Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Совет профессионалов: не начинайте с BS4/Scrapy
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
Поищите XHR запросы в консоли разработчика
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Кнопка, которую я искал месяцы
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят. И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Вырезаете JSON из HTML любыми костылямии (я использую html.find(«=<") ).
Отрендерите JS через Headless Browsers
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из Cool website достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Парсер что это простым языком, для чего нужен и как его сделать

Приветствую Вас на страницах блога: My-busines.ru. Сегодня мы рассмотрим популярный термин – один из способов автоматизации при работе с вебсайтами.
Парсеры — специализированные программы, способные исследовать контент в автоматическом режиме и обнаруживать необходимые фрагменты.
Под парсингом подразумевается действие, в ходе которого конкретный документ анализируется с точки зрения синтаксиса и лексики. Он преобразовывается; если в нем выявлены искомые сведения, они выбираются для последующего применения.
Для скорой обработки информации применяется парсинг. Так называют поочередную синтаксическую оценку данных, размещенных на интернет-страничках. Данный способ применяется для своевременного обрабатывания и копирования большого количества информации, если ручной труд требует много времени.
Для чего нужен
С целью создания веб-сайта и его эффективного продвижения необходимо огромное количество контента, который нужно длительно формировать в ручном порядке.
Парсеры имеют последующие возможности:
Какие бывают виды
Приобретение сведений в интернете – сложная, обыденная, забирающая большое количество времени деятельность. Парсеры могут в сутки рассортировать значительную долю веб-ресурсов в поисках необходимых сведений, автоматизируют её.
Более стремительно «парсят» всеобщую сеть роботы поисковых концепций. Однако, сведения накапливаются парсерами и в индивидуальных интересах. На её базе, н-р, возможно писать диссертацию. Парсинг применяют программы автоматичного контроля уникальности текстовый данных, стремительно сопоставляя содержимое сотен веб-страничек с предоставленным текстом.
Без схем парсинга обладателям интернет-магазинов, которым необходимы сотни монотипных изображений продуктов, технических данных и иного контента, было бы сложно ручным способом забивать характеристики продуктов.
Выделяют 2 более распространенных разновидности парсинга в интернете:
Некоторые программы объединяют данные функции, плюс затягивают добавочные функции и полномочия.
Как сделать парсер
Какие программы использовать
Рассмотрим некоторые наилучшие легкодоступные программы парсинга:
Что такое парсер сайтов
Эта концепция функционирует по установленной программе, сравнивает конкретную комбинацию слов, с тем, что обнаружилось в интернете. Как действовать с приобретенными сведениями, прописано в командной строчке, именуемой «регулярное выражение». Она складывается из знаков, организовывает принцип поиска.
Парсер сайтов осуществляет службу в ряд этапов:
Видео на эту тему:
В заключение нужно добавить, что в статье рассмотрены только законные виды парсинга.
Маркетолог, вебмастер, блогер с 2011 года. Люблю WordPress, Email маркетинг, Camtasia Studio, партнерские программы)) Создаю сайты и лендинги под ключ НЕДОРОГО. Обучаю созданию и продвижению (SEO) сайтов в поисковых системах.
В 2,5 раза больше конверсий


Парсинг: что это такое простыми словами
Сегодня парсинг настолько распространен, что о нем должен знать каждый вебмастер, а маркетолог и подавно. Когда-нибудь его надо включать в список обязательных инструментов, ведь при грамотном использовании можно извлечь немало пользы. Процесс этот отличается от взлома, а если следовать инструкциям (прописанным в robots.txt на сайтах), то и вполне законный.

Что такое парсинг и что значит парсить
Дословный перевод слова parsing — делать грамматический разбор или структурировать. В программировании/информатике, это автоматический сбор и систематизация необходимых сведений, размещенных на веб-ресурсах с помощью специальных программ.
Принцип работы парсинга основывается на сравнении готового общепринятого шаблона и найденной в сети информации. Например, вы создали интернет-магазин и хотите его продвигать. Вам нужно скопировать данные о товарах (цены, изображения, описания) у конкурентов, а потом разместить на своем сайте. Делать это вручную — длительная и рутинная работа, особенно когда речь идет о 500-1000 товарах. Поэтому процесс автоматизируется, и сбор данных доверяется программе/сервису. Результатом станет колоссальная экономия времени.
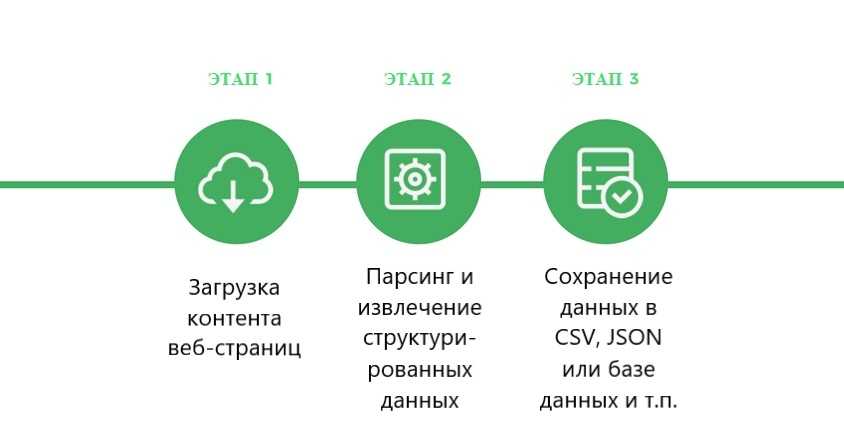
Подробнее о преимуществах автоматического сбора данных:
Единственное, что не умеет делать парсер, это уникализировать информацию — контент просто собирается из открытых источников.
Программа парсер
В роли парсера может выступить программа, сервис или скрипт. Функция у них одна — собрать данные с указанных web-сайтов, анализировать и выдать в нужном формате. Обычно используют десктопные и облачные парсеры, основное преимущество которых в отсутствии необходимости скачивать программу и устанавливать на свой комп. Вся работа производится в облаке.
Вот, например, несколько облачных парсеров на русском языке.
А это пара десктопных сервисов:
Что такое парсинг слов и зачем нужно
Парсинг также активно применяется вебмастерами и оптимизаторами для сбора семантического ядра с дальнейшей кластеризацией запросов. Таким образом, инструмент может решить вопросы с продвижением сайта и составлением рекламной кампании в Яндекс.Директе и Гугл Адс.
Среди популярных программ для парсинга в Seo:
В этапы работ над семантическим ядром сайта входит — определение поисковых фраз, анализ конкурентов, сбор данных со всех источников и т. д.
Что такое парсинг товаров и зачем нужно
Парсить товары, значит — собирать нужную информацию о продукции из готового каталога онлайн-магазинов. Обычно это делается в целях анализа ценовой политики конкурентов или для заполнения витрины своих сайтов. Ручной сбор такой информации и тщательная сортировка занимает много времени, поэтому автоматизация процесса напрашивается априори.
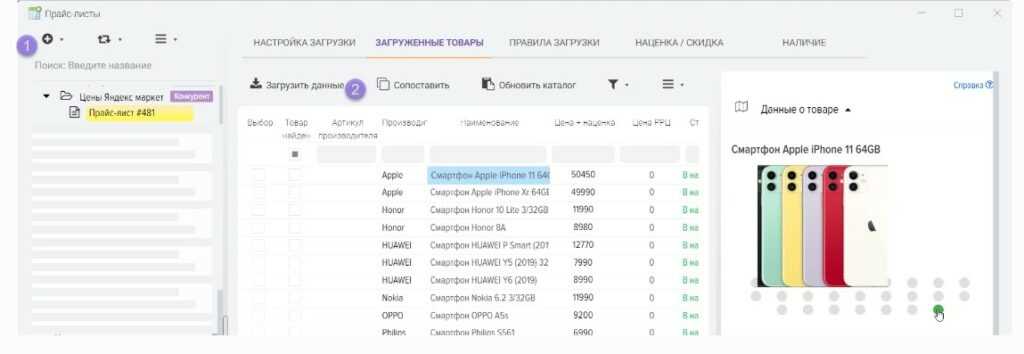
Например, парсинг товаров часто используется владельцами крупных интернет-магазинов. Это позволяет избавиться от рутинной работы, увеличить скорость сбора данных и сделать процесс более качественным.
Вот как работает парсинг:
Что такое парсинг сайтов и зачем нужно
Парсинг сайтов бывает двух типов:
Алгоритм работы простой — машинальное извлечение открытых данных. Парсер переходит по ссылкам исследуемого сайта и собирает информацию по каждой странице. Сведения записываются в Excel или какой-нибудь другой файл.
Что такое парсинг аудитории и зачем нужно
Автоматический поиск и выгрузка данных о пользователях соцсетей по конкретному алгоритму называется парсингом аудитории. Данный процесс проводится на автомате (специальными программами) или вручную (таргетологи) — целью является выгрузка собранной информации в соответствующий рекламный кабинет.
 Парсинг аудиторий из Инстаграма и Фейсбука
Парсинг аудиторий из Инстаграма и Фейсбука
Чаще всего аудиторию группы парсят по активным ее пользователям — админам, модераторам, редакторам или просто старожилам, регулярно публикующим контент. Такой метод позволяет быстро и точно подобрать ЦА под свою нишу. Это будут потенциальные покупатели, которых реально заинтересует товар или услуга. Таким образом, маркетолог сэкономит средства и время, а реклама не будет показываться всем подряд.
Парсинг по аудитории можно настроить еще точнее, используя различные критерии выбора — возраст, семейное положение, финансовый статус, хобби и интересы. В таком случае бюджет РК сократится еще больше, а вероятность покупок и целевых действий возрастет.
Что такое парсинг в программировании и зачем нужно
Принцип работы парсинга в программировании — сравнение строк или конкретных символов с готовым шаблоном, написанном на одном из языков. Другими словами, это процесс сопоставления и проверки стоковых данных, проводимый по определенным правилам. Цель — найти проблемы производительности, несоответствие кода требованиям и другие недостатки сайтов/ресурсов/приложений.
Обычно айтишники разрабатывают собственные парсеры на таких языках, как C++, Java Programing. Делается это из-за того что иногда требуемый синтаксический анализатор невозможно найти в свободном доступе.
На самом деле, парсинг в программировании не является чем-то сверх сложным. Рассмотрим, как он работает на примере разбора даты из строки.

С первого взгляда это какой-то непонятный код, но если приглядеться, то можно разобрать узнаваемые части.
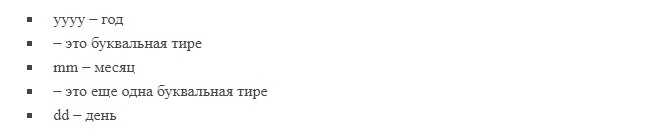
Примерно таким же способом осуществляется синтаксический анализ целого языка. Строки делятся на маленькие биты синтаксиса. Парсинг применяется не только в программировании, но также в аналитике и любой другой области, где можно работать с данными в стоковом формате.
Что такое парсинг в Инстаграм и зачем нужно
Парсинг в Инсте используют как один из инструментов для работы с ЦА — чтобы отсортировать пользователей, заинтересованных в товаре. Благодаря этому снижается рутина и экономится время.
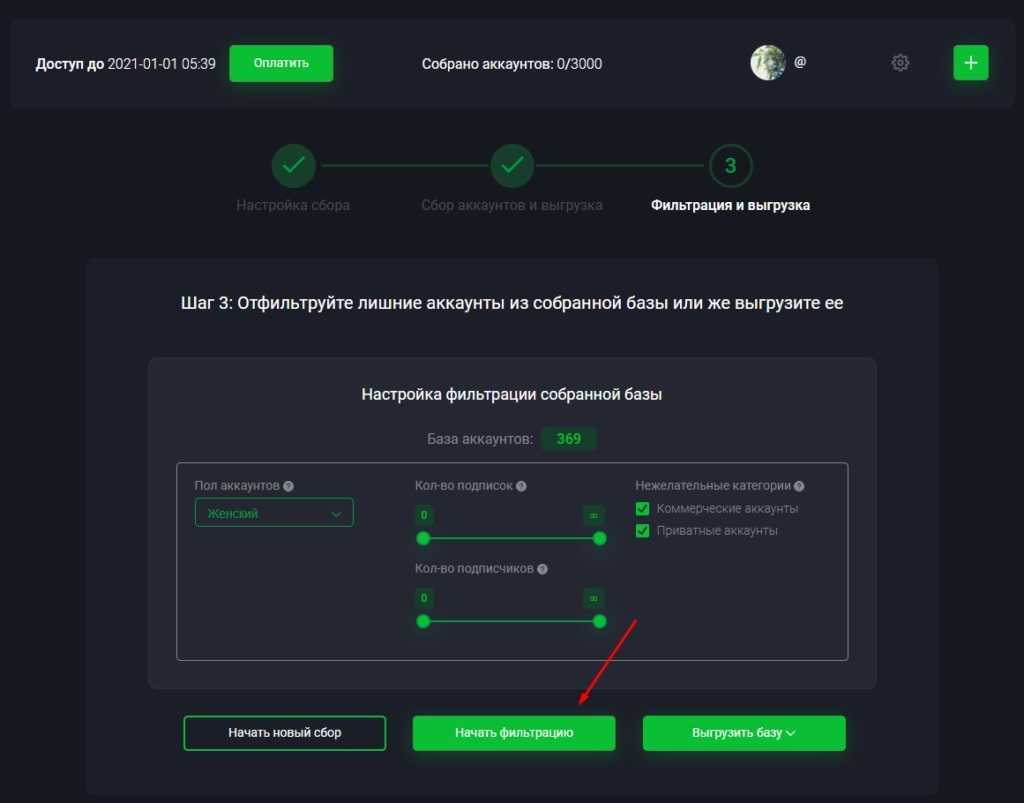
У парсинга в Instagram имеются широкие возможности анализа и мониторинга. Инструмент помогает собрать всю нужную информацию и наладить взаимодействие с пользователями. Вот что с его помощью получится сделать в Инстаграме:
Все эти функции позволят точечно запустить рекламную кампанию, настроить таргет и оформить «вкусное» коммерческое предложение.
Что такое парсинг Авито и зачем нужно
Парсинг полезен также в Авито — самой популярной доски объявлений в Рунете. С его помощью можно получить информацию обо всех постах, размещенных в определенных категориях, включая номера телефонов и адреса.
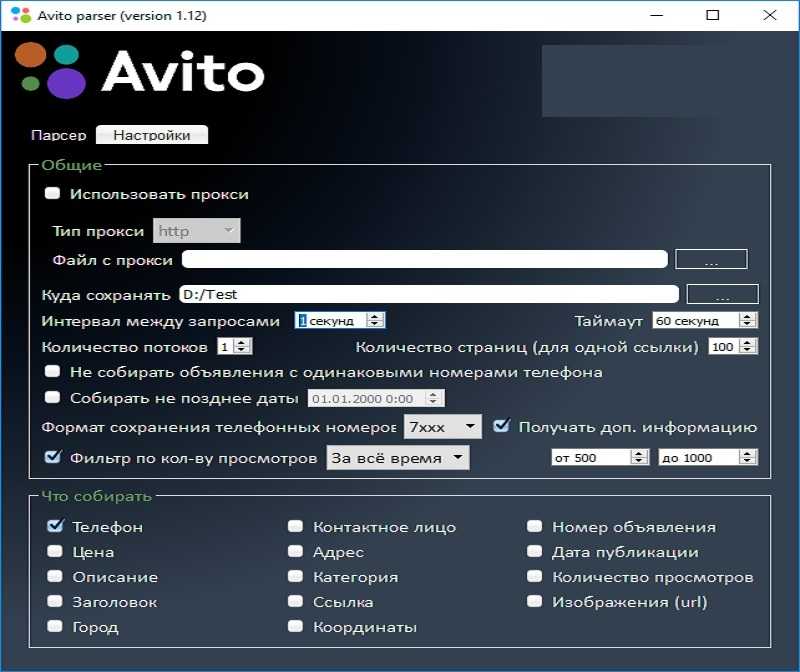
Чтобы спарсить данные с Avito, достаточно сделать так:
Инструмент соберет всю требуемую информацию в течение дня (в зависимости от объема данных) и выгрузит в документ. Обычно арбитражникам и маркетологам бывают нужны имена/контакты людей, цены на товары и изображения.
Полученные сведения можно использовать для отправки уведомлений на email, Gold calling, заполнения собственных площадок, анализа конкурентов и много чего еще. Сейчас есть возможность применять несколько парсеров для Авито — AvitoMonsterParser, FastParserAvito, Avi2-parser и другие.
Что такое парсер выдачи и зачем нужно
Парсеры для мониторинга поисковой выдачи входят в обязательный джентльменский набор опытного вебмастера, оптимизатора и маркетолога. Инструмент в этом случае настроен на сбор информации с заданного источника (Гугл, Яндекс, соцсети, форумы).
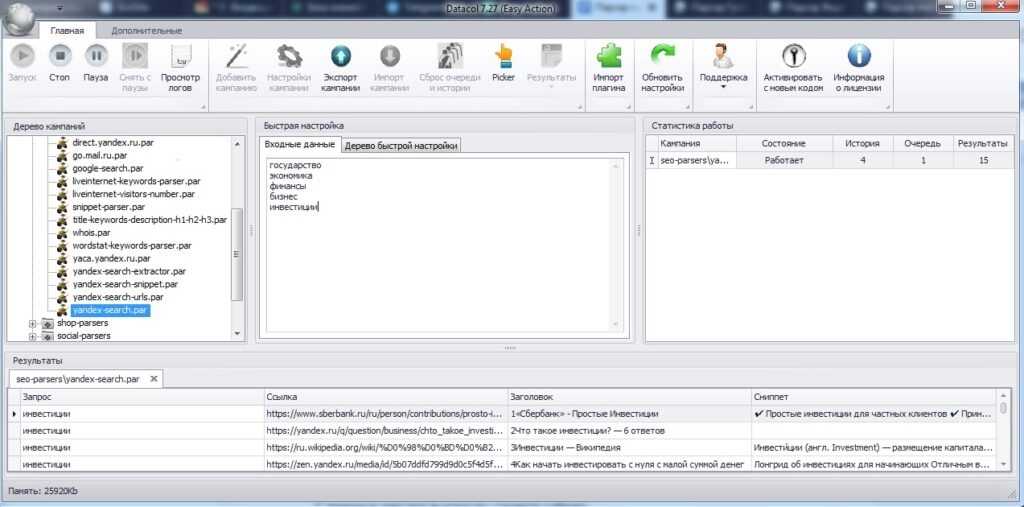 Ттак выглядит парсер на Яндекс
Ттак выглядит парсер на Яндекс
В первую очередь такой сбор данных нужен для анализа сайтов конкурентов. Парсинг даст возможность определить лидеров топа, узнать их характеристики в разрезе Seo. Например, вот какие данные чужих ресурсов:
Предоставленная информация поможет специалисту найти качественные сайты-доноры для размещения на них обратных ссылок, потенциальных клиентов/партнеров, а также площадки для рекламы.
Что такое парсинг цен и зачем нужно
Обычно ценовая «разведка», а в частности про оборот товара осложняется тем, что некоторые компании скрывают такую информацию. Напротив, такие гиганты, как Wildberries, Lamoda, Leroy Merlin ее открыто выставляют. На основе этих данных можно будет составить общее представление о продажах и сделать полезные выводы. К примеру, определить самые продаваемые позиции и сфокусироваться на них, а дешевые отсечь.

Цены можно парсить из разметки shema.org — это самый простой способ. Но если стоимость бывает зачеркнута или прайс с остатками товара загружается отдельными запросами к серверу, приходится использовать более функциональные программы. Сегодня есть такие проги, которые умеют раскрывать информацию методом эмулирования.
Кейсы по заработку на парсинге
Существует несколько способов заработка на парсинге. Но обычно заказчиков интересуют:
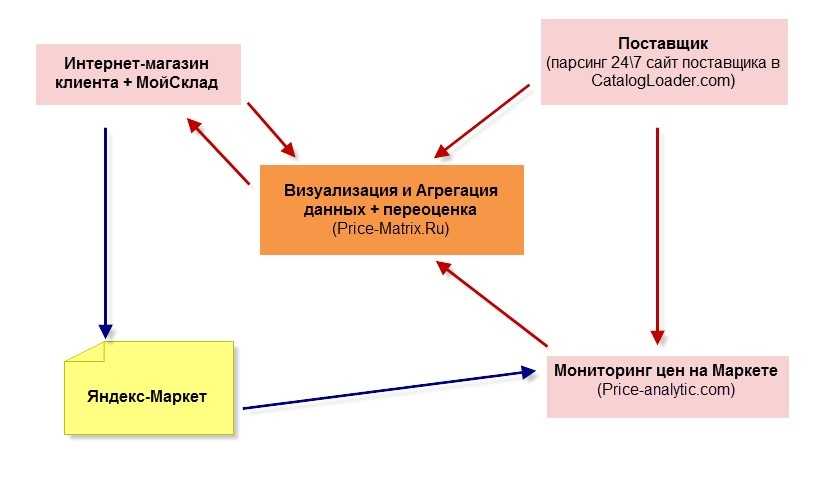
Ниже представлен интересный кейс от CatalogLoader, решивший задачи компании, закупающейся в буржунете и продающей на Яндекс.Маркете.
Что надо было сделать:
Задача решилась эффективно, клиент получил все необходимые данные. Использовался парсер сервиса CatalogLoader.com, собравший всю актуальную информацию с зарубежного интернет-магазина по нужным категориям/брендам. Сведения выгрузили в Price-Matrix.ru, где можно их анализировать и делать переоценку.
Еще один кейс, выложенный на сайте im-business. К ним обратился клиент, занимающийся грузоперевозками Россия-Беларусь. Ниша оказалась весьма конкурентной, поэтому человеку приходилось держать постоянный штат операторов и регулярно обновлять сайты с запросами на перевозку — чтобы не упустить заказы, иначе конкуренты не спят.
Задача для команды была следующая: спарсить информацию с 5 сайтов, которые постоянно мониторят заявки и отбирают их по определенным критериям. Сложность была в том, что все площадки разные — для некоторых требовалась регистрация. Пришлось в настройках прописать код для авторизации.
Дальше сделали так:
Все полученные данные сохраняли в общей таблице, каждый параметр по своим ячейкам. Заказчику давалась возможность отфильтровывать грузы, отмечать взятые в работу, а обработанные заявки выгружать для логиста.
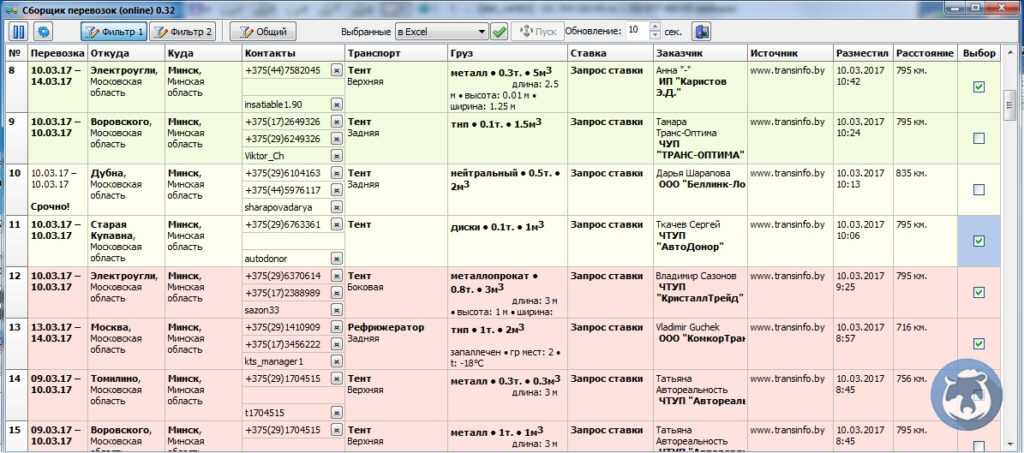
Результат — удалось сбросить значительную нагрузку с операторов фирмы, заявки стали обнаруживаться гораздо быстрее. Все это позволило опережать конкурентов и выходить в профит.
Заключение
Если у вас растущий бизнес или вы просто торгуете широко распространенными товарами, с парсингом вам придется столкнуться рано или поздно. Ничего противозаконного в нем нет, особенно при получении информации с интернет-магазинов. Здесь вы не нарушите закон о персональных данных или чьи-то авторские права
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
Парсинг или как его еще иногда называют web scraping – процесс автоматического сбора информации с различных сайтов. Форумы, новостные сайты, социальные сети, маркейтплейсы, интернет-магазины и даже поисковая выдача, вот далеко не полный список ресурсов с которых собирают контент.
И часто контент требуется собирать в больших объемах, массово, а если еще данные нужны с определенной периодичностью, то решить такую задачу руками не представляется возможным. Вот тут на помощь приходят специальные алгоритмы, которые по определенным условиям собирают информацию, структурируют и выдают в нужном виде.
Кому и зачем нужно парсить сайты?
В основном парсинг используют профессионалы для решения рабочих задач, поскольку автоматизация позволяет получить сразу большой массив данных, но также он пригодится и для решения частных задач.
Классификация программ и инструментов для парсинга
По использованию ресурсов
Это важный момент, если парсер будет использоваться для бизнес задач и регулярно, вам нужно решить на чьей стороне будет работать алгоритм, на стороне исполнителя или вашей. С одной стороны, для развертывания облачного решения у себя, потребуется специалист для установки и поддержки софта, выделенное место на сервере, и работа программы будет отъедать серверные мощности. И это дорого. С другой, если вы можете себе это позволить, возможно такое решение обойдется дешевле (если масштабы сбора данных действительно промышленные), нужно изучать тарифные сетки.
Есть еще момент с приватностью, политики некоторых компаний не позволяют хранить данные на чужих серверах и тут нужно смотреть на конкретный сервис, во-первых, собранные парсером данные могут передаваться сразу по API, во-вторых, этот момент решается дополнительным пунктом в соглашении.
По способу доступа
Удаленные решения
Сюда отнесем облачные программы (SaaS-решения), главное преимущество таких решений в том, что они установлены на удаленном сервере и не используют ресурсы вашего компьютера. Вы подключаетесь к серверу через браузер (в этом случае возможна работа с любой ОС) или приложение и берете нужные вам данные.
Облачные сервисы, как и все готовые решения в этой статье, не гарантируют, что вы сможете парсить любой сайт. Вы можете столкнуться со сложной структурой, технологией сайта, которую “не понимает” сервис, защитой, которая окажется “не по зубам” или невозможностью интерпретировать данные (например, вывод текстовых данных не текстом, а картинками).
Octoparse – один из популярных облачных сервисов.
Mozenda – популярный сервис позволяющий работать в облаке и на локальной машине, имеет интерфейс для визуального захвата данных без знания программирования.
Десктоп решения (программы для парсинга)
Такие программы устанавливаются на компьютер. Применяются для нерегулярных и нересурсоемких задач. Многие позволяют настраивать параметры сбора данных визуально.

По используемому фреймворку
Если задачи, стоящие при сборе данных нестандартные, нужно выстроить подходящую архитектуру, работать с множеством потоков, и существующие решения вас не устраивают, нужно писать свой собственный парсер. Для этого нужны ресурсы, программисты, сервера и специальный инструментарий, облегчающий написание и интеграцию парсинг программы, ну и конечно поддержка (потребуется регулярная поддержка, если изменится источник данных, нужно будет поменять код). Рассмотрим какие библиотеки существуют в настоящее время. В этом разделе не будем оценивать достоинства и недостатки решений, т.к. выбор может быть обусловлен характеристиками текущего программного обеспечения и другими особенностями окружения, что для одних будет достоинством для других – недостатком.
Парсинг сайтов Python
Библиотеки для парсинга сайтов на Python предоставляют возможность создания быстрых и эффективных программ, с последующей интеграцией по API. Важной особенностью является, что представленные ниже фреймворки имеют открытый исходный код.
Scrapy – наиболее распространенный фреймворк, имеет большое сообщество и подробную документацию, хорошо структурирован.

BeautifulSoup – предназначен для анализа HTML и XML документов, имеет документацию на русском, особенности – быстрый, автоматически распознает кодировки.

Лицензия: Creative Commons, Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0)
PySpider – мощный и быстрый, поддерживает Javascript, нет встроенной поддержки прокси.

Лицензия: Apache License, Version 2.0
Grab – особенность – асинхронный, позволяет писать парсеры с большим количеством сетевых потоков, есть документация на русском, работает по API.

Лицензия: MIT License
Lxml – простая и быстрая при анализе больших документов библиотека, позволяет работать с XML и HTML документами, преобразовывает исходную информацию в типы данных Python, хорошо документирована. Совместима с BeautifulSoup, в этом случае последняя использует Lxml как парсер.

Selenium – инструментарий для автоматизации браузеров, включает ряд библиотек для развертывания, управления браузерами, возможность записывать и воспроизводить действия пользователя. Предоставляет возможность писать сценарии на различных языках, Java, C#, JavaScript, Ruby.
Лицензия: Apache License, Version 2.0
Парсинг сайтов на JavaScript
JavaScript также предлагает готовые фреймворки для создания парсеров с удобными API.
Puppeteer — это headless Chrome API для NodeJS программистов, которые хотят детально контролировать свою работу, когда работают над парсингом. Как инструмент с открытым исходным кодом, Puppeteer можно использовать бесплатно. Он активно разрабатывается и поддерживается самой командой Google Chrome. Он имеет хорошо продуманный API и автоматически устанавливает совместимый двоичный файл Chromium в процессе установки, а это означает, что вам не нужно самостоятельно отслеживать версии браузера. Хотя это гораздо больше, чем просто библиотека для парсинга сайтов, она очень часто используется для парсинга данных, для отображения которых требуется JavaScript, она обрабатывает скрипты, таблицы стилей и шрифты, как настоящий браузер. Обратите внимание, что хотя это отличное решение для сайтов, которым для отображения данных требуется javascript, этот инструмент требует значительных ресурсов процессора и памяти.
Лицензия: Apache License, Version 2.0
Cheerio – быстрый, анализирует разметку страницы и предлагает функции для обработки полученных данных. Работает с HTML, имеет API устроенное так же, как API jQuery.

Лицензия: MIT License
Apify SDK – является библиотекой Node.js, позволяет работать с JSON, JSONL, CSV, XML,XLSX или HTML, CSS. Работает с прокси.

Лицензия: Apache License, Version 2.0
Osmosis – написан на Node.js, ищет и загружает AJAX, поддерживает селекторы CSS 3.0 и XPath 1.0, логирует URL, заполняет формы.
Лицензия: MIT License
Парсинг сайтов на Java
Java также предлагает различные библиотеки, которые можно применять для парсинга сайтов.
Jaunt – библиотека предлагает легкий headless браузер (без графического интерфейса) для парсинга и автоматизации. Позволяет взаимодействовать с REST API или веб приложениями (JSON, HTML, XHTML, XML). Заполняет формы, скачивает файлы, работает с табличными данными, поддерживает Regex.

Лицензия: Apache License (Срок действия программного обеспечения истекает ежемесячно, после чего должна быть загружена самая последняя версия)
Jsoup – библиотека для работы с HTML, предоставляет удобный API для получения URL-адресов, извлечения и обработки данных с использованием методов HTML5 DOM и селекторов CSS. Поддерживает прокси. Не поддерживает XPath.

Лицензия: MIT License
HtmlUnit – не является универсальной средой для модульного тестирования, это браузер без графического интерфейса. Моделирует HTML страницы и предоставляет API, который позволяет вызывать страницы, заполнять формы, кликать ссылки. Поддерживает JavaScript и парсинг на основе XPath.

Лицензия: Apache License, Version 2.0
CyberNeko HTML Parser – простой парсер, позволяет анализировать HTML документы и обрабатывать с помощью XPath.

Лицензия: Apache License, Version 2.0
Расширения для браузеров
Парсеры сайтов выполненные в виде расширений для браузера удобны с точки зрения использования, установка минимальная – нужен всего лишь браузер, захват данных визуальный – не требует программирования.
Scrape.it – расширение для браузера Chrome для сбора данных с сайтов с визуальным Point-Click интерфейсом.




В зависимости от решаемых задач
Мониторинг конкурентов
Сервисы для мониторинга цен позволяют отслеживать динамику цен конкурентов на те же товарные позиции, которые продаете и вы. Далее цены сравниваются и вы можете повышать или понижать стоимость в зависимости от ситуации на рынке. Это позволяет в каждый момент времени предлагать самую выгодную цену на рынке, делая покупку в вашем магазине привлекательнее чем у конкурента, и не упустить прибыль, если конкуренты по какой-то причине подняли цены.
Подобные сервисы часто адаптированы к какому-либо маркетплейсу, для того чтобы получить цены интернет-магазинов, торгующих со своего сайта, нужно настраивать сбор данных самостоятельно или заказывать настройку парсинга индивидуально.
Монетизация подобных сервисов – подписочная модель с тарифной сеткой, ранжирующей количество собираемых цен/конкурентов.
Организация совместных закупок
Подобные сервисы предназначены для организации совестных закупок в социальных сетях. Такие парсеры собирают данные о товарах выгружают их в группы ВКонтакте и Одноклассники, что позволяет автоматизировать процесс наполнения витрины и мониторить ассортимент, остатки и цены на сайтах поставщиков. Как правило, эти парсеры имеют личный кабинет с возможностью управления, настроенные интеграции для сбора данных, систему уведомлений, возможность экспортировать данные и не требуют доработки.
Монетизация – подписка с тарификацией, зависящей от количества сайтов.
Автоматизация интернет-магазинов
Такие сервисы позволяют автоматизировать загрузку товаров (картинки, описания, характеристики) от оптовика, синхронизируют цены и остатки. Это позволяет вести работу по добавлению товара и управлению ценами в полностью автоматизированном режиме и экономить на персонале. В качестве источника может выступать как xml или csv файл, так и сайт, с которого робот забирает информацию.
Парсинг SEO данных и аналитика
Парсеры применяемые для целей поисковой оптимизации помогают собирать мета данные (H1, Title, Description), ключевые слова, составлять семантическое ядро, собирать поведенческие и количественные аналитические данные о конкурентах. Спектр инструментов очень широк по функциональности, рассмотрим популярные сервисы, чтобы вы могли подобрать подходящий.
SiteAnalyzer – парсинг-программа для проверки основных технических и SEO данных сайтов. Главная особенность – программа полностью бесплатна. Работает на локальном компьютере, доступна только для ОС Windows.

Парсеры на основе таблиц
Такие парсеры собирают данные прямо в таблицы excel и google sheets. В основе действия таких парсеров лежат макросы автоматизирующие действия или специальные формулы извлекающие данные с сайтов. Подобные парсеры подходят для несложных задач, когда собираемые данные не защищены и находятся на простых, не динамичных сайтах.
ParserOk – парсинг сайтов на основе vba(макросов) в таблицы Microsoft Excel. Надстройка позволяет импортировать данные с сайтов по заранее созданным шаблонам и относительно проста в настройке. Недостатком является то, что если шаблон не соответствует вашему запросу, то потребуется доработка.
Стоимость лицензии составляет 2700 р., демо версия рассчитана на 10 дней.
Функции google sheets – importhtml и importxml – функции позволяющие импортировать данные прямо в таблицы. При помощи этих функций можно организовать несложный сбор данных по заранее запрограммированным вводным. Знание языка запросов “Xpath” существенно расширит область применения формул.
Настраиваемые решения для парсинга
Подобные сервисы работают “под ключ”, подходят к задаче индивидуально, парсинг пишется под конкретный запрос. Такие решения лучше всего подходят для частных задач бизнеса, например, когда нужно анализировать конкурентов, собирать определенные типы данных и делать это регулярно. Плюсы таких решений в том, что специально разработанное под задачу решение соберет данные даже с хорошо защищенных сайтов или данные, которые требуют интерпретации, например когда цена выводится не текстом, а в виде картинки. Программы и сервисы с самостоятельной настройкой в этих ситуациях не справятся с подобной задачей. Плюс, подобные сервисы не требуют выделять время отдельного сотрудника на сбор данных или переделку парсинга в случае изменения на сайте источнике.
Стоимость работы с индивидуально настроенным парсингом, если у вас несколько разных сайтов и необходимость регулярно получать данные будет выгодней, это не сложно проверить если посчитать стоимость готового решения + стоимость программиста для написания парсинга и его поддержки + стоимость содержания серверов.
Примеры подобных сервисов есть в начале статьи в разделе облачных парсеров, многие из них предлагают настраиваемые решения. Добавим русскоязычный сервис.
iDatica – сервис специализируется на организации парсинга, очистки данных, матчинга и визуализации данных под запрос. iDatica имеет русскоязычную поддержку, опытных специалистов и зарекомендовала себя как надежный партнер для разработки решений сбора и визуализации данных. По запросу команда выделяет аналитика для работы с вашими проектами.

iDatica – сервис специализируется на организации парсинга, очистки данных, матчинга и визуализации данных под запрос
Как правильно выбрать парсер
Для парсинга сложных сайтов с определенной регулярностью обратите внимание на облачные решения. Вам потребуется отдельный сотрудник для ведения этого проекта.
Если задача завязана на увеличение прибыли или даже жизнеспособность проекта стоит обратить внимание на облачный сервис с возможностью программировать или библиотеки для парсинга, выделить отдельного программиста для этой задачи и серверные мощности.
Если нужно получить решение быстро и нужно быть уверенным в качестве результата, стоить выбрать компанию реализующую проект под ключ.



