Погружение в матрицу: Анализ структуры и методы распознавания QR-кода
Содержание статьи
В современном мире информация может представляться в самых причудливых формах. Причины для этого разные и не всегда имеют стеганографическую подоплеку. У «человека разумного» буквально появился «третий глаз»: мобильный телефон стал неотъемлемым атрибутом каждого из нас. А что именно с его помощью мы попытаемся разглядеть, ты узнаешь из этой статьи.

Повсеместно распространенным штрих-кодом сейчас уже никого не удивишь. В реальной жизни представление информации в виде последовательности черно-белых полос стало привычным настолько же, насколько привычной стала покупка какого-либо товара в супермаркете. Кодирование информации о продукте (страна-изготовитель, непосредственно сам изготовитель товара, тип товара и т.п.) производится с целью упрощения дальнейшего ее извлечения автоматизированными средствами. Именно для этого хорошо подходит штриховой код, который в силу своей линейной структуры хорошо читается в горизонтальном направлении.
Однако прогресс не стоит на месте, и в скором времени того объема информации, который способны перенести в себе линейные кодировки (до 30 цифровых символов), стало не хватать производителям бесконечно растущих объемов продукции. Инженеры стали задумываться о способах расширения объемов кодируемых данных и результатом их деятельности стало появление на свет двумерных штрих-кодов, но вот сфера их применения, в силу специфики, перестала ограничиваться исключительно «пометкой» различной продукции. Нынче представители семейства «матричных» активно используются в среде потребительской, и теперь им находят все более интересные способы применения. И чтобы при случайной встрече с ними ты не смотрел на них, как на картинку с ребусом, мы научимся распознавать их не только по внешним признакам, но и напишем программный инструмент, который позволит тебе определить содержание контейнера с данными, а также поговорим о нестандартных способах использования матричного кодирования. Пришел. Увидел. Распознал.
Чтобы не получить в конечном счете «кашу» из определений, предлагаю придерживаться общей классификации способов кодирования информации. Как уже было упомянуто в начале, разделяют два принципиально разных типа кодирования:
Многоуровневые коды нам неинтересны, так как они представляют собой попросту «многослойный» линейный код. В свою очередь, матричные кодировки «упаковывают» информацию как по горизонтали, так и по вертикали, что позволяет радикально увеличить объем хранимых данных и, соответственно, снять ограничения на их тип — теперь становится возможным кодирование текстовых данных.

Из всего многообразия матричных кодов нам интересен QR-код. Его повсеместная распространенность (одна только Япония использует эти кодировки с такой завидной популярностью, как, например, мы используем таблички с указанием названия улицы и номера дома) обусловлена прежде всего высокой степенью его распознаваемости и, как следствие, простотой распознающего оборудования. Кстати, аббревиатура QR образована от англ. «quick response», что в переводе на великий и могучий означает «быстрый отклик».
Быстро «откликнуться» конкретный экземпляр QR-кодов может на самое непривередливое оборудование. Так, например, имея в наличии мобильный телефон или любой другой девайс с камерой практически любого разрешения, можно считать себя уже достаточно укомплектованным для охоты за QR-кодами. Если сфотографировать QR-картинку, прилагающуюся к статье (или открыть ее с диска и сделать банальный PrintScreen, но это выглядит менее эффектно), пропустить фотографию через одну из программ распознавания, то мы получим следующую строку:
Xakep Online: https://xakep.ru
Что делать с полученной информацией (перейти по ссылке на веб-ресурс, сохранить ссылочку в заметках или в контактах и т.п.), ты решишь самостоятельно.
Программы для распознавания QR-кодов доступны практически под любые платформы, однако большинство из них рассчитано на мобильную аудиторию. Неудивительно, ведь в подавляющем большинстве случаев, когда мы можем встретить «белый квадрат с черными точками», у нас под рукой не окажется ничего, кроме мобильного телефона.
Большинство программ находятся в свободном доступе и являются бесплатными, однако мало кто из разработчиков делится исходными кодами своего ПО. Может быть, этот факт обусловлен отсутствием интереса конечного пользователя, а может быть, производитель не хочет раскрывать деталей алгоритма распознавания. Так или иначе, мы самостоятельно разберемся с деталями распознавания QR-кода программным способом, написав полноценное приложение, которое, в прямом смысле, позволит нам получать из картинки содержащуюся в ней текстовую информацию.
Готовим инструменты

Разбираем матрицу
Рассмотрим общую структуру приложения, которое, как предполагается, будет декодировать QR-код. Первую и, пожалуй, самую большую часть исходного кода занимает описание основного программного класса: определение констант, структурные секции, секции описания функций, предоставляемых сторонней библиотекой. Представление исходных данных в виде картинки описывает структура PTIMAGE.
Структура, описывающая параметры изображения
unsafe public struct PTIMAGE
<
public int dwWidth;// ширина изображения в пикселях
public int dwHeight;//высота изображения в пикселях
public byte* pBits;//указатель на данные исходного изображения
public byte* pPalette;// указатель на данные о палитре изображения (1,4,8 бит)
public short wBitsPerPixel; //число бит на пиксель
>
SDK поддерживает большинство форматов файлов изображений. Учитывая тот факт, что большинство камер экспортируют снимки в наиболее распространенные форматы, проблем с несовместимостью быть не должно. Далее идет раздел описания функций, которые экспортируют библиотеки, входящие в состав SDK. Заострять внимание на их подключении мы не будем.
Следующим этапом будет описание параметров библиотеки декодирования баркодов в структуре PTDECODEPARA:
Структура PTDECODEPARA используется для определения параметров при декодировании баркода на изображении
public unsafe struct PTDECODEPARA
<
public int dwStartX;// начало координаты X в пикселях
в окне поиска изображений для декодирования
public int dwStartY;
public int dwEndX;
public int dwEndY;
public int dwMaxCount;//максимальное количество символов для поиска; если значение равно 0, то ищем все символы
>;
Манипулируя со значением переменной dwMaxCount, мы получаем возможность управлять производительностью приложения, фокусируя наш «декодировщик» на конкретных областях исходного изображения и избегая функционирования «в холостую». Следующая структура заполняется непосредственно после определения области изображения, в которой находится баркод:
После декодирования структура PTBARCODEINFO содержит баркод с информацией
public unsafe struct PTBARCODEINFO
<
/координаты четырех углов баркода в пикселях/
public int dwX1, dwY1;
public int dwX2, dwY2;
public int dwX3, dwY3;
public int dwX4, dwY4;
public byte* pData; //указатель на буфер, который содержит данные баркода
public int dwDataLen; //длина данных (в байтах) баркода
>;
Если ты внимательно посмотришь на картинку с QR-кодом, то сразу заметишь три выделяющихся квадратных области — это ориентиры для средств распознавания, своего рода «указатель» программе на то, что среди прочего набора пикселей на картинке присутствует QR-код.
Главная функция нашего приложения проста до безобразия, поэтому в полном объеме приводить ее не будем, а сосредоточим внимание на следующих инструкциях:
Как ты уже понял, непосредственно процесс распознавания скрывается в инструкциях функции DecodeQR(), которая после определения области QR-кода передает инструкции обработчику баркода, а он, в свою очередь, демонстрирует пользователю информацию, содержащуюся в картинке:
Вроде бы результат достигнут. Однако легкий «краш-тест» полученного приложения позволил выявить его сильные и слабые стороны.
Однако с распознаванием кодов в 3D все несколько хуже: искажение в соотношении сторон QR-кода может негативно сказаться на качестве определения его содержимого.
В общем, можно сказать, что эта библиотека предоставляет разработчику широкие возможности для работы с матричными кодами. В ней имеются встроенные средства коррекции ошибок и восстановления поврежденных областей исходных изображений, а возможности изменения параметров точности распознавания позволяют программисту найти золотую середину в тандеме параметров «производительность/эффективность».
Рамки применения QR-кода ограничиваются исключительно фантазией своего интегратора. Банальный обмен контактными данными (адреса сайтов на картинке в каком-либо общественном месте, эффектная демонстрация данных визитки на черно-белой карточке, реклама и объявления, приглашения и др.) на фоне массы других способов уже кажется, как минимум, неоригинальным.

Идея расширения видимой реальности с помощью подручных средств, коими являются мобильные телефоны, кажется уже не настолько далекой и требующей технического прогресса.
А практичность данного вида представления информации для конечного потребителя заметна уже сейчас. Обладатель телефона, интересующийся, например, меню какого-либо ресторана (бара, кафе, памятником архитектуры или любым другим зданием, содержащим QR-код, который несет полезную информацию), при наведении камерой на QR-область может ознакомиться в реальном времени с меню, не посещая заведение.
Или ознакомиться с расписанием маршрута проезжающего мимо общественного транспорта, содержащего «полезную картинку». Альтернативное кодирование информации может оказаться полезным в вещах, имеющих стеганографическую подоплеку. Например, QR-код может быть спрятан в каком-нибудь изображении и вылезать наружу при его обесцвечивании. Ну а информация, которая появится при его распознавании, конечно же, будет зашифрованной. Поскольку стеганография — хорошо, сочетание ее с криптографией — всяко лучше.
Links

Денис Макрушин
Специализируется на исследовании угроз и разработке технологий защиты от целевых атак. #InspiredByInsecure
Алгоритмы распознавания штриховых кодов
( Barcodes Recognition Algorithms
Preprint, Inst. Appl. Math., the Russian Academy of Science)
Краснобаев А.А.
(A.A.Krasnobaev)
ИПМ им. М.В.Келдыша РАН
Москва, 2004
Работа выполнена при финансовой поддержке Российского фонда фундаментальных исследований (проекты №№ 020100671, 020790425)
Аннотация
Данная работа посвящена описанию разработанных алгоритмов для автоматического считывания линейных штриховых кодов при помощи системы работающей с видеоизображением (везде по тексту называемой видеосканером). Рассмотрены основные положения технологии штрихового кодирования. Представлен краткий обзор существующих сканеров штриховых кодов и принципов их работы. Разработанный алгоритм предназначался для использования в автономном устройстве – видеосканере. Вычислительные части видеосканера представляют собой ПЛИС фирмы Altera семейства Cyclone и сигнальный процессор фирмы Analog Devices семейства Black Fin. Использование ПЛИС позволило распараллелить работу алгоритма локализации штрихового кода. Операции фильтрации изображения, и осреднения по площади выполняются одновременно с получением изображения очередного кадра с датчика изображения. Работа алгоритма моделировалась в программном пакете MatLab 6.5 компании MathWork Inc. После успешного моделирования он был внедрён в устройство. Испытания устройства показали высокую надёжность и скорость (от 6 до 12 кадров в секунду) распознавания штриховых кодов без использования искусственной подсветки наблюдаемой сцены. По этим показателям разработанный видеосканер существенно превзошёл аналогичные сканеры фирм Opticon и OEM, которые используют искусственную подсветку при захвате кадра изображения.
Abstract
This work is dedicated to describing of developed algorithm for automatic reading bar code by using system that works with video information. Here described the main definition of bar coding technology and existing bar code reading systems. Developed algorithm is assigned to use in self-contained unit. FPGA Cyclone (Altera) and DSP Black Fin (Analog Devices) are computing parts of device. Using of FPGA allow to parallel work of algorithm for localization bar code. Filtering and averaging operation are performed simultaneously with acquisition of image. Algorithm work was modeling in software MathLab 6.5 MathWork Inc. After successful modeling it was inculcate in device. The device testing indicated high reliability and quick-action (from 6 to 12 frames per second) in bar code recognition without using artificial lighting. Therein developed scanner exceeds possibilities similar scanners Opticon and OEM, that uses artificial lighting.
Введение в штриховое кодирование.
Технология штрихового кодирования.
Традиционные методы ввода данных с листа бумаги в компьютер посредством клавиатуры имеют ряд недостатков [3]:
— Практика показывает, что в среднем случается 1 ошибка на 300 введённых символов.
— Ввод данных происходит достаточно медленно.
— Требуется обязательное участие человека в процессе.
Такие недостатки значительно сказываются при больших объёмах вводимых данных (например, при сортировке почты). На помощь приходят автоматические системы ввода данных, такие, как модули памяти, основанные на ППЗУ, магнитные карты, радио метки, системы видео распознавания символов, штрих-коды и т. д.
Последние несколько лет большое распространение получила технология штрихового кодирования. Это связано с надёжностью, компактностью и дешёвизной наносимого символа, с возможностью выбора оборудования для работы с ним. Штриховое кодирование широко применяется в розничной торговле, почтовых и грузовых перевозках, для идентификации электронных компонентов и медицинских препаратов.
Символика штрихового кода может быть распечатана на достаточно простом оборудовании, её можно масштабировать довольно в широких пределах.
Штриховое кодирование считается надёжным – 1 ошибка на 1 миллион символов [3].
Символ штрихового кода.
Линейный штриховой код по определению это код, представляющий знаки с помощью наборов параллельных штрихов различной толщины и шага, которые оптически считываются путём поперечного сканирования (ГОСТ 25868). На рис. 1 показан типичный символ штрихового кода и проставлены его основные размеры.
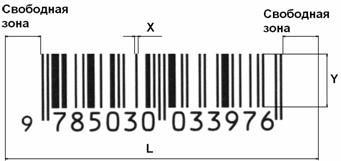
Рис. 1. Стандартный вид линейного штрихового кода. Иногда под штрихами печатаются закодированные цифры.
Основные характеристики изображения символа штрих-кода (ГОСТ 30721-2000):
— Размер Х: установленная ширина узких и одиночных элементов символа штрихового кода.
— Длина символа L: общая протяжённость полной строки знаков символа штрихового кода, включая свободные зоны.
— Высота штрихового кода Y: размер отдельных штрихов в символе линейной символики, измеряемый перпендикулярно направлению считывания.
В штрих-кодах кодируется различная информация. Например, код ЕАН-13 (ГОСТ Р 51201-98) кодирует уникальный номер товара. Существуют коды, кодирующие символьные строки ANSII – код 128 (ГОСТ 30743-2001).
Штриховой код может быть представлен, как печатная версия кода Морзе, где узкие элементы – точки, а широкие – тире. Информация содержится в ширина х штрихов и пробелов, высота может рассматриваться, как избыточность данных.
Обзор существующих систем считывания штрих-кода.
Общая схема системы чтения штрих-кодов показана на рис. 2. Она состоит из: электрооптической системы, осуществляющей считывание значений яркости в областях обзора сканера, блока АЦП, осуществляющего преобразование значений яркости в цифровой вид и процессорного модуля, производящего обработку и декодирование поступающей информации. На выходе системы можно получить раскодированные данные.

Рис. 2. Обобщенная схема сканера штрих-кодов.
Сканирование линейных штриховых символик обычно осуществлялось либо сканерами с линейкой ПЗС в качестве чувствительного элемента, либо различными типами лазерных сканеров, либо сканерами, осуществляющими декодирование на основе изображения, полученного с ПЗС матриц.
Принцип работы считывающего устройства сканера с ПЗС линейкой показан на рис. 3. Этот сканер не содержит механических частей. Позиционирование штрих-кода так, чтобы все его элементы попали на ПЗС линейку, осуществляется оператором. Вследствие этого, сканеры данного типа являются ручными.
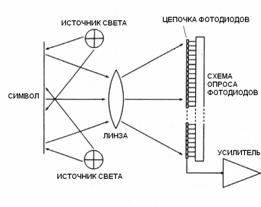
Рис. 3. Принцип работы сканера с ПЗС линейкой.
Принцип работы лазерного сканера показан на рис. 4. Сфокусированный линзой свет (луч лазера) образует ярко освещённую область на сканируемой поверхности. Датчик яркости осуществляет преобразование яркости из освещенной области в электрический сигнал, пропорциональный количеству отражённого света.
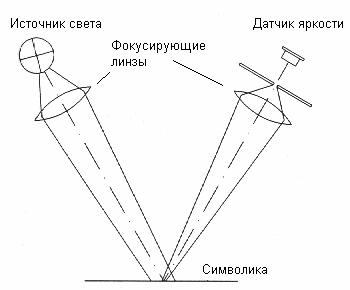
Рис. 4. Принцип работы лазерного сканера.
Лазерное пятно периодически сканирует вдоль прямых линий. Если одна из прямых линий пересечёт все штрихи одного символа, то возможно декодирование. В случае ручного сканера пятно лазера перемещается вдоль одной прямой, и задачей оператора является ориентировать сканер так, чтобы все штрихи символики были пересечены линией, создаваемой перемещающимся лучом. Если есть необходимость в автоматическом определении ориентации штрих-кодов, то прибегают к использованию всенаправленных сканеров. В этих устройствах движение сканирующего пятна осуществляется вдоль нескольких пересекающихся под углами 120 ° прямых (см. рис. 5).
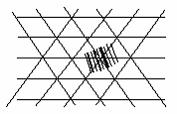
Рис. 5. Траектории движения светового пятна при сканировании всенаправленным лазерным сканером штрих-кодов.
Как только одна из прямых пересечёт все штрихи символики, можно приступать к её распознаванию. Недостатком таких сканеров является требование, чтобы отношение высоты к длине символики составляло не менее 0.4 [3].
Единственным способом перемещения лазерного пятна является качающееся зеркало. Это обуславливает появление электромеханических частей в конструкции лазерного сканера, что делает его менее надёжным по сравнению с устройствами, не содержащими такие части.
Рис. 6. Примеры символик, распознаваемых видеосканерами. Эти символики плохо или совсем не распознаются лазерными сканерами.
Обобщённая схема работы видеосканера штрих-кодов показана на рис. 7. Задачами сигнального процессора являются: локализация штриховых символик, выделение структурных элементов и декодирование.
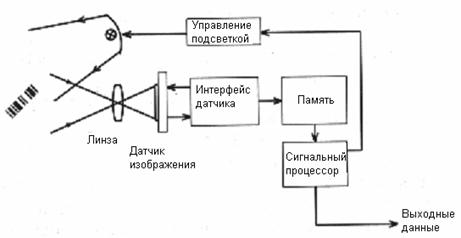
Рис. 7. Обобщенная структурная схема видеосканера.
Для видеосканера требуется разработка алгоритмов и методов обнаружения штриховых символик кардинально отличных от других сканеров. Это связанно с большим потоком неструктурированной входной видео информации. Используются как последовательные, так и параллельные алгоритмы обработки изображений. Параллельные алгоритмы более эффективны, но требуют специальных схемотехнических решений при создании оборудования сканера. Ниже описывается разработанный алгоритм для обнаружения и декодирования штрих-кодов.
Алгоритм работы видеосканера штрих-кодов.
Разработанный алгоритм можно разделить на три большие части, как показано на рис. 8.

Рис. 8. Блок схема алгоритма работы видеосканера штрих-кодов.
Алгоритм локализации штрих-кодов содержит часть, которая определяет участок изображения, содержащий штриховую символику. Внутри выделенного участка ищется прямая, пересекающая все штрихи символики, и формирует вектор яркостей вдоль этой прямой.
Полученный вектор яркостей передаётся на алгоритм выделения структурных элементов, где осуществляется перевод нечетких значений ширины элементов символики (штрихов и пробелов) в числа, кратные модулю (элементу минимальной ширины) штрихового кода. На выходе алгоритма получается целочисленный вектор значений ширины элементов.
Алгоритм декодирования разбирает структуру целочисленного вектора и декодирует закодированные символы в соответствии с кодовыми таблицами.
При разработке алгоритма учитывались такие параметры, как надёжность, быстродействие, экономичность аппаратного решения. Параметр надёжности является наиболее сложным для определения. Большая доля нагрузки при его оценке ложится на эксперимент.
Для достижения высокого быстродействия при анализе изображений необходимо использовать различные формы одновременности и параллельности процессов [2]. В разработанном алгоритме локализации штрих-кодов самой часто используемой операцией является фильтрация при помощи матриц размером 2х2 и 3х3. Эта операция использует данные только из локальной и заранее известной области обработки, требует значительно меньшего объёма памяти, чем те операции, исходные данные для которых разбросаны по всему изображению или расположение которых существенно зависит от результатов предыдущих вычислений. Учитывая также объём входных данных 1600х1200х5=9.6МБ/сек, эта часть алгоритма была адаптирована для выполнения одновременно нескольких фильтраций на ряде элементов жёсткой логики.
При разработке алгоритма выделения структурных элементов штрих-кода предполагались неопределёнными размер и положение входных данных. В алгоритме также применяются итерационные методы для определения расположения штрихов и пробелов. Следовательно, объём используемой памяти, и режим работы алгоритма изменяются в зависимости от входных данных. Этот алгоритм полностью реализуется программно.
Алгоритм декодирования штрих-кода – алгоритм верхнего уровня. Он получает на вход значительно меньший объём информации, имеет большое множество вариантов работы в зависимости от типа декодируемого кода. Поэтому он может быть реализован только программно.
Быстродействие и экономичность аппаратных решений определяются количеством используемых в алгоритме элементарных операций. Преимущественно использовались операции сложения, изменения знака и сдвига, реализованные на жёсткой логике.
Локализация штрихового кода в изображении сцены.
Постановка задачи.
Алгоритм локализации линейного штрих-кода должен работать в масштабе реального времени (для этого он должен обеспечивать обработку не менее 5 кадров в секунду) и при этом себестоимость изделия должна быть невысокой (сравнимой с аналогами). Учитывая, что объём входной информации (9,6МБ/сек) существенен, последовательная реализация алгоритма будет стоить достаточно дорого, вследствие высоких цен на сигнальные процессоры с высокой тактовой частотой (около 1 GHz ). Должна быть возможность параллелизации алгоритма и при этом паралеллизуемые операции должны быть достаточно простыми или их количество должно быть небольшим.
В первой части алгоритма определяются границы участков, занимаемых штрих-кодом, а во второй ищется отрезок прямой, пресекающей все штрихи и пробелы данной символики. Значения яркости вдоль отрезка передаются на алгоритм выделения структурных элементов.
Алгоритм определения границ участков занимаемых штрих-кодом.
Следует заметить, что штрих-код, также как и текст, имеет довольно резкое, многократно изменяющееся на небольших площадях, значение яркости. Но, в отличие от текста, это изменение имеет определенную пространственную монотонность вдоль штрихов. Таким образом, локально анализируя свойства текстуры изображения, можно различать штрих-код по однонаправленности градиентов яркости на некоторой площади. В алгоритме использовались простейшие локальные дифференцирующие фильтры. Осуществлялась двухмерная фильтрация (1) исходного монохромного изображения, с приведёнными в таблице фильтрующими матрицами (см. табл. 1).
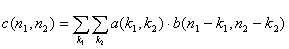 (1)
(1)
a – исходное изображение.
b – фильтрующая матрица.
Получение и распознавание данных штрихкода
Подпишитесь на событие получения
Получение данных
После получения баркодесканнеррепорт можно получить доступ к данным штрихкода и выполнить их анализ. Баркодесканнеррепорт имеет три свойства:
Если вы хотите получить доступ к скандаталабел или скандататипе, необходимо сначала задать для исдекодедатаенаблед значение true.
Получение типа данных проверки
Получение декодированного типа метки штрихкода довольно тривиально, — мы просто вызываем метод Name для скандататипе.
Получение метки данных для проверки
Получение необработанных данных сканирования
Эти данные в целом имеют формат, предоставленный сканером. Однако сведения о заголовках и трейлерах сообщений удаляются, так как они не содержат полезных сведений о приложении и, скорее всего, будут относиться к сканеру.
Общие сведения о заголовке — это префиксный символ (например, символ STX). Распространенные сведения о трейлере — это символ-признак конца (например, символ ЕТКС или CR) и символ проверки блока, если он создан сканером.
Это свойство должно содержать символ символикой, если он возвращается сканером (например, a для UPC-a). Он также должен включать контрольные цифры, если они есть в метке и возвращены сканером. (Обратите внимание, что в зависимости от конфигурации сканера могут присутствовать и символикой символы и контрольные цифры. Сканер вернет их при наличии, но не будет создавать или рассчитывать их, если они отсутствуют.)
Некоторые товары могут быть помечены дополнительным штрихкодом. Этот штрихкод обычно размещается справа от основного штрихкода и состоит из дополнительных двух или пяти символов информации. Если сканер считывает товары, содержащие как основной, так и дополнительный штрихкоды, дополнительные символы добавляются к основным символам, а результат доставляется в приложение в виде одной метки. (Обратите внимание, что сканер может поддерживать конфигурацию, которая включает или отключает чтение дополнительных кодов).
Некоторые товары могут быть помечены несколькими метками, иногда называемыми многосимволными метками или многоуровневые метки. Эти штрихкоды обычно располагаются вертикально и могут быть одного или разных символикой. Если сканер считывает рекламные материалы, содержащие несколько меток, каждый штрихкод передается в приложение в виде отдельной метки. Это необходимо из-за текущего отсутствия стандартизации этих типов штрихкодов. Один из них не способен определить все варианты на основе отдельных данных штрихкода. Таким образом, приложению необходимо определить, когда на основе возвращенных данных был считан штрих-код с несколькими метками. (Обратите внимание, что сканер может не поддерживать чтение нескольких меток.)
Это значение задается до возведения в приложение полученного события.
Поддержка и обратная связь
Получение ответов на вопросы
Помогите нам определить свои вопросы:



