Наиболее часто встраивающаяся варианта
В статистике модой называется величина признака (варианта), которая чаще всего встречается в данной совокупности.
Медианой в статистике называется варианта, которая находится в середине вариационного ряда. Медиана делит ряд пополам. Обозначают медиану символом.
Распределительные средние – мода и медиана, их сущность и способы исчисления.
Данные показатели относятся к группе распределительных средних и используются для формирования обобщающей характеристики величины варьирующего признака.
Мода  – это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:
– это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:

 — частота модального интервала;
— частота модального интервала;

Для определения медианы в дискретном ряду при наличии частот, сначала исчисляется полусумма частот, а затем определяется какое значение варьирующего признака ей соответствует. При исчислении медианы интервального ряда сначала определяются медианы интервалов, а затем определяется какое значение варьирующего признака соответствует данной частоте. Для определения величины медианы используется формула:

 — частота медианного интервала;
— частота медианного интервала;
Медианный интервал не обязательно совпадает с модальным.
Моду и медиану в интервальном ряду распределения можно определить графически. Мода определяется по гистограмме распределения. Для этого выбирается самый высокий прямоугольник, который в данном случае является модальным. Затем правую вершину модального прямоугольника соединяют с правым верхним углом предыдущего прямоугольника. А левую вершину модального прямоугольника – с левым верхним углом последующего прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось абсцисс.
Элементы статистики
Продолжаем изучать элементарные задачи по математике. Сегодня мы поговорим о статистике.
Статистика — это раздел математики в котором изучаются вопросы сбора, измерения и анализа информации, представленной в числовой форме. Происходит слово статистика от латинского слова status (состояние или положение дел).
Так, с помощью статистики мы можем узнать свое положение дел, касающихся финансов. С начала месяца можно вести дневник расходов и по окончании месяца, воспользовавшись статистикой, узнать сколько денег в среднем мы тратили каждый день или какая потраченная сумма была наибольшей в этом месяце либо узнать какую сумму мы тратили наиболее часто.
На основе этой информации можно провести анализ и сделать определенные выводы: следует ли в следующем месяце немного сбавить аппетит, чтобы тратить меньше денег, либо наоборот позволить себе не только хлеб с водой, но и колбасу.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
Элементы выборки обозначаются с помощью переменных с индексами 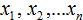 . Последний
. Последний 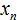 элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.
элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные
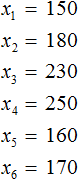
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
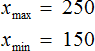
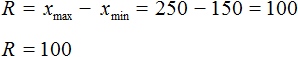
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.
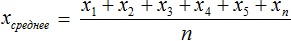
Вернемся к нашему примеру
Узнаем сколько в среднем мы тратили в каждом из шести дней:
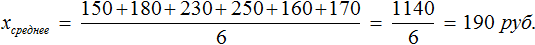
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
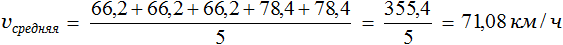
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
Сложим эти расстояния и результат разделим на 5
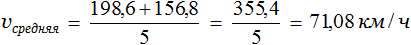
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
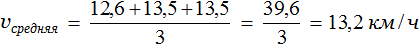
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
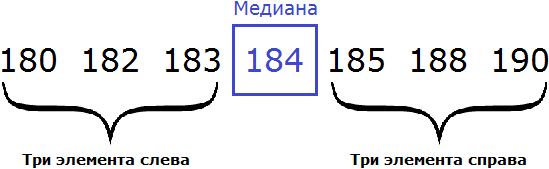
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
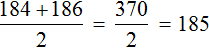
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
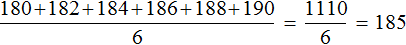
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
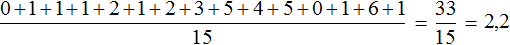
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
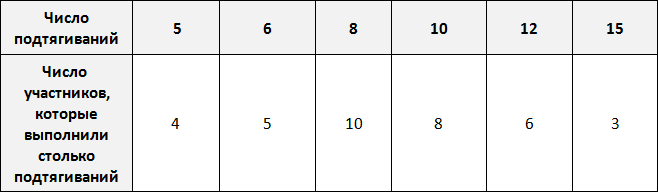
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок?
Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Возникло желание поддержать проект?
Используй кнопку ниже
42 thoughts on “Элементы статистики”
Спасибо, что вы вернулись.
Будут ли новые уроки?
4. Мода. Медиана. Генеральная и выборочная средняя
Мода на экране, медиана в треугольнике, а средние – это температура по больнице и в палате. Продолжаем наш практический курс занимательной статистики (Занятие 1) изучением центральных характеристик статистической совокупности, названия которых вы видите в заголовке. И начнём мы с его конца, поскольку о средних величинах речь зашла практически с первых же абзацев темы. Для подготовленных читателей оглавление:
ну а «чайникам» лучше ознакомиться с материалом по порядку:
Итак, пусть исследуется некоторая генеральная совокупность объёма 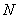 , а именно её числовая характеристика
, а именно её числовая характеристика 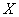 , не важно, дискретная или непрерывная (Занятия 2, 3).
, не важно, дискретная или непрерывная (Занятия 2, 3).
Генеральной средней называется среднее арифметическое всех значений этой совокупности: 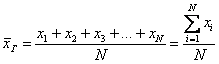
Если среди чисел 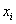 есть одинаковые (что характерно для дискретного ряда), то формулу можно записать в более компактном виде:
есть одинаковые (что характерно для дискретного ряда), то формулу можно записать в более компактном виде: 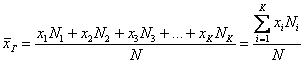 , где
, где
варианта 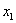 повторяется
повторяется 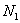 раз;
раз;
варианта 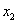 –
– 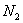 раз;
раз;
варианта 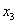 –
– 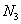 раз;
раз;
…
варианта 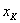 –
– 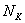 раз.
раз.
Живой пример вычисления генеральной средней встретился в Примере 2, но чтобы не занудничать, я даже не буду напоминать его содержание.
Далее. Как мы помним, обработка всей генеральной совокупности часто затруднена либо невозможна, и поэтому из неё организуют представительную выборку объема 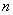 , и на основании исследования этой выборки делают вывод обо всей совокупности.
, и на основании исследования этой выборки делают вывод обо всей совокупности.
Выборочной средней называется среднее арифметическое всех значений выборки: 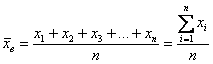
и при наличии одинаковых вариант формула запишется компактнее:
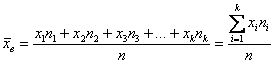 – как сумма произведений вариант
– как сумма произведений вариант 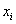 на соответствующие частоты
на соответствующие частоты 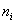 .
.
Выборочная средняя 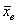 позволяет достаточно точно оценить истинное значение
позволяет достаточно точно оценить истинное значение 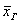 , чего вполне достаточно для многих исследований. При этом, чем больше выборка, тем точнее будет эта оценка.
, чего вполне достаточно для многих исследований. При этом, чем больше выборка, тем точнее будет эта оценка.
Практику начнём, а точнее продолжим, с дискретного вариационного ряда и знакомого условия:
По результатам выборочного исследования 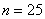 рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
Это числа из Примера 4 (см. по ссылке выше), но теперь нам требуется: вычислить выборочную среднюю, и, не отходя от станка, найти моду и медиану.
Как решать задачу? Если нам даны первичные данные (исходные необработанные значения), то их можно тупо просуммировать и разделить результат на объём выборки:
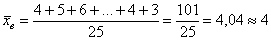 – среднестатистический квалификационный разряд рабочих цеха.
– среднестатистический квалификационный разряд рабочих цеха.
Но во многих задачах требуется составить вариационный ряд (см. Пример 4): 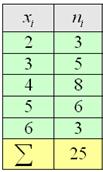
– или же этот ряд предложен изначально (что бывает чаще). И тогда, мы, конечно, используем «цивилизованную» формулу: 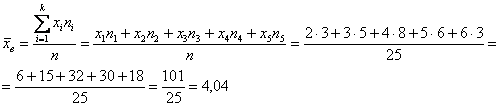
Далее. Мода и медиана. Эти понятия тоже вводятся как для генеральной, так и для выборочной совокупности, и определения я сформулирую в общем виде.
Мода. Мода 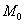 дискретного вариационного ряда – это варианта с максимальной частотой. В данном случае
дискретного вариационного ряда – это варианта с максимальной частотой. В данном случае 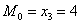 . Моду легко отыскать по таблице, и ещё легче на полигоне частот – это абсцисса самой высокой точки:
. Моду легко отыскать по таблице, и ещё легче на полигоне частот – это абсцисса самой высокой точки: 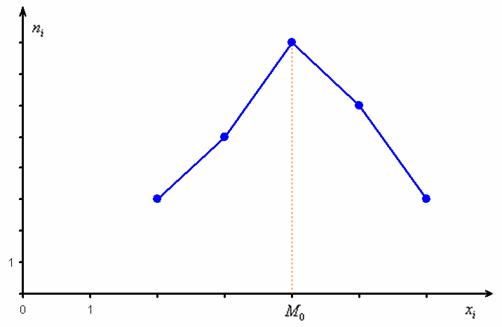
Иногда таковых значений несколько (с одинаковой максимальной частотой), и тогда модой считают каждое из них.
Если все или почти все варианты различны (что характерно для интервального ряда), то модальное значение определяется несколько другим способом, о котором во 2-й части урока.
Медиана. Медиана 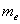 вариационного ряда* – это значение, которая делит его на две равные части (по количеству вариант).
вариационного ряда* – это значение, которая делит его на две равные части (по количеству вариант).
* не важно, дискретного или интервального, генеральной совокупности или выборочной.
Медиану можно отыскать несколькими способами.
Если даны первичные данные, то сортируем их по возрастанию либо убыванию (см. Задание 1) и находим середину ранжированного ряда: 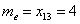 . Почему именно 13-е число? Потому что перед ним находится 12 чисел и после него тоже 12 чисел, таким образом, значение
. Почему именно 13-е число? Потому что перед ним находится 12 чисел и после него тоже 12 чисел, таким образом, значение 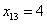 разделило ряд на две равные части, а значит, является медианой. Этот номер можно найти аналитически:
разделило ряд на две равные части, а значит, является медианой. Этот номер можно найти аналитически:
– если совокупность содержит нечётное количество чисел (наш случай), то делим её объём пополам: 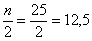 и округляем полученное значение в бОльшую сторону: 13 – получая тем самым срединный номер.
и округляем полученное значение в бОльшую сторону: 13 – получая тем самым срединный номер.
– если совокупность содержит чётное количество чисел, например, 20, то делаем то же самое: 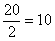 , и медианное значение здесь рассчитывается как среднее арифметическое 10-го и следующего числа:
, и медианное значение здесь рассчитывается как среднее арифметическое 10-го и следующего числа: 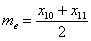 .
.
Напоминаю, что изложенная инструкция работает для упорядоченного (по возрастанию либо убыванию) ряда. Но есть и более быстрый путь, где ничего не нужно сортировать. Это использование стандартной функции Экселя:
– забиваем в любую свободную ячейку =МЕДИАНА(, выделяем мышью все числа, закрываем скобку ) и жмём Enter. Попробуйте самостоятельно. Этот способ удобен, когда вам дано много значений.
Следует отметить, что в Экселе существуют и отдельные функции для вычисления средней (=СРЗНАЧ), моды (=МОДА) и ещё много чего, но я против использования этих функций в учебном курсе, за исключением случаев, где это действительно целесообразно. …Почему против? Потому что они не помогают понять суть показателей и, более того, отупляют. Так, среднюю гораздо вразумительнее рассчитывать следующим образом:
=СУММ(выделяем мышью диапазон) / объем совокупности. Вычисления рекомендую опробовать лично (ссылка выше).
Ситуация вторая. Когда составлен либо изначально дан готовый дискретный ряд. Тут можно поступить «по любительски» – начать отсчитывать примерно равное количество чисел по краям ряда: 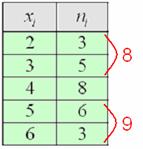
после чего мысленно либо на черновике их отбрасывать, в данном случае отбросим по 8 штук сверху и снизу: 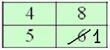
откуда становится ясно, что медианное значение: 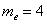
Второй способ более академичен, находим относительные накопленные частоты: 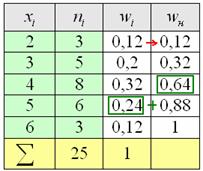
и то значение «икса», у которого 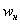 «переваливает» за отметку 0,5 (50% упорядоченной совокупности). Для 3-го разряда успело накопиться
«переваливает» за отметку 0,5 (50% упорядоченной совокупности). Для 3-го разряда успело накопиться 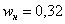 (32% совокупности), а вот для 4-го – уже
(32% совокупности), а вот для 4-го – уже 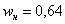 (64%). Таким образом, отметка в 50% пройдена именно здесь, и, стало быть, .
(64%). Таким образом, отметка в 50% пройдена именно здесь, и, стало быть, .
Запишем красивый ответ: 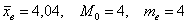
Полученные значения близки друг к другу, и это говорит о симметрии вариационного ряда относительно центра, что хорошо видно по полигону частот (см. чертёж выше). И с высокой вероятностью можно утверждать, что примерно так же распределена и вся генеральная совокупность (все рабочие цеха).
И тут возникает следующий закономерный вопрос: а зачем вообще нужна мода с медианой? – ведь есть средняя.
А дело в том, что в ряде случаев среднее значение неудовлетворительно характеризует центральную тенденцию статистической совокупности:
Известны результаты продаж пиджаков в универмаге города: 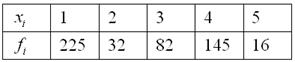
где, 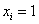 – количество пуговиц на пиджаке,
– количество пуговиц на пиджаке, 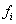 – число продаж, буква «эф» – это тоже достаточно популярная буква для обозначения частот, и она не должна вас смущать при встрече.
– число продаж, буква «эф» – это тоже достаточно популярная буква для обозначения частот, и она не должна вас смущать при встрече.
…ну, а если вам не нравятся пиджаки, то представьте какие-нибудь шляпки с цветочками 🙂
Также обратим внимание, что в условии задачи ничего не сказано о том, генеральная ли это совокупность или выборочная, и в подобной ситуации я не рекомендую ничего додумывать – среднюю просто обозначаем через 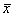 , без подстрочного индекса.
, без подстрочного индекса.
Вычислить среднюю – в экселевском файле уже забиты исходные данные и приведена краткая инструкция. Если под пальцами нет Экселя, то считаем на калькуляторе. Не ленимся! – заданий я предлагаю немного (у вас своих хватает :)), но прорешать их очень важно! Краткое решение для сверки в конце урока.
…какие мысли на счёт полученного значения 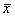 ? С такой статистикой магазин разорится.
? С такой статистикой магазин разорится.
И, конечно, важнейший показатель здесь мода: 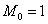 . Потому что такая мода 🙂 Более того, в прикладных исследованиях рассматривают несколько модальных значений (вроде даже в Экселе функция есть), в частности, ещё одной модой можно считать варианту
. Потому что такая мода 🙂 Более того, в прикладных исследованиях рассматривают несколько модальных значений (вроде даже в Экселе функция есть), в частности, ещё одной модой можно считать варианту 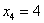 . Но это уже попсовая статистика, которую я не буду развивать в этом курсе.
. Но это уже попсовая статистика, которую я не буду развивать в этом курсе.
Ещё хуже (в содержательном плане) ситуация с медианой – продолжаем решать задачу в Экселе (ссылка выше) либо в тетради! Особо зоркие читатели медиану углядят и устно, и в конце урока я привёл способ, который просто бросился мне в глаза.
Теперь надеваем пиджаки / шляпы и возвращаемся на фабрику, где бухгалтер Петрова вычислила генеральную среднюю заработную плату рабочих: 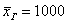 денежных единиц. Здесь мы плавно перешли к интервальному ряду, который целесообразно составлять для «денежных» показателей.
денежных единиц. Здесь мы плавно перешли к интервальному ряду, который целесообразно составлять для «денежных» показателей.
Что будет, если к совокупности добавить руководящий персонал и директора Петрова? Средняя зарплата немного увеличится: 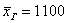 , и это уже будет несколько искажённая картина.
, и это уже будет несколько искажённая картина.
А вот если сюда добавить олигарха Петровского, то полученная средняя 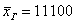 не только дезинформирует, но и вызовет широкое возмущение общественности.
не только дезинформирует, но и вызовет широкое возмущение общественности.
Поэтому, если в статистической совокупности есть «аномальные» отклонения в ту или иную сторону, то в качестве оценки центрального значения как нельзя лучше подходит медиана, которая в нашем условном примере будет равна, скажем, 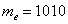 . Ниже этой планки зарабатывает ровно половина совокупности и выше – другая половина, включая Петрова и Петровского. …Главное только, чтобы они наняли правильного статистика 🙂
. Ниже этой планки зарабатывает ровно половина совокупности и выше – другая половина, включая Петрова и Петровского. …Главное только, чтобы они наняли правильного статистика 🙂
Как вычислить моду, медиану и среднюю интервального ряда?
Начнём опять с ситуации, когда нам даны первичные статические данные:
По результатам выборочного исследования цен на ботинки в магазинах города получены следующие данные (ден. ед.): 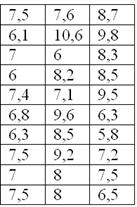
– это в точности числа из Примера 6 статьи об интервальном вариационном ряде.
Но теперь нам нужно найти среднюю, моду и медиану.
Решение: чтобы найти среднюю по первичным данным, лучше всего просуммировать все варианты и разделить полученный результат на объём совокупности:
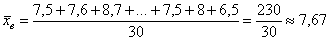 ден. ед.
ден. ед.
Эти подсчёты, кстати, займут не так много времени и при использовании оффлайн калькулятора. Но если есть Эксель, то, конечно, забиваем в любую свободную ячейку =СУММ(, выделяем мышкой все числа, закрываем скобку ), ставим знак деления /, вводим число 30 и жмём Enter. Готово.
Что касается моды, то её оценка по исходным данным, становится непригодна. Хоть мы и видим среди чисел одинаковые, но среди них запросто может найтись пять так шесть-семь вариант с одинаковой максимальной частотой, например, частотой 2. Кроме того, цены могут быть округлёнными. Поэтому модальное значение рассчитывается по сформированному интервальному ряду (о чём чуть позже).
Чего не скажешь о медиане: забиваем в Эксель =МЕДИАНА(, выделяем мышью все числа, закрываем скобку ) и жмём Enter: 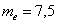 . Причём, здесь даже ничего не нужно сортировать.
. Причём, здесь даже ничего не нужно сортировать.
Но в Примере 6 была проведена сортировка по возрастанию (вспоминаем и сортируем – ссылка выше), и это хорошая возможность повторить формальный алгоритм отыскания медианы. Делим объём выборки пополам:
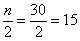 , и поскольку она состоит из чётного количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного ряда:
, и поскольку она состоит из чётного количества вариант, то медиана равна среднему арифметическому 15-й и 16-й варианты упорядоченного (!) вариационного ряда:
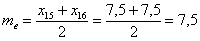 ден. ед.
ден. ед.
Ситуация вторая. Когда дан готовый интервальный ряд (типичная учебная задача).
Продолжаем анализировать тот же пример с ботинками, где по исходным данным был составлен ИВР. Для вычисления средней потребуются середины 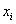 интервалов:
интервалов: 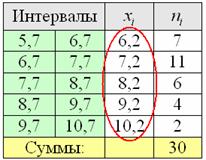
– чтобы воспользоваться знакомой формулой дискретного случая: 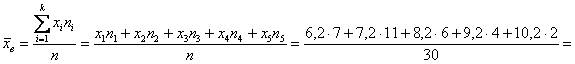
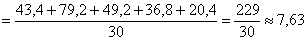 – отличный результат! Расхождение с более точным значением (
– отличный результат! Расхождение с более точным значением (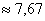 ), вычисленным по первичным данным, составляет всего 0,04.
), вычисленным по первичным данным, составляет всего 0,04.
По сути дела, здесь мы приблизили интервальный ряд дискретным, и это приближение оказалось весьма эффективным. Впрочем, особой выгоды тут нет, т.к. при современном программном обеспечении не составляет труда вычислить точное значение даже по очень большому массиву первичных данных. Но это при условии, что они нам известны 🙂
С другими центральными показателями всё занятнее.
Чтобы найти моду, нужно найти модальный интервал (с максимальной частотой) – в данной задаче это интервал 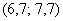 с частотой 11, и воспользоваться следующей страшненькой формулой:
с частотой 11, и воспользоваться следующей страшненькой формулой: 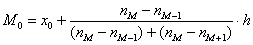 , где:
, где:
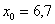 – нижняя граница модального интервала;
– нижняя граница модального интервала;
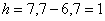 – длина модального интервала;
– длина модального интервала;
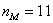 – частота модального интервала;
– частота модального интервала;
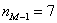 – частота предыдущего интервала;
– частота предыдущего интервала;
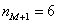 – частота следующего интервала.
– частота следующего интервала.
Таким образом:
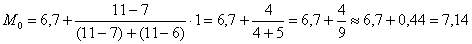 ден. ед. – как видите, «модная» цена на ботинки заметно отличается от средней арифметической
ден. ед. – как видите, «модная» цена на ботинки заметно отличается от средней арифметической 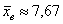 .
.
Не вдаваясь в геометрию формулы, просто приведу гистограмму относительных частот и отмечу  :
: 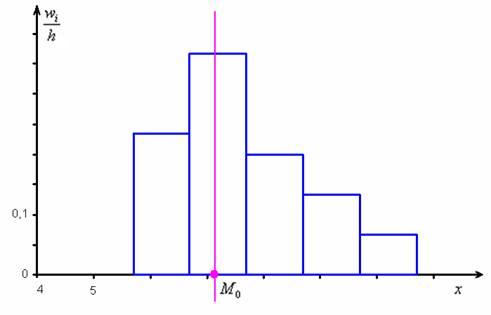
откуда хорошо видно, что мода смещена относительно центра модального интервала в сторону левого интервала с бОльшей частотой. Логично.
Справочно разберу редкие случаи:
– если модальный интервал крайний, то 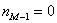 либо
либо 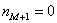 ;
;
– если обнаружатся 2 модальных интервала, которые находятся рядом, например, 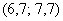 и
и 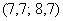 , то рассматриваем модальный интервал
, то рассматриваем модальный интервал 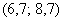 , при этом близлежащие интервалы (слева и справа) по возможности тоже укрупняем в 2 раза.
, при этом близлежащие интервалы (слева и справа) по возможности тоже укрупняем в 2 раза.
– если между модальными интервалами есть расстояние, то применяем формулу к каждому интервалу, получая тем самым 2 или бОльшее количество мод.
Вот такой вот депеш мод 🙂
И медиана. Если дан готовый интервальный ряд, то медиана рассчитывается чуть по менее страшной формуле, но сначала нудно (описка по Фрейду:)) найти медианный интервал – это интервал, содержащий варианту (либо 2 варианты), которая делит вариационный ряд на две равные части.
Выше я рассказал, как определить медиану, ориентируясь на относительные накопленные частоты 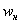 , здесь же сподручнее рассчитать «обычные» накопленные частоты
, здесь же сподручнее рассчитать «обычные» накопленные частоты 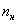 . Вычислительный алгоритм точно такой же – первое значение сносим слева (красная стрелка), и каждое следующее получается как сумма предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера):
. Вычислительный алгоритм точно такой же – первое значение сносим слева (красная стрелка), и каждое следующее получается как сумма предыдущего с текущей частотой из левого столбца (зелёные обозначения в качестве примера): 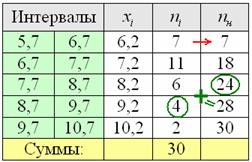
Всем понятен смысл чисел в правом столбце? – это количество вариант, которые успели «накопиться» на всех «пройденных» интервалах, включая текущий.
Поскольку у нас чётное количество вариант (30 штук), то медианным будет тот интервал, который содержит 30/2 = 15-ю и 16-ю варианту. И ориентируясь по накопленным частотам, легко прийти к выводу, что эти варианты содержатся в интервале 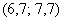 .
.
Формула медианы: 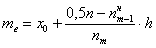 , где:
, где:
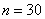 – объём статистической совокупности;
– объём статистической совокупности;
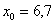 – нижняя граница медианного интервала;
– нижняя граница медианного интервала;
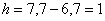 – длина медианного интервала;
– длина медианного интервала;
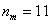 – частота медианного интервала;
– частота медианного интервала;
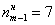 – накопленная частота предыдущего интервала.
– накопленная частота предыдущего интервала.
Таким образом:
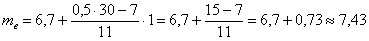 ден. ед. – заметим, что медианное значение, наоборот, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант:
ден. ед. – заметим, что медианное значение, наоборот, оказалось смещено правее, т.к. по правую руку находится значительное количество вариант: 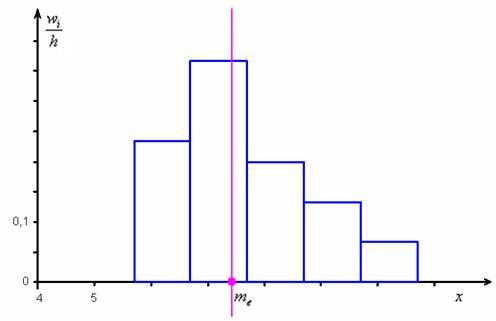
И справочно особые случаи:
– Если медианным является крайний левый интервал, то 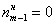 ;
;
– Если вариационный ряд содержит чётное количество вариант и две средние варианты попали в разные интервалы, то объединяем эти интервалы, и по возможности удваиваем предыдущий интервал
Ответ: 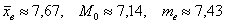 ден. ед.
ден. ед.
Здесь центральные показатели оказались заметно отличны друг от друга, и это говорит об асимметрии распределения, которая хорошо видна по гистограмме.
И задача для тренировки:
Для изучения затрат времени на изготовление одной детали рабочими завода проведена выборка, в результате которой получено следующее статистическое распределение: 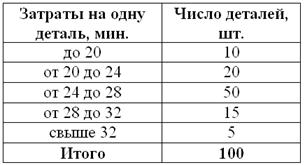
…да, тематичная у меня получилась статья 🙂
Найти среднюю, моду и медиану.
Это, кстати, уже каноничная «интервальная» задача, в которой исследуется непрерывная величина – время.
Решаем эту задачу в Экселе – все числа и инструкции уже там. Если нет Экселя, считаем на калькуляторе, что в данном случае может оказаться даже удобнее. Образец решения, как обычно, в конце урока.
Несмотря на разнообразия рассмотренных показателей, их всё равно бывает не достаточно. Существуют крайне неоднородные совокупности, у которых варианты «кучкуются» во многих местах, и по этой причине средняя, мода и медиана неудовлетворительно характеризуют центральную тенденцию.
В таких случаях вариационный ряд дробят с помощью квартилей, децилей, а в упоротых специализированных исследованиях – и с помощью перцентилей.
Квартили упорядоченного вариационного ряда – это варианты 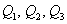 , которые делят его на 4 равные (по количеству вариант) части. Откуда автоматически следует, что 2-я квартиль – есть в точности медиана:
, которые делят его на 4 равные (по количеству вариант) части. Откуда автоматически следует, что 2-я квартиль – есть в точности медиана: 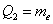 .
.
В тяжёлых случаях проводится разбиение на 10 частей – децилями 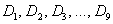 – это варианты, который делят упорядоченный вариационный ряд на 10 равных (по количеству вариант) частей.
– это варианты, который делят упорядоченный вариационный ряд на 10 равных (по количеству вариант) частей.
И в очень тяжелых случаях в ход пускается 99 перцентилей 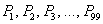 .
.
И после разбиения вариационного ряда каждый участок исследуется по отдельности – рассчитываются локальные средние показатели, локальные показатели вариации и т.д.
В учебном курсе квартили, децили, перцентили встречаются редко, и посему я оставляю этот материал (их нахождение) для самостоятельного изучения.
Ну а сейчас мы перейдём к рассмотрению другой группы статистических показателей – как раз к показателям вариации.
Пример 9. Решение: заполним расчётную таблицу: 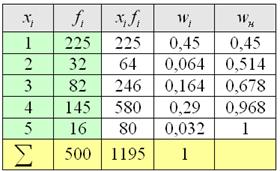
Вычислим среднюю:
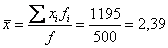 – две с половиной пуговицы, Карл!
– две с половиной пуговицы, Карл!
По правому столбцу определяем «иксовое» значение, которое делит совокупность на 2 равные части: 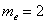 (именно здесь накопленная частота «перевалила» за 0,5).
(именно здесь накопленная частота «перевалила» за 0,5).
Кроме того, медиану легко усмотреть и устно – поскольку половина совокупности равна 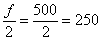 , а сумма первых двух частот
, а сумма первых двух частот 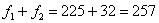 , то совершенно понятно, что 250-й и 251-й пиджак – двухпуговичные.
, то совершенно понятно, что 250-й и 251-й пиджак – двухпуговичные.
Пример 11. Решение: поскольку длина внутренних интервалов равна 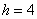 , то длины крайних интервалов полагаем такими же (см. конец статьи Интервальный вариационный ряд). Заполним расчётную таблицу:
, то длины крайних интервалов полагаем такими же (см. конец статьи Интервальный вариационный ряд). Заполним расчётную таблицу: 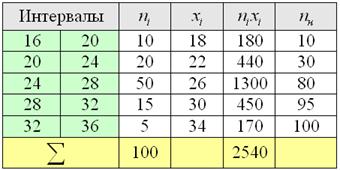
Вычислим выборочную среднюю:
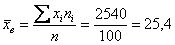 мин.
мин.
Моду вычислим по формуле 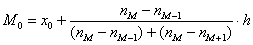 , в данном случае:
, в данном случае:
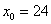 – нижняя граница модального интервала;
– нижняя граница модального интервала;
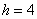 – длина модального интервала;
– длина модального интервала;
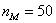 – частота модального интервала;
– частота модального интервала;
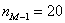 – частота предшествующего интервала;
– частота предшествующего интервала;
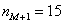 – частота следующего интервала.
– частота следующего интервала.
Таким образом:
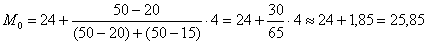 мин.
мин.
Анализируя накопленные частоты, приходим к выводу, что медианным является интервал 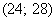 (именно он содержит 50-ю и 51-ю варианты, которые делят ряд пополам).
(именно он содержит 50-ю и 51-ю варианты, которые делят ряд пополам).
Медиану вычислим по формуле 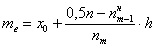 , в данном случае:
, в данном случае:
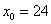 – нижняя граница медианного интервала;
– нижняя граница медианного интервала;
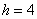 – длина этого интервала;
– длина этого интервала;
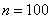 – объём статистической совокупности;
– объём статистической совокупности;
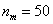 – частота медианного интервала;
– частота медианного интервала;
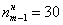 – накопленная частота предыдущего интервала.
– накопленная частота предыдущего интервала.
Таким образом:
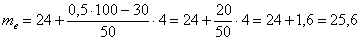 мин.
мин.
Ответ: среднее время изготовления детали характеризуется следующими центральными характеристиками: 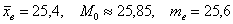
Автор: Емелин Александр
(Переход на главную страницу)
 «Всё сдал!» — онлайн-сервис помощи студентам
«Всё сдал!» — онлайн-сервис помощи студентам