Как читать код: 8 принципов, которые стоит запомнить

«Ненавижу читать чужой код», — эту мантру часто можно услышать от разработчиков любого уровня. Тем не менее, это необходимое умение, особенно для разработчиков, которым предстоит освоиться в существующей кодовой базе, и если вы подойдете к этой работе с правильным настроем и правильными инструментами, это может быть весьма приятным и просветляющим опытом.
Мы не любим читать чужой код по той причине, что он написан не нами. Само собой разумеется, что в глубине души мы считаем себя лучшими программистами на планете и никто не сможет написать такой крутой код, как мы. Написание кода — это интенсивный мыслительный процесс, а пассивный читатель не испытывает ничего подобного.
Код, который вы видите на экране, мог быть написан несколькими людьми. Возможно, в процессе споров и сотрудничества. Возможно, им потребовались недели, чтобы выдать код, который обходил какие-то недокументированные ограничения, о которых вам неизвестно, и это знание осталось только в головах тех, кто его писал.
Все, что вы увидите как читатель — это законченный продукт. И если не провести некоторых раскопок, единственный контекст, с которым вы будете работать — это тот самый код на вашем экране.
1. Учитесь копать
Когда вы впервые знакомитесь с серьезной кодовой базой, возможно, вы не будете чувствовать себя разработчиком. Скорее вы будете себя чувствовать археологом, частным сыщиком, или исследователем религиозных книг. Это вполне нормально, ведь в вашем распоряжении есть несколько инструментов для «раскопок». Если вам повезло, и ваши предшественники использовали контроль версий, это стоит отпраздновать! У вас есть доступ к богатству метаданных, и это очень сильно облегчит вам понимание контекста, в котором создавался код. Далее я исхожу из того, что вы используете Git, но в случае с SVN, все будет примерно так же.
git blame
git log
2. Вернитесь в прошлое
Вы можете переключиться на какой угодно коммит и запустить проект так, как будто бы этот коммит был последним. Вам может понадобиться переключиться на коммит, который был последним перед появлением какой-нибудь сложно отслеживаемой проблемы. А может вам просто станет скучно и вы захотите покопаться в истории кода и увидеть, каким был проект за годы до того, как вы туда пришли.
Если проект хранится на GitHub или подобном сервисе, вы можете получить уйму информации, читая тикеты, пулл-реквесты и код-ревью. Обращайте внимание на тикеты, в которых было больше всего обсуждений. Там могут быть «болевые точки», с которыми вы можете столкнуться в будущем, поэтому хорошо бы заранее иметь о них представление.
3. Читайте спецификации
Спецификации — это новые комментарии. Читайте юнит-спецификации, чтобы выяснить предназначение функций и модулей, и возможные пограничные случаи (edge-cases), которые они обрабатывают. Читайте интеграционные спецификации, чтобы выяснить, как пользователи будут взаимодействовать с вашим приложением и какие процессы поддерживает ваше приложение.
4. Думайте о комментариях, как о подсказках
Если вы наткнулись на непонятную функцию и прочли комментарий к ней, который еще больше вас запутал, возможно, что этот комментарий просто устарел и не обновлялся.
Глаза программиста имеют способность пропускать пропускать зеленый текст комментариев, и возможно, что этот поставивший вас в тупик комментарий относился к функции, которая исчезла уже много месяцев (или лет) назад, и никто, кроме вас, этого не заметил.
5. Найдите Main
Это может казаться очевидным, но в первую очередь убедитесь, что вы понимаете, где код начинает исполнение и что происходит в процессе запуска. Посмотрите, какие файлы подключаются, какие классы инстанцируются, какие опции конфига устанавливаются.
Скорее всего, вы будете постоянно сталкиваться с ними и в остальном коде. Некоторые модули будут иметь очень общее назначение, и будут выделяться из остального кода. Они представляют собой более маленькие и понятные кусочки функционала, с которыми вам следует познакомиться перед тем, как пытаться разобраться со всем приложением полностью.
Выполните git blame на этом файле и посмотрите, какие части основного файла были изменены недавно. Недавно измененный код может подсказать вам, над какими проблемами работала команда в последнее время. Возможно, они представили новую библиотеку, или долго пытались наладить библиотеку, которая не слишком хорошо работала. А может быть, там просто какой-то бойлерплейт код, который нужно регулярно обновлять.
Попробуйте найти отсылки к этим модулям в других частях кода, чтобы понять, как и когда они используются. Это может помочь вам понять место и роль модулей в основном приложении.
6. Обращайте внимание на стиль.
Вы ведь изучаете это приложение не просто так, и рано или поздно ваш код тоже туда попадет, поэтому обращайте внимание на стиль. Это включает в себя такие вещи как соглашение о стандартах оформления кода: именование, пробелы, скобки, а также соглашение о написании кода.
Каков общий уровень абстракции? Если это высокоабстрактный код со многими уровнями абстракции, то вам следует писать так же. Если вы хорошенько покопались в истории, то наверное сможете найти момент, когда один из разработчиков решил абстрагировать часть кода. Как он выглядел до этого, и что стало с ним после выноса на новый уровень абстракции? Пытайтесь следовать тем же соглашениям, когда пишете свой код.
7. Ожидайте встретить мусор
Вам могут встретиться функции, а может, и целые файлы, которые никогда не используются. Вы можете встретить закомментированный код, который простоял нетронутым несколько лет ( git blame в помощь). Не тратьте на это слишком много времени, и не бойтесь избавляться от подобных артефактов.
Если этот код был нужен, кто-нибудь отметит это на код-ревью. А вы сделаете доброе дело, уменьшив количество умственной нагрузки для следующего, кто будет читать этот код.
8. Не отчаивайтесь
Держите предыдущие пункты в голове, и не падайте духом, если чувствуете, что совершенно запутались. Изучение кода — это не линейный процесс, не ожидайте сразу понять все на 100%. Обращайте внимание на важные детали и знайте, как копать, чтобы найти ответы на вопросы, и вы довольно быстро обнаружите, что все становится понятно.
Автор: Уильям Шон, консультант и разработчик в Ann Arbor. Оригинал здесь.
Не судите чужой код строго
Так сложилось что большую часть своей сознательной жизни я программирую на PHP. Наш мозг, воспринимая информацию из любого источника, делает это без отрыва от авторитетности этого источника. Грубо говоря, если вы любите PHP — вы автоматически добавили очков авторитетности автору этой статьи, а если не любите — автоматически отняли. Этот процесс происходит на бессознательном уровне и является по сути призмой восприятия, которая с одной стороны защищает нас от падения в бесконечный анализ информации любой степени авторитетности, но с другой стороны ограничивает нас в поиске новой более актуальной информации. Самое поганое здесь то, что авторитетность источника редко когда проверяется на сознательном уровне (потому что на это нужны время и ресурсы в виде драгоценных калорий), я могу быть с той же долей вероятности разработчиком плюсов, домохозяйкой-кухаркой, водопроводчиком без принцессы или генетически модифицированным котом. Не судите мою статью строго, у меня лапки.
То же самое относится к чтению чужого кода: если его автор сидит по левую руку от вашего трона, работает в вашей фирме 10+ лет и зарабатывает на один ноль больше вас, это совершенно не то же самое, что автор, которого уволили за что-то плохое, а вас наняли на его место. Но по сути то и там и там код — это всего лишь набор байтов, которые было бы полезно оценивать без привязки к авторитетности источника.
Когда мы читаем чужой код, нас могут посещать самые разнообразные эмоции: восхищение, смех, раздражение, разочарование, полное неприятие. Полезно знать о том что проявление любых эмоций в любом контексте — это автоматический ответ низшего (первого) уровня нервной системы, сформированный эволюционным путем, необходимый в первобытной среде. Основная задача такого ответа, в случае «негативной» эмоции — запустить механизм действий «бей или беги» с одной единственной целью — выжить. В нашей текущей офисной среде при анализе чужого кода подобный ответ становится скорее бесполезным и даже вредным, поскольку вы тратите на него драгоценное время и ресурсы, плюс загрязняете свой мозг нейромедиаторами, понижающими вашу сообразительность в угоду скорости реакции. Хорошая новость в том что этот ответ можно перепрограммировать. Можно подавлять негативные эмоциональные реакции, а можно их инвентировать, например, смеяться там где вы раньше злились. Смех, в отличие от злости, выбрасывает в мозг хорошие вкусные полезные нейромедиаторы, доставляющие удовольствие, закрепляющие опыт и мотивирующие на дальнейшую работу.
Для того чтобы перепрограммировать эмоцию, нужно мысленно выйти в мета-позицию, чтобы вместо осуждения чужого кода оценить собственную обстановку, оценить себя. Почему этот кусок чужого кода вызывает во мне отвращение? Действительно ли дело в том что его писал дилетант, а мне такому хорошему и опытному теперь приходится страдать? Если я такой хороший и опытный, то почему у меня возникают проблемы с тем чтобы понять чужой код и переписать его так как я считаю нужным? Возможно мне просто не хватает оперативной памяти для того чтобы осознать эту лапшу? Возможно автор этого куска знает что-то чего не знаю я?
Современные средства разработки позволяют практически на лету преобразовывать чужой код в более понятные и приятные структуры. Функция или переменная плохо названа — ctrl+shift+R и в пару секунд она называется по хорошему. Табуляции вместо пробелов, неудобно, непривычно раскиданы отступы и открывающиеся бракеты в египетском стиле — ctrl+shift+F и форматирование восстановлено! Комментарий избыточен или устарел — ctrl+D и его нет. Если изменить призму восприятия, чтение чужого кода может превратиться в увлекательную интерактивную детективную игру.
Код это всего лишь инструмент. Как бы плохо и ужасно он не был написан, в конкретное время и в конкретном месте он успешно решал конкретную проблему, а значит он уже «оправдан». Что-то изменилось в бизнес-требованиях, что то было не учтено — код поломался или стал не актуален, и это нормально. Код имеет свойство эволюционировать самыми разными путями: и постепенно, обрастая пластами и революционно, переписываясь с нуля. Конечно хорошо, когда программист предвидит будущее и на начальных этапах закладывает в код возможности для дальнейшего его развития. Но эта секира остра с двух сторон, вы можете ошибиться с предсказыванием будущего, будущее может не наступить вовсе, а время и ресурсы будут безвозвратно утеряны. Тут важно понимать код какой степени качества от вас требуется. Если это огромная распределенная система, модули к которой программируют ваши коллеги из самых разных точек земного шара в фирмах слабо связанных с вашей, тогда да, имеет смысл использовать модные паттерны, оборачивать модули в сервис-контейнеры даже там где вы не можете себе представить зачем это нужно. Но если это маленькая локальная CRM для одной фирмы, модули которой зависят друг от друга настолько жестко, что отключение любого модуля по сути ведет к остановке работы всей системы… в этом случае вполне оправданно вызывать чужие методы напрямую, это уменьшит количество классов, облегчит вашу оперативную память и сократит время на отладку проблем. Но вот возникает ситуация когда маленькая локальная CRM превращается в нечто расширяемое, что ваша фирма хочет выложить в открытый доступ и продавать. Бизнес-требования изменились. Стоит ли винить программиста в том что он не предвидел этого?
Стандартизация
Код это всего лишь инструмент, но его создание — это чистое творчество. Любую задачу можно решить бесконечным числом самых разнообразных способов. Некоторые из них более производительны, чем другие — пример объективной оценки. Некоторые из них более читабельны, чем другие — пример субъективной оценки. Даже если вы убедите весь офис в том что какой-то кусок кода не читабелен, все еще останется как минимум один автор, который с вами не согласится. Стандартизация кода направлена на то чтобы преобразовать чистое творчество в как можно более рутинный набор действий для того чтобы другим программистам было проще разбираться в вашем коде. То есть, по сути, чтобы вас можно было заменить другим специалистом, более покладистым и дешевым. А через пару десятков лет так и вовсе искусственным интеллектом. Стоит помнить, что если какой-то стандарт противоречит здравому смыслу, возможно его имеет смысл нарушать в некоторых местах, а то и вовсе отказаться от него или заменить на другой, более подходящий.
Матёрые стандарты продают себя с позиции «при выборе стандарта обратите внимание на популярность сообщества». Интересно как они продавали себя когда только-только вышли в свет. Основная мысль в том, что популярность того или иного стандарта это не тот фактор, который вы бы хотели учитывать в первую очередь при выборе. Популярность и сообщества очень инертны и могут на протяжении многих десятилетий отвергать новые более хорошие стандарты. Особенно если они революционны.
Аналогичные примеры встречаются сплошь и рядом и в культуре программирования. Стандарт PSR ратует за 4 пробела вместо табуляции, игнорируя очевидный факт: среда разработки большинства PHP-программистов изменилась с консольных редакторов на полноценные IDE, в которых оперировать табуляциями удобнее во многих смыслах: и удалять проще, нажимая Backspace один раз, и настроить можно индивидуальную длину табуляции по вкусу.
Применяя тот или иной стандарт задавайтесь вопросом: кому вы делаете удобнее? Кому неудобнее? Кому станет лучше от правила «именуем имена методов лоуерКамелКейсом»? Очевидно лишь тем, кто привык их так именовать. Всем остальным станет неудобно, им придется адаптироваться, а это потери времени и ресурсов абсолютно на пустом месте, учитывая то что
а) теперь у нас есть волшебные IDE, подсвечивающие разными цветами разные элементы кода,
б) программисты имеют свойство перескакивать с проекта на проект, стандарты кодирования в которых могут различаться.
Лично я при разработке своих проектов использую:
Умение разбираться в чужом коде
Триггер, вызывающий рвотные порывы у подавляющего большинства программистов (пример субъективной оценки). Вам никогда не казалось странным, что зачастую нам проще переписать весь код с нуля, чем разбираться в чужом? В любой другой отрасли мы действуем иначе: сперва учимся читать, потом — писать; сперва пользоваться (электроприборами, зданиями), затем — их проектировать. Мне кажется все дело в нашем образовании (конкретно в области программирования). Нас учат достигать цели самым прямым и быстрым способом, используя некоторые свеже-приобретенные знания. В результате мы комбинируем их (знания) ровно до тех пор пока «оно» не заработает, немного тестируем и отправляем учителю на модерацию. На мой взгляд было бы неплохо добавить в этот процесс дополнительную ступень, на которой мы сравниваем наш код с мастер-кодом, который хоть и не является идеальным и единственно правильным, но дает альтернативный путь решения, зачастую более оптимальный и читабельный.
Что касается триггера, чтобы его отключить, достаточно просто мысленно поставить себя на место заказчика, который всю свою жизнь наблюдает за уходящими-приходящими программистами, утверждающими что работа их предшественников это фекалии и нужно все переписать чтобы стало хорошо. Заказчик не обладает компетенцией чтобы выяснить говорите ли вы правду или просто ленитесь разбираться в чужом коде. Чтобы завоевать его доверие в подобном вопросе, следует покопаться в чужом коде и найти парочку гигантских дыр в безопасности и продемонстрировать их заказчику. Но даже в этой ситуации с точки зрения бизнеса, возможно, будет выгоднее «закостылить». Особенно если это аутсорс с конкретными сроками и деньгами. Нужно ли винить программиста в этом?
Чужой код
Найдены дубликаты

Баяны
177K постов 11.9K подписчиков
Правила сообщества
Сообщество для постов, которые ранее были на Пикабу.
Для полного щщастя тэга «моё» не хватает.
Это кажется с башорга начала 2000-ых
ахаха )) боян не боян, не видел )
Про швабры надо запомнить))
Но ведь фсё продумал. Нех было переделывать. А так учёл все варианты.
программисты не задумываясь работают с чужим кодом, если им этого кода не видно.
Базар двух тупорылых школьников
Ну первый понятно кто. А второй?

О коде



Мозги
И исходники в комментариях


И еще один секрет: если хочешь писать без багов — пиши
Шкала удовольствия
Баг в моем коде | Я пытаюсь решить это в 2 часа ночи


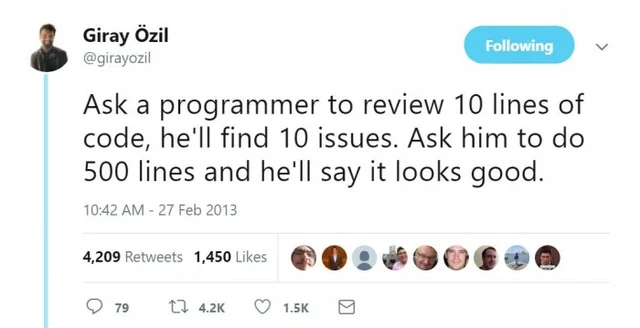
Что насчет 5000?
Попросии программиста посмотреть 10 строчек кода, он найдет 10 проблем. Попроси посмотреть 500 строчек, Он скажет, что он выглядит хорошо


Российский программист получил восемь лет тюрьмы за создание утилиты для обработки логов ботнетов
Министерство юстиции США сообщило о вынесении приговора российскому программисту Александру Бровко.
Еще в 2019 году 36-летний Александр Бровко был арестован в Чехии, откуда его экстрадировали в США в связи с масштабным расследованием деятельности российских хакерских группировок. По заявлению правительства США, Бровко был «членом элитных онлайн-форумов, созданных для русскоязычных киберпреступников, где те обмениваются инструментами и услугами для совершения преступлений».
Согласно судебным документам, Бровко родился и вырос в России, имел диплом системного инженера, но в какой-то момент потерял работу в полиграфическом и рекламном бизнесе «из-за разногласий с руководством компании». Тогда Бровко стал работать на своего бывшего одноклассника, «который нуждался в помощи для направления интернет-трафика на определенные сайты», и это стало его точкой входа в мир киберпреступников. Бровко говорит, что ему было стыдно за ту работу, но найти другую он не мог.
В итоге Бровко стал работать с Александром Твердохлебовым, который эмигрировал из России в 2007 году, получил американское гражданство и проживал в Калифорнии. В 2017 году Твердохлебов был арестован и отправлен в тюрьму на девять лет, так как управлял ботнетом, который насчитывал около 500 000 зараженных компьютеров. В обвинительном заключении Бровко от 2018 года Твердохлебов фигурирует под инициалами «А.Т.».
Благодаря своему ботнету Твердохлебов имел доступ к тысячам взломанных машин, и его малварь похищала имена пользователей и пароли с этих компьютеров. Бровко было поручено проанализировать логи ботов и найти в них учетные данных от интернет-банкингов. Впоследствии эта информация использовалась для кражи миллионов долларов со счетов американцев (посредством мошеннических переводов).
В итоге Бровко написал программу для автоматического скрапинга этих данных. Также он вручную проверял, работают ли обнаруженные комбинации имени пользователя и пароля для банковских счетов пользователей. Прокуроры утверждают, что он выписывал данные о количество денег на счетах пострадавших, стремясь найти наиболее «выгодных» жертв.
За все это Бровко получал от Твердохлебова около 70 000 долларов в год, и на эти деньги, по утверждению адвоката, содержал жену и сына. Также документы гласят, что Бровко оказывал услуги другим хакерам и даже пытался самостоятельно продавать банковскую информацию жертв другим преступникам. Когда полиция провела обыск в его доме, было изъято большое количество оборудования, которое затем использовали в качестве доказательств в суде.
Ужасы чужого кода: как найти смысл и не умереть
Даже самым крутым программистам трудно читать чужой код. Узнайте, почему это так страшно и как с этим справиться.
В жизни каждого разработчика наступает момент, когда нужно взяться за код, написанный другим человеком. Это может быть связано с поддержкой старого проекта, оптимизацией legacy-кода, переделыванием приложения, которое не доделал другой программист.
Хорошо, если этот код написан по архитектурному паттерну, у него есть документация, комментарии или хотя бы понятные названия переменных. Однако чаще всего приходится работать с говнокодом (это термин, если что).
В этой статье я опишу личный опыт чтения ужасного кода. Поэтому приготовьтесь сначала лицезреть моё страдание и только потом получить какие-то полезные советы.

Пишет о программировании, в свободное время создает игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Виновник торжества
Мне и раньше приходилось сталкиваться с плохим кодом (например, своим), но недавно попался настолько ужасный, что я решил написать об этом статью.
Для начала попробуйте понять, что делает этот цикл, зная только, что приложение работает с 3D-графикой:
Первое, что бросается в глаза, — нарушение традиций в выборе имени счётчика.

Чтобы разобраться, что тут происходит, нужно понять, что такое msh, object и gm. С последним всё предельно просто:
Теперь остаётся только понять, что такое oo. Это очень хороший вопрос, потому что oo — это глобальная переменная, объявление которой нужно ещё поискать.
Вот другой фрагмент:
Название метода не вносит никакой ясности. Не говоря уже о том, что разработчик игнорирует соглашение об идентификаторах. Он даже единого стиля не придерживается, потому что в этом же файле можно встретить метод, который называется getPointOfIntersection ().

Складывается ощущение, что разработчик не знает главного правила программирования:

«Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живёте».
Как с этим жить
Очевидно, что невозможно заставить всех писать чистый и понятный код. Поэтому единственный выход — научиться читать всё, что попадается под руки. Это умение можно разделить на два навыка: чтение и расшифровка (эти названия условные).
Расшифровка может пригодиться, когда нужно срочно понять, как работает код. Особенно если он настолько ужасный, что просто пытаться вникнуть в проект — глупо. Рассмотрим на примере:
Это достаточно небольшой метод, который, однако, записан таким образом, что невозможно понять, что он делает. В этом случае не стоит тратить силы, чтобы вникнуть, — лучше сразу привести его в человеческий вид.
Для начала можно расставить пробелы и переносы строк:
Сделать это можно с помощью специальных инструментов, но лучше попробовать вручную. Возможно, в процессе получится что-то понять. Попутно можно добавить комментарии:
Становится понятно, что метод проверяет коллизию двух двумерных объектов. Поэтому можно поменять названия переменных и самого метода:
Когда весь код приобретёт более-менее человеческий вид, можно будет провести рефакторинг:
Например, можно вместо координат принимать объекты:
Всё это должно помочь разобраться в коде здесь и сейчас. Если же нужно постоянно работать с чужими проектами, то есть смысл попрактиковаться в чтении. Есть несколько простых советов, которые помогут в этом нелёгком деле.
1. Пробуйте писать в разных стилях
Обычно я пишу вот так:
Даже если нужно выполнить одну инструкцию, я всё равно использую фигурные скобки. Мне кажется, так легче понять, что является частью ветвления, а что — нет.
Но иногда стоит посмотреть, как пишут другие, и попробовать так же. Например, вот так:
Если часто практиковаться, можно привыкнуть, и тогда читать такие конструкции будет проще.
2. Читайте чужой код
Попробуйте зайти в случайный репозиторий на GitHub и разобраться, как там всё устроено и как оно работает. Изучите несколько проектов, чтобы научиться понимать разные стили.
Подумайте, почему разработчик пишет так, а не иначе, как он составляет документацию и так далее. Так вы не только научитесь читать чужой код, но и, возможно, найдёте пару интересных приёмов, которые захотите использовать сами.
3. Давайте другим читать ваш код
Дайте другому разработчику посмотреть ваш проект. Сразу будьте готовы к тому, что ваш код тоже так себе. Обратная связь поможет понять, что вы делаете не так, а если повезёт, получите несколько рекомендаций, как улучшить свой код.
В процессе вы можете понаблюдать, что делают более опытные коллеги, чтобы вникнуть в ваш проект.
4. Попробуйте прочесть код, который писали давно
Скорее всего, сначала вы ничего не поймёте, а потом почувствуете сильный стыд. Это нормально и случается со всеми программистами.

Сейчас вы уже лучше, чем были когда-то давно, поэтому сможете увидеть, что делали не так. Возможно, вы заметите, что до сих пор используете те же самые приёмы, и исправите это.
5. Больше рефакторинга
Иногда код необходимо переделать, даже если он работает. Конечно, это касается в первую очередь проектов, которые нужно поддерживать. Если не прибегать к рефакторингу, то придётся постоянно держать в голове весь плохой код, чтобы не приходилось каждый раз вникать заново. Кроме того, вы вряд ли заметите баги и уязвимости, потому что весь код выглядит как одна большая уязвимость.
Заключение
Последний совет: не обманывайте себя. Вы, я и любые другие разработчики пишут ужасно. Просто потому, что так устроено программирование — приложения не могут быть безупречными и совсем понятными.

Однако это не значит, что можно окончательно забить на чистоту и читаемость кода. Просто нужно понимать, что мастерство в программировании, как и в любом другом деле, это не пункт назначения — это сам путь.
Нужно стремиться к тому, чтобы писать совершенный код, но помнить, что не нужно зацикливаться на этом. Именно так мы подходим к обучению на курсе «Профессия C#-разработчик». Студенты учатся писать чистый, поддерживаемый код с документацией, который не стыдно показать коллегам.
Профессия C#-разработчик
130 часов — и вы научитесь писать программы на языке, созданном Microsoft. Вы создадите 5 проектов для портфолио, даже если до этого никогда не программировали. После обучения — гарантированное трудоустройство.



