Кодирование информации
В информатике большое число информационных процессов проходит с использованием кодирования данных. Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.

Это означает, что при кодировании текста каждому символу присваивается определенное значение в виде нулей и единиц – байта.
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.

ASCII
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.

Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.

На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.

Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.

Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Стандарты кодирования видео
Как вы знаете, видеоряд состоит из быстро меняющихся фрагментов. Смена кадров происходит со скоростью в интервале 24-60 кадров в секунду.
Размер видеоряда в байтах определяется размером кадра (количеством пикселей на экран по высоте и ширине), количеством используемых цветов, а также количеством кадров в секунду. Но наряду с этим может присутствовать ещё и звуковая дорожка.
Что такое кодирование и шифрование информации: отличия и особенности

Часто в процессе программирования мы слышим разные слова и определения, которые вроде означают одно и т о ж е, но на самом деле имеют различное значение. Сегодня разберем две такие пары:
Часто значение этих двух слов путают, а на самом деле они означают разные рабочие направления.
Это будет означать одно и то же по смыслу, потому что кодер в качестве своего основного инструмента использует какой-нибудь язык программирования.
Кодирование и шифрование информации
Что такое хеширование
Главная цель хеширования — это преобразовать входящие данные в определенной и уникальной последовательности символов таким образом, чтобы не было возможности заполучить эти самые входящие данные в их исходном виде.
Для расчета таких хеш-сумм применяются специализированные скрипты. Примером применения хеша является:
Что такое шифрование информации
Шифрование очень схоже по смыслу с кодированием, они могут и часто используются как синонимы, однако значения этих терминов преследуют немного разнонаправленные цели.
Шифрование бывает разным, но цель любого шифрования — это сделать нечитабельной какую-то информацию. Часто для расшифровки (расшифровка — это обратный процесс шифрования) нужно обладать ключом или ключами шифрования информации. При использовании 2-х ключей первый ключ — всегда открытый и применяется для шифровки информации, а второй ключ — всегда закрытый и используется для расшифровки информации.
Задач а любого шифрования — полностью предотвратить злоумышленный доступ к данным всем, кто не обладает соответствующим ключом для расшифровки этих самых данных.
Что такое кодирование информации
Главная цель кодирования — это преобразовать входящую информацию в такую последовательность символов, чтобы потом было удобно обрабатывать или считывать такую информацию другими пользователями, устройствами или программами.
Типичными примерами кодирования являются:
Подытожим
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Кодирование и шифрование — в чём разница?
Одно делается для удобства, а другое — для защиты.
👉 Эта статья — для расширения кругозора. Если нужна практика, заходите в раздел «Это баг», там вагон практики.
«Данные закодированы» и «данные зашифрованы» — это не одно и то же. После этой статьи вы тоже сможете различать эти два подхода к данным.
Кодирование
Кодирование — это представление данных в каком-то виде, с которым удобно работать человеку или компьютеру.
Кодирование нужно для того, чтобы все, кто хочет, могли получать, передавать и работать с данными так, как им хочется. Благодаря кодированию мы можем обмениваться данными между собой — мы просто кодируем их в понятном для всех виде.
Например, древний человек видит волка, это для него данные. Ему нужно передать данные своему племени. Он произносит какой-то звук, который у других его соплеменников вызывает ассоциации с понятием «волк» или «опасность». Все мобилизуются. В нашем случае звук — это был способ кодирования.
 Слово «волк» и сопутствующий ему звук — это вид кодирования. Сам волк может не использовать такую кодировку
Слово «волк» и сопутствующий ему звук — это вид кодирования. Сам волк может не использовать такую кодировку
Для следующего примера возьмём букву «а». Её можно произнести как звук — это значит, что мы закодировали эту букву в виде звуковой волны. Также эту букву можно написать прописью или в печатном виде. Всё это примеры кодирования буквы «а», удобные для человека.
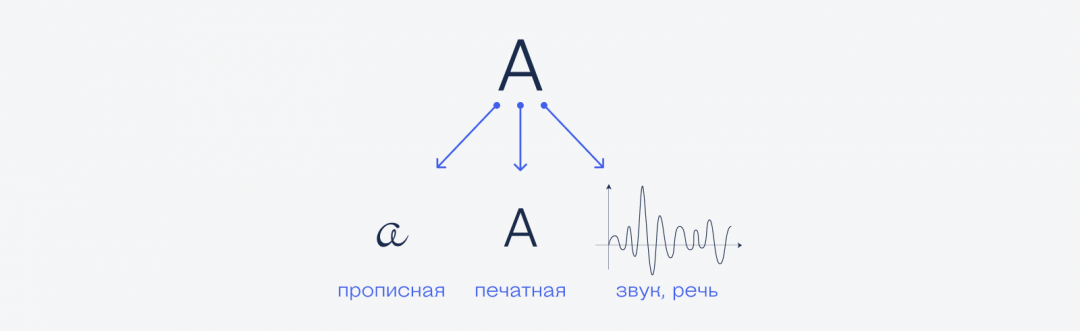
В компьютере буква «а» кодируется по-разному, в зависимости от выбранной кодировки внутри операционной системы:
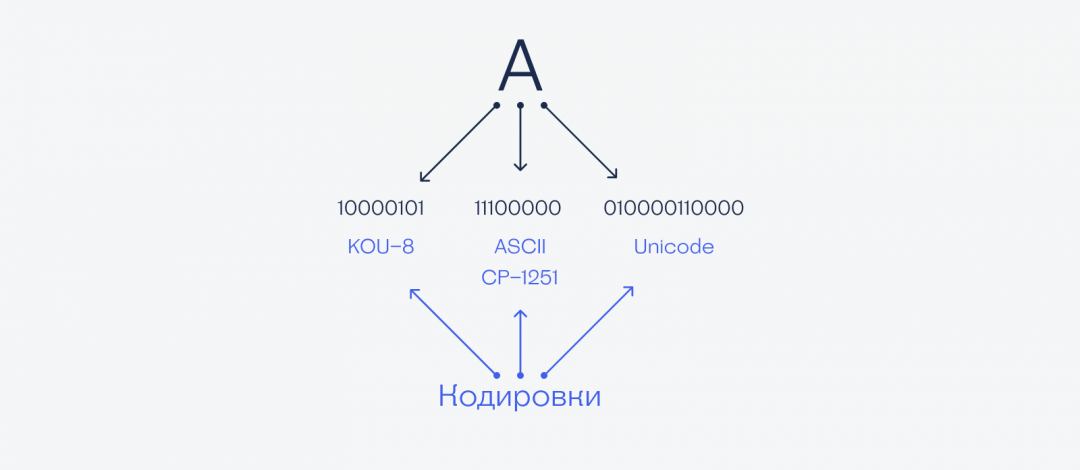
Кодирование — это то, как удобнее воспринимать информацию тем, кто ей пользуется. Например, моряки кодируют букву «а» последовательностью из короткого и длинного сигнала или точкой и тире. На языке жестов, которым пользуются глухонемые, она обозначается сложенными почти в кулак пальцами.
Сломанная кодировка
Когда встречаем незнакомую кодировку, то можно подумать, что перед нами зашифрованные данные. Например, если посмотреть на двух людей, которые общаются языком жестом, можно подумать, что они зашифровали своё общение. На самом деле вы просто не были готовы воспринимать информацию в этой кодировке.
Похожая ситуация в компьютере. Допустим, вы увидели такой текст:
рТЙЧЕФ, ЬФП ЦХТОБМ лПД!
Здесь написано «Привет, это журнал Код!», только в кодировке КОИ-8, которую интерпретировали через кодировку CP-1251. Компьютер не знал, какая здесь должна быть кодировка, поэтому взял стандартную для него CP-1251, посмотрел символы по таблице и выдал то, что получилось. Если бы компьютер знал, что для этой кодировки нужна другая таблица, мы бы всё прочитали правильно с первого раза.
Ещё кодирование
Кодированием пользуется весь мир на протяжении всей своей истории:
👉 Кодирование нужно для того, чтобы сделать данные максимально понятным для получателя и для всех, кто тоже использует такие же обозначения.
Шифрование
Если кодирование нужно, чтобы сделать информацию понятной для всех, то шифрование работает наоборот — прячет данные от всех, у кого нет ключа расшифровки.
Задача шифрования — превратить данные, которые могут прочитать все, в данные, которые может прочитать только тот, у кого есть специальное знание (ключ безопасности, сертификат, пароль или расшифровочная матрица). Если пароля нет, то данные внешне представляют из себя полную бессмыслицу, например:
Здесь зашифрована та же самая фраза — «Привет, это журнал Код!». Но не зная ключа для расшифровки и принципа шифрования, вы не сможете её прочитать.
Шифрование нужно, например, чтобы передать данные от одного к другому так, чтобы по пути их никто не прочитал. Шифрование используют:
Шифрование бывает аналоговое и компьютерное, простое и сложное, взламываемое и нет. Обо всём этом ещё расскажем, подписывайтесь.
Что такое кодировки?
Компьютеры постоянно работают с текстами: это ленты новостных сайтов, фондовые биржи, сообщения в социальных сетях и мессенджерах, банковские приложения и многое другое. Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок. Кодировки прошли большой путь от таблиц символов, созданных отдельно для каждого компьютера, до единой кодировки, принятой во всём мире.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
Компьютеры и числа
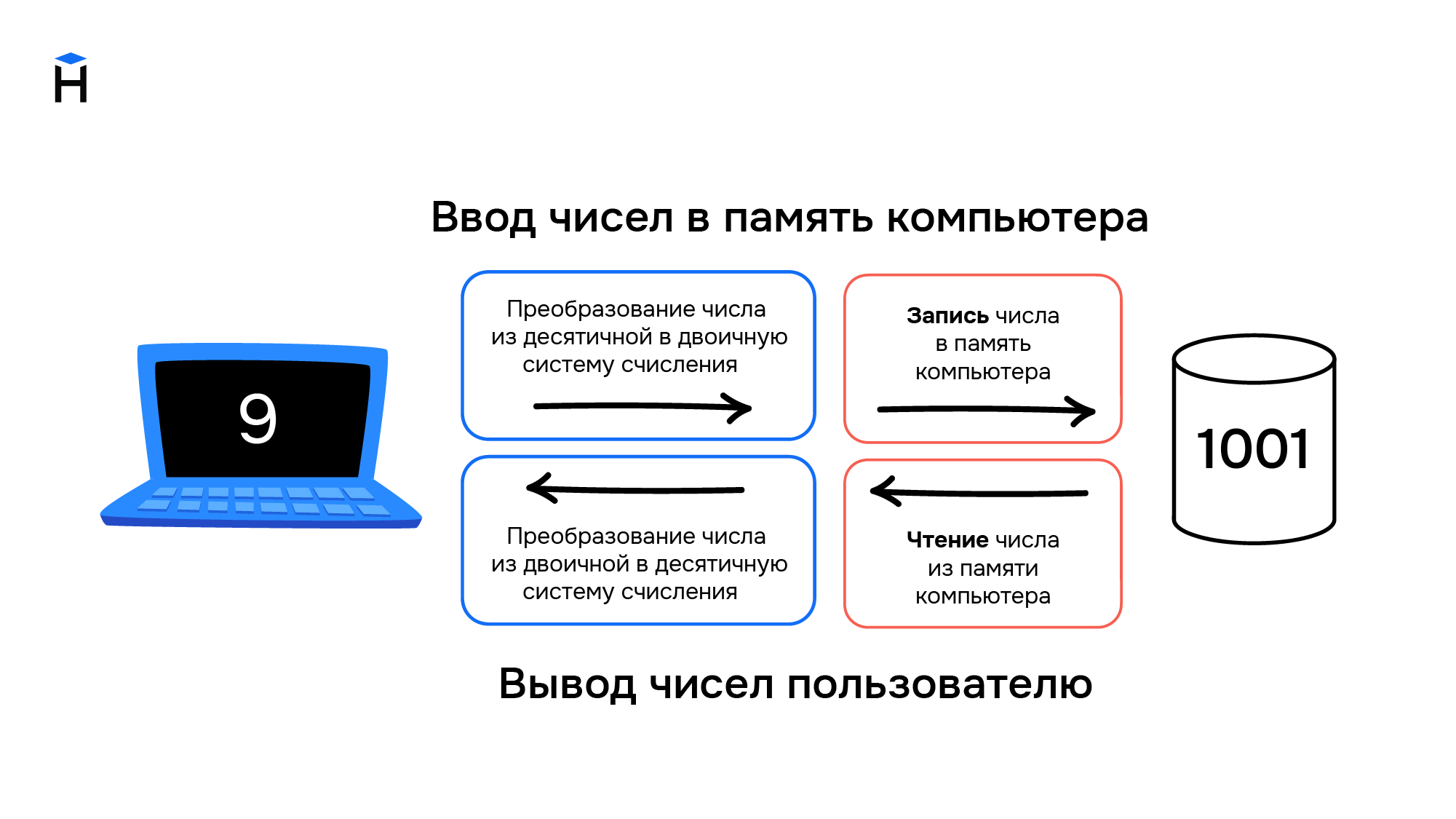
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
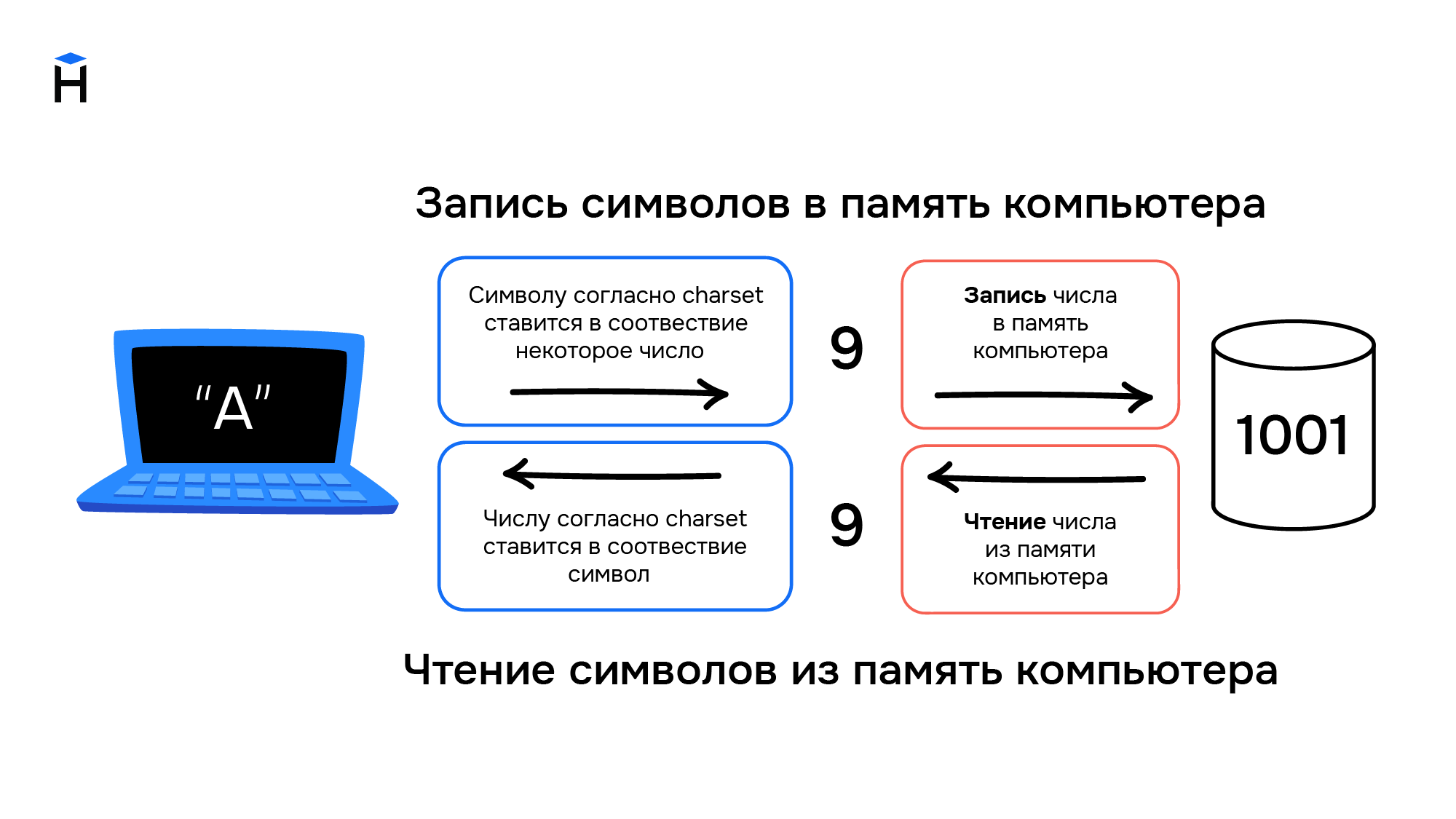
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
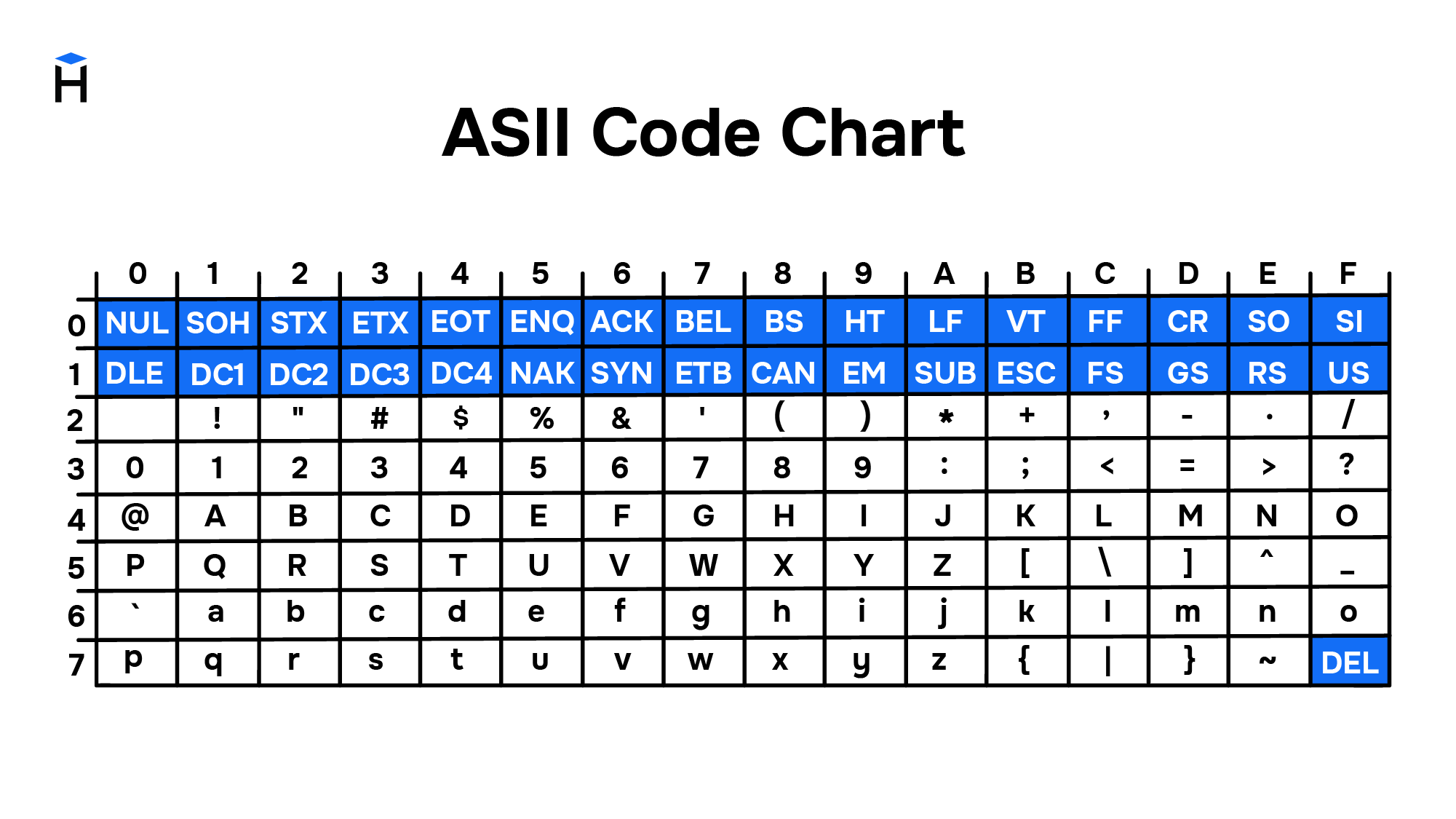
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
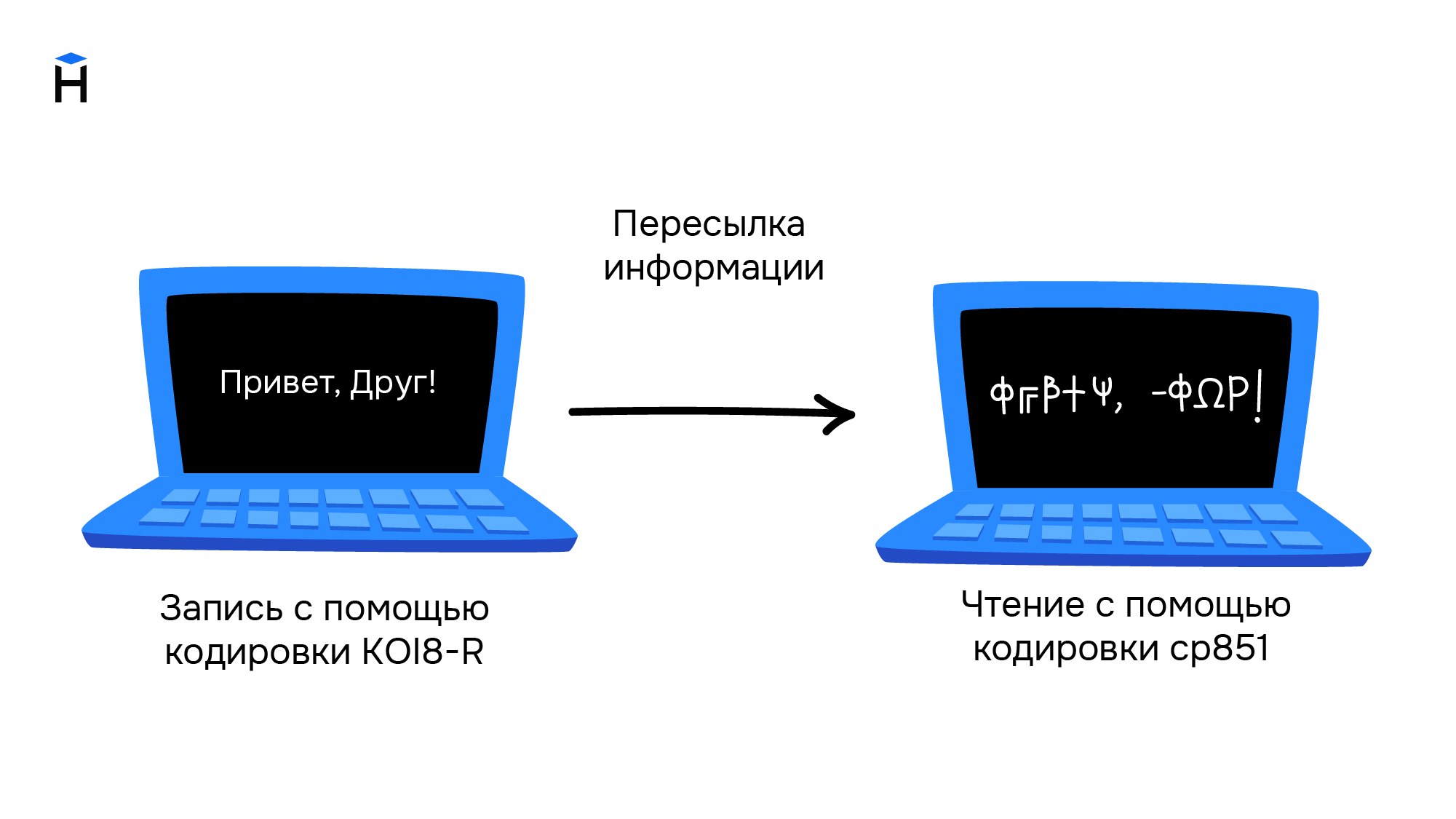
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Информатика
Именная карта банка для детей
с крутым дизайном, +200 бонусов
Закажи свою собственную карту банка и получи бонусы
План урока:
Примеры кодирования информации:
Другими словами, переход сообщения из одной формы ее в другую, согласно определенным правилам, и выражает в чем суть кодирования информации.
Информация проходит кодирование в целях:
История кодирования информации насчитывает сотни веков. Издавна люди использовали криптограммы (зашифрованные сообщения).
В 19 веке с изобретением телеграфа С. Морзе был придуман и принципиально новый способ шифрования. Телеграфное сообщение передавалось по проводам последовательностью коротких и долгих сигналов (точка и тире).
Вслед за ним Ж. Бодо создал основополагающий в истории современной информатики метод бинарного кодирования информации, который заключается в применении всего двух различающихся электрических сигналов. Кодирование информации в компьютере также подразумевает использование двух чисел.
Разработанная в 1948г. К. Шенноном «Теория информации и кодирования» стала основополагающей в современном кодировании данных.
Кодирование информации в информатике, одна из базовых тем. Понимание для чего нужна процедура кодирования передаваемой информации, каким образом она осуществляется, поможет в изучении принципов работы компьютера.
Способы кодировки
Проанализируем разнообразные виды информации и особенности ее кодирования.
По принципу представления все информационные сведения можно классифицировать на следующие группы:
Способы кодирования информации обусловлены поставленными целями, а также имеющимися возможностями,методами ее дальнейшей обработки и сохранения. Одинаковые сообщения могут отображаться в виде картинок и условных знаков (графический способ), чисел (числовой способ) или символов (символьный способ).
Соответственно происходит и классификация информации по способу кодирования:
Чтобы расшифровать сообщение, отображаемое в выбранной системе кодирования информации, необходимо осуществить декодирование – процесс восстановления до исходного материала. Для успешного осуществления расшифровки необходимо знать вид кода и методы шифрования.
Самыми распространенными видами кодировок информации являются следующие:
Различают такие методы кодирования информации как:
Двоичный код
Самый широко используемый метод кодирования информации – двоичное кодирование. Кодирование данных двоичным кодом применяется во всех современных технологиях.
Двоичное кодирование информации применяется для различных данных:
Обработка графических изображений
Кодирование текстовой, звуковой и графической информации осуществляется в целях ее качественного обмена, редактирования и хранения. Кодировка информационных сообщений различного типа обладает своими отличительными чертами, но, в целом, она сводится к преобразованию их в двоичном виде.
Рисунки, иллюстрации в книгах, схемы, чертежи и т.п. – примеры графических сообщений. Современные люди для работы с графическими данными все чаще применяют компьютерные технологии.
Суть кодирования графической и звуковой информации заключается в преобразовании ее из аналогового вида в цифровой.
Кодирование графической информации – это процедура присвоения каждому компоненту изображения определенного кодового значения.
Способы кодирования графической информации подчиняются методам представления изображений (растрового или векторного):

Источник
Многим станет интересно: «В чем суть кодирования графической информации, представленной в виде 3D-изображений?» Дело в том, что работа с трехмерными данными сочетает способы растровой и векторной кодировки.
Кодирование и обработка графической информации различного формата имеет как свои преимущества, так и недостатки.
Метод координат
Любые данные можно передать с помощью двоичных чисел, в том числе и графические изображение, представляющие собой совокупность точек. Чтобы установить соответствие чисел и точек в бинарном коде, используют метод координат.
Метод координат на плоскости основан на изучении свойств точки в системе координат с горизонтальной осью Ox и вертикальной осью Oy. Точка будет иметь 2 координаты.
Если через начало координат проходит 3 взаимно перпендикулярные оси X, Y и Z, то используется метод координат в пространстве. Положение точки в таком случае определяется тремя координатами.
Система координат в пространстве
Перевод чисел в бинарный код
Числовой способ кодирования информации, т.е. переход информационных данных в бинарную последовательность чисел широко распространен в современной компьютерной технике. Любая числовую, символьную, графическую, аудио- и видеоинформацию можно закодировать двоичными числами. Рассмотрим подробнее кодирование числовой информации.
Привычная человеку система счисления (основанная на цифрах от 0 до 9), которой мы активно пользуемся, появилась несколько сотен тысяч лет назад. Работа всей вычислительной техники организована на бинарной системе счисления. Алфавитом у нее минимальный – 0 и 1. Кодировка чисел совершается путем перехода из десятичной в двоичную систему счисления и выполнении вычислений непосредственно с бинарными числами.
Кодирование и обработка числовой информации обусловлено желаемым результатом работы с цифрами. Так, если число вводится в рамках текстового файла, то оно будет иметь код символа, взятого из используемого стандарта. Для математических вычислений числовые данные преобразуются совершенно другим способом.
Принципы кодирования числовой информации, представленной в виде целых или дробных чисел (положительных, отрицательных или равных 0) отличаются по своей сути. Самый простой способ перевести целое число из десятичной в двоичную систему счисления заключается в следующем:
Одна из важнейших частей компьютерной работы – кодирование символьной информации. Все многообразие цифр, русских и латинских букв, знаков препинания, математических знаков и отдельных специальных обозначений относятся к символам. Cимвольный способ кодирования состоит в присвоении определенному знаку установленного шифра.
Рассмотрим подробнее самые распространенные стандарты ASCII и Unicode – то, что применяется для кодирования символьной информации во всем мире.
Фрагмент таблицы ASCII
Первоначально было установлено, что для любого знака отводится в памяти компьютера 8 бит (1 бит – это либо «0», либо «1») бинарной последовательности. Первая таблица кодировки ASCII (переводится как «американский кодовый стандарт обмена сообщениями») содержала 256 символов. Ограниченная численность закодированных знаков, затрудняющая межнациональный обмен данными, привела к необходимости создания стандарта Unicode, основанного на ASCII. Эта международная система кодировки содержит 65536 символов. Закодировать огромное количество всевозможных обозначений стало возможным благодаря использованию 16-битного символьного кодирования.
Кодирование символьной и числовой информации принципиально отличается. Для ввода-вывода цифр на монитор или использовании их в текстовом файле происходит преобразование их согласно системе кодировки. В процессе арифметических действий число имеет совершенно другое бинарное значение, потому что оно переходит в двоичную систему счисления, где и совершаются все вычислительные действия.
Выбирать способ кодирования информации – графический, числовой или символьный необходимо отталкиваясь от цели кодировки. Например, число «21» можно ввести в компьютерную память цифрами или буквами «двадцать один», слово «ЗИМА» можно передать русскими буквами «зима» или латинскими «ZIMA», штрих-код товара передается изображением и цифрами.
Преобразование звука
Компьютерные технологии успешно внедряются в различные сферы деятельности, включая кодирование и обработку звуковой информации. С физической точки зрения, звук – это аналоговый сплошной сигнал. Процесс его перевода в ряд электрических импульсов называется кодированием звуковой информации.
Задачи, которые необходимо решить для успешной оцифровки сигнала:
Преобразование звука: а) аналоговый сигнал; б)дискретный сигнал.
Различают следующие методы кодирования звуковой информации:
Обработка текста
Текст – осмысленный порядок знаков. С использованием компьютера кодирование и обработка текстовой информации (набор, редактирование, обмен и сохранение письменного текста) значительно упростилось.
Кодирование текстовой информации – присвоение любому символу текста кода из кодировочной системы. Различают следующие стандарты кодировки:
В задачах на кодирование текстовой информации часто встречаются следующие понятия:
Например, мощность алфавита ASCII составляет 256 символов. При этом один знак занимает 8 бит (или 1 байт) памяти, а Unicode – 35536 символов и 16 бит (или 2 байта) соответственно.



