Что такое компиляция в программировании?
Компилируется ли язык программирования или интерпретируется, на самом деле это не зависит от природы языка программирования. Любой язык программирования может интерпретироваться так называемым интерпретатором или компилироваться с помощью так называемого компилятора.
Рабочий цикл программы
При использовании любого языка программирования существует определенный рабочий цикл создания кода. Вы пишете его, запускаете, находите ошибки и отлаживаете. Таким образом, вы переписываете и дописываете программу, проверяете ее. То, о чем пойдет речь в этой статье, это « запускаемая » часть программы.
Когда пишете программу, вы хотите, чтобы ее инструкции работали на компьютере. Компьютер обрабатывает информацию с помощью процессора, который поэтапно выполняет инструкции, закодированные в двоичном формате. Как из выражения « a = 3; » получить закодированные инструкции, которые процессор может понять?
Мы делаем это с помощью компиляции. Существует специальные приложения, известные как компиляторы. Они принимают программу, которую вы написали. Затем анализируют и разбирают каждую часть программы и строят машинный код для процессора. Часто его также называют объектным кодом.
На одном из этапов процесса обработки задействуется компоновщик, принимающий части программы, которые отдельно были преобразованы в объектный код, и связывает их в один исполняемый файл. Вот схема, описывающая данный процесс:

Конечным элементом этого процесса является исполняемый файл. Когда вы запускаете или сообщаете компьютеру, что это исполняемый файл, он берет первую же инструкцию из него, не фильтрует, не преобразует, а сразу запускает программу и выполняет ее без какого-либо дополнительного преобразования. Это ключевая характеристика процесса компиляции — его результат должен быть исполняемым файлом, не требующим дополнительного перевода, чтобы процессор мог начать выполнять первую инструкцию и все следующие за ней.
Первые компиляторы были написаны непосредственно через машинный код или с использованием ассемблеров. Но цель компилятора очевидна: перевести программу в исполняемый машинный код для конкретного процессора.
Не все языки программирования учитывают это в своей концепции. Например, Java предназначался для запуска в « интерпретирующей » среде, а Python всегда должен интерпретироваться.
Интерпретация программы
Альтернативой компиляции является интерпретация. Чем отличаются компиляторы и интерпретаторы? Основная разница между компилятором и интерпретатором заключается в том, как они работают. Компилятор берет всю программу и преобразует ее в машинный код, который понимает процессор.
Интерпретатор — это исполняемый файл, который поэтапно читает программу, а затем обрабатывает, сразу выполняя ее инструкции.
Другими словами, программа-интерпретатор выполняет программу поэтапно как часть собственного исполняемого файла. Объектный код не передается процессору, интерпретатор сам является объектным кодом, построенным таким образом, чтобы его можно было вызвать в определенное время.
Это ломает рабочий цикл, который был приведен на диаграмме выше. Теперь у нас есть новая диаграмма:

На ней мы видим, что в отличии от компилятора, интерпретатор всегда должен быть под рукой, чтобы мы могли вызвать его и запустить нашу программу. В некотором смысле интерпретатор становится процессором. Программы, написанные для интерпретации, называются « скриптами », потому что они являются сценариями действий для другой программы, а не прямым машинным кодом.
Природа интерпретатора
Интерпретаторы могут создаваться по-разному. Существуют интерпретаторы, которые читают исходную программу и не выполняют дополнительной обработки. Они просто берут определенное количество строк кода за раз и выполняют его.
Некоторые интерпретаторы выполняют собственную компиляцию, но обычно преобразуют программу байтовый код, который имеет смысл только для интерпретатора. Это своего рода псевдо машинный язык, который понимает только интерпретатор.
Такой код быстрее обрабатывается, и его проще написать для исполнителя ( части интерпретатора, которая исполняет ), который считывает байтовый код, а не код источника.
Есть интерпретаторы, для которых этот вид байтового кода имеет более важное значение. Например, язык программирования Java « запускается » на так называемой виртуальной машине. Она является исполняемым кодом или частью программы, которая считывает конкретный байтовый код и эмулирует работу процессора. Обрабатывая байтовый код так, как если бы процессор компьютера был виртуальным процессором.
За и против
Основным аргументом за использование процесса компиляции является скорость. Возможность компилировать любой программный код в машинный, который может понять процессор ПК, исключает использование промежуточного кода. Можно запускать программы без дополнительных шагов, тем самым увеличивая скорость обработки кода.
Но наибольшим недостатком компиляции является специфичность. Когда компилируете программу для работы на конкретном процессоре, вы создаете объектный код, который будет работать только на этом процессоре. Если хотите, чтобы программа запускалась на другой машине, вам придется перекомпилировать программу под этот процессор. А перекомпиляция может быть довольно сложной, если процессор имеет ограничения или особенности, не присущие первому. А также может вызывать ошибки компиляции.
Основное преимущество интерпретации — гибкость. Можно не только запускать интерпретируемую программу на любом процессоре или платформе, для которых интерпретатор был скомпилирован. Написанный интерпретатор может предложить дополнительную гибкость. В определенном смысле интерпретаторы проще понять и написать, чем компиляторы.
С помощью интерпретатора проще добавить дополнительные функции, реализовать такие элементы, как сборщики мусора, а не расширять язык.
Другим преимуществом интерпретаторов является то, что их проще переписать или перекомпилировать для новых платформ.
Написание компилятора для процессора требует добавления множества функций, или полной переработки. Но как только компилятор написан, можно скомпилировать кучу интерпретаторов и на выходе мы имеем перспективный язык. Не нужно повторно внедрять интерпретатор на базовом уровне для другого процессора.
Самым большим недостатком интерпретаторов является скорость. Для каждой программы выполняется так много переводов, фильтраций, что это приводит к замедлению работы и мешает выполнению программного кода.
Это проблема для конкретных real-time приложений, таких как игры с высоким разрешением и симуляцией. Некоторые интерпретаторы содержат компоненты, которые называются just-in-time компиляторами ( JIT ). Они компилируют программу непосредственно перед ее исполнением. Это специальные программы, вынесенные за рамки интерпретатора. Но поскольку процессоры становятся все более мощными, данная проблема становится менее актуальной.
Заключение
Для меня не имеет значения, скомпилировано что-то или интерпретировано, если оно может выполнить задачу эффективно.
Сообщите мне, что бы вы предпочли: интерпретацию или компиляцию? Спасибо за уделенное время!
Пожалуйста, оставьте ваши комментарии по текущей теме статьи. Мы крайне благодарны вам за ваши комментарии, дизлайки, подписки, отклики, лайки!
Основные принципы программирования: компилируемые и интерпретируемые языки
Основные принципы программирования: компилируемые и интерпретируемые языки
Как и в предыдущей статье этого цикла, я хочу обратить ваше внимание на ключевые принципы программирования, которые влияют на всё то, что мы делаем, но с которыми мы редко сталкиваемся напрямую и поэтому не до конца их понимаем. Тема сегодняшней статьи — компилируемые и интерпретируемые языки.
Будучи разработчиками, мы часто сталкиваемся с такими понятиями, как компилятор и интерпретатор, но я считаю, что многие не совсем понимают, что они означают. Между тем, компиляция и интерпретация — это основы работы всех языков программирования. Давайте взглянем на то, как на самом деле устроены эти понятия.
Вступление
Мы полагаемся на такие инструменты, как компиляция и интерпретация, чтобы преобразовать наш код в форму, понятную компьютеру. Код может быть исполнен нативно, в операционной системе после конвертации в машинный (путём компиляции) или же исполняться построчно другой программой, которая делает это вместо ОС (интерпретатор).
Компилируемый язык — это такой язык, что программа, будучи скомпилированной, содержит инструкции целевой машины; этот машинный код непонятен людям. Интерпретируемый же язык — это такой, в котором инструкции не исполняются целевой машиной, а считываются и исполняются другой программой (которая обычно написана на языке целевой машины). Как у компиляции, так и у интерпретации есть свои плюсы и минусы, и именно это мы и обсудим.
Прежде чем мы продолжим, стоит отметить, что многие языки программирования имеют как компилируемую, так и интерпретируемую версии, поэтому классифицировать их затруднительно. Тем не менее, чтобы не усложнять, в дальнейшем я буду разделять компилируемые и интерпретируемые языки.
Компилируемые языки
Главное преимущество компилируемых языков — это скорость исполнения. Поскольку они конвертируются в машинный код, они работают гораздо быстрее и эффективнее, нежели интерпретируемые, особенно если учесть сложность утверждений некоторых современных скриптовых интерпретируемых языков.
Низкоуровневые языки как правило являются компилируемыми, поскольку эффективность обычно ставится выше кроссплатформенности. Кроме того, компилируемые языки дают разработчику гораздо больше возможностей в плане контроля аппаратного обеспечения, например, управления памятью и использованием процессора. Примерами компилируемых языков являются C, C++, Erlang, Haskell и более современные языки, такие как Rust и Go.
Проблемы компилируемых языков, в общем-то, очевидны. Для запуска программы, написаной на компилируемом языке, её сперва нужно скомпилировать. Это не только лишний шаг, но и значительное усложнение отладки, ведь для тестирования любого изменения программу нужно компилировать заново. Кроме того, компилируемые языки являются платформо-зависимыми, поскольку машинный код зависит от машины, на которой компилируется и исполняется программа.
Интерпретируемые языки
В отличие от компилируемых языков, интерпретируемым для исполнения программы не нужен машинный код; вместо этого программу построчно исполнят интерпретаторы. Раньше процесс интерпретации занимал очень много времени, но с приходом таких технологий, как JIT-компиляция, разрыв между компилируемыми и интерпретируемыми языками сокращается. Примерами интерпретируемых языков являются PHP, Perl, Ruby и Python. Вот некоторые из концептов, которые стали проще благодаря интерпретируемым языкам:
Основным недостатком интерпретируемых языком является их невысокая скорость исполнения. Тем не менее, JIT-компиляция позволяет ускорить процесс благодаря переводу часто используемых последовательностей инструкции в машинный код.
Бонус: байткод-языки
В байткод-языке сперва происходит компиляция программы из человекочитаемого языка в байткод. Байткод — это набор инструкций, созданный для эффективного исполнения интерпретатором и состоящий из компактных числовых кодов, констант и ссылок на память. С этого момента байткод передаётся в виртуальную машину, которая затем интерпретирует код также, как и обычный интерпретатор.
При компиляции кода в байткод происходит задержка, но дальнейшая скорость исполнения значительно возрастает в силу оптимизации байткода. Кроме того, байткод-языки являются платформо-независимыми, превосходя при этом по скорости интерпретируемые. Для них также доступна JIT-компиляция.
Заключение
Многие языки в наши дни имеют как компилируемые, так и интерпретируемые реализации, сводя разницу между ними на нет. У каждого вида исполнения кода есть преимущества и недостатки.
Вкратце, компилируемые языки являются самыми эффективными, поскольку они исполняются как машинный код и позволяют использовать аппаратное обеспечение системы. Однако это вводит дополнительные ограничение на написание кода и делает его платформо-зависимым. Интерпретируемые же языки не зависят от платформы и позволяют использовать такие техники динамического программирования, как метапрограммирование. Тем не менее, в скорости исполнения они значительно уступают компилируемым языкам.
Байткод-языки, в свою очередь, пытаются использовать сильные стороны обоих видов языков, и у них это неплохо получается.
Хинт для программистов: если зарегистрируетесь на соревнования Huawei Cup, то бесплатно получите доступ к онлайн-школе для участников. Можно прокачаться по разным навыкам и выиграть призы в самом соревновании.
Перейти к регистрации
Процесс компиляции программ на C++
Цель данной статьи:
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
Состав компилятора g++
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
driver.cpp:
1) Препроцессинг
Самая первая стадия компиляции программы.
Препроцессор — это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит происходит работа с препроцессорными директивами. Например, препроцессор добавляет хэдеры в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
Хэдеры, включенные в программу с помощью директивы #include, рекурсивно проходят стадию препроцессинга и включаются в выпускаемый файл. Однако, каждый хэдер может быть открыт во время препроцессинга несколько раз, поэтому, обычно, используются специальные препроцессорные директивы, предохраняющие от циклической зависимости.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
Взглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
Мы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
Но на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Введение в компиляторы, интерпретаторы и JIT’ы
Но прежде чем говорить о том, как это всё работает, давайте разберём один простой пример. Представим, что у нас есть новый язык программирования (придумайте любое название). Язык довольно прост:
set a 1
set b 2
add a b c
print c
Теперь давайте напишем программу, которая считывает каждое «выражение», находит оператор и операнды, а затем что-то с ними делает, в зависимости от конкретного оператора. Это довольно просто реализовать на PHP, как вы можете видеть на примере листинга 1.
Это очень простая программа, и вам не придётся писать своё следующее веб-приложение на вашем новом языке. Но данный пример помогает понять, как легко можно создать новый язык и получить программу, которая способна считывать и выполнять этот язык. В нашем случае она построчно считывает исходный файл и выполняет код в зависимости от текущего оператора. Для запуска приложения нам не нужно преобразовывать его в ассемблер или двоичный код, оно и так прекрасно работает. Этот метод выполнения программ называется интерпретированием. Например, таким образом часто выполняются программы на Basic: каждое выражение считывается и сразу же выполняется в высокоуровневом режиме.
Но тут есть ряд проблем. Одна из них заключается в том, что написать подобный языковой процессор довольно легко, а вот выполняться новый язык будет очень медленно. Ведь нам придётся обрабатывать каждую строку и проверять:
Но, несмотря на неторопливость, у интерпретирования есть преимущества: мы можем сразу запускать программу после каждого внесённого изменения. Для внимательных: когда я что-то меняю в PHP-скрипте, я сразу могу его выполнить и увидеть изменения; означает ли это, что PHP — интерпретируемый язык? На данный момент будем считать, что да. PHP-скрипт интерпретируется подобно нашему гипотетическому простому языку. Но в следующих разделах мы ещё к этому вернёмся!
Транскомпилирование
Как можно заставить нашу программу «работать быстро»? Это можно сделать разными способами. Один из них, разработанный в Facebook, называется HipHop (я имею в виду «старую» систему HipHop, а не используемую сегодня HHVM). HipHop преобразовывал один язык (PHP) в другой (С++). Результат преобразования можно было с помощью компилятора С++ превратить в двоичный код. Его компьютер способен понять и выполнить без дополнительной нагрузки в виде интерпретатора. В результате экономится ОГРОМНОЕ количество вычислительных ресурсов и приложение работает гораздо быстрее.
Этот метод называется source-to-source компилированием, или транскомпилированием, или даже транспилированием (transpiling). На самом деле происходит не компилирование в двоичный код, а преобразование в то, что может быть скомпилировано в машинный код существующими компиляторами.
Транскомпилирование позволяет напрямую выполнять двоичный код, что повышает производительность. Однако у этого метода есть и обратная сторона: прежде чем выполнить код, нам сначала нужно провести транскомпилирование, а затем настоящее компилирование. Но это нужно делать только тогда, когда в приложение вносятся изменения, т. е. только во время разработки.
Транскомпилирование также используется для того, чтобы сделать «жёсткие» языки более простыми и динамичными. Например, браузеры не понимают код, написанный на LESS, SASS и SCSS. Но зато его можно транспилировать в CSS, который браузеры понимают. Поддерживать CSS проще, но приходится дополнительно транскомпилировать.
Компилирование
Чтобы всё работало ещё быстрее, нужно избавиться от стадии транскомпилирования. То есть компилировать наш язык сразу в двоичный код, который мог бы тут же выполняться, без дополнительной нагрузки в виде интерпретирования или транскомпилирования.
К сожалению, написание компилятора — одна из труднейших задач в информатике. Например, при компилировании в двоичный код нужно учитывать, на каком компьютере он будет выполняться: на 32-битной Linux, или 64-битной Windows, или вообще на OS X. Зато интерпретируемый скрипт может легко выполняться где угодно. Как и в PHP, нам не нужно переживать о том, где выполняется наш скрипт. Хотя может встречаться и код, предназначенный для конкретной ОС, что сделает невозможным выполнение скрипта на других системах, но это не вина интерпретатора.
Но даже если мы избавимся от стадии транскомпилирования, нам никуда не деться от компилирования. Например, большие программы, написанные на С (компилируемый язык), могут компилироваться чуть ли не час. Представьте, что вы написали приложение на PHP и вам нужно ждать ещё десять минут, прежде чем увидеть, работают ли внесённые изменения.
Используя всё лучшее
Если интерпретирование подразумевает медленное выполнение, а компилирование сложно в реализации и требует больше времени при разработке, то как работают языки вроде PHP, Python или Ruby? Они довольно быстрые!
Это потому, что они используют и интерпретирование, и компилирование. Давайте посмотрим, как это получается.
Что, если бы мы могли преобразовывать наш выдуманный язык не напрямую в двоичный код, а в нечто, очень на него похожее (это называется «байт-код»)? И если бы этот байт-код был так близок к тому, как работает компьютер, что его интерпретирование выполнялось бы очень быстро (например, миллионы байт-кодов в секунду)? Это сделало бы наше приложение почти таким же быстрым, как и компилируемое, при этом сохранились бы все преимущества интерпретируемых языков. Самое главное, нам не пришлось бы компилировать скрипты при каждом изменении.
Выглядит очень заманчиво. По сути, подобным образом работают многие языки — PHP, Ruby, Python и даже Java. Вместо считывания и поочерёдного интерпретирования строк исходного кода, в этих языках используется другой подход:
Ещё одна оптимизация: после генерирования байт-кода мы можем использовать его при всех последующих запросах. Так что можно закешировать и его (главное, убедитесь, что при изменении исходного файла байт-код будет перекомпилироваться). Именно это делают кеши кода операций (opcode caches), вроде расширения OPCache в PHP: кешируют скомпилированные скрипты, чтобы их можно было быстро выполнить при последующих запросах без избыточных загрузок и компилирования в байт-код.
Наконец, последний шаг к высокой скорости — выполнение байт-кода нашим PHP-интерпретатором. В следующей части мы сравним это с обычными интерпретаторами. Во избежание путаницы: подобный интерпретатор байт-кода часто называется «виртуальной машиной», потому что в определённой степени он копирует работу машины (компьютера). Не надо путать это с виртуальными машинами, запускаемыми на компьютерах, вроде VirtualBox или VMware. Речь идёт о таких вещах, как JVM (Java Virtual Machine) в мире Java и HHVM (HipHop Virtual Machine) в мире PHP. Свои виртуальные машины есть у Python и Ruby. В некотором роде все они являются высокоспециализированными и производительными интерпретаторами байт-кода.
Каждая ВМ выполняет собственный байт-код, генерируемый конкретным языком, и они несовместимы между собой. Вы не можете выполнять байт-код PHP на ВМ Python, и наоборот. Однако теоретически возможно создать программу, компилирующую PHP-скрипты в байт-код, который будет понятен ВМ Python. Так что в теории вы можете запускать PHP-скрипты в Python (серьёзный вызов!).
Байт-код
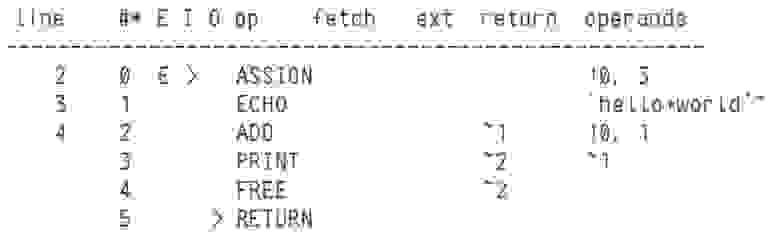
Как выглядит и работает байт-код? Рассмотрим два примера. Возьмём PHP-код:
Посмотреть его байт-код можно с помощью 3v4l.org или установив расширение VLD. Получим следующее:
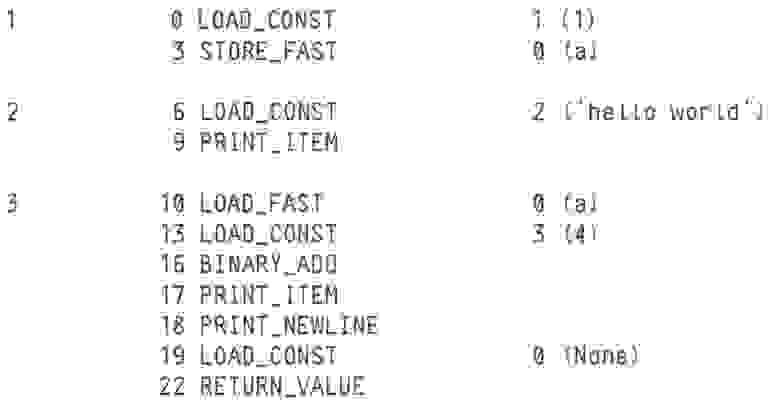
Теперь возьмём аналогичный пример на Python:
Python может напрямую сгенерировать коды операций ©python:
Поскольку байт-код состоит из простых инструкций, интерпретирование проходит очень быстро. Вместо тысяч двоичных инструкций, которые нужно обработать для каждого выражения интерпретируемого языка, в байт-коде на каждое выражение приходится по несколько сотен инструкций (иногда и того меньше). Поэтому виртуальные машины работают гораздо быстрее интерпретируемых языков.
Иными словами, виртуалки взяли всё лучшее от двух миров. Хотя нам по-прежнему нужно компилировать из исходного кода в байт-код, этот процесс становится быстрым и прозрачным. А после получения байт-кода виртуальная машина быстро и эффективно интерпретирует его без излишних накладных расходов. И в результате мы имеем высокопроизводительное приложение.
От исходного кода к байт-коду
Теперь, когда мы умеем эффективно выполнять сгенерированный байт-код, остаётся задача компилирования исходного кода в этот байт-код.
Рассмотрим следующие PHP-выражения:
Все они одинаково верны и должны быть преобразованы в одинаковые байт-коды. Но как мы их считываем? Ведь в нашем собственном интерпретаторе мы парсим команды, разделяя их пробелами. Это означает, что программист должен писать код в одном стиле, в отличие от PHP, где вы можете в одной строке использовать отступления или пробелы, скобки в одной строке или переносить на вторую строку и т. д. В первую очередь компилятор попытается преобразовать ваш исходный код в токены. Этот процесс называется лексингом (lexing) или токенизацией.
Лексинг
Токенизация (лексинг) заключается в преобразовании исходного PHP-кода — без понимания его значения — в длинный список токенов. Это сложный процесс, но в PHP вы можете довольно легко сделать нечто подобное. Представленный в листинге 2 код выдаёт следующий результат:
Строковое значение преобразуется в токены:
Парсеры и токенизаторы полезны и в других сферах. Например, они используются для парсинга SQL-выражений в базах данных, и на PHP также написано немало парсеров и токенизаторов. У объектно-реляционного маппера Doctrine есть свой парсер для DQL-выражений, а также «транскомпилятор» для преобразования DQL в SQL. Многие движки шаблонов, в том числе Twig, используют собственные токенизаторы и парсеры для «компилирования» файлов шаблонов обратно в PHP-скрипты. По сути, эти движки тоже транскомпиляторы!
Абстрактное синтаксическое дерево
После токенизации и парсинга нашего языка мы можем генерировать байт-код. Вплоть до PHP 5.6 он генерировался во время парсинга. Но привычнее было бы добавить в процесс отдельную стадию: пусть парсер генерирует не байт-код, а так называемое абстрактное синтаксическое дерево (Abstract Syntax Tree, AST). Это древовидная структура, в которой абстрактно представлена вся программа. AST не только упрощает генерирование байт-кода, но и позволяет нам вносить изменения в дерево, прежде чем оно будет преобразовано. Дерево всегда генерируется особым образом. Узел дерева, представляющий собой выражение if, обязательно имеет под собой три элемента:
В результате мы можем «переписать» программу до того, как она будет преобразована в байт-код. Иногда это используется для оптимизации кода. Если мы обнаружим, что разработчик раз за разом перевычислял переменную внутри цикла, и мы знаем, что переменная всегда имеет одно и то же значение, то оптимизатор может переписать AST так, чтобы создать временную переменную, которую не нужно каждый раз вычислять заново. Дерево можно использовать для небольшой реорганизации кода, чтобы он работал быстрее: удалить ненужные переменные и т. п. Это не всегда возможно, но когда у нас есть дерево всей программы, то такие проверки и оптимизации выполнять куда легче. Внутри AST можно посмотреть, объявляются ли переменные до их использования или используется ли присваивание в условном блоке ( if ($a = 1) <> ). И при обнаружении потенциально ошибочных структур выдать предупреждение. С помощью дерева можно даже анализировать код с точки зрения информационной безопасности и предупреждать пользователей во время выполнения скрипта.
Всё это называется статическим анализом — он позволяет создавать новые возможности, оптимизации и системы валидации, помогающие разработчикам писать гармоничный, безопасный и быстрый код.
В PHP 7.0 появился новый движок парсинга (Zend 3.0), который тоже генерирует AST во время парсинга. Поскольку он достаточно свежий, с его помощью можно сделать не так много. Но сам факт его наличия означает, что мы можем ожидать появления в ближайшем будущем самых разных возможностей. Функция token_get_all() уже принимает новую, недокументированную константу TOKEN_PARSE, которая в будущем может использоваться для возвращения не только токенов, но и отпарсенного AST. Сторонние расширения вроде php-ast позволяют просматривать и редактировать дерево прямо в PHP. Полная переработка движка Zend и реализации AST откроет PHP для самых разных новых задач.
Помимо виртуальных машин, выполняющих высокооптимизированный байт-код, сгенерированный из AST, есть и другая методика повышения скорости. Но это одна из самых сложных в реализации вещей.
Как выполняется приложение? Много времени тратится на его настройку: например, нужно запустить фреймворк, отпарсить маршруты, обработать переменные среды и т. д. По завершении всех этих процедур программа обычно всё ещё не запущена. По сути, куча времени потрачена лишь на функционирование какой-то части вашего приложения. А что, если мы выявим те части, которые могут часто запускаться и способны преобразовывать маленькие куски кода (допустим, всего несколько методов) в двоичный код? Конечно, на это компилирование может уходить относительно много времени, но всё равно метод компилируется куда быстрее, чем всё приложение. Возможно, при первом вызове функции вы столкнётесь с маленькой задержкой, но все последующие вызовы будут выполняться молниеносно, минуя виртуальную машину, и сразу в виде двоичного кода.
Мы получаем скорость компилируемого кода и наслаждаемся преимуществами кода интерпретируемого. Подобные системы могут работать быстрее обычного интерпретируемого байт-кода, иногда гораздо быстрее. Речь идёт о JIT-компиляторах (just-in-time, точно в срок). Название подходит как нельзя лучше. Система обнаруживает, какие части байт-кода могут быть хорошими кандидатами на компилирование в двоичный код, и делает это в тот момент, когда нужно выполнять эти самые части. То есть — точно в срок. Программа может стартовать немедленно, не нужно ждать завершения компилирования. В двоичный код преобразуются только самые эффективные части кода, так что процесс компилирования автоматизируется и ускоряется.
Хотя не все JIT-компиляторы работают таким образом. Некоторые компилируют все методы на лету; другие пытаются только определить, какие функции нужно скомпилировать на ранней стадии; третьи будут компилировать функции, если они вызываются два и больше раза. Но все JIT’ы используют один принцип: компилировать маленькие куски кода, когда они действительно нужны.
Ещё одно преимущество JIT’ов по сравнению с обычным компилированием заключается в том, что они способны лучше прогнозировать и оптимизировать на основании текущего состояния приложения. JIT’ы могут динамически анализировать код во время runtime и делать предположения, на которые неспособны обычные компиляторы. Ведь во время компиляции у нас нет информации о текущем состоянии программы, а JIT’ы компилируют на стадии выполнения.
Если вам доводилось работать с HHVM, то вы уже использовали JIT-компилятор: PHP-код (и надмножественный язык Hack) преобразуется в байт-код, запускаемый на виртуальной машине HHVM. Машина обнаруживает блоки, которые могут быть безопасно преобразованы в двоичный код; если это ещё не было сделано, она это делает и запускает их. По окончании запуска ВМ переходит к следующим байт-кодам, которые могут быть преобразованы в двоичный код.
PHP 7 не выполняется на JIT-компиляторе, но зато его новая система превосходит все предыдущие релизы. Сейчас во всех его компонентах проводятся эксперименты со статическим анализом, динамической оптимизацией, и даже есть простые JIT-системы. Так что не исключено, что однажды даже PHP 7 окажется позади!



