Топологическая сортировка, считывает пары строк, разделенных пробельными символами, и выполняет сортировку, в зависимости от заданного шаблона.
Удаляет повторяющиеся строки из отсортированного файла. Эту команду часто можно встретить в конвейере с командой sort.
Пример 12-8. Частота встречаемости отдельных слов
Команда expand преобразует символы табуляции в пробелы. Часто используется в конвейерной обработке текста.
Команда unexpand преобразует пробелы в символы табуляции. Т.е. она является обратной по отношению к команде expand.
Использование команды cut для получения списка смонтированных файловых систем:
Использование команды cut для получения версии ОС и ядра:
Использование команды cut для извлечения заголовков сообщений из электронных писем:
Использование команды cut при разборе текстового файла:
Используется для объединения нескольких файлов в один многоколоночный файл.
Может рассматриваться как команда, родственная команде paste. Эта мощная утилита позволяет объединять два файла по общему полю, что представляет собой упрощенную версию реляционной базы данных.
Команда join оперирует только двумя файлами и объедияет только те строки, которые имеют общее поле (обычно числовое), результат объединения выводится на stdout. Объединяемые файлы должны быть отсортированы по ключевому полю.
На выходе ключевое поле встречается только один раз.
Пример 12-9. Какие из файлов являются сценариями?
Пример 12-10. Генератор 10-значных случайных чисел
Пример 12-11. Мониторинг системного журнала с помощью tail
Поиск участков текста в файле(ах), соответствующих шаблону pattern, где pattern может быть как обычной строкой, так и регулярным выражением.
Если файл(ы) для поиска не задан, то команда grep работает как фильтр для устройства stdout, например в конвейере.
Если grep вызывается для поиска по группе файлов, то вывод будет содержать указание на имена файлов, в которых найдены совпадения.
Для того, чтобы заставить grep выводить имя файла, когда поиск производится по одному-единственному файлу, достаточно указать устройство /dev/null в качестве второго файла.
Пример 12-12. Сценарий-эмулятор «grep»
Утилита agrep имеет более широкие возможности поиска приблизительных совпадений. Образец поиска может отличаться от найденной строки на указанное число символов.
Для поиска по bzip-файлам используйте bzgrep.
Пример 12-13. Поиск слов в словаре
Скриптовые языки, специально разработанные для анализа текстовых данных.
Утилита контекстного поиска и преобразования текста, замечательный инструмент для извлечения и/или обработки полей (колонок) в структурированных текстовых файлах. Синтаксис awk напоминает язык C.
От переводчика: в случае, если у вас локаль отлична от «C», то вышеприведенная команда может не дать результата, поскольку wc вернет не слово «total», в конце вывода, а «итого». Тогда можно попробовать несколько измененный вариант:
Использование wc для подсчета количества вхождений слова «Linux» в основной исходный файл с текстом этого руководства.
Отдельные команды располагают функциональностью wc в виде своих ключей.
Замена одних символов на другие.
В отдельных случаях символы необходимо заключать в кавычки и/или квадратные скобки. Кавычки предотвращают интерпретацию специальных символов командной оболочкой. Квадратные скобки должны заключаться в кавычки.
Команда tr «A-Z» «*» tr A-Z \* filename на звездочки (вывод производится на stdout). В некоторых системах этот вариант может оказаться неработоспособным, тогда попробуйте tr A-Z ‘[**]’.
Обратите внимание: команда tr корректно распознает символьные классы POSIX. [1]
Пример 12-14. toupper: Преобразование символов в верхний регистр.
Пример 12-15. lowercase: Изменение имен всех файлов в текущем каталоге в нижний регистр.
Пример 12-16. du: Преобразование текстового файла из формата DOS в формат UNIX.
Пример 12-17. rot13: Сверхслабое шифрование по алгоритму rot13.
Пример 12-18. Более «сложный» шифр
Различные версии tr
Утилита tr имеет две, исторически сложившиеся, версии. BSD-версия не использует квадратные скобки ( tr a-z A-Z), в то время как SysV-версия использует их ( tr ‘[a-z]’ ‘[A-Z]’). GNU-версия утилиты tr напоминает версию BSD, но диапазоны символов обязательно должны заключаться в квадратные скобки.
Очень простая утилита форматирования текста, чаще всего используемая как фильтр в конвейерах для того, чтобы выполнить «перенос» длинных строк текста.
Пример 12-19. Отформатированный список файлов.
Очень мощной альтернативой утилите fmt, является утилита par (автор Kamil Toman), которую вы сможете найти на http://www.cs.berkeley.edu/
Пример 12-20. Пример форматирования списка файлов в каталоге
Утилита удаления колонок. Удаляет колонки (столбцы) сиволов из файла и выводит результат на stdout. colrm 2 4 filename.
Если файл содержит символы табуляции или непечатаемые символы, то результат может получиться самым неожиданным. В таких случаях, как правило, утилиту colrm, в конвейере, окружают командами expand и unexpand.
Пример 12-21. nl: Самонумерующийся сценарий.
Подготовка файла к печати. Утилита производит разбивку файла на страницы, приводя его в вид пригодный для печати или для вывода на экран. Разнообразные ключи позволяют выполнять различные манипуляции над строками и колонками, соединять строки, устанавливать поля, нумеровать строки, добавлять колонтитулы и многое, многое другое. Утилита pr соединяет в себе функциональность таких команд, как nl, paste, fold, column и expand.
GNU утилита, предназначена для нужд локализации и перевода сообщений программ, выводимых на экран, на язык пользователя. Не смотря на то, что это актуально, прежде всего, для программ на языке C, тем не менее gettext с успехом может использоваться в сценариях командной оболочки для тех же целей. См. info page.
Утилита преобразования текста из одной кодировки в другую. В основном используется для нужд локализации.
Может рассматриваться как разновилность утилиты iconv, описанной выше. Универсальная утилита для преобразования текстовой информации в различные кодировки.
Примечания
Это верно только для GNU-версии команды tr, поведение этой команды, в коммерческих UNIX-системах, может несколько отличаться.
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
Пример скрипта для сравнения двух строковых переменных
Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
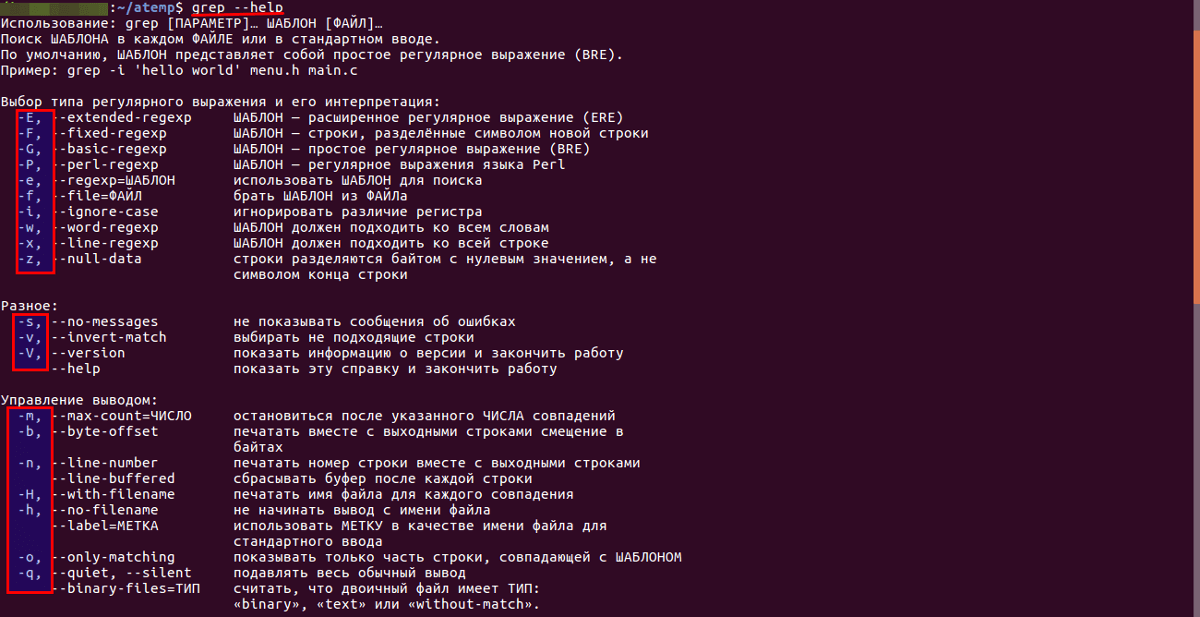
Основы работы с grep
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
Основные опции
Практическое применение grep
Поиск подстроки в строке
В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
Вывод нескольких строк
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивныйрежим поиска
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод толькоимени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
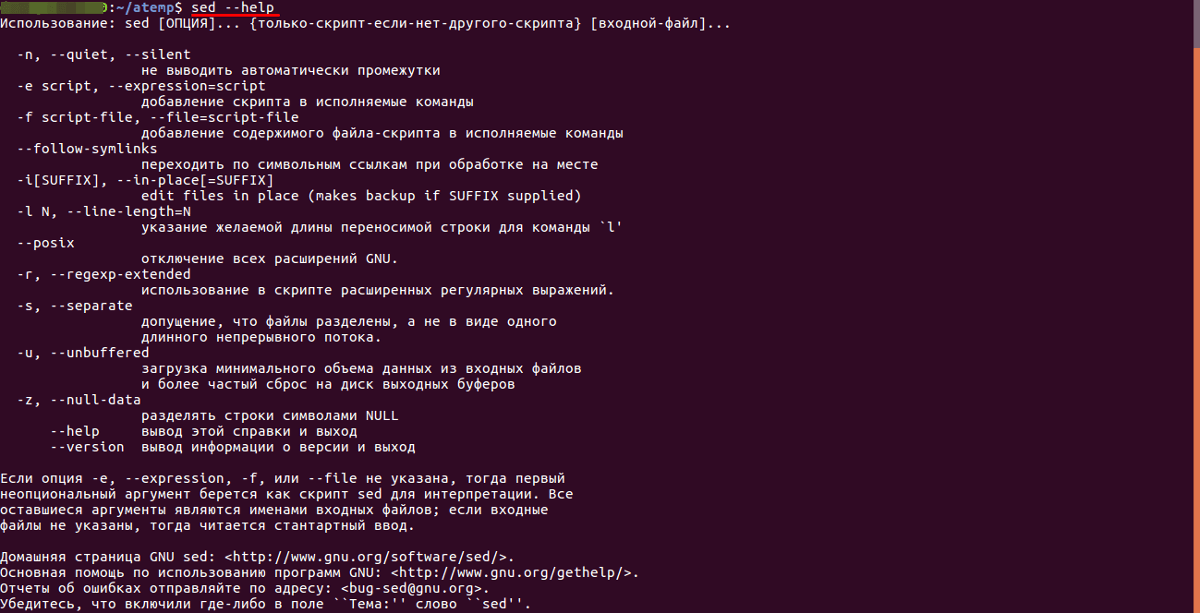
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удалениевсех чиселиз текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимогофайла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда: sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Написание скриптов на Bash
Если вы уже более опытный пользователь, то, наверное, часто выполняете различные задачи через терминал. Часто встречаются задачи, для которых нужно выполнять несколько команд по очереди, например, для обновления системы необходимо сначала выполнить обновление репозиториев, а уже затем скачать новые версии пакетов. Это только пример и таких действий очень много, даже взять резервное копирование и загрузку скопированных файлов на удаленный сервер. Поэтому, чтобы не набирать одни и те же команды несколько раз можно использовать скрипты. В этой статье мы рассмотрим написание скриптов на Bash, рассмотрим основные операторы, а также то как они работают, так сказать, bash скрипты с нуля.
Основы скриптов
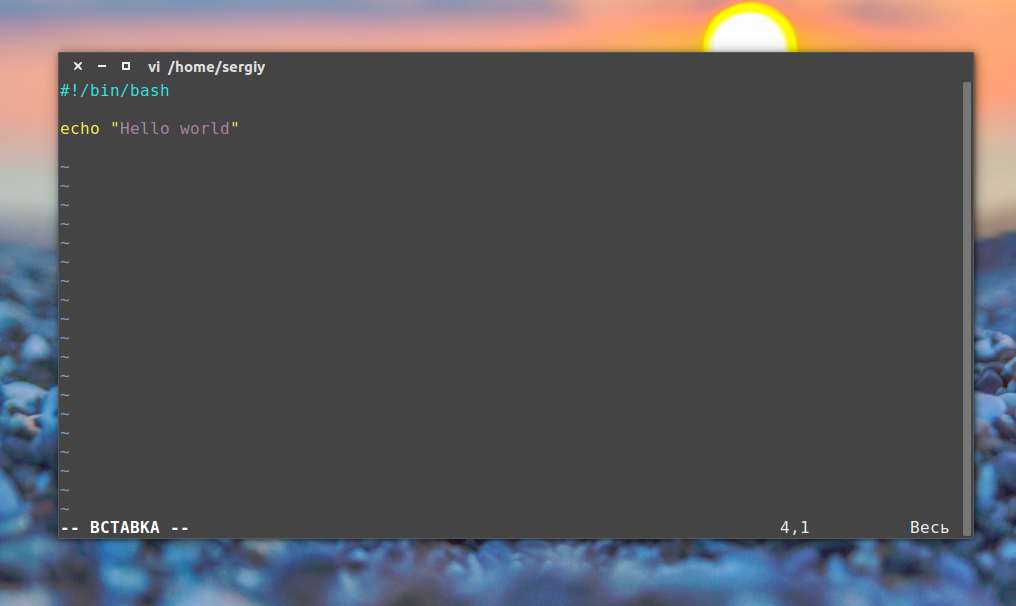
Простейший пример скрипта для командной оболочки Bash:
!/bin/bash echo «Hello world»
Утилита echo выводит строку, переданную ей в параметре на экран. Первая строка особая, она задает программу, которая будет выполнять команды. Вообще говоря, мы можем создать скрипт на любом другом языке программирования и указать нужный интерпретатор, например, на python:
!/usr/bin/env python print(«Hello world»)
!/usr/bin/env php echo «Hello world»;
В первом случае мы прямо указали на программу, которая будет выполнять команды, в двух следующих мы не знаем точный адрес программы, поэтому просим утилиту env найти ее по имени и запустить. Такой подход используется во многих скриптах. Но это еще не все. В системе Linux, чтобы система могла выполнить скрипт, нужно установить на файл с ним флаг исполняемый.
Этот флаг ничего не меняет в самом файле, только говорит системе, что это не просто текстовый файл, а программа и ее нужно выполнять, открыть файл, узнать интерпретатор и выполнить. Если интерпретатор не указан, будет по умолчанию использоваться интерпретатор пользователя. Но поскольку не все используют bash, нужно указывать это явно.
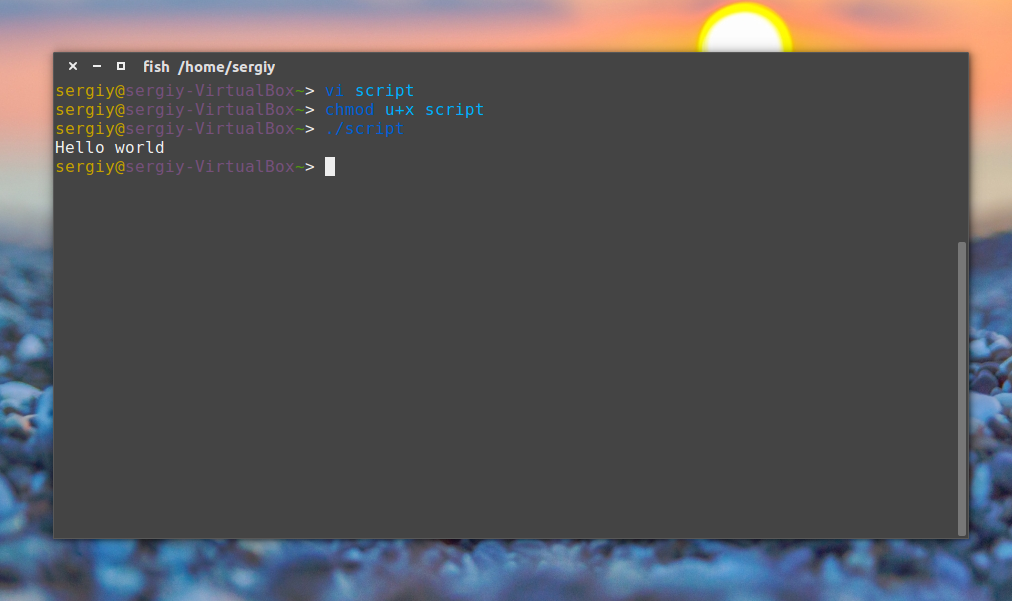
chmod ugo+x файл_скрипта
Теперь выполняем нашу небольшую первую программу:
Все работает. Вы уже знаете как написать маленький скрипт, скажем для обновления. Как видите, скрипты содержат те же команды, что и выполняются в терминале, их писать очень просто. Но теперь мы немного усложним задачу. Поскольку скрипт, это программа, ему нужно самому принимать некоторые решения, хранить результаты выполнения команд и выполнять циклы. Все это позволяет делать оболочка Bash. Правда, тут все намного сложнее. Начнем с простого.
Переменные в скриптах
Написание скриптов на Bash редко обходится без сохранения временных данных, а значит создания переменных. Без переменных не обходится ни один язык программирования и наш примитивный язык командной оболочки тоже.
Возможно, вы уже раньше встречались с переменными окружения. Так вот, это те же самые переменные и работают они аналогично.
Например, объявим переменную string:
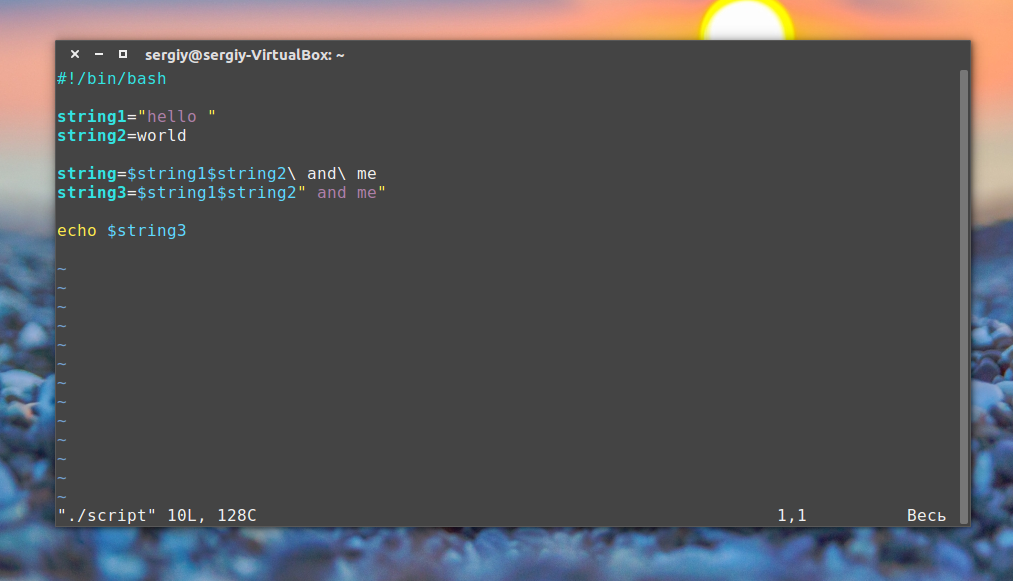
Модифицируем наш скрипт:
Bash не различает типов переменных так, как языки высокого уровня, например, С++, вы можете присвоить переменной как число, так и строку. Одинаково все это будет считаться строкой. Оболочка поддерживает только слияние строк, для этого просто запишите имена переменных подряд:
Обратите внимание, что как я и говорил, кавычки необязательны если в строке нет спецсимволов. Присмотритесь к обоим способам слияния строк, здесь тоже демонстрируется роль кавычек. Если же вам нужны более сложные способы обработки строк или арифметические операции, это не входит в возможности оболочки, для этого используются обычные утилиты.
Переменные и вывод команд
Переменные не были бы настолько полезны, если бы в них невозможно было записать результат выполнения утилит. Для этого используется такой синтаксис:
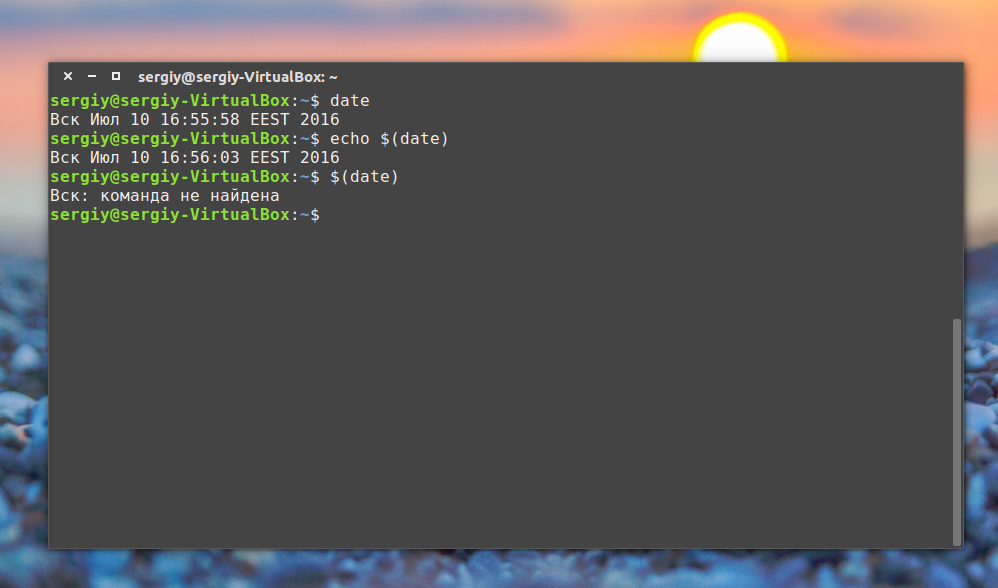
$( команда )
С помощью этой конструкции вывод команды будет перенаправлен прямо туда, откуда она была вызвана, а не на экран. Например, утилита date возвращает текущую дату. Эти команды эквивалентны:
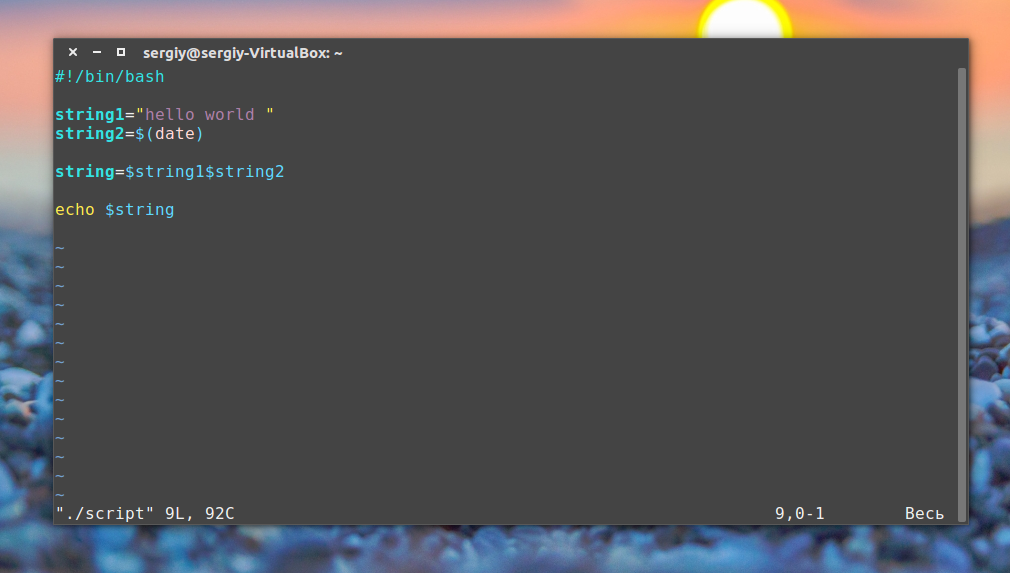
Понимаете? Напишем скрипт, где будет выводиться hello world и дата:
string1=»hello world » string2=$(date)
Теперь вы знаете достаточно о переменных, и готовы создать bash скрипт, но это еще далеко не все. Дальше мы рассмотрим параметры и управляющие конструкции. Напомню, что это все обычные команды bash, и вам необязательно сохранять их в файле, можно выполнять сразу же на ходу.
Параметры скрипта
Не всегда можно создать bash скрипт, который не зависит от ввода пользователя. В большинстве случаев нужно спросить у пользователя какое действие предпринять или какой файл использовать. При вызове скрипта мы можем передавать ему параметры. Все эти параметры доступны в виде переменных с именами в виде номеров.
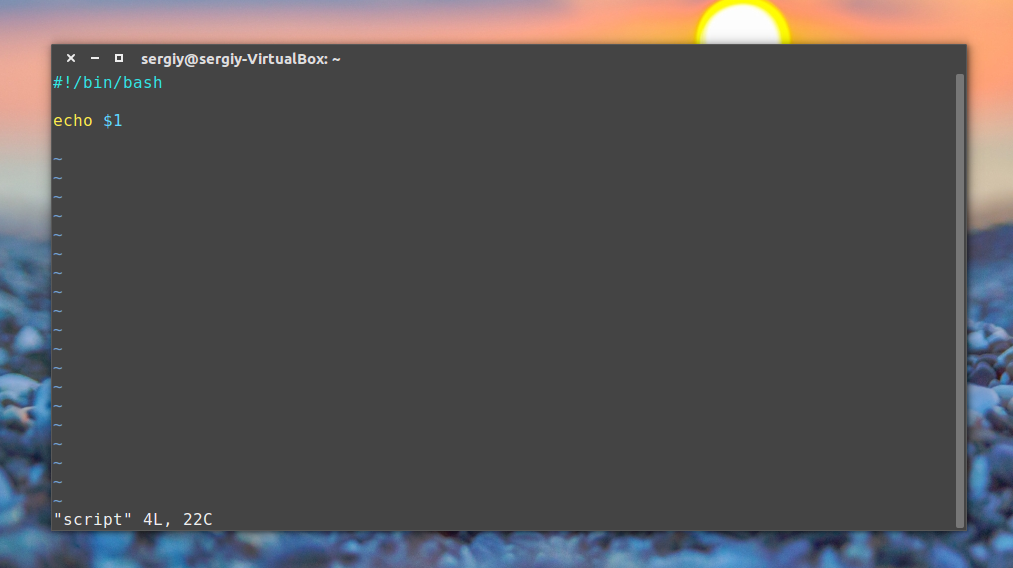
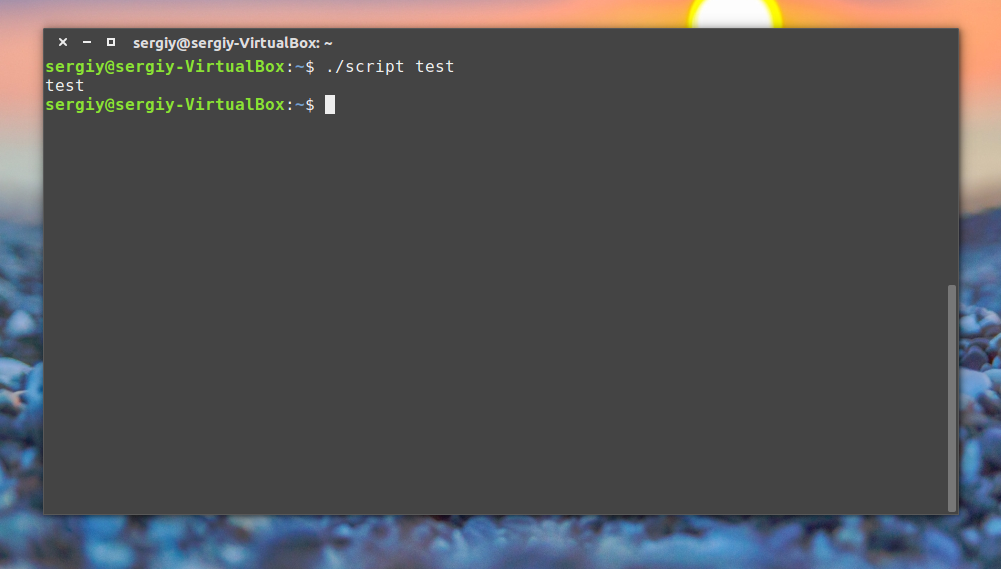
Переменная с именем 1 содержит значение первого параметра, переменная 2, второго и так далее. Этот bash скрипт выведет значение первого параметра:
Управляющие конструкции в скриптах
Создание bash скрипта было бы не настолько полезным без возможности анализировать определенные факторы, и выполнять в ответ на них нужные действия. Это довольно-таки сложная тема, но она очень важна для того, чтобы создать bash скрипт.
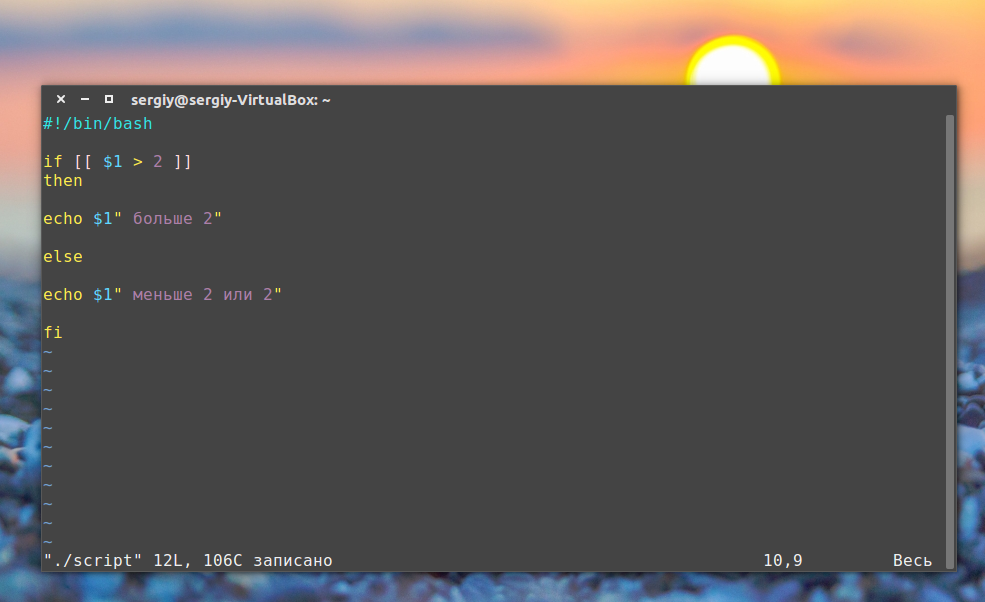
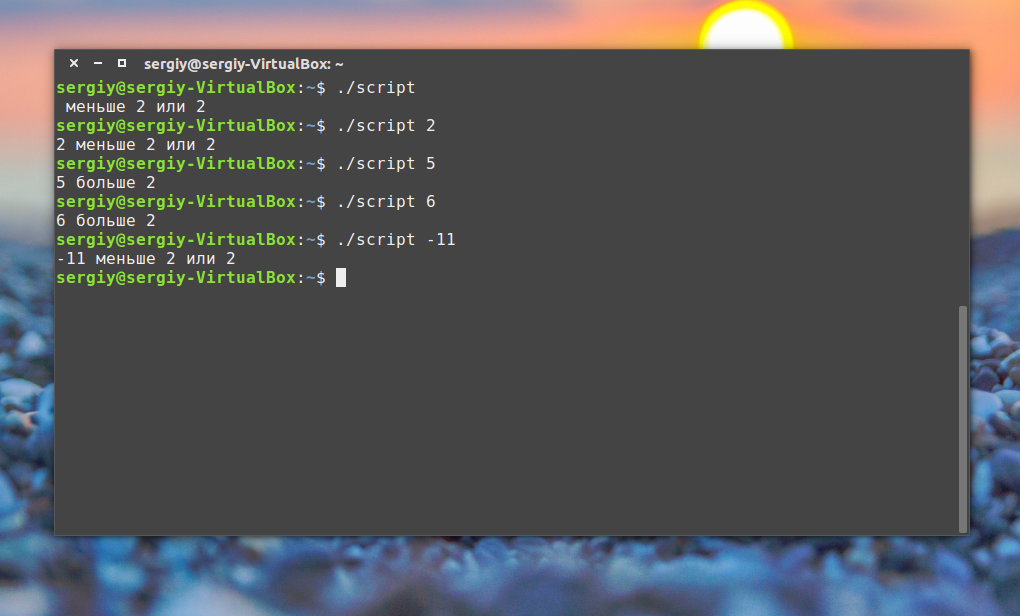
В Bash для проверки условий есть команда Синтаксис ее такой:
if команда_условие then команда else команда fi
Эта команда проверяет код завершения команды условия, и если 0 (успех) то выполняет команду или несколько команд после слова then, если код завершения 1 выполняется блок else, fi означает завершение блока команд.
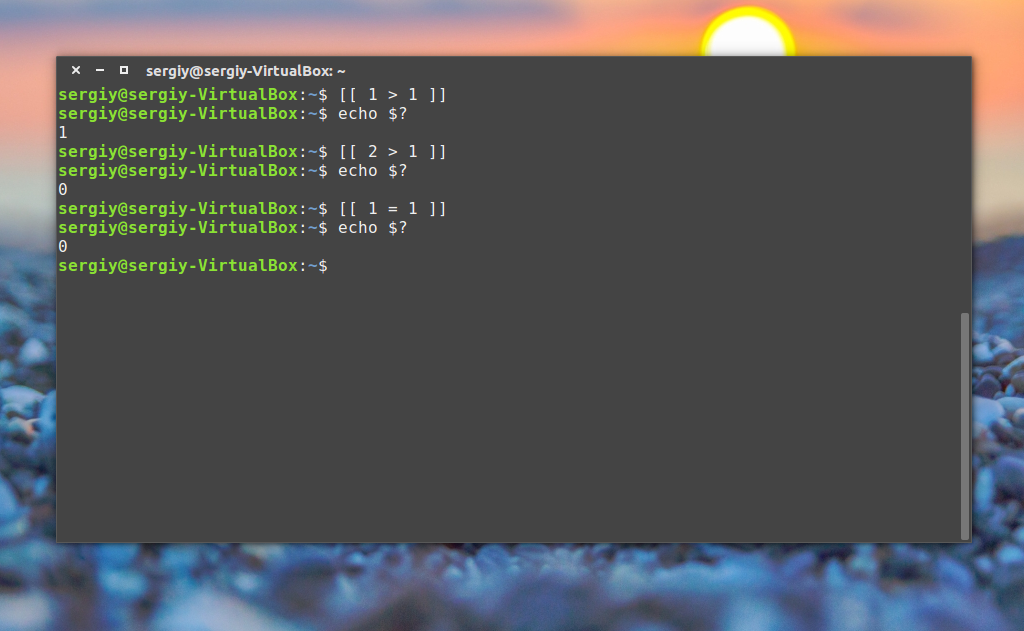
Но поскольку нам чаще всего нас интересует не код возврата команды, а сравнение строк и чисел, то была введена команда [[, которая позволяет выполнять различные сравнения и выдавать код возврата зависящий от результата сравнения. Ее синтаксис:
[[ параметр1 оператор параметр2 ]]
Теперь объединением все это и получим скрипт с условным выражением:
Конечно, у этой конструкции более мощные возможности, но это слишком сложно чтобы рассматривать их в этой статье. Возможно, я напишу об этом потом. А пока перейдем к циклам.
Циклы в скриптах
Преимущество программ в том, что мы можем в несколько строчек указать какие действия нужно выполнить несколько раз. Например, возможно написание скриптов на bash, которые состоят всего из нескольких строчек, а выполняются часами, анализируя параметры и выполняя нужные действия.
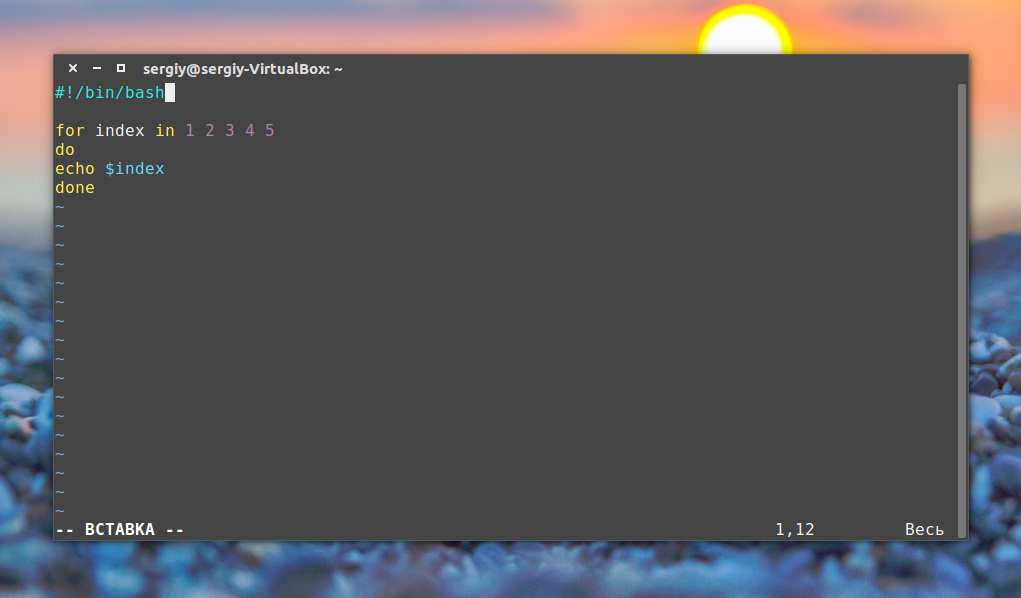
Первым рассмотрим цикл for. Вот его синтаксис:
for переменная in список do команда done
Перебирает весь список, и присваивает по очереди переменной значение из списка, после каждого присваивания выполняет команды, расположенные между do и done.
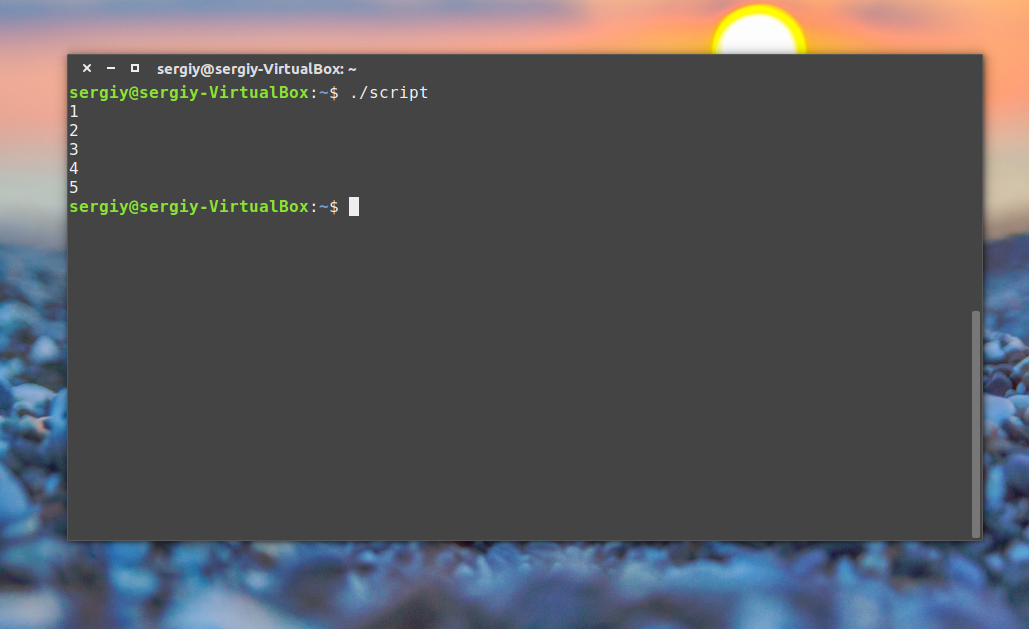
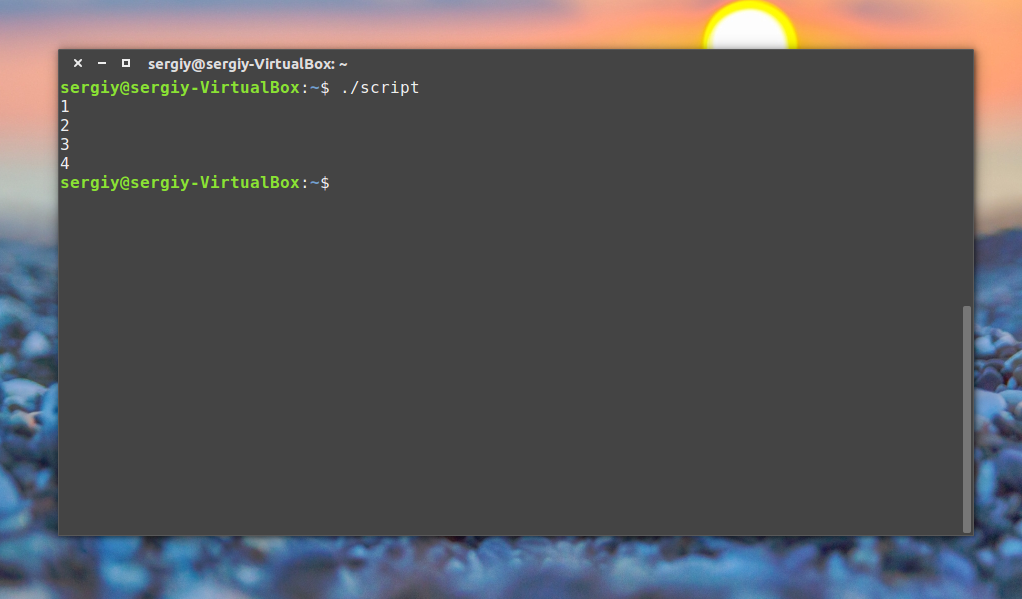
Например, переберем пять цифр:
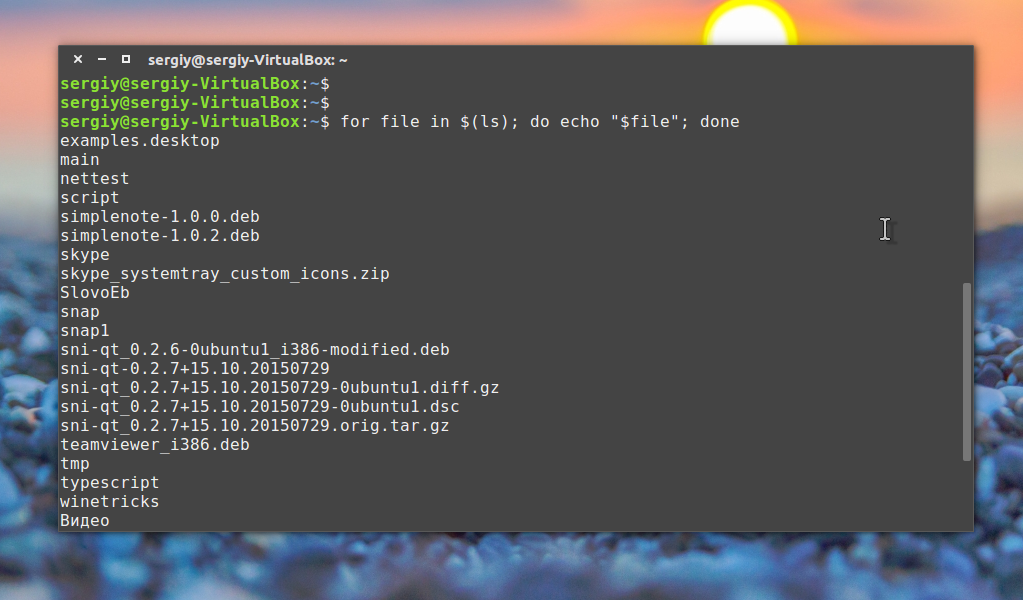
Или вы можете перечислить все файлы из текущей директории:
Как вы понимаете, можно не только выводить имена, но и выполнять нужные действия, это очень полезно когда выполняется создание bash скрипта.
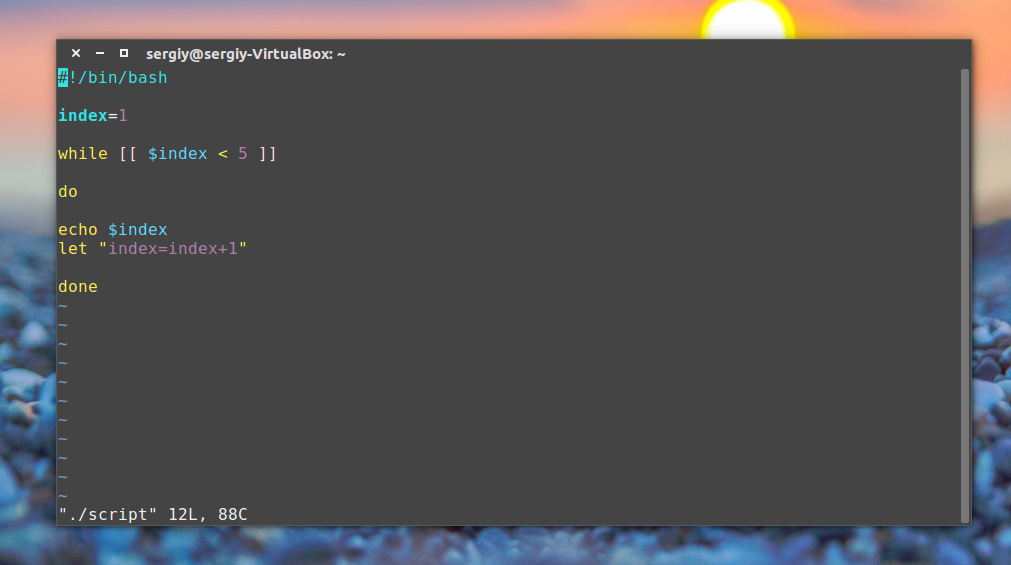
while команда условие do команда done
Как видите, все выполняется, команда let просто выполняет указанную математическую операцию, в нашем случае увеличивает значение переменной на единицу.
Хотелось бы отметить еще кое-что. Такие конструкции, как while, for, if рассчитаны на запись в несколько строк, и если вы попытаетесь их записать в одну строку, то получите ошибку. Но тем не менее это возможно, для этого там, где должен быть перевод строки ставьте точку с запятой «;». Например, предыдущий цикл можно было выполнить в виде одной строки:
Все очень просто я пытался не усложнять статью дополнительными терминами и возможностями bash, только самое основное. В некоторых случаях, возможно, вам понадобиться сделать gui для bash скрипта, тогда вы можете использовать такие программы как zenity или kdialog, с помощью них очень удобно выводить сообщения пользователю и даже запрашивать у него информацию.
Выводы
Теперь вы понимаете основы создания скрипта в linux и можете написать нужный вам скрипт, например, для резервного копирования. Я пытался рассматривать bash скрипты с нуля. Поэтому далеко не все аспекты были рассмотрены. Возможно, мы еще вернемся к этой теме в одной из следующих статей.
Bash-скрипты, часть 7: sed и обработка текстов
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.
Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.
Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
Вот что получится при выполнении этой команды.
Простой пример вызова sed
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
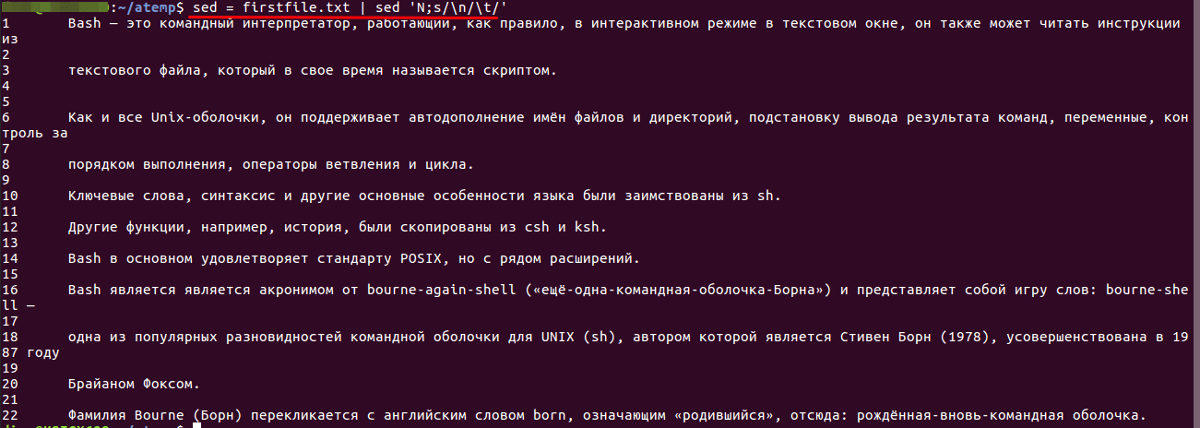
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Выполнение наборов команд при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела. Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
Вот что получится после того, как команда, представленная в таком виде, будет выполнена.
Другой способ работы с sed
Чтение команд из файла
Вот содержимое файла mycommands :
Вызовем sed, передав редактору файл с командами и файл для обработки:
Результат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
Вот что содержится в файле, и что будет получено после его обработки sed.
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
Выполнение этой команды можно модифицировать несколькими способами.
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g :
Как видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.
Как результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
Использование флага команды замены p
Сохранение результатов обработки текста в файл
Символы-разделители
Однако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s :
В данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Вызов команды выглядит так:
Мы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
Удаление строк до конца файла
Строки можно удалять и по шаблону:
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a :
Теперь взглянем на команду a :
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a :
Команда a с указанием номера опорной строки
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Вставка в поток содержимого файла
Вот что произойдёт, если применить при вызове команды r шаблон:
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
Замена указателя места заполнения на реальные данные
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.