Три простых способа улучшить производительность кода Python
1. Бенчмарк, бенчмарк и еще раз бенчмарк
Тестирование производительности программы кажется утомительным процессом. Но если у вас уже есть рабочий код Python, разделенный на функции, то задачу можно свести к простому добавлению декоратора к функции, требующей профилирования.
Прежде всего установим line_profiler, позволяющий измерить затраты времени на каждую строчку кода в функции:
Во время исполнения программы функция sum_of_lists при вызове будет профилирована. Обратите внимание на декоратор @profile над определением функции.
Чтобы запустить бенчмарк, введите:

В пятой колонке видим, какой процент времени исполнения ушел на каждую строчку. Это поможет вам определить, какие участки кода нуждаются в оптимизации больше всего.
Имейте в виду, что эта библиотека для измерения сама потребляет значительные ресурсы во время использования. Но она замечательно подходит для выявления слабых мест в программе с последующей заменой их на что-нибудь более эффективное.
Чтобы запустить line_profiler из Jupyter Notebook, попробуйте магическую команду %%lprun .
2. По возможности избегайте циклов
Посмотрим, насколько резво работает новая версия с картой по сравнению с изначальной. Измерим их скорость 1000 раз.
Версия с map более чем в 6 раз быстрее!
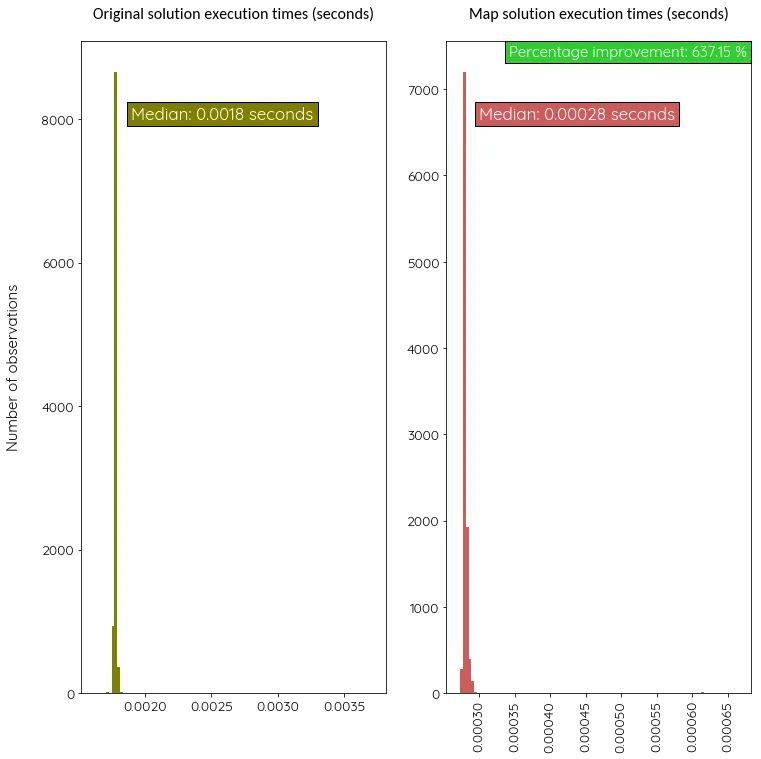
3. Компилируйте ваши модули Python с помощью Cython
Если совсем нет желания редактировать проект, но хочется хоть какого-нибудь улучшения производительности без лишних усилий, ваш лучший друг – Cython.
Для этого потребуется установить на машине как собственно Cython, так и компилятор С:
Если вы работаете на Debian системе, загрузите GCC следующим образом:
Давайте разделим изначальный код примера на два файла с названиями test_cython.py и test_module.pyx :
Наш главный файл должен импортировать эту функцию с файла test_module.pyx :
Теперь напишем скрипт setup.py для компиляции нашего модуля при помощи Cython:
Наконец пришло время скомпилировать наш модуль:
Теперь сравним эффективность этой версии с оригинальной, произведя, снова-таки, тысячу измерений.
В этом случае Cython улучшил производительность нашей программы почти вдвое по сравнению с первым вариантом. Но этот показатель будет меняться в зависимости от того, какого рода код вы пытаетесь оптимизировать.
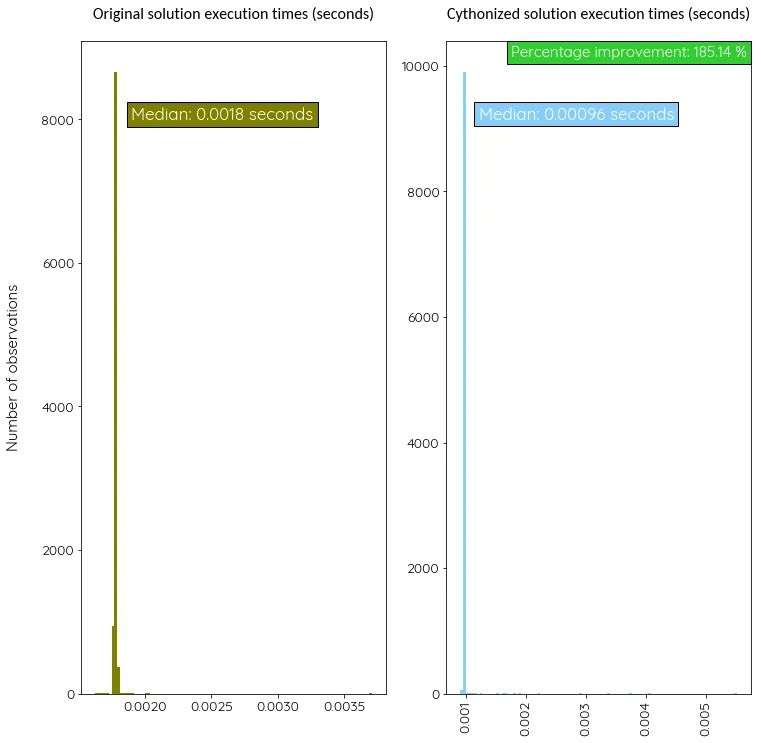
Итоги
Как оптимизировать код на Python

Как я сократил время выполнения приложения на 1/10
Данные советы просты в реализации и могут пригодиться вам в обозримом будущем.
Считается, что первоочередной задачей программиста является написание чистого и эффективного кода. Как только вы создали чистый код, можете переходить к следующим 10 подсказкам. Я подробно объясню их ниже.
Как я измеряю время и сложность кода?
Используйте структуры данных из хеш-таблиц
Если есть такая возможность, то вместо перебора данных коллекций пользуйтесь поиском.
Векторизация вместо циклов
Присмотритесь к Python-библиотекам, созданным на С (Numpy, Scipy и Pandas), и оцените преимущества векторизации. Вместо прописывания цикла, который раз за разом обрабатывает по одному элементу массива М, можно выполнять обработку элементов одновременно. Векторизация часто включает в себя оптимизированную стратегию группировки.
Сократите количество строк в коде
Пользуйтесь встроенными функциями Python. Например, map()
Каждое обновление строковой переменной создает новый экземпляр
Пример выше уменьшает объем памяти.
Для сокращения строк пользуйтесь циклами и генераторами for
Пользуйтесь многопроцессорной обработкой
Если ваш компьютер выполняет более одного процесса, тогда присмотритесь к многопроцессорной обработке в Python.
Она разрешает распараллеливание в коде. Многопроцессорная обработка весьма затратна, поскольку вам придется инициировать новые процессы, обращаться к общей памяти и т.д., поэтому пользуйтесь ей только для большого количества разделяемых данных. Для небольших объемов данных многопроцессорная обработка не всегда оправдана.
Многопроцессорная обработка очень важна для меня, поскольку я обрабатываю по несколько путей выполнения одновременно.
Пользуйтесь Cython
Cython — это статический компилятор, который будет оптимизировать код за вас.
Загрузите расширения Cythonmagic и пользуйтесь тегом Cython для компиляции кода через Cython.
Воспользуйтесь Pip для установки Cython:
Для работы с Cython:
Пользуйтесь Excel только при необходимости
Не так давно мне нужно было реализовать одно приложение. И мне бы пришлось потратить много времени на загрузку и сохранение файлов из/в Excel. Вместо этого я пошел другим путем: создал несколько CSV-файлов и сгруппировал их в отдельной папке.
Примечание: все зависит от задачи. Если создание файлов в Excel сильно тормозит работу, то можно ограничиться несколькими CSV-файлами и утилитой на нативном языке, которая объединит эти CSV в один Excel-файл.
Пользуйтесь Numba
Это — JIT-компилятор (компилятор «на лету»). С помощью декоратора Numba компилирует аннотированный Python- и NumPy-код в LLVM.
Разделите функцию на две части:
1. Функция, которая выполняет вычисления. Ее декорируйте с @autojit.
2. Функция, которая выполняет операции ввода-вывода.
Пользуйтесь Dask для распараллеливания операций Pandas DataFrame
Dask очень классный! Он помог мне с параллельной обработкой множества функций в DataFrame и NumPy. Я даже попытался масштабировать их в кластере, и все оказалось предельно просто!
Пользуйтесь пакетом swifter
Swifter использует Dask в фоновом режиме. Он автоматически рассчитывает наиболее эффективный способ для распараллеливания функции в пакете данных.
Это плагин для Pandas.
Пользуйтесь пакетом Pandarallel
Pandarallel может распараллеливать операции на несколько процессов.
Опять же, подходит только для больших наборов данных.
Общие советы
Как только вы добились чистого кода, можно приступать к рекомендациям, описанным выше.

Заключение
В данной статье были даны краткие подсказки по написанию кода. Они будут весьма полезны для тех, кто хочет улучшить производительность Python-кода.
Как оптимизировать код на Python
Как я сократил время выполнения приложения на 1/10

Jul 20, 2019 · 4 min read

Данные советы просты в реализации и могут пригодиться вам в обозримом будущем.
Считается, что первоочередной задачей программиста является написание чистого и эффективного кода. Как только вы создали чистый код, можете переходить к следующим 10 подсказкам. Я подробно объясню их ниже.
Как я измеряю время и сложность кода?
Используйте структуры данных из хеш-таблиц
Если есть такая возможность, то вместо перебора данных коллекций пользуйтесь поиском.
Векторизация вместо циклов
Присмотритесь к Python-библиотекам, созданным на С (Numpy, Scipy и Pandas), и оцените преимущества векторизации. Вместо прописывания цикла, который раз за разом обрабатывает по одному элементу массива М, можно выполнять обработку элементов одновременно. Векторизация часто включает в себя оптимизированную стратегию группировки.
Сократите количество строк в коде
Пользуйтесь встроенными функциями Python. Например, map()
Каждое обновление строковой переменной создает новый экземпляр
Пример выше уменьшает объем памяти.
Для сокращения строк пользуйтесь циклами и генераторами for
Пользуйтесь многопроцессорной обработкой
Если ваш компьютер выполняет более одного процесса, тогда присмотритесь к многопроцессорной обработке в Python.
Она разрешает распараллеливание в коде. Многопроцессорная обработка весьма затратна, поскольку вам придется инициировать новые процессы, обращаться к общей памяти и т.д., поэтому пользуйтесь ей только для большого количества разделяемых данных. Для небольших объемов данных многопроцессорная обработка не всегда оправдана.
Многопроцессорная обработка очень важна для меня, поскольку я обрабатываю по несколько путей выполнения одновременно.
Пользуйтесь Cython
Cython — это статический компилятор, который будет оптимизировать код за вас.
Загрузите расширения Cythonmagic и пользуйтесь тегом Cython для компиляции кода через Cython.
Воспользуйтесь Pip для установки Cython:
Для работы с Cython:
Пользуйтесь Excel только при необходимости
Не так давно мне нужно было реализовать одно приложение. И мне бы пришлось потратить много времени на загрузку и сохранение файлов из/в Excel. Вместо этого я пошел другим путем: создал несколько CSV-файлов и сгруппировал их в отдельной папке.
Примечание: все зависит от задачи. Если создание файлов в Excel сильно тормозит работу, то можно ограничиться несколькими CSV-файлами и утилитой на нативном языке, которая объединит эти CSV в один Excel-файл.
Пользуйтесь Numba
Это — JIT-компилятор (компилятор «на лету»). С помощью декоратора Numba компилирует аннотированный Python- и NumPy-код в LLVM.
Разделите функцию на две части:
1. Функция, которая выполняет вычисления. Ее декорируйте с @autojit.
2. Функция, которая выполняет операции ввода-вывода.
Пользуйтесь Dask для распараллеливания операций Pandas DataFrame
Dask очень классный! Он помог мне с параллельной обработкой множества функций в DataFrame и NumPy. Я даже попытался масштабировать их в кластере, и все оказалось предельно просто!
Пользуйтесь пакетом swifter
Swifter использует Dask в фоновом режиме. Он автоматически рассчитывает наиболее эффективный способ для распараллеливания функции в пакете данных.
Это плагин для Pandas.
Пользуйтесь пакетом Pandarallel
Pandarallel может распараллеливать операции на несколько процессов.
Опять же, подходит только для больших наборов данных.
Общие советы
Как только вы добились чистого кода, можно приступать к рекомендациям, описанным выше.

Заключение
В данной статье были даны краткие подсказки по написанию кода. Они будут весьма полезны для тех, кто хочет улучшить производительность Python-кода.
Десять способов для ускорения кода на Python
1. Познакомьтесь со встроенными функциями

Рисунок 1 | Встроенные функции в Python 3
Python поставляется с множеством встроенных функций, реализованных на языке программирования C, которые очень быстры и хорошо поддерживаются (рисунок 1). Например, функции, связанные с алгебраическими вычислениями: abs(), len(), max(), min(), set(), sum()).
В качестве примера рассмотрим встроенные функции set() и sum(). Их использование позволяет повысить скорость выполнения кода в десятки раз.

Рисунок 2 | Примеры функций set() и sum()
2. sort() или sorted()
Обе функции предназначены для сортировки списков. Функция sort() немного быстрее, чем sorted(). Это связано с тем, что метод sort() изменяет первичный список. sorted() создает новый отсортированный список и оставляет исходный список без изменений.


Рисунок 3| sort() и sorted()
Но функция sorted() более универсальна. Она принимает любую коллекцию, в то время как функция sort()работает только со списками. Например, с помощью sorted() можно быстро отсортировать словарь по его ключам или значениям.

Использование sorted() со словарем
3. Используйте символы вместо функций
Для создания пустого словаря или списка вместо dict() или list() можно использовать фигурные скобки «<>». Как и для пустого набора, когда нужно использовать set()) и [].

Использование list() и dict() напрямую.
4. Генератор списков
Для создания нового списка из старого списка мы используем цикл for. Он позволяет перебрать старый список, преобразовать его значения на основе заданных условий и сохранить в новом списке. Например, чтобы найти все четные числа из another_long_list, можно использовать приведенный ниже код:
Но есть более лаконичный способ переборки. Для его реализации мы помещаем исходный цикл for всего в одну строку кода. При этом скорость выполнения увеличивается почти в 2 раза.

В сочетании с третьим способом мы можем превратить список в словарь или набор, изменив [] на <>. Давайте перепишем код с рисунка 5. Мы можем пропустить присвоение и завершить итерацию внутри скобок. Например,sorted_dict3 =
Функция sorted(a_dict.items(), key=lambda item: item[1]) вернет список кортежей (рисунок 4). Здесь мы используем множественное присваивание для распаковки кортежей. Так как каждому кортежу в списке мы присваивали ключ его первому элементу и значение его второму элементу. После этого каждая пара ключ-значение сохраняется в словаре.
5. Используйте функцию enumerate() для получения значений и индексов
Можно использовать функцию enumerate(), которая превращает значения списка в пары index и value. Это также ускорит Python-код примерно в 2 раза.

Рисунок 7 | Пример enumerate()
6. Используйте zip() для слияния списков
Иногда нужно перебирать два списка или даже более. Для этого можно использовать функцию zip(), которая преобразует несколько списков в один список кортежей. При этом спискам лучше иметь одинаковую длину, иначе выполнение zip() остановится, как только закончится самый короткий список.

Чтобы получить доступ к элементам в каждом кортеже, можно разделить список кортежей, добавив звездочку (*) и используя несколько переменных. Например, letters1, numbers1 = zip(*pairs_list).
7. Совмещайте set() и in
Для проверки наличия определенного значения часто пишется подобная функция:
Затем вызывается метод check_membership(value), чтобы увидеть, есть ли значение в another_long_list. Но лучше просто использовать in, вызвав value in another_long_list.

Проверка вхождения, с помощью in и set()
Для большей эффективности необходимо сначала удалить дубликаты из списка с помощью set(), а затем проверить вхождение в объекте набора. Так мы сократим количество элементов, которые необходимо проверить.
8. Проверка переменной на истинность
Для проверки пустых переменных, списков, словарей не нужно явно указывать == True или is True в операторе if. Вместо этого лучше указать имя переменной.

Простая проверка переменной
Если нужно проверить, является ли переменная пустой, используйте if not string_returned_from_function.
9. Для подсчета уникальных значений используйте Counters()
Чтобы подсчитать уникальные значения в списке a_long_list, который мы создали в пункте 1, нужно создать словарь. Его ключи являются числами, а значения – счетчиками. Выполняя проход по списку, увеличиваем значение счетчика, если элемент уже есть в словаре. А также добавлять его в словарь, если его там нет.
Но более эффективный способ сделать это – использовать подкласс Counter() из библиотеки коллекций :
Чтобы получить десять наиболее часто встречающихся чисел, используйте метод most_common, доступный в Counter().

10. Вложите цикл for внутрь функции
Предположим, что мы создали функцию, и нам необходимо вызвать ее определённое количество раз. Для этого функция помещается в цикл for.
Но вместо выполнения функции миллион раз (длина a_long_list составляет 1 000 000), можно интегрировать цикл for внутрь функции. Это сэкономит около 22% времени.

Рисунок 12 | цикл for внутри функции
Надеюсь, что некоторые из перечисленных способов ускорения выполнения кода Python окажутся полезными для вас.
Пожалуйста, оставляйте ваши комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, лайки, отклики, дизлайки, подписки!
10 практик кода, ускоряющих выполнение программ на Python 🐍

«Питон – медленный». Наверняка вы не раз сталкивались с этим утверждением, особенно от людей, пришедших в Python из C, C++ или Java. Во многих случаях это верно. Циклы или сортировка массивов, списков или словарей иногда действительно работают медленно. В конце концов, главная миссия Python – сделать программирование приятным и легким. Ради лаконичности и удобочитаемости пришлось отчасти принести в жертву производительность.
Тем не менее, в последние годы предпринято немало усилий для решения проблемы. Теперь мы можем эффективно обрабатывать большие наборы данных с помощью NumPy, SciPy, Pandas и numba, поскольку все эти библиотеки написаны на C/C++. Еще один интересный проект – PyPy ускоряет код Python в 4.4 раза по сравнению с CPython (оригинальная реализация Python).
Но ускорить Python можно и без внешних библиотек. В наших силах разогнать его с помощью полезных трюков, используемых в повседневной практике кодинга.
1. Стандартные функции
Стандартные варианты в 36 ( set ) и 20 ( sum ) раз быстрее, чем функции, написанные самим разработчиком.
2. sort() vs sorted()
Так происходит потому, что метод sort() изменяет список прямо на месте, в то время как sorted() создает новый отсортированный список, сохраняя исходный нетронутым. Другими словами, порядок значений внутри a_long_list фактически уже изменился.
Однако функция sorted() более универсальна. Она может работать с любой итерируемой структурой. Поэтому, если нужно отсортировать, например, словарь (по ключам или по значениям), придется использовать sorted() :
3. Литералы вместо функций
4. Генераторы списков
Обычно, когда требуется создать новый список из старого на основе определенных условий, мы используем цикл for – итерируем все значения и сохраняем нужные в новом списке.
Например, отберём все чётные числа из списка another_long_list :
Но есть более лаконичный и элегантный способ сделать то же самое. Код цикла for можно сократить до одной-единственной строки с помощью генератора списка, выиграв при этом в скорости почти в два раза:
Сочетая это правило с Правилом #3 (использование литералов), мы легко можем превратить список в словарь или множество, просто изменив скобки:
5. enumerate() для значения и индекса
Иногда при переборе списка нужны и значения, и их индексы. Чтобы вдвое ускорить код используйте enumerate() для превращения списка в пары индекс-значение:
6. zip() для перебора нескольких списков
Обратите внимание, списки должны быть одинаковой длины, так как функция zip() останавливается, когда заканчивается более короткий список.
И наоборот, чтобы получить доступ к элементам каждого кортежа, мы можем распаковать список кортежей, добавив звездочку ( * ) и используя множественное присваивание:
7. Комбинация set() и in
Если нужно проверить, содержит ли список некоторое значение, можно написать такую неуклюжую функцию:
Однако есть более характерный для Python способ сделать это – использовать оператор in :
Преобразование списка в множество заняло 20 мс. Но это одноразовые затраты. Зато сама проверка заняла 5 мкс – то есть в 2 тыс. раз меньше, что становится важным при частых обращениях.
8. Проверка на True
Практически в любой программе необходимо проверять, являются ли переменные/списки/словари/. пустыми. На этих проверках тоже можно немножко сэкономить.
Аналогично можно проверять обратное условие, добавив оператор not :
9. Подсчет уникальных значений с Counter()
Если нам необходимо подсчитать количество уникальных значений в списке, можно, например, создать словарь, в котором ключи – это значения списка, а значения – счетчик встречаемости.
Однако более эффективный способ для решения этой задачи – использование Counter() из модуля collections. Весь код при этом уместится в одной строчке:
Этот фрагмент будет работать примерно в 10 раз быстрее, чем предыдущий.
Одним словом, collections – это замечательный модуль, который должен быть в базовом наборе инструментов любого Python-разработчика. Не поленитесь прочитать наше руководство по применению модуля.
10. Цикл for внутри функции
Однако правильнее будет перевернуть конструкцию – и поместить цикл внутрь функции.
В данном примере для миллиона итераций (длина a_long_list ) мы сэкономили около 22% времени.
Будем рады, если вы поделитесь в комментариях своими подходами к ускорению кода в Python. Вот ещё несколько статей, которые могут вас заинтересовать:



