Гены, генетический код и его свойства
Содержание:
Генетический код – это информация в геноме, где закодированы строение и структура белковых молекул человеческого организма. Одна молекула ДНК является «носительницей знаний» о сотнях тысяч белков.
Структура белковой молекулы записана как на ленте кинопленке – на одном гене. Чтобы синтез белка прошел удачно, информация определенным образом считывается с молекулы ДНК. Благодаря этому синтезируются разные и похожие по структуре белковые макромолекулы.
Ген – это элементарная единица, предназначенная для хранения наследственной информации. Учеными-генетиками подсчитано количество наследственной информации, которая пока определяется 30 000 генов.
Все гены делятся на две большие категории:
Структура гена

Нить ДНК состоит из последовательно расположенных нуклеотидов, а цепочка белковой молекулы строится из аминокислот. Для синтеза белка нужно 20 аминокислот. Каждая аминокислота кодируется тремя нуклеотидами ДНК (триплет).
К сведению: Для каждого организма генетический код является универсальной формулой, которая отличается только последовательностью нуклеотидов. В 1965 году ученые-генетики частично расшифровали структуру генетического кода. Был открыт 61 триплет, чтобы закодировать аминокислоты и 3 стоп-триплета, означающие окончание гена.
Общие черты генетического кода:
Свойства генетического кода

Генетический код строится из триплетов (тройки) нуклеотидов, расположенных в нескольких комбинациях. Каждый триплет кодирует конкретную аминокислоту, которая будет встроена в полипептидную белковую цепочку. Часть кодонов расшифрована и есть таблицы, в которых указана последовательность триплетов ДНК, необходимых для построения отдельных белковых молекул.
На заметку: Исключительность каждой личности – факт, установленный научно. Исключение составляют только однояйцевые близнецов. Комбинации генов в геноме постоянно меняются, поэтому невозможно рождение второго Баха, Менделеева, Пушкина или любого другого человека, который уже существовал на Земле.
Генетический код
Генети́ческий код — свойственный всем живым организмам способ кодирования аминокислотной последовательности белков при помощи последовательности нуклеотидов.
В ДНК используется четыре азотистых основания — аденин (А), гуанин (G), цитозин (С), тимин (T), которые в русскоязычной литературе обозначаются буквами А, Г, Ц и Т. Эти буквы составляют алфавит генетического кода. В РНК используются те же нуклеотиды, за исключением тимина, который заменён похожим нуклеотидом — урацилом, который обозначается буквой U (У в русскоязычной литературе). В молекулах ДНК и РНК нуклеотиды выстраиваются в цепочки и, таким образом, получаются последовательности генетических букв.


Белки практически всех живых организмов построены из аминокислот всего 20 видов. Эти аминокислоты называют каноническими. Каждый белок представляет собой цепочку или несколько цепочек аминокислот, соединённых в строго определённой последовательности. Эта последовательность определяет строение белка, а следовательно все его биологические свойства.
Реализация генетической информации в живых клетках (то есть синтез белка, кодируемого геном) осуществляется при помощи двух матричных процессов: транскрипции (то есть синтеза мРНК на матрице ДНК) и трансляции генетического кода в аминокислотную последовательность (синтез полипептидной цепи на мРНК). Для кодирования 20 аминокислот, а также сигнала «стоп», означающего конец белковой последовательности, достаточно трёх последовательных нуклеотидов. Набор из трёх нуклеотидов называется триплетом. Принятые сокращения, соответствующие аминокислотам и кодонам, изображены на рисунке.
Содержание
Свойства
Таблицы соответствия кодонов мРНК и аминокислот
| 2-е основание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U | C | A | G | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1-е основание | U | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
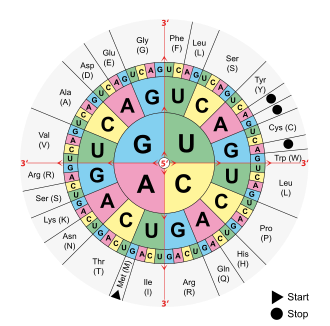
| Ala/A | GCU, GCC, GCA, GCG | Leu/L | UUA, UUG, CUU, CUC, CUA, CUG |
|---|---|---|---|
| Arg/R | CGU, CGC, CGA, CGG, AGA, AGG | Lys/K | AAA, AAG |
| Asn/N | AAU, AAC | Met/M | AUG |
| Asp/D | GAU, GAC | Phe/F | UUU, UUC |
| Cys/C | UGU, UGC | Pro/P | CCU, CCC, CCA, CCG |
| Gln/Q | CAA, CAG | Ser/S | UCU, UCC, UCA, UCG, AGU, AGC |
| Glu/E | GAA, GAG | Thr/T | ACU, ACC, ACA, ACG |
| Gly/G | GGU, GGC, GGA, GGG | Trp/W | UGG |
| His/H | CAU, CAC | Tyr/Y | UAU, UAC |
| Ile/I | AUU, AUC, AUA | Val/V | GUU, GUC, GUA, GUG |
| START | AUG | STOP | UAG, UGA, UAA |
Вариации стандартного генетического кода
В некоторых белках нестандартные аминокислоты, такие как селеноцистеин и пирролизин, вставляются рибосомой, прочитывающей стоп-кодон, что зависит от последовательностей в мРНК. Селеноцистеин сейчас рассматривается в качестве 21-й, а пирролизин 22-й аминокислот, входящих в состав белков.
Несмотря на эти исключения, у всех живых организмов генетический код имеет общие черты: кодон состоят из трёх нуклеотидов, где два первых являются определяющими, кодоны транслируются тРНК и рибосомами в последовательность аминокислот.
История представлений о генетическом коде
Тем не менее в начале 60-х годов XX века новые данные обнаружили несостоятельность гипотезы «кода без запятых». Тогда эксперименты показали, что кодоны, считавшиеся Криком бессмысленными, могут провоцировать белковый синтез в пробирке, и к 1965 году был установлен смысл всех 64 триплетов. Оказалось, что некоторые кодоны просто-напросто избыточны, то есть целый ряд аминокислот кодируется двумя, четырьмя или даже шестью триплетами.
Таинственный код нашего генома
Расшифровка генетического код стала важным научным событием двадцатого века. Сейчас перед учеными появляются новые загадки о функционировании нашего генома.
Автор
Редакторы
Последовательность ДНК определяет строение белка с помощью триплетного генетического кода, в котором каждой аминокислоте соответствует три нуклеотида. Случайные мутации приводят к изменению последовательности нуклеотидов, в результате чего появляются новые варианты белков. Именно так до недавнего времени представляли себе ученые эволюцию белков. Но благодаря исследованиям последних лет оказалось, что помимо генетического кода есть и другие «коды», которые диктуют эволюции белков свои правила.
Одним из важных свойств генетического кода является его избыточность — каждая аминокислота, как правило, кодируется не одним, а 2–6 кодонами. Интересно, что при этом частота использования разных кодонов, отвечающих за одну и ту же аминокислоту, различается как в прокариотических, так и в эукариотических геномах [1]. У организмов с коротким жизненным циклом предпочтения одних кодонов другим связывают с необходимостью в увеличении эффективности транскрипции и стабильности мРНК [2], [3]. Однако в случае геномов млекопитающих такое объяснение подходит лишь для небольшого количества случаев, поэтому в последние годы ученые активно занимаются изучением особенностей геномов млекопитающих и причин предпочтительного использования тех или иных кодонов.
Важное значение в частоте использования кодонов играют транскрипционные факторы — к такому выводу пришла группа ученых из Университета Вашингтона под руководством Джона Стаматояннопоулоса (John A. Stamatoyannopoulos). В опубликованной в журнале Science статье обсуждается, как транскрипционные факторы могут управлять эволюцией белков посредством влияния на частоту использования кодонов [4].
Транскрипционные факторы (ТФ) — это белки, регулирующие транскрипцию генов при связывании с ДНК. ТФ могут повышать транскрипцию или снижать ее, влияя, таким образом, на количество мРНК и белка, соответствующих определенному гену. Долгое время считалось, что ТФ связываются только в некодирующей (не содержащей генов) части ДНК. В своем новом исследовании группа Стаматояннопоулоса выяснила, что на самом деле во многих генах человека ТФ связываются с кодирующими последовательностями ДНК (т.е. с теми, которые являются частью генов). Так как эффективность связывания ТФ с ДНК зависит от того, какие именно нуклеотиды находятся в сайте связывания, ТФ могут снижать возможное разнообразие кодонов в местах своей посадки (рис. 1). При этом даже нейтральные с точки зрения белка мутации (те, при которых последовательность аминокислот не меняется благодаря избыточности генетического кода) могут изменять эффективность связывания ТФ с ДНК и становиться материалом для естественного отбора. Получается, что эволюция белков определяется не только хорошо изученным генетическим кодом, но и другим особенным кодом — «кодом связывания ТФ». Ранее были описаны и некоторые другие «регуляторные» коды, которые контролируют организацию хроматина [5], пространственную структуру и сплайсинг мРНК [5], [6], эффективность трансляции [7], ко-трансляционный фолдинг белков [8] (рис. 2). Все они могут влиять на предпочтительное использование тех или иных кодонов.
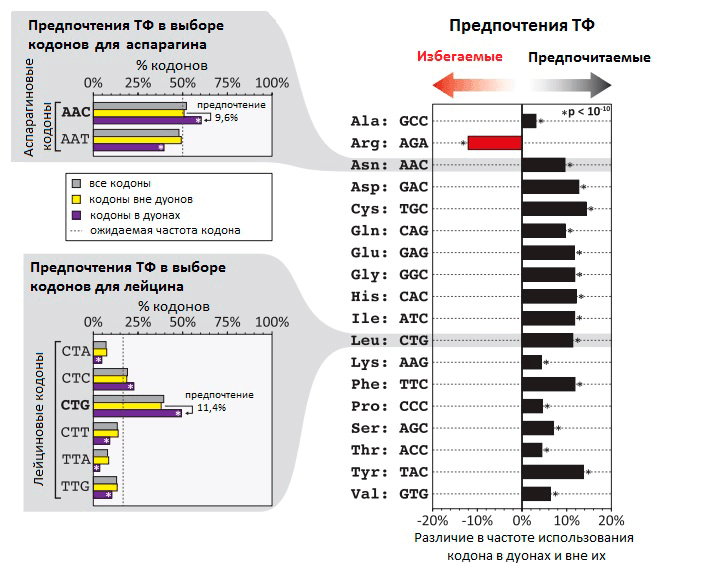
Рисунок 1. Неслучайная частота использования кодов в дуонах в местах связывания ТФ с ДНК. На гистограмме видно, что частота использования некоторых кодонов на 5–15% выше в дуонах, чем вне дуонов. В случае аргинина кодон AGA, напротив, гораздо реже встречается в дуонах, чем в других участках генома. В левой части рисунка — распределение частоты использования разных кодонов на примере кодонов для аспарагина и лейцина.
Насколько в геноме распространено применение дополнительных «регуляторных» кодов, которые перекрывают генетический код, и какое влияние они оказывают на эволюцию белков? Сотрудники лаборатории Стаматояннопоулоса попытались ответить на этот вопрос при исследовании «кода связывания ТФ». Чтобы выявить участки ДНК, связывающиеся с ТФ, они применили метод картирования с помощью дезоксирибонуклеазы I. Этот фермент разрушает одноцепочечные участки ДНК — если только они в этот момент не связаны с ТФ (в таком случае они сохранятся). Ученые исследовали 81 тип человеческих клеток, определив точные нуклеотидные последовательности связанных с ТФ участков генов. Оказалось, что приблизительно 14% кодонов в 86,9% генов человека связаны с различными транскрипционными факторами. В своей статье исследователи предлагают называть эти участки генов «дуонами», т.к. они кодируют два типа информации — информацию о белковой последовательности в виде генетического кода и информацию об экспрессии гена с помощью связывания ТФ. Для нормальной экспрессии гена необходимо связывание ДНК с ТФ, поэтому существуют определенные ограничения на использование различных кодонов, обусловленные строением ДНК-связывающего участка ТФ.
В геноме человека широко распространены однонуклеотидные полиморфизмы (single nucleotide polymorphisms, SNP) — различия последовательности гомологичных генов разных людей на один нуклеотид. Могут ли такие однонуклеотидные различия повлиять на эффективность связывания ТФ с ДНК? Чтобы узнать это, ученые из лаборатории Стаматояннопоулоса нашли на полученной ими карте дуонов почти 600 тыс. известных сайтов SNP, связанных с развитием какого-либо заболевания или проявлением определенного фенотипического признака. Оказалось, что 17,4% сайтов полиморфизма изменяют результаты картирования с помощью дезоксирибонуклеазы I, т.е. они, вероятно, снижают эффективность связывания ТФ с ДНК. Это изменение не зависит от того, является ли данный полиморфизм синонимичным или несинонимичным (т.е. влияет ли замена нуклеотида на замену аминокислоты в белке). Интересно, что значительная часть несинонимичных замен, хотя и приводит к изменению последовательности белка, не приводит к нарушению его функций. В этих случаях изменения нуклеотидной последовательности приводят только к нарушению связывания ТФ с ДНК. Эта находка поддерживает гипотезу о том, что SNP в кодирующей ДНК могут приводить к развитию заболеваний без влияния на функцию белка [9], [10]. Поэтому при изучении роли SNP в различных заболеваниях и при исследовании экзома необходимо учитывать весь спектр «регуляторных кодов», взаимодействующих с последовательностью гена.
«Регуляторные коды» далеко не всегда мирно и гармонично сосуществуют. В генах плодовой мушки Drosophila melanogaster ближе к концу экзонов наблюдается резкое снижение частоты использования оптимальных для трансляции кодонов и повышение частоты использования кодонов, которые облегчают сплайсинг мРНК [11]. Это показывает, что в ходе эволюции потребность в точном сплайсинге была выше, чем потребность в более эффективной трансляции. Также при исследовании дуонов и других ТФ-связывающих участков ДНК оказалось, что среди этих последовательностей нет стоп-кодонов.
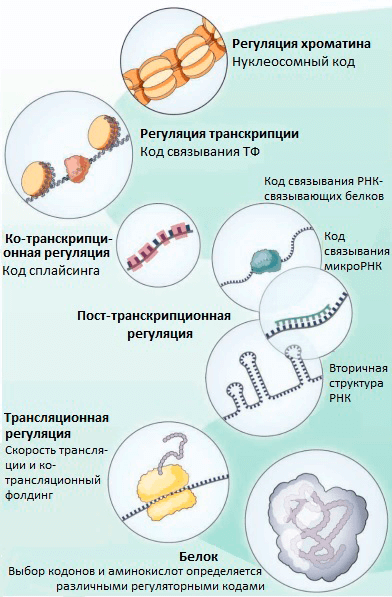
Рисунок 2. «Тайные коды» нашего генома, которые определяют частоту использования кодонов и выбор аминокислот в эволюции белков, независимо от выполнения белком его функций
Что же может обеспечить взаимовыгодное соседство «регуляторных» и генетического кодов? Одним из ключевых ограничений для белок-кодирующих генов является то, что последовательность гена должна обеспечивать нормальный фолдинг кодируемого белка. Мутации, нарушающие правильную укладку, с большой вероятностью будут отсеяны как вредные. Можно предположить, что когда необходимость правильного фолдинга отсутствует (например, в неструктурированных белках [12]), белок-кодирующая последовательность может содержать большее количество регуляторных элементов для различных «регуляторных кодов». Действительно ли это так, помогут узнать дальнейшие исследования.
Несмотря на то, что в работе Стаматояннопоулоса и его коллег было сделано много интересных наблюдений о функционировании «кода связывания ТФ», некоторые вопросы остаются открытыми. Например, авторы статьи отмечают, что ТФ гораздо реже связываются с генами с высокой экспрессией, но не ясно, как ТФ при связывании с белок-кодирующими участками ДНК могут воздействовать на транскрипцию этих генов. Возможно, что связывание ТФ в данном случае вызывает активацию альтернативного промотора или соседнего гена, снижая таким образом экспрессию гена с ТФ-связывающей последовательностью. С другой стороны, этот эффект может быть связан с перестройкой хроматина, которая приводит к снижению экспрессии ряда генов.
Новые исследования помогут ученым лучше понять, как различные «регуляторные коды» взаимодействуют друг с другом и с генетическим кодом. Интересно узнать, всегда ли природа могла найти оптимальное решение при сочетании разных кодов, или иногда возникали противоречия, приводящие к неоптимальным или вредным последствиям. Например, может оказаться, что белок-кодирующие последовательности ДНК, которым «трудно справиться» с обилием и разнообразием регуляторных элементов, активно используются патогенами при инфицировании хозяина. Обнаружение перекрывающихся «регуляторных кодов» в нашем геноме открывает новые перспективы для интерпретации различий и особенностей в последовательностях ДНК и указывает на то, что исследование генетического кода еще не подошло к концу.
Перевод редакционной колонки журнала Science [13].
Код генетический
В ДНК используется четыре нуклеотида — аденин (А), гуанин (G), цитозин (С), тимин (T), которые в русскоязычной литературе обозначаются буквами А, Г, Ц и Т. Эти буквы составляют алфавит генетического кода. В РНК используются те же нуклеотиды, за исключением тимина, который заменён похожим нуклеотидом — урацилом, который обозначается буквой U (У в русскоязычной литературе). В молекулах ДНК и РНК нуклеотиды выстраиваются в цепочки и, таким образом, получаются последовательности генетических букв.

Для построения белков в природе используется 20 различных аминокислот. Каждый белок представляет собой цепочку или несколько цепочек аминокислот в строго определённой последовательности. Эта последовательность определяет строение белка, а следовательно все его биологические свойства. Набор аминокислот также универсален для почти всех живых организмов.
Реализация генетической информации в живых клетках (то есть синтез белка, кодируемого геном) осуществляется при помощи двух матричных процессов: транскрипции (то есть синтеза иРНК на матрице ДНК) и трансляции генетического кода в аминокислотную последовательность (синтез полипептидной цепи на матрице иРНК). Для кодирования 20 аминокислот, а также сигнала «стоп», означающего конец белковой последовательности, достаточно трёх последовательных нуклеотидов. Набор из трёх нуклеотидов называется триплетом. Принятые сокращения, соответствующие аминокислотам и кодонам, изображены на рисунке.
Содержание
Свойства генетического кода
Таблицы соответствия кодонов и аминокислот
| 2-е основание | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U | C | A | G | ||||||||||||||||||||||||||||||||||||||||||
| 1-е основание | U | ||||||||||||||||||||||||||||||||||||||||||||
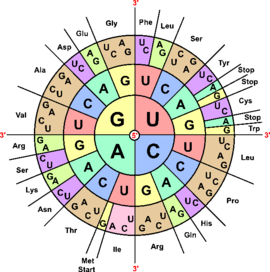
| Ala/A | GCU, GCC, GCA, GCG | Leu/L | UUA, UUG, CUU, CUC, CUA, CUG |
|---|---|---|---|
| Arg/R | CGU, CGC, CGA, CGG, AGA, AGG | Lys/K | AAA, AAG |
| Asn/N | AAU, AAC | Met/M | AUG |
| Asp/D | GAU, GAC | Phe/F | UUU, UUC |
| Cys/C | UGU, UGC | Pro/P | CCU, CCC, CCA, CCG |
| Gln/Q | CAA, CAG | Ser/S | UCU, UCC, UCA, UCG, AGU, AGC |
| Glu/E | GAA, GAG | Thr/T | ACU, ACC, ACA, ACG |
| Gly/G | GGU, GGC, GGA, GGG | Trp/W | UGG |
| His/H | CAU, CAC | Tyr/Y | UAU, UAC |
| Ile/I | AUU, AUC, AUA | Val/V | GUU, GUC, GUA, GUG |
| START | AUG | STOP | UAG, UGA, UAA |
Вариации стандартного генетического кода
В некоторых белках нестандартные аминокислоты, такие как селеноцистеин и пирролизин вставляются рибосомой, прочитывающей стоп-кодон, что зависит от последовательностей в иРНК. Селеноцистеин сейчас рассматривается в качестве 21-й, а пирролизин 22-й аминокислот, входящих в состав белков.
Несмотря на эти исключения, у всех живых организмов генетический код имеет общие черты: кодон состоят из трёх нуклеотидов, где два первых являются определяющими, кодоны транслируются тРНК и рибосомами в последовательность аминокислот.



