ASCII таблица

ASCII — A merican S tandard C ode for I nformation I nterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL \0 | & #000; | Null char | |
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT \t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF \n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR \r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
ASCII


ASCII (англ. American Standard Code for Information Interchange ) — американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов. В американском варианте английского языка произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски произносится также [а́ски] или [аски́].
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованным 8-м битом и второй половиной кодовой таблицы (например КОИ-8).
Содержание
Наложение символов
Благодаря символу BS (возврат на шаг) на принтере можно печатать один символ поверх другого. В ASCII было предусмотрено добавление таким образом диакритики к буквам, например:
Примечание: в старых шрифтах апостроф ‘ рисовался с наклоном влево, а тильда
была сдвинута вверх, так что они как раз подходили на роль акута и тильды сверху.
Если на символ накладывается тот же символ, то получается эффект жирного шрифта, а если на символ накладывается подчёркивание, то получается подчёркнутый текст.
Примечание: это используется, например, в справочной системе man.
Национальные варианты ASCII
Стандарт ISO 646 (ECMA-6) предусматривает возможность размещения национальных символов на месте @ [ \ ] ^ `
. В дополнение к этому, на месте # может быть размещён £, а на месте $ — ¤. Такая система хорошо подходит для европейских языков, где нужны лишь несколько дополнительных символов. Вариант ASCII без национальных символов называется US-ASCII, или «International Reference Version».
Для некоторых языков с нелатинской письменностью (русского, греческого, арабского, иврита) существовали более радикальные модификации ASCII. Одним из вариантов был отказ от строчных латинских букв — на их месте размещались национальные символы (для русского и греческого — только заглавные буквы). Другой вариант — переключение между US-ASCII и национальным вариантом «на лету» с помощью символов SO (Shift Out) и SI (Shift In) — в этом случае в национальном варианте можно полностью устранить латинские буквы и занять всё пространство под свои символы. См. также КОИ-7.
Впоследствии оказалось удобнее использовать 8-битные кодировки (кодовые страницы), где нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. Таким образом, верхняя половина таблицы ASCII до повсеместного внедрения Юникода активно использовалась для представления локализированных символов, букв местного языка. Отсутствие единого стандарта размещения кириллических символов в таблице ASCII доставляло множество проблем с кодировками (КОИ-8, Windows-1251 и другие). Другие языки с нелатинской письменностью тоже страдали из-за наличия нескольких разных кодировок.
В Юникоде первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
Кодировка
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0. | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1. | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2. | ! | « | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3. | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | ? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4. | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5. | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6. | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7. | p | q | r | s | t | u | v | w | x | y | z | < | | | > | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0. | NUL | SOM | EOA | EOM | EQT | WRU | RU | BELL | BKSP | HT | LF | VT | FF | CR | SO | SI |
| 1. | DC0 | DC1 | DC2 | DC3 | DC4 | ERR | SYNC | LEM | S0 | S1 | S2 | S3 | S4 | S5 | S6 | S7 |
| 2. | ||||||||||||||||
| 3. | ||||||||||||||||
| 4. | BLANK | ! | « | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 5. | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | ? | |||
| 6. | ||||||||||||||||
| 7. | ||||||||||||||||
| 8. | ||||||||||||||||
| 9. | ||||||||||||||||
| A. | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| B. | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ↑ | ← |
| C. | ||||||||||||||||
| D. | ||||||||||||||||
| E. | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
| F. | p | q | r | s | t | u | v | w | x | y | z | ESC | DEL |
На тех компьютерах, где минимально адресуемой единицей памяти было 36-битное слово, поначалу использовали 6-битные символы (1 слово = 6 символов). После перехода на ASCII на таких компьютерах в одном слове стали размещать либо 5 семибитных символов (1 бит оставался лишним), либо 4 девятибитных символа.
ASCII-коды используются также для определения нажатой клавиши при программировании. Для стандартной QWERTY-клавиатуры таблица кодов выглядит следующим образом:
Представление символов, таблицы кодировок
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
Кодировки стандарта ASCII ( [math]8[/math] бит):
Структурные свойства таблицы [ править ]
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство [ править ]
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^<31>[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^<16>[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы [ править ]
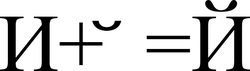
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления [ править ]
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 [ править ]
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования [ править ]
Правила записи кода одного символа в UTF-8 [ править ]
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8 [ править ]
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16 [ править ]
UTF-16LE и UTF-16BE [ править ]
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32 [ править ]
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Порядок байт [ править ]
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
[math]M = \sum_
Варианты записи [ править ]
Порядок от старшего к младшему [ править ]
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему [ править ]
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок [ править ]
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок [ править ]
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия [ править ]

Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт [ править ]
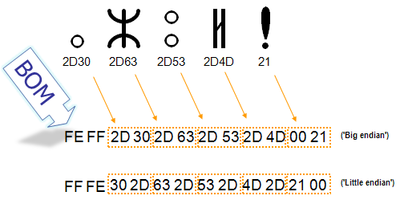
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода [ править ]
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.



