Классификация кодов
Применяемые в технике связи коды можно классифицировать по ряду специфических признаков.
По длине кодов и взаимному расположению в них символов различают равномерные и неравномерные коды.
Равномерные коды имеют одинаковую длину комбинаций. Для равномерного кода число возможных комбинаций составляет 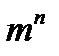 . Примером такого кода является пятизначный код Бодо, применяемый в телеграфии. Код Бодо содержит пять двоичных элементов (m = 2, n = 5). Число возможных кодовых комбинаций в этом коде равно
. Примером такого кода является пятизначный код Бодо, применяемый в телеграфии. Код Бодо содержит пять двоичных элементов (m = 2, n = 5). Число возможных кодовых комбинаций в этом коде равно  , что позволяет кодировать все буквы русского алфавита (твердый знак не передают). Однако этого мало для передачи сообщения на русском языке, содержащего буквы, цифры, знаки препинания и условные знаки (точка, запятая, двоеточие, сложение, вычитание, умножение и т. д.). Поэтому применяют «Международный код №2» (МТК-2). В коде МТК-2 используется регистровый принцип, согласно которому одна и та же пятиэлементная кодовая комбинация может использоваться до трех раз в зависимости от положения регистра: русский, латинский, цифровой. Общее число различных знаков при этом равно 84, что достаточно для кодирования телеграммы.
, что позволяет кодировать все буквы русского алфавита (твердый знак не передают). Однако этого мало для передачи сообщения на русском языке, содержащего буквы, цифры, знаки препинания и условные знаки (точка, запятая, двоеточие, сложение, вычитание, умножение и т. д.). Поэтому применяют «Международный код №2» (МТК-2). В коде МТК-2 используется регистровый принцип, согласно которому одна и та же пятиэлементная кодовая комбинация может использоваться до трех раз в зависимости от положения регистра: русский, латинский, цифровой. Общее число различных знаков при этом равно 84, что достаточно для кодирования телеграммы.
Неравномерные коды отличаются тем, что кодовые комбинации у них отличаются друг от друга не только взаимным расположением символов, но и их количеством при минимизации средней длины кодовой последовательности. Это приводит к тому, что различные комбинации имеют различную длительность.
По признаку помехозащищенности коды, как и методы кодирования, делят на примитивные (первичные, простые, безызбыточные) и помехоустойчивые (корректирующие, избыточные).
Коды, у которых все возможные кодовые комбинации используются для передачи информации, называются примитивными или кодами без избыточности. В простых равномерных кодах превращение одного символа комбинации в другой, например 0 в 1 или 1 в 0, приводит к появлению новой разрешенной комбинации, т.е. к ошибке в принятом сообщении.
Примитивное, или безызбыточное, кодирование применяется для согласования алфавита источника и алфавита канала. Отличительное свойство примитивного кодирования состоят в том, что избыточность дискретного источника, образованного выходом примитивного кодера, равна избыточности источника на входе кодера. Примитивное кодирование используется также в целях шифрования передаваемой информации для ее защиты от несанкционированного доступа и повышения устойчивости работы устройств синхронизации систем связи.
В помехоустойчивых кодах для передачи сообщения используются не все кодовые комбинации, а только некоторая их часть (разрешенные кодовые комбинации). Тем самым создается возможность обнаружения и исправления ошибки при неправильном воспроизведении некоторого числа символов. Корректирующие свойства кодов обеспечиваются введением в кодовые комбинации дополнительных (избыточных) символов.
В настоящее время разработано большое число помехоустойчивых кодов, которые могут быть классифицированы по различным признакам.
По способу кодирования помехоустойчивые коды обычно разбивают на два класса: блочные и непрерывные.
Блочное кодирование состоит в том, что последовательность символов источника сообщений (последовательность нулей и единиц) разделяется на блоки, которые обычно называют кодовыми комбинациями. На практике количество символов в блоке может быть в пределах от 3 до нескольких сотен.

Блоки, содержащие k символов каждый, по определенному закону преобразуются кодером в n-символьные блоки, причем n > k. Например, схема блочного кодера

Каждый символ выходного блока информации получается как сумма по модулю 2 нескольких символов входного блока, для чего используются n сумматоров по модулю 2. Совокупность всех возможных кодовых комбинаций при блочном способе кодирования, и есть блочный код.
Непрерывные коды характеризуются тем, что кодирование и декодирование информационной последовательности символов осуществляется без ее разбиения на блоки. Каждый символ выходной последовательности получается как результат некоторых операций над символами входной последовательности. Кодирование и декодирование непрерывных кодов носит непрерывный характер. При этом результат декодирования предыдущих или последующих символов может повлиять на декодирование текущего символа. Среди непрерывных кодов наиболее часто применяют сверточные коды.
Блочные коды подразделяются на разделимые и неразделимые. К разделимым относятся коды, кодовые комбинации которых состоят из двух частей: информационной и проверочной. Обычно проверочные символы получаются посредством некоторых операций над информационными символами. Разделимые коды условно обозначают в виде (n, k), где n – число символов в кодовой комбинации, k – число информационных символов. Число проверочных символов в разделимых блочных кодах равно r = n-k.
К неразделимым относятся коды, кодовые комбинации которых нельзя разделить на информационные и проверочные части.
Самый большой класс разделимых кодов составляют систематические коды, у которых значения проверочных символов определяются в результате проведения линейных операций над информационными символами. Последовательность линейных операций и число проверочных символов определяется тем, сколько ошибок должен исправлять и обнаруживать данный код. Проверочные символы могут располагаться на любом месте кодовой комбинации. Однако обычно проверочные символы записывают к информационным символам справа, т.е. располагают на месте младших разрядов.
Например, рассмотрим схему наиболее простого систематического кодера (5,4). Здесь всего лишь один проверочный символ формируется из информационных символов путем их суммирования по модулю 2. Этот код называют кодом с проверкой на четность. Так как новую разрешенную комбинацию систематического кода можно получить линейными преобразованиями двух разрешенных, то такие коды часто называют линейными или групповыми.

К несистематическим (нелинейным) относятся коды, в которых проверочные символы формируются за счет некоторых нелинейных операций над информационными символами. Примером нелинейного кода является код Бергера.
4.4 Основные характеристики помехоустойчивых кодов
Основными характеристиками помехоустойчивых кодов являются:
1. Длина кода n – это число символов в кодовой комбинации. Например, комбинация 11010 состоит из пяти символов, следовательно, n=5. Если все кодовые комбинации содержат одинаковое число символов, то код называется равномерным. В неравномерных кодах длина кодовых комбинаций может быть разной.
2. Основание кода m – это число различных символов в коде. Для двоичных кодов символами являются 1 и 0, поэтому m=2.
5. Избыточность кода Ки в общем случае определяется выражением
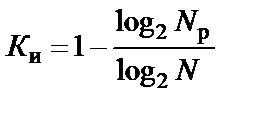
и показывает, какая доля длины кодовой комбинации не используется для передачи информации, а используется для повышения помехоустойчивости кода. Для разделимых кодов
 ,
,
где величина k/n называется относительной скоростью кода.
6. Кодовое расстояние d(А,В) – это число позиций, в которых две кодовые комбинации А и В отличаются друг от друга. Например, если А=01101, В=10111, то d(А,В)=3. Кодовое расстояние между комбинациями А и В может быть найдено в результате сложения по модулю 2 одноименных разрядов комбинаций, а именно
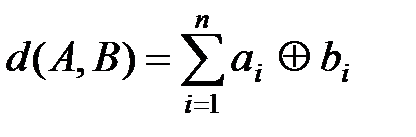 ,
,
где ai и bi – i-е разряды кодовых комбинаций A и B; символ Å обозначает сложение по модулю 2.
Кодовое расстояние между различными комбинациями конкретного кода может быть различным. Так, для первичных кодов это расстояние для различных пар кодовых комбинаций может принимать значения от единицы до величины длины кода.
7. Минимальное кодовое расстояние dmin – это минимальное расстояние между разрешенными кодовыми комбинациями данного кода. Минимальное кодовое расстояние является основной характеристикой корректирующей способности кода. В первичных (безызбыточных) кодах все комбинации являются разрешенными, поэтому минимальное кодовое расстояние для них равно единице (dmin=1). Такие коды не способны обнаруживать и исправлять ошибки. Для того чтобы код обладал корректирующими способностями, его минимальное кодовое расстояние должно быть не менее двух (dmin ³ 2).
Для обнаружения всех ошибок кратностью s и менее, минимальное кодовое расстояние должно удовлетворять условию
Если код используется для исправления ошибок кратности не более t, то минимальное кодовое расстояние должно иметь значение
Для обнаружения s ошибок и исправления t ошибок должно выполняться условие
Таким образом, задача построения кода с заданной корректирующей способностью сводится к обеспечению необходимого кодового расстояния. Увеличение dmin приводит к росту избыточности кода. При этом желательно, чтобы число проверочных символов r было минимальным. В настоящее время известен ряд верхних и нижних границ, которые устанавливают связь между кодовым расстоянием и числом проверочных символов.
Классификация кодов




![]()
![]()
Все коды можно разделить на 2 класса:
1) Простые (примитивные) – для передачи сообщений используются все возможные комбинации. Не вносят избыточности, поэтому не являются помехоустойчивыми.
2) Избыточные (корректирующие, помехоустойчивые) – используют лишь определенную разрешенную часть всех возможных комбинаций. Оставшаяся часть используется для обнаружения и/или исправления ошибок, возникающих при передаче сообщений.
Простые коды разделяют на:
а) равномерные – все кодовые комбинации (КК) имеют одинаковое число разрядов (n=const);
б) неравномерные – КК состоят из разного числа разрядов (n=var).
Коды также классифицируются по основанию кода m или числу различных используемых в нем символов:
Корректирующие коды делятся на блоковые, непрерывные и составные:
(1) Блоковые коды – коды, в которых последовательность элементарных сообщений источника разбивается на отрезки, и каждый из них преобразуется в определенную последовательность (блок) кодовых символов
Всякий линейный код м/б представлен в системной форме: А=(а0, а1, а2,…,аk-1, r10,…,rn-1), где k – количество информационных символов, (n-k) – проверочные символы.
2_ Нелинейные коды – применяются значительно реже. Различают:
а) двоичные циклические коды;
б) m-ичные циклические коды.
3_ Простые с корректирующим бывают:
а) Разделимые коды – коды, в которых определенные разряды КК отводятся для информационных и проверочных символов. Обозначаются как (n,k)-коды, где n – число разрядов КК, k – число разрядов, отводимых для информационных символов.
б) Неразделимые коды – не имеют четкого разделения КК на информационные и проверочные символы. Пример: код 7-10 (МТК №3).
(2) Непрерывныве коды – последовательность символов простого кода преобразуестя по определенному алгоритму в непрерывную последовательность, содержащую как информационные, так и проверочные символы. Здесть процесс кодирования и декодирования носит непрерывный характер.
(3) Составные коды – коды, при формировании КК которых применяется 2 и более методов кодирования.
Перечислите виды классификации кодов
Классификация рассматриваемых в данной главе методов кодирования приведена на рис. 5.2. Эта классификация не является исчерпывающей, в нее включены лишь некоторые методы, которые широко используются в современных системах связи.
Коды можно разделить на две самостоятельные группы. К первой относятся коды, использующие все возможные комбинации – неизбыточные коды. В литературе их еще называют простыми, или первичными. Ко второй группе относятся коды, использующие лишь определенную часть всех возможных комбинаций, такие коды называются избыточными. Оставшаяся часть комбинаций используется для обнаружения или исправления ошибок, возникающих при передаче сообщений. В этих кодах количество разрядов кодовых комбинаций можно условно разделить на определенное число разрядов, предназначенных для информации (информационные разряды), и число разрядов, предназначенных для коррекции ошибок (проверочные разряды).
Обе группы кодов, в свою очередь, подразделяются на равномерные и неравномерные. Равномерные коды – это коды, все кодовые комбинации которых содержат постоянное количество разрядов. Неравномерные коды содержат кодовые комбинации с различным числом разрядов. Ввиду того что неравномерные избыточные коды не нашли применения на практике из-за сложности их технической реализации, в дальнейшем их рассматривать не будем.
Все корректирующие (избыточные) коды делятся на два больших класса: блочные и непрерывные коды (рис. 5.2).

При кодировании блочным кодом последовательность  элементов данных от источника сообщений принимается за блок (сообщение). Каждому возможному блоку из информационных символов ставится в соответствие кодовый блок (слово) длиной
элементов данных от источника сообщений принимается за блок (сообщение). Каждому возможному блоку из информационных символов ставится в соответствие кодовый блок (слово) длиной  . Код называется
. Код называется  – кодом,
– кодом,  . Кодовый блок в канале связи искажается шумом и декодируется независимо от других кодовых блоков.
. Кодовый блок в канале связи искажается шумом и декодируется независимо от других кодовых блоков.
В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат исключительно для коррекции ошибок. Неразделимые коды не имеют четкого разделения кодовой комбинации на информационные и проверочные символы. К ним относятся коды с постоянным весом и коды Плоткина [2].
Разделимые блочные коды, в свою очередь, делятся на несистематические и систематические. Наиболее многочисленный класс разделимых кодов составляют систематические коды. Основная их особенность в том, что проверочные символы образуются как линейные комбинации информационных символов. К систематическим кодам относятся коды с проверкой на четность, коды с повторением, корреляционный, инверсный, коды Хэмминга, Голея, Рида-Маллера, Макдональда, Варшамова, с малой плотностью проверок на четность, итеративный код [2].
В несистематических кодах проверочные символы представляют собой суммы подблоков с  разрядами, на которые разделена последовательность информационных символов. К этим кодам относятся коды Бергера.
разрядами, на которые разделена последовательность информационных символов. К этим кодам относятся коды Бергера.
Разновидностью систематических кодов являются циклические коды. Кроме всех свойств систематического кода, циклические коды имеют следующее свойство: если некоторая кодовая комбинация принадлежит коду, то получающаяся путем циклической перестановки символов новая комбинация также принадлежит данному коду. К наиболее известным циклическим кодам относятся простейшие коды, коды Хэмминга, Боуза-Чоудхури-Хоквингема, мажоритарные, коды Файра, Абрамсона, Миласа-Абрамсона, Рида-Соломона, компаундные коды.
Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
Перечислите виды классификации кодов
Важным понятием при работе с информацией является классификация объектов.
Пример 2.6. Всю информацию об университете можно классифицировать по многочисленным информационным объектам, которые будут характеризоваться общими свойствами:
Свойства информационного объекта определяются информационными параметрами, называемыми реквизитами. Реквизиты представляются либо числовыми данными, например вес, стоимость, год, либо признаками, например цвет, марка машины, фамилия.
Пример 2.7. Информация о каждом студенте в отделе кадров университета систематизирована и представлена посредством одинаковых реквизитов:
Все перечисленные реквизиты характеризуют свойства информационного объекта «Студент».
Кроме выявления общих свойств информационного объекта классификация нужна для разработки правил (алгоритмов) и процедур обработки информации, представленной совокупностью реквизитов.
Алгоритм обработки информационных объектов библиотечного фонда позволяет получить информацию о всех книгах по определенной тематике, об авторах, абонентах и т.д.
Алгоритм обработки информационных объектов фирмы позволяет получить информацию об объемах продаж, о прибыли, заказчиках, видах производимой продукции и т.д.
Алгоритмы обработки в том и другом случае преследуют разные цели, обрабатывают разную информацию, реализуются разными способами.
При любой классификации желательно, чтобы соблюдались следующие требования:
В любой стране разработаны и применяются государственные, отраслевые, региональные классификаторы. Например, классифицированы: отрасли промышленности, оборудование, профессии, единицы измерения, статьи затрат и т.д.
При классификации широко используются понятия классификационный признак и значение классификационного признака, которые позволяют установить сходство или различие объектов. Возможен подход к классификации с объединением этих двух понятий в одно, названное как признак классификации. Признак классификации имеет также синоним основание деления.
Пример 2.9. В качестве признака классификации выбирается возраст, который состоит из трех значений: до 20 лет, от 20 до 30 лет, свыше 30 лет.
Можно в качестве признаков классификации использовать: возраст до 20 лет, возраст от 20 до 30 лет, возраст свыше 30 лет,
Разработаны три метода классификации объектов: иерархический, фасетный, дескрипторный. Эти методы различаются разной стратегией применения классификационных признаков. Рассмотрим основные идеи этих методов для создания систем классификации.
Иерархическая система классификации
Иерархическая система классификации (рис. 2.3) строится следующим образом:
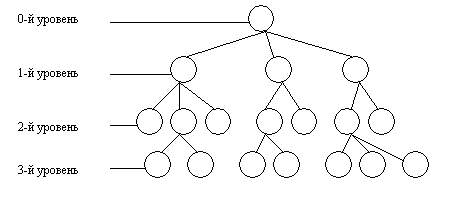
Рис. 2.3. Иерархическая система классификации
Учитывая достаточно жесткую процедуру построения структуры классификации, необходимо перед началом работы определить ее цель, т.е. какими свойствами должны обладать объединяемые в классы объекты. Эти свойства принимаются в дальнейшем за признаки классификации.
Запомните! В иерархической системе классификации из-за жесткой структуры особое внимание следует уделить выбору классификационных признаков.
В иерархической системе классификации каждый объект на любом уровне должен быть отнесен к одному классу, который характеризуется конкретным значением выбранного классификационного признака. Дня последующей группировки в каждом новом классе необходимо задать свои классификационные признаки и их значения. Таким образом, выбор классификационных признаков будет зависеть от семантического содержания того класса, для которого необходима группировка на последующем уровне иерархии.
Количество уровней классификации, соответствующее числу признаков, выбранных в качестве основания деления, характеризует глубину классификации.
Достоинства иерархической системы классификации:
Созданная иерархическая система классификации имеет глубину классификации, равную четырем.
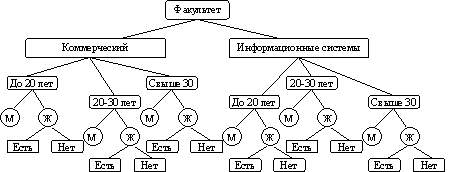
Рис. 2.4. Пример иерархической системы классификации для информационного объекта «Факультет»
Фасетная система классификации
Пример 2.11. Фасет цвет содержит значения: красный, белый, зеленый, черный, желтый.
Фасет специальность содержит названия специальностей.
Фасет образование содержит значения: среднее, среднее специальное, высшее.
Схема построения фасетной системы классификации в виде таблицы отображена на рис. 2.5. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2. Фi. Фn. Например, цвет, размер одежды, вес и т.д. Произведена нумерация строк таблицы. В каждой клетке таблицы хранится конкретное значение фасета. Например, фасет цвет, обозначенный Ф2, содержит значения: красный, белый, зеленый, черный, желтый.
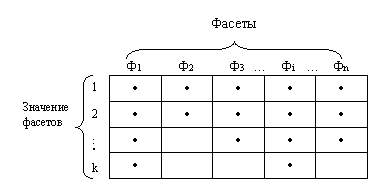 Ф1, Ф2. Фi. Фn
Ф1, Ф2. Фi. Фn
Рис 2.5. Фасетная система классификации
Процедура классификации состоит в присвоении каждому объекту соответствующих значений из фасетов. При этом могут быть использованы не все фасеты. Для каждого объекта задается конкретная группировка фасетов структурной формулой, в которой отражается их порядок следования:
При построении фасетной системы классификации необходимо, чтобы значения, используемые в различных фасетах, не повторялись. Фасетную систему легко можно модифицировать, внося изменения в конкретные значения любого фасета.
Достоинства фасетной системы классификации:
Недостатком фасетной системы классификации является сложность ее построения, так как необходимо учитывать все многообразие классификационных признаков.
Пример 2.12. Обратитесь к содержанию примера 2.10, где показано построение иерархической системы классификации. Для сопоставления разработаем фасетную систему классификации.
Сгруппируем и представим в виде таблицы (рис. 2.6) все классификационные признаки по фасетам:
фасет название факультета с пятью названиями факультетов;
фасет возраст с тремя возрастными группами;
фасет пол с двумя градациями;
фасет дети с двумя градациями.
Структурную формулу любого класса можно представить в виде:
Присваивая конкретные значения каждому фасету, получим следующие классы:
К1=(Радиотехнический факультет, возраст до 20 лет, мужчина, есть дети);
K2=(Коммерческий факультет, возраст от 20 до 30 лет, мужчина, детей нет);
К3=(Математический факультет, возраст до 20 лет, женщина, детей нет) и т.д.
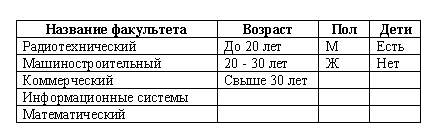
Рис. 2.6. Пример фасетной системы классификации для информационного объекта «Факультет»
Дескрипторная система классификации
Для организации поиска информации, для ведения тезаурусов (словарей) эффективно используется дескрипторная (описательная) система классификации, язык которой приближается к естественному языку описания информационных объектов. Особенно широко она используется в библиотечной системе поиска.
Суть дескрипторного метода классификации заключается в следующем:
Пример 2.13. В качестве объекта классификации рассматривается успеваемость студентов. Ключевыми словами могут быть выбраны: оценка, экзамен, зачет, преподаватель, студент, семестр, название предмета. Здесь нет синонимов, и поэтому указанные ключевые слова можно использовать как словарь дескрипторов. В качестве предметной области выбирается учебная деятельность в высшем учебном заведении. Ключевыми словами могут быть выбраны: студент, обучаемый, учащийся, преподаватель, учитель, педагог, лектор, ассистент, доцент, профессор, коллега, факультет, подразделение университета, аудитория, комната, лекция, практическое занятие, занятие и т.д. Среди указанных ключевых слов встречаются синонимы, например: студент, обучаемый, учащийся, преподаватель, учитель, педагог, факультет, подразделение университета и т.д. После нормализации словарь дескрипторов будет состоять из следующих слов: студент, преподаватель, лектор, ассистент, доцент, профессор, факультет, аудитория, лекция, практическое занятие и т.д.
Между дескрипторами устанавливаются связи, которые позволяют расширить область поиска информации. Связи могут быть трех видов:
синонимические указывающие некоторую совокупность ключевых слов как синонимы;
родо-видовые, отражающие включение некоторого класса объектов в более представительный класс;
ассоциативные, соединяющие дескрипторы, обладающие общими свойствами.
Пример 2.14. Синонимическая связь: студент-учащийся-обучаемый.Родо-видовая связь: университет-факультет-кафедра. Ассоциативная связь: студент-экзамен-профессор-аудитория.
СИСТЕМА КОДИРОВАНИЯ
Система кодирования применяется для замены названия объекта на условное обозначение (код) в целях обеспечения удобной и более эффективной обработки информации.
Код строится на базе алфавита, состоящего из букв, цифр и других символов. Код характеризуется:
Процедура присвоения объекту кодового обозначения называется кодированием. Можно выделить две группы методов, используемых в системе кодирования (рис.2.7), которые образуют:
классификационную систему кодирования, ориентированную на проведение предварительной классификации объектов либо на основе иерархической системы, либо на основе фасетной системы;
регистрационную систему кодирования, не требующую предварительной классификации объектов. Рассмотрим представленную на рис. 2.7 систему кодирования.
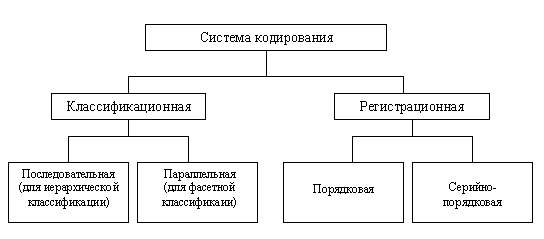
Рис. 2.7. Система кодирования, использующая разные методы
Классификационное кодирование
Классификационное кодирование применяется после проведения классификации объектов. Различают последовательное и параллельное кодирование.
Последовательное кодирование используется для иерархической классификационной структуры. Суть метода заключается в следующем: сначала записывается код старшей группировки 1-го уровня, затем код группировки 2-го уровня, затем код группировки 3-го уровня и т.д. В результате получается кодовая комбинация, каждый разряд которой содержит информацию о специфике выделенной группы на каждом уровне иерархической структуры. Последовательная система кодирования обладает теми же достоинствами и недостатками, что и иерархическая система классификации.
Принятая система кодирования позволяет легко расшифровать любой код группировки, например:
Параллельное кодирование используется для фасетной системы классификации. Суть метода заключается в следующем: все фасеты кодируются независимо друг от друга; для значений каждого фасета выделяется определенное количество разрядов кода. Параллельная система кодирования обладает теми же достоинствами и недостатками, что и фасетная система классификации.
Принятая система кодирования позволяет легко расшифровать любой кол группировки, например:
Регистрационное кодирование используется для однозначной идентификации объектов и не требует предварительной классификации объектов. Различают порядковую и серийно-порядковую систему.
Порядковая система кодирования предполагает последовательную нумерацию объектов числами натурального ряда. Этот порядок может быть случайным или определяться после предварительного упорядочения объектов, например по алфавиту. Этот метод применяется в том случае, когда количество объектов невелико, например кодирование названий факультетов университета, кодирование студентов в учебной группе.
Серийно-порядковая система кодирования предусматривает предварительное выделение групп объектов, которые составляют серию, а затем в каждой серии производится порядковая нумерация объектов. Каждая серия также будет иметь порядковую нумерацию. По своей сути серийно-порядковая система является смешанной: классифицирующей и идентифицирующей. Применяется тогда, когда количество групп невелико.
КЛАССИФИКАЦИЯ ИНФОРМАЦИИ ПО РАЗНЫМ ПРИЗНАКАМ
Любая классификация всегда относительна. Один и тот же объект может быть классифицирован по разным признакам или критериям. Часто встречаются ситуации, когда в зависимости от условий внешней среды объект может быть отнесен к разным классификационным группировкам. Эти рассуждения особенно актуальны при классификации видов информации без учета ее предметной ориентации, так как она часто может быть использована в разных условиях, разными потребителями, для разных целей.
На рис. 2.8 приведена одна из схем классификации циркулирующей в организации (фирме) информации. В основу классификации положено пять наиболее общих признаков: место возникновения, стадия обработки, способ отображения, стабильность, функция управления.
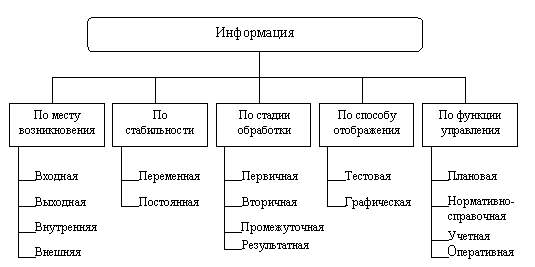
Рис. 2.8. Классификация информации, циркулирующей в организации
Место возникновения. По этому признаку информацию можно разделить на входную, выходную, внутреннюю, внешнюю.
Одна и та же информация может являться входной для одной фирмы, а для другой, ее вырабатывающей, выходной. По отношению к объекту управления (фирма или ее подразделение: цех, отдел, лаборатория) информация может быть определена как внутренняя, так и внешняя.
Стадия обработки. По стадии обработки информация может быть первичной, вторичной, промежуточной, результатной.
Промежуточная информация используется в качестве исходных данных для последующих расчетов.
Результатная информация получается в процессе обработки первичной и промежуточной информации и используется для выработки управленческих решений.
Способ отображения. По способу отображения информация подразделяется на текстовую и графическую.
Стабильность.По стабильности информация может быть переменной (текущей) и постоянной (условно-постоянной).
Переменная информация отражает фактические количественные и качественные характеристики производственно-хозяйственной деятельности фирмы. Она может меняться для каждого случая как по назначению, так и по количеству. Например, количество произведенной продукции за смену, еженедельные затраты на доставку сырья, количество исправных станков и т.п.
постоянная справочная информация включает описание постоянных свойств объекта в виде устойчивых длительное время признаков. Например, табельный номер служащего, профессия работника, номер цеха и т.п.;
постоянная нормативная информация содержит местные, отраслевые и общегосударственные нормативы. Например, размер налога на прибыль, стандарт на качество продуктов определенного вида, размер минимальной оплаты труда, тарифная сетка оплаты государственным служащим;
постоянная плановая информация содержит многократно используемые в фирме плановые показатели. Например, план выпуска телевизоров, план подготовки специалистов определенной квалификации.
Функция управления. По функциям управления обычно классифицируют экономическую информацию. При этом выделяют следующие группы: плановую, нормативно-справочную, учетную и оперативную (текущую).
Пример 2.20. Плановой информацией фирмы могут быть такие показатели, как план выпуска продукции, планируемая прибыль от реализации, ожидаемый спрос на продукцию и т.д.
Нормативно-справочная информация содержит различные нормативные и справочные данные. Ее обновление происходит достаточно редко.
Пример 2.21. Нормативно-справочной информацией на предприятии являются:
время, предназначенное для изготовления типовой детали (нормы трудоемкости);
среднедневная оплата рабочего по разряду;
адрес поставщика или покупателя и т.д.
Пример 2.22. Учетной информацией являются: количество проданной продукции за определенный период времени; среднесуточная загрузка или простой станков и т.п.
Пример 2.23. Оперативной информацией являются:
количество изготовленных деталей за час, смену, день;
количество проданной продукции задень или определенный час;
объем сырья от поставщика на начало рабочего дня и т.д.



