Как сделать документацию к коду?

Есть две крайности, которых лучше избегать:
1. красивая и исчерпывающая документация требует колоссальных ресурсов на поддержку
2. сложно воспринимаемый код, без малейших подсказок с чего все начинается и чем заканчивается
Кстати, проектная работа, это не только документация к коду, это еще и свод правил, которые позволят архитектуре не расползтись кто в лес кто по дрова, а также сохранят стилистику написания кода для единообразия и легкой поддерживаемости кода.

Думаю, вышеописанные пукнты не вяжутся с JS, хоть и прекрасно работают в других средах (php, java etc).
На JS вообще очень сложно писать «правильно» и «хорошо»))

Согласен, JSDOC, юнит тесты и автоматическая документация прекрасно работают в JS, но это, имхо, вообще не тот язык, который следует использовать в таких приложениях.

На счет 2007-го, а разве в JS уже появилась статическая типизация, интерфейсы, приватные свойства?))
Да и в сто раз проще написать hhvm совместимый код на PHP+фрейме ежели использовать его. Выйдет и быстрее, и проще, и лучше.
Пять стратегий документирования кода
В этом разделе мы рассмотрим подходы к фактическому документированию кода. Существует несколько подходов, которыми пользуются писатели и инженеры, мы познакомимся с пятью из них с примерами и комментариями.
После прочтения вступления к модулю “Документирование кода” одна из читательниц поделилась своим подходом. Вот, что она написала:
Кажется, такое разделение и расположение комментариев кода имеет место быть. Можно разделять пояснения на две основные категории:
После разделения, пояснения Как? встраиваются в код в виде комментариев (примерно на каждые 5-10 строк). Пояснения Почему? встраиваются во внешних разделах до или после кода. Разумеется, в пояснениях Как? можно получить подробную информацию о Почему? причинах, и наоборот, поэтому разделение этих двух вопросов на практике может быть не таким простым. Но такая общая закономерность, скорее всего, верна.
Кроме того, такой подход интересен тем, что он побуждает подумать над вопросом Почему?. Техническим писателям, документирующим код (который пишут другие), не всегда получается учитывать Почему?.Иногда бывает трудно понять, какие вопросы Почему? существуют. Зачем использовать этот класс вместо другого? Почему так, а не так? Часто существует много разных способов достижения цели, так почему же идти по этому пути, а не каким-то другим?
В общении с разработчиками о примерах кода, стоит задавать это вопрос: Почему?
Подход 2: сопоставление комментариев в третьей колонке
Лучшие практики для документации в целом (не только для документирования кода) включают размещение полезных инструкций рядом с областью, вызывающей затруднения, что в контексте документирования кода может означать добавление встроенных комментариев, пронизывающих весь код. Но предположим, что нужен большой комментарий о том, что происходит в коде (поскольку уровень сложности не может быть передан в коротком комментарии). Как сопоставить длинную концептуальную / пояснительную информацию с кодом?
Если ваш комментарий больше кода, есть риск сделать код нечитаемым. Если разместить комментарий в разделах, которые идут задолго до или после кода, есть риск создать пропасть между объяснением и кодом, так что читатели не будут знать, к каким частям кода относится объяснение.
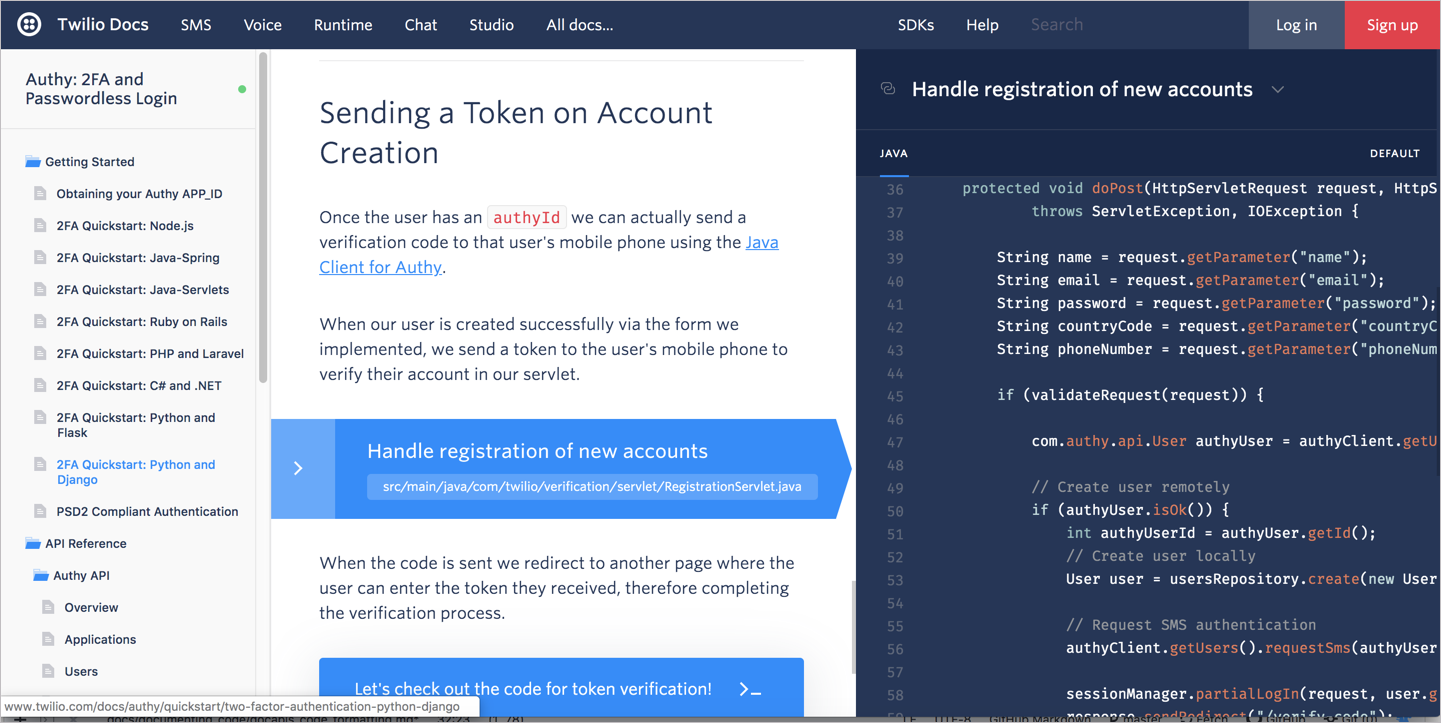 Документация Twilio, с третьей колонкой для кода
Документация Twilio, с третьей колонкой для кода
В этом примере концептуальное содержание и шаги появляются в средней колонке, код справа, на темном фоне для создания визуального контраста.
Некоторые экраны Twilio фактически “размывают” нерелевантный код, позволяя сосредоточить свое внимание на линиях, сформулированных в концептуальной области, например:
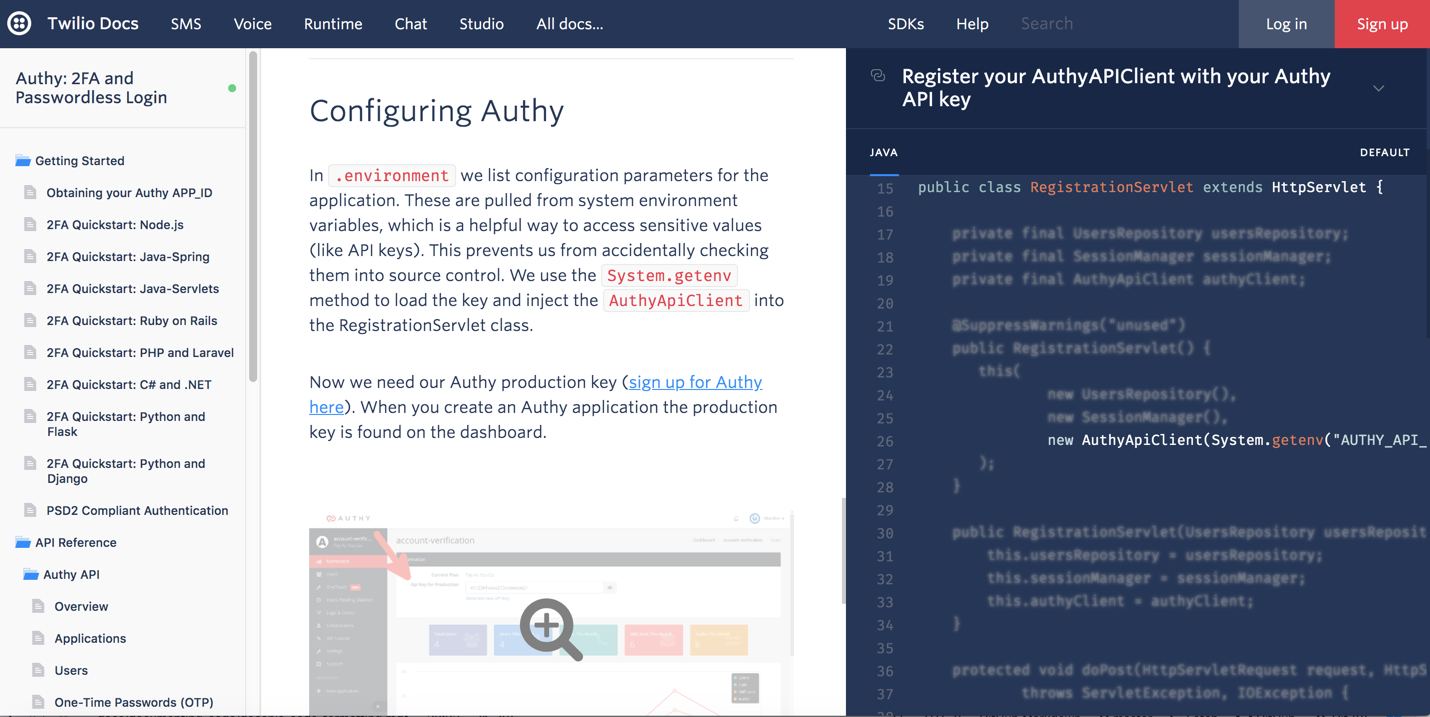 Размытие нерелевантного кода
Размытие нерелевантного кода
Одной из проблем такого подхода является пространство экрана. Чтобы добавить третью колонку, нужно занять весь экран без полей. (Странно, что в Twilio нет возможности свернуть левую панель навигации, освободив тем самым больше места для кода.)
Таким образом, код виден только частично. Код можно растянуть по горизонтали с возможностью прокрутки вправо, но, несомненно, дизайнерам тяжело дался пользовательский интерфейс, который включает в себя горизонтальную и вертикальную прокрутку.
Вдобавок, реализация размытия фокуса области экрана с кодом, на описании которого находится пользователь, должна быть технически сложной и громоздкой.
Другая проблема заключается в том, что код и пояснения к нему редко можно выровнять линейно. Предположим, есть метод в коде, который занимает всего одну строку, но описание этого метода занимает три длинных параграфа концептуального объяснения. К тому времени, когда пользователь достигает нижней части концептуального объяснения, код уже не виден. Пользователю приходится сделать много лишних манипуляций, чтобы найти соответствующий код. Дизайн пользовательского интерфейса для размещения всех этих движущихся частей не только кажется сложным, но и увеличивает нагрузку на пользователя.
Еще одна проблема, связанная с таким дизайном, заключается в том, что код часто относится к нескольким файлам. Отображение в колонке не указывает, отображается ли весь код в одном и том же файле Java или мы видим код из нескольких файлов Java. Представление вкладок в столбце кода требует еще более сложного формата документации. Сложно представить, что все это возможно сделать с помощью синтаксиса Markdown.
Подход 3: подход Лего
Другой подход заключается в создании кода с нуля, уровня за уровнем, который можно назвать “подходом Лего”. В качестве примера подхода Лего можно посмотреть на пример в eBay Shopping API Поиск по продавцу: Просмотр информации о продавце.
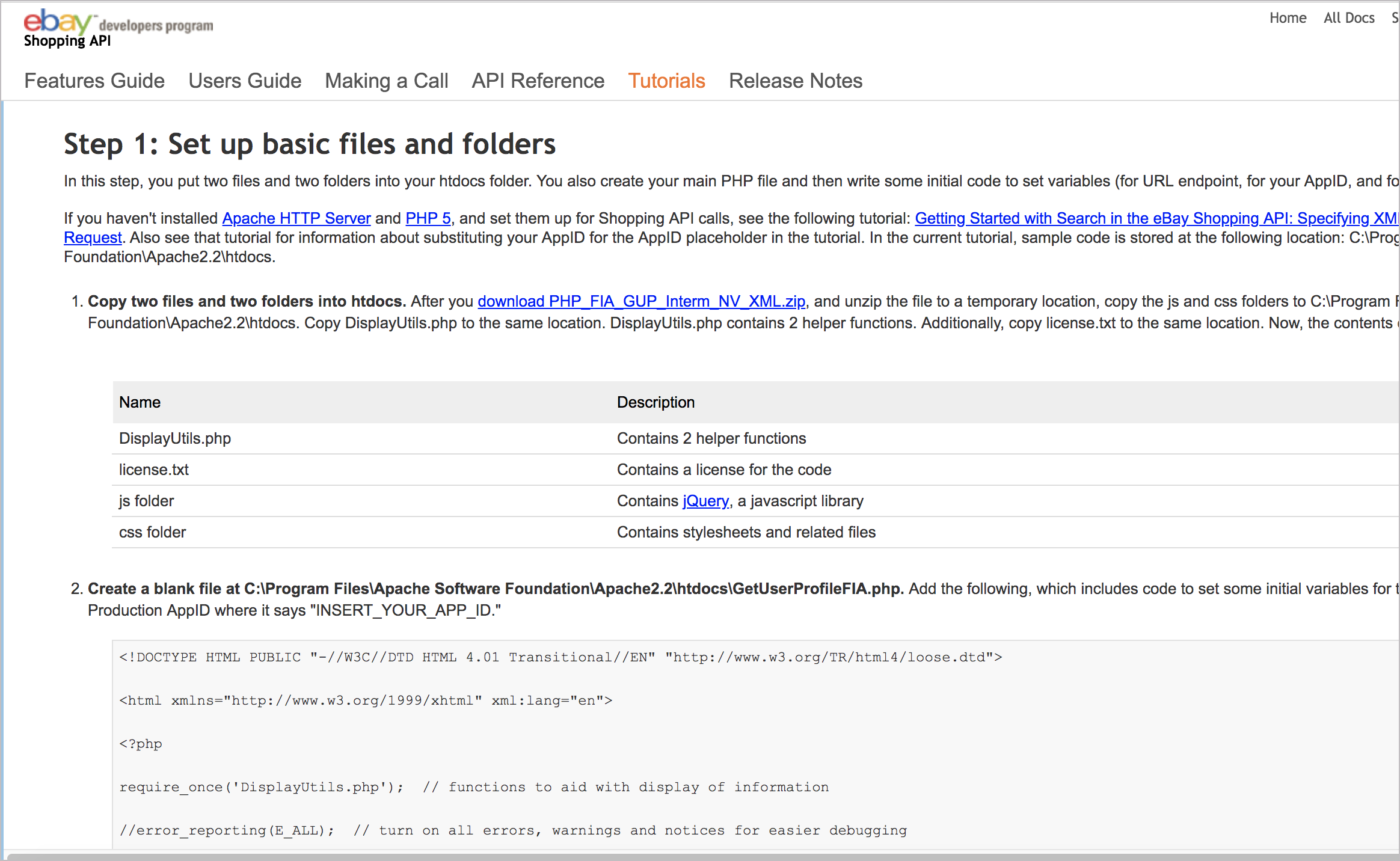 Подход Лего показан в API eBay Shopping
Подход Лего показан в API eBay Shopping
У них в руководстве всего 5 шагов:
Проблема с подходом Лего заключается в том, что технический писатель вряд ли воссоздаст логику построения, которой следовал разработчик. Скорее всего, разработчики просто отправят готовый кусок кода в документ, и тогда придется получать пояснения от разработчика о коде, как описано в разделе Почему так трудно документировать код?, где описаны основные проблемы.
Несмотря на проблемы с подходом Лего, если нужно научить кого-то, как понимать код, нужно начать с простого и идти шаг за шагом от простого к сложному. Следующая техника объясняет такой подход от простого к сложному при помощи метафоры наутилуса.
Подход 4: подход Наутилус
Подход Наутилус аналогичен подходу Лего, но вместо того, чтобы описывать куски работы, которые выполняются один за другим в порядке сборки, здесь описываются основные простые шаблоны, которые должны знать пользователи. Начинается с самого простого кода, а затем проект увеличиваться и увеличиваться по мере необходимости, как растущая спиральная структура оболочки наутилуса.
Пол Густафсон, управляющий компанией, занимающейся техническим обслуживанием письма, в Bay Area, которая называется Экспертная поддержка, представляет подход с метафорой Наутилуса, описанный здесь. Пол говорит, что наутилус является хорошей метафорой для технической коммуникации, потому что наутилус представляет спиральную схему (последовательность Фибоначчи), которая начинает с малого и постепенно растет по мере необходимости:
Следуя подходу Наутилус, мы начинаем с простых базовых шаблонов, а затем постепенно наращиваем объем кода вокруг него по мере необходимости. Мы не начинаем с описания сложной законченной работы с самого начала. Законченная работа, вероятно, включает в себя все виды абстракций кода и перестановки для чистого, готового продукта.
Проблема в том, что мы часто хотим объяснить, как работает готовый код, проводя пользователя через все от начала до конца. У нас может быть 500 строк кода, которые мы хотим сформулировать, но подход Nautilus заставил бы нас объяснить только несколько небольших фрагментов этого кода (по крайней мере, для начала). Следовательно, существует проблема типа A-против-Z: мы описываем A (самый простой шаблон ядра), но конечным продуктом является Z. Как именно мы добираемся от A до Z? Как мы придем от простых шаблонов, которые могут занимать 20 строк кода, до чудовищно сложного, законченного кода, который занимает 500 строк?
Для технического писателя, смотрящего на окончательный код, нет ясного понимания того, как разработчик попал туда. Мы часто не можем отделить подобную логику, с которой начинал разработчик, что привело его к этой более сложной цели. Все, что мы видим, это этот сложный конец. Как декомпилировать код, чтобы восстановить логику, с которой разработчик начал? Как понять, что это были за начальные паттерны, которые положили начало всему процессу? Если вы не разрабатывали код и не являетесь разработчиком, то будет практически невозможно восстановить шаблон Наутилуса, стоящий за кодом.
 Как задокументировать процесс создания картины?
Как задокументировать процесс создания картины?
Чтобы задокументировать процесс создания такой картины, что лучше: начать с верха и идти к низу? Нет, это было бы смешно. Скорее всего, лучше начинать с создания овала головы. Потом, несколько общих набросков для глаз и так далее. Может быть, набросать линии перспективы и другую основную структуру. Никто сразу не приступает к цветам, освещению и теням, верно? То же самое с кодом. Начинаем с основы, а затем прокладываем путь к большему количеству завершающих деталей.
Чтобы проиллюстрировать этот момент более четко, приведем пример кода. Автор курса не инженер, но ему удобно работать с Jekyll и темами, он создал шаблон, который будет принимать экспорт контента из инструмента для создания тикетов (например, JIRA) и отображать его в виде отчета документации на веб-странице.
Финальный шаблон выглядит так:
Этот код выглядит как бред, правда. Здесь есть несколько инклюдов, в которых абстрагирована логика, потому что они будут повторяться ее из отчета в отчет. Здесь убраны скрипты и стили, так как они загромождают код, поэтому они хранятся во включаемых файлах.
Представьте, что вы пытаетесь задокументировать этот код. Если бы вы начали сверху и дошли до конца, это было бы настоящим беспорядком. Пользователю также будет трудно читать длинное объяснение. Такой запутанный клубок. И он не распутается, если поспешно собрать все, не задумываясь о чистом, элегантном решении. Нужно было быстро выпустить отчет, поэтому шаблон был взломан как можно быстрее. Разработчики, создающие приложения, часто внедряют подобные хаки и другие костыли, используя скотч и WD-40, как говорит Джоэл Спольски, чтобы получить рабочее решение, поставленное в срок.
Даже этот кусок сбивает с толку, поскольку есть странные вещи с переменными, вставленными в скобки в ссылках на файл YAML.
Чтобы по-настоящему объединить код с основной логикой, разработчики должны начать с этого:
Чтобы собрать эту информацию, нужно взять интервью у разработчика. И при общении с разработчиком, нужно понимать его язык и объяснения. В качестве альтернативы можно попросить разработчика описать логику собственного кода с помощью руководства с правильными вопросами. Например, можно спросить:
Подход 5: Интерактивный браузер
Изучение основных шаблонов смещает документацию в область руководства. С этим типом обучения связан интерактивный браузер, в котором действие сочетается с обучением. Интерфейсы, выполняемые браузером, имеют своей целью помочь пользователям лучше понять результаты входных и выходных данных, чтобы пользователи могли сами убедиться в том, как работает код, используя более практичный для себя подход.
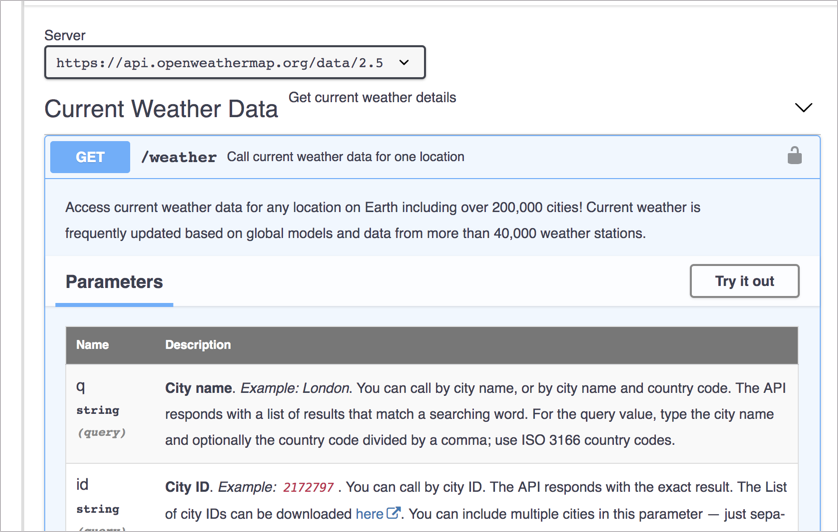 Кнопка Try it out в интерфейсе Swagger
Кнопка Try it out в интерфейсе Swagger
Swagger предлагает оригинальное сочетание документации с активным взаимодействием, которые помогают пользователям изучать API (читая и выполняя). Но выполнение запросов с помощью конечных точек API REST обычно довольно простое. Более интенсивные руководства по коду будет сложнее сделать интерактивными в браузере. Тем не менее, некоторые «Notebooks» (как их часто называют) позволяют запускать код, в частности Jupyter Notebooks. Описание Jupyter:
У Google есть несколько вариантов блокнота для совместной работы с документацией TensorFlow, в которой есть операции, которые можно выполнять на веб-страницах. На следующем скриншоте можно увидеть опцию Run code now :
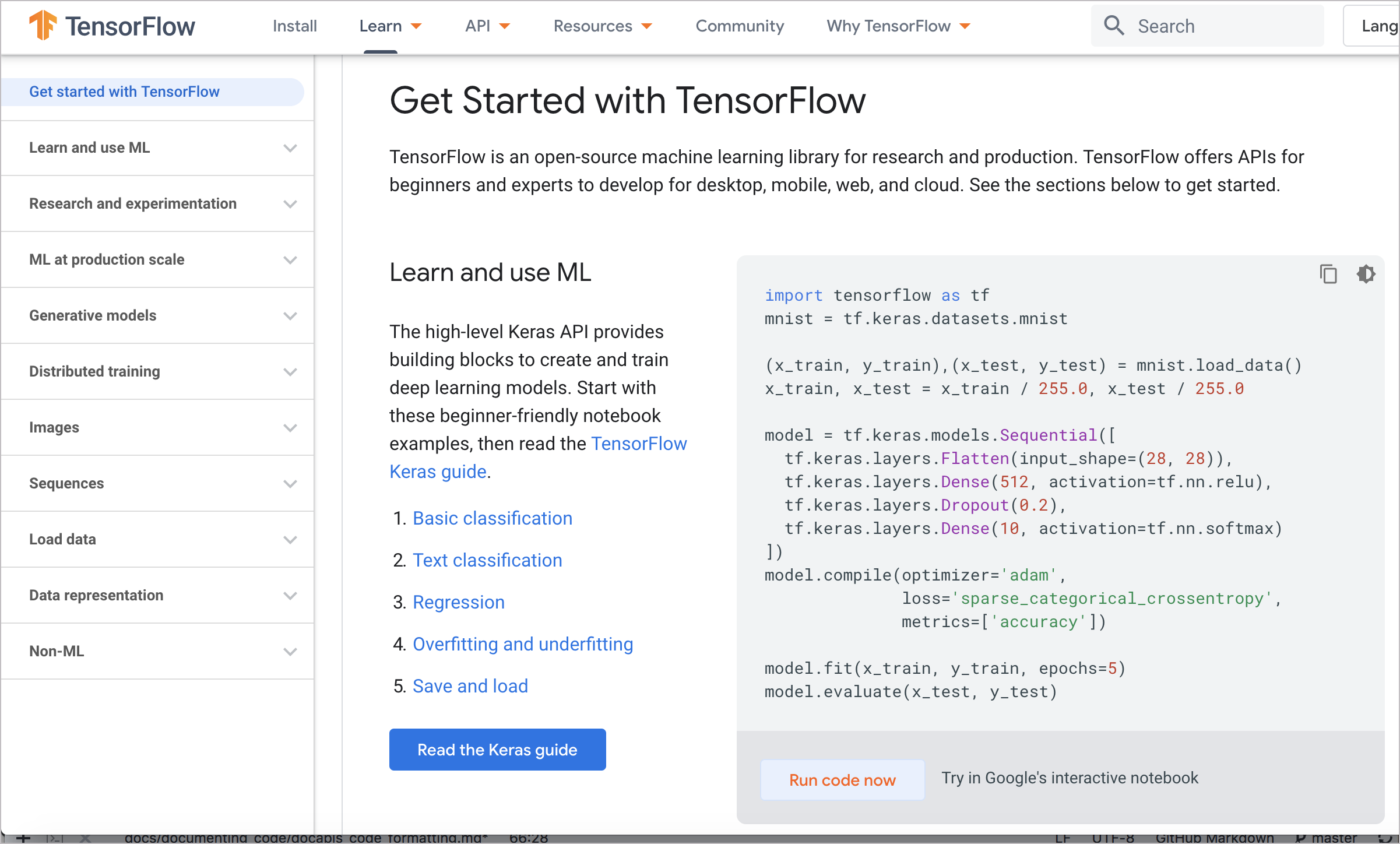 Интерактивный пример кода от TensorFlow
Интерактивный пример кода от TensorFlow
Клик на Run code now открывает интерактивную записную книжку Google, которая фактически запускает код в браузере:
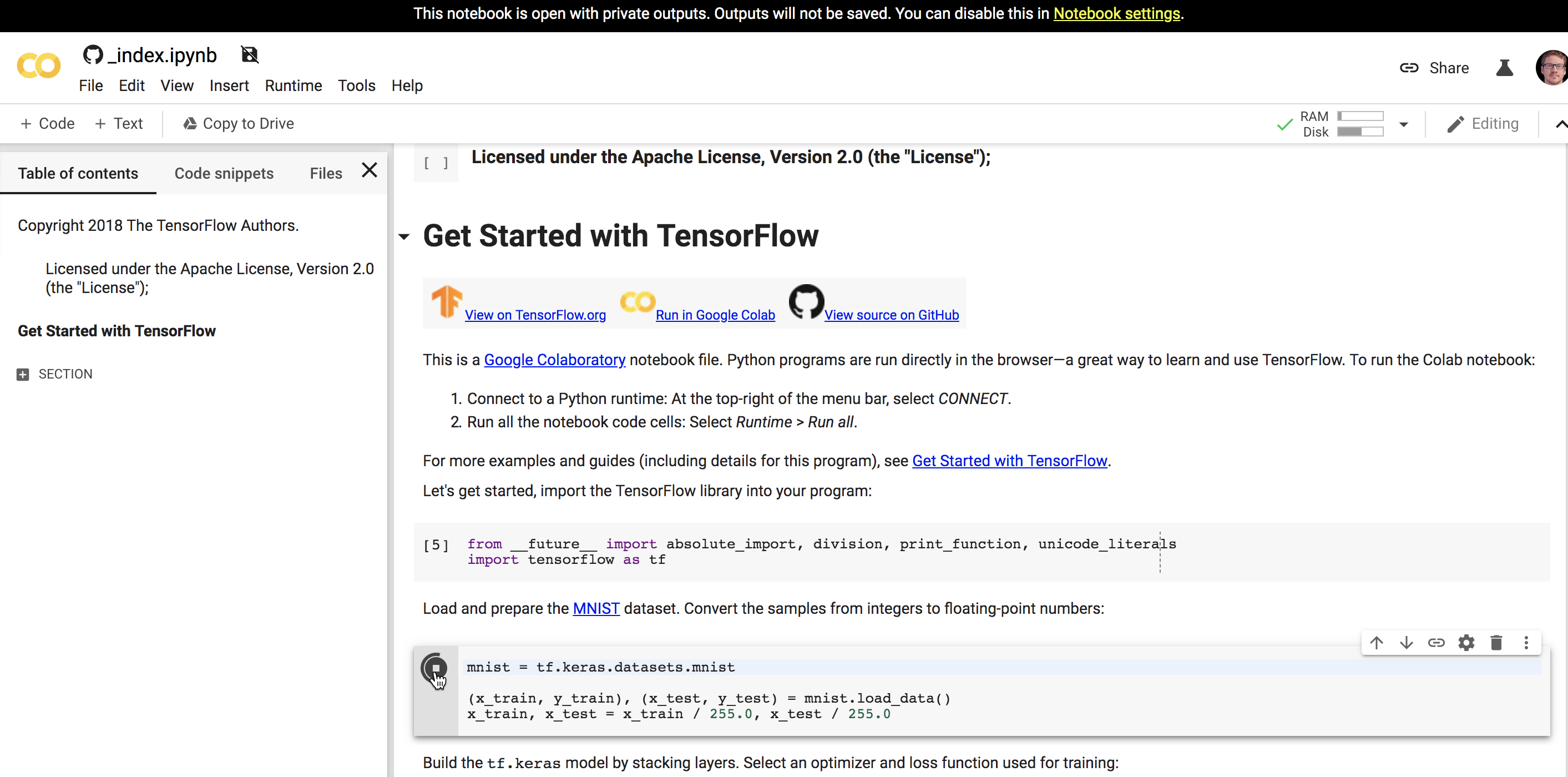 Интерактивный блокнот Google позволяет запускать код в браузере
Интерактивный блокнот Google позволяет запускать код в браузере
Хотя интерактивные записные книжки выглядят круто, они кажутся огромной работой для чего-то, что может быть легко достигнуто с помощью образца приложения. Вместо того, чтобы выяснить, как вы можете скомпилировать код Python или другой язык в браузере, почему бы просто не предоставить пример приложения, которое пользователи могут загрузить, а затем выполнить локально, используя свои собственные инструменты компиляции и настройки?
Заключение
В этом разделе мы рассмотрели 5 подходов документирования кода:
Лучше использовать подход, который помогает пользователям получить нужные знания для создания собственного кода.
👨💻 Практическое занятие: сравниваем документацию кода с одним из подходов
Ищем раздел с руководством по коду на одном из сайтов документации API, которые изучали. Или посмотрите на один из сайтов документации API в этом посте от Nordic APIs: 5 Примерjd отличной документации API (и почему мы так думаем). В этом посте перечислены пять примеров документации API: Stripe, Twilio, Dropbox, GitHub и Twitter.
И попробуем выяснить, какому подходу лучше всего соответствует документация кода.
Документируем код эффективно при помощи Doxygen

Данная статья входит в получившийся цикл статей о системе документирования Doxygen:
В этой статье мы сначала познакомимся с самой системой и её возможностями, затем разберёмся с её установкой и базовыми принципами работы, и, наконец, завершим знакомство рассмотрением различных примеров документации, примеров того, как следует документировать те или иные части кода. Словом, познакомимся со всем тем, что позволит вам освоиться и начать работать с этой замечательной системой.
Введение
Вероятнее всего, каждый из нас сталкивался с результатами работы различных генераторов документации. Общий принцип их работы следующий: на вход такого генератора поступает специальным образом комментированный исходный код, а иногда и другие компоненты программы, а на выходе создаётся готовая документация для распространения и использования.
Рассматриваемая система Doxygen как раз и выполняет эту задачу: она позволяет генерировать на основе исходного кода, содержащего комментарии специального вида, красивую и удобную документацию, содержащую в себе ссылки, диаграммы классов, вызовов и т.п. в различных форматах: HTML, LaTeX, CHM, RTF, PostScript, PDF, man-страницы.
Впрочем, следуя сложившейся традиции, в примерах я буду использовать C++, однако это не должно смущать вас, если вы предпочитаете другой поддерживаемый язык, поскольку особой разницы на практике вы даже не заметите, и большинство сказанного далее будет справедливо и для вашего языка.
К слову, список проектов, использующих Doxygen имеется на официальном сайте, причём большинство из этих проектов свободные. Поэтому желающие могут скачать исходник того или иного проекта и посмотреть как там разработчики осуществляли документацию.
Установка и настройка
Скачать последнюю версию Doxygen можно на официальном сайте, дистрибутивы которой доступны для большинства популярных операционных систем, кроме того, вы можете воспользоваться вашим пакетным менеджером. Помимо этого для комфортной и полнофункциональной работы рекомендуется установить Graphviz.
Далее работа с Doxygen весьма тривиальна: достаточно запустить программу, указав ей путь к файлу с настройками.
Но в этом файле и вся тонкость. Дело в том, что каждому проекту соответствует свой файл настроек, в котором может быть прописан путь до исходников проекта, путь, по которому должна быть создана документация, а также большое число других разнообразных опций, которые подробно описаны в документации, и которые позволяют максимально настроить документацию проекта под свои нужды.
В принципе, для редактирования данного файла и, вообще, работой с Doxygen, можно воспользоваться программой Doxywizard, которая чаще всего идёт вместе с Doxygen и которая позволяет чуть удобнее работать с файлом настроек (слева – Doxywizard; справа – файл открытый в текстовом редакторе):
Итак, приступим к созданию файла с настройками. Вообще, если вы используете Doxywizard, то он будет создан автоматически, в противном случае для создания этого файла необходимо запустить программу Doxygen с ключом -g (от generate):
Рассмотрим основные опции, которые могут вам пригодится, чтобы создать первую вашу документацию:
| Тэг | Назначение | По умолчанию |
| DOXYFILE_ENCODING | Кодировка, которая используется для всех символов в данном файле настроек | UTF-8 |
| OUTPUT_LANGUAGE | Устанавливает язык, на котором будет сгенерирована документация | English |
| PROJECT_NAME | Название проекта, которое может представлять собой единое слово или последовательность слов (если вы редактируете вне Doxywizard, последовательность слов необходимо поместить в двойные кавычки) | My Project |
| PROJECT_NUMBER | Данный тэг может быть использован для указания номера проекта или его версии | — |
| PROJECT_BRIEF | Краткое однострочное описание проекта, которое размещается сверху каждой страницы и даёт общее представление о назначении проекта | — |
| OUTPUT_DIRECTORY | Абсолютный или относительный путь, по которому будет сгенерирована документация | Текущая директория |
| INPUT | Список файлов и/или директорий, разделенных пробелом, которые содержат в себе исходные коды проекта | Текущая директория |
| RECURSIVE | Используется в том случае, если необходимо сканировать исходные коды в подпапках указанных директорий | NO |
После того, как мы внесли необходимые изменения в файл с настройками (например, изменили язык, названия проекта и т.п.) необходимо сгенерировать документацию.
Для её генерации можно воспользоваться Doxywizard (для этого необходимо указать рабочую директорию, из которой будут браться исходные коды, перейти на вкладку «Run» и нажать «Run doxygen») или запустив программу Doxygen, указав ей в качестве параметра путь к файлу с настройками:
Основы документирования на Doxygen
Теперь, когда мы разобрались с тем, как настраивать Doxygen и работать с ним, впору разобраться с тем, как необходимо документировать код, основными принципами и подходами.
Сразу отметим, что, вообще, всего существует два основных типа документирующих блоков: многострочный блок и однострочный блок.
Разница между ними чуть более сильная, чем между однострочным и многострочным комментарием. Дело в том, что текст, написанный в однострочном блоке относится к краткому описанию документируемого элемента (сродни заголовку), а текст, написанный в многострочном блоке относится к подробному описанию. Про эту разницу не следует забывать.
Многострочный блок
Мы сказали, что любой блок – это комментарий, оформленный специальным образом. Поэтому необходимо определить каким таким «специальным образом». Вообще, существует целый ряд способов для описания многострочного блока, и выбор конкретного способа зависит от ваших предпочтений:
При этом звездочки не обязательно ставить на каждой строке. Такая запись будет эквивалентной:
Сказанное о необязательности промежуточных звездочек также остаётся справедливым. Помимо названных двух стилей есть ещё ряд, но на них пока мы не будем останавливаться.
При этом ещё раз обратите внимание на то, что текст написанный в таком комментарии относится к подробному описанию.
Для указания краткого описания может быть использована команда \brief. Указанный после команды текст, вплоть до конца параграфа будет относится к краткому описания, и для отделения подробного описания и краткого описания используется пустая строка.
Однострочный блок
Для описания однострочного блока опять же существует целый ряд способов оформления, рассмотрим два из них:
При этом хотелось бы обратить внимание на два момента:
Например следующие два способа документирования дадут один и тот же результат:
Да, Doxygen крайне гибок в плане способов документирования, однако не стоит этим злоупотреблять, и в рамках одного проекта всегда придерживайтесь заранее оговоренного единообразного стиля
Размещение документирующего блока после элемента
Во всех предыдущих примерах подразумевалось, что документирующий блок предварял документируемый элемент, но иногда бывают ситуации, когда удобнее разместить его после документируемого элемента. Для этого необходимо в блок добавить маркер «
Кроме того, обратите внимание на то, что вы можете создавать и собственные команды. Подробно об этом можно прочитать в соответствующем разделе документации.
Документирование основных элементов исходного кода
Теперь мы можем рассмотреть специфичные особенности документирования различных элементов исходного кода, начиная от файлов в целом и заканчивая классами, структурами, функциями и методами.
Документирование файла
Хорошей практикой является добавление в начало файла документирующего блока, описывающегося его назначение. Для того, чтобы указать, что данный блок относится к файлу необходимо воспользоваться командой \file (причём в качестве параметра можно указать путь к файлу, к которому относится данный блок, но по умолчанию выбирается тот файл, в который блок добавляется, что, как правило, соответствует нашим нуждам).
Документирование функций и методов
При документировании функций и методов чаще всего необходимо указать входные параметры, возвращаемое функцией значение, а также возможные исключения. Рассмотрим последовательно соответствующие команды.
Параметры
Для указания параметров необходимо использовать команду \param для каждого из параметров функции, при этом синтаксис команды имеет следующий вид:
В результате мы получим такую вот аккуратную документацию функции:
Возвращаемое значение
Для описание возвращаемого значения используется команда \return (или её аналог \returns). Её синтаксис имеет следующий вид:
Рассмотрим пример с описанием возвращаемого значения (при этом обратите внимание на то, что параметры описываются при помощи одной команды и в результате они в описании размещаются вместе):
Получаем следующий результат:
Исключения
Для указания исключения используется команда \throw (или её синонимы: \throws, \exception), которая имеет следующий формат:
Простейший пример приведён ниже:
Документирование классов
Классы также могут быть задокументированы просто предварением их документирующим блоком. При этом огромное количество информации Doxygen получает автоматически, учитывая синтаксис языка, поэтому задача документирования классов значительно упрощается. Так при документировании Doxygen автоматические определяет методы и члены класса, уровни доступа к функциям, дружественные функции и т.п.
Если ваш язык не поддерживает явным образом определенные концепции, такие как например уровни доступа или создание методов, но их наличие подразумевается и его хотелось бы как-то выделить в документации, то существует ряд команд (например, \public, \private, \protected, \memberof), которые позволяют указать явно о них Doxygen.
Документирование перечислений
Документирование перечислений не сильно отличается от документирования других элементов. Рассмотрим пример, в котором иллюстрируется то, как можно удобно документировать их:
То есть описание состояний указывается, собственно, после них самих при помощи краткого или подробного описания (в данном случае роли это не играет).
Результат будет иметь следующий вид:
Модули
Отдельное внимание следует обратить на создание модулей в документации, поскольку это один из наиболее удобных способов навигации по ней и действенный инструмент её структуризации. Пример хорошей группировки по модулям можете посмотреть здесь.
Далее мы кратко рассмотрим основные моменты и приведём пример, однако если вы хотите разобраться во всех тонкостях, то тогда придётся обратиться к соответствующему разделу документации.
Создание модуля
Для объявления модуля рекомендуется использовать команду \defgroup, которую необходимо заключить в документирующий блок:
Идентификатор модуля представляет собой уникальное слово, написанное на латинице, который впоследствии будет использован для обращения к данному модулю; заголовок модуля – это произвольное слово или предложение (желательно краткое) которое будет отображаться в документации.
Обратите внимание на то, что при описании модуля можно дополнить его кратким и подробным описанием, что позволяет раскрыть назначение того или иного модуля, например:
Размещение документируемого элемента в модуле
Для того, чтобы отнести тот или иной документируемый элемент в модуль, существуют два подхода.
Первый подход – это использование команды \ingroup:
Его недостатком является то, что данную команду надо добавлять в документирующие блоки каждого элемента исходного кода, поскольку их в рамках одного модуля может быть достаточно много.
Поэтому возникает необходимость в другом подходе, и второй подход состоит в использовании команд начала и конца группы: @ <и @>. Следует отметить, что они используются наряду с командами \defgroup, \addtogroup и \weakgroup.
Пример использования приведён ниже:
Смысл примера должен быть понятен: мы объявляем модуль, а затем добавляем к ней определенные документируемые элементы, которые обрамляются при помощи символов начала и конца модуля.
Однако, модуль должен определяться один раз, причём это объявление будет только в одном файле, а часто бывает так, что элементы одного модуля разнесены по разным файлым и потому возникает необходимость использования команды \addtogroup, которая не переопределяет группу, а добавляет к ней тот или иной элемент:
Название модуля указывать необязательно. Дело в том, что данная команда может быть использована как аналог команды \defgroup, и если соответствующий модуль не был определена, то она будет создана с соответствующим названием и идентификатором.
Наконец, команда \weakgroup аналогична команде \addtogroup, отличие заключается в том, что она просто имеет меньший приоритет по сравнению с ней в случае если возникают конфликты, связанные с назначение одного и того же элемента к разным модулям.
Создание подмодуля
Для создания подмодуля достаточно при его определении отнести его к тому или иному подмодулю, подобно любому другому документируемому элементу.
Пример приведён ниже:
Пример создания нескольких модулей
Обратите внимание на то, что вид документирующих блоков несколько изменился по сравнению с приведёнными ранее примерами, но как мы говорили ранее, принципиального значения это не играет и выбирайте тот вариант, который вам ближе.
В результате мы получим следующую документацию:
Оформления текста документации
Теперь, после того, как мы в общих чертах разобрались с тем как документировать основные элементы кода, рассмотрим то, как можно сделать документацию более наглядной, выразительной и полной.
Код внутри документации
Зачастую внутри пояснения к документации необходимо для примера добавить какой-то код, например для иллюстрации работы функции.
Команды \code и \endcode
Один из наиболее простых и универсальных способов сделать это – команды \code и \endcode, которые применяются следующим образом:
Используемый язык определяется автоматически в зависимости от расширения файла, в котором располагается документирующий блок, однако в случае, если такое поведение не соответствует ожиданиям расширение можно указать явно.
Рассмотрим пример использования:
Результат будет иметь следующий вид:
Примеры кода
Иногда удобнее приводить примеры использования кода хранить в отдельных файлах. Для этого эти файлы необходимо разместить в отдельной директории и прописать к ней путь в настройках:
Рассмотрим, некоторые способы того, как примеры кода могут быть использованы в документации.
Команда \example
Данная команда показывает, что документирующий блок относится к примеру кода.
Текст исходного кода будет добавлен в раздел «примеры», а исходный код примера будет проверен на наличие документированных элементов, и если таковые будут найдены, то к ним в описание будет добавлена ссылка на пример.
В данном примере, значение EXAMPLE_PATH = examples
Команда \include
Для того, чтобы добавить в описание к документируемому элементу код примера используется команда \include, общий формат которой имеет следующий вид:
Она полностью копирует содержимое файла и вставляет его в документацию как блок кода (аналогично оформлению кода в блок начинающийся командой \code и заканчивающийся командой \endcode).
Команда \snippet
Команда \snippet аналогична предыдущей команде, однако она позволяет вставлять не весь файл, а его определенный фрагмент. Неудивительно, что её формат несколько другой:
Для выделения определенного фрагмента кода необходимо в начале и в конце его разместить документирующий блок с указанием имени фрагмента:
Автоматическое внедрение кода документируемого объекта
Наконец, Doxygen поддерживает возможность автоматической вставки тела функций, методов, классов, структур и т.п., в их подробное описание. Для этого используется следующая опция:
Формулы с использованием LaTeX
Doxygen позволяет использовать TeX формулы прямо в документации, это очень удобно и результат получается весьма достойным. Однако стоит отметить, что при этом имеются ограничения: на данный момент формулы могут быть вставлены только в HTML и LaTeX документацию, но этого, как правило, вполне достаточно.
На данный момент существует два подхода к отображению формул:
Способы добавление формул в документацию
Существуют три способа добавления формул в документацию. Последовательно рассмотрим каждый из них с примерами из документации:
Результатом будет строка следующего вида: расстояние между и равно
Результатом будет строка следующего вида:
В итоге мы получим следующий результат (заметим, что окружение eqnarray* – это ненумерованное окружение для размещения нескольких формул):
Пример внедрения формул в документацию
Рассмотрим конкретный пример документации с использованием формул LaTeX:
Результат представлен ниже:
Кратко о Markdown
Markdown – это облегчённый язык разметки (почитать о нём можно, например, здесь, а также в специальном разделе в документации). Начиная с версии 1.8.0. Doxygen обеспечивает его пока ограниченную поддержку и он служит одним из способов оформить документацию (альтернативой могут быть, например, команды для оформления документации или HTML вставки, которые, впрочем, не универсальны).
Не хотелось бы сейчас расписывать подробности и принципы данного языка, поэтому ограничимся рассмотрением того, как данный язык позволяет «украсить» нашу документацию:
Результат представлен ниже:
Подводя итоги
На этой ироничной ноте я решил остановиться. Я прекрасно понимаю, что ещё многое не было описано и затронуто, но, надеюсь, что главные свои цели статья выполнила: познакомить с понятием генератора документации, познакомиться с системой Doxygen, объяснить основные принципы и подходы к документации, а также мельком затронуть вопросы, связанные с её оформление и детализацией, подготовив задел для вашей дальнейшей работы.



