Представление символов, таблицы кодировок
Содержание
Представление символов в вычислительных машинах [ править ]
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Таблицы кодировок [ править ]
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII [ править ]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
Кодировки стандарта ASCII ( [math]8[/math] бит):
Структурные свойства таблицы [ править ]
Кодировки стандарта UNICODE [ править ]
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство [ править ]
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^<31>[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^<16>[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы [ править ]
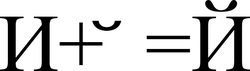
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления [ править ]
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 [ править ]
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования [ править ]
Правила записи кода одного символа в UTF-8 [ править ]
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8 [ править ]
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16 [ править ]
UTF-16LE и UTF-16BE [ править ]
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32 [ править ]
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Порядок байт [ править ]
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
[math]M = \sum_
Варианты записи [ править ]
Порядок от старшего к младшему [ править ]
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему [ править ]
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок [ править ]
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок [ править ]
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия [ править ]

Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт [ править ]
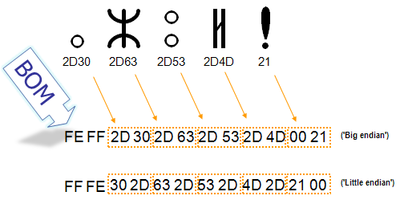
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода [ править ]
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры [ править ]
Кодирование символов
Кодировка символов (часто называемая также кодовой страницей ) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | 0 | Ctrl + @ | Нуль |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| enq | 5 | Ctrl + E | Запрос |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | Управление устройством 2 |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | Конец среды |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + \ | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
Базовая таблица кодировки ASCII
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы | |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| тильда | |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| < | левая открывающая фигурная скобка |
| > | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| / | слэш, косая черта, знак дроби |
| правая закрытая угловая скобка, знак больше | |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Тип кодировки задается в свойствах проекта Microsoft Visual Studio: 

Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR :
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T(«строка»)



