Кодировка base64 что это
Если Интернет является информационной магистралью, то в случае с электронной почтой имеются ограничения. Через нее могут передаваться только небольшие данные.
Так как же проехать на грузовике через это маленькое ущелье?
Мы должны разобрать наш грузовик на части и переправить эти части с одного конца на другой.
То же самое происходит, когда вы отправляете вложения по электронной почте. В процессе, известном как кодирование, двоичные данные преобразуются в текст ASCII, который можно без проблем транспортировать по электронной почте. В конце пути данные декодируются и мы получаем исходный файл.
Одним из методов кодирования данных в виде обычного текста ASCII является Base64.
Это один из способов, используемых стандартом MIME для отправки данных, отличных от обычного текста.
Base64 в помощь
Кодирование Base64 занимает три байта, каждый из которых состоит из восьми битов, и представляет их в виде четырех печатных символов в стандарте ASCII. По сути, делается это в два шага.
Первым шагом является преобразование трех байтов в четыре числа из шести бит. Каждый символ в стандарте ASCII состоит из семи битов. Base64 использует только 6 бит (что соответствует 2 ^ 6 = 64 символам), чтобы гарантировать, что закодированные данные могут быть пригодны для печати и читаемы «по-человечески».
Например, три байта равны 155, 162 и 233, соответствующий (и пугающий) поток битов равен 100110111010001011101001, который, в свою очередь, соответствует 6-битовым значениям 38, 58, 11 и 41.
Эти цифры преобразуются в символы из таблицы ASCII на втором шаге с использованием таблицы «Base64 encoding». 6-битные значения нашего примера преобразуются в последовательность ASCII «m6Lp».
Этот двухэтапный процесс применяется ко всей последовательности байтов, которые закодированы. Чтобы гарантировать, что закодированные данные могут быть правильно напечатаны и не превышают ограничения почтового сервера, символы новой строки добавляются так, чтобы общая длина строк не превышала 76 символов. Символы новой строки кодируются, как и все остальные данные.
Решение
В процессе кодирования мы можем столкнуться с проблемой. Если размер исходных данных в байтах кратен трем, все работает нормально. Если это не так, мы можем получить один или два 8-битных байта. Однако для правильного кодирования нам нужно ровно три байта.
Решение состоит в том, чтобы добавить достаточно байтов со значением «0» для создания 3-байтовой группы. Два таких значения добавляются, если у нас есть один дополнительный байт данных, один добавляется для двух дополнительных байтов.
Конечно, эти искусственные завершающие «0» не могут быть закодированы, используя таблицу кодирования ниже. Они должны быть представлены 65-м символом.
Отступом Base64 является «=». Естественно, он может появляться только в конце закодированных данных.
Кодирование и декодирование в формате Base64
Документация
Кодирование Base64 широко используется в случаях, когда требуется перекодировать двоичные данные для передачи по каналу приспособленному для передачи текстовых данных. Это делается с целью защиты двоичных данных от любых возможных повреждений при передаче. Base64 широко используется во многих приложениях, включая электронную почту (MIME), и при сохранении больших объёмов данных в XML.
В языке JavaScript существуют две функции, для кодирования и декодирования данных в/из формат Base64 соответственно:
Функция atob() декодирует Base64-кодированную строку. В противоположность ей, функция btoa() создаёт Base64 кодированную ASCII строку из «строки» бинарных данных.
Tools
Related Topics
The «Unicode Problem»
Since DOMString s are 16-bit-encoded strings, in most browsers calling window.btoa on a Unicode string will cause a Character Out Of Range exception if a character exceeds the range of a 8-bit byte (0x00
0xFF). There are two possible methods to solve this problem:
Here are the two possible methods.
Solution #1 – escaping the string before encoding it
To decode the Base64-encoded value back into a String:
Unibabel implements common conversions using this strategy.
Solution #2 – rewrite the DOMs atob() and btoa() using JavaScript’s TypedArray s and UTF-8
Use a TextEncoder polyfill such as TextEncoding (also includes legacy windows, mac, and ISO encodings), TextEncoderLite, combined with a Buffer and a Base64 implementation such as base64-js.
When a native TextEncoder implementation is not available, the most light-weight solution would be to use TextEncoderLite with base64-js. Use the browser implementation when you can.
The following function implements such a strategy. It assumes base64-js imported as
SGVsbG8gd29ybGQh или история base64
Краткая предыстория
Вообще, все началось давно. Настолько давно, что вряд ли остались свидетели holy wars тех дней, когда решалось — сколько же бит должно быть в байте.
Это сейчас нам кажется само собой разумеющимся, что 1 байт = 8 бит, что в байте можно закодировать 256 различных значений. Но когда-то было совсем не так. История помнит и семибитные кодировки, и шестибитные, и даже более экзотические системы (например — ЭВМ «Сетунь», которая использовала троичную логику, то есть один троичный бит — трит мог иметь три, а не два значения, для нее было справедливо соотношение 1 трайт = 6 тритам). Но если оставить в стороне всякую экзотику, то мэйнстримом все-таки были кодировки, в которых 6, 7 или 8 бит в байте.
Шестибитная кодировка (например — BCD) позволяла закодировать в одном байте 64 различных значения, что, как казалось, было вполне достаточно для кодирования алфавитно-цифровых символов, а «лишний» седьмой бит расширял кодировку уже до 128 символов.
Однако скоро восьмибитный байт стал общепринятым.
Проблема восьмого бита
Утверждение восьмибитных кодировок как стандарта де-факто принесло много проблем. К этому моменту уже существовала определенная инфраструктура, использующая именно семибитные кодировки, и holy wars разгорелись с новой силой.
До нас они дошли в виде проблем с «обрезанием восьмого бита» в системе электронной почты. Утверждение восьмибитного байта дало 256 различных значений для одного байта, что, в свою очередь позволило уместить в одной кодовой таблице и общепринятые символы (цифры, знаки препинания, латиницу) и символы, скажем кириллицы. Казалось бы — сплошное удобство, текст можно набирать хоть русскими буквами, хоть английскими, а если нужно — и для немецких умлаутов место найдется!
Но, как всегда, дьявол крылся в деталях. Уже накопленный и работающий хард-н-софт зачастую был приспособлен для кодировок семибитных, что приводило к разнообразным проблемам.
Например, почтовый сервер при передаче письма мог совершенно спокойно обнулить старшие биты в каждом байте сообщения, что не могло не привести к проблемам, зачастую информация просто катастрофически терялась.
Для временного решения этой проблемы было предложено несколько вариантов. Одним из них стала кодировка «КОИ-8». Решение, нужно признать, весьма элегантное — в этой кодировке русские буквы располагались по порядку латинских и отличались от них ровно на тот самый старший бит. Таким образом при обрезании этого бита русская «А» превращалась в латинскую «A», «Б» — в «B» и так далее, сообщение просто транслитерировалось и его все-таки можно было прочитать. Правда, и тут не обошлось без скелета в шкафу — сортировка в русском алфавитном порядке в «КОИ» становилась кошмаром…
А что было делать другим языкам, народам и кодировкам? А бинарные данные? Все равно кодировки с транслитерацией не решали фундаментальную проблему — потерю восьмого бита, потерю части информации. Так родилась кодировка (а точнее — алгоритм) Base64.
Алгоритм Base64
Идея base64 проста — обратимое кодирование, с возможностью восстановления, которое переводит все символы восьмибитной кодовой таблицы в символы, гарантированно сохраняющиеся при передаче данных в любых сетях и между любыми устройствами.
В основе алгоритма лежит сведение трех восьмерок битов (24) к четырем шестеркам (тоже 24) и представление этих шестерок в виде символов ASCII. Таким образом получается обратимое шифрование, единственным недостатком которого будет увеличивающийся при кодировании размер — в соотношении 4:3.
Пример:
Возьмем текст русский текст «АБВГД». В двоичной форме в кодировке Windows-1251 мы получим 5 байтов:
11000000
11000001
11000010
11000011
11000100
(00000000) — лишний нулевой байт нужен, чтобы общее число бит делилось на 6
Разделим эти биты на группы по 6:
110000
001100
000111
000010
110000
111100
010000
000000
Берем массив символов «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и получившиеся числа переводим в эти символы, используя их, как индексы массива, получаем «wMHCw8Q». Остается только добавить в конце один символ «=», как указание на один лишний нулевой байт, который мы добавляли на первом шаге и получить окончательный результат:
«АБВГД»: base64 = «wMHCw8Q=»
Обратное преобразование не менее легко, попробуйте, например, расшифровать то, что вынесено в заголовок этой статьи.
Применение
Алгоритм base64 и по сей день применяется там, где нет возможности гарантировать бережного обращения с вашей информацией — например при кодировании вложений электронной почты. В PGP алгоритм base64 используется для кодирования бинарных данных.
Можно представить себе и другие применения base64 — например при сохранении в базу данных, если заранее неизвестно окружение (ох уж эти magic_qoutes в PHP!) и нет необходимости в индексации и поиске по тексту, можно воспользоваться base64.
base64 вполне может использоваться для получения хэшей, например по алгоритму md5, как средство против табличного подбора хэша, если данные, например пароль пользователя в системе, предварительно будут преобразованы в base64.
Что такое base64 и зачем он нужен в веб разработке?
Зачем это нужно?
Так исторически сложилось, что многие форматы передачи и хранения данных используют текст вместо бинарных кодов (html, url схемы, xml, email… и тп). Но что, если формат передачи данных текстовый, а передать необходимо бинарные данные (отдельно либо вместе с текстовыми данными). Вот тут на помощь и приходит base64.
Типовое применение в веб разработке
data: URL и base64 data: URL — это определённая стандартом RFC 2397 схема, которая позволяет включать небольшие элементы данных в строку URL, как если бы они были ссылкой на внешний ресурс. Согласно RFC «data: URI» – это фактически «data: URL» (URL — унифицированный указатель ресурса), хотя реально он ни на что не указывает.
Формат data: URL следующий:
Несколько типовых применений на примерах.
Пример использования в HTML:
(Переносы на новую строку осуществлены для облегчения восприятия. Их не должно быть) Все, что следует за data:image/png;base64, – это base64 код небольшого png изображения (красная точка 10×10 px). Этот пример будет выглядеть так –
Пример использования в CSS:
Получение бинарных данных из canvas в виде текстового base64 представления
12 comments on “ Что такое base64 и зачем он нужен в веб разработке? ”
Так а чем лучше такой подход для изображений? Не раскрыта тема, зачем надо такое использовать.
Хорошее замечание 😉 попробуем разобраться.
Такой подход лучше только в тех случаях, когда в зависимости от задачи Вам удобно:
Включение картинки непосредственно в CSS в виде base64, позволит браузеру отобразить ее при первой отрисовке страницы, не делая дополнительных запросов к серверу. Это особенно заметно в медленных мобильных браузерах и при медленном соединении.
Так же можно поступить с подгружаемыми шрифтами. Включая их в CSS в виде base64, вы гарантируете, что кастомный шрифт уже будет правильно отображен во время первой отрисовки страницы, а не спустя некоторое время (которое обычно браузер тратит на подгрузку внешнего шрифта)
Я не советую использовать этот подход везде, но в зависимости от задачи и требований к приложению, иногда такой подход может быть лучше. В целом.. Если пункты a) и b) не критичны для Ваших проектов, то включать изображения в css/html в виде base64 не стоит 🙂
Другие области применения в веб
Отличная статья, спасибо. Особенно актуально для email-писем.
Можно заметить что при малых размерах изображений css, применяя gzip сжатие для файла стилей(и отдачу сжатого файла с сервера) получаем не только устранение запросов но и сокращение объёма(20%-25%).
Мануал по методу кодирования base 16/32/64.
История появления кодировки.
Кодировка base берет свое начало еще с тех времен, когда не было определено сколько бит должно содержаться в одном байте. Сейчас всем известно, что в одном байте содержится 8 бит и с помощью него можно закодировать 256 различных значений, но так было не всегда.
Раньше были популярны кодировки, содержащие 6, 7 или 8 бит в байте. Таким образом, 6 бит позвояло закодировать в одном байте 64 различных значения, а 7-ми битная кодировка 128 значений. Казалось бы, что этого достаточно для того, чтобы закодировать буквенно-цифровой алфавит. Но вскоре была принята кодировка, содержащая 8 бит в одном байте.
Такая кодировка привнесла много проблем. В первую очередь, эти проблемы были связаны с оборудованием, которое уже работало на других кодировках, где байт содержал 6 или 7 бит. Но помимо этого была проблема обрезания 8-го бита в системах электронной почты, т.к. весь сфот был заточен под 7-ми или 6-ти битную кодировку. Как пример, 7-ми битная кодировка могла спокойно обнулить каждый 8-ой бит, что приводило к потери данных.
Тут на помощь пришел base 64. Идея base64 проста — обратимое кодирование, с возможностью восстановления, которое переводит все символы восьмибитной кодовой таблицы в символы, гарантированно сохраняющиеся при передаче данных в любых сетях и между любыми устройствами. В основе алгоритма лежит сведение трех восьмерок битов (24) к четырем шестеркам (тоже 24) и представление этих шестерок в виде символов ASCII. Таким образом получается обратимое шифрование, единственным недостатком которого будет увеличивающийся при кодировании размер — в соотношении 4:3.
Ниже приведена схема смещения битов в base 64
Пример:
Возьмем русский текст «АБВГД». В двоичной форме в кодировке Windows-1251 мы получим 5 байтов: 11000000 11000001 11000010
11000011 11000100 (00000000) — лишний нулевой байт нужен, чтобы общее число бит делилось на 6
Разделим эти биты на группы по 6: 110000 001100 000111 000010
110000 111100 010000 000000
Берем массив символов «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и получившиеся числа переводим в эти символы, используя их, как индексы массива, получаем «wMHCw8Q». Остается только добавить в конце один символ «=», как указание на один лишний нулевой байт, который мы добавляли на первом шаге и получить окончательный результат: «АБВГД»: base64 = «wMHCw8Q=» Возможно и обратное преобразование.
Base 16
Base 32
Base 32 использует 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64). В данном алгоритме преобразования нам необходимо будет разделять двоичные значения на группы по 5 бит.
Основные отличия кодировок
Base64
Позволяет кодировать информацию, представленную набором байтов, используя всего 64 символа: A-Z, a-z, 0-9, /, +. В конце кодированной последовательности может содержаться несколько спецсимволов (обычно “=”).
Преимущества: Позволяет представить последовательность любых байтов в печатных символах. В сравнении с другими Base-кодировками дает результат, который составляет только 133.(3)% от длины исходных данных.
Недостатки: Регистрозависимая кодировка.
Base32
Использует только 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64).
Преимущества: Последовательность любых байтов переводит в печатные символы. Регистронезависимая кодировка. Не используются цифры, слишком похожие на буквы (например, 0 похож на О, 1 на l).
Недостатки: Кодированные данные составляют 160% от исходных.
Как закодировать/декодировать base?
В основном в заданиях по ctf вам будет попадаться base 64. Его легко определить, т.к. на конце будет знак «=». Например, мы кодировали строку «АБВГД» в base 64 и у нас получился результат «wMHCw8Q=». Как мы видим, здесь присутсвует знак «=», который говорит нам о том, что строка зашифрована в base 64.
Итак, как же ее декодировать? Все очень просто. Base 16, 32, 64 легко декодировать онлайн-сервисами. Т.е. вбиваете в гугле подобный запрос:»base 64 online decoder» и вам будет выдан большой перечнь ссылок на онлайн декодеры. Берем первый попавшийся, разве что для уточнения стоит воспользоваться сразу несколькимим онлайн декодерами.
Процесс кодирования почти ничем не отличается, разве, что вам нужно вбить в запросе не «decode», а «encrypt». Бывает, что нужно обращать внимание на то, какой кодировкой вы пользуетесь. В русскоязычной версии ОС «Windows» обычно используется кодировка windows-1251.
Практика
Задание 1:
Взгляните на эту строку:
ZmxhZ2lzVzBXdGhpc2lzQkFTRTY0Cg==
На конце мы видим «=», причем двойное, что сразу наводит на мысль, что это base 64. Воспользуемся онлайн-декодером.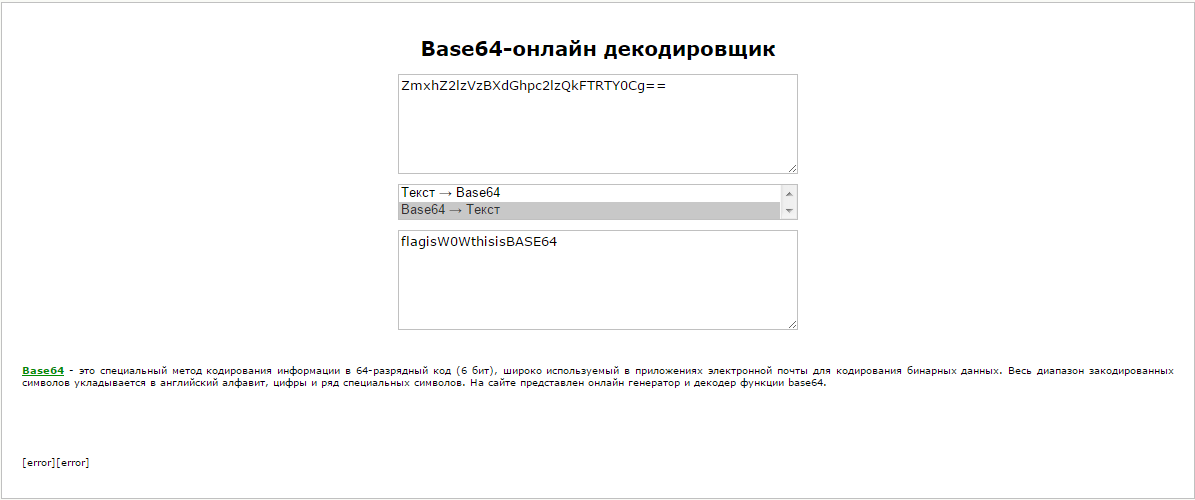
Задание 2:
Посмотрим на эту строку:
MZWGCZ33MJQXGZJTGJ6Q
На конце мы не видим знака «=». На base 16 тоже не похоже, тогда попробуем base 32.
Снова воспользуемся онлайн-декодером.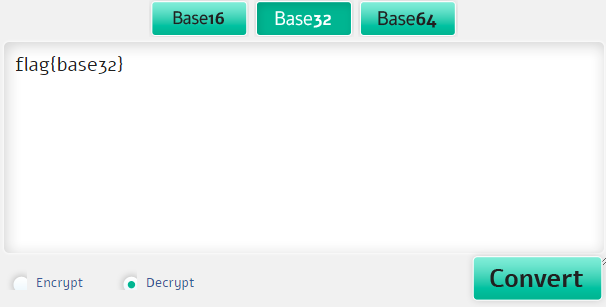
И вот наш флаг: flag
Задание 3:
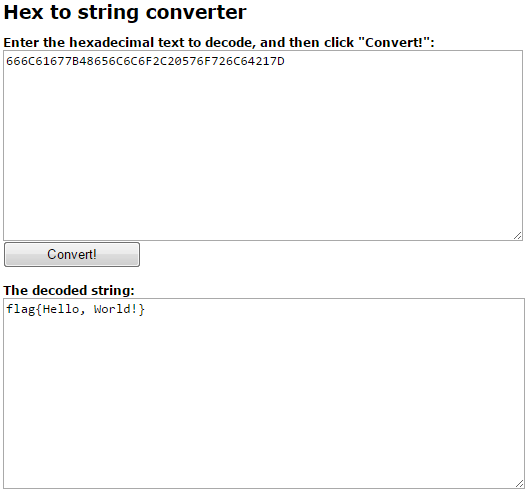
Была получена такая строка: 666C61677B48656C6C6F2C20576F726C64217D
Здесь нет ни знака «=», алфавит ограниченный. Похоже на base 16 или просто hex.
Как и прежде, пользуемся онлайн-декодером.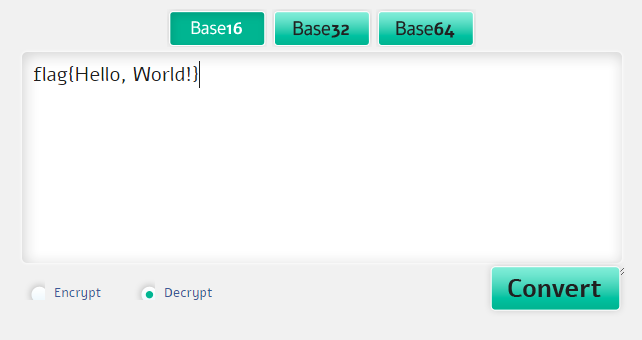
Отлично, у нас есть флаг, но это же задание можно было решить и через hex декодер.