Кто и зачем собирает большие данные?

Осенью 2019 года разразился скандал с сервисом Apple Card: при регистрации в нем выдавались разные кредитные лимиты для мужчин и женщин. Даже Стиву Возняку не повезло:
За год до этого выяснилось, что платформа Netflix показывает пользователям разные постеры и тизеры — в зависимости от их пола, возраста и национальности. За это сервис обвинили в расизме.
Наконец, Марку Цукербергу регулярно достается за то, что Facebook якобы собирает, продает и манипулирует данными своих пользователей. В разные годы его обвиняли и даже судили за манипуляции во время американских выборов, пособничество российским спецслужбам, разжигание ненависти и радикальных взглядов, неуместную рекламу, утечку данных о пользователях, препятствия расследованиям против педофилов.
Что такое большие данные
Большие данные — они же биг дата (англ. Big Data) или метаданные — это массив данных, которые поступают регулярно и в большом объеме. Их собирают, обрабатывают и анализируют, получая на выходе четкие модели и закономерности.
Яркий пример — это данные с Большого адронного коллайдера, которые поступают непрерывно и в большом количестве. С их помощью ученые решают множество задач.
Но большие данные в сети — это не только статистика для научных исследований. По ним можно проследить, как ведут себя пользователи разных групп и национальностей, на что обращают внимание и как взаимодействуют с контентом. Иногда для этого данные собирают не из одного источника, а из нескольких, сопоставляя и выявляя определенные закономерности.

О том, насколько важны большие данные в сети заговорили тогда, когда их стало действительно много. На начало 2020 года пользователей интернета в мире насчитывалось 4,5 млрд человек, из них 3,8 млрд зарегистрированы в соцсетях.
У кого есть доступ к Big Data
По данным опросов, больше половины россиян уверены, что их данные в сети используются третьими лицами. В то же время, многие размещают в соцсетях и приложениях личную информацию, фото и даже номер телефона.
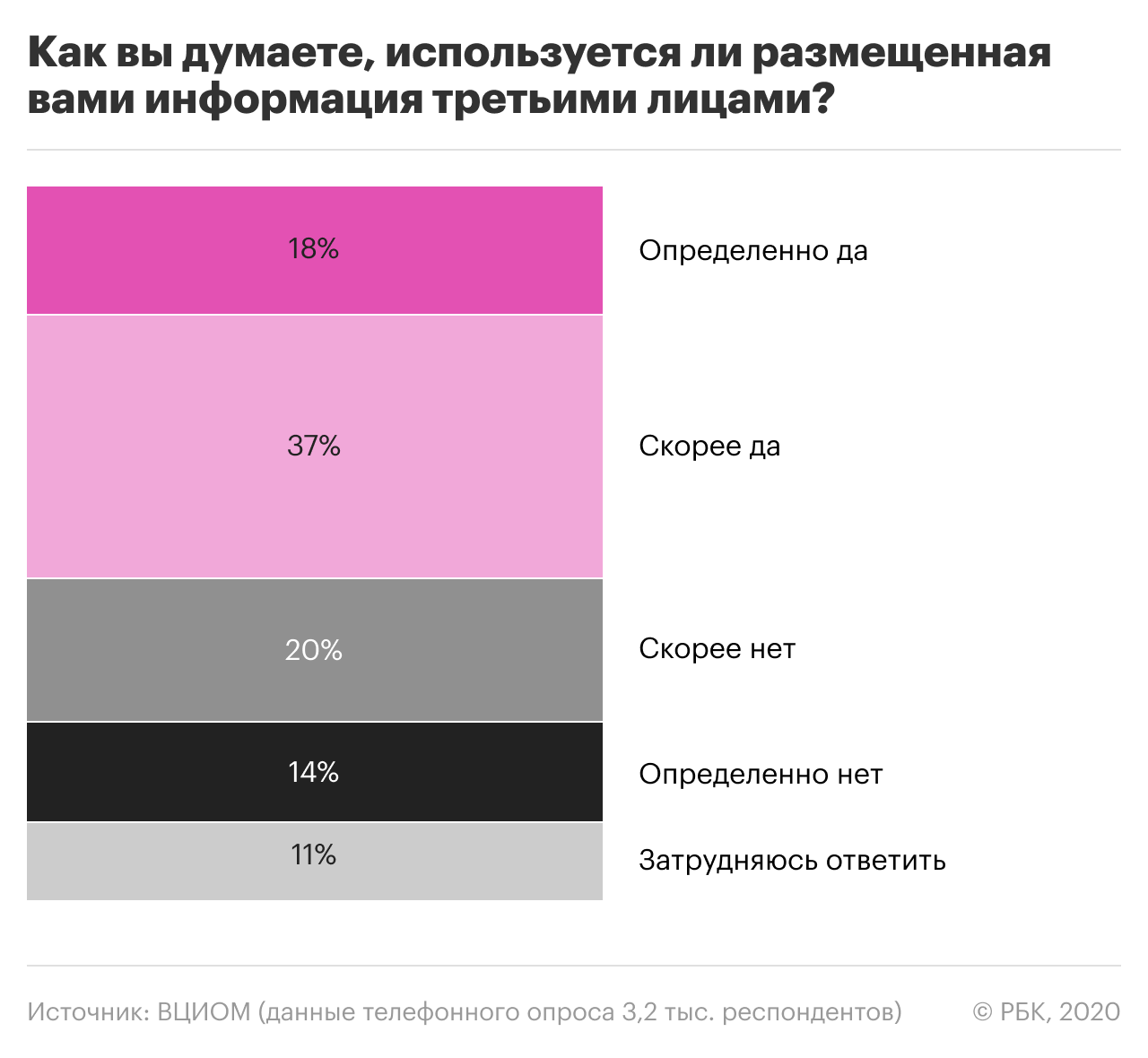
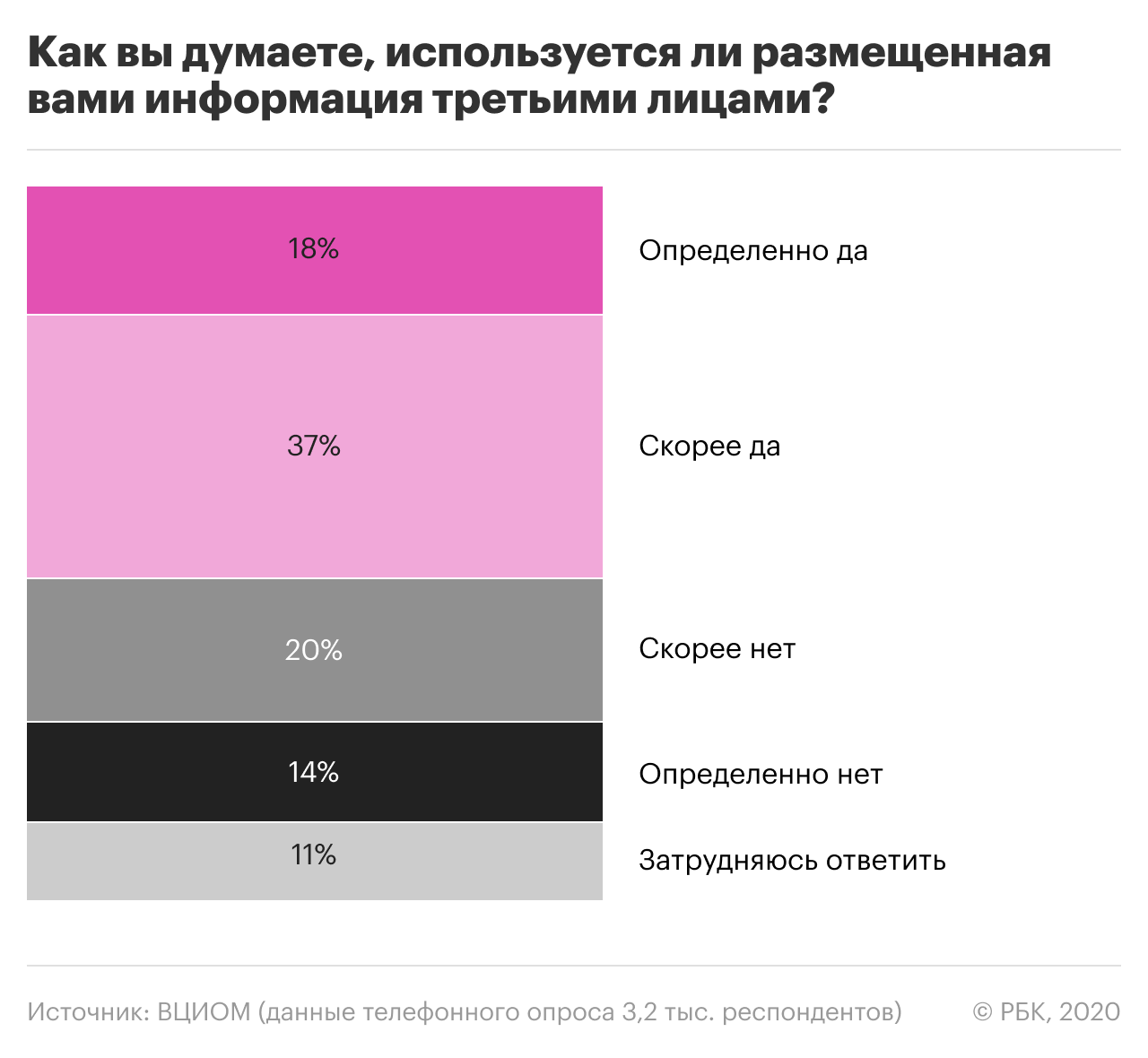
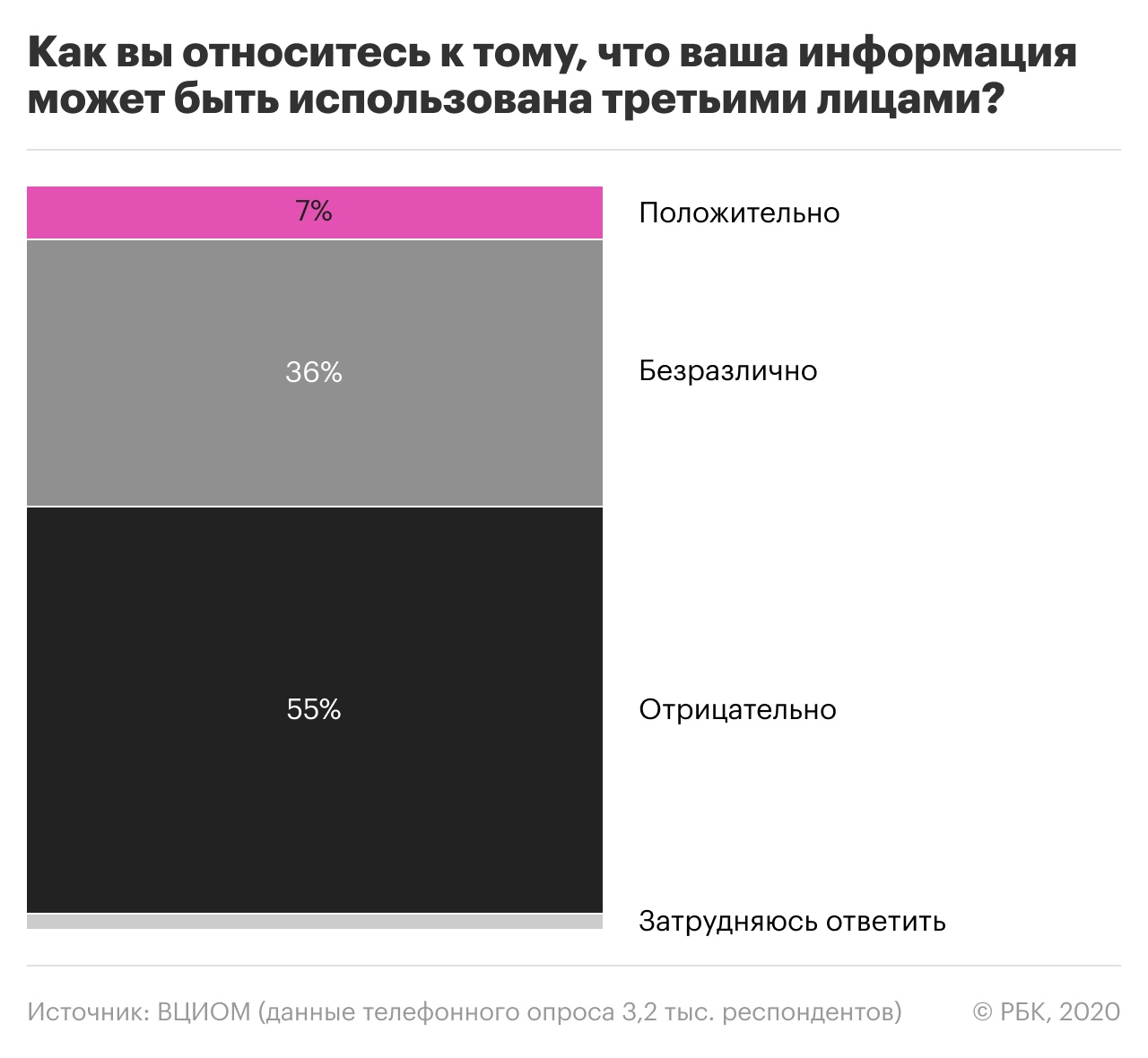
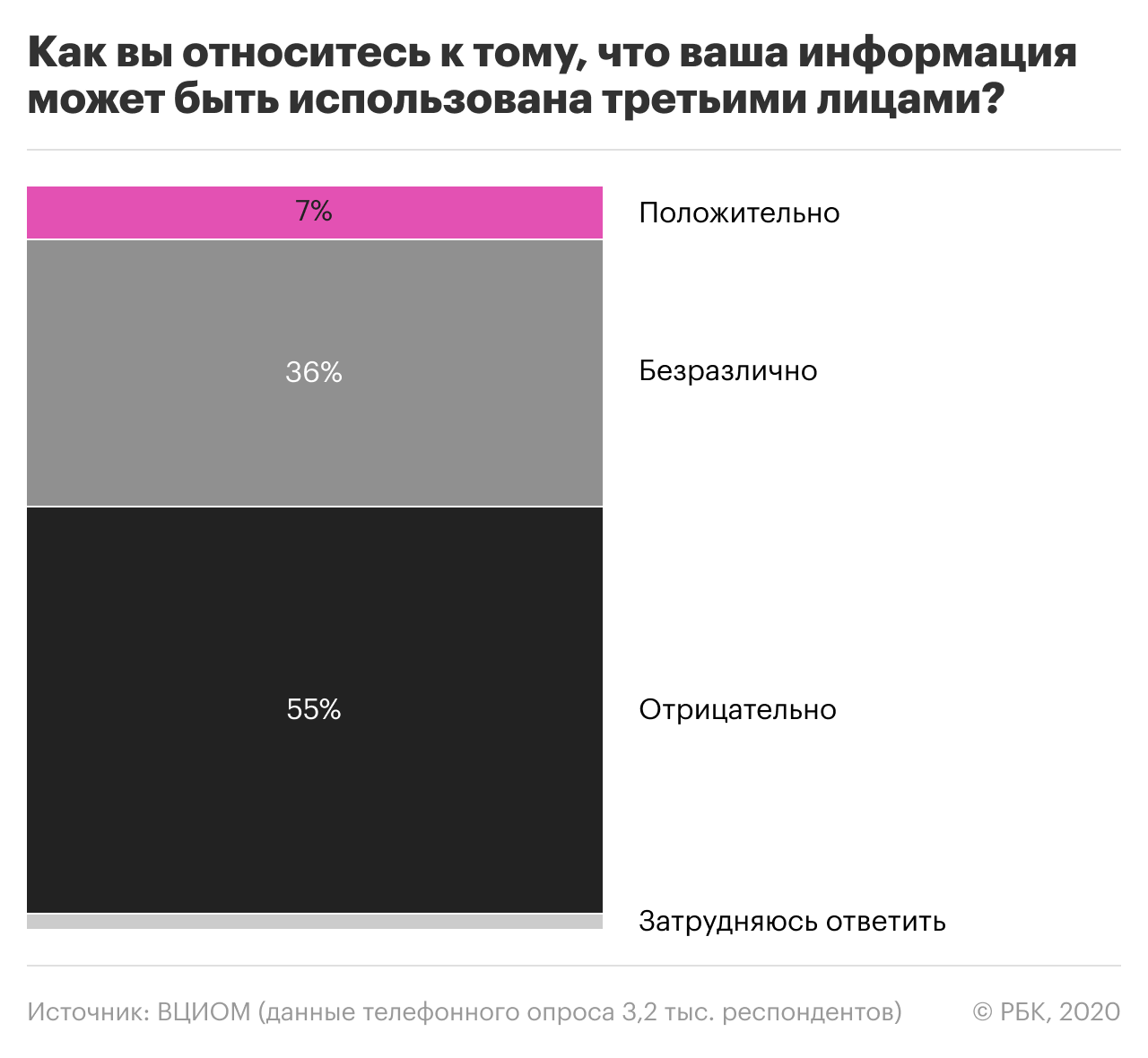
Здесь нужно пояснить: первое лицо — это сам пользователь, который размещает свои данные на каком-либо ресурсе или в приложении. При этом он дает согласие (ставит галочку в соглашении) на обработку этих данных вторым лицом — то есть владельцами ресурса. Третье лицо — это те, кому владельцы ресурса могут передать или продать данные пользователей. Часто это прописано в пользовательском соглашении, но не всегда.
В роли третьего лица выступают госорганы, хакеры или компании, которые покупают данные для коммерческих целей. Первые могут получить данные по решению суда или вышестоящей инстанции. Хакеры, понятно, никакими разрешениями не пользуются — они просто взламывают базы, хранящиеся на серверах. Компании (по закону) могут получить доступ к данным только в том случае, если вы сами им разрешили — поставив галку под соглашением. В противном случае это противозаконно.
Для чего компании используют Big Data?
Большие данные в коммерческой сфере использовали десятки лет, просто их поток не был таким интенсивным, как сейчас. Это, к примеру, записи с камер наблюдения, данные GPS-навигаторов или онлайн-платежи. Теперь, с развитием соцсетей, онлайн-сервисов и приложений все это можно связать и получить максимально полную картину: где живут потенциальные клиенты, что они любят смотреть, куда ездят в отпуск и какая у них марка машины.

Из примеров выше понятно, что с помощью больших данных компании, в первую очередь, хотят таргетировать рекламу. То есть предлагать продукты, услуги или отдельные опции только нужной аудитории и даже настраивать продукт под конкретного пользователя. К тому же, реклама в том же Facebook и на других крупных площадках становится все дороже, и показывать ее всем подряд совсем не выгодно.
Данные о потенциальных клиентах из открытых источников активно используют страховые компании, частные клиники и работодатели. Первые, к примеру, могут изменить условия страховки, если увидят, что вы часто ищете информацию по определенным заболеваниям или лекарствам, а работодатели — оценить, не склонны ли вы к конфликтам и асоциальному поведению.
Но есть и еще одна важная задача, над которой бьются в последние годы: подобраться к самой платежеспособной аудитории. Сделать это не так просто, хотя задачу заметно облегчают платежные сервисы и электронные чеки через единого ОФД (оператора фискальных данных). Чтобы подобраться как можно ближе, компании даже пытаются отследить и «воспитать» потенциальных клиентов с самого детства: через онлайн-игры, интерактивные игрушки и обучающие сервисы.
Самые большие возможности по сбору данных — у мировых корпораций, которые владеют сразу несколькими сервисами. У того же Facebook сейчас — более 2,5 млрд активных пользователей. При этом компания владеет и другими сервисами: Instagram — более 1 млрд, WhatsApp — более 2 млрд и другие.
Но еще большим влиянием обладает Google: почтой Gmail пользуется 1,5 млрд человек в мире, еще 2,5 млрд — мобильной ОС Android, больше 2 млрд — YouTube. И это не считая приложений Google-поиска и Google Maps, магазина Google Play и браузера Chrome. Осталось прикрутить свой онлайн-банк — и Google сможет знать о вас буквально все. Кстати, Яндекс в этом плане уже на шаг впереди, но он охватывает только русскоязычную аудиторию.
👍 В первую очередь компании интересует, что мы постим и лайкаем в соцсетях. К примеру, если банк видит, что вы женаты и активно лайкаете девушек в Instagram или Tinder, потребительский кредит вам, скорее, одобрят. А ипотеку на семью — уже нет.
Важно и то, на какую рекламу вы кликаете, как часто и с каким результатом.
📥 Cледующий шаг — это личные сообщения: в них информации гораздо больше. Утечки сообщений случались у ВКонтакте, Facebook, WhatsApp и других мессенджеров. По ним, к слову, легко отследить и геолокацию в момент отправки сообщения. Наверняка вы замечали: стоит с кем-то обсудить покупку чего-либо или просто заказ пиццы — в ленте тут же появляется релевантная реклама.
🚕 Большие данные активно используют и «сливают» сервисы доставки и такси. Они знают, где вы живете и работаете, что любите, какой у вас примерный доход. Uber, к примеру показывает цену выше, если вы едете из бара домой и явно перебрали. А когда у вас на телефоне куча других агрегаторов — наоборот, предложит подешевле.
🎞 Есть сервисы, которые используют фото и видео, чтобы собрать как можно больше информации. Например, библиотеки компьютерного зрения — такая есть у Google. Они сканируют вас и окружающее пространство, чтобы понять, какой у вас размер груди или рост, какие марки вы носите, на какой машине ездите, есть ли у вас дети и домашние животные.
💳 Те, кто предоставляет смс-шлюзы банкам для их рассылок, могут отследить ваши покупки по карте — зная 4 последние цифры и номер телефона — а потом продать эти данные кому-то еще. Отсюда весь этот спам со скидками и пиццей в подарок.
🤷♂️ Наконец, мы сами сливаем свои данные левым сервисам и приложениям. Вспомните этот хайп вокруг Getcontact, когда все радостно забивали свой номер телефона, чтобы узнать, как он записан у других. А теперь найдите их соглашение и почитайте, что там написано насчет передачи ваших данных (спойлер: владельцы могут передавать их третьим лицам на их усмотрение):
Корпорации могут годами успешно собирать и даже продавать данные пользователей, пока не дойдет до судебного иска — как это случилось с тем же Facebook. И то решающую роль сыграло нарушение компанией GDPR — закона в ЕС, который ограничивает использование данных гораздо жестче, чем американский. Еще один недавний пример — скандал с антивирусом Avast: один из дочерних сервисов компании собирал и продавал данные от 100 до 400 млн пользователей.
Но есть ли у всего этого хоть какие-то плюсы для нас?
Как большие данные помогают всем нам?
Да, есть и светлая сторона.
Большие данные помогают ловить преступников и предупреждать теракты, находить пропавших детей и защищать их от опасности.
С их помощью мы получаем крутые предложения от банков и персональные скидки. Благодаря им мы не платим за многие сервисы и соцсети, которые зарабатывают только на рекламе. Иначе один только Instagram обходился бы нам в несколько тысяч долларов в месяц.
Наконец, иногда это просто удобно: когда сервисы уже знают, где вы и что хотите, и вам не приходится самим искать нужную информацию.
Еще одна перспективная сфера для применения Big Data — образование.
В одном из американских вузов штата Вирджиния провели исследование, чтобы собрать данные о студентах так называемой группы риска. Это те, которые плохо учатся, пропускают занятия и вот-вот отчислятся. Дело в том, что в штатах каждый год отчисляются около 400 000 человек. Это плохо и для вузов, которым снижают рейтинг и урезают финансирование, и для самих студентов: многие берут кредиты на образование, которые после отчисления все равно придется выплачивать. Не говоря уже о потерянном времени и карьерных перспективах. С помощью больших данных можно вовремя вычислить отстающих и предложить им репетитора, дополнительные занятия и другую адресную помощь.
Такое, кстати, подойдет и для школ: тогда система будет оповещать учителей и родителей — мол, у ребенка проблемы, давайте вместе ему поможем. А еще Big Data поможет понять, какие учебники работают лучше и кто из учителей доступнее объясняет материал.
Еще один положительный пример — карьерное профилирование: это когда подросткам помогают определиться с будущей профессией. Здесь большие данные позволяют собрать ту информацию, которую невозможно добыть с помощью традиционных тестов: как ведет себя пользователь, на что обращает внимание, как взаимодействует с контентом.
В тех же США работает программа по профориентации — SC ACCELERATE. В ней, в том числе, используют технологию CareerChoice GPS: анализируют данные о характере учащихся, их склонностях к предметам, сильные и слабые стороны. Затем данные используют, чтобы помочь подросткам выбрать подходящие для них вузы.
Подписывайтесь и читайте нас в Яндекс.Дзене — технологии, инновации, эко-номика, образование и шеринг в одном канале.
Что такое Big Data и почему их называют «новой нефтью»

Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений.
Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и ИТ-специальностям. Затем к сбору и анализу подключились ИТ-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Какие есть характеристики Big Data?
Компания Meta Group предложила основные характеристики больших данных [2]:
Сегодня к этим трем добавляют еще три признака [3]:
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
В каких отраслях уже используют Big Data?
Павел Иванченко, руководитель по IoT «МегаФона»:
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения».
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
Каковы проблемы и перспективы Big Data?
Главные проблемы:
Плюсы и перспективы:
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
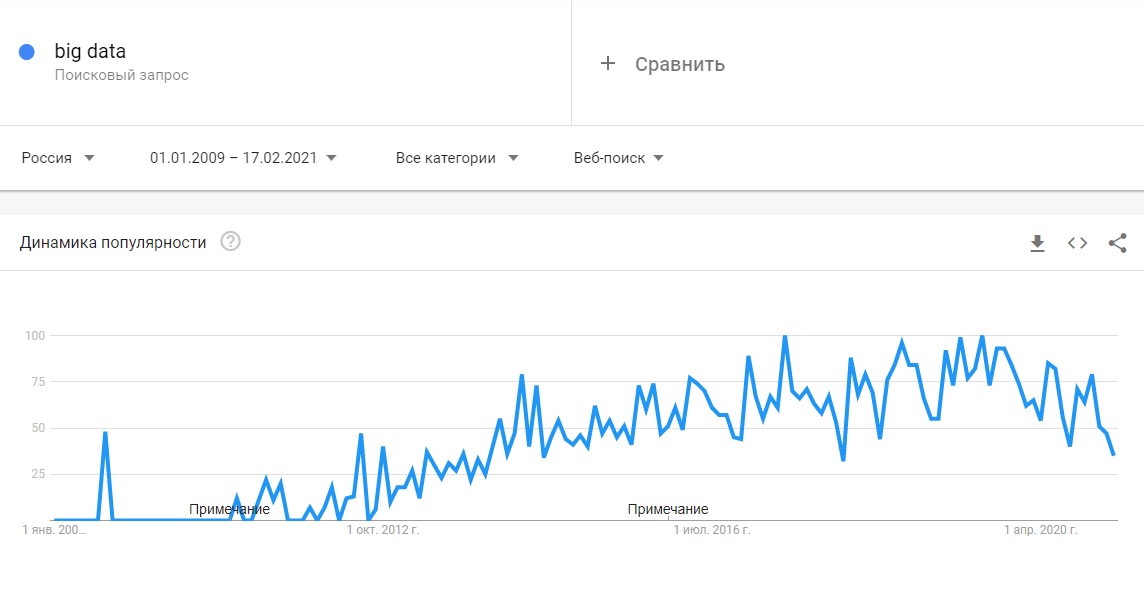
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.