Помехоустойчивое кодирование. Часть 1: код Хэмминга

Код Хэмминга – не цель этой статьи. Я лишь хочу на его примере познакомить вас с самими принципами кодирования. Но здесь не будет строгих определений, математических формулировок и т.д. Эта просто неплохой трамплин для понимания более сложных блочных кодов.
Самый, пожалуй, известный код Хэмминга (7,4). Что значат эти цифры? Вторая – число бит информационного слова — то, что мы хотим передать в целости и сохранности. А первое – размер кодового слова: информация удобренная избыточностью. Кстати термины «информационное слово» и «кодовое слово», употребляются во всех 7-ми книгах по теории помехоустойчивого кодирования, которые мне довелось бегло пролистать.
Такой код исправляет 1 ошибку. И не важно где она возникла. Избыточность несёт в себе 3 бита информации, этого достаточно, чтобы указать на одно из 7 положений ошибки или показать, что её нет. То есть ровно 8 вариантов ответов мы ждём. А 8 = 2^3, вот как всё совпало.
Чтобы получить кодовое слово, нужно информационное слово представить в виде полинома и умножить его на порождающий полином g(x). Любое число, переведя в двоичный вид, можно представить в виде полинома. Это может показаться странным и у не подготовленного читателя сразу встаёт только один вопрос «да зачем же так усложнять?». Уверяю вас, он отпадёт сам собой, когда мы получим первые результаты.
К примеру информационное слово 1010, значение каждого его разряда это коэффициент в полиноме:

Во многих книгах пишут наоборот x+x^3. Не поддавайтесь на провокацию, это вносит только путаницу, ведь в записи числа 2-ичного, 16-ричного, младшие разряды идут справа, и сдвиги мы делаем влево/вправо ориентируясь на это. А теперь давайте умножим этот полином на порождающий полином. Порождающий полином специально для Хэмминга (7,4), встречайте: g(x)=x^3+x+1. Откуда он взялся? Ну пока считайте что он дан человечеству свыше, богами (объясню позже).
Если нужно складывать коэффициенты, то делаем по модулю 2: операция сложения заменяется на логическое исключающее или (XOR), то есть x^4+x^4=0. И в конечном итоге результат перемножения как видите из 4х членов. В двоичном виде это 1001110. Итак, получили кодовое слово, которое будем передавать на сторону по зашумлённому каналу. Замете, что перемножив информационное слово (1010) на порождающий полином (1011) как обычные числа – получим другой результат 1101110. Этого нам не надо, требуется именно «полиномиальное» перемножение. Программная реализация такого умножения очень простая. Нам потребуется 2 операции XOR и 2 сдвига влево (1й из которых на один разряд, второй на два, в соответствии с g(x)=1011):
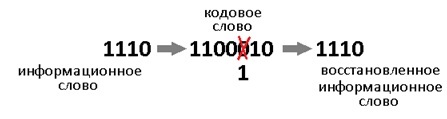
Давайте теперь специально внесём ошибку в полученное кодовое слово. Например в 3-й разряд. Получиться повреждённое слово: 1000110.
Как расшифровать сообщение и исправить ошибку? Разумеется надо «полиномиально» разделить кодовое слово на g(x). Тут я уже не буду писать иксы. Помните что вычитание по модулю 2 — это то же самое что сложение, что в свою очередь, тоже самое что исключающее или. Поехали:
Нацело разделить не получилось, значит у нас есть ошибка (ну конечно же). Результат деления в таком случае нам без надобности. Остаток от деления является синдром, его размер равен размеру избыточности, поэтому мы дописали там ноль. В данном случае содержание синдрома нам никак не помогает найти местоположение повреждения. А жаль. Но если мы возьмём любое другое информационное слово, к примеру 1100. Точно так же перемножим его на g(x), получим 1110100, внесём ошибку в тот же самый разряд 1111100. Разделим на g(x) и получим в остатке тот же самый синдром 011. И я гарантирую вам, что к такому синдрому мы придём в обще для всех кодовых слов с ошибкой в 3-м разряде. Вывод напрашивается сам собой: можно составить таблицу синдромов для всех 7 ошибок, делая каждую из них специально и считая синдром.
В результате собираем список синдромов, и то на какую болезнь он указывает:
Теперь у нас всё есть. Нашли синдром, исправили ошибку, ещё раз поделили в данном случае 1001110 на 1011 и получили в частном наше долгожданное информационное слово 1010. В остатке после исправления уже будет 000. Таблица синдромов имеет право на жизнь в случае маленьких кодов. Но для кодов, исправляющих несколько ошибок – там список синдромов разрастается как чума. Поэтому рассмотрим метод «вылавливания ошибок» не имея на руках таблицы.
Внимательный читатель заметит, что первые 3 синдрома вполне однозначно указывают на положение ошибки. Это касается только тех синдромов, где одна единица. Кол-во единиц в синдроме называют его «весом». Опять вернёмся к злосчастной ошибке в 3м разряде. Там, как вы помните был синдром 011, его вес 2, нам не повезло. Сделаем финт ушами — циклический сдвиг кодового слова вправо. Остаток от деления 0100011 / 1011 будет равен 100, это «хороший синдром», указывает что ошибка во втором разряде. Но поскольку мы сделали один сдвиг, значит и ошибка сдвинулась на 1. Вот собственно и вся хитрость. Даже в случае жуткого невезения, когда ошибка в 6м разряде, вы, обливаясь потом, после 3 мучительных делений, но всё таки находите ошибку – это победа, лишь потому, что вы не использовали таблицу синдромов.
А как насчёт других кодов Хэмминга? Я бы сказал кодов Хэмминга бесконечное множество: (7,4), (15,11), (31,26),… (2^m-1, 2^m-1-m). Размер избыточности – m. Все они исправляют 1 ошибку, с ростом информационного слова растёт избыточность. Помехоустойчивость слабеет, но в случае слабых помех код весьма экономный. Ну ладно, а как мне найти порождающую функцию например для (15,11)? Резонный вопрос. Есть теорема, гласящая: порождающий многочлен циклического кода g(x) делит (x^n+1) без остатка. Где n – нашем случае размер кодового слова. Кроме того порождающий полином должен быть простым (делиться только на 1 и на самого себя без остатка), а его степень равна размеру избыточности. Можно показать, что для Хэмминга (7,4):
Этот код имеет целых 2 порождающих полинома. Не будет ошибкой использовать любой из них. Для остальных «хэммингов» используйте вот эту таблицу примитивных полиномов:
Соответственно для (15,11) порождающий многочлен g(x)=x^4+x+1. Ну а теперь переходим к десерту – к матрицам. С этого обычно начинают, но мы этим закончим. Для начала преобразую g(x) в матрицу, на которую можно умножить информационное слово, получив кодовое слово. Если g = 1011, то:
Называют её «порождающей матрицей». Дадим обозначение информационному слову d = 1010, а кодовое обозначим k, тогда:
Это довольно изящная формулировка. По быстродействию ещё быстрее, чем перемножение полиномов. Там нужно было делать сдвиги, а тут уже всё сдвинуто. Вектор d указывает нам: какие строки брать в расчёт. Самая нижняя строка матрицы – нулевая, строки нумеруются снизу вверх. Да, да, всё потому что младшие разряды располагаются справа и от этого никуда не деться. Так как d=1010, то я беру 1ю и 3ю строки, произвожу над ними операцию XOR и вуаля. Но это ещё не всё, приготовьтесь удивляться, существует ещё проверочная матрица H. Теперь перемножением вектора на матрицу мы можем получить синдром и никаких делений полиномов делать не надо.
Посмотрите на проверочную матрицу и на список синдромов, который получили выше. Это ответ на вопрос откуда берётся эта матрица. Здесь я как обычно подпортил кодовое слово в 3м разряде, и получил тот самый синдром. Поскольку сама матрица – это и есть список синдромов, то мы тут же находим положение ошибки. Но в кодах, исправляющие несколько ошибок, такой метод не прокатит. Придётся вылавливать ошибки по методу, описанному выше.
Чтобы лучше понять саму природу исправления ошибок, сгенерируем в обще все 16 кодовых слов, ведь информационное слово состоит всего из 4х бит:
Посмотрите внимательно на кодовые слова, все они, отличаются друг от друга хотя бы на 3 бита. К примеру возьмёте слово 1011000, измените в нём любой бит, скажем первый, получиться 1011010. Вы не найдёте более на него похожего слова, чем 1011000. Как видите для формирования кодового слова не обязательно производить вычисления, достаточно иметь эту таблицу в памяти, если она мала. Показанное различие в 3 бита — называется минимальное «хэммингово расстояние», оно является характеристикой блокового кода, по нему судят сколько ошибок можно исправить, а именно (d-1)/2. В более общем виде код Хэмминга можно записать так (7,4,3). Отмечу только, что Хэммингово расстояние не является разностью между размерами кодового и информационного слов. Код Голея (23,12,7) исправляет 3 ошибки. Код (48, 36, 5) использовался в сотовой связи с временным разделением каналов (стандарт IS-54). Для кодов Рида-Соломона применима та же запись, но это уже недвоичные коды.
Список используемой литературы:
1. М. Вернер. Основы кодирования (Мир программирования) — 2004
2. Р. Морелос-Сарагоса. Искусство помехоустойчивого кодирования (Мир связи) — 2006
3. Р. Блейхут. Теория и практика кодов, контролирующих ошибки — 1986
Помехоустойчивое кодирование с иcпользованием различных кодов
Это продолженеие статьи о помехоустойчивом кодировании, которая очень долго лежала в черновиках. В прошлой части нет ничего интересного с практической точки зрения — лишь общие сведения о том, зачем это нужно, где применяется и т.п. В данной части будут рассматриваться некоторые (самые простые) коды для обнаружения и/или исправления ошибок. Итак, поехали.
Попытался все описать как можно легче для человека, который никогда не занимался кодированием информации, и без каких-либо особых математических формул.
Когда мы передаем сообщение от источника к приемнику, при передаче данных может произойти ошибка (помехи, неисправность оборудования и пр.). Чтобы обнаружить и исправить ошибку, применяют помехоустойчивое кодирование, т.е. кодируют сообщение таким образом, чтобы принимающая сторона знала, произошла ошибка или нет, и при могла исправить ошибки в случае их возникновения.
По сути, кодирование — это добавление к исходной информации дополнительной, проверочной, информации. Для кодирования на передающей стороне используются кодер, а на принимающей стороне — используют декодер для получения исходного сообщения.
Избыточность кода — это количество проверочной информации в сообщении. Рассчитывается она по формуле:
k/(i+k), где
k — количество проверочных бит,
i — количество информационных бит.
Например, мы передаем 3 бита и к ним добавляем 1 проверочный бит — избыточность составит 1/(3+1) = 1/4 (25%).
Код с проверкой на четность
Проверка четности – очень простой метод для обнаружения ошибок в передаваемом пакете данных. С помощью данного кода мы не можем восстановить данные, но можем обнаружить только лишь одиночную ошибку.
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10110 (изменился второй бит)
Как мы видим, количество единиц в принятом пакете нечетно, следовательно, при передаче произошла ошибка.
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10010 (изменились 2 и 3 биты)
В принятых данных число единиц четно, и, следовательно, декодер не обнаружит ошибку.
Так как около 90% всех нерегулярных ошибок происходит именно с одиночным разрядом, проверки четности бывает достаточно для большинства ситуаций.
Код Хэмминга
первый проверочный бит на 2 0 = 1;
второй проверочный бит на 2 1 = 2;
третий проверочный бит на 2 2 = 4;
r1 = i1 + i2 + i4
r2 = i1 + i3 + i4
r3 = i2 + i3 + i4
В принципе, работа этого алгоритма разобрана очень детально в статье Код Хэмминга. Пример работы алгоритма, так что особо подробно описывать в этой статье не вижу смысла. Вместо этого приведу структурную схему кодера:
и декодера
(может быть, довольно запутано, но лучше начертить не получилось)
e0,e1,e2 опрделяются как функции, зависящие от принятых декодером бит k1 — k7:
e0 = k1 + k3 + k5 + k7 mod 2
e1 = k2 + k3 + k6 + k7 mod 2
e2 = k4 + k5 + k6 + k7 mod 2
Набор этих значений e2e1e0 есть двоичная запись позиции, где произошла ошибка при передаче данных. Декодер эти значения вычисляет, и если они все не равны 0 (то есть не получится 000), то исправляет ошибку.
Коды-произведения
В канале связи кроме одиночных ошибок, вызванных шумами, часто встречаются пакетные ошибки, вызванные импульсными помехами, замираниями или выпадениями (при цифровой видеозаписи). При этом пораженными оказываются сотни, а то и тысячи бит информации подряд. Ясно, что ни один помехоустойчивый код не сможет справиться с такой ошибкой. Для возможности борьбы с такими ошибками используются коды-произведения. Принцип действия такого кода изображён на рисунке:
Передаваемая информация кодируется дважды: во внешнем и внутреннем кодерах. Между ними устанавливается буфер, работа которого показана на рисунке:
Информационные слова проходят через первый помехоустойчивый кодер, называемый внешним, т.к. он и соответствующий ему декодер находятся по краям системы помехоустойчивого кодирования. Здесь к ним добавляются проверочные символы, а они, в свою очередь, заносятся в буфер по столбцам, а выводятся построчно. Этот процесс называется перемешиванием или перемежением.
При выводе строк из буфера к ним добавляются проверочные символы внутреннего кода. В таком порядке информация передается по каналу связи или записывается куда-нибудь. Условимся, что и внутренний, и внешний коды – коды Хэмминга, с тремя проверочными символами, то есть и тот, и другой могут исправить по одной ошибке в кодовом слове (количество «кубиков» на рисунке не критично — это просто схема). На приемном конце расположен точно такой же массив памяти (буфер), в который информация заносится построчно, а выводится по столбцам. При возникновении пакетной ошибки (крестики на рисунке в третьей и четвертой строках), она малыми порциями распределяется в кодовых словах внешнего кода и может быть исправлена.
Назначение внешнего кода понятно – исправление пакетных ошибок. Зачем же нужен внутренний код? На рисунке, кроме пакетной, показана одиночная ошибка (четвертый столбец, верхняя строка). В кодовом слове, расположенном в четвертом столбце — две ошибки, и они не могут быть исправлены, т.к. внешний код рассчитан на исправление одной ошибки. Для выхода из этой ситуации как раз и нужен внутренний код, который исправит эту одиночную ошибку. Принимаемые данные сначала проходят внутренний декодер, где исправляются одиночные ошибки, затем записываются в буфер построчно, выводятся по столбцам и подаются на внешний декодер, где происходит исправление пакетной ошибки.
Использование кодов-произведений многократно увеличивает мощность помехоустойчивого кода при добавлении незначительной избыточности.
| Нить | Вес Хэмминга |
|---|---|
| 111 0 1 | 4 |
| 111 0 1 000 | 4 |
| 00000000 | 0 |
| 678 0 1234 0 567 | 10 |
| График подсчета населения (вес Хэмминга для двоичных чисел) для (десятичных) чисел от 0 до 256. |
СОДЕРЖАНИЕ
История и использование
Эффективное внедрение
| Выражение | Двоичный | Десятичная дробь | Комментарий | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| a | 01 | 10 | 11 | 00 | 10 | 11 | 10 | 10 | 27834 | Исходный номер |
| b0 = (a >> 0) & 01 01 01 01 01 01 01 01 | 01 | 00 | 01 | 00 | 00 | 01 | 00 | 00 | 1, 0, 1, 0, 0, 1, 0, 0 | Каждый другой бит от |
| b1 = (a >> 1) & 01 01 01 01 01 01 01 01 | 00 | 01 | 01 | 00 | 01 | 01 | 01 | 01 | 0, 1, 1, 0, 1, 1, 1, 1 | Остальные биты из |
| c = b0 + b1 | 01 | 01 | 10 | 00 | 01 | 10 | 01 | 01 | 1, 1, 2, 0, 1, 2, 1, 1 | Подсчет единиц в каждом 2-битном срезе |
| d0 = (c >> 0) & 0011 0011 0011 0011 | 0001 | 0000 | 0010 | 0001 | 1, 0, 2, 1 | Все остальные отсчитываются от c | ||||
| d2 = (c >> 2) & 0011 0011 0011 0011 | 0001 | 0010 | 0001 | 0001 | 1, 2, 1, 1 | Остальные отсчеты от c | ||||
| e = d0 + d2 | 0010 | 0010 | 0011 | 0010 | 2, 2, 3, 2 | Подсчет единиц в каждом 4-битном срезе | ||||
| f0 = (e >> 0) & 00001111 00001111 | 00000010 | 00000010 | 2, 2 | Все остальные считают от е | ||||||
| f4 = (e >> 4) & 00001111 00001111 | 00000010 | 00000011 | 2, 3 | Остальные отсчеты от e | ||||||
| g = f0 + f4 | 00000100 | 00000101 | 4, 5 | Подсчет единиц в каждом 8-битном срезе | ||||||
| h0 = (g >> 0) & 0000000011111111 | 0000000000000101 | 5 | Все остальные считают от g | |||||||
| h8 = (g >> 8) & 0000000011111111 | 0000000000000100 | 4 | Остальные отсчеты от g | |||||||
| i = h0 + h8 | 0000000000001001 | 9 | Подсчет единиц во всем 16-битном слове | |||||||
Если разрешено большее использование памяти, мы можем вычислить вес Хэмминга быстрее, чем описанные выше методы. Имея неограниченную память, мы могли бы просто создать большую таблицу поиска веса Хэмминга для каждого 64-битного целого числа. Если мы можем сохранить таблицу поиска функции Хэмминга для каждого 16-битного целого числа, мы можем сделать следующее, чтобы вычислить вес Хэмминга для каждого 32-битного целого числа.
Muła et al. показали, что векторизованная версия popcount64b может работать быстрее, чем специальные инструкции (например, popcnt на процессорах x64).
Минимальный вес
Языковая поддержка
Некоторые компиляторы C предоставляют встроенные функции, обеспечивающие подсчет битов. Например, GCC (начиная с версии 3.4 в апреле 2004 г.) включает встроенную функцию, __builtin_popcount которая будет использовать инструкцию процессора, если она доступна, или эффективную реализацию библиотеки в противном случае. LLVM-GCC включает эту функцию с версии 1.5 в июне 2005 года.
В Java структура данных растущего битового массива BitSet имеет BitSet.cardinality() метод, который подсчитывает количество установленных битов. Кроме того, существует Integer.bitCount(int) и Long.bitCount(long) функция для подсчета бит в примитивных 32-битных и 64-битных числах, соответственно. Кроме того, BigInteger целочисленный класс произвольной точности также имеет BigInteger.bitCount() метод подсчета битов.
В Python у этого int типа есть bit_count() метод для подсчета количества установленных битов. Эта функция является новой в Python 3.10, выпуск которой запланирован на 2021 год.
Начиная с GHC 7.4, в базовом пакете Haskell есть popCount функция, доступная для всех типов, которые являются экземплярами Bits класса (доступны из Data.Bits модуля).
MySQL версии SQL языка обеспечивает в BIT_COUNT() качестве стандартной функции.
Fortran 2008 имеет стандартную внутреннюю элементарную функцию, popcnt возвращающую количество ненулевых битов в целочисленном (или целочисленном массиве).
FreePascal реализует popcnt начиная с версии 3.0.
Корректирующие коды. Начало новой теории кодирования

Введение
По основному своему образованию я не математик, но в связи с читаемыми мной дисциплинами в ВУЗе пришлось в ней дотошно разбираться. Долго и упорно читал классические учебники ведущих наших Университетов, пятитомную математическую энциклопедию, множество тонких популярных брошюр по отдельным вопросам, но удовлетворения не возникало. Не возникало и глубокое понимание прочитанного.
Вся математическая классика ориентирована, как правило, на бесконечный теоретический случай, а специальные дисциплины опираются на случай конечных конструкций и математических структур. Отличие подходов колоссальное, отсутствие или недостаток хороших полных примеров — пожалуй главный минус и недостаток вузовских учебников. Очень редко существует задачник с решениями для начинающих (для первокурсников), а те, что имеются, грешат пропусками в объяснениях. В общем я полюбил букинистические магазины технической книги, благодаря чему пополнилась библиотека и в определенной мере багаж знаний. Читать довелось много, очень много, но «не заходило».
Этот путь привел меня к вопросу, а что я уже могу самостоятельно делать без книжных «костылей», имея перед собой только чистый лист бумаги и карандаш с ластиком? Оказалось совсем немного и не совсем то, что было нужно. Пройден был сложный путь бессистемного самообразования. Вопрос был такой. Могу ли я построить и объяснить, прежде всего себе, работу кода, обнаруживающего и исправляющего ошибки, например, код Хемминга, (7, 4)-код?
Известно, что код Хемминга широко используется во многих прикладных программах в области хранения и обмена данными, особенно в RAID; кроме того, в памяти типа ECC и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
Информационная безопасность. Коды, шифры, стегосообщения
Информационное взаимодействие путем обмена сообщениями его участников должно обеспечиваться защитой на разных уровнях и разнообразными средствами как аппаратными так и программными. Эти средства разрабатываются, проектируются и создаются в рамках определенных теорий (см. рис.А) и технологий, принятых международными договоренностями об OSI/ISO моделях.
Защита информации в информационных телекоммуникационных системах (ИТКС) становится практически основной проблемой при решении задач управления, как в масштабе отдельной личности – пользователя, так и для фирм, объединений, ведомств и государства в целом. Из всех аспектов защиты ИТКС в этой статье будем рассматривать защиту информации при ее добывании, обработке, хранении и передаче в системах связи.
Уточняя далее предметную область, остановимся на двух возможных направлениях, в которых рассматриваются два различных подхода к защите, представлению и использованию информации: синтаксическом и семантическом. На рисунке используются сокращения: кодек–кодер-декодер; шидеш – шифратор-дешифратор; скриз – скрыватель – извлекатель.
Рисунок А – Схема основных направлений и взаимосвязи теорий, направленных на решение задач защиты информационного взаимодействия
Синтаксические особенности представления сообщений позволяют контролировать и обеспечивать правильность и точность (безошибочность, целостность) представления при хранении, обработке и особенно при передаче информации по каналам связи. Здесь главные задачи защиты решаются методами кодологии, ее большой части — теории корректирующих кодов.
Семантическая (смысловая) безопасность сообщений обеспечивается методами криптологии, которая средствами криптографии позволяет защитить от овладения содержанием информации потенциальным нарушителем. Нарушитель при этом может скопировать, похитить, изменить или подменить, или даже уничтожить сообщение и его носитель, но он не сможет получить сведений о содержании и смысле передаваемого сообщения. Содержание информации в сообщении останется для нарушителя недоступным. Таким образом, предметом дальнейшего рассмотрения будет синтаксическая и семантическая защита информации в ИТКС. В этой статье ограничимся рассмотрением только синтаксического подхода в простой, но весьма важной его реализации корректирующим кодом.
Сразу проведу разграничительную линию в решении задач информационной безопасности:
теория кодологии призвана защищать информацию (сообщения) от ошибок (защита и анализ синтаксиса сообщений) канала и среды, обнаруживать и исправлять ошибки;
теория криптологии призвана защищать информацию от несанкционированного доступа к ее семантике нарушителя (защита семантики, смысла сообщений);
теория стеганологии призвана защищать факт информационного обмена сообщениями, а также обеспечивать защиту авторского права, персональных данных (защита врачебной тайны).
В общем «поехали». По определению, а их довольно много, понять что есть код очень даже не просто. Авторы пишут, что код — это алгоритм, отображение и ещё что-то. О классификации кодов я не буду здесь писать, скажу только, что (7, 4)-код блоковый.
В какой-то момент до меня дошло, что код — это кодовые специальные слова, конечное их множество, которыми заменяют специальными алгоритмами исходный текст сообщения на передающей стороне канала связи и которые отправляются по каналу получателю. Замену осуществляет устройство-кодер, а на приемной стороне эти слова распознает устройство-декодер.
Поскольку роль сторон переменчива оба этих устройства объединяют в одно и называют сокращенно кодек (кодер/декодер), и устанавливают на обоих концах канала. Дальше, раз есть слова, есть и алфавит. Алфавит — это два символа <0, 1>, в технике массово используются блоковые двоичные коды. Алфавит естественного языка (ЕЯ) — множество символов — букв, заменяющих при письме звуки устной речи. Здесь не будем углубляться в иероглифическую письменность в слоговое или узелковое письмо.
Алфавит и слова — это уже язык, известно, что естественные человеческие языки избыточны, но что это означает, где обитает избыточность языка трудно сказать, избыточность не очень хорошо организована, хаотична. При кодировании, хранении информации избыточность стремятся уменьшить, пример, архиваторы, код Морзе и др.
Ричард Хемминг, наверное, раньше других понял, что если избыточность не устранять, а разумно организовать, то ее можно использовать в системах связи для обнаружения ошибок и автоматического их исправления в кодовых словах передаваемого текста. Он понял, что все 128 семиразрядных двоичных слов могут использоваться для обнаружения ошибок в кодовых словах, которые образуют код — подмножество из 16 семиразрядных двоичных слов. Это была гениальная догадка.
До изобретения Хемминга ошибки приемной стороной тоже обнаруживались, когда декодированный текст не читался или получалось не совсем то, что нужно. При этом посылался запрос отправителю сообщения повторить блоки определенных слов, что, конечно, было весьма неудобно и тормозило сеансы связи. Это было большой не решаемой десятилетиями проблемой.
Построение (7, 4)-кода Хемминга
Вернемся к Хеммингу. Слова (7, 4)-кода образованы из 7 разрядов С j =  , j = 0(1)15, 4-информационные и 3-проверочные символа, т.е. по существу избыточные, так как они не несут информации сообщения. Эти три проверочных разряда удалось представить линейными функциями 4-х информационных символов в каждом слове, что и обеспечило обнаружение факта ошибки и ее места в словах, чтобы внести исправление. А (7, 4)-код получил новое прилагательное и стал линейным блоковым двоичным.
, j = 0(1)15, 4-информационные и 3-проверочные символа, т.е. по существу избыточные, так как они не несут информации сообщения. Эти три проверочных разряда удалось представить линейными функциями 4-х информационных символов в каждом слове, что и обеспечило обнаружение факта ошибки и ее места в словах, чтобы внести исправление. А (7, 4)-код получил новое прилагательное и стал линейным блоковым двоичным.
Линейные функциональные зависимости (правила (*)) вычислений значений символов
 имеют следующий вид:
имеют следующий вид:



Исправление ошибки стало очень простой операцией — в ошибочном разряде определялся символ (ноль или единица) и заменялся другим противоположным 0 на 1 или 1 на 0.
Сколько же различных слов образуют код? Ответ на этот вопрос для (7, 4)-кода получается очень просто. Раз имеется лишь 4 информационных разряда, а их разнообразие при заполнении символами имеет  = 16 вариантов, то других возможностей просто нет, т. е. код состоящий всего из 16 слов, обеспечивает представление этими 16-ю словами всю письменность всего языка.
= 16 вариантов, то других возможностей просто нет, т. е. код состоящий всего из 16 слов, обеспечивает представление этими 16-ю словами всю письменность всего языка.
Информационные части этих 16 слов получают нумерованный вид №
( ):
):
0=0000; 4= 0100; 8=1000; 12=1100;
1=0001; 5= 0101; 9=1001; 13=1101;
2=0010; 6= 0110; 10=1010; 14=1110;
3=0011; 7= 0111; 11=1011; 15=1111.
Каждому из этих 4-разрядных слов необходимо вычислить и добавить справа по 3 проверочных разряда, которые вычисляются по правилам (*). Например, для информационного слова №6 равного 0110 имеем  и вычисления проверочных символов дают для этого слова такой результат:
и вычисления проверочных символов дают для этого слова такой результат:




Шестое кодовое слово при этом приобретает вид:  Таким же образом необходимо вычислить проверочные символы для всех 16-и кодовых слов. Подготовим для слов кода 16-строчную таблицу К и последовательно будем заполнять ее клетки (читателю рекомендую проделать это с карандашом в руках).
Таким же образом необходимо вычислить проверочные символы для всех 16-и кодовых слов. Подготовим для слов кода 16-строчную таблицу К и последовательно будем заполнять ее клетки (читателю рекомендую проделать это с карандашом в руках).
Таблица К – кодовые слова Сj, j = 0(1)15, (7, 4) – кода Хемминга
Описание таблицы: 16 строк — кодовые слова; 10 колонок: порядковый номер, десятичное представление кодового слова, 4 информационных символа, 3 проверочных символа, W-вес кодового слова равен числу ненулевых разрядов (≠ 0). Заливкой выделены 4 кодовых слова-строки — это базис векторного подпространства. Собственно, на этом все — код построен.
Таким образом, в таблице получены все слова (7, 4) — кода Хемминга. Как видите это было не очень сложно. Далее речь пойдет о том, какие идеи привели Хемминга к такому построению кода. Мы все знакомы с кодом Морзе, с флотским семафорным алфавитом и др. системами построенными на разных эвристических принципах, но здесь в (7, 4)-коде используются впервые строгие математические принципы и методы. Рассказ будет как раз о них.
Математические основы кода. Высшая алгебра
Подошло время рассказать какая Р.Хеммингу пришла идея открытия такого кода. Он не питал особых иллюзий о своем таланте и скромно формулировал перед собой задачу: создать код, который бы обнаруживал и исправлял в каждом слове одну ошибку (на деле обнаруживать удалось даже две ошибки, но исправлялась лишь одна из них). При качественных каналах даже одна ошибка — редкое событие. Поэтому замысел Хемминга все-таки в масштабах системы связи был грандиозным. В теории кодирования после его публикации произошла революция.
Это был 1950 год. Я привожу здесь свое простое (надеюсь доступное для понимания) описание, которого не встречал у других авторов, но как оказалось, все не так просто. Потребовались знания из многочисленных областей математики и время, чтобы все глубоко осознать и самому понять, почему это так сделано. Только после этого я смог оценить ту красивую и достаточно простую идею, которая реализована в этом корректирующем коде. Время я в основном, потратил на разбирательство с техникой вычислений и теоретическим обоснованием всех действий, о которых здесь пишу.
Создатели кодов, долго не могли додуматься до кода, обнаруживающего и исправляющего две ошибки. Идеи, использованные Хеммингом, там не срабатывали. Пришлось искать, и нашлись новые идеи. Очень интересно! Захватывает. Для поиска новых идей потребовалось около 10 лет и только после этого произошел прорыв. Коды, обнаруживающие произвольное число ошибок, были получены сравнительно быстро.
Векторные пространства, поля и группы. Полученный (7, 4)-код (Таблица К) представляет множество кодовых слов, являющихся элементами векторного подпространства (порядка 16, с размерностью 4), т.е. частью векторного пространства размерности 7 с порядком  Из 128 слов в код включены лишь 16, но они попали в состав кода не просто так.
Из 128 слов в код включены лишь 16, но они попали в состав кода не просто так.
Во-первых, они являются подпространством со всеми вытекающими отсюда свойствами и особенностями, во-вторых, кодовые слова являются подгруппой большой группы порядка 128, даже более того, аддитивной подгруппой конечного расширенного поля Галуа GF( ) степени расширения n = 7 и характеристики 2. Эта большая подгруппа раскладывается в смежные классы по меньшей подгруппе, что хорошо иллюстрируется следующей таблицей Г. Таблица разделена на две части: верхняя и нижняя, но читать следует как одну длинную. Каждый смежный класс (строка таблицы) — элемент факторгруппы по эквивалентности составляющих.
) степени расширения n = 7 и характеристики 2. Эта большая подгруппа раскладывается в смежные классы по меньшей подгруппе, что хорошо иллюстрируется следующей таблицей Г. Таблица разделена на две части: верхняя и нижняя, но читать следует как одну длинную. Каждый смежный класс (строка таблицы) — элемент факторгруппы по эквивалентности составляющих.
Таблица Г – Разложение аддитивной группы поля Галуа GF () в смежные классы (строки таблицы Г) по подгруппе 16 порядка.
Столбцы таблицы – это сферы радиуса 1. Левый столбец (повторяется) – синдром слова (7, 4)-кода Хемминга, следующий столбец — лидеры смежного класса. Раскроем двоичное представление одного из элементов (25-го выделен заливкой) факторгруппы и его десятичное представление:

Техника получение строк таблицы Г. Элемент из столбца лидеров класса суммируется с каждым элементом из заголовка столбца таблицы Г (суммирование выполняется для строки лидера в двоичном виде по mod2). Поскольку все лидеры классов имеют вес W=1, то все суммы отличаются от слова в заголовке столбца только в одной позиции (одной и той же для всей строки, но разных для столбца). Таблица Г имеет замечательную геометрическую интерпретацию. Все 16 кодовых слов представляются центрами сфер в 7-мерном векторном пространстве. Все слова в столбце от верхнего слова отличаются в одной позиции, т. е. лежат на поверхности сферы с радиусом r =1.
Второе — все множество 7-разрядных двоичных слов из 128 слов равномерно распределено по 16 сферам. Декодер может получить слово лишь из этого множества 128-ми известных слов с ошибкой или без нее. Третье — приемная сторона может получить слово без ошибки или с искажением, но всегда принадлежащее одной из 16-и сфер, которая легко определяется декодером. В последней ситуации принимается решение о том, что послано было кодовое слово — центр определенной декодером сферы, который нашел позицию (пересечение строки и столбца) слова в таблице Г, т. е номера столбца и строки.
Здесь возникает требование к словам кода и к коду в целом: расстояние между любыми двумя кодовыми словами должно быть не менее трех, т. е. разность для пары кодовых слов, например, Сi = 85==1010101; Сj = 25== 0011001 должна быть не менее 3; 85 — 25 = 1010101 — 0011001 =1001100 = 76, вес слова-разности W(76) = 3. (табл. Д заменяет вычисления разностей и сумм). Здесь под расстоянием между двоичными словами-векторами понимается количество не совпадающих позиций в двух словах. Это расстояние Хемминга, которое стало повсеместно использоваться в теории, и на практике, так как удовлетворяет всем аксиомам расстояния.
Замечание. (7, 4)-код не только линейный блоковый двоичный, но он еще и групповой, т. е. слова кода образуют алгебраическую группу по сложению. Это означает, что любые два кодовых слова при суммировании снова дают одно из кодовых слов. Только это не обычная операция суммирования, выполняется сложение по модулю два.
Таблица Д — Сумма элементов группы (кодовых слов), используемой для построения кода Хемминга
Сама операция суммирования слов ассоциативна, и для каждого элемента в множестве кодовых слов имеется противоположный ему, т. е. суммирование исходного слова с противоположным дает нулевое значение. Это нулевое кодовое слово является нейтральным элементом в группе. В таблице Д- это главная диагональ из нулей. Остальные клетки (пересечения строка/столбец) — это номера-десятичные представления кодовых слов, полученные суммированием элементов из строки и столбца.При перестановке слов местами (при суммировании) результат остается прежним, более того, вычитание и сложение слов имеют одинаковый результат. Дальше рассматривается система кодирования/декодирования, реализующая синдромный принцип.
Применение кода. Кодер
Пример 1. Необходимо передать слово «цифра» в ЕЯ. Входим в таблицу ASCII-кодов, буквам соответствуют: ц –11110110, и –11101000, ф – 11110100, р – 11110000, а – 11100000 октеты. Или иначе в ASCII — кодах слово «цифра» = 1111 0110 1110 1000 1111 0100 1111 0000 1110 0000
с разбивкой на тетрады (по 4 разряда). Таким образом, кодирование слова «цифра» ЕЯ требует 10 кодовых слов (7, 4)-кода Хемминга. Тетрады представляют информационные разряды слов сообщения. Эти информационные слова (тетрады) преобразуются в слова кода (по 7 разрядов) перед отправкой в канал сети связи. Выполняется это путем векторно-матричного умножения: информационного слова на порождающую матрицу. Плата за удобства получается весьма дорого и длинно, но все работает автоматически и главное — сообщение защищается от ошибок.
Порождающая матрица (7, 4)-кода Хемминга или генератор слов кода получается выписыванием базисных векторов кода и объединением их в матрицу. Это следует из теоремы линейной алгебры: любой вектор пространства (подпространства) является линейной комбинацией базисных векторов, т.е. линейно независимых в этом пространстве. Это как раз и требуется — порождать любые векторы (7-разрядные кодовые слова) из информационных 4-разрядных.
Порождающая матрица (7, 4, 3)-кода Хемминга или генератор слов кода имеет вид:
Справа указаны десятичные представления кодовых слов Базиса подпространства и их порядковые номера в таблице К
№ i строки матрицы — это слова кода, являющиеся базисом векторного подпространства.
Информационные слова сообщения имеют вид:
Это половины символа (ц). Для (7, 4)-кода, определенного ранее, требуется найти кодовые слова, соответствующее информационному слову-сообщению (ц) из 8-и символов в виде:
Чтобы превратить эту букву–сообщение (ц) в кодовые слова u, каждую половинку буквы-сообщения i умножают на порождающую матрицу G[k, n] кода (матрица для таблицы К):
Получили два кодовых слова с порядковыми номерами 15 и 6.
Покажем детальное формирование нижнего результата №6 – кодового слова (умножение строки информационного слова на столбцы порождающей матрицы); суммирование по (mod2)
∙ = 0∙1 +1∙0 + 1∙0 + 0∙0 = 0(mod2);
∙ = 0∙0 +1∙1 + 1∙0 + 0∙0 = 1(mod2);
∙ = 0∙0 +1∙0 + 1∙1 + 0∙0 = 1(mod2);
∙ = 0∙0 +1∙0 + 1∙0 + 0∙1 = 0(mod2);
∙ = 0∙0 +1∙1 + 1∙1 + 0∙1 = 0(mod2);
∙ = 0∙1 +1∙0 + 1∙1 + 0∙1 = 1(mod2);
∙ = 0∙1 +1∙1 + 1∙0 + 0∙1 = 1(mod2).
В результате перемножения получили 15 и 6 слова таблицы К кода.
Применение кода. Декодер
Декодер размещается на приемной стороне канала там, где находится получатель сообщения. Назначение декодера состоит в предоставлении получателю переданного сообщения в том виде, в котором оно существовало у отправителя в момент отправления, т.е. получатель может воспользоваться текстом и использовать сведения из него для своей дальнейшей работы.
Основной задачей декодера является проверка того, является ли полученное слово (7 разрядов) тем, которое было отправлено на передающей стороне, не содержит ли слово ошибок. Для решения этой задачи для каждого полученного слова декодером путем умножения его на проверочную матрицу Н[n-k, n] вычисляется короткий вектор-синдром S (3 разряда).
Рассматриваемый код является систематическим, т. е. символы информационного слова размещаются подряд в старших разрядах кодового слова. Восстановление информационных слов выполняется простым отбрасыванием младших (проверочных) разрядов, число которых известно. Далее используется таблица ASCII-кодов в обратном порядке: входом являются информационные двоичные последовательности, а выходом – буквы алфавита естественного языка. Итак, (7, 4)-код систематический, групповой, линейный, блочный, двоичный.
Основу декодера образует проверочная матрица Н[n-k, n], которая содержит число строк, равное числу проверочных символов, а столбцами все возможные, кроме нулевого, столбцы из трех символов  . Проверочная матрица строится из слов таблицы К, они выбираются так, чтобы быть ортогональными к кодирующей матрице, т.е. их произведение — нулевая матрица. Проверочная матрица получает следующий вид в операциях умножения она транспонируется. Для конкретного примера проверочная матрица Н[n-k, n] приведена ниже:
. Проверочная матрица строится из слов таблицы К, они выбираются так, чтобы быть ортогональными к кодирующей матрице, т.е. их произведение — нулевая матрица. Проверочная матрица получает следующий вид в операциях умножения она транспонируется. Для конкретного примера проверочная матрица Н[n-k, n] приведена ниже:
Видим, что произведение порождающей матрицы на проверочную в результате дает нулевую матрицу.
В результате вычисленный синдром имеет нулевое значение, что подтверждает отсутствие ошибки в словах кода.
Пример 3. Обнаружение одной ошибки в слове, полученном на приемном конце канала (таблица К).
А) Пусть требуется передать 7 – е кодовое слово, т.е.
Установление факта искажения кодового слова выполняется умножением полученного искаженного слова на проверочную матрицу кода. Результатом такого умножения будет вектор, называемый синдромом кодового слова.
Выполним такое умножение для наших исходных (7-го вектора с ошибкой) данных.
Итак, при вычислениях получен синдром S= для обоих слов одинаковый. Смотрим на проверочную матрицу и отыскиваем в ней столбец, совпадающий с синдромом. Это третий слева столбец. Следовательно, ошибка допущена в третьем слева разряде, что совпадает с условиями примера. Этот третий разряд изменяется на противоположное значение и мы вернули принятые декодером слова к виду кодовых. Ошибка обнаружена и исправлена.
Вот собственно и все, именно так устроен и работает классический (7, 4)-код Хемминга.
Здесь не рассматриваются многочисленные модификации и модернизации этого кода, так как важны не они, а те идеи и их реализации, которые в корне изменили теорию кодирования, и как следствие, системы связи, обмена информацией, автоматизированные системы управления.
Заключение
В работе рассмотрены основные положения и задачи информационной безопасности, названы теории, призванные решать эти задачи.
Задача защиты информационного взаимодействия субъектов и объектов от ошибок среды и от воздействий нарушителя относится к кодологии.
Рассмотрен в деталях (7, 4)-код Хемминга, положивший начало нового направлению в теории кодирования — синтеза корректирующих кодов.
Показано применение строгих математических методов, используемых при синтезе кода.
Приведены примеры иллюстрирующие работоспособность кода.



