2.5. Символы и строки¶
До сих пор наши программы работали только с числами. Но многим программам надо работать с текстовыми данными. Для этого есть два основных объекта — символы и строки.
2.5.1. Символьный тип данных¶
В питоне, чтобы сохранить символ в переменной, надо просто написать
Вводить символы можно обычной командой input() :
(именно прямо так), выводить — обычным print :
(На самом деле, в питоне нет отдельного «типа» для символов, символ в питоне — это просто строка длины 1, про строки см. ниже. Но часто удобно думать про символы отдельно от строк.)
2.5.2. Коды символов¶
Есть общепринятая договоренность, которая каждому числу от 0 до 255 ставит в соответствие некоторый символ. Точнее, таких договоренностей есть несколько, они называется кодировки, но для латинских букв, цифр и частоупотребимых символов типа того же доллара, запятой или плюса, во всех кодировках соответствующие числа одинаковы. Для русских букв это не так: в разных кодировках им соответствуют разные числа, но это отдельная тема.
Эта общепринятая сейчас кодировка для латинских букв, цифр и частоупотребимых символов называется ASCII, иногда говорят таблица ASCII. Основная часть этой таблицы выглядит так:
| 32 | 48 | 0 | 64 | @ | 80 | P | 96 | ` | 112 | p | |
| 33 | ! | 49 | 1 | 65 | A | 81 | Q | 97 | a | 113 | q |
| 34 | « | 50 | 2 | 66 | B | 82 | R | 98 | b | 114 | r |
| 35 | # | 51 | 3 | 67 | C | 83 | S | 99 | c | 115 | s |
| 36 | $ | 52 | 4 | 68 | D | 84 | T | 100 | d | 116 | t |
| 37 | % | 53 | 5 | 69 | E | 85 | U | 101 | e | 117 | u |
| 38 | & | 54 | 6 | 70 | F | 86 | V | 102 | f | 118 | v |
| 39 | ‘ | 55 | 7 | 71 | G | 87 | W | 103 | g | 119 | w |
| 40 | ( | 56 | 8 | 72 | H | 88 | X | 104 | h | 120 | x |
| 41 | ) | 57 | 9 | 73 | I | 89 | Y | 105 | i | 121 | y |
| 42 | * | 58 | : | 74 | J | 90 | Z | 106 | j | 122 | z |
| 43 | + | 59 | ; | 75 | K | 91 | [ | 107 | k | 123 | < |
| 44 | , | 60 | 76 | L | 92 | \ | 108 | l | 124 | | | |
| 45 | — | 61 | = | 77 | M | 93 | ] | 109 | m | 125 | > |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | |
| 47 | / | 63 | ? | 79 | O | 95 | _ | 111 | o | 127 | — |
Здесь символ номер 32 — это пробел.
Например, символ доллар имеет номер (говорят код) 36, а символ N — 78.
Обратите внимание, что все цифры идут подряд, все заглавные буквы идут подряд, и все маленькие буквы идут подряд. Это нам будет очень полезно. (Для русских букв это выполняется не всегда.)
Узнать код символа в питоне можно операцией ord, а узнать символ по коду можно операцией chr. Например:
Нам поможет то, что все цифры идут подряд. Поэтому достаточно из кода цифры вычесть код нуля:
2.5.3. Сравнения символов¶
Символы можно сравнивать операторами =, >, =, len(s) :
В-третьих, строки можно складывать. Сложить две строки — значит приписать к одной строке другую:
Прибавлять можно и символы:
Наконец, строковые константы — это уже привычные вам последовательности символов в кавычках:
На самом деле, в питоне можно использовать как апострофы (символы ‘ ), так и кавычки (символы » )
Аналогично для записи символа «апостроф»/»кавычка» в переменную типа char:
Поскольку символ \ имеет такой особый смысл, то чтобы записать в строку прямо этот символ, его надо написать два раза:
Еще частный случай строки — пустая строка, т.е. строка длины ноль:
Ну и наконец, строка — это все-таки массив символов. Можно использовать все известные вам операции над массивами (писать s[i], чтобы получить доступ к i-му символу строки, и т.д.). Например, так можно проверить, есть ли в строке пробелы:
2.5.6. int и т.п.¶
Есть еще три полезных команды:
Они переводят числа в строки и обратно, с int вы уже сталкивались.
2.5.7. Другие операции¶
Вы знаете ряд хитрых команд работы с массивами, и иногда будет возникать желание их использовать при работе со строками. Лучше их не используйте, пока вы точно не будете понимать не только что, но и насколько быстро они работают. В большинстве случаев можно обойтись без них (и так даже будет проще!), плюс вы точно не знаете, как долго они работают.
Например, пусть вам надо из строки удалить все пробелы. Можно писать примерно так (считаем, что у вас уже есть исходная строка s ):
Но это работает долго (поверьте мне 🙂 ) и требует от вас помнить все эти команды (а на питоне — еще и осознавать код). Проще так:
How to get the ASCII value of a character
How do I get the ASCII value of a character as an int in Python?


5 Answers 5
The function ord() gets the int value of the char. And in case you want to convert back after playing with the number, function chr() does the trick.
In Python 2, there was also the unichr function, returning the Unicode character whose ordinal is the unichr argument:
Note that ord() doesn’t give you the ASCII value per se; it gives you the numeric value of the character in whatever encoding it’s in. Therefore the result of ord(‘ä’) can be 228 if you’re using Latin-1, or it can raise a TypeError if you’re using UTF-8. It can even return the Unicode codepoint instead if you pass it a unicode:

You are looking for:
The accepted answer is correct, but there is a more clever/efficient way to do this if you need to convert a whole bunch of ASCII characters to their ASCII codes at once. Instead of doing:
or the slightly faster:
you convert to Python native types that iterate the codes directly. On Python 3, it’s trivial:
Encoding as a type that natively iterates by ordinal means the conversion goes much faster; in local tests on both Py2.7 and Py3.5, iterating a str to get its ASCII codes using map(ord, mystr) starts off taking about twice as long for a len 10 str than using bytearray(mystr) on Py2 or mystr.encode(‘ascii’) on Py3, and as the str gets longer, the multiplier paid for map(ord, mystr) rises to
Исчерпывающее руководство по Юникоду и кодировке символов в Python

Вводная часть статьи даст общее понимание работы с Юникодом, не привязанное к какому-то определённому языку, однако практические примеры будут приведены именно на Python, а их описание будет довольно лаконичным.
Изучив эту статью, вы:
Система нумерации и кодировка символов настолько тесно связаны, что их придётся раскрыть в одном руководстве, в противном случае материал будет неполным.
Прим. Статья ориентирована на Python 3, а все примеры кода созданы с помощью оболочки CPython 3.7.2. Большая часть более ранних версий Python 3 также будут корректно обрабатывать код. Если вы всё ещё используете Python 2 и различия в обработке текста и бинарных данных между 2 и 3 версиями языка вас отпугивают, это руководство может помочь вам преодолеть барьер.
Что такое кодировка символов?
Существуют десятки, если не сотни, кодировок символов. Понять эту концепцию легче всего, разобрав одну из самых простых, ASCII.
Она охватывает следующее:
Приведём формальное определение кодировки символов.
13 сентября – 9 октября, Санкт-Петербург и онлайн, Беcплатно
На самом высоком уровне — это способ перевода символов (таких как буквы, знаки пунктуации, служебные знаки, пробелы и контрольные символы) в целые числа и затем непосредственно в биты. Каждый символ может быть закодирован уникальным двоичным кодом. Если вы плохо знакомы с концепцией битов, не волнуйтесь, мы вскоре о ней поговорим.
Группы символов выделяют в отдельные категории. Каждому символу соответствует кодовая точка, которую можно рассматривать просто как целое число. В таблице ASCII символы сегментированы следующим образом:
| Диапазон кодовых точек | Класс |
|---|---|
| от 0 до 31 | Контрольные и неотображаемые символы |
| от 32 до 64 | Знаки пунктуации, символы, числа и пробел |
| от 65 до 90 | Буквы английского алфавита в верхнем регистре |
| от 91 до 96 | Дополнительные графемы, такие как [ и \ |
| от 97 до 122 | Буквы английского алфавита в нижнем регистре |
| от 123 до 126 | Дополнительные графемы, такие как < и | |
| 127 | Контрольный неотображаемый символ ( DEL ) |
Всего кодировка ASCII содержит 128 символов. В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
| Кодовая точка | Символ (имя) | Кодовая точка | Символ (имя) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (Start of Heading) | 65 | A |
| 2 | STX (Start of Text) | 66 | B |
| 3 | ETX (End of Text) | 67 | C |
| 4 | EOT (End of Transmission) | 68 | D |
| 5 | ENQ (Enquiry) | 69 | E |
| 6 | ACK (Acknowledgment) | 70 | F |
| 7 | BEL (Bell) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (Horizontal Tab) | 73 | I |
| 10 | LF (Line Feed) | 74 | J |
| 11 | VT (Vertical Tab) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (Carriage Return) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (Shift In) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Device Control 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (Negative Acknowledgment) | 85 | U |
| 22 | SYN (Synchronous Idle) | 86 | V |
| 23 | ETB (End of Transmission Block) | 87 | W |
| 24 | CAN (Cancel) | 88 | X |
| 25 | EM (End of Medium) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (Escape) | 91 | [ |
| 28 | FS (File Separator) | 92 | \ |
| 29 | GS (Group Separator) | 93 | ] |
| 30 | RS (Record Separator) | 94 | ^ |
| 31 | US (Unit Separator) | 95 | _ |
| 32 | SP (Space) | 96 | ` |
| 33 | ! | 97 | a |
| 34 | « | 98 | b |
| 35 | # | 99 | c |
| 36 | $ | 100 | d |
| 37 | % | 101 | e |
| 38 | & | 102 | f |
| 39 | ‘ | 103 | g |
| 40 | ( | 104 | h |
| 41 | ) | 105 | i |
| 42 | * | 106 | j |
| 43 | + | 107 | k |
| 44 | , | 108 | l |
| 45 | — | 109 | m |
| 46 | . | 110 | n |
| 47 | / | 111 | o |
| 48 | 0 | 112 | p |
| 49 | 1 | 113 | q |
| 50 | 2 | 114 | r |
| 51 | 3 | 115 | s |
| 52 | 4 | 116 | t |
| 53 | 5 | 117 | u |
| 54 | 6 | 118 | v |
| 55 | 7 | 119 | w |
| 56 | 8 | 120 | x |
| 57 | 9 | 121 | y |
| 58 | : | 122 | z |
| 59 | ; | 123 | < |
| 60 | 124 | | | |
| 61 | = | 125 | > |
| 62 | > | 126 | |
| 63 | ? | 127 | DEL (delete) |
Модуль string
Модуль string — простой и удобный инструмент, разграничивающий содержащиеся в ASCII символы по группам, разделяя их в строки-константы. Вот как выглядит основная часть модуля:
Мы можем использовать определённые в модуле константы для рутинных операций:
Что такое биты
Настало время вспомнить, что такое бит, базовая единица информации, которой оперируют вычислительные устройства.
Бит — это сигнал, который имеет два возможных состояния. Есть различные способы символического отображения этих состояний:
Таблица ASCII из предыдущего раздела использует то, что обычно назвали бы числами (от 0 до 127), однако для наших целей важно понимать, что это десятичные числа (с основанием 10).
Каждое из этих десятичных чисел можно выразить последовательностью бит (числом с основанием 2). Вот таблица соотношения двоичных и десятичных чисел:
| Десятичное | Двоичное (кратко) | Двоичное (в байте) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что при увеличении десятичного числа n для его отображения (а следовательно и для отображения символа, относящегося к этому числу) требуется всё больше значимых бит.
Вот удобный метод представить строки ASCII как последовательность бит. Каждый символ из строки ASCII переводится в последовательность из 8 нолей и единиц с пробелами между этими последовательностями:
Строковой литерал f-string f»
На самом деле этот метод можно использовать разве что для развлечения. Он выдаст ошибку для любого символа, не представленного в ASCII-таблице. Позже мы рассмотрим, как эта проблема решается в других кодировках.
Нам нужно больше бит
Исходя из определения бита, можно вывести следующую закономерность: при определённом количестве бит n с их помощью можно выразить 2 n разных значений.
Вот что это означает:
В качестве естественного вывода из приведённой выше формулы мы можем установить следующее: для того, чтобы вычислить количество бит, необходимых для выражения определённого числа разных значений, нам нужно найти n в уравнении 2 n =x, где переменная x известна.
Вот как можно это рассчитать:
Округление вверх в методе n_bits_required() требуется для расчёта значений, которые не являются чистой степенью двойки. К примеру, вам нужно сохранить набор из 110 различных символов. Для этого потребуется log(110) / log(2) == 6.781 бит, но поскольку бит для вычислительной техники является мельчайшей неделимой величиной, для отображения 110 различных значений нам понадобится 7 бит, при этом несколько значений останутся невостребованными.
Всё сказанное служит для обоснования одной идеи: ASCII, строго говоря, семибитная кодировка. Эта таблица содержит 128 кодовых точек, и, соответственно, символов, от 0 до 127 включительно. Это требует 7 бит:
Проблема заключается в том, что современные компьютеры не используют для хранения чего-либо семибитные последовательности. Основной единицей хранения информации современных вычислительных устройств являются восьмибитные последовательности, байты.
Прим. В этой статье под байтом подразумевается группа из 8 бит, как повелось с 60-х годов прошлого века. Если вам не по душе это новомодное название, можете называть их октетами.
То, что ASCII-таблица использует 7 бит из доступных 8, означает, что память вычислительного устройства, занятого строками символов ASCII, наполовину пуста. Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Прим. перев. Если быть точным, то пустой остаётся только одна восьмая часть памяти. Однако с помощью именно этого незадействованного бита можно было бы создать вдвое больше кодовых точек.
Вы можете выразить числа от 0 до 3 всего двумя битами, от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011. Самая большая кодовая точка ASCII, 127, требует только 7 значимых бит.
С учётом этого взгляните, как метод make_bitseq() преобразует строки ASCII в строки, состоящие из байт, где каждый символ требует один байт:
Неэффективное использование восьмибитной структуры памяти современных вычислительных устройств привело к появлению неструктурированного семейства конфликтующих кодировок, задействующих оставшуюся незанятой половину кодовых точек, доступных в одном байте.
Несмотря на попытку задействовать дополнительный бит, эти конфликтующие кодировки не могли отобразить все возможные символы, используемые человечеством в письменности.
Со временем появилась одна большая схема кодировки, которая объединила их. Однако, прежде чем мы до этого доберёмся, поговорим немного о краеугольных камнях схем кодировки символов — системах счисления.
Изучаем основы: другие системы счисления
В ASCII-таблице, как мы увидели, каждый символ соответствует числу от 0 до 127.
Этот диапазон чисел выражен в десятичной системе счисления. Именно эту систему используют для счёта люди, просто потому что на руках у нас по 10 пальцев.
Однако существуют и другие системы счисления, которые, в частности, широко используются в исходном коде CPython. Следует понимать, что действительное число не изменяется, а системы счисления просто по-разному его выражают.
Вопрос, какое число записано в строке «11» покажется странным, ведь для большинства очевидно, что это одиннадцать.
Однако в строке может быть представлено и другое число, в зависимости от системы счисления. Помимо десятичной, используются такие общепринятые альтернативы:
Что же мы подразумеваем, говоря что определённая система счисления имеет основу N?
Один из способов объяснения разных систем счисления заключается в том, чтобы представить, что у вас N пальцев.
Если же вам требуется более подробное объяснение систем счисления, обратитесь к книге Чарльза Петцольда «Код». В этой книге детально объясняются основы работы вычислительной техники.
Чаще в Python для обозначения того, что целое число представлено в системе счисления, отличной от десятичной, используют префиксы-литералы. Для каждой из трёх альтернативных систем существует свой литерал.
| Тип литерала | Префикс | Пример |
|---|---|---|
| Нет | Нет | 11 |
| Binary literal | 0b или 0B | 0b11 |
| Octal literal | 0o или 0O | 0o11 |
| Hex literal | 0x или 0X | 0x11 |
| Десятичные | Двоичные | Восмеричные | Шестнадцатеричные |
|---|---|---|---|
| 0 | 0b0 | 0o0 | 0x0 |
| 1 | 0b1 | 0o1 | 0x1 |
| 2 | 0b10 | 0o2 | 0x2 |
| 3 | 0b11 | 0o3 | 0x3 |
| 4 | 0b100 | 0o4 | 0x4 |
| 5 | 0b101 | 0o5 | 0x5 |
| 6 | 0b110 | 0o6 | 0x6 |
| 7 | 0b111 | 0o7 | 0x7 |
| 8 | 0b1000 | 0o10 | 0x8 |
| 9 | 0b1001 | 0o11 | 0x9 |
| 10 | 0b1010 | 0o12 | 0xa |
| 11 | 0b1011 | 0o13 | 0xb |
| 12 | 0b1100 | 0o14 | 0xc |
| 13 | 0b1101 | 0o15 | 0xd |
| 14 | 0b1110 | 0o16 | 0xe |
| 15 | 0b1111 | 0o17 | 0xf |
| 16 | 0b10000 | 0o20 | 0x10 |
| 17 | 0b10001 | 0o21 | 0x11 |
| 18 | 0b10010 | 0o22 | 0x12 |
| 19 | 0b10011 | 0o23 | 0x13 |
| 20 | 0b10100 | 0o24 | 0x14 |
Кстати, вы можете сами убедиться, что подобные способы записи чисел очень часто используется в Стандартной Библиотеке Python. Найдите папку lib/python3.7/ в своей системе, перейдите в неё и введите команду:
Введение в Юникод
Как видите, проблема ASCII в том, что этой таблицы недостаточно для отображения знаков, символов и глифов, использующихся во всех языках и диалектах мира. Её недостаточно даже для английского языка.
Юникод служит тем же целям, что и ASCII, но содержит намного больший набор кодовых точек. В период времени между появлением ASCII и принятием Юникода использовалось ещё несколько различных кодировок, но рассматривать их подробно нет смысла, так как Юникод и одна из его схем, UTF-8, в настоящее время стали использоваться практически повсеместно.
Вы можете представить Юникод как расширенную версию ASCII-таблицы — с 1 114 112 возможными кодовыми точками, от 0 до 1 114 111. Это 17*(2 16 ) или 0x10ffff в шестнадцатеричном представлении. Фактически, ASCII является частью Юникода, так как первые 128 символов этих кодировок полностью совпадают.
Юникод содержит практически любой символ, который только можно представить, включая дополнительные непечатаемые. Например, кодовая точка 8207 соответствует отметке RTL, которая используется для смены направления письма. Она полезна в текстах, где абзацы на одном из европейских языков соседствуют с абзацами на арабских языках.
Прим. Кстати, если уж мы хотим быть совсем точны в деталях, то надо отметить ещё один факт. Исторически сложилось, что в Юникоде доступны только 1 111 998 кодовых точек.
Юникод и UTF-8
Довольно скоро стало понятно, что все необходимые символы невозможно вместить в таблицу, используя только один байт. Современные, более ёмкие кодировки требовали использования больших объёмов.
Ранее мы упоминали, что Юникод сам по себе не является кодировкой. И вот почему.
Юникод не содержит указаний по извлечению из текста бит, он работает только с кодовыми точками. В нём нет стандарта конверсии текста в двоичные данные и обратно.
Юникод является абстрактным стандартом кодировки. Для практического его применения чаще всего используют схему UTF-8. Стандарт Юникод (таблица соответствий символов кодовыми точкам) определяет несколько различных кодировок на основе единого набора символов.
Как и менее распространённые UTF-16 и UTF-32, UTF-8 — формат кодировки для отображения символов Юникода в двоичном виде, используя один или несколько байт на один символ. UTF-16 и UTF-32 мы обсудим чуть позже, но пока нам интересен UTF-8 как самый популярный формат.
Сначала требуется разобрать термины «кодирование» и «декодирование».
Кодирование и декодирование в Python 3
Тип данных str в Python 3 рассчитан на представление текста в удобном для чтения формате и может содержать любые символы Юникода.
Кодирование и декодирование — это процесс перехода данных из одной формы в другую.
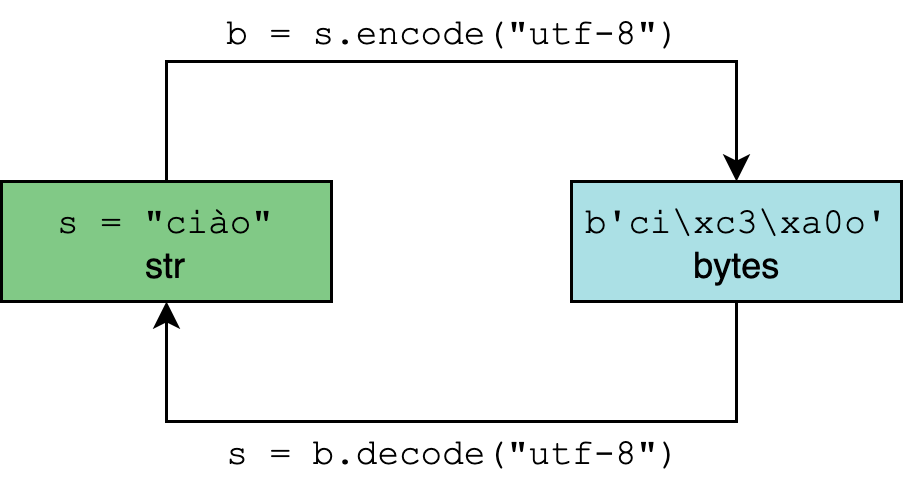
Таким образом символ ñ требует два байта для бинарного представления с помощью UTF-8.
Python 3: всё на Юникоде
Python 3 полностью реализован на Юникоде, а точнее на UTF-8. Вот что это означает:
Мы делаем упор на эти моменты, чтобы вы вдруг не подумали, что кодировка UTF-8 является универсальной. Она действительно широко распространена, но вы вполне можете столкнуться и с другими вариантами. Не будет лишним предусмотреть это в коде.
Один байт, два байта, три байта, четыре…
Одна из важнейших особенностей UTF-8 состоит в том, что это кодировка с переменным размером.
Вспомните раздел, посвящённый ASCII. Любой символ в этой таблице требует максимум одного байта пространства. Это можно быстро проверить с помощью следующего генератора:
С UTF-8 дела обстоят по-другому. Символы Юникода могут занимать от одного до четырёх байт. Вот пример четырёхбайтного символа:
Это небольшая, но важная особенность метода len() :
Таблица ниже показывает, сколько байт занимают основные типы символов.
*Такие как английский, арабский, греческий, ирландский.
**Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница).
***Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи.
Прим. У UTF-8 есть и другие технические особенности. Те, кто работает на Python, редко с ними сталкиваются, поэтому мы не будем раскрывать их в этой статье, но упомянем вкратце, чтобы сохранить полноту картины. Так, UTF-8 использует коды-префиксы, указывающие на количество байт в последовательности. Такой приём позволяет декодеру группировать байты в условиях кодировки с переменным размером. Количество байт в последовательности определяется первым её байтом. Другие технические подробности можно найти на странице Википедии, посвящённой UTF-8 или на официальном сайте.
Особенности UTF-16 и UTF-32
Рассмотрим альтернативные кодировки, UTF-16 и UTF-32. Различие между ними и UTF-8 в основном практическое. Продемонстрируем величину расхождения с помощью перевода туда и обратно:
В данном случае, когда мы кодируем четыре буквы греческого алфавита в двоичные данные с помощью UTF-8, а декодируем обратно в текст с использованием UTF-16, на выходе получается строка с совершенно другими символами (из корейского алфавита).
Так происходит, если для кодирования и декодирования применяют разные кодировки. Два варианта декодирования одного бинарного объекта могут вернуть текст даже на другом языке.
Таблица ниже демонстрирует количество байт, используемых в разных кодировках:
| Кодировка | Байт на символ (включительно) | Варьируемая длина |
|---|---|---|
| UTF-8 | От 1 до 4 | Да |
| UTF-16 | От 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Любопытный аспект семейства UTF: UTF-8 не всегда занимает меньше памяти, чем UTF-16. Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
Так получается из-за того, что кодовые точки в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) в кодировке UTF-8 занимают три байта, а в UTF-16 только два.
Это не означает, что нужно работать с UTF-16, независимо от того, насколько часто вы работаете с символами в этом диапазоне. Один из самых важных поводов придерживаться UTF-8 — в мире кодировок лучше держаться вместе с большинством.
Кроме того, в 2019 году компьютерная память стоит дёшево, и экономия четырёх байт за счёт использования нестандартной кодировки вряд ли стоит усилий.
Прим. перев. Есть и более весомые причины использовать UTF-8. Среди них её обратная совместимость с ASCII, а также то, что это самосинхронизирующаяся кодировка.
Python и встроенные функции
Вы освоили самую сложную часть статьи. Теперь посмотрим, как всё изученное реализуется на Python.
В Python есть несколько встроенных функций, каким-либо образом относящихся к системам счисления и кодировке:
Логически их можно сгруппировать по назначению.
В таблице ниже эти функции разобраны более подробно:
| Функция | Форма | Тип аргументов | Тип возвращаемых данных | Назначение |
|---|---|---|---|---|
| ascii() | ascii(obj) | Различный | str | Представление объекта символами ASCII. Не входящие в таблицу символы экранируются |
| bin() | bin(number) | number: int | str | Бинарное представление целого чиста с префиксом «0b» |
| bytes() | bytes(последовательность_целых_чисел) |
bytes([i])
i
int(x, base=10)
len(c) == 1
str(b[, enc[, errors]])
Дальше можно посмотреть полезные примеры использования этих функций.



