Увеличиваем скорость работы Python до уровня C++ с Numba
Увеличиваем скорость работы Python до уровня C++ с Numba
В этой статье автор разобрался, как увеличить скорость работы Python, и продемонстрировал реализацию на реальном примере.
Прим. ред. Это перевод. Мнение редакции может не совпадать с мнением автора оригинала.
Тест базовой скорости
Для сравнения базовой скорости Python и C++ я буду использовать алгоритм генерации случайных простых чисел.
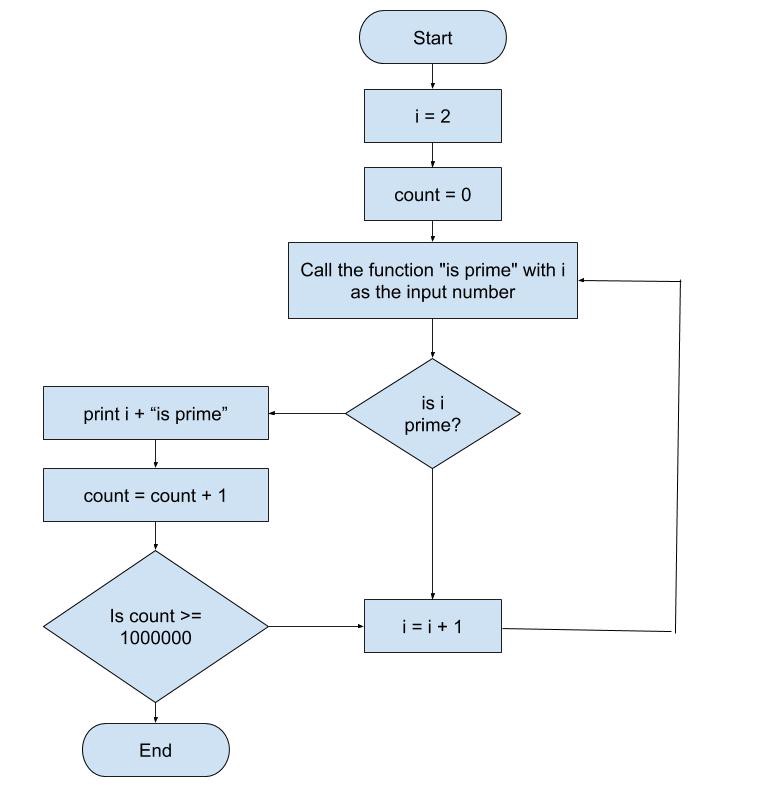
Блок-схема алгоритма генерации простых чисел
Реализация на Python
Реализация на C++
Результат
Комментарий
Как и ожидалось, программа на C++ выполняется в 25 раз быстрее, чем на Python. Ожидания подтвердились, потому что:
Благодаря тому, что Python это гибкий универсальный язык, наш результат можно улучшить. Один из лучших способов увеличить скорость Python — Numba.
Numba
Numba — это Open Source JIT-компилятор, который переводит код на Python и NumPy в быстрый машинный код.
Чтобы начать использовать Numba, просто установите её через консоль:
Реализация на Python с использованием Numba
Как вы могли заметить, в коде добавились декораторы njit:
Итоговая скорость Python
Теперь вы знаете что Python способен обогнать C++. О других способах увеличения скорости работы Python читайте в статье про пять проектов, которые помогают ускорить код на Python.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Десять способов для ускорения кода на Python
1. Познакомьтесь со встроенными функциями

Рисунок 1 | Встроенные функции в Python 3
Python поставляется с множеством встроенных функций, реализованных на языке программирования C, которые очень быстры и хорошо поддерживаются (рисунок 1). Например, функции, связанные с алгебраическими вычислениями: abs(), len(), max(), min(), set(), sum()).
В качестве примера рассмотрим встроенные функции set() и sum(). Их использование позволяет повысить скорость выполнения кода в десятки раз.

Рисунок 2 | Примеры функций set() и sum()
2. sort() или sorted()
Обе функции предназначены для сортировки списков. Функция sort() немного быстрее, чем sorted(). Это связано с тем, что метод sort() изменяет первичный список. sorted() создает новый отсортированный список и оставляет исходный список без изменений.


Рисунок 3| sort() и sorted()
Но функция sorted() более универсальна. Она принимает любую коллекцию, в то время как функция sort()работает только со списками. Например, с помощью sorted() можно быстро отсортировать словарь по его ключам или значениям.

Использование sorted() со словарем
3. Используйте символы вместо функций
Для создания пустого словаря или списка вместо dict() или list() можно использовать фигурные скобки «<>». Как и для пустого набора, когда нужно использовать set()) и [].

Использование list() и dict() напрямую.
4. Генератор списков
Для создания нового списка из старого списка мы используем цикл for. Он позволяет перебрать старый список, преобразовать его значения на основе заданных условий и сохранить в новом списке. Например, чтобы найти все четные числа из another_long_list, можно использовать приведенный ниже код:
Но есть более лаконичный способ переборки. Для его реализации мы помещаем исходный цикл for всего в одну строку кода. При этом скорость выполнения увеличивается почти в 2 раза.

В сочетании с третьим способом мы можем превратить список в словарь или набор, изменив [] на <>. Давайте перепишем код с рисунка 5. Мы можем пропустить присвоение и завершить итерацию внутри скобок. Например,sorted_dict3 =
Функция sorted(a_dict.items(), key=lambda item: item[1]) вернет список кортежей (рисунок 4). Здесь мы используем множественное присваивание для распаковки кортежей. Так как каждому кортежу в списке мы присваивали ключ его первому элементу и значение его второму элементу. После этого каждая пара ключ-значение сохраняется в словаре.
5. Используйте функцию enumerate() для получения значений и индексов
Можно использовать функцию enumerate(), которая превращает значения списка в пары index и value. Это также ускорит Python-код примерно в 2 раза.

Рисунок 7 | Пример enumerate()
6. Используйте zip() для слияния списков
Иногда нужно перебирать два списка или даже более. Для этого можно использовать функцию zip(), которая преобразует несколько списков в один список кортежей. При этом спискам лучше иметь одинаковую длину, иначе выполнение zip() остановится, как только закончится самый короткий список.

Чтобы получить доступ к элементам в каждом кортеже, можно разделить список кортежей, добавив звездочку (*) и используя несколько переменных. Например, letters1, numbers1 = zip(*pairs_list).
7. Совмещайте set() и in
Для проверки наличия определенного значения часто пишется подобная функция:
Затем вызывается метод check_membership(value), чтобы увидеть, есть ли значение в another_long_list. Но лучше просто использовать in, вызвав value in another_long_list.

Проверка вхождения, с помощью in и set()
Для большей эффективности необходимо сначала удалить дубликаты из списка с помощью set(), а затем проверить вхождение в объекте набора. Так мы сократим количество элементов, которые необходимо проверить.
8. Проверка переменной на истинность
Для проверки пустых переменных, списков, словарей не нужно явно указывать == True или is True в операторе if. Вместо этого лучше указать имя переменной.

Простая проверка переменной
Если нужно проверить, является ли переменная пустой, используйте if not string_returned_from_function.
9. Для подсчета уникальных значений используйте Counters()
Чтобы подсчитать уникальные значения в списке a_long_list, который мы создали в пункте 1, нужно создать словарь. Его ключи являются числами, а значения – счетчиками. Выполняя проход по списку, увеличиваем значение счетчика, если элемент уже есть в словаре. А также добавлять его в словарь, если его там нет.
Но более эффективный способ сделать это – использовать подкласс Counter() из библиотеки коллекций :
Чтобы получить десять наиболее часто встречающихся чисел, используйте метод most_common, доступный в Counter().

10. Вложите цикл for внутрь функции
Предположим, что мы создали функцию, и нам необходимо вызвать ее определённое количество раз. Для этого функция помещается в цикл for.
Но вместо выполнения функции миллион раз (длина a_long_list составляет 1 000 000), можно интегрировать цикл for внутрь функции. Это сэкономит около 22% времени.

Рисунок 12 | цикл for внутри функции
Надеюсь, что некоторые из перечисленных способов ускорения выполнения кода Python окажутся полезными для вас.
Пожалуйста, оставляйте ваши комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, лайки, отклики, дизлайки, подписки!
Пять проектов, которые помогают ускорить код на Python

Python — простой и удобный динамический язык язык, но все отлично знают про его слабость: он работает медленнее, чем код на Си, Java или даже JavaScript, когда дело доходит до задач, которым требуется интенсивная работа ЦП. Если вы не хотите с этим мириться и считаете, что просто вставить в компьютер больше оперативной памяти — не выход, то у вас остаётся два пути:
Приводим пять проектов, которые попытались решить эту проблему одним из двух этих способов.
Среди всех кандидатов на замену CPython самым выделяющимся является PyPy. Quora, например, использует его на продакшене. Пожалуй, у него есть все шансы стать средой по умолчанию из-за отличной совместимости с существующим кодом.
PyPy использует JIT-компиляцию, так же, как и движок Google Chrome для выполнения JavaScript, что и даёт прирост в скорости. Однако для любителей использовать самые последние возможности языка есть неприятная новость — PyPy реализует поддержку новых версий языка со значительной задержкой.
Pyston
Этот проект, который был спонсирован Dropbox’ом, использует LLVM (Low Level Virtual Machine) инфраструктуру для компилятора, который тоже использует JIT. Если проводить сравнение с PyPy, Pyston ещё только на начальном уровне развития — актуальная версия сейчас 0.5.1, и она поддерживает далеко не все возможности языка.
Nuitka
Вместо того, чтобы увеличивать производительность байткод-компилятора и интерпретатора Python, некоторые разработчики решили, что код на Python можно транслировать в другие языки, которые уже сами по себе выполняются быстро. Так поступила и команда Nuitka — их проект компилирует программы Python в код на C++. Реализация во многом опирается на существующие бинарники среды Python, что несколько ограничивает переносимость проекта, но не стоит недооценивать прирост скорости, который предоставляет такая трансляция. В дальнейшем авторы планируют транслировать Python напрямую в Си (правда, это планы на весьма далёкое будущее), что ускорит скорость работы ещё во много раз.
Cython
Cython — надстройка над Python, особая версия языка, которая компилируется в Си и интерфейсы с C/C++ кодом. Это один из путей для написания Си расширений для Python (чтобы могли быть имплементированы участки кода, которые требуют особой скорости). Впрочем, его можно использовать и отдельно от обычного Python. Обратная сторона медали заключается в том, что перенос существующей кодовой базы не будет полностью автоматическим — технически, вы уже пишете не совсем на Python.
Cython достаточно широко распространён и используется во многих библиотеках. Так, например, некоторые алгоритмы в scikit-learn написаны именно на Cython для повышения производительности.
Numba
Numba комбинирует два предыдущих подхода. От Cython она берёт идею, что следует ускорять те части языка, которые больше всего этого требуют (например, математические вычисления, привязанные к ЦП); так же, как PyPy или Pyston, она делает это с помощью LLVM. Функции, компилируемые Numba, могут быть помечены особыми декораторами, и Numba будет работать над их ускорением вместе с NumPy. Однако Numba не использует JIT, поэтому на компиляцию уходит дополнительное время.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Ускорение кода на Python средствами самого языка
 Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и на Хабре.
Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и на Хабре.
Так что же делать?
Тогда, если для вашего проекта выше перечисленные методы не подошли, что делать? Менять Python на другой язык? Нет, сдаваться нельзя. Будем оптимизировать сам код. Примеры будут взяты из программы, строящей множество Мандельброта заданного размера с заданным числом итераций.
Время работы исходной версии при параметрах 600*600 пикселей, 100 итераций составляло 3.07 сек, эту величину мы возьмем за 100%
Скажу заранее, часть оптимизаций приведет к тому, что код станет менее pythonic, да простят меня адепты python-way.
Шаг 0. Вынос основного кода программы в отдельную
Данный шаг помогает интерпретатору python лучше проводить внутренние оптимизации про запуске, да и при использовании psyco данный шаг может сильно помочь, т.к. psyco оптимизирует лишь функции, не затрагивая основное тело программы.
Если раньше рассчетная часть исходной программы выглядела так:
мы получили время 2.4 сек, т.е. 78% от исходного.
Шаг 1. Профилирование
Стандартная библиотека Python’a, это просто клондайк полезнейших модулей. Сейчас нас интересует модуль cProfile, благодаря которому, профилирование кода становится простым и, даже, интересным занятием.
Полную документацию по этому модулю можно найти здесь, нам же хватит пары простых команд.
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
.
С её помощью, легко определить места, требующие оптимизации (строки с наибольшими значениями ncalls (кол-во вызовов функции), tottime и percall (время работы всех вызовов данной функции и каждого отдельного соответственно)).
В моем случае интересной частью вывода было (время выполнение отличается от указанного выше, т.к. профилировщик добавляет свой «оверхед»):
4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
3533224 0.296 0.000 0.296 0.000
360000 0.081 0.000 0.081 0.000
360000 0.044 0.000 0.044 0.000
360000 0.036 0.000 0.036 0.000
.
Итак, профиль получен, теперь займемся оптимизацией вплотную.
Шаг 2. Анализ профиля
Видим, что на первом месте по времени стоит наша основная функция mandelbrot, за ней идет системная функция abs, за ней несколько функций из модуля math, далее — одиночные вызовы функций, с минимальными временными затратами, они нам не интересны.
Итак, системные функции, «вылизаные» сообществом, нам врядли удастся улучшить, так что перейдем к нашему собственному коду:
Шаг 3. Математика
Сейчас, код выглядит так:
Заметим, что оператор возведения в степень ** — довольно «общий», нам же необходимо лишь возведение во вторую степень, т.е. все конструкции вида x**2 можно заменить на х*х, выиграв таким образом еще немного времени. Посмотрим на время:
1.9 сек, или 62% изначального времени, достигнуто простой заменой двух строк:
Шажки 5, 6 и 7. Маленькие, но важные
Прописная истина, о которой знают все программисты на Python — работа с глобальными переменными медленней работы с локальными. Но часто забывается факт, что это верно не только для переменных но и вообще для всех объектов. В коде функции идут вызовы нескольких функций из модуля math. Так почему бы не импортировать их в самой функции? Сделано:
Еще 0.1сек отвоевано.
Вспомним, что abs(x) вернет число типа float. Так что и сравнивать его стоит с float а не int:
Еще 0.15сек. 53% от начального времени.
И, наконец, грязный хак.
В конкретно этой задаче, можно понять, что нижняя половина изображения, равна верхней, т.о. число вычислений можно сократить вдвое, получив в итоге 0.84сек или 27% от исходного времени.
Заключение
Профилируйте. Используйте timeit. Оптимизируйте. Python — мощный язык, и программы на нем будут работать со скоростью, пропорциональной вашему желанию разобраться и все отполировать:)
Цель данной статьи, показать, что за счет мелких и незначительных изменения, таких как замен ** на *, можно заставить зеленого змея ползать до двух раз быстрее, без применения тяжелой артиллерии в виде Си, или шаманств psyco.
Также, можно совместить разные средства, такие как вышеуказанные оптимизации и модуль psyco, хуже не станет:)
Спасибо всем кто дочитал до конца, буду рад выслушать ваши мнения и замечания в комментариях!
UPD Полезную ссылку в коментариях привел funca.
Python (+numba) быстрее Си — серьёзно?! Часть 1. Теория
Давно собирался написать статью о numba и о сравнении её быстродействия с си. Статья про хаскелл «Быстрее, чем C++; медленнее, чем PHP» подтолкнула к действию. В комментариях к этой статье упомянули о библиотеке numba и о том, что она магическим образом может приблизить скорость выполнения кода на питоне к скорости на си. В данной статье после небольшого обзора по numba (часть 1) чуть более подробный разбор этой ситуации (часть 2).
Моё знакомство с Numba началось в 2015 году вот с этого вопроса на stackoverflow про скорость умножения матриц на питоне: Efficient outer product in python
С тех пор произошло много событий в каждой из библиотек, но качественно картина в отношении numba / cython / pypy не изменилась: numba обгоняет cython за счёт использования нативных процессорных инструкций ( cython не умеет jit), а pypy – за счёт более эффективного выполнения байткода llvm.
Мне numba пригождается по работе (обработка гиперспектральных изображений) и в преподавании (численное интегрирование, решение дифф.уравнений).
как установить
как ускорять
Чтобы ускорить функцию, надо перед её определением вписать декоратор njit:
Ускорение в 40 раз.
Корень нужен, потому что иначе numba распознает сумму арифметической прогрессии(!) и вычислит её за константное время.
jit vs njit
Раньше был актуален режим просто @jit (а не @njit ). Смысл в том, что в этом режиме можно использовать неподдерживаемые нумбой операции: нумба на большой скорости доходит до первой такой операции, затем замедляется, и до конца функции исполнение продолжается с обычной питоновской скоростью, даже если больше в функции ничего «запретного» не встречается (т.н. object mode), что, очевидно, нерационально. Сейчас от @jit постепенно отказываются, рекомендуется всегда пользоватся @njit (или в полной форме @jit(nopython=True) ): в этом режиме нумба ругается исключениями на такие места – всё равно лучше их переписать, чтобы не потерять в скорости.
что умеет разгонять
В разогнанных функциях можно использовать только часть функционала питона и нумбы. Все операторы, функции и классы делятся в отношении нумбы на две части: те, которые нумба «понимает» и те, которые она «не понимает».
В документации по numba есть два таких списка (с примерами):
Из примечательного в этих списках:
Никакие другие библиотеки (в частности, scipy и pandas) она не понимает совсем.
Но даже того подмножества языка, которое она понимает, достаточно, чтобы разогнать большую часть кода для научных приложений, на которые numba в первую очередь и ориентирована.
важно!
Из разогнанных функций можно вызывать только разогнанные, не разогнанные нельзя.
(хотя разогнанные функции можно вызывать и из разогнанных и из не разогнанных).
globals
В разогнанных функциях глобальные переменные становятся константами: их значение фиксируется на момент компиляции функции (пример). => Не используйте глобальные переменные в разогнанных функциях (кроме констант).
сигнатуры
В нумбе каждой функции сопоставляется один или несколько типов входных и выходных аргументов, т.н. сигнатуры. При первом вызове функции сигнатура формируется и автоматически компилируется соответствующий бинарный код функции. При запуске с другими типами аргументов будут создаваться новые сигнатуры и новые бинарники (старые при этом сохраняются). Таким образом, «выход на режим» по скорости исполнения для каждой сигнатуры наступает, начиная со второго запуска с этими типами аргументов. Так что надо либо
Есть ещё третий способ. Сигнатуры можно задавать вручную:
При запуске функции с сигнатурой, указанной в декораторе, уже первый запуск будет быстрым: компиляция произойдёт в тот момент, когда питон увидит определение функции, а не при первом запуске. Сигнатур может быть несколько, порядок их следования имеет значение.
Предупреждение: этот последний способ не future-safe. Авторы numba предупреждают о том, что синтаксис указания типов может измениться в будущем, @jit / @njit без сигнатур – более безопасный в этом плане вариант.
f.signatures начинают показывать сигнатуры только тогда, когда питон о них узнает, то есть после первого вызова функции, либо если они заданы вручную.
Кроме f.signatures сигнатуры можно посмотреть через f.inspect_types() – кроме типов входных параметров эта функция покажет типы выходных параметров, а также типы всех локальных переменных.
Кроме типов входных и выходных параметров, есть возможность вручную указать типы локальных переменных:
В нумбе у целых чисел нет длинной арифметики как в «просто» питоне, но есть стандартные типы различной ширины от int8 до int64 (таблица типов в документации). Есть ещё типы int_ (а также float_ ), используя которые вы предоставляете нумбе возможность выбрать оптимальную (с её точки зрения) ширину поля.
классы
Поддержка классов (@jitclass) вообще есть, но пока она экспериментальная, так что лучше пока избегать их использования (на текущий момент, по моему опыту, с ними сильно медленнее, чем без них).
custom dtypes
Умеет выполнять разогнанный код на GPU, причём в отличие от того же, например, pycuda или pytorch, не только на nvidia, но и на amd’шных карточках. С этим пока разбирался мало. Вот статья на хабре 2016 года Сравнение производительности GPU-расчетов на Python и C. Там получилась сопоставимая с С скорость.
ahead-of-time компиляция
В нумбе есть режим обычной (то есть не jit) компиляции (документация), но этот режим является не основным, я с ним не разбирался.
автоматическое распараллеливание
Некоторые задачи (например, умножение матрицы на число) распараллеливаются естественным образом. Но есть такие задачи, выполнение которых распараллелить не получается. С декоратором @njit(parallel=True) нумба анализирует код разгоняемой функции, находит такие участки, каждый из которых самого по себе распараллелить невозможно, и выполняет их одновременно на разных ядрах CPU (документация). Раньше распараллеливать функции можно было только вручную при помощи @vectorize (документация), что требовало изменения кода.
освобождение GIL
Функции, декорированные @jit(nogil=True) и запущенные в разных потоках, могут исполняться параллельно. Для избежания race conditions необходимо использовать синхронизацию потоков.
документация
Нумбе до сих пор не хватает толковой документации. Она есть, но в ней есть не всё.
оптимизация
Есть некоторая непредсказуемость при оптимизации кода вручную: unpythonic код зачастую работает быстрее, чем pythonic.
Заинтересовавшимся темой могу порекомендовать видео мастер-класса по numba с конференции scipy 2017 (есть исходники на гитхабе). Оно правда длинновато и частично устарело (например, строки уже поддерживаются), но общее представление получить помогает: там есть, в частности, про pythonic/unpythonic, jit(parallel=True) и пр.
Во второй части рассмотрим применение numba на примере кода из упомянутой в начале статьи.



