Бесплатно создайте и скачайте QR-коды!
БЕСПЛАТНО!
Сгенерированные QR-коды являются бесплатными и доступными в течение длительного срока. Используя данный сервис создания QR-кодов, Вы принимаете Условия использования.
Встраивание QR-кода
Просто вставьте данный HTML код в Ваш сайт, блог или E-Mail.
API генератора QR-кодов
Вы хотите создавать QR-коды с собственными данными на своём сайте или своим приложением? Детали Вы найдёте в документации QR-Code API.
Программы для QR-кодов
Выберите между профессиональной программной для создания штрихкодов Barcode Studio или бесплатной программой QR-Code Studio. Обе программы доступны для Microsoft Windows, Mac OS X и Linux.
TEC-IT Datenverarbeitung GmbH
С 1996 года компания TEC-IT, Австрия, разрабатывает программное обеспечение для создания штрихкодов, печати, создания маркировочных этикеток, составления отчетов и сбора данных.
Вы ищите высококачественное программное обеспечение — TEC-IT предоставляет этот уровень качества.
Новости
Ссылки
Условия использования: Использование данного приложения и полученных QR-кодов предназначено исключительно для легальных целей и должно соответствовать текущему национальному и международному законодательству. Функциональность, корректность и доступность данного бесплатного онлайн сервиса не гарантируются. Создание более 30 QR-кодов за одну минуту должно быть письменно разрешено компанией TEC-IT. Дополнительная информация: Правовые положения и конфиденциальность. Версия: 1.4.0.12514
Алгоритм генерации QR-кода

QR код — это монохромная картинка, на которой некоторые устройства (например смартфон со специальным приложением) распознают текст. Этим текстом может быть не только простая фраза, но и, хоть это и не входит в официальную спецификацию, ссылка, номер телефона или визитная карточка. Такие коды чаще всего используют, чтобы закодировать ссылку и распечатать её на плакате или визитке.
Эта статья — подробная инструкция по созданию QR кода с примерами на каждом шаге, которая требует от вас только базового умения работать с бинарными данными и владения любым языком программирования (если вы хотите создать автоматический генератор QR кода).
За основу этой статьи взят цикл статей «QR Code Demystified» Джейсона Брауна (Jason Brown). В этих статьях опущено много нюансов, что вызвало у меня некоторые проблемы. Все эти нюансы учтены и упомянуты здесь.
Кодирование данных
Цифровое кодирование
Этот тип кодирования требует 10 бит на 3 символа. Вся последовательность символов разбивается на группы по 3 цифры, и каждая группа (трёхзначное число) переводится в 10-битное двоичное число и добавляется к последовательности бит. Если общее количество символов не кратно 3, то если в конце остаётся 2 символа, полученное двузначное число кодируется 7 битами, а если 1 символ, то 4 битами.
Например, есть строка «12345678», которую надо закодировать. Мы разбиваем её на числа: 123, 456 и 78, затем переводим каждое из них в двоичный вид: 0001111011, 0111001000 и 1001110, и объединяем это в один поток: 000111101101110010001001110.
Буквенно-цифровое кодирование
В этом случае на 2 символа требуется 11 бит информации. Входной поток символов разделяется на группы по 2, в группе каждый символ кодируется согласно таблице внизу, значение первого символа в группе умножается на 45 и прибавляется к значение второго символа. Полученное число переводится в 11-битное двоичное число и добавляется к последовательности бит. Если в последней группе 1 символ, то его значение сразу кодируется 6-битным числом и добавляется к последовательности бит.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| U | V | W | X | Y | Z | Пробел | $ | % | * | + | — | . | / | : |
| 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
Например, строка «HELLO» кодируется следующим образом. Разбиваем на группы: HE, LL, O; находим соответствующее значение символам в каждой группе: (17, 14), (21, 21), (24); находим значение для каждой группы: 17 * 45 + 14 = 779, 21 * 45 + 21 = 966, 24 = 24; переводим каждое значение в двоичный вид: 779 = 01100001011, 966 = 01111000110, 24 = 011000; и объединяем всё это в одну последовательность бит: 0110000101101111000110011000.
Побайтовое кодирование
Это универсальный способ кодирования, которым можно закодировать любые символы. Единственным недостатком метода является относительно низкая плотность информации. В этом случае текст кодируется в любой кодировке (рекомендуемо в UTF-8) и полученная последовательность байт берётся в неизменном виде.
Например, строка «Хабр», закодированния кодировкой UTF-8, состоит из следующих байт: 11010000, 10100101, 11010000, 10110000, 11010000, 10110001, 11010001 и 10000000. Их надо просто объединить в один поток бит: 1101000010100101110100001011000011010000101100011101000110000000.
Добавление служебной информации
На этом этапе надо определиться с уровнем коррекции: чем выше этот уровень, тем выше допустимый уровень повреждения изображения и тем меньше информации при равном размере. Всего есть 4 уровня корекции: L (допустимо максимум 7% повреждений), M (15%), Q (25%) и H (30%). Чаще всего используется уровень M. Если вы хотите добавить на QR код свой рисунок (на Хабре есть несколько статей на эту тему), то используйте уровень H.
Ещё одно свойство QR кода — его версия (чем она больше, тем больше размер). Всего существует 40 версий. Номер версии зависит от количества кодируемой информации и от уровня коррекции. В таблице 2 указано максимальное количество полезной информации вместе со служебной (в битах), которое можно закодировать в QR коде этой версии. Из этой таблицы определется версия нашего QR кода.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| L | 152 | 272 | 440 | 640 | 864 | 1088 | 1248 | 1552 | 1856 | 2192 |
| M | 128 | 224 | 352 | 512 | 688 | 864 | 992 | 1232 | 1456 | 1728 |
| Q | 104 | 176 | 272 | 384 | 496 | 608 | 704 | 880 | 1056 | 1232 |
| H | 72 | 128 | 208 | 288 | 368 | 480 | 528 | 688 | 800 | 976 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 2592 | 2960 | 3424 | 3688 | 4184 | 4712 | 5176 | 5768 | 6360 | 6888 |
| M | 2032 | 2320 | 2672 | 2920 | 3320 | 3624 | 4056 | 4504 | 5016 | 5352 |
| Q | 1440 | 1648 | 1952 | 2088 | 2360 | 2600 | 2936 | 3176 | 3560 | 3880 |
| H | 1120 | 1264 | 1440 | 1576 | 1784 | 2024 | 2264 | 2504 | 2728 | 3080 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | |
| L | 7456 | 8048 | 8752 | 9392 | 10208 | 10960 | 11744 | 12248 | 13048 | 13880 |
| M | 5712 | 6256 | 6880 | 7312 | 8000 | 8496 | 9024 | 9544 | 10136 | 10984 |
| Q | 4096 | 4544 | 4912 | 5312 | 5744 | 6032 | 6464 | 6968 | 7288 | 7880 |
| H | 3248 | 3536 | 3712 | 4112 | 4304 | 4768 | 5024 | 5288 | 5608 | 5960 |
| 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 14744 | 15640 | 16568 | 17528 | 18448 | 19472 | 20528 | 21616 | 22496 | 23648 |
| M | 11640 | 12328 | 13048 | 13800 | 14496 | 15312 | 15936 | 16816 | 17728 | 18672 |
| Q | 8264 | 8920 | 9368 | 9848 | 10288 | 10832 | 11408 | 12016 | 12656 | 13328 |
| H | 6344 | 6760 | 7208 | 7688 | 7888 | 8432 | 8768 | 9136 | 9776 | 10208 |
Добавление служебных полей
К этому моменту уже должен быть выбран уровень коррекции и определена версия. Теперь надо перед последоветельностью бит, полученной в предыдущем пункте, добавить в начале два поля: способ кодирования и количество данных. Способ кодирования — поле длиной 4 бита, которое имеет следующие значения: 0001 для цифрового кодирования, 0010 для буквенно-цифрового и 0100 для побайтового. Количество данных — это количество кодируемых символов, а для побайтового — количество байт (а не бит в полученной последовательности), представленное в виде двоичного числа определённой длины (определяется по таблице 3).
| Версия 1–9 | Версия 10–26 | Версия 27–40 | |
| Цифровое | 10 бит | 12 бит | 14 бит |
| Буквенно-цифровое | 9 бит | 11 бит | 13 бит |
| Побайтовое | 8 бит | 16 бит | 16 бит |
Если длина полученной последовательности бит оказалась больше допустимой для выбранной версии, то версию надо увеличить на одну и проделать добавление служебных полей заново.
Спецификация допускает использование смешанного кодирования. Это значит, что несколько групп данных можно закодировать разными способами и объединить их в одну последовательность. Это делается следующим образом: и так далее.
Заполнение
На данном этапе у нас есть последовательность бит данных, количество бит в которой наверняка не кратно 8. Надо дополнить её нулями так, чтобы её длина стала кратна 8. Теперь нашу последовательность бит можно разбить на группы по 8 бит и представить в виде последовательности байт (далее мы так и будем делать). Если количество бит в текущей последовательности байт меньше того, которое нужно для выбранной версии, то её надо дополнить чередующимися байтами 11101100 и 00010001. Таким образом, у нас получилась последовательность байт, длина которой соответствует выбранной версии QR кода.
Пример. Есть последовательность: 10101011101; дополняем её нулями, чтобы её длина стала кратна 8: 10101011101 00000; теперь предположим, что её длина — 104 бита, а для выбранной версии необходимо 128 бит, тогда для заполнения нужно добавить 24 «заполняющих» бита (3 байта): 10101011101 00000 11101100 00010001 11101100. Готово.
Разделение информации на блоки
Последовательность байт, полученная на предыдущем этапе, (далее данные) разделяется на обределённое для версии и уровня коррекции количество блоков, которое приведено в таблице 4. Если количество блоков равно одному, то этот этап можно пропустить.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| L | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 4 |
| M | 1 | 1 | 1 | 2 | 2 | 4 | 4 | 4 | 5 | 5 |
| Q | 1 | 1 | 2 | 2 | 4 | 4 | 6 | 6 | 8 | 8 |
| H | 1 | 1 | 2 | 4 | 4 | 4 | 5 | 6 | 8 | 8 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 4 | 4 | 4 | 4 | 6 | 6 | 6 | 6 | 7 | 8 |
| M | 5 | 8 | 9 | 9 | 10 | 10 | 11 | 13 | 14 | 16 |
| Q | 8 | 10 | 12 | 16 | 12 | 17 | 16 | 18 | 21 | 20 |
| H | 11 | 11 | 16 | 16 | 18 | 16 | 19 | 21 | 25 | 25 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | |
| L | 8 | 9 | 9 | 10 | 12 | 12 | 12 | 13 | 14 | 15 |
| M | 17 | 17 | 18 | 20 | 21 | 23 | 25 | 26 | 28 | 29 |
| Q | 23 | 23 | 25 | 27 | 29 | 34 | 34 | 35 | 38 | 40 |
| H | 25 | 34 | 30 | 32 | 35 | 37 | 40 | 42 | 45 | 48 |
| 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 16 | 17 | 18 | 19 | 19 | 20 | 21 | 22 | 24 | 25 |
| M | 31 | 33 | 35 | 37 | 38 | 40 | 43 | 45 | 47 | 49 |
| Q | 43 | 45 | 48 | 51 | 53 | 56 | 59 | 62 | 65 | 68 |
| H | 51 | 54 | 57 | 60 | 63 | 66 | 70 | 74 | 77 | 81 |
Определение количество байт в каждом блоке
Для этого надо разделить всё количество байт (можно определить количество байт в данных или разделить число из таблицы 2 на восемь) на количество блоков данных. Если это число не целое, то надо определить остаток от деления. Этот остаток определяет сколько блоков из всех дополнены (такие блоки, количество байт в которых больше на один чем в остальных). Вопреки ожиданию, дополненными блоками должны быть не первые блоки, а последние.
Например, для версии 9 и уровня коррекции M количестов данных — 182 байта, количество блоков — 5. Деля количество байт данных на количество блоков, получаем 36 байт и 2 байта в остатке. Это значит, что блоки данных будут иметь следующие размеры: 36, 36, 36, 37, 37 (байт). Если бы остатка не было, что все 5 блоков имели бы размер 36 байт.
Заполнение блоков
Блок заполняется байтами из данных полностью. Когда текущий блок полностью заполняется, очередь переходит к следующему. Байтов данных должно хватить ровно на все блоки, ни больше и ни меньше.
Создание байтов коррекции
Следующий алгоритм применяется к каждому блоку данных (если блок данных один, то просто к данным).
Этот алгоритм основан на алгоритме Рида–Соломона. Первое что надо сделать — определать сколько байтов коррекции надо создать (таблица 5). По количеству байтов коррекции определяется так называемый генерирующий многочлен (таблица 6). Многочленом он называется, потому что оригинальный метод использует многочлен с теми же коэффициентами.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| L | 7 | 10 | 15 | 20 | 26 | 18 | 20 | 24 | 30 | 18 |
| M | 10 | 16 | 26 | 18 | 24 | 16 | 18 | 22 | 22 | 26 |
| Q | 13 | 22 | 18 | 26 | 18 | 24 | 18 | 22 | 20 | 24 |
| H | 17 | 28 | 22 | 16 | 22 | 28 | 26 | 26 | 24 | 28 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 20 | 24 | 26 | 30 | 22 | 24 | 28 | 30 | 28 | 28 |
| M | 30 | 22 | 22 | 24 | 24 | 28 | 28 | 26 | 26 | 26 |
| Q | 28 | 26 | 24 | 20 | 30 | 24 | 28 | 28 | 26 | 30 |
| H | 24 | 28 | 22 | 24 | 24 | 30 | 28 | 28 | 26 | 28 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | |
| L | 28 | 28 | 30 | 30 | 26 | 28 | 30 | 30 | 30 | 30 |
| M | 26 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 |
| Q | 28 | 30 | 30 | 30 | 30 | 28 | 30 | 30 | 30 | 30 |
| H | 30 | 24 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| M | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 |
| Q | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| H | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| Количество байтов коррекции | Генерирующий многочлен |
| 7 | 87, 229, 146, 149, 238, 102, 21 |
| 10 | 251, 67, 46, 61, 118, 70, 64, 94, 32, 45 |
| 13 | 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78 |
| 15 | 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105 |
| 16 | 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120 |
| 17 | 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136 |
| 18 | 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153 |
| 20 | 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190 |
| 22 | 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231 |
| 24 | 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21 |
| 26 | 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70 |
| 28 | 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123 |
| 30 | 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180 |
Перед выполнением цикла надо подготовить массив, длина которого равна максимуму из количества байтов в текущем блоке и количества байтов коррекции, и заполнить его начало байтами из текущего блока, а конец нулями.
Первые N байтов подготовленного массива после этого цикла — и есть байты коррекции. Для каждого блока данных получится соответствующий блок байтов коррекции.
Ничего не понятно? Мне тоже. Посмотрите на пример и всё станет ясно.
Эта таблица — значения для поля Галуа длиной 256. Она может быть вычеслена автоматически.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 29 | 58 | 116 | 232 | 205 | 135 | 19 | 38 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 76 | 152 | 45 | 90 | 180 | 117 | 234 | 201 | 143 | 3 | 6 | 12 | 24 | 48 | 96 | 192 |
| 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 |
| 157 | 39 | 78 | 156 | 37 | 74 | 148 | 53 | 106 | 212 | 181 | 119 | 238 | 193 | 159 | 35 |
| 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
| 70 | 140 | 5 | 10 | 20 | 40 | 80 | 160 | 93 | 186 | 105 | 210 | 185 | 111 | 222 | 161 |
| 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 |
| 95 | 190 | 97 | 194 | 153 | 47 | 94 | 188 | 101 | 202 | 137 | 15 | 30 | 60 | 120 | 240 |
| 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 |
| 253 | 231 | 211 | 187 | 107 | 214 | 177 | 127 | 254 | 225 | 223 | 163 | 91 | 182 | 113 | 226 |
| 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 |
| 217 | 175 | 67 | 134 | 17 | 34 | 68 | 136 | 13 | 26 | 52 | 104 | 208 | 189 | 103 | 206 |
| 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 |
| 129 | 31 | 62 | 124 | 248 | 237 | 199 | 147 | 59 | 118 | 236 | 197 | 151 | 51 | 102 | 204 |
| 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 |
| 133 | 23 | 46 | 92 | 184 | 109 | 218 | 169 | 79 | 158 | 33 | 66 | 132 | 21 | 42 | 84 |
| 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 |
| 168 | 77 | 154 | 41 | 82 | 164 | 85 | 170 | 73 | 146 | 57 | 114 | 228 | 213 | 183 | 115 |
| 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 |
| 230 | 209 | 191 | 99 | 198 | 145 | 63 | 126 | 252 | 229 | 215 | 179 | 123 | 246 | 241 | 255 |
| 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 |
| 227 | 219 | 171 | 75 | 150 | 49 | 98 | 196 | 149 | 55 | 110 | 220 | 165 | 87 | 174 | 65 |
| 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 |
| 130 | 25 | 50 | 100 | 200 | 141 | 7 | 14 | 28 | 56 | 112 | 224 | 221 | 167 | 83 | 166 |
| 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 |
| 81 | 162 | 89 | 178 | 121 | 242 | 249 | 239 | 195 | 155 | 43 | 86 | 172 | 69 | 138 | 9 |
| 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | 232 | 233 | 234 | 235 | 236 | 237 | 238 | 239 |
| 18 | 36 | 72 | 144 | 61 | 122 | 244 | 245 | 247 | 243 | 251 | 235 | 203 | 139 | 11 | 22 |
| 240 | 241 | 242 | 243 | 244 | 245 | 246 | 247 | 248 | 249 | 250 | 251 | 252 | 253 | 254 | 255 |
| 44 | 88 | 176 | 125 | 250 | 233 | 207 | 131 | 27 | 54 | 108 | 216 | 173 | 71 | 142 | 1 |
Эту таблицу можно вычислить из таблицы 7.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| — | 0 | 1 | 25 | 2 | 50 | 26 | 198 | 3 | 223 | 51 | 238 | 27 | 104 | 199 | 75 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 4 | 100 | 224 | 14 | 52 | 141 | 239 | 129 | 28 | 193 | 105 | 248 | 200 | 8 | 76 | 113 |
| 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 |
| 5 | 138 | 101 | 47 | 225 | 36 | 15 | 33 | 53 | 147 | 142 | 218 | 240 | 18 | 130 | 69 |
| 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
| 29 | 181 | 194 | 125 | 106 | 39 | 249 | 185 | 201 | 154 | 9 | 120 | 77 | 228 | 114 | 166 |
| 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 |
| 6 | 191 | 139 | 98 | 102 | 221 | 48 | 253 | 226 | 152 | 37 | 179 | 16 | 145 | 34 | 136 |
| 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 |
| 54 | 208 | 148 | 206 | 143 | 150 | 219 | 189 | 241 | 210 | 19 | 92 | 131 | 56 | 70 | 64 |
| 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 |
| 30 | 66 | 182 | 163 | 195 | 72 | 126 | 110 | 107 | 58 | 40 | 84 | 250 | 133 | 186 | 61 |
| 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 |
| 202 | 94 | 155 | 159 | 10 | 21 | 121 | 43 | 78 | 212 | 229 | 172 | 115 | 243 | 167 | 87 |
| 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 |
| 7 | 112 | 192 | 247 | 140 | 128 | 99 | 13 | 103 | 74 | 222 | 237 | 49 | 197 | 254 | 24 |
| 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 |
| 227 | 165 | 153 | 119 | 38 | 184 | 180 | 124 | 17 | 68 | 146 | 217 | 35 | 32 | 137 | 46 |
| 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 |
| 55 | 63 | 209 | 91 | 149 | 188 | 207 | 205 | 144 | 135 | 151 | 178 | 220 | 252 | 190 | 97 |
| 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 |
| 242 | 86 | 211 | 171 | 20 | 42 | 93 | 158 | 132 | 60 | 57 | 83 | 71 | 109 | 65 | 162 |
| 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 |
| 31 | 45 | 67 | 216 | 183 | 123 | 164 | 118 | 196 | 23 | 73 | 236 | 127 | 12 | 111 | 246 |
| 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 |
| 108 | 161 | 59 | 82 | 41 | 157 | 85 | 170 | 251 | 96 | 134 | 177 | 187 | 204 | 62 | 90 |
| 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | 232 | 233 | 234 | 235 | 236 | 237 | 238 | 239 |
| 203 | 89 | 95 | 176 | 156 | 169 | 160 | 81 | 11 | 245 | 22 | 235 | 122 | 117 | 44 | 215 |
| 240 | 241 | 242 | 243 | 244 | 245 | 246 | 247 | 248 | 249 | 250 | 251 | 252 | 253 | 254 | 255 |
| 79 | 174 | 213 | 233 | 230 | 231 | 173 | 232 | 116 | 214 | 244 | 234 | 168 | 80 | 88 | 175 |
Пример. Здесь все байты я буду представлять в виде десятичных чисел от 0 до 255. Исходный блок данных:
64 196 132 84 196 196 242 194 4 132 20 37 34 16 236 17
Используется 2-я версия с уровнем коррекции H. В этом случае надо создать 28 байтов коррекции (таблица 5) и использовать генерирующий многочлен (таблица 6):
168 223 200 104 224 234 108 180 110 190 195 147 205 27 232 201 21 43 245 87 42 195 212 119 242 37 9 123
Создадим массив (подготовленный массив) на 28 элементов и заполним его байтами данных:
64 196 132 84 196 196 242 194 4 132 20 37 34 16 236 17 0 0 0 0 0 0 0 0 0 0 0 0
Я подробно распишу первый шаг цикла, остальные в виде готового массива. Первый элемент массива — 64. Убираем его из подготовленного массива:
196 132 84 196 196 242 194 4 132 20 37 34 16 236 17 0 0 0 0 0 0 0 0 0 0 0 0 0
В таблице 8 находим ему соответствие — 6; прибавляем по модулю 255 это число к каждому числу генерирующего многочлена:
174 229 206 110 230 240 114 186 116 196 201 153 211 33 238 207 27 49 251 93 48 201 218 125 248 43 15 129
Для каждого числа гененирующего многочлена находим соответствие в таблице 7:
241 122 83 103 244 44 62 110 248 200 56 146 178 39 11 166 12 140 216 182 70 56 43 51 27 119 38 23
И почленно производим операцию побитового сложения по модулю 2 с подготовленным массивом:
53 254 7 163 48 222 252 106 124 220 29 176 162 203 26 166 12 140 216 182 70 56 43 51 27 119 38 23
Повторяем эти действия 16 раз (16 байт данных). В итоге получатся следующие байты коррекции:
16 85 12 231 54 54 140 70 118 84 10 174 235 197 99 218 12 254 246 4 190 56 39 217 115 189 193 24
Объединение блоков
У нас имеется несколько блоков данных и столько же блоков байтов коррекции, их надо объединить в один поток байт. Делается это следующим образом: из каждого блока данных по очереди берётся один байт информации, когда очередь доходит до последнего блока, из него берётся байт и очередь переходит к первому блоку. Так продолжается до тех пор, пока в каждом блоке не кончатся байты. Если в текущем блоке уже нет байт, то он пропускается (такое происходит, когда обычные блоки уже пусты, а в дополненных ещё есть по одному байту). Аналогичным образом надо сделать с блоками байтов коррекции. Они берутся в том же порядке, что и соответствующие блоки данных.
Размещение информации на QR коде
У нас есть последовательность байт, которая готова для того, чтобы её поместили на холст. Холст состоит из модулей — элементарных квадратов.

Базовые элементы
Размер QR кода зависит только от версии. Для первой версии это 21 модуль, а размеры старших версий определяются из таблицы 9. Вобще в ней указаны места расположения выравнивающих узоров (об этом чуть позже), но размер холста можно определить как последнее число + 7 модулей. Хочу обратить ваше внимание, что отступ, рамка из белых модулей шириной 4 модуля, — полноценная часть QR кода, и её нельзя не учитывать. Несмотря на это, я указываю высоту ширину именно части с чёрными модулями и начинаю отчёт с её верхнего левого угла ((0, 0) — верхний левый модуль верхнего левого поискового узора).
Верхняя строка — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| — | 18 | 22 | 26 | 30 | 34 | 6, 22, 38 | 6, 24, 42 |
| 9 | 10 | 11 | 12 | 13 |
| 6, 26, 46 | 6, 28, 50 | 6, 30, 54 | 6, 32, 58 | 6, 34, 62 |
| 14 | 15 | 16 | 17 | 18 |
| 6, 26, 46, 66 | 6, 26, 48, 70 | 6, 26, 50, 74 | 6, 30, 54, 78 | 6, 30, 56, 82 |
| 9 | 20 | 21 | 22 | 23 |
| 6, 30, 58, 86 | 6, 34, 62, 90 | 6, 28, 50, 72, 94 | 6, 26, 50, 74, 98 | 6, 30, 54, 78, 102 |
| 24 | 25 | 26 | 27 | 28 |
| 6, 28, 54, 80, 106 | 6, 32, 58, 84, 110 | 6, 30, 58, 86, 114 | 6, 34, 62, 90, 118 | 6, 26, 50, 74, 98, 122 |
| 29 | 30 | 31 | 32 |
| 6, 30, 54, 78, 102, 126 | 6, 26, 52, 78, 104, 130 | 6, 30, 56, 82, 108, 134 | 6, 34, 60, 86, 112, 138 |
| 33 | 34 | 35 | 36 |
| 6, 30, 58, 86, 114, 142 | 6, 34, 62, 90, 118, 146 | 6, 30, 54, 78, 102, 126, 150 | 6, 24, 50, 76, 102, 128, 154 |
| 37 | 38 | 39 | 40 |
| 6, 28, 54, 80, 106, 132, 158 | 6, 32, 58, 84, 110, 136, 162 | 6, 26, 54, 82, 110, 138, 166 | 6, 30, 58, 86, 114, 142, 170 |
Поисковые узоры
Это узоры, которые представляют из себя чёрный квадрат размером 3 на 3 модуля, который окружён рамкой из белых модулей, которая окружена рамкой из чёрных модулей, которая окружена рамкой из белых модулей только с тех сторон, где нет отступа. Поисковые узоры располагаются в верхних и левых углах (всего 3).
Выравнивающие узоры
Используются начиная с 2-й версии, представляют из себя чёрный квадрат размером 1 на 1 модуль, который окружён рамкой из белых модулей, которая окружена рамкой из чёрных модулей, в итоге этот узор имеет размер 5 на 5. Места, где располагаются выравнивающие узоры, указаны в таблице 9. Точнее там указаны узлы сетки по вертикали и горизонтали, где располагаются центральные модули узоров. Например, если в таблице написано 6, 22, 38, это значит, что центры модулей должны располагаться в следующих точках: (6, 6), (6, 22), (6, 38), (22, 6), (22, 22), (22, 38), (38, 6), (38, 22), (38, 38). Есть одно важное условие: выравнивающие узоры не должны наслаиваться на поисковые узоры. То есть, когда версия больше 6, в точках (первая, первая), (первая, последняя) и (последняя, первая) выравнивающих узоров не должно быть. В нашем примере это (6, 6), (6, 38) и (38, 6).
Полосы синхронизации
Здесь всё просто. Полосы начинаются от самого нижнего правого чёрного модуля верхнего левого поискового узора и идут, чередуя чёрные и белые модули, вниз и вправо до противоположных поисковых узоров. При наслоении на выравнивающий узор он должен остаться без изменений.
Код версии
Эти элементы используются начиная с 7-й версии. Код версии дублируется в 2-х местах, причём зеркально, то есть указав цвет модуля в координатах (x, y), можно смело указывать такой же цвет в координатах (y, x). Модули в этих местах выстраиваются согласно рисунку ниже и таблице 10 (1 — чёрный, 0 — белый).
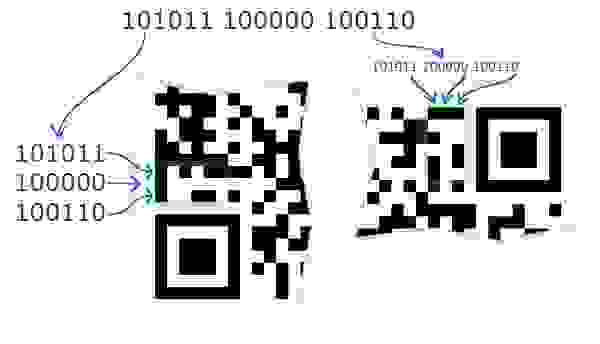
| Версия | Код версии |
| 7 | 000010 011110 100110 |
| 8 | 010001 011100 111000 |
| 9 | 110111 011000 000100 |
| 10 | 101001 111110 000000 |
| 11 | 001111 111010 111100 |
| 12 | 001101 100100 011010 |
| 13 | 101011 100000 100110 |
| 14 | 110101 000110 100010 |
| 15 | 010011 000010 011110 |
| 16 | 011100 010001 011100 |
| 17 | 111010 010101 100000 |
| 18 | 100100 110011 100100 |
| 19 | 000010 110111 011000 |
| 20 | 000000 101001 111110 |
| 21 | 100110 101101 000010 |
| 22 | 111000 001011 000110 |
| 23 | 011110 001111 111010 |
| 24 | 001101 001101 100100 |
| 25 | 101011 001001 011000 |
| 26 | 110101 101111 011100 |
| 27 | 010011 101011 100000 |
| 28 | 010001 110101 000110 |
| 29 | 110111 110001 111010 |
| 30 | 101001 010111 111110 |
| 31 | 001111 010011 000010 |
| 32 | 101000 011000 101101 |
| 33 | 001110 011100 010001 |
| 34 | 010000 111010 010101 |
| 35 | 110110 111110 101001 |
| 36 | 110100 100000 001111 |
| 37 | 010010 100100 110011 |
| 38 | 001100 000010 110111 |
| 39 | 101010 000110 001011 |
| 40 | 111001 000100 010101 |
Код маски и уровня коррекции
Этот код, так же как и предыдущий, дублируется в 2-х местах: рядом с верхним левым поисковым узором и рядом с нижним и правым поисковыми узорами (элемент терпит разрыв). В нём особым образом зашифрованы код маски (об этом чуть позже) и код уровня коррекции. Готовые коды приведены в таблице 11. Маска определяется на самом последнем шаге, когда всё остальное свободное пространство заполняется данными. Из за того, что маска выбирается на основе лучшего варианта (для этого надо перебрать все маски), к добавлению кода маски и уровня коррекции придётся не раз возвращаться. Пока что не добавляйте этот элемент. На рисунке изображено где именно и в каком направлении выстраиваются модули этого элемента, а также красным отмечен модуль, который всегда чёрный.

| Уровень коррекции | Код маски | Код |
| L | 0 | 111011111000100 |
| L | 1 | 111001011110011 |
| L | 2 | 111110110101010 |
| L | 3 | 111100010011101 |
| L | 4 | 110011000101111 |
| L | 5 | 110001100011000 |
| L | 6 | 110110001000001 |
| L | 7 | 110100101110110 |
| M | 0 | 101010000010010 |
| M | 1 | 101000100100101 |
| M | 2 | 101111001111100 |
| M | 3 | 101101101001011 |
| M | 4 | 100010111111001 |
| M | 5 | 100000011001110 |
| M | 6 | 100111110010111 |
| M | 7 | 100101010100000 |
| Q | 0 | 011010101011111 |
| Q | 1 | 011000001101000 |
| Q | 2 | 011111100110001 |
| Q | 3 | 011101000000110 |
| Q | 4 | 010010010110100 |
| Q | 5 | 010000110000011 |
| Q | 6 | 010111011011010 |
| Q | 7 | 010101111101101 |
| H | 0 | 001011010001001 |
| H | 1 | 001001110111110 |
| H | 2 | 001110011100111 |
| H | 3 | 001100111010000 |
| H | 4 | 000011101100010 |
| H | 5 | 000001001010101 |
| H | 6 | 000110100001100 |
| H | 7 | 000100000111011 |
Добавление данных
Всё оставшееся свободное пространство на холсте разбивается на столбики: каждые 2 модуля, не важно что находится в этих модулях, кроме вертикильной полосы синхронизации, которая просто пропускается. Заполнение начинается с правого нижнего угла, идёт в пределах столбика справа налево, снизу вверх. Если текущий модуль занят (например полосой синхронизации или выравнивающим узором), то он просто пропускается. Если достигнут верх столбика, то движение продолжается с верхнего правого угла столбика, который расположен левее, и идёт сверху вниз. Достигнув низа, движение продолжается от нижнего правого угла столбика, который расположен левее, и идёт снизу вверх. И так далее, пока всё свободное пространство не будет заполнено.

Заполнение происходит бит за битом из байтов данных, при этом 1 это чёрный модуль, а 0 — белый. Если данных не хватает, то оставшееся пространство заполняется нулевыми модулями.
При этом на каждый модуль накладывается одна из масок. Всего масок 8 штук (от 0 до 7), их список в таблице 12. Если выражение из таблицы равно нулю, то цвет модуля инвертируется, иначе остаётся неизменным. Маска применяется только к модулям данных.
X — столбец, Y — строка, % — остаток от деления, / — целочисленное деление.
| Номер маски | Маска |
| 0 | (X+Y) % 2 |
| 1 | Y % 2 |
| 2 | X % 3 |
| 3 | (X + Y) % 3 |
| 4 | (X/3 + Y/2) % 2 |
| 5 | (X*Y) % 2 + (X*Y) % 3 |
| 6 | ((X*Y) % 2 + (X*Y) % 3) % 2 |
| 7 | ((X*Y) % 3 + (X+Y) % 2) % 2 |
Маска выбирается по разному: некоторые всегда используют одну и ту же, другие каждый раз случайную, но спецификация настаивает, чтобы каждая маска оценивалась и выбиралась самая оптимальная. Способ с оценкой требует больше времени, но нет ничего страшного, если будет выбрана не оптимальная маска, поэтому не обязательно использовать именно его, но я всё равно расскажу о нём. От выбранной маски зависит код маски и уровня коррекции (см. выше), сейчас самое время добавить этот элемент.
Выбор лучшей маски
Эта часть не обязательна, и, если вы уже определились с выбором маски и добавили на холст данные, ваш QR код готов.
Суть этой процедуры заключается в том, чтобы сгенерировать QR код с каждой из восьми масок, начислить каждой штрафные очки по определённым правилам и выбрать маску с наименьшим количеством очков. Помните, что вместе с данными, на холст заново добавляется элемент кода маски и уровня коррекции.
Правило 1
По горизонтали и вертикали за каждые 5 и больше идущих подряд модулей одного цвета начисляется количество очков, равное длине этого участка минус 2. В этом и во всех остальных правилах отступ не рассматривается, всё ограничивается основным полем.

Правило 2
За каждый квадрат модулей одного цвета размером 2 на 2 начисляется по 3 очка.

Правило 3
За каждую последовательность модулей ЧБЧЧЧБЧ, с 4-мя белыми модулями с одной из сторон (или с 2-х сразу), добавляется 40 очков (по вертикали или горизонтали). Проще говоря, за эти элементы:

В нашем примере всего 3 таких элемента, за что он получает 120 дополнительных очков (не обязательно эти элементы должны пересекаться с поисковым узором):

Правило 4
В конце концов для каждой маски вы получите своё количество штрафных баллов, вам останется только выбрать ту, у которых этих баллов меньше, и ваш QR код полностью готов. Как показывает практика, чем ниже номер маски, тем больше вероятность того, что она окажется лучшей, поэтому для оптимизации можно выбирать лучшую маску не из всех, а, например, из 4-х.



