Генетический код: свойства и функции
Генетические функции ДНК заключаются в том, что она обеспечивает хранение, передачу и реализацию наследственной информации, которая представляет собой информацию о первичной структуре белков (т.е. их аминокислотном составе). Связь ДНК с синтезом белка была предсказана биохимиками Дж. Бидлом и Э. Тейтумом еще в 1944 г. при изучении механизма мутаций у плесневого грибка Neurospora. Информация записана в виде определенной последовательности азотистых оснований в молекуле ДНК с помощью генетического кода. Расшифровку генетического кода считают одним из великих открытий естествознания ХХ в. и по значимости приравнивают к открытию ядерной энергии в физике. Успех в этой области связан с именем американского ученого М. Ниренберга, в лаборатории которого был расшифрован первый кодон — YYY. Однако весь процесс расшифровки занял более 10 лет, в нем участвовало много известных ученых из разных стран, и не только биологи, но и физики, математики, кибернетики. Решающий вклад в разработку механизма записи генетической информации был внесен Г. Гамовым, который первым предположил, что кодон состоит из трех нуклеотидов. Совместными усилиями ученых была дана полная характеристика генетического кода.
Основными свойствами генетического кода являются: триплетность, вырожденность и неперекрываемость. Триплетность означает, что последовательность из трех оснований определяет включение в молекулу белка специфической аминокислоты (например, АУГ — метионин). Вырожденность кода заключается в том, что одна и та же аминокислота может кодироваться двумя или несколькими кодонами. Неперекрываемость означает, что одно и то же основание не может входить в состав двух соседних кодонов.
Установлено, что код является универсальным, т.е. принцип записи генетической информации одинаков у всех организмов.
Триплеты, кодирующие одну и ту же аминокислоту, называются кодонами-синонимами. Обычно они имеют одинаковые основания в 1-й и 2-й позициях и различаются только по третьему основанию. Например, включение аминокислоты аланина в молекулу белка кодируют кодоны-синонимы в молекуле РНК — GCA, GCC, GCG, GCY. В составе генетического кода имеются три некодирующих триплета (нонсенс-кодоны — UAG, UGA, UAA), которые играют роль stop-сигналов в процессе считывания информации.
Установлено, что универсальность генетического кода не является абсолютной. При сохранении общего для всех организмов принципа кодирования и особенностей кода в ряде случаев наблюдается изменение смысловой нагрузки отдельных кодовых слов. Это явление получило название неоднозначности генетического кода, а сам код был назван квазиуниверсальным.
Читайте также другие статьи темы 6 «Молекулярные основы наследственности»:
Перейти к чтению других тем книги «Генетика и селекция. Теория. Задания. Ответы»:
Биология. 11 класс
§ 23. Генетический код и его свойства
Как вы знаете, признаки и свойства каждого организма определяются прежде всего белками, которые синтезируются в его клетках. Белки выполняют самые разнообразные функции (вспомните какие), обеспечивая тем самым протекание процессов жизнедеятельности. Можно сказать, что именно от этих биополимеров в первую очередь и зависит существование организма. Однако время функционирования белков, как и многих других биомолекул, весьма ограничено. Поэтому синтез белков в организме должен осуществляться непрерывно. Этот процесс протекает во всех клетках одноклеточных и многоклеточных организмов.
Вам также известно, что хранителем наследственной (генетической) информации, т. е. информации о первичной структуре белков, является ДНК. Участок молекулы ДНК, содержащий информацию о первичной структуре одного белка, получил название ген. Кроме того, генами называют участки ДНК, хранящие информацию о строении молекул рРНК и тРНК.
В биосинтезе белков, который осуществляется в рибосомах, ДНК прямого участия не принимает. Передача генетической информации, содержащейся в ДНК, к месту синтеза белка происходит с помощью посредника. Этим посредником является матричная (информационная) РНК (мРНК, иРНК), которая синтезируется на одной из цепей молекулы ДНК по принципу комплементарности.
В молекулах ДНК и мРНК информация о первичной структуре белков «записана» в виде последовательности нуклеотидов. Сами же белки синтезируются из аминокислот. Значит, в природе существует особая система кодирования, на основании которой последовательность нуклеотидов расшифровывается в виде последовательности аминокислот молекул белков. Этот «шифр» называется генетическим кодом. Таким образом, генетический код — это система записи информации о первичной структуре белков в виде последовательности нуклеотидов ДНК (мРНК).
Генетический код обладает следующими свойствами.
1. Код является триплетным. Это значит, что каждая аминокислота кодируется триплетом (кодоном) — сочетанием трех последовательно расположенных нуклеотидов. В состав молекул ДНК и РНК входит по 4 типа нуклеотидов. Если бы за определенную аминокислоту «отвечал» один нуклеотид, можно было бы закодировать только 4 из 20 белокобразующих аминокислот. Дублетов (по два нуклеотида) хватило бы лишь на 4 2 = 16 аминокислот. Количество возможных триплетов (сочетаний трех нуклеотидов) составляет 4 3 = 64. Этого с избытком хватает для кодирования всех 20 видов аминокислот (табл. 23.1).
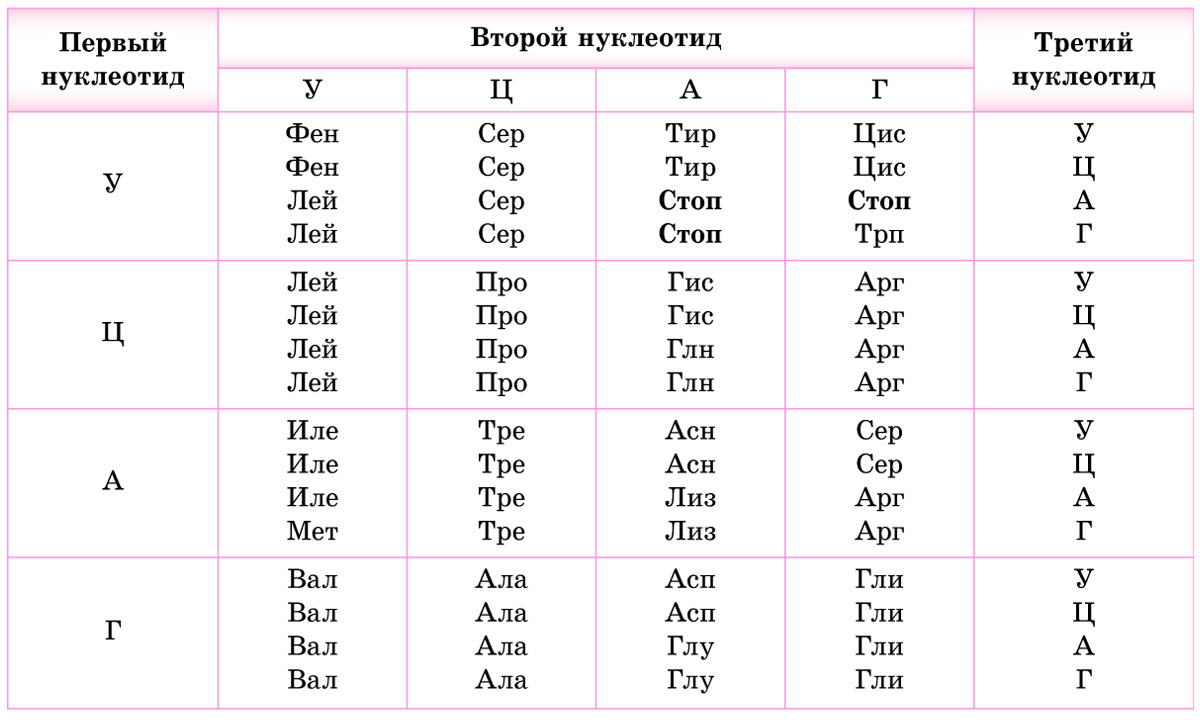
Обратите внимание, что 3 из 64 кодонов (в молекулах мРНК — УАА, УАГ и УГА) не кодируют аминокислоты. Это так называемые стоп-кодоны *или нонсенс-кодоны (от англ. nonsense — бессмыслица)*, они служат сигналом окончания синтеза белка. *Остальные триплеты называются смысловыми.*
* Генетический код расшифровали американские биохимики Р. Холли, Х. Г. Корана и М. Ниренберг в середине прошлого века. Работа стартовала в 1961 г. В бесклеточные системы, содержащие все необходимые компоненты для синтеза белка (рибосомы, аминокислоты, тРНК и др.), ученые сначала вводили искусственно синтезированные мРНК, состоящие только из одного типа нуклеотидов. Было выяснено, что в присутствии, например, полицитидиловой мРНК (ЦЦЦЦЦЦ. ) синтезируется полипептид, состоящий только из остатков аминокислоты пролина, в присутствии полиуридиловой (УУУУУУ. ) — из фенилаланина. Стало понятно, что кодону ЦЦЦ соответствует пролин, а триплет УУУ кодирует фенилаланин. К 1965 г., благодаря использованию искусственно синтезированных молекул мРНК с известными повторяющимися последовательностями нуклеотидов, удалось расшифровать все остальные триплеты. В 1968 г. это открытие было удостоено Нобелевской премии.*
2. Код однозначен — каждый триплет кодирует только одну аминокислоту.
3. Как уже отмечалось, число триплетов превышает количество кодируемых аминокислот. Поэтому генетический код является избыточным (вырожденным) — одна и та же аминокислота может кодироваться разными триплетами. Например, в мРНК цистеин (Цис) может быть закодирован триплетом УГУ или УГЦ, треонин (Тре) — АЦУ, АЦЦ, АЦА или АЦГ. Некоторые аминокислоты, например лейцин (Лей), кодируются шестью различными триплетами, в то же время метионину (Мет) и триптофану (Трп) соответствует только по одному кодону (проверьте по таблице генетического кода).
4. Код не перекрывается — один и тот же нуклеотид не может одновременно входить в состав двух соседних триплетов.
5. Код непрерывен. В полинуклеотидной цепи нуклеотиды располагаются непрерывно и соседние триплеты ничем не отделены друг от друга. Это значит, что фактически деление на триплеты условно — все зависит от того, с какого именно нуклеотида начинается их считывание. Поэтому в клетках считывание информации, содержащейся в генах, всегда начинается со строго определенного нуклеотида.
Если в составе гена происходит изменение количества нуклеотидов (их выпадение или вставка) на число, не кратное трем, наблюдается так называемый сдвиг рамки считывания (рис. 23.1). Это прив одит к существенному изменению последовательности аминокислот в белке, который кодируется измененным геном. В некоторых случаях сдвиг рамки считывания приводит к возникновению стоп-кодонов, из-за чего синтез белка обрывается.
*Суть происходящего при сдвиге рамки считывания можно понять на следующем примере. Прочитайте предложение, составленное из трехбуквенных слов (аналогично триплетам):
ЖИЛ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ.
В этом предложении заключен определенный смысл, понять который можно и без знаков препинания. Выпадение одной буквы аналогично выпадению одного нуклеотида. Оно приводит к изменению порядка считывания и потере смысла:
ЖЛБ ЫЛК ОТТ ИХБ ЫЛС ЕРМ ИЛМ НЕТ ОТК ОТ — выпадение второй буквы.
То же самое произошло бы и после вставки лишней буквы. В случае замены одной буквы либо при изменении их количества на три смысл предложения меняется не столь значительно. Например:
ЖИВ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — замена третьей буквы;
БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение первых трех букв.
Однако смысл предложения (в нашей аналогии — первичная структура белка) во многом зависит от положения измененных букв (нуклеотидов). Так, смысл может существенно исказиться:
ЖИЛ БОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение пятой, шестой и седьмой букв.
Аналогичная ситуация наблюдается и с белками. В зависимости от расположения замененной (утраченной, добавленной) аминокислоты молекула белка может сохранить пространственную конфигурацию и функции, частично изменить их или же полностью утратить свои исходные характеристики.*
Как уже отмечалось, правильное считывание генетической информации обеспечивается только тогда, когда оно начинается со строго определенной позиции. У эукариот стартовым кодоном молекулы мРНК является триплет АУГ. Именно с него и начинается считывание.
6. Код универсален — у всех живых организмов одним и тем же триплетам соответствуют одни и те же аминокислоты. Иными словами, у всех организмов генетический код расшифровывается одинаково (за редким исключением). Это свидетельствует о единстве происхождения живых организмов.
*Некоторые вариации генетического кода обнаружены у бактерий, инфузорий, дрожжей, в коде митохондриальной ДНК и т. д. Например, у бактерий триплет мРНК ГУГ может играть роль стартового кодона, а у эукариот он предназначен только для кодирования аминокислоты валин. В митохондриях млекопитающих триплет УГА кодирует триптофан, в то время как в матричной РНК, синтезированной в ядре клетки, он служит стоп-кодоном. И наоборот, в коде митохондрий триплеты АГА и АГГ являются сигналами окончания синтеза белка, а в «основной версии» генетического кода им соответствует аминокислота аргинин.*
Необходимые сведения из теории кодирования

Длина кодовой комбинации – количество символов в комбинации, обозначаемое буквой n.
Представление информации кодом
Для примера рассмотрим простую систему с основанием m = 2 в виде обычного реле. Как известно, в реле может быть только два сигнала – либо контакт замкнут, либо разомкнут, соответственно передать можно только два сигнала – либо 1 когда контакт реле замкнут и на объекте присутствует напряжение, или 0, если контакт разомкнут, и напряжение на объекте нет. Ниже представлена система из шести реле и возможные кодовые комбинации при различных положениях реле:

Представленную выше систему часто используют для сигнализации. Например, нормальной работа системы будет считаться тогда, когда замкнуты все реле (комбинация 111111). Если на каком-то участке произошел сбой и контакт не был замкнут, то по сигналу легко определить на каком участке произошел сбой. Например, при комбинации 110111 понятно что проблема на участке с Р4, что значительно упрощает устранение причины отказа. Также такую информацию вполне возможно представлять в бумажном виде (распечатанном, например), на перфолентах, в цифровом виде.
Длина всех рассмотренных комбинаций в этом примере равна шести, то есть n = 6 (110111,101101 и так далее).
Также в кодовых комбинациях присутствует такое понятие как вес комбинации, который равен количеству единичных символов в коде и обозначается буквой l. Для комбинации 101101 вес l = 4, 111111 вес l = 6, 110111 вес l = 5.
Классификация кодов
Для удобства использования коды классифицируют. Рассмотрим основные классификации:

Очень часто в технике применяют код типа 2 из 5, имеющего число комбинаций:

У всех комбинаций присущ одинаковый вес l = 2.
Вес определенной n членной комбинации изменяющейся от 0 до n, в общем случае можно выразить биномом Ньютона:

Общее число комбинаций для n = 5:


Рассмотренный выше код (1.2) неполный, так как при его формировании было использовано только восемь комбинаций четного веса при возможных шестнадцати. Из оставшихся восьми нечетных комбинаций также можно сформировать неполный нечетный код.
Код 2 из 5 (1.1) – двухпеременный. Расстояние между смежными комбинациями в данном коде везде равно двум. Если те же комбинации расположить в другом порядке, то можно получить четырехпеременный код:

Если у кода отсутствуют арифметические свойства – он комбинаторный. Формирование комбинаторных кодов производят по законам теории соединений (перестановок, сочетаний, размещений), которая изучается в разделе математики называемом комбинаторикой. Из рассмотренных ранее кодов к комбинаторным относят нечетные, четные, равновесные.
Кодирование информации в эвм (машинные коды)
Способы представления информации в ЭВМ, кодирование и преобразование кодов в значительной степени зависят от принципа действия устройств, в которых эта информация формируется, накапливается, обрабатывается и отображается.
Для кодирования Символьной или текстовой информации применяются различные системы: при вводе информации с клавиатуры кодирование происходит при нажатии клавиши, на которой изображен требуемый символ, при этом в клавиатуре вырабатывается так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши.
Номер нажатой клавиши никак не связан с формой символа, нанесенного на клавише. Опознание символа и присвоение ему внутреннего кода ЭВМ производятся специальной программой по специальным таблицам, например: ДКОИ, КОИ-7, ASCII (Американский стандартный код передачи информации). В настоящее время получил развитие 16-разрядный код Unicode, который позволяет одновременно закодировать все буквы всех известных языков. Для букв русского языка в нем предусмотрены коды 1040…1093. Впервые Unicode использовался в Windows NT.
Всего с помощью таблицы кодирования ASCII (рисунок 3.4) можно закодировать 256 различных символов. Эта таблица разделена на две части: основную и расширенную.

Рисунок 3.4 – Таблица кодирования текстовой информации ASCII
Первая половина таблицы стандартизована. Она не содержит управляющие коды. Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Здесь же размещаются знаки пунктуации и математические знаки, большие и малые латинские буквы.
Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы – управляющие вспомогательные программы, что позволяет набор различных шрифтов.
Дисплей по каждому коду символа выводит на экран изображение символа – не просто цифровой код, а соответствующую ему картинку, так как каждый символ имеет свою форму.
Высвечивание символа на экране дисплея ЭВМ осуществляется с помощью точек, образующих символьную матрицу.
Каждый Пиксел в такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой 0, светлая (яркая) – 1.
Кодирование аудиоинформации – процесс более сложный. Аудиоинформация является аналоговой. Для преобразования ее в цифровую форму используют аппаратурные средства: аналого-цифровые преобразователи (АЦП), в результате работы которых аналоговый сигнал оцифровывается – представляется в виде числовой последовательности. Для вывода оцифрованного звука на аудиоустройства необходимо проводить обратное преобразование, которое осуществляется с помощью цифро-аналоговых преобразователей (ЦАП).
Кодирование числовой информации (машинные коды).
Прямой код двоичного числа образуется из абсолютного значения этого числа и кода знака (нуль или единица) перед его старшим числовым разрядом.
A10=+10 A2=+1010 [A2]П=0:1010;
B10=-15 B2=-1111 [B2]П=1:1111.
Двоеточием здесь отмечена условная граница, отделяющая знаковый разряд от значащих.
Обратный код двоичного числа образуется по следующему правилу. Обратный код положительных чисел совпадает с их прямым кодом. Обратный код отрицательного числа содержит единицу в знаковом разряде числа, а значащие разряды числа заменяются на инверсные, т. е. нули заменяются единицами, а единицы — нулями.
A10=+5 A2=+101 [A2]П=[A2]OK=0:101;
B10=-13 B2=-1010 [B2]OK=1:0010.
Свое название обратный код чисел получил потому, что коды цифр отрицательного числа заменены на инверсные. Укажем наиболее важные свойства обратного кода чисел:
– сложение положительного числа С с его отрицательным значением в обратном коде дает так называемую машинную единицу МЕок= 1: 111… 11, состоящую из единиц в знаковом и значащих разрядах числа;
– нуль в обратном коде имеет двоякое значение. Он может быть положительным – 0: 00…0 и отрицательным числом — 1; 11… 11. Значение отрицательного нуля совпадает с МЕок. Двойственное представление нуля явилось причиной того, что в современных ЭВМ все числа представляются не обратным, а дополнительным кодом.
Дополнительный код положительных чисел совпадает с их прямым кодом. Дополнительный код отрицательного числа представляет собой результат суммирования обратного кода числа с единицей младшего разряда (2° — для целых чисел, 2-k — для дробных).
A10=+19 A2=+10011 [A2]П=[A2]OK=[A2]ДК=0:10011;
B10=-13 В2=-1101 [B2]ДК=[B2]OK+20=1:0010+1=1:0011.
Укажем основные свойства дополнительного кода:
– сложение дополнительных кодов положительного числа С с его отрицательным значением дает так называемую машинную единицу дополнительного кода:
МЕДК=МЕОК+20=10: 00…00, т. е. число 10 (два) в знаковых разрядах числа;
– дополнительный код получил такое свое название потому, что представление отрицательных чисел является дополнением прямого кода чисел до машинной единицы МЕдк.
Модифицированные обратные и дополнительные коды двоичных чисел отличаются соответственно от обратных и дополнительных кодов удвоением значений знаковых разрядов. Знак “+” в этих кодах кодируется двумя нулевыми знаковыми разрядами, а “-” – двумя единичными разрядами.
A10=9 A2=+1001 [A2]П=[A2]OK=[A2]ДК=0:1001
B10=-9 B2=-1001 [B2]OK=1:0110 [B2]ДК=1:0111
Целью введения модифицированных кодов являются фиксация и обнаружение случаев получения неправильного результата, когда значение результата превышает максимально возможный результат в отведенной разрядной сетке машины. В этом случае перенос из значащего разряда может исказить значение младшего знакового разряда. Значение знаковых разрядов “01” свидетельствует о положительном переполнении разрядной сетки, а “10” – об отрицательном переполнении. В настоящее время практически во всех моделях ЭВМ роль удвоенных разрядов для фиксации переполнения разрядной сетки играют переносы, идущие в знаковый и из знакового разряда.
Основное свойства кода 13 букв
Для кодирования растрового рисунка, напечатанного с использованием шести красок, применили неравномерный двоичный код. Для кодирования цветов используются кодовые слова.
Белый — 0, Зелёный — 11111, Фиолетовый — 11110, Красный — 1110, Чёрный — 10. Укажите кратчайшее кодовое слово для кодирования синего цвета, при котором код будет допускать однозначное декодирование.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Заметим, что кодовые слова, начинающиеся с 0, мы взять не можем, поскольку Белый уже закодирован кодовым словом 0. Кодовое слово 10 занято Чёрным. Кодовые слова, состоящие только из единиц, составить нельзя, иначе однозначное декодирование будет негарантированно. Значит, можем взять кодовое слово 110.
По каналу связи передаются сообщения, содержащие только 4 буквы: С, Л, О, Н; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв С, О, Н используются такие кодовые слова: С: 011, О: 00, Н: 11. Укажите такое кодовое слово для буквы Л, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите тот, у которого меньшая длина.
Для того, чтобы код можно было однозначно декодировать, необходимо, чтобы выполнялось условие Фано: никакое кодовое слово не должно являться началом другого кодового слова.
Вариант «1» не удовлетворяет условию Фано. Вариант «10» — удовлетворяет. Вариант «010» удовлетворяет условию Фано. Вариант «0» не удовлетворяет условию Фано.
Выбирая из второго и третьего варианта, останавливаемся на втором, поскольку он короче.
Правильный ответ указан под номером 2.
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Т, О, М; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, М используются такие кодовые слова: Т: 100, О: 00, М: 11. Укажите такое кодовое слово для буквы А, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите тот, у которого меньшая длина.
Для того, чтобы код можно было однозначно декодировать, необходимо, чтобы выполнялось условие Фано: никакое кодовое слово не должно являеться началом другого кодового слова.
Вариант «1» не удовлетворяет условию Фано. Вариант «0» — не удовлетворяет. Вариант «01» удовлетворяет условию Фано. Вариант «101» удовлетворяет условию Фано.
Выбирая из четвёртого и третьего варианта, останавливаемся на третьем, поскольку он короче.
Правильный ответ указан под номером 3.
По каналу связи передаются сообщения, содержащие только 4 буквы К, О, Р, А; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Р, А, К используются такие кодовые слова:
Укажите такое кодовое слово для буквы О, при котором код будет допускать однозначное декодирование. Если таких кодовых слов несколько, укажите то, у которого меньшая длина.
Для того, чтобы код можно было однозначно декодировать, необходимо, чтобы выполнялось условие Фано: никакое кодовое слово не должно являться началом другого кодового слова.
Вариант «1» не удовлетворяет условию Фано. Вариант «0» — не удовлетворяет. Вариант «11» удовлетворяет условию Фано. Вариант «001» удовлетворяет условию Фано.
Выбирая из четвёртого и третьего варианта, останавливаемся на третьем, поскольку он короче.
Правильный ответ указан под номером 3.
По каналу связи передаются сообщения, содержащие только 4 буквы П, О, С, Т; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, П используются такие кодовые слова:
Укажите такое кодовое слово для буквы С, при котором код будет допускать однозначное декодирование. Если таких кодовых слов несколько, укажите тот, у которого меньшая длина.
Для того, чтобы код можно было однозначно декодировать, необходимо, чтобы выполнялось условие Фано: никакое кодовое слово не должно являться началом другого кодового слова.
Вариант «1» не удовлетворяет условию Фано. Вариант «0» — не удовлетворяет. Вариант «00» удовлетворяет условию Фано. Вариант «110» удовлетворяет условию Фано.
Выбирая из четвёртого и третьего варианта, останавливаемся на третьем, поскольку он короче.
Правильный ответ указан под номером 3.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А–111, Б–110, В–100, Г–101.
Укажите, каким кодовым словом может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
Мы видим, что выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова, поэтому однозначно можем раскодировать сообщение с начала.
Чтобы закодировать Д, необходимо выполнение условия Фано в новом коде.
Каждый из этих вариантов может быть новым словом, т. к. не является началом ни одного из кодовых слов. Поэтому выбираем самое короткое — 0.
Правильный ответ указан под номером 1.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
Для того, чтобы сообщение, записанное с помощью неравномерного по длине кода, однозначно раскодировалось, требуется, чтобы никакой код не был началом другого (более длинного) кода.
Рассмотрим варианты для буквы Д, начиная с самого короткого.
1) Д=10: код буквы Д является началом кода буквы Б=101, поэтому этот вариант не подходит.
2) Д=11: код буквы Д является началом кода буквы В=111, Д=110, поэтому этот вариант не подходит.
3) Д=000: код буквы Д не является началом другого кода, следовательно, это правильный ответ.
4) Д=1111: код буквы Д является началом кода буквы В=111, поэтому этот вариант не подходит.
Правильный ответ указан под номером 3.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А — 001, Б — 010, В— 000, Г — 011.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д.
Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
Для того, чтобы сообщение, записанное с помощью неравномерного по длине кода, однозначно раскодировалось, требуется, чтобы никакой код не был началом другого (более длинного) кода.
Рассмотрим варианты для буквы Д, начиная с самого короткого.
1) Д=00: код буквы Д является началом кода буквы В=000, поэтому этот вариант не подходит.
2) Д=01: код буквы Д является началом кода буквы Б=010, Г=011, поэтому этот вариант не подходит.
3) Д=101: код буквы Д не является началом другого кода, следовательно, это правильный ответ.
Правильный ответ указан под номером 3.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А — 111, Б — 110, В — 101, Г — 100.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
Для того, чтобы сообщение, записанное с помощью неравномерного по длине кода, однозначно раскодировалось, требуется, чтобы никакой код не был началом другого (более длинного) кода. Рассмотрим варианты для буквы Д, начиная с самого короткого.
1) Д=1: код буквы Д является началом всех представленных кодов букв, поэтому этот вариант не подходит.
2) Д=0: код буквы Д не является началом другого кода, поэтому этот вариант подходит.
3) Д=01: код буквы Д не является началом другого кода, поэтому этот вариант подходит.
4) Д=10: код буквы Д является началом кодов букв В и Г, следовательно, этот вариант не подходит.
Таким образом, подходят два варианта: 0 и 01. 0 короче, чем 01.
Правильный ответ указан под номером 2.
По каналу связи передаются сообщения, содержащие только четыре буквы: А, Б, В, Г; для передачи используется двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В используются такие кодовые слова: А — 0;
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Для того, чтобы сообщение, записанное с помощью неравномерного по длине кода, однозначно раскодировалось, требуется, чтобы никакой код не был началом другого (более длинного) кода.
Рассмотрим варианты для буквы Г, начиная с самого короткого.
1) Г=1: код буквы Г является началом кода буквы Б — 110, поэтому этот вариант не подходит.
2) Если код Г=01, то условие Фано нарушается, поскольку тогда код буквы А является началом кода буквы Г.
3) Если код Г=101, то условие Фано не нарушается. Данное кодовое слово является кратчайшим для буквы Г.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г использовали соответственно кодовые слова 000, 001, 10, 11. Укажите кратчайшее возможное кодовое слово для буквы Д, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением. Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Однозначные коды не подходят по условию Фано. Кратчайшее подходящее кодовое слово — 01. Но выбирая его, не останется вариантов закодировать букву E, значит, нужно взять минимум трехзначный код. Минимальный из них, подходящий по условию Фано — 010. Тогда букву Е можно закодировать как 011.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г использовали соответственно кодовые слова 000, 001, 10, 11. Укажите кратчайшее возможное кодовое слово для буквы Д, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением. Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Поскольку все однозначные и двузначные слова не подходят по условию Фано, нужно найти трехзначное слово, которое было бы максимально и удовлетряло условию. Так как 111, 101 и 110 нарушают условие Фано, то искомое слово — 010.
Заметим, что двузначное кодовое слово 01 не подходит, поскольку при его использовании нельзя подобрать кодовое слово для буквы Е.
Дублирует задание 13481.
По каналу связи передаются сообщения, содержащие только шесть букв: А, B, C, D, E, F. Для передачи используется неравномерный двоичный код, удовлетворяющий условию Фано. Для букв A, B, C используются такие кодовые слова: А — 11, B — 101, C — 0. Укажите кодовое слово наименьшей возможной длины, которое можно использовать для буквы F. Если таких слов несколько, укажите то из них, которое соответствует наименьшему возможному двоичному числу. Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование
Поскольку все однозначные и двузначные слова не подходят по условию Фано, значит, нужно найти трехзначное слово, которое было бы минимально и удовлетворяло условию. Это слово — 100. Однако при выборе кода 100 мы закрываем возможные варианты для D И E. Значит, трехзначные слова нам тоже не подходят, если взять четырехзначные то там мы для кодирования можем взять слово 1000. Тогда для кодирования D и E можно использовать слова 10010 и 10011.



