шаги помогут вам активировать это скрытое меню и отобразить исходный HTML-код страницы:
Исходный код страницы в браузере Opera
Чтобы просмотреть исходный код активной веб-страницы в браузере Opera, используйте следующую комбинацию клавиш: CTRL + U ( COMMAND + OPTION + U в macOS). Если вы предпочитаете загружать источник в текущей вкладке, введите следующий текст слева от URL-адреса страницы в адресной строке и нажмите Enter : view-source:
Настольная версия Opera также позволяет просматривать исходный код HTML, CSS и другие элементы с помощью встроенных инструментов разработчика. Чтобы запустить этот интерфейс, который по умолчанию будет отображаться в правой части главного окна браузера, нажмите следующую комбинацию клавиш: CTRL + SHIFT + I ( COMMAND + OPTION + I в macOS).
Исходный код в браузере Vivaldi
Вы также можете добавить следующий текст в начало URL-адреса страницы, который отображает исходный код на текущей вкладке: view-source:
Другой метод – через интегрированные инструменты разработчика браузера, доступные по сочетанию клавиш CTRL + SHIFT + I или через опцию средств разработчика в меню.
Как научиться читать код сайта и зачем это нужно, если вы не программист

Часто возникают ситуации, когда необходимо проанализировать содержимое веб-страницы: посмотреть description, узнать размер какого-то элемента или просто выяснить, какой используется шрифт. С помощью опции «Просмотреть код» можно узнать не только это, но и многое другое – практически всю подноготную сайта.
Для каких целей нужен навык чтения кода и как в несколько кликов посмотреть содержимое сайта? Об этом и многом другом поговорим в сегодняшней статье.
Зачем мне нужен исходный код сайта?
Думаете, если вы не программист или верстальщик, то код вам вряд ли понадобится? На самом деле, он может помочь в разных ситуациях. Код может быть полезен:
Еще несколько возможностей при просмотре кода страницы: выгрузка картинок с исходным размером, просмотр сайта в адаптивном режиме, возможность изменять содержимое веб-страницы. Последнее работает в локальном режиме – изменения будут применены только на текущем ПК до тех пор, пока страница не будет обновлена.
Как узнать код сайта
Прежде чем переходить к просмотру кода сайта, давайте сначала разберемся, что же включает в себя код любого веб-ресурса. Как правило, это список пронумерованных строк с информацией о том или ином элементе сайта. Если открыть код главной страницы Timeweb, то мы увидим, что в четвертой строке установлен заголовок документа:
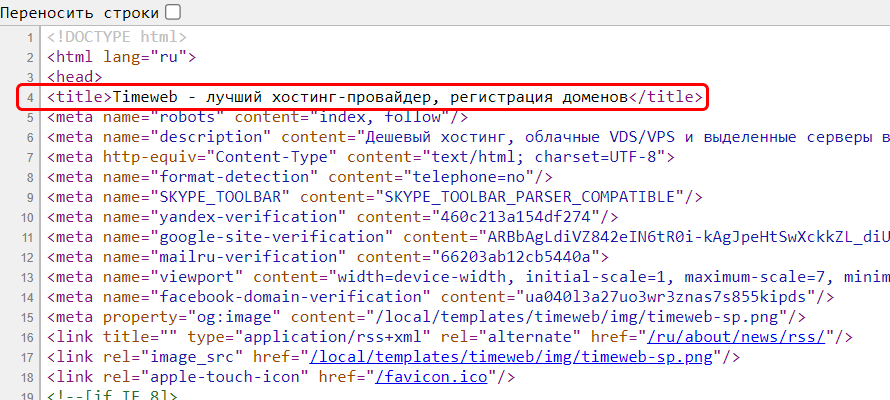
Как видите, здесь все логично и понятно.
Подробнее о том, что представляет собой код сайта, мы поговорим в следующем разделе, а пока давайте рассмотрим основные способы его просмотра.
Способ 1: Функция «Посмотреть код»
Открываем страницу, код которой нужно просмотреть, и кликаем по любой области правой кнопкой мыши. В отобразившемся меню выбираем «Посмотреть код». Также вы можете воспользоваться комбинацией клавиш «CTRL+SHIFT+I».
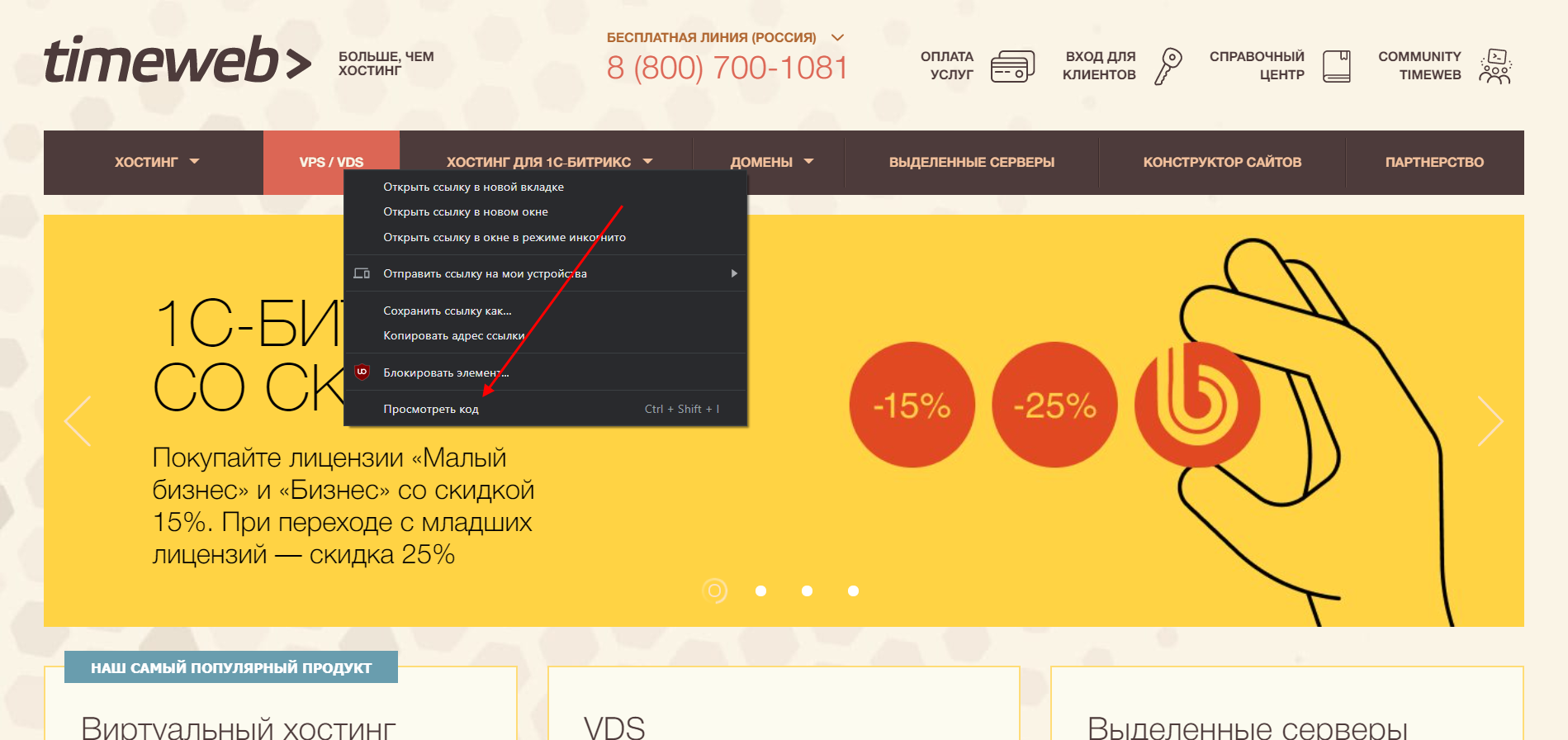
В результате мы попадаем в инспектор браузера – на экране появляется дополнительное окно, где сверху находится код страницы, а снизу – CSS-стили.
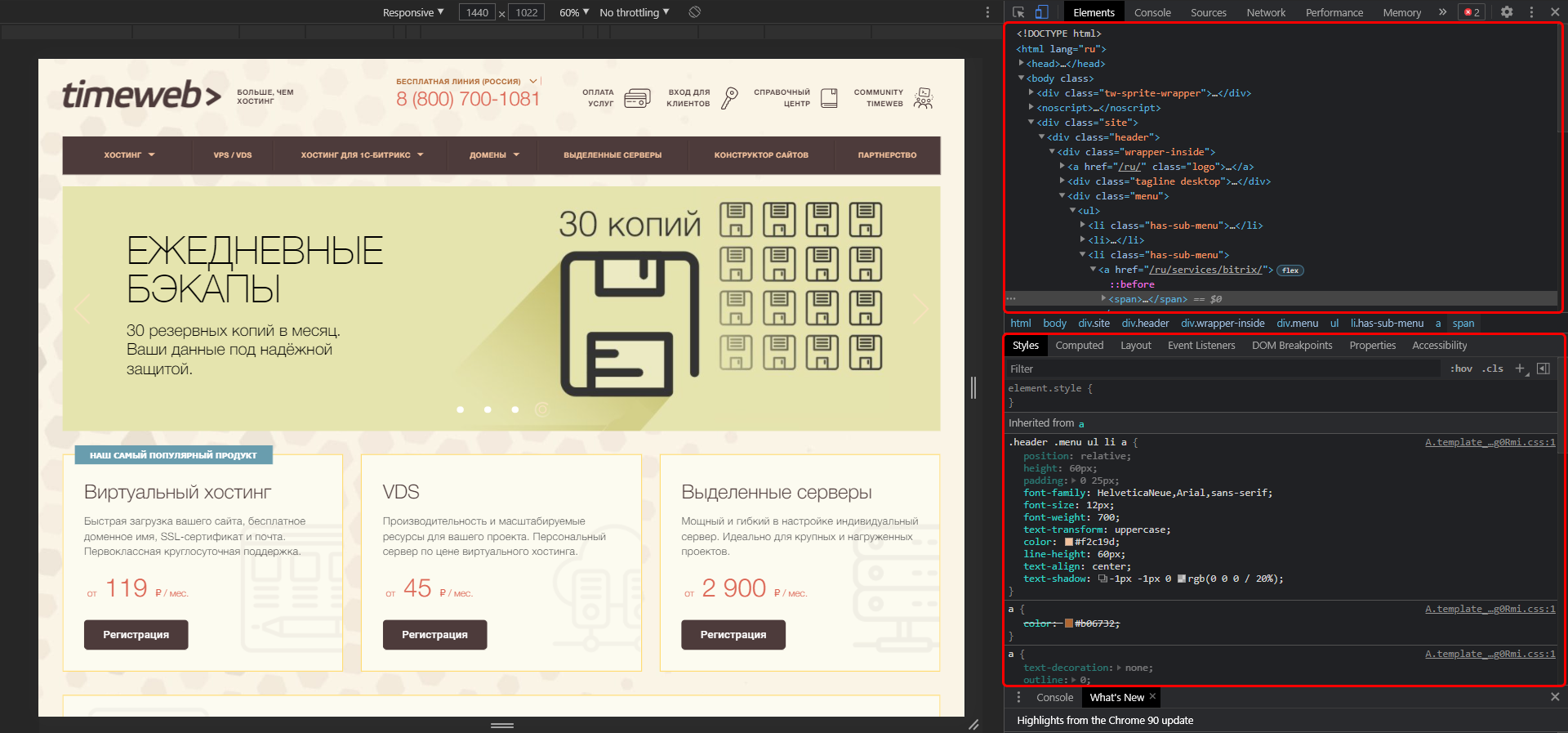
Обратите внимание на то, что запуск инструмента разработчика выполнялся в Google Chrome. В другом браузере название кнопки запуска может отличаться.
Способ 2: «Просмотр кода страницы»
Если в предыдущем случае мы могли открыть всю подноготную сайта, то сейчас нам будет доступен лишь HTML-код. Чтобы его посмотреть, находим на сайте пустое поле и кликаем по нему правой кнопкой мыши, затем выбираем «Просмотр кода страницы» (можно воспользоваться комбинацией клавиш «CTRL+U»). Если вы кликните правой кнопкой по элементу сайта, то кнопка «Просмотр кода страницы» будет отсутствовать.

После этого нас перенаправит на новую страницу со всем исходным кодом:
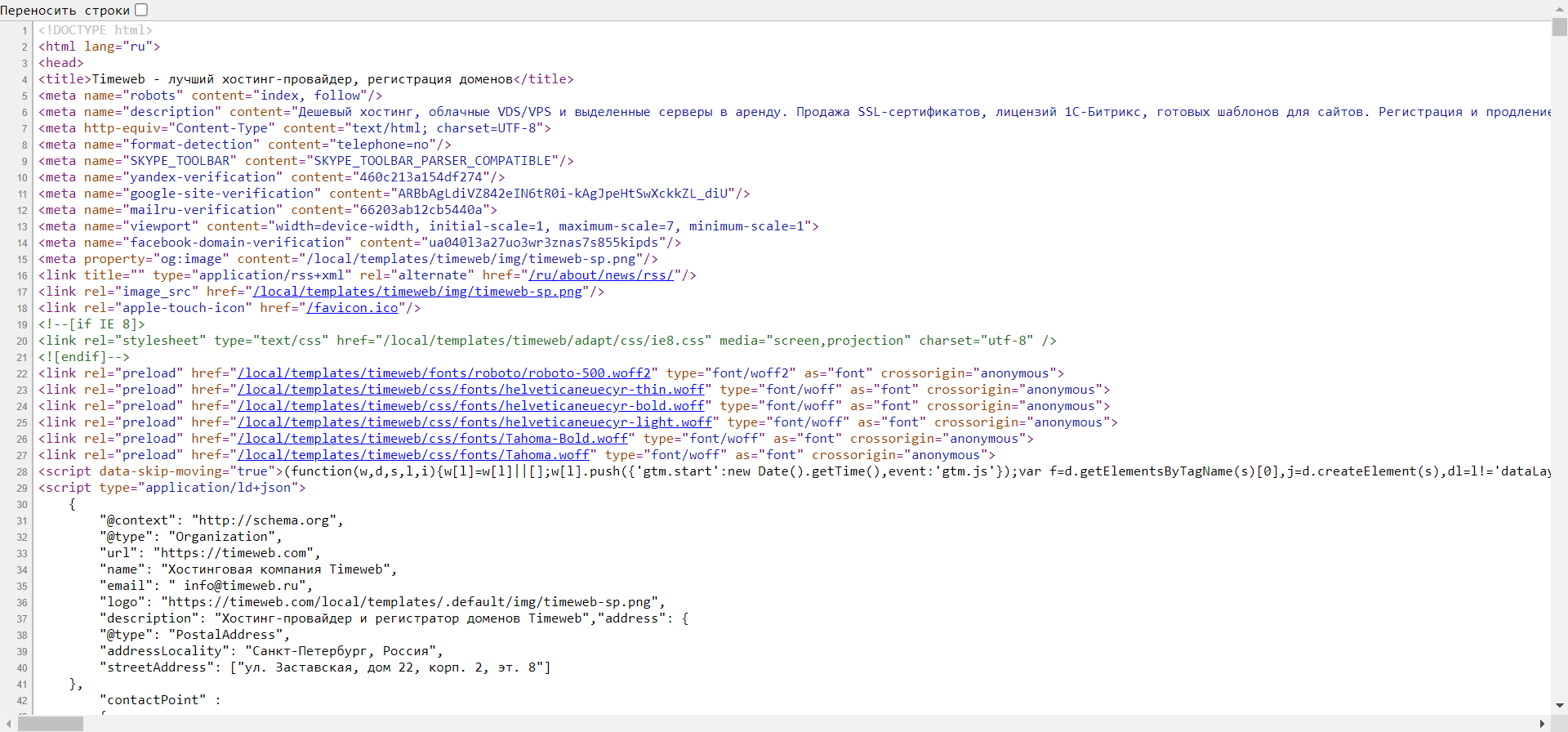
Здесь мы также можем посмотреть все содержимое страницы, однако узнать CSS и изменить данные у нас не получится.
Что такое HTML и CSS
Например, часто используется такая конструкция:
Это мой первый сайт!
Подобных тегов более сотни, для их изучения рекомендую обратиться к справочнику.
CSS – это помощник HTML, который позволяет преображать страницу как угодно: можно настраивать цвета элементов, изменять их положение, размер и форму, добавлять адаптивность и многое другое. Подключение CSS выполняется непосредственно в HTML-файле с помощью специального тега.
Рассмотрим на небольшом примере, как работают стили:
Каждый сайт, который вы встречаете, использует связку HTML и CSS. Стоит упомянуть, что еще есть язык программирования JavaScript, который позволяет оживлять страницу. Например, он может активировать формы обратной связи, создать сложную анимацию, установить всплывающие окна и многое другое. Обычным пользователям разбираться в нем не нужно от слова совсем. Если вы собираетесь вести аналитику сайта или просто интересуетесь его содержимым, то в знаниях JavaScript нет никакой необходимости.
Как я могу использовать код
Выше мы рассмотрели лишь основные моменты, связанные с кодом сайта – научились просматривать его и узнали, что такое HTML и CSS. Теперь давайте применим полученные знания на практике – посмотрим, как всем этим пользоваться.
Вариант 1: Редактирование контента
Как мы уже говорили ранее, можно поменять контент страницы внутри своего браузера. Изменения будем видеть лишь мы, но это дает нам возможность посмотреть альтернативный вариант размещения элементов.
Например, доступна возможность изменять содержимое текста – для этого достаточно выбрать нужный текст, кликнуть по нему правой кнопкой мыши и перейти в «Посмотреть код». После этого перед нами отобразится инспектор с выделенным текстом.
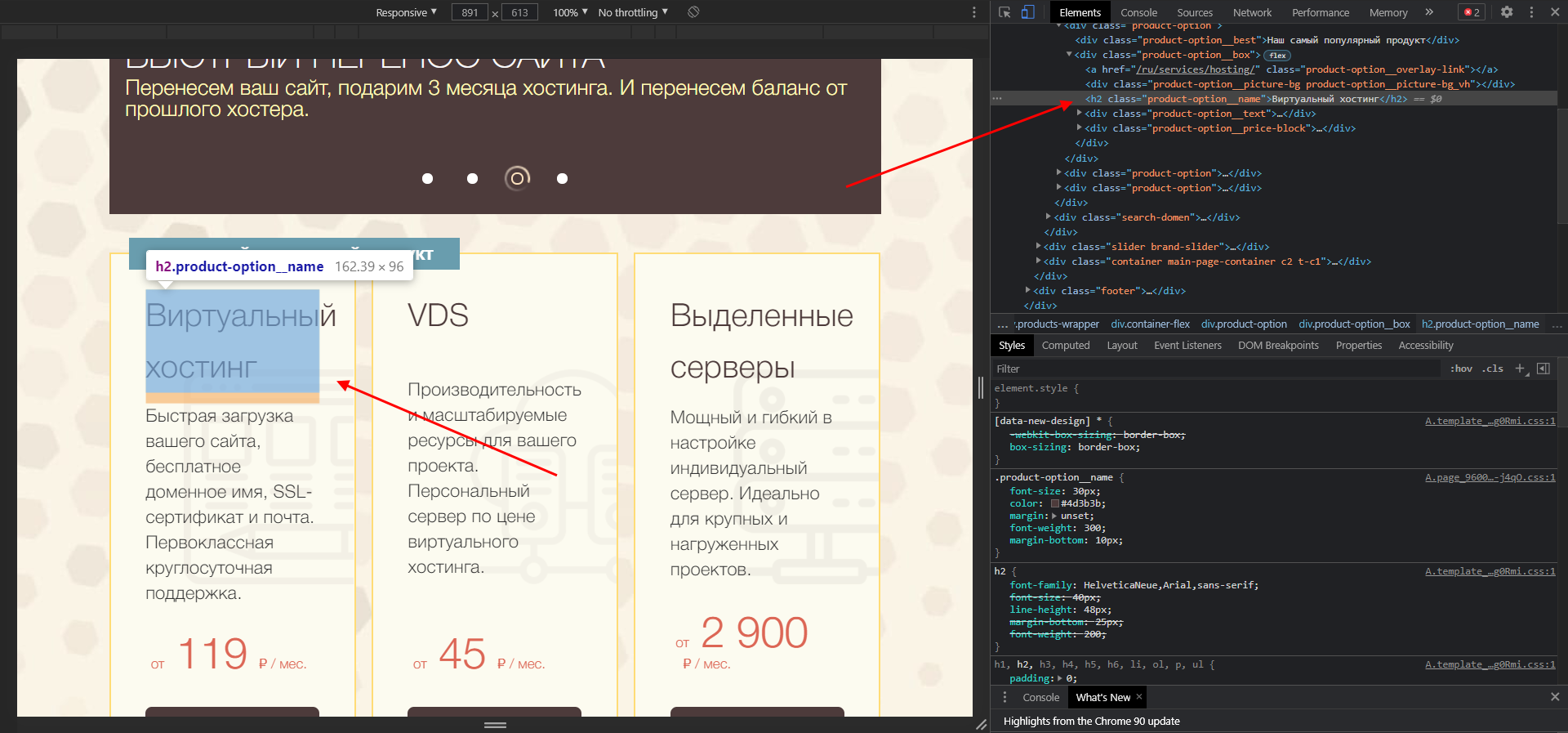
В среде разработчика мы можем заменить текст, расположенный в данном теге. Чтобы это сделать, находим его в коде, кликаем по нему двойным щелчком мыши и заменяем на другой. Ниже пример: мы поменяли «Виртуальный хостинг» на «Классное решение».
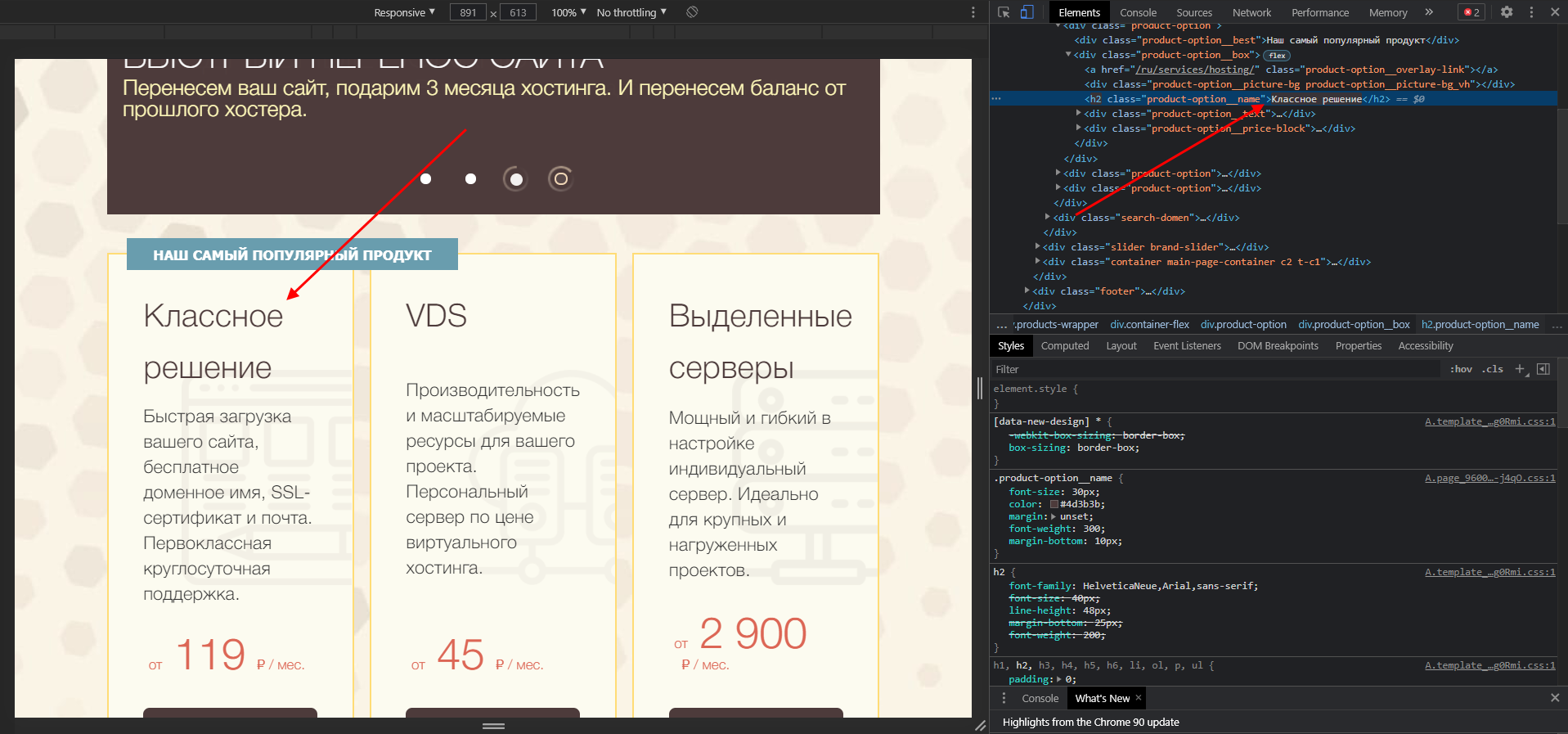
Чтобы отменить внесенные изменения, достаточно воспользоваться клавишей «F5» – страница будет обновлена, а весь контент станет исходным.
Аналогичным образом мы можем поменять CSS-стили через нижнее окно, но для этого потребуются некоторые знания. Подробную информацию рекомендую посмотреть в CSS-справочнике.
Вариант 2: Скачивание картинок
Сейчас мы можем напрямую загружать картинки с сайта, но по некоторым причинам это получается далеко не всегда. В таких случаях остается только один способ – выгрузить картинку через код. Сделать это довольно просто:
Аналогичным образом мы можем выгрузить и фоновое изображение, но его стоит искать через CSS-стили в атрибуте background.
Вариант 3: Просмотр SEO-элементов
С помощью кода можно посмотреть основные SEO-теги. Сделать это можно следующим образом:
Подобные элементы можно посмотреть и через инспектор кода.
Как посмотреть исходный код на телефоне
Функционал мобильных браузеров сильно ограничен – посмотреть код сайт через инспектор мы не можем. Доступен только вариант с отображением всего HTML-кода страницы. Чтобы им воспользоваться, необходимо перед ссылкой прописать «view-source:». Например, для https://timeweb.com/ru это будет выглядеть так:
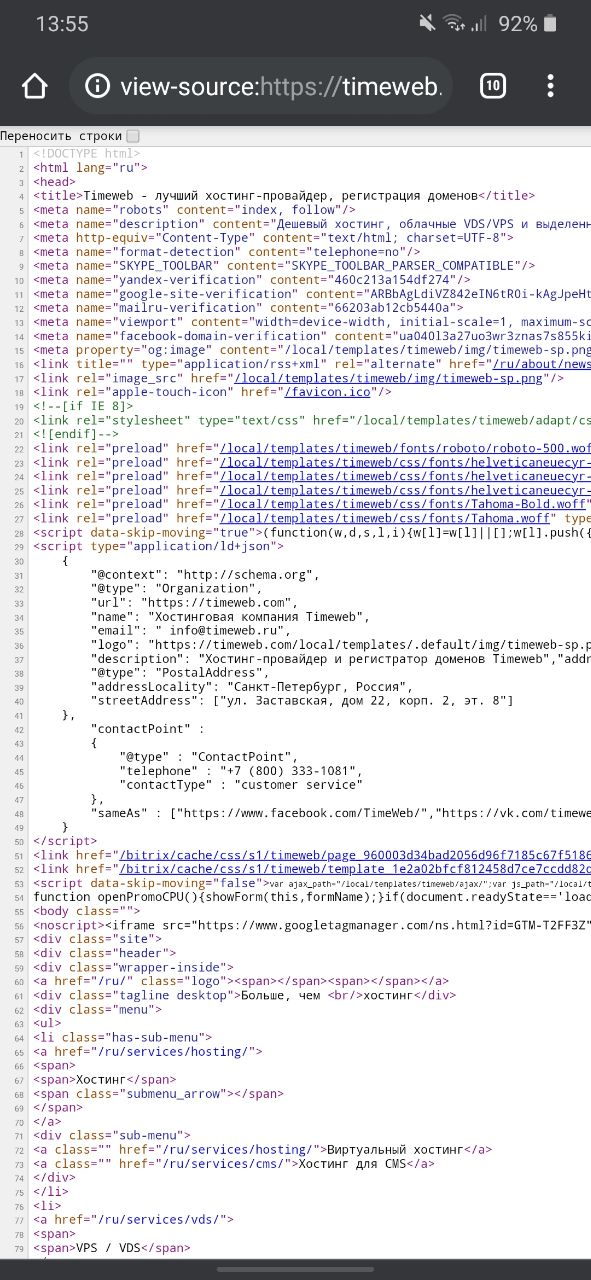
Если нужны расширенные возможности для устройства на Android, то можно поискать специальные приложения, например, VT View Source.
Заключение
Как работают веб-приложения
1. Чем веб-приложения отличаются от сайтов
Для меня сайт это в первую очередь что-то информационное и статичное: визитка компании, сайт рецептов, городской портал или вики. Набор подготовленных заранее HTML-файлов, которые лежат на удаленном сервере и отдаются браузеру по запросу.
Сайты содержат различную статику, которая как и HTML-файл не генерируется на лету. Чаще всего это картинки, CSS-файлы, JS-скрипты, но могут быть и любые другие файлы: mp3, mov, csv, pdf.
Блоги, визитки с формой для контакта, лендинги с кучей эффектов я тоже отношу для простоты к сайтам. Хотя в отличие от совсем статических сайтов, они уже включают в себя какую-то бизнес-логику.
А веб-приложение — это что-то технически более сложное. Тут HTML-страницы генерируются на лету в зависимости от запроса пользователя. Почтовые клиенты, соцсети, поисковики, интернет-магазины, онлайн-программы для бизнеса, это все веб-приложения.
2. Какие бывают веб-приложения
Веб-приложения можно разделить на несколько типов, в зависимости от разных сочетаний его основных составляющих:
3. Pyhon-фреймворк Django aka бэкенд

В разработке фреймворк — это набор готовых библиотек и инструментов, которые помогают создавать веб-приложения. Для примера опишу принцип работы фреймворка Django, написанного на языке программирования Python.
Первым этапом запрос от пользователя попадает в роутер (URL dispatcher), который решает какую функцию для обработки запроса надо вызвать. Решение принимается на основе списка правил, состоящих из регулярного выражения и названия функции: если такой-то урл, то вот такая функция.
Функция, которая вызывается роутером, называется вью (view). Внутри может содержаться любая бизнес-логика, но чаще всего это одно из двух: либо из базы берутся данные, подготавливаются и возвращаются на фронт; либо пришел запрос с данными из какой-то формы, эти данные проверяются и сохраняются в базу.
Данные приложения хранятся в базе данных (БД). Чаще всего используются реляционные БД. Это когда есть таблицы с заранее заданными колонками и эти таблицы связаны между собой через одну из колонок.
Данные в БД можно создавать, читать, изменять и удалять. Иногда для обозначения этих действий можно встретить аббревиатуру CRUD (Create Read Update Delete). Для запроса к данным в БД используется специальный язык SQL (structured query language).
В Джанго для работы с БД используются модели (model). Они позволяют описывать таблицы и делать запросы на привычном разработчику питоне, что гораздо удобнее. За это удобство приходится платить: такие запросы медленнее и ограничены в возможностях по сравнению с использованием чистого SQL.
Полученные из БД данные подготавливаются во вью к отправке на фронт. Они могут быть подставлены в шаблон (template) и отправлены в виде HTML-файла. Но в случае одностраничного приложения это происходит всего один раз, когда генерируется HTML-страница, на который подключаются все JS-скрипты. В остальных случаях данные сериализуются и отправляются в JSON-формате.
4. Javascript-фреймворки aka фронтенд
Клиентская часть приложения — это скрипты, написанные на языке программирования Javascript (JS) и исполняемые в браузере пользователя. Раньше вся клиентская логика основывалась на использовании библиотеки JQuery, которая позволяет работать с DOM, анимацией на странице и делать AJAX запросы.
DOM (document object model) — это структура HTML-страницы. Работа с DOM — это поиск, добавление, изменение, перемещеие и удаление HTML-тегов.
AJAX (asynchronous javascript and XML) — это общее название для технологий, которые позволяют делать асинхронные (без перезагрузки страницы) запросы к серверу и обмениваться данными. Так как клиентская и серверная части веб-приложения написаны на разных языках программирования, то для обмена информацией необходимо преобразовывать структуры данных (например, списки и словари), в которых она хранится, в JSON-формат.
JSON (JavaScript Object Notation) — это универсальный формат для обмена данными между клиентом и сервером. Он представляет собой простую строку, которая может быть использована в любом языке программирования.
Сериализация — это преобразование списка или словаря в JSON-строку. Для примера:
Десериализация — это обратное преобразование строки в список или словарь.
С помощью манипуляций с DOM можно полностью управлять содержимым страниц. С помощью AJAX можно обмениваться данными между клиентом и сервером. С этими технологиями уже можно создать SPA. Но при создании сложного приложения код фронтенда, основанного на JQuery, быстро становится запутанным и трудно поддерживаемым.
К счастью, на смену JQuery пришли Javascript-фреймворки: Backbone Marionette, Angular, React, Vue и другие. У них разная философия и синтаксис, но все они позволяют с гораздо большим удобством управлять данными на фронтенде, имеют шаблонизаторы и инструменты для создания навигации между страницами.
HTML-шаблон — это «умная» HTML-страница, в которой вместо конкретных значений используются переменные и доступны различные операторы: if, цикл for и другие. Процесс получения HTML-страницы из шаблона, когда подставляются переменные и применяются операторы, называется рендерингом шаблона.
Полученная в результате рендеринга страница показывается пользователю. Переход в другой раздел в SPA это применение другого шаблона. Если необходимо использовать в шаблоне другие данные, то они запрашиваются у сервера. Все отправки форм с данными это AJAX запросы на сервер.
5. Как клиент и сервер общаются между собой
Общение клиента с сервером происходит по протоколу HTTP. Основа этого протокола — это запрос от клиента к серверу и ответ сервера клиенту.
Для запросов обычно используют методы GET, если мы хотим получить данные, и POST, если мы хотим изменить данные. Еще в запросе указывается Host (домен сайта), тело запроса (если это POST-запрос) и много дополнительной технической информации.
Современные веб-приложения используют протокол HTTPS, расширенную версию HTTP с поддержкой шифрования SSL/TLS. Использование шифрованного канала передачи данных, независимо от важности этих данных, стало хорошим тоном в интернете.
Есть еще один запрос, который делается перед HTTP. Это DNS (domain name system) запроc. Он нужен для получения ip-адреса, к которому привязан запрашиваемый домен. Эта информация сохраняется в браузере и мы больше не тратим на это время.
Когда запрос от браузера доходит до сервера, он не сразу попадает в Джанго. Сначала его обрабатывает веб-сервер Nginx. Если запрашивается статический файл (например, картинка), то сам Nginx его отправляет в ответ клиенту. Если запрос не к статике, то Nginx должен проксировать (передать) его в Джанго.
К сожалению, он этого не умеет. Поэтому используется еще одна программа-прослойка — сервер приложений. Например для приложений на питоне, это могут быть uWSGI или Gunicorn. И вот уже они передают запрос в Джанго.
После того как Джанго обработал запрос, он возвращает ответ c HTML-страницей или данными, и код ответа. Если все хорошо, то код ответа — 200; если страница не найдена, то — 404; если произошла ошибка и сервер не смог обработать запрос, то — 500. Это самые часто встречающиеся коды.
6. Кэширование в веб-приложениях

Еще одна технология, с которой мы постоянно сталкиваемся, которая присутствует как веб-приложениях и программном обеспечении, так и на уровне процессора в наших компьютерах и смартфонах.
Cache — это концепция в разработке, когда часто используемые данные, вместо того чтобы их каждый раз доставать из БД, вычислять или подготавливать иным способом, сохраняются в быстро доступном месте. Несколько примеров использования кэша:
Делаем современное веб-приложение с нуля
Итак, вы решили сделать новый проект. И проект этот — веб-приложение. Сколько времени уйдёт на создание базового прототипа? Насколько это сложно? Что должен уже со старта уметь современный веб-сайт?
В этой статье мы попробуем набросать boilerplate простейшего веб-приложения со следующей архитектурой:
Введение
Перед разработкой, конечно, сперва нужно определиться, что мы разрабатываем! В качестве модельного приложения для этой статьи я решил сделать примитивный wiki-движок. У нас будут карточки, оформленные в Markdown; их можно будет смотреть и (когда-нибудь в будущем) предлагать правки. Всё это мы оформим в виде одностраничного приложения с server-side rendering (что совершенно необходимо для индексации наших будущих терабайт контента).
Давайте чуть подробнее пройдёмся по компонентам, которые нам для этого понадобятся:
Инфраструктура: git
Наверное, про это можно было и не говорить, но, конечно, мы будем вести разработку в git-репозитории.
Итоговый проект можно посмотреть на Github. Каждой секции статьи соответствует один коммит (я немало ребейзил, чтобы добиться этого!).
Инфраструктура: docker-compose
Начнём с настройки окружения. При том изобилии компонент, которое у нас имеется, весьма логичным решением для разработки будет использование docker-compose.
Добавим в репозиторий файл docker-compose.yml следующего содержания:
Давайте разберём вкратце, что тут происходит.
Не менее важный docker/backend/.dockerignore :
Воркер в целом аналогичен бэкенду, только вместо gunicorn у нас обычный запуск питонячьего модуля:
Наконец, фронтенд. Про него на Хабре есть целая отдельная статья, но, судя по развернутой дискуссии на StackOverflow и комментариям в духе «Ребят, уже 2018, нормального решения всё ещё нет?» там всё не так просто. Я остановился на таком варианте докерфайла.
Итак, наш каркас из контейнеров готов и можно наполнять его содержимым!
Бэкенд: каркас на Flask
Теперь наш бэкенд мы можем официально ПОДНЯТЬ!
Фронтенд: каркас на Express
В дальнейшем нам вообще не потребуется Node.js на машине разработчика (хотя мы могли и сейчас извернуться и запустить npm init через Docker, ну да ладно).
В Dockerfile мы упомянули npm run build и npm run start — нужно добавить в package.json соответствующие команды:
Команда build пока ничего не делает, но она нам ещё пригодится.
Добавим в зависимости Express и создадим в index.js простое приложение:
Теперь docker-compose up frontend поднимает наш фронтенд! Более того, на http://localhost:40002 уже должно красоваться классическое “Hello, world”.
Фронтенд: сборка с webpack и React-приложение
Пришло время изобразить в нашем приложении нечто больше, чем plain text. В этой секции мы добавим простейший React-компонент App и настроим сборку.
При программировании на React очень удобно использовать JSX — диалект JavaScript, расширенный синтаксическими конструкциями вида
Однако, JavaScript-движки не понимают его, поэтому обычно во фронтенд добавляется этап сборки. Специальные компиляторы JavaScript (ага-ага) превращают синтаксический сахар в уродливый классический JavaScript, обрабатывают импорты, минифицируют и так далее.
2014 год. apt-cache search java
Итак, простейший React-компонент выглядит очень просто.
Он просто выведет на экран наше приветствие более убедительным кеглем.
Добавим и клиентскую точку входа:
Для сборки всей этой красоты нам потребуются:
webpack — модный молодёжный сборщик для JS (хотя я уже три часа не читал статей по фронтенду, так что насчёт моды не уверен);
babel — компилятор для всевозможных примочек вроде JSX, а заодно поставщик полифиллов на все случаи IE.
Если предыдущая итерация фронтенда у вас всё ещё запущена, вам достаточно сделать
для установки новых зависимостей. Теперь настроим webpack:
Чтобы заработал babel, нужно сконфигурировать frontend/.babelrc :
Наконец, сделаем осмысленной нашу команду npm run build :
Бэкенд: данные в MongoDB
Прежде, чем двигаться дальше и вдыхать в наше приложение жизнь, надо сперва её вдохнуть в бэкенд. Кажется, мы собирались хранить размеченные в Markdown карточки — пора это сделать.
В то время, как существуют ORM для MongoDB на питоне, я считаю использование ORM практикой порочной и оставляю изучение соответствующих решений на ваше усмотрение. Вместо этого сделаем простенький класс для карточки и сопутствующий DAO:
(Если вы до сих пор не используете аннотации типов в Python, обязательно гляньте эти статьи!)
Теперь надо создать MongoCardDAO и дать Flask-приложению к нему доступ. Хотя сейчас у нас очень простая иерархия объектов (настройки → клиент pymongo → база данных pymongo → MongoCardDAO ), давайте сразу создадим централизованный царь-компонент, делающий dependency injection (он пригодится нам снова, когда мы будем делать воркер и tools).
Время добавить новый роут в Flask-приложение и наслаждаться видом!
Упс… ох, точно. Нам же нужно добавить контент! Заведём папку tools и сложим в неё скриптик, добавляющий одну тестовую карточку:
Успех! Теперь время поддержать это на фронтенде.
Фронтенд: Redux
Начнём с добавления Redux. Redux — JavaScript-библиотека для хранения состояния. Идея в том, чтобы вместо тысячи неявных состояний, изменяемых вашими компонентами при пользовательских действиях и других интересных событиях, иметь одно централизованное состояние, а любое изменение его производить через централизованный механизм действий. Так, если раньше для навигации мы сперва включали гифку загрузки, потом делали запрос через AJAX и, наконец, в success-коллбеке прописывали обновление нужных частей страницы, то в Redux-парадигме нам предлагается отправить действие “изменить контент на гифку с анимацией”, которое изменит глобальное состояние так, что одна из ваших компонент выкинет прежний контент и поставит анимацию, потом сделать запрос, а в его success-коллбеке отправить ещё одно действие, “изменить контент на подгруженный”. В общем, сейчас мы это сами увидим.
Начнём с установки новых зависимостей в наш контейнер.
Первое — собственно, Redux, второе — специальная библиотека для скрещивания React и Redux (written by mating experts), третье — очень нужная штука, необходимость который неплохо обоснована в её же README, и, наконец, четвёртое — библиотечка, необходимая для работы Redux DevTools Extension.
Начнём с бойлерплейтного Redux-кода: создания редьюсера, который ничего не делает, и инициализации состояния.
Наш клиент немного видоизменяется, морально готовясь к работе с Redux:
Фронтенд: страница карточки
Прежде, чем сделать страницы с SSR, надо сделать страницы без SSR! Давайте наконец воспользуемся нашим гениальным API для доступа к карточкам и сверстаем страницу карточки на фронтенде.
Время воспользоваться интеллектом и задизайнить структуру нашего состояния. Материалов на эту тему довольно много, так что предлагаю интеллектом не злоупотреблять и остановится на простом. Например, таком:
Заведём компонент «карточка», принимающий в качестве props содержимое cardData (оно же — фактически содержимое нашей карточки в mongo):
Теперь заведём компонент для всей страницы с карточкой. Он будет ответственен за то, чтобы достать нужные данные из API и передать их в Card. А фетчинг данных мы сделаем React-Redux way.
Для начала создадим файлик frontend/src/redux/actions.js и создадим действие, которые достаёт из API содержимое карточки, если ещё не:
Ох, у нас появилось действие, которое ЧТО-ТО ДЕЛАЕТ! Это надо поддержать в редьюсере:
(Обратите внимание на сверхмодный синтаксис для клонирования объекта с изменением отдельных полей.)
Теперь, когда вся логика унесена в Redux actions, сама компонента CardPage будет выглядеть сравнительно просто:
Добавим простенькую обработку page.type в наш корневой компонент App:
И теперь остался последний момент — надо как-то инициализировать page.type и page.cardSlug в зависимости от URL страницы.
Но в этой статье ещё много разделов, мы же не можем сделать качественное решение прямо сейчас. Давайте пока что сделаем это как-нибудь глупо. Вот прям совсем глупо. Например, регуляркой при инициализации приложения!
Так, секундочку… а где же наш контент? Ох, да мы ведь забыли распарсить Markdown!
Воркер: RQ
Парсинг Markdown и генерация HTML для карточки потенциально неограниченного размера — типичная «тяжёлая» задача, которую вместо того, чтобы решать прямо на бэкенде при сохранении изменений, обычно ставят в очередь и исполняют на отдельных машинах — воркерах.
Есть много опенсорсных реализаций очередей задач; мы возьмём Redis и простенькую библиотечку RQ (Redis Queue), которая передаёт параметры задач в формате pickle и сама организует нам спаунинг процессов для их обработки.
Время добавить редис в зависимости, настройки и вайринг!
Немного бойлерплейтного кода для воркера.
Для самого парсинга подключим библиотечку mistune и напишем простенькую функцию:
Мы объявили свой класс джобы, прокидывающий вайринг в качестве дополнительного kwargs-аргумента во все таски. (Обратите внимание, что он создаёт каждый раз НОВЫЙ вайринг, потому что некоторые клиенты нельзя создавать перед форком, который происходит внутри RQ перед началом обработки задачи.) Чтобы все наши таски не стали зависеть от вайринга — то есть от ВСЕХ наших объектов, — давайте сделаем декоратор, который будет доставать из вайринга только нужное:
Добавляем декоратор к нашей таске и радуемся жизни:
Радуемся жизни? Тьфу, я хотел сказать, запускаем воркер:
Ииии… он ничего не делает! Конечно, ведь мы не ставили ни одной таски!
Давайте перепишем нашу тулзу, которая создаёт тестовую карточку, чтобы она: а) не падала, если карточка уже создана (как в нашем случае); б) ставила таску на парсинг маркдауна.
Пересобрав контейнер с бэкендом, мы наконец можем увидеть контент нашей карточки в браузере:
Фронтенд: навигация
Прежде, чем мы перейдём к SSR, нам нужно сделать всю нашу возню с React хоть сколько-то осмысленной и сделать наше single page application действительно single page. Давайте обновим нашу тулзу, чтобы создавалось две (НЕ ОДНА, А ДВЕ! МАМА, Я ТЕПЕРЬ БИГ ДАТА ДЕВЕЛОПЕР!) карточки, ссылающиеся друг на друга, и потом займёмся навигацией между ними.
Теперь мы можем ходить по ссылкам и созерцать, как каждый раз наше чудесное приложение перезагружается. Хватит это терпеть!
Сперва навесим свой обработчик на клики по ссылкам. Поскольку HTML со ссылками у нас приходит с бэкенда, а приложение у нас на React, потребуется небольшой React-специфический фокус.
Добавляем глупенький редьюсер под это дело:
Внимательный читатель обратит внимание, что URL страницы не будет изменяться при навигации между карточками — даже на скриншоте мы видим Hello, world-карточку по адресу demo-карточки. Соответственно, навигация вперёд-назад тоже отвалилась. Давайте сразу добавим немного чёрной магии с history, чтобы починить это!
Теперь при переходах по ссылкам URL в адресной строке браузера будет реально меняться. Однако, кнопка «Назад» сломается!
А вот как — действие navigate:
Вот теперь история заработает.
Фронтенд: server-side rendering
Пришло время для нашей главной (на мой взгляд) фишечки — SEO-дружелюбия. Чтобы поисковики могли индексировать наш контент, полностью создаваемый динамически в React-компонентах, нам нужно уметь выдавать им результат рендеринга React, и ещё и научиться потом делать этот результат снова интерактивным.



