Атрибут rel=canonical: что это, для чего нужен, когда применять, как правильно прописать, ошибки использования

Rel=”canonical” – это атрибут, задающий канонический (приоритетный) адрес для дублирующих страниц, по которому основная страница ранжируется и отображается в выдаче поисковой системы.
Для чего нужен?
Когда две одинаковые страницы с идентичным содержанием можно найти через разные УРЛы. Соответственно тогда в индекс поисковой системы пытаются попасть несколько одинаковых страниц. Эти одинаковые страницы называются дублями.
Как результат, ни одна из них не способна полноценно продвигаться, потому что внутренние ссылки не могут сосредоточиться на одной единственной странице, ссылаясь по отдельности на каждый из дублей – вес «рассеивается».
Аналогичная ситуация и с внешними ссылками. Они ссылаются то на один, то на другой документ, из-за чего не настолько эффективны в продвижении, как могли бы быть. Вебмастер в данном случае даже не может определиться, на какую конкретно страницу покупать ссылки, потому что в индексе может оказаться та, которую он не собирался продвигать.
Как итог, веб-ресурс не может раскрыть весь свой потенциал и подняться в результатах поиска выше, чем мог бы. К тому же поисковые системы могут не индексировать дубли, потому что зачем им это делать, если на сайте несколько одинаковых страниц. Или они могут проиндексировать ту страницу, которую вы не собираетесь продвигать.
Канонический атрибут позволяет исключить проблему дублирующегося контента. Он показывает роботам, какой URL является приоритетным (основным) и будет включен в индекс системы, а весь ссылочный вес и прочие характеристики дубликатов переходят ему.
Поэтому, если на вашем веб-ресурсе содержатся страницы с идентичной или сильно похожей информацией, имеющие разные адреса, rel=“canonical” укажет основной адрес, который и будет включен в поиск.
Кроме выбора приоритетного УРЛа для индексации страницы каноникал помогает:
Все популярные поисковики прекрасно распознают данный тег, а некоторые веб-страницы без применения приоритетных ссылок просто невозможно эффективно продвигать.
Когда использовать?
Есть несколько причин для использования canonical.
1. На сайте есть аналогичные или похожие страницы
Поисковый робот воспримет их как дубли. Тогда в индекс машина включит лишь одну страницу, ту, которую посчитает полезней. Чтобы избежать этого необходимо указать, какую конкретно страницу включить в результаты поиска. Для этого в HTML-код страницы, которую вы не хотите включать в поиск, нужно добавить приоритетный (канонический) адрес.
Допустим, одна и та же страница содержит два URL:
Если приоритетный адрес /images, то его следует прописать в исходный код документа /pages?id23.
Выглядит это следующим образом, в коде страницы /pages?id23 мы прописываем:
Важно! Обязательно rel=”canonical должен прописываться перед ссылкой, иначе роботы поисковых систем могут не учесть это правило.
Старайтесь предупреждать появление дублей заранее. Есть огромное количество страниц, где постоянно появляются дубли:
Движки управления сайтом кроме основных документов генерируют еще и дополнительные страницы с аналогичным контентом, однако у них другие функции:
Так, включив в WordPress функцию древовидных комментариев, под каждым комментарием посетителя будет отображаться кликабельная кнопка «Ответить».
По этой ссылке можно перейти и вы попадете на идентичную страницу с аналогичным УРЛом, в конце которого добавлено слово “reptytocom”. Это уже совсем другой адрес для ботов, но информация на страницах одинаковая, поэтому появляется дубль.
Во избежание подобных проблем следует прописывать каноникал в коде всех подобных статических документов.
2. Нужно поменять URL сайта
Смена адреса может понадобиться в двух случаях:
Здесь канонический адрес воспримется роботом поисковой системы как редирект на новое главное зеркало, из-за чего две версии веб-ресурса объединятся в одну.
Разместите в HTML-коде страниц «старого» сайта линки на эти же документы «нового», добавив canonical. К примеру, URL http://site.ru нужно поменять на https://site.ru. Тогда в исходном коде страницы http://site.ru/ укажите:
Когда указывается атрибут на другую, не дублирующую страницу, поисковый бот рассматривает это как различие в структуре сайтов. Тогда переехать на канонический УРЛ не получится. Важно перепроверять, чтобы содержание старой и новой версии ресурса было аналогичным или практически одинаковым.
На заметку. Если прописать атрибут для отдельных документов, он не укажет на главное зеркало.
3. Когда на постраничных документах в категориях веб-ресурса есть страницы «Показать все»
Тут следует указать canonical для страницы «Показать все» в каждой странице пагинации. К примеру, для URL https://site.ru/category-3/page-2 нужно написать канонический адрес:
Как правильно прописать
Есть несколько способов сделать так, чтобы в базу данных поисковиков документ попал только по одному нужному вам URL-адресу:
В html
Самый распространенный метод. Чтобы задать основную страницу, в исходном коде дублей между тегами и напишите полный адрес той страницы, которую желаете видеть в выдаче. Допустим, для страницы с UTM-меткой https://site.ru/*utm_medium канонической является https://site.ru/prioritetniy-url.
Зайдите в HTML-код документа https://site.ru/*utm_medium (правой кнопкой мыши на странице –> посмотреть исходный код) и пропишите в нем:
Если у приоритетной страницы есть мобильная версия, добавьте следующий атрибут:
Важно! Избегайте ошибок в link с каноническим атрибутом – пишите абсолютные ссылки, с относительными могут быть проблемы. Также обязательно указывайте rel=”canonical” и rel=»alternate» перед ссылкой, а не после!
Плюсы:
Минусы:
В Sitemap
В карте сайта тоже можно задать приоритетный URL-адрес для любого документа. Любая страница в Sitemap считается канонической. Конечно никто не обещает, что абсолютно все URL на этой странице будут восприниматься как канонические, но в принципе это удобный вариант прописать основные адреса на объемном ресурсе.
Важно знать! Здесь атрибут canonical несет рекомендационный характер для поисковой системы, поэтому они могут не учесть его.
Плюсы:
Минусы:
В заголовке http
Больше подходит страницам, например, формата PDF. Тогда сервер в процессе запроса повторяющегося файла отправит ссылку на исходный файл.
Важно! Данный метод подойдет для вебмастеров, кому доступны настройки сервера. Нет смысла задавать для HTML-документов.
Плюсы:
Минусы:
В WordPress с помощью плагина
Для CMS движков сегодня доступно множество плагинов, позволяющих легко указывать приоритетные страницы с нужным УРЛом.
Yoast SEO

All in one seo pack


Чтобы активировать данную функцию, достаточно поставить галочку возле Канонические URL’ы.
Однако есть пара проблем, мешающих нормальной индексации ресурса:
Platinum seo pack
У данного плагина не было проблем со страницами пагинации. Была только проблема в удалении стандартного атрибута rel=”canonical”. Включив функцию добавления канонического атрибута и затем посмотрев исходный код какой-то из страниц, атрибут непосредственно от движка тоже оставался. Это случалось не всегда, да и проблема решалась после добавления в файл шаблона functions.php код:
Этот плагин был закрыт 16 апреля 2019 года и больше не доступен для скачивания. Причина: проблема безопасности. Не известно, будет ли решена проблема и станет ли доступным плагин снова.
Как проверить правильно ли прописан rel=canonical

Есть специальный сервис, позволяющий провести тщательный SEO-анализ ресурса: Screaming Frog SEO Spider. Здесь вы увидите информацию о:
А чтобы быть уверенным, что вы корректно указали канонический адрес URL, ознакомьтесь с рекомендациями их выбора:
Ошибки использования rel=canonical
Помните, что тег canonical – это рекомендационная директива. Она лишь подсказывает поисковикам, какую страницу сделать канонической, но последнее решение остается за машиной.
Заключение
Rel=”canonical” – полезный и простой в использовании атрибут, который поможет сделать индексацию вашего веб-ресурса правильной. Грамотное использование инструмента позволит роботам быстрее включать в индекс страницы вашего сайта и, следовательно, вам эффективнее продвигать его благодаря хорошему ранжированию.
Оцените эту статью. Чтобы мы могли делать лучший контент! Напишите в комментариях, что вам понравилось и не понравилось!
Рейтинг статьи: 3.8 / 5. Кол-во оценок: 5
Пока нет голосов! Будьте первым, кто оценит эту статью.
Урок 400 Атрибут rel=canonical. Что такое канонический URL и как им пользоваться
Атрибут rel=canonical позволяет бороться с дублями страниц. Когда одно и то же содержимое доступно по разным URL, канонические ссылки указывают главную страницу. Эта страница (приоритетная) как раз и будет находиться в индексе поисковых систем и весь вес со страниц дубликатов будет перетекать на основную страницу.
Атрибут canonical прописывается на страницах дублей с указанием наиболее приоритетной страницы в разделестраницы вот так:
Данный тег прекрасно понимают все основные поисковые системы и канонические ссылки являются для некоторых типов страниц неотъемлемыми с точки зрения SEO оптимизации. Об этом всем мы с вами поговорим сегодня.
Rel canonical: что это
Когда на один и тот же контент можно попасть с помощью разных URL’ов, в индексе поисковых систем начинает участвовать сразу несколько страниц. В итоге ни одна страница толком не продвигается, так как внутренние ссылки идут то на одну страницу, то на другую.
Тоже самое касается внешних ссылок. Невозможно сосредоточиться максимально на продвижении одной страницы, а это в итоге не раскрывает потенциал страницы полностью. Или же, к примеру, покупаются ссылки на одну страницу, а на самом деле в индексе совершенно другая страница.
В результате чего сайт будет занимать позиции ниже, чем мог бы. Атрибут rel=canonical как раз позволяет нам оставить в индексе только самую приоритетную страницу. Также весь ссылочный вес передается на нее.
Чтобы в индексе была только одна страница, нужно прописать на страницах дубликатах в разделеканоническую ссылку на приоритетную:
Откуда могут появиться дублирующиеся страницы?
Если для удаления дублей, можно воспользоваться 301 редиректом, я рекомендую в первую очередь обратить внимание на него. Если же 301 редирект не помогает или его использование неуместно, то на помощь можно позвать канонические ссылки, только будьте аккуратными.
Статья сайта относится к нескольким рубрикам
Если в ЧПУ вашего сайта выводится рубрика статей, то можно столкнуться с проблемой. Одна и та же статья может располагаться сразу по нескольким URL адресам. Вот у меня, к примеру, есть статья про безопасность в WordPress, она располагается сразу в 2-х категориях: “Полезное для блога” и “WordPress плагины”. Поэтому доступна сразу по 2-ум разным URL адресам:
Это для нас, обычных посетителей, как будто страница одна и та же. Для поисковиков же это 2 разные страницы, которые являются дублями. И они могут включить в индекс либо сразу обе страницы, либо не ту, которую хотелось бы. Как раз в подобных случаях выручает rel=canonical, который позволяет указать поисковикам, что нужно проиндексировать только одну конкретную страницу.
В моем случае со страницы https://wpnew.ru/sozdanie-bloga/poleznoe_dlya_bloga/bezopasnost-wordpress.html прописан канонический URL на https://wpnew.ru/sozdanie-bloga/razdel-4-plaginy/bezopasnost-wordpress.html и поэтому в индексе только второй вариант страницы.
Данный rel=canonical у меня прописывается автоматически с помощью плагина для WordPress, более подробно в конце урока.
Товары интернет-магазина в нескольких категориях
Еще одно из самых популярных явлений, это когда товары в интернет-магазинах расположены сразу в нескольких категориях. В виде примера приведу товар iPhone 6s, который может располагаться сразу на нескольких страницах:
Все точно также, нужно указать со всех страниц rel=canonical на основную, приоритетную страницу. Как выбрать правильно каноническую страницу расскажу ниже.
Страница печати, разные id
Также на некоторых страницах встречаются страницы для печати. У них к URL добавляется что-то вроде ?print=true. То есть, один и тот же контент может находиться на:
В таком случае со страницы site.ru/content/post-1?print=true нужно прописать в область(внимание, не в body!) следующее:
Благодаря этому действию, страница site.ru/content/post-1?print=true не будет участвовать в поиске, то есть не будет проиндексирована.
Тег more
Я же в идеале бы рекомендовал делать ссылки прямыми (с той же самой главной страницы), без тега more.
Дубли replytocom
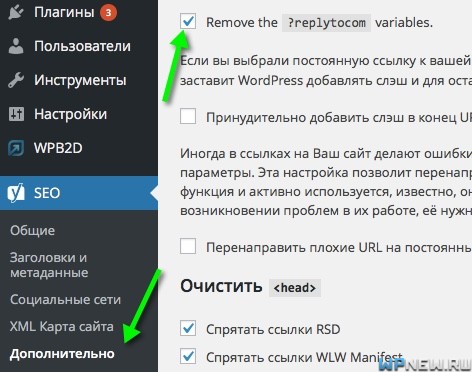
Партнерская программа
Когда реализуете партнерскую программу, часто много ссылок c “хвостами” начинают ссылаться на вас. Получается, что-то вроде этого: site.ru/?partner=id777. С подобных страниц тоже нужно прописывать атрибут canonical, чтобы они не попали в индекс.
Как правильно использовать rel=canonical
Как вы уже поняли, чтобы в индексе был только 1 вариант страницы, нужно со всех дублирующихся страниц проставить атрибут canonical. Вот как он должен выглядеть
Данный тег должен находиться внутри.
Как правильно выбрать канонический урл?
Каноническая страница – это та страница, которая рекомендуется поисковикам для индексации среди всех дублей. Какую же лучше выбрать?
Частые ошибки с атрибутом rel=canonical
Запомните: rel=canonical передает вес входящих ссылок.
Почитайте еще эти статьи (официальные руководства от Яндекса и Google):
Частные случаи использования rel=canonical
Сanonical сама на себя
Меня не раз спрашивали, можно ли ставить каноническую ссылку саму на себя? Такое обычно происходит при автоматической генерации с помощью разных плагинов или силами CMS. Ответ – да, можно, ничего в этом плохого нет.
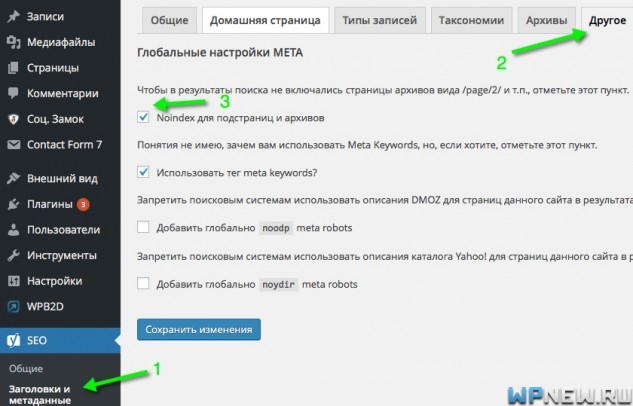
Canonical для страниц пагинации
Многие вебмастера хотят сделать rel=canonical со страниц пагинации (site.ru/category/page/2) на первую страницу (site.ru/category). Это неправильно, как я считаю. Все-таки здесь встречаются не полные дубли, такие страницы пагинации лучше закрыть с помощью:
В WordPress это можно сделать автоматически, поставив галочку в плагине WordPress SEO by Yoast:
Товары
Если товары разделены на несколько страниц (их много и сделана разбивка на несколько страниц), то лучше основным каноническим урлом сделать вывод всех товаров, которое обычно выводится с помощью добавления к URL что-то подобное этому ?all=products.
Атрибут rel=canonical в WordPress
Многие SEO плагины для WordPress очень хорошо дружат с атрибутом rel=canonical. Мой любимый и, как я считаю, лучший SEO плагин Yoast SEO вообще ничего не требует. Просто достаточно его активировать и необходимые канонические URL сами прописываются.
В некоторых других SEO плагинах в настройках нужно просто поставить галочку напротив “Канонические страницы” (или еще что-то подобное).
То есть по умолчанию, если статья на моем блоге присвоена сразу к нескольким категориям, то автоматически прописывается каноническая страница. Именно поэтому на странице https://wpnew.ru/sozdanie-bloga/poleznoe_dlya_bloga/bezopasnost-wordpress.html у меня прописан следующий атрибут rel=canonical (обратите внимание, это другой URL):

По умолчанию, благодаря плагину Yoast SEO, если пост располагается сразу в нескольких категориях, в индекс же попадает только один вариант.
Выводы
Я надеюсь, что вполне понятно, смог объяснить, что такое атрибут rel=canonical и как им пользоваться. Настоятельно рекомендую ознакомиться вам еще с этим уроком: Как удалить ненужные страницы в индексе Яндекса и Google. Все эти действия с rel=canonical, 301-ым редиректом, meta name robots, файлом robots.txt позволят сделать выдачу вашего сайта “чистым”.
Я за “чистый” индекс без дублей, служебных страниц и пр. ненужных вещей. Благодаря чистоте SEO продвижение сайта будет проще и правильнее.
И еще: чтобы не было подобных заморочек я рекомендую будущие ваши сайты создавать без указания категорий в URL статей/товаров. То есть пусть будет что-то вроде:
Отдельное спасибо за ретвиты и репосты, мои друзья. Обязательно жду ваших мыслей в комментариях.
Поиск страниц с атрибутом rel=»canonical» на сайте
Что такое атрибут rel=»canonical»
Как прописать атрибут rel=»canonical» в коде страницы
Задается он с помощью тега LINK с атрибутом rel=”canonical” в блоке HEAD страницы. Для этого необходимо поместить в HEAD следующую запись:
Где «канонический URL» – это полный адрес страницы, которую вы считаете предпочтительной для индексации.
Пример употребления атрибута:
Обязательно использовать относительный (полный) путь на страницу!
В каких случаях применяют этот атрибут?
Этот атрибут применяется в тех случаях, когда на сайте имеются страницы с идентичным или очень похожим контентом. Чтобы поисковая система не расценивала такие страницы как дубли, необходимо разместить на них ссылку на предпочтительную для индексации каноничную страницу. Это один из самых простых способов борьбы с дублями страниц. Более подробно изучить информацию про дубли страниц и способы борьбы с ними вы сможете в нашей статье Дубли страниц на сайте.
Почему это важно для поисковых систем
Информация от Яндекс о поддержке поисковыми роботами rel=»canonical» появилась еще в 2011 году – https://yandex.ru/blog/webmaster/10371.
Кроме того, вы можете ознакомиться с рекомендациями от Яндекс по употреблению rel=»canonical» в разделе Яндекс.Помощь.
Google также официально рекомендует использовать rel=»canonical» для борьбы с повторяющимися URL. Об этом можно прочитать в руководстве Консолидация повторяющихся URL.
Почему нужно знать, на каких страницах сайта есть rel=»canonical»
Как обнаружить на сайте страницы с rel=»canonical»
Это можно сделать с помощью сервиса Labrika. Отчет «Страницы с rel=»canonical» вы можете найти в разделе «Технический аудит» левого бокового меню.
Страница с отчетом выглядит следующим образом:

Цифрами на странице обозначены:
После получения данных о канонических страницах на сайте вы сможете увидеть ошибки, если они есть, и исправить их, чтобы избежать проблем с индексацией сайта.
Зачем нужен rel canonical

Canonical — в переводе с английского канонический, то есть принятый за образец, эталонный. У web-мастеров это слово имеет свое утилитарное назначение: в HTML-коде оно указывает на приоритетную для индексации страницу, контент которой частично или полностью дублируется в других документах на сайте. Попробуем разобраться с логикой применения тега canonical.
Содержание
Что такое rel canonical
Чтобы объяснить на пальцах, что такое тег «рел каноникал», нужно начать с базовых терминов из словарика юного HTML-щика.
Атрибут rel (от англ. relationship — взаимосвязь) определяет отношения между текущей страницей и документом, на который ведет ссылка под атрибутом href.
В свою очередь, атрибут href (от англ. hypertext reference — гиперссылка) сообщает, о какой ссылке вообще идет речь, т. е. задает адрес документа.
Rel с помощью разных атрибутов сообщает поисковому роботу, что ему делать с указанной далее ссылкой. Например:
Именно каноническую страницу поисковик будет выводить на SERP (страницу выдачи). Правда, это не совсем команда, а, скорее, пожелание. Поисковик волен его проигнорировать и посчитать приоритетной любую из дублирующихся страниц.
Часто canonical называют meta-тегом, т.к. он прописывается в контейнере и передает уточняющую информацию краулеру, но, строго говоря, это не тег, а значение атрибута rel, который прописывается для тега .
Зачем вообще нужны эти заморочки с каноническими ссылками? Атрибут каноникал решает проблему с дублями страниц, которые негативно отражаются на продвижении сайта:
Чтобы как-то навести порядок с дублями, в 2009 г. команда Google дала возможность web-мастерам канонизировать URL определенной страницы. Как это было, читайте здесь: Specify your canonical | Google Search Central Blog.
Настройка канонических документов не только обеспечивает приоритет при индексировании и избавляет от проблем с совпадающими кусками контента, но и передает ссылочную массу со всех дублей на основной адрес.
Когда нужна канонизация

Атрибут rel canonical помогает закрывать от индексации дубли. Ситуации, когда на различающихся URL оказывается одинаковый контент, чаще всего возникают по трем причинам.
HTTP:// и HTTPS:// протоколы
С точки зрения робота это 4 разных сайта, но для пользователя, с какого бы адреса он ни зашел, не будет никакой разницы. Это классический случай, когда на пустом месте поисковый алгоритм может обнаружить дубли, поэтому нужно указать ему canonical URL.
Важно! Если вы работаете по SSL-протоколу, каноническим нужно назначить адрес HTTPS, т.к. защищенный домен — это важный фактор ранжирования.
Генерирование дублей CMS
Сейчас даже самый скромный интернет-магазин предлагает покупателям возможность настроить параметры выбора товара.
Например, мы продаем садового гнома. Основная его категория в каталоге — «Садовые фигуры», но к 8 марта мы решили предложить гнома в разделе «Подарок маме». И вот у нас уже 2 URL на одну позицию:
Таких категорий может быть очень много: «Садовые гномы до 50 см», «Фигуры для сада производства Франции» и т.п. И все это дубли исходной карточки нашего гнома-001 на различающихся URL. Чтобы поисковик не запутался и не пессимизировал сайт из-за кучи дублирующегося контента на разных адресах, нужно присвоить приоритетному URL атрибут rel со значением canonical.
По такому принципу CMS генерируют дублирующиеся страницы везде, где возможна сортировка позиций по различным параметрам: цене, популярности, отзывам, прочим фильтрам (цвет, размер, сезон, бренд и т.п.). Сюда же можно отнести адреса с динамическими GET-параметрами и UTM-метками для отслеживания рекламных кампаний или переходов из соцсетей.
Пагинация
Пагинация — это распределение большого массива данных по страницам. Она существенно облегчает работу пользователя с большими объемами информации и увеличивает скорость загрузки сайта. Без пагинации страница сайта с каталогом товаров или библиотекой статей будет разворачиваться этаким бесконечным манускриптом.
Пагинация реализуется разными способами. Обычно это или список с номерами страниц, или буквенный каталог, или цифры, задающие диапазон отображаемых карточек.

Пагинация делает удобным взаимодействие с сайтом, но переходы между страницами провоцируют формирование дублей. Чтобы этого избежать, можно использовать canonical одним из двух способов:
Правила формирования канонических страниц
Чаще всего канонической назначается первоисходая страница, где с самого начала был опубликован дублирующийся в дальнейшем контент. Прописывая для тега атрибут rel=canonical, нужно соблюдать определенные правила.
Как правильно настроить канонизацию

Путь настройки canonical зависит от характера дублирующихся документов и от способа управления содержимым сайта.
Вручную в HTML-коде
Характер дублей: HTML-документы.
Где руками прописывать атрибут rel=canonical, мы уже выяснили: выбираем приоритетную страницу и даем указания боту в HTML-коде в контейнере по формуле: . После остается ввести эту команду на все дубли.
В плагине CMS
Характер дублей: HTML-документы.
На большинстве популярных движков — в базовой комплектации или в виде отдельного плагина — предусмотрен функционал для автоматической настройки канонизации. Например:
В заголовке HTTP
Характер дублей: документы не в формате HTML.
На запрос дубля сервер должен отдавать адрес первоисточника.
Внесение команды в HTTP-заголовок через PHP:
В файле Sitemap
Характер дублей: HTML-документы. Карта сайта создается для ускорения индексации и не заменяет указание canonical в коде.
Google настаивает, что в Sitemap нужно указывать только канонические ссылки. Соответственно, все URL в XML-файле поисковики будут по умолчанию считать приоритетными при индексировании.
Через 301 редирект
Характер дублей: зеркала сайта, устаревшие данные.
Перенаправить трафик и передать вес на основную страницу с дублей можно, настроив 301 редирект. Способ актуален для следующих ситуаций:
Ошибки настроек canonical

Ошибки канонизации сводят всю кропотливую работу на нет: поисковые роботы просто игнорируют некорректные рекомендации. Перечислим самые распространенные траблы.
Проверка настроек canonical
Для контроля канонических ссылок удобен многофункциональный инструмент комплексной SEO-проверки Screaming Frog SEO Spider Website Crawler. Если вам нужно проверить меньше 500 URL, будет достаточно бесплатной версии. За безлимитную лицензию придется платить £149.00 в год. Отчет Canonical доступен во вкладке Canonicals.

В Google Search Console есть свой инструмент для анализа URL. Подробнее о работе с инструментом читайте в справке суппорта Google здесь.
В Yandex отчет по canonical находится в панели Вебмастера во вкладке «Индексирование» → «Страницы в поиске». При корректной настройке каноничности дубли страниц исчезают из поиска и попадают в список «Исключенные страницы».
Когда Яндекс-бот находит какие-то нестыковки, он присылает уведомление с разъяснениями, что не так и как это исправить. Но известны случаи технических сбоев, когда web-мастера получали странные послания, что «у важных страниц изменился атрибут rel canonical», хотя никаких манипуляций с канонизацией перед этим не проводилось.



