Алгоритм Хаффмана
Алгоритм Хаффмана (англ. Huffman’s algorithm) — алгоритм оптимального префиксного кодирования алфавита. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. Используется во многих программах сжатия данных, например, PKZIP 2, LZH и др.
Содержание
Определение [ править ]
Алгоритм построения бинарного кода Хаффмана [ править ]
Построение кода Хаффмана сводится к построению соответствующего бинарного дерева по следующему алгоритму:
Время работы [ править ]
Пример [ править ]
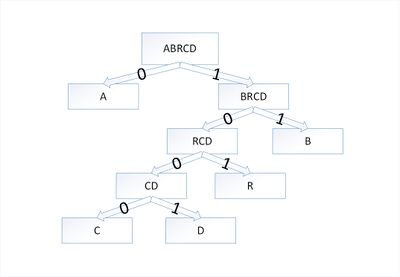
В дереве Хаффмана будет [math]5[/math] узлов:
| Узел | a | b | r | с | d |
|---|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 1 | 1 |
| Узел | a | b | r | cd |
|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 2 |
Затем опять объединим в один узел два минимальных по весу узла — [math]r[/math] и [math]cd[/math] :
| Узел | a | rcd | b |
|---|---|---|---|
| Вес | 5 | 4 | 2 |
Еще раз повторим эту же операцию, но для узлов [math]rcd[/math] и [math]b[/math] :
| Узел | brcd | a |
|---|---|---|
| Вес | 6 | 5 |
На последнем шаге объединим два узла — [math]brcd[/math] и [math]a[/math] :
| Узел | abrcd |
|---|---|
| Вес | 11 |
Остался один узел, значит, мы пришли к корню дерева Хаффмана (смотри рисунок). Теперь для каждого символа выберем кодовое слово (бинарная последовательность, обозначающая путь по дереву к этому символу от корня):
| Символ | a | b | r | с | d |
|---|---|---|---|---|---|
| Код | 0 | 11 | 101 | 1000 | 1001 |
Корректность алгоритма Хаффмана [ править ]
Чтобы доказать корректность алгоритма Хаффмана, покажем, что в задаче о построении оптимального префиксного кода проявляются свойства жадного выбора и оптимальной подструктуры. В сформулированной ниже лемме показано соблюдение свойства жадного выбора.
[math]f[x]d_T(x) + f[y]d_T(y) = (f[x] + f[y])(d_
из чего следует, что
[math] B(T) = B(T’) + f[x] + f[y] [/math]
Код Хаффмана
Алгоритм Хаффмана — адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
В отличие от алгоритма Шеннона — Фано, алгоритм Хаффмана остаётся всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами.
Этот метод кодирования состоит из двух основных этапов:
Содержание
Кодирование Хаффмана
Один из первых алгоритмов эффективного кодирования информации был предложен Д. А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (т.е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево). [1]
Допустим, у нас есть следующая таблица частот:
| 15 | 7 | 6 | 6 | 5 |
|---|---|---|---|---|
| А | Б | В | Г | Д |
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от листа дерева, соответствующего текущему символу, до его корня, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Для данной таблицы символов коды Хаффмана будут выглядеть следующим образом.
| А | Б | В | Г | Д |
|---|---|---|---|---|
| 0 | 100 | 101 | 110 | 111 |
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока. Кроме того, наиболее частый символ сообщения А закодирован наименьшим количеством бит, а наиболее редкий символ Д — наибольшим.
При этом общая длина сообщения, состоящего из приведённых в таблице символов, составит 87 бит (в среднем 2,2308 бита на символ). При использовании равномерного кодирования общая длина сообщения составила бы 117 бит (ровно 3 бита на символ). Заметим, что энтропия источника, независимым образом порождающего символы с указанными частотами составляет
2,1858 бита на символ, т.е. избыточность построенного для такого источника кода Хаффмана, понимаемая, как отличие среднего числа бит на символ от энтропии, составляет менее 0,05 бит на символ.
Классический алгоритм Хаффмана имеет ряд существенных недостатков. Во-первых, для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования. Во-вторых, избыточность кодирования обращается в ноль лишь в тех случаях, когда вероятности кодируемых символов являются обратными степенями числа 2. В-третьих, для источника с энтропией, не превышающей 1 (например, для двоичного источника), непосредственное применение кода Хаффмана бессмысленно.
Адаптивное сжатие
Адаптивное сжатие позволяет не передавать модель сообщения вместе с ним самим и ограничиться одним проходом по сообщению как при кодировании, так и при декодировании.
В создании алгоритма адаптивного кодирования Хаффмана наибольшие сложности возникают при разработке процедуры обновления модели очередным символом. Теоретически можно было бы просто вставить внутрь этой процедуры полное построение дерева кодирования Хаффмана, однако, такой алгоритм сжатия имел бы неприемлемо низкое быстродействие, так как построение Н-дерева — это слишком большая работа и производить её при обработке каждого символа неразумно. К счастью, существует способ модифицировать уже существующее Н-дерево так, чтобы отобразить обработку нового символа.
Обновление дерева при считывании очередного символа сообщения состоит из двух операций.
Первая — увеличение веса узлов дерева. Вначале увеличиваем вес листа, соответствующего считанному символу, на единицу. Затем увеличиваем вес родителя, чтобы привести его в соответствие с новыми значениями веса потомков. Этот процесс продолжается до тех пор, пока мы не доберемся до корня дерева. Среднее число операций увеличения веса равно среднему количеству битов, необходимых для того, чтобы закодировать символ.
Вторая операция — перестановка узлов дерева — требуется тогда, когда увеличение веса узла приводит к нарушению свойства упорядоченности, то есть тогда, когда увеличенный вес узла стал больше, чем вес следующего по порядку узла. Если и дальше продолжать обрабатывать увеличение веса, двигаясь к корню дерева, то дерево перестанет быть деревом Хаффмана.
Чтобы сохранить упорядоченность дерева кодирования, алгоритм работает следующим образом. Пусть новый увеличенный вес узла равен W+1. Тогда начинаем двигаться по списку в сторону увеличения веса, пока не найдем последний узел с весом W. Переставим текущий и найденный узлы между собой в списке, восстанавливая таким образом порядок в дереве (при этом родители каждого из узлов тоже изменятся). На этом операция перестановки заканчивается.
После перестановки операция увеличения веса узлов продолжается дальше. Следующий узел, вес которого будет увеличен алгоритмом, — это новый родитель узла, увеличение веса которого вызвало перестановку.
Переполнение
В процессе работы алгоритма сжатия вес узлов в дереве кодирования Хаффмана неуклонно растет. Первая проблема возникает тогда, когда вес корня дерева начинает превосходить вместимость ячейки, в которой он хранится. Как правило, это 16-битовое значение и, следовательно, не может быть больше, чем 65535. Вторая проблема, заслуживающая ещё большего внимания, может возникнуть значительно раньше, когда размер самого длинного кода Хаффмана превосходит вместимость ячейки, которая используется для того, чтобы передать его в выходной поток. Декодеру все равно, какой длины код он декодирует, поскольку он движется сверху вниз по дереву кодирования, выбирая из входного потока по одному биту. Кодер же должен начинать от листа дерева и двигаться вверх к корню, собирая биты, которые нужно передать. Обычно это происходит с переменной типа «целое», и, когда длина кода Хаффмана превосходит размер типа «целое» в битах, наступает переполнение.
Можно доказать, что максимальную длину код Хаффмана для сообщений с одним и тем же входным алфавитом будет иметь, если частоты символов образует последовательность Фибоначчи. Сообщение с частотами символов, равными числам Фибоначчи до Fib (18), — это отличный способ протестировать работу программы сжатия по Хаффману.
Масштабирование весов узлов дерева Хаффмана
Принимая во внимание сказанное выше, алгоритм обновления дерева Хаффмана должен быть изменен следующим образом: при увеличении веса нужно проверять его на достижение допустимого максимума. Если мы достигли максимума, то необходимо «масштабировать» вес, обычно разделив вес листьев на целое число, например, 2, а потом пересчитав вес всех остальных узлов.
Однако при делении веса пополам возникает проблема, связанная с тем, что после выполнения этой операции дерево может изменить свою форму. Объясняется это тем, что мы делим целые числа и при делении отбрасываем дробную часть.
Правильно организованное дерево Хаффмана после масштабирования может иметь форму, значительно отличающуюся от исходной. Это происходит потому, что масштабирование приводит к потере точности нашей статистики. Но со сбором новой статистики последствия этих «ошибок» практически сходят на нет. Масштабирование веса — довольно дорогостоящая операция, так как она приводит к необходимости заново строить все дерево кодирования. Но, так как необходимость в ней возникает относительно редко, то с этим можно смириться.
Выигрыш от масштабирования
Масштабирование веса узлов дерева через определенные интервалы дает неожиданный результат. Несмотря на то, что при масштабировании происходит потеря точности статистики, тесты показывают, что оно приводит к лучшим показателям сжатия, чем если бы масштабирование откладывалось. Это можно объяснить тем, что текущие символы сжимаемого потока больше «похожи» на своих близких предшественников, чем на тех, которые встречались намного раньше. Масштабирование приводит к уменьшению влияния «давних» символов на статистику и к увеличению влияния на неё «недавних» символов. Это очень сложно измерить количественно, но, в принципе, масштабирование оказывает положительное влияние на степень сжатия информации. Эксперименты с масштабированием в различных точках процесса сжатия показывают, что степень сжатия сильно зависит от момента масштабирования веса, но не существует правила выбора оптимального момента масштабирования для программы, ориентированной на сжатие любых типов информации.
Применение
Сжатие данных по Хаффману применяется при сжатии фото- и видеоизображений (JPEG, стандарты сжатия MPEG), в архиваторах (PKZIP, LZH и др.), в протоколах передачи данных MNP5 и MNP7.
Алгоритм сжатия Хаффмана
В преддверии старта курса «Алгоритмы для разработчиков» подготовили для вас перевод еще одного полезного материала.

Кодирование Хаффмана – это алгоритм сжатия данных, который формулирует основную идею сжатия файлов. В этой статье мы будем говорить о кодировании фиксированной и переменной длины, уникально декодируемых кодах, префиксных правилах и построении дерева Хаффмана.
Мы знаем, что каждый символ хранится в виде последовательности из 0 и 1 и занимает 8 бит. Это называется кодированием фиксированной длины, поскольку каждый символ использует одинаковое фиксированное количество битов для хранения.
Допустим, дан текст. Каким образом мы можем сократить количество места, требуемого для хранения одного символа?
Основная идея заключается в кодировании переменной длины. Мы можем использовать тот факт, что некоторые символы в тексте встречаются чаще, чем другие (см. здесь), чтобы разработать алгоритм, который будет представлять ту же последовательность символов меньшим количеством битов. При кодировании переменной длины мы присваиваем символам переменное количество битов в зависимости от частоты их появления в данном тексте. В конечном итоге некоторые символы могут занимать всего 1 бит, а другие 2 бита, 3 или больше. Проблема с кодированием переменной длины заключается лишь в последующем декодировании последовательности.
Как, зная последовательность битов, декодировать ее однозначно?
Рассмотрим строку «aabacdab». В ней 8 символов, и при кодировании фиксированной длины для ее хранения понадобится 64 бита. Заметим, что частота символов «a», «b», «c» и «d» равняется 4, 2, 1, 1 соответственно. Давайте попробуем представить «aabacdab» меньшим количеством битов, используя тот факт, что «a» встречается чаще, чем «b», а «b» встречается чаще, чем «c» и «d». Начнем мы с того, что закодируем «a» с помощью одного бита, равного 0, «b» мы присвоим двухбитный код 11, а с помощью трех битов 100 и 011 закодируем «c» и «d».
В итоге у нас получится:
Таким образом строку «aabacdab» мы закодируем как 00110100011011 (0|0|11|0|100|011|0|11), используя коды, представленные выше. Однако основная проблема будет в декодировании. Когда мы попробуем декодировать строку 00110100011011, у нас получится неоднозначный результат, поскольку ее можно представить как:
Чтобы избежать этой неоднозначности, мы должны гарантировать, что наше кодирование удовлетворяет такому понятию, как префиксное правило, которое в свою очередь подразумевает, что коды можно декодировать всего одним уникальным способом. Префиксное правило гарантирует, что ни один код не будет префиксом другого. Под кодом мы подразумеваем биты, используемые для представления конкретного символа. В приведенном выше примере 0 – это префикс 011, что нарушает префиксное правило. Итак, если наши коды удовлетворяют префиксному правилу, то можно однозначно провести декодирование (и наоборот).
Давайте пересмотрим пример выше. На этот раз мы назначим для символов «a», «b», «c» и «d» коды, удовлетворяющие префиксному правилу.
С использованием такого кодирования, строка «aabacdab» будет закодирована как 00100100011010 (0|0|10|0|100|011|0|10). А вот 00100100011010 мы уже сможем однозначно декодировать и вернуться к нашей исходной строке «aabacdab».
Кодирование Хаффмана
Теперь, когда мы разобрались с кодированием переменной длины и префиксным правилом, давайте поговорим о кодировании Хаффмана.
Метод основывается на создании бинарных деревьев. В нем узел может быть либо конечным, либо внутренним. Изначально все узлы считаются листьями (конечными), которые представляют сам символ и его вес (то есть частоту появления). Внутренние узлы содержат вес символа и ссылаются на два узла-наследника. По общему соглашению, бит «0» представляет следование по левой ветви, а «1» — по правой. В полном дереве N листьев и N-1 внутренних узлов. Рекомендуется, чтобы при построении дерева Хаффмана отбрасывались неиспользуемые символы для получения кодов оптимальной длины.
Мы будем использовать очередь с приоритетами для построения дерева Хаффмана, где узлу с наименьшей частотой будет присвоен высший приоритет. Ниже описаны шаги построения:
Путь от корня до любого конечного узла будет хранить оптимальный префиксный код (также известный, как код Хаффмана), соответствующий символу, связанному с этим конечным узлом.
Дерево Хаффмана
Ниже вы найдете реализацию алгоритма сжатия Хаффмана на языках C++ и Java:
Примечание: память, используемая входной строкой, составляет 47 * 8 = 376 бит, а закодированная строка занимает всего 194 бита, т.е. данные сжимаются примерно на 48%. В программе на С++ выше мы используем класс string для хранения закодированной строки, чтобы сделать программу читаемой.
Поскольку эффективные структуры данных очереди приоритетов требуют на вставку O(log(N)) времени, а в полном бинарном дереве с N листьями присутствует 2N-1 узлов, и дерево Хаффмана – это полное бинарное дерево, то алгоритм работает за O(Nlog(N)) времени, где N – количество символов.
Код Хаффмана
В этой статье мы рассмотрим один из самых распространенных методов сжатия данных. Речь пойдет о коде Хаффмана (Huffman code) или минимально-избыточном префиксном коде (minimum-redundancy prefix code). Мы начнем с основных идей кода Хаффмана, исследуем ряд важных свойств и затем приведем полную реализацию кодера и декодера, построенных на идеях, изложенных в этой статье.
Идея, лежащая в основе кода Хаффмана, достаточно проста. Вместо того чтобы кодировать все символы одинаковым числом бит (как это сделано, например, в ASCII кодировке, где на каждый символ отводится ровно по 8 бит), будем кодировать символы, которые встречаются чаще, меньшим числом бит, чем те, которые встречаются реже. Более того, потребуем, чтобы код был оптимален или, другими словами, минимально-избыточен.
Первым такой алгоритм опубликовал Дэвид Хаффман (David Huffman) [1] в 1952 году. Алгоритм Хаффмана двухпроходный. На первом проходе строится частотный словарь и генерируются коды. На втором проходе происходит непосредственно кодирование.
Стоит отметить, что за 50 лет со дня опубликования, код Хаффмана ничуть не потерял своей актуальности и значимости. Так с уверенностью можно сказать, что мы сталкиваемся с ним, в той или иной форме (дело в том, что код Хаффмана редко используется отдельно, чаще работая в связке с другими алгоритмами), практически каждый раз, когда архивируем файлы, смотрим фотографии, фильмы, посылаем факс или слушаем музыку.
Код Хаффмана
| (1) | ci не является префиксом для cj, при i!=j |
| (2) | 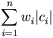 | минимальна (|ci| длина кода ci) |
называется минимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Замечания:
Известно, что любому бинарному префиксному коду соответствует определенное бинарное дерево.
Определение 2: Бинарное дерево, соответствующее коду Хаффмана, будем называть деревом Хаффмана.
Задача построения кода Хаффмана равносильна задаче построения соответствующего ему дерева. Приведем общую схему построения дерева Хаффмана:
Приведем пример: построим дерево Хаффмана для сообщения S=»A H F B H C E H E H C E A H D C E E H H H C H H H D E G H G G E H C H H».
Для начала введем несколько обозначений:
В списке, как и требовалось, остался всего один узел. Дерево Хаффмана построено. Теперь запишем его в более привычном для нас виде.
Листовые узлы дерева Хаффмана соответствуют символам кодируемого алфавита. Глубина листовых узлов равна длине кода соответствующих символов.
| A=0010bin | C=000bin | E=011bin | G=0101bin |
| B=01001bin | D=0011bin | F=01000bin | H=1bin |
Теперь у нас есть все необходимое для того чтобы закодировать сообщение S. Достаточно просто заменить каждый символ соответствующим ему кодом:
S / =»0010 1 01000 01001 1 000 011 1 011 1 000 011 0010 1 0011 000 011 011 1 1 1 000 1 1 1 0011 011 0101 1 0101 0101 011 1 000 1 1″.
Оценим теперь степень сжатия. В исходном сообщении S было 36 символов, на каждый из которых отводилось по [log2|A|]=3 бита (здесь и далее будем понимать квадратные скобки [] как целую часть, округленную в положительную сторону, т.е. [3,018]=4). Таким образом, размер S равен 36*3=108 бит
Итак, нам удалось сжать 108 в 89 бит.
Ясно, что следуя этому алгоритму мы в точности получим исходное сообщение S.
Канонический код Хаффмана
Как можно было заметить из предыдущего раздела, код Хаффмана не единственен. Мы можем подвергать его любым трансформациям без ущерба для эффективности при соблюдении всего двух условий: коды должны остаться префиксными и их длины не должны измениться.
Далее, для краткости, будем называть канонический код Хаффмана просто каноническим кодом.
Определение 4: Бинарное дерево, соответствующее каноническому коду Хаффмана, будем называть каноническим деревом Хаффмана.
В качестве примера приведем каноническое дерево Хаффмана для сообщения S, и сравним его с обычным деревом Хаффмана.
Выпишем теперь канонические коды для всех символов нашего алфавита в двоичной и десятичной форме. При этом сгруппируем символы по длине кода.
| B=00000bin=0dec | A=0001bin=1dec | C=010bin=2dec | H=1bin=1dec |
| F=00001bin=1dec | D=0010bin=2dec | E=011bin=3dec | |
| G=0011bin=3dec |
Убедимся в том, что свойства (1) и (2) из определения 3 выполняются:
Рассмотрим теперь три символа: A, D, G. Все они имеют код одной длины. Лексикографически A м уровне (имеет длину кода 3). Его порядковый номер на этом уровне равен 2 (учитывая два нелистовых узла слева), т.е. численно равен коду символа C. Теперь запишем этот номер в двоичной форме и дополним его нулевым битом слева (т.к. 2 представляется двумя битами, а код символа C тремя): 2dec=10bin=>0 10bin. Мы получили в точности код символа C.
Таким образом, мы пришли к очень важному выводу: канонические коды вполне определяются своими длинами. Это свойство канонических кодов очень широко используется на практике. Мы к нему еще вернемся.
Теперь вновь закодируем сообщение S, но уже при помощи канонических кодов:
Z / =»0001 1 00001 00000 1 010 011 1 011 1 010 011 0001 1 0010 010 011 011 1 1 1 010 1 1 1 0010 011 0011 1 0011 0011 011 1 010 1 1″
Т.к. мы не изменили длин кодов, размер закодированного сообщения не изменился: |S / |=|Z / |=89 бит.
Теперь приведем алгоритм декодирования (CANONICAL_DECODE) [5]:
Z / =»0001 1 00001 00000 1 010 011 1 011 1 010 011 0001 1 0010 010 011 011 1 1 1 010 1 1 1 0010 011 0011 1 0011 0011 011 1 010 1 1″
Итак, мы декодировали 3 первых символа: A, H, F. Ясно, что следуя этому алгоритму мы получим в точности сообщение S.
Это, пожалуй, самый простой алгоритм для декодирования канонических кодов. К нему можно придумать массу усовершенствований. Подробнее о них можно прочитать в [5] и [9].
Вычисление длин кодов
Для того чтобы закодировать сообщение нам необходимо знать коды символов и их длины. Как уже было отмечено в предыдущем разделе, канонические коды вполне определяются своими длинами. Таким образом, наша главная задача заключается в вычислении длин кодов.
Оказывается, что эта задача, в подавляющем большинстве случаев, не требует построения дерева Хаффмана в явном виде. Более того, алгоритмы использующие внутреннее (не явное) представление дерева Хаффмана оказываются гораздо эффективнее в отношении скорости работы и затрат памяти.
На сегодняшний день существует множество эффективных алгоритмов вычисления длин кодов ([3], [4]). Мы ограничимся рассмотрением лишь одного из них. Этот алгоритм достаточно прост, но несмотря на это очень популярен. Он используется в таких программах как zip, gzip, pkzip, bzip2 и многих других.
Вернемся к алгоритму построения дерева Хаффмана. На каждой итерации мы производили линейный поиск двух узлов с наименьшим весом. Ясно, что для этой цели больше подходит очередь приоритетов, такая как пирамида (минимальная). Узел с наименьшим весом при этом будет иметь наивысший приоритет и находиться на вершине пирамиды. Приведем этот алгоритм.
Будем считать, что для каждого узла сохранен указатель на его родителя. У корня дерева этот указатель положим равным NULL. Выберем теперь листовой узел (символ) и следуя сохраненным указателям будем подниматься вверх по дереву до тех пор, пока очередной указатель не станет равен NULL. Последнее условие означает, что мы добрались до корня дерева. Ясно, что число переходов с уровня на уровень равно глубине листового узла (символа), а следовательно и длине его кода. Обойдя таким образом все узлы (символы), мы получим длины их кодов.
Максимальная длина кода
Как правило, при кодировании используется так называемая кодовая книга (CodeBook), простая структура данных, по сути два массива: один с длинами, другой с кодами. Другими словами, код (как битовая строка) хранится в ячейке памяти или регистре фиксированного размера (чаще 16, 32 или 64). Для того чтобы не произошло переполнение, мы должны быть уверены в том, что код поместится в регистр.
Оказывается, что на N-символьном алфавите максимальный размер кода может достигать (N-1) бит в длину. Иначе говоря, при N=256 (распространенный вариант) мы можем получить код в 255 бит длиной (правда для этого файл должен быть очень велик: 2.292654130570773*10^53
=2^177.259)! Ясно, что такой код в регистр не поместится и с ним нужно что-то делать.
Для начала выясним при каких условиях возникает переполнение. Пусть частота i-го символа равна i-му числу Фибоначчи. Например: A-1, B-1, C-2, D-3, E-5, F-8, G-13, H-21. Построим соответствующее дерево Хаффмана.
Такое дерево называется вырожденным. Для того чтобы его получить частоты символов должны расти как минимум как числа Фибоначчи или еще быстрее. Хотя на практике, на реальных данных, такое дерево получить практически невозможно, его очень легко сгенерировать искусственно. В любом случае эту опасность нужно учитывать.
Эту проблему можно решить двумя приемлемыми способами. Первый из них опирается на одно из свойств канонических кодов. Дело в том, что в каноническом коде (битовой строке) не более [log2N] младших бит могут быть ненулями. Другими словами, все остальные биты можно вообще не сохранять, т.к. они всегда равны нулю. В случае N=256 нам достаточно от каждого кода сохранять лишь младшие 8 битов, подразумевая все остальные биты равными нулю. Это решает проблему, но лишь отчасти. Это значительно усложнит и замедлит как кодирование, так и декодирование. Поэтому этот способ редко применяется на практике.
Второй способ заключается в искусственном ограничении длин кодов (либо во время построения, либо после). Этот способ является общепринятым, поэтому мы остановимся на нем более подробно.
Существует два типа алгоритмов ограничивающих длины кодов. Эвристические (приблизительные) и оптимальные. Алгоритмы второго типа достаточно сложны в реализации и как правило требуют больших затрат времени и памяти, чем первые. Эффективность эвристически-ограниченного кода определяется его отклонением от оптимально-ограниченного. Чем меньше эта разница, тем лучше. Стоит отметить, что для некоторых эвристических алгоритмов эта разница очень мала ([6], [7], [8]), к тому же они очень часто генерируют оптимальный код (хотя и не гарантируют, что так будет всегда). Более того, т.к. на практике переполнение случается крайне редко (если только не поставлено очень жесткое ограничение на максимальную длину кода), при небольшом размере алфавита целесообразнее применять простые и быстрые эвристические методы.
Мы рассмотрим один достаточно простой и очень популярный эвристический алгоритм. Он нашел свое применение в таких программах как zip, gzip, pkzip, bzip2 и многих других.
Начнем работу с уровня L. Переместим узел RNL на место своего родителя. Т.к. узлы идут парами нам необходимо найти место и для соседного с RNL узла. Для этого найдем ближайший к L уровень j, содержащий листовые узлы, такой, что j < (L-1). На месте LNj сформируем нелистовой узел и присоединим к нему в качестве дочерних узел LNj и оставшийся без пары узел с уровня L. Ко всем оставшимся парам узлов на уровне L применим такую же операцию. Ясно, что перераспределив таким образом узлы, мы уменьшили высоту нашего дерева на 1. Теперь она равна (L-1). Если теперь L / < (L-1), то проделаем то же самое с уровнем (L-1) и т.д. до тех пор, пока требуемое ограничение не будет достигнуто.
Вернемся к нашему примеру, где L=5. Ограничим максимальную длину кода до L / =4.
Видно, что в нашем случае RNL=F, j=3, LNj=C. Сначала переместим узел RNL=F на место своего родителя.
Теперь на месте LNj=C сформируем нелистовой узел.
Присоединим к сформированному узлу два непарных: B и C.
Таким образом, мы ограничили максимальную длину кода до 4. Ясно, что изменив длины кодов, мы немного потеряли в эффективности. Так сообщение S, закодированное при помощи такого кода, будет иметь размер 92 бита, т.е. на 3 бита больше по сравнению с минимально-избыточным кодом.
Ясно, что чем сильнее мы ограничим максимальную длину кода, тем менее эффективен будет код. Выясним насколько можно ограничивать максимальную длину кода. Очевидно что не короче [log2N] бит.
Вычисление канонических кодов
Теперь присвоим коды остальным символам. Код первого символа на уровне i равен Si, второго Si + 1, третьего Si + 2 и т.д.
Выпишем оставшиеся коды для нашего примера:
| B = S5 = 00000bin | A = S4 = 0001bin | C = S3 = 010bin | H = S1 = 1bin |
| F = S5 + 1 = 00001bin | D = S4 + 1 = 0010bin | E = S3 + 1 = 011bin | |
| G = S4 + 2 = 0011bin |
Видно, что мы получили точно такие же коды, как если бы мы явно построили каноническое дерево Хаффмана.
Передача кодового дерева
Для того чтобы закодированное сообщение удалось декодировать, декодеру необходимо иметь такое же кодовое дерево (в той или иной форме), какое использовалось при кодировании. Поэтому вместе с закодированными данными мы вынуждены сохранять соответствующее кодовое дерево. Ясно, что чем компактнее оно будет, тем лучше.
Можно сохранить список частот символов (т.е. частотный словарь). С его помощью декодер без труда сможет реконструировать кодовое дерево. Хотя этот способ и менее расточителен чем предыдущий, он не является наилучшим.
Более того, этот метод можно несколько расширить. Мы можем применить алгоритм RLE не только к группам нулевых длин, но и ко всем остальным. Такой способ передачи кодового дерева является общепринятым и применяется в большинстве современных реализаций.
Реализация: SHCODEC
Приложение: биография Д. Хаффмана
 |



