Машинный код
Из Википедии — свободной энциклопедии

Маши́нный код (платфо́рменно-ориенти́рованный код), маши́нный язы́к — система команд (набор кодов операций) конкретной вычислительной машины, которая интерпретируется непосредственно процессором или микропрограммами этой вычислительной машины. [1]
Компьютерная программа, записанная на машинном языке, состоит из машинных инструкций, каждая из которых представлена в машинном коде в виде т. н. опкода — двоичного кода отдельной операции из системы команд машины. Для удобства программирования вместо числовых опкодов, которые только и понимает процессор, обычно используют их условные буквенные мнемоники. Набор таких мнемоник, вместе с некоторыми дополнительными возможностями (например, некоторыми макрокомандами, директивами), называется языком ассемблера.
Каждая модель процессора имеет собственный набор команд, хотя во многих моделях эти наборы команд сильно перекрываются. Говорят, что процессор A совместим с процессором B, если процессор A полностью «понимает» машинный код процессора B. Если процессоры A и B имеют некоторое подмножество инструкций, по которым они взаимно совместимы, то говорят, что они одной «архитектуры» (имеют одинаковую архитектуру набора команд).
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Машинный код
Машинный код или машинный язык представляет собой набор инструкций, выполняемых непосредственно центральным процессором компьютера (CPU). Каждая команда выполняет очень конкретную задачу, например, загрузки (load), перехода (jump) или элементарной арифметической или логической операции для единицы данных в регистре процессора или памяти. Каждая программа выполняется непосредственно процессором и состоит из ряда таких инструкций.
Машинный код можно рассматривать как самое низкоуровневое представление скомпилированной или собранной компьютерной программы или в качестве примитивного и аппаратно-зависимого языка программирования. Писать программы непосредственно в машинном коде возможно, однако это утомительно и подвержено ошибкам, так как необходимо управлять отдельными битами и вычислять числовые адреса и константы вручную. По этой причине машинный код практически не используется для написания программ.
Почти все практические программы сегодня написаны на языках более высокого уровня или ассемблере. Исходный код затем транслируется в исполняемый машинный код с помощью таких утилит, как интерпретаторы, компиляторы, ассемблеры, и/или линкеры. [Источник 1]
Содержание
Инструкции машинного кода (ISA)
Каждый процессор или семейство процессоров имеет свой собственный набор инструкций машинного кода. Инструкции являются паттернами битов, которые в силу физического устройства соответствуют различным командам машины. Говорят, что процессор A совместим с процессором B, если процессор A полностью «понимает» машинный код процессора B. Если процессоры A и B имеют некоторое подмножество инструкций, по которым они взаимно совместимы, то говорят, что они одной архитектуры. Таким образом, набор команд является специфическим для одного класса процессоров. Новые процессоры одной архитектуры часто включают в себя все инструкции предшественника и могут включать дополнительные. Иногда новые процессоры прекращают поддержку или изменяют значение какого-либо кода команды (как правило, потому, что это необходимо для новых целей), влияя на совместимость кода до некоторой степени; даже почти полностью совместимые процессоры могут показать различное поведение для некоторых команд, но это редко является проблемой.
Системы также могут отличаться в других деталях, таких как расположение памяти, операционные системы или периферийные устройства. Поскольку программа обычно зависит от таких факторов, различные системы, как правило, не запустят один и тот же машинный код, даже если используется тот же тип процессора. [Источник 2]
Виды ISA
x86 всегда был архитектурой с инструкциями переменной длины, так что когда пришла 64-битная эра, расширения x64 не очень сильно повлияли на ISA. ARM это RISC-процессор разработанный с учетом инструкций одинаковой длины, что было некоторым преимуществом в прошлом. Так что в самом начале все инструкции ARM кодировались 4-мя байтами. Это то, что сейчас называется «режим ARM».
На самом деле, самые используемые инструкции процессора на практике могут быть закодированы c использованием меньшего количества информации. Так что была добавлена ISA с названием Thumb, где каждая инструкция кодируется всего лишь 2-мя байтами. Теперь это называется «режим Thumb». Но не все инструкции ARM могут быть закодированы в двух байтах, так что набор инструкций Thumb ограниченный. Код, скомпилированный для режима ARM и Thumb может сосуществовать в одной программе. Затем создатели ARM решили, что Thumb можно расширить: так появился Thumb-2 (в ARMv7). Thumb-2 это всё ещё двухбайтные инструкции, но некоторые новые инструкции имеют длину 4 байта. Распространено заблуждение, что Thumb-2 — это смесь ARM и Thumb. Это неверно. Режим Thumb-2 был дополнен до более полной поддержки возможностей процессора и теперь может легко конкурировать с режимом ARM. Основное количество приложений для iPod/iPhone/iPad скомпилировано для набора инструкций Thumb-2, потому что Xcode делает так по умолчанию. Потом появился 64-битный ARM. Это ISA снова с 4-байтными инструкциями, без дополнительного режима Thumb. Но 64-битные требования повлияли на ISA, так что теперь у нас 3 набора инструкций ARM: режим ARM, режим Thumb (включая Thumb-2) и ARM64. Эти наборы инструкций частично пересекаются, но можно сказать, это скорее разные наборы, нежели вариации одного. Существует ещё много RISC ISA с инструкциями фиксированной 32-битной длины — это как минимум MIPS, PowerPC и Alpha AXP. [Источник 3]
Выполнение инструкций
Компьютерная программа представляет собой последовательность команд, которые выполняются процессором. В то время как простые процессоры выполняют инструкции один за другим, суперскалярные процессоры способны выполнять несколько команд одновременно.
Программа может содержать специальные инструкций, которые передают выполнение инструкции, не идущей по порядку вслед за предыдущей. Условные переходы принимаются (выполнение продолжается по другому адресу) или нет (выполнение продолжается на следующей инструкции) в зависимости от некоторых условий.
Абсолютный и позиционно-независимый код
Позиционно-независимый код — программа, которая может быть размещена в любой области памяти, так как все ссылки на ячейки памяти в ней относительные (например, относительно счётчика команд). Такую программу можно переместить в другую область памяти в любой момент, в отличие от перемещаемой программы, которая хотя и может быть загружена в любую область памяти, но после загрузки должна оставаться на том же месте.
Возможность создания позиционно-независимого кода зависит от архитектуры и системы команд целевой платформы. Например, если во всех инструкциях перехода в системе команд должны указываться абсолютные адреса, то код, требующий переходов, практически невозможно сделать позиционно-независимым. В архитектуре x86 непосредственная адресация в инструкциях работы с данными представлена только абсолютными адресами, но поскольку адреса данных считаются относительно сегментного регистра, который можно поменять в любой момент, это позволяет создавать позиционно-независимый код со своими ячейками памяти для данных. Кроме того, некоторые ограничения набора команд могут сниматься с помощью самомодифицирующегося кода или нетривиальных последовательностей инструкций.
Хранение в памяти
Гарвардская архитектура представляет собой компьютерную архитектуру с физически разделенным хранением сигнальных путей для инструкций и данных. На сегодняшний день, в большинстве процессоров реализованы отдельные сигнальные пути для повышения производительности. Модифицированная Гарвардская архитектура поддерживает такие задачи, как загрузка исполняемой программы из дисковой памяти в качестве данных, а затем её выполнение. Гарвардская архитектура контрастирует с архитектурой фон Неймана, где данные и код хранятся в памяти вместе, и считываются процессором, позволяя компьютеру выполнять команды.
С точки зрения процесса, кодовое пространство является частью его адресного пространства, в котором код сохраняется во время исполнения. В многозадачных системах оно включает в себя сегмент кода программы и, как правило, совместно используемые библиотеки. В многопоточной среде различные потоки одного процесса используют кодовое пространство и пространство данных совместно, что повышает скорость переключения потока.
Связь с языками программирования
Ассемблерные языки
Гораздо более читаемым представлением машинного языка называется язык ассемблера, использующий мнемонические коды для обозначения инструкций машинного кода, а не с помощью числовых значений. Например, на процессоре Zilog Z80, машинный код 00000101, который дает указание процессору декрементировать регистр процессора B, будет представлен на языке ассемблера как DEC B.
Связь с микрокодом
В некоторых компьютерных архитектурах, машинный код реализуется с помощью более фундаментального базового слоя программ, называемых микропрограммами, обеспечивающими общий интерфейс машинного языка для линейки различных моделей компьютеров с самыми различными базовыми потоками данных. Это делается для облегчения портирования программ на машинном языке между различными моделями. Примером такого использования являются компьютеры IBM System/360 и их наследники. Несмотря на то, что ширина потоков данных разнится от 8 до 64 бит и более, тем не менее они представляют общую архитектуру на уровне машинного языка по всей линейке.
Использование микрокода для реализации эмулятора позволяет компьютеру симулировать совершенно другую архитектуру. Семейство System / 360 использовало это для портирования программ с более ранних машин IBM на новые семейства компьютеров, например на IBM 1401/1440/1460.
Связь с байткодом
Машинный код, как правило, отличается от байт-кода (также известного как р-код), который либо выполняется интерпретатором, или сам компилируется в машинный код для более быстрого исполнения. Исключением является ситуация, когда процессор предназначен для использования конкретного байт-кода как машинного, например, как в случае с процессорами Java. Машинный и ассемблерный код иногда называют собственным (внутренним) кодом ЭВМ, когда ссылаются на платформо-зависимые части свойств или библиотек языка. [Источник 4]
Примеры
Пример MIPS 32-bit инструкции
Набор инструкций MIPS – пример машинного кода с инструкциями фиксированной длины – 32 бита. Тип инструкции содержится в поле op (поле операции) – первые 6 бит. Например типы инструкций перехода или немедленных операций полностью определяются этим полем. Инструкции регистров включают дополнительное поле funct, для определения конкретной операции. Все поля, использущиеся в данных типах инструкций:
Rs,rt и rd – индикаторы задействования регистров, shamt – параметр сдвига,а поле address/immediate явно содержит операнд.
Пример: сложение значений в регистрах 1 и 2 и запись результата в регистр 6:
Пример: загрузка значения в регистр 8, взятое из ячейки памяти, находящейся на 68 ячеек дальше, чем адрес, находящийся в регистре 3:
Пример: переход к адресу 1024:
Пример для x86 (MS DOS) – “Hello, World!”
Программа «Hello, world!» для процессора архитектуры x86 (ОС MS-DOS, вывод при помощи BIOS прерывания int 10h) выглядит следующим образом (в шестнадцатеричном представлении):
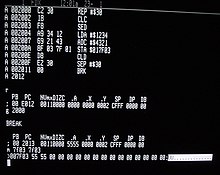
BB 11 01 B9 0D 00 B4 0E 8A 07 43 CD 10 E2 F9 CD 20 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
Данная программа работает при её размещении по смещению 10016. Отдельные инструкции выделены цветом:
Как работает процессор и языки программирования

Эта статья будет полезна всем, кто по каким-либо причинам не знает, как работает процессор, как и зачем появились языки программирования и принцип их работы.
Все описанное ниже как всегда упрощено для лучшего понимания.
Процессор и оперативная память
Все вы знаете, что процессор в компьютере — это мозг. Он управляет всеми процессами, происходящими внутри этой консервной банки. Но знаете ли вы, как он работает?

Начнем вот с чего. Процессор не понимает русский, английский и другие языки. Он понимает числа, которые являются для него простыми командами, например: взять из памяти какие-то данные, добавить какие-то данные, сложить и т.д.
Процессор знает много команд и у каждой из них есть свой числовой код, например:

Совокупность всех команд и их числовых кодов, заложенных инженерами в процессор, называется архитектурой процессора. Это не аппаратная архитектура, а программная. Каждый производитель процессоров закладывает свою архитектуру. Это значит, что у одной и той же команды будут разные числовые коды на разных процессорах.

Понимаете прикол? Это значит, что вам нужно писать код для каждой архитектуры процессора. Жуть.
Так. Понятно. Процессор может выполнять маленькие числовые команды. Но откуда он их берет? Из оперативной памяти. Думайте об оперативке, как о большом количестве маленьких ячеек. Каждая ячейка имеет свой адрес — это обычное число, например 2001. По адресу ячейки процессор может запросить данные и оперативная память вернет их ему. Также в эту ячейку процессор может записать новые данные.
Как я уже сказал, в ячейках оперативной памяти хранятся команды для процессора. Но также в них могут храниться любые другие данные, которые можно представить в числовом виде, например: буквы, изображения, музыка или видео.
Получается такая картина: процессор обращается к оперативной памяти по адресу ячейки, оперативка возвращает ему команду из этой ячейки, процессор выполняет команду. А что дальше? А дальше процессор опять обращается к памяти (уже в другую ячейку), получает команду, выполняет ее и этот цикл повторяется снова и снова. То есть процессор все время выполняет какую-то заданную последовательность команд (числовых кодов). Эта последовательность команд называется машинным кодом.

Ассемблер
Как мы помним, процессор спроектирован таким образом, чтобы выполнять простые команды, загруженные из оперативной памяти.
Для того, чтобы заставить процессор выполнить какую-то программу, например решить уравнение 2 + 2 * 2, нам нужно написать цепочку простых числовых команд.

Согласитесь, что писать такой код очень сложно и легко запутаться. И это мы всего лишь написали код для решения простого уравнения. А теперь представьте, как написать ВКонтактик или Инстаграм.
Для упрощения жизни люди придумали инструмент Ассемблер и язык программирования на ассемблере.
Теперь все числовые коды команд процессора заменили на буквенные аббревиатуры, которые стало легче запоминать и читать.
Помните примеры кодов команд, которые были указаны выше? Теперь они выглядят так:
Также к названию команд были добавлены операнды (один или более), которые дают дополнительную информацию для выполнения команды.

Рассмотрим еще один пример программы на ассемблере, которая выводит фразу «Hello, World!«. Пример ассемблированного кода:
Что-то слишком много непонятного кода для такой пустяковой задачи, не правда ли?
Языки программирования высшего уровня
Помните в самом начале я писал, что каждый производитель процессоров делает свою архитектуру? И что у каждой архитектуры свои числовые коды команд?
Так вот одну и ту же программу на ассемблере вам придется «пересобирать» под каждую из архитектур процессора. Для каждой архитектуры нужно скачивать отдельный инструмент Ассемблер и прогонять через него свой код.
Это усложняет портативность. Добавим сюда сложность в написании больших программ и получим необходимость в создании новых инструментов.
Так стали появляться языки программирования высокого уровня.
Их суть заключается в том, что цепочки команд на ассемблере были объединены в отдельные функции. Теперь вам достаточно написать одну команду, чтобы показать сообщение «Hello, World!».
Компилируемые языки
Первыми появились компилируемые языки программирования. К ним относится С, С++, Java и другие.
Компилируемый язык программирования означает, что есть инструмент компилятор, который преобразует код высшего порядка в код, понятный процессору.
Рассмотрим чуть подробнее. Например на языке С вывод фразы «Hello, World!» будет выглядеть так: printf(«Hello, World!»). Просто и понятно.

Но процессор не поймет этой команды. Как мы помним, он знает и понимает только маленькие числовые команды. Поэтому компилятор языка C преобразует команду в ассемблированный код, а затем в машинный код, понятный процессору.

Программа, написанная на компилируемом языке программирования, перед запуском всегда проходит процесс компиляции. То есть весь написанный код высшего порядка преобразуется в машинный код, понятный процессору.
Затем компилятор делает исполняемый файл, который можно скинуть другу, чтобы он запустил вашу программу на своем компьютере.

Но у некоторых компиляторов есть свой прикол: чтобы ваша программа работала на всех операционных системах и всех архитектурах процессоров, вам нужно скомпилировать ее для этих вещей. И это может быть не так удобно.
Интерпретируемые языки
Компилируемые языки намного упростили задачу написания кода. Но что, если я скажу, что можно написать программу, которая будет работать на всех архитектурах процессоров и любой операционной системе?
Вот тут в ход идут интерпретируемые языки программирования такие как: Python, PHP, Perl, Pascal и другие.
Это тоже языки высшего порядка, которые также упрощают написание кода. Но у них есть как минимум два преимущества перед компилируемыми языками:
Интерпретатор работает почти так же, как и компилятор, но с одной маленькой, но значительной особенностью: он преобразует код высшего порядка не в машинный код, а еще ниже — в байткод.

Байткод — это код, который понимают все процессоры не зависимо от архитектуры.
Конечно, в этом решении есть свой недостаток. В силу своей гибкости интерпретируемые языки подвержены низкой скорости работы из-за большего числа инструкций, которые генерирует интерпретатор. Но это напрямую зависит от того, насколько круто написан интерпретатор.
Подытожим
Байткод — саааамый низкий язык, который понимает процессор.
Машинный код — цепочка числовых команд. Все числовые команды процессора создают архитектуру процессора, заложенную инженерами при проектировании. У разных производителей процессоров могут отличаться номера одних и тех же команд.
Ассемблер — инструмент, который преобразует ассемблированный код в машинный. Программы на ассемблированном языке писать проще, чем машинный код, но все равно гемор.
Компилятор и Интерпретатор — инструменты, преобразующие код высшего уровня в код, понятный процессору.
Язык высшего уровня — это сказка, позволяющая создавать большие программы с помощью простых и понятных функций.
Я надеюсь, что теперь вы лучше представляете, как работает ваш компьютер или смартфон и будете терпеливее относится к их затупам 🙂 Ведь железка не виновата, что тупит, а виноват горе-программист, который написал плохой код.
Если вы с чем-то не согласны, у вас есть вопросы или просто хотите сказать спасибо — прошу в комментарии. Пообщаемся 🙂
СОДЕРЖАНИЕ
Набор инструкций
В наборе команд процессора могут быть все команды одинаковой длины или могут быть команды переменной длины. Как организованы шаблоны, зависит от конкретной архитектуры и типа обучения. Большинство инструкций имеют одно или несколько полей кода операции, которые определяют базовый тип инструкции (например, арифметическая, логическая, переход и т. Д.), Операцию (например, сложение или сравнение) и другие поля, которые могут указывать тип операнда (s ), режим (ы) адресации, смещение (я) адресации или индекс, или само значение операнда (такие постоянные операнды, содержащиеся в инструкции, называются непосредственными ).
Программ
На выполнение программы могут влиять специальные инструкции «перехода», которые передают выполнение на адрес (и, следовательно, на инструкцию), отличный от следующего числового последовательного адреса. Возникновение этих условных переходов зависит от такого условия, как значение, которое больше, меньше или равно другому значению.
Языки ассемблера
Пример
Например, сложение регистров 1 и 2 и помещение результата в регистр 6 кодируется:
Загрузите значение в регистр 8, взятое из ячейки памяти 68 ячеек после ячейки, указанной в регистре 3:
Переход по адресу 1024:
Связь с микрокодом
Использование микрокода для реализации эмулятора позволяет компьютеру представить архитектуру совершенно другого компьютера. Линия System / 360 использовала это, чтобы позволить переносить программы с более ранних машин IBM на новое семейство компьютеров, например, эмулятор IBM 1401/1440/1460 на IBM S / 360 model 40.
Связь с байт-кодом
Машинный код и ассемблерный код иногда называют собственным кодом, когда речь идет о платформенно-зависимых частях языковых функций или библиотек.
Хранение в памяти
Читаемость людьми
Машинный код
Машинный код (платформенно-ориентированный код), машинный язык — система команд (набор кодов операций) конкретной вычислительной машины, которая интерпретируется непосредственно процессором или микропрограммами этой вычислительной машины. [1]
Каждая инструкция выполняет определённое (обычное элементарное) действие, такое как операция с данными (например, сложение или копирование; в регистре или в памяти) или переход к другому участку кода (изменение порядка исполнения; при этом переход может быть безусловным или условным, зависящим от результатов предыдущих инструкций). Каждая исполнимая программа состоит из последовательности таких атомарных инструкций.
Машинный код можно рассматривать как примитивный язык программирования или как самый низкий уровень представления скомпилированных или ассемблированных компьютерных программ. Хотя вполне возможно создавать программы прямо в машинном коде, сейчас это делается редко в силу громоздкости кода и трудоёмкости управления ресурсами процессора, за исключением ситуаций, когда требуется экстремальная оптимизация. Поэтому подавляющее большинство программ пишется на языках более высокого уровня и транслируется в машинный код компиляторами. Машинный код иногда называют нативным кодом (также собственным или родным кодом — от англ. native code ), когда говорят о платформенно-зависимых частях языка или библиотек. [2]
Программы на интерпретируемых языках (таких как Бейсик или Python) не транслируются в машинный код, вместо этого они либо исполняются непосредственно интерпретатором, либо транслируются в псевдокод (байт-код). Однако интерпретаторы этих языков (которые сами можно рассматривать как процессоры) как правило представлены в машинном коде.
Каждая модель процессора имеет свой собственный набор команд, хотя во многих моделях эти наборы команд сильно перекрываются. Говорят, что процессор A совместим с процессором B, если процессор A полностью «понимает» машинный код процессора B. Если процессор A знает несколько команд, которых не понимает процессор B, то B несовместим с A.
Раньше процессоры просто выполняли инструкции одну за другой, но новые суперскалярные процессоры способны выполнять несколько инструкций за раз.
Также инструкции бывают постоянной длины (у RISC-, MISC-архитектур) и диапазонной (у CISC-архитектур; например, для архитектуры x86 команда имеет длину от 8 до 120 битов).
Содержание
Микрокод
В некоторых компьютерных архитектурах поддержка машинного кода реализуется ещё более низкоуровневым слоем программ, называемых микропрограммами, что позволяет обеспечить единый интерфейс машинного языка у всей линейки или семейства компьютеров, которые могут иметь значительные структурные отличие между собой. Это делается для облегчения переноса программ в машинном коде между разными моделями компьютеров. Примером этого является семейство компьютеров IBM System/360 и их преемников: несмотря на разные шины шириной от 8 до 64 бит и выше, тем не менее у них общая архитектура на уровне машинного языка.
Использование слоя микрокода для реализации эмулятора позволяет компьютеру представлять архитектуру совершенно другого компьютера. В линейке System/360 это использовалось для переноса программ с более ранних машин IBM на новое семейство — например, эмулятор IBM 1401/1440/1460 на IBM S/360 model 40.
Абсолютный и позиционно-независимый код
Позиционно-независимый код (англ. position-independent code ) — программа, которая может быть размещена в любой области памяти, так как все ссылки на ячейки памяти в ней относительные (например, относительно счётчика команд). Такую программу можно переместить в другую область памяти в любой момент, в отличие от перемещаемой программы, которая хотя и может быть загружена в любую область памяти, но после загрузки должна оставаться на том же месте. [1]
Возможность создания позиционно-независимого кода зависит от архитектуры и системы команд целевой платформы. Например, если во всех инструкциях перехода в системе команд должны указываться абсолютные адреса, то код, требующий переходов, практически невозможно сделать позиционно-независимым. В архитектуре x86 непосредственная адресация в инструкциях работы с данными представлена только абсолютными адресами, но поскольку адреса данных считаются относительно сегментного регистра, который можно поменять в любой момент, это позволяет создавать позиционно-независимый код со своими ячейками памяти для данных. Кроме того, некоторые ограничения набора команд могут сниматься с помощью самомодифицирующегося кода или нетривиальных последовательностей инструкций.
Программа «Hello, world!»
Программа «Hello, world!» для процессора архитектуры x86 (ОС DOS, вывод при помощи BIOS Int 10h (англ.) выглядит следующим образом (в шестнадцатеричном представлении побайтно):
BB 11 01 B9 0D 00 B4 0E 8A 07 43 CD 10 E2 F9 CD 20 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
Данная программа работает при её размещении по смещению 10016. Отдельные инструкции выделены цветом:



